MANUALE MICROSOFT AZURE
Per imparare a utilizzarlo, per ottenere la certificazione
CORSI APPLICAZIONI MICROSOFT 365 PER IL LAVORO - Segnalali agli amici, costano pochissimo
MOTORE DI RICERCA E SCHEDE DIDATTICHE SULLE APPLICAZIONI MICROSOFT 365
ORGANIZZA LO STUDIO PER IL CORSO/CONCORSO OSS CON QUESTO DIAGRAMMA DI GANTT
WIKI CARDS EXPLORER CON RIASSUNTO AUTOMATICO SU CLIC
Dona 1 Euro
PROGETTO FINALE – Realizzazione di un e-commerce. Breve illustrazione.
CAPITOLO 1 – Panoramica Generale
Introduzione generale su Azure
Inquadramento argomenti del capitolo con slides illustrate
1. Servizi principali di Azure – Compute, Storage, Networking
2. Organizzazione e gestione delle risorse con i Resource Groups
3. Sicurezza in Azure – Postura, Identità e Protezione dei Dati
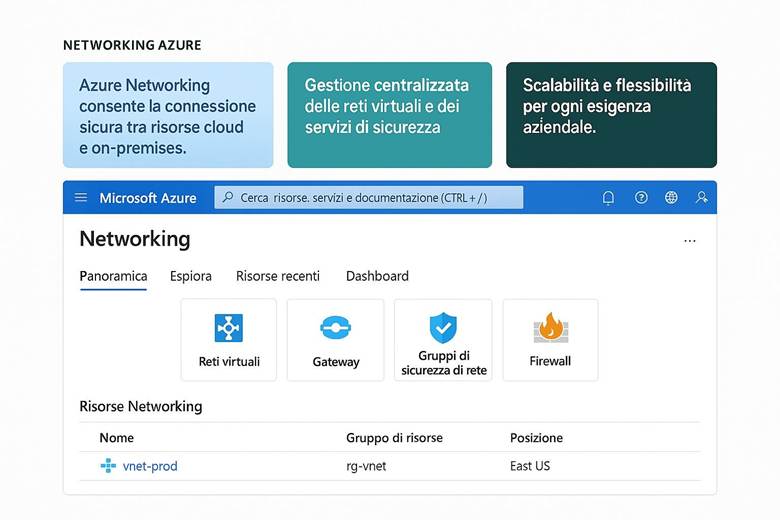
4. Reti in Azure – Connettività sicura e flessibile
5. Archiviazione dei dati – Tipi di account e ridondanza
6. Servizi di calcolo – le Macchine Virtuali (VM) in dettaglio
7. Monitoraggio e Osservabilità con Azure Monitor
8. Gestione dei costi e Budgeting nel cloud Azure
9. Azure Marketplace – Soluzioni pronte dei partner
CAPITOLO 2 – I principali servizi
Inquadramento argomenti del capitolo con slides illustrate
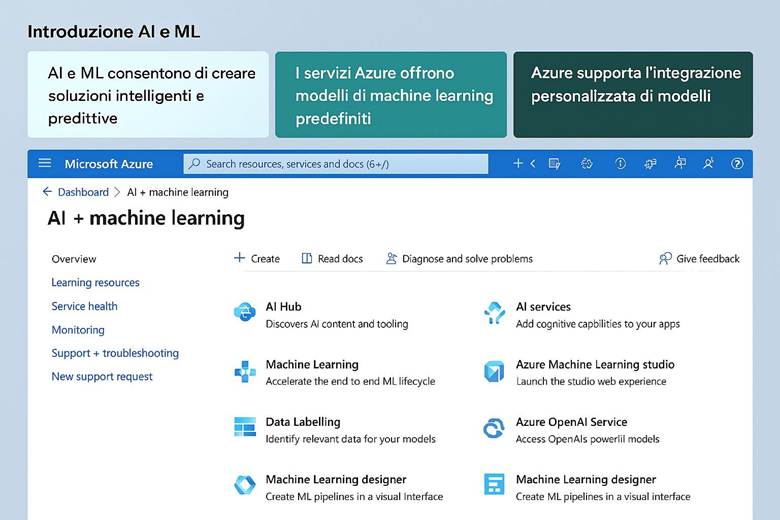
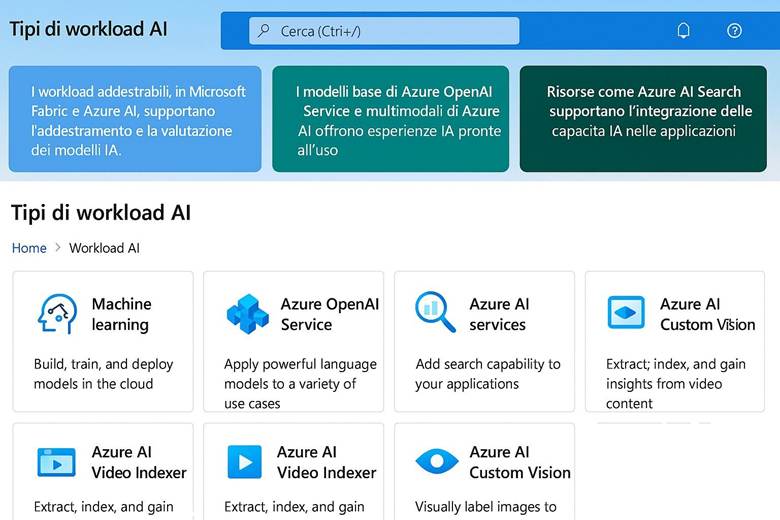
5. Intelligenza Artificiale e Machine Learning
6. DevOps e Application Lifecycle
9. Analisi dei Dati (Analytics e Big Data)
10. Governance e Gestione Cloud
CAPITOLO 3 – Il servizio di calcolo
Inquadramento argomenti del capitolo con slides illustrate
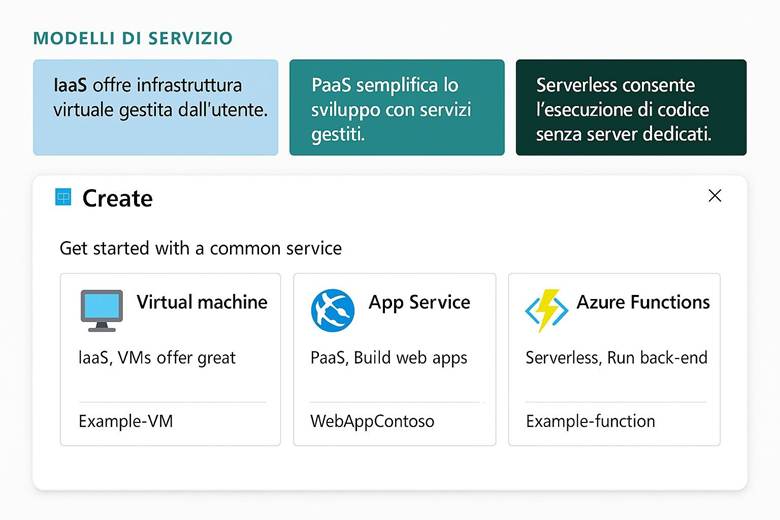
1. Modelli di servizio: IaaS, PaaS e Serverless
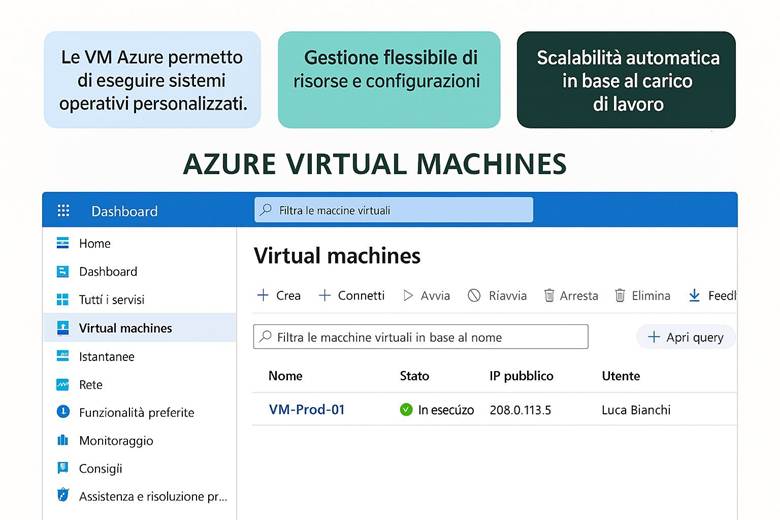
2. Azure Virtual Machines (IaaS) – Controllo e flessibilità
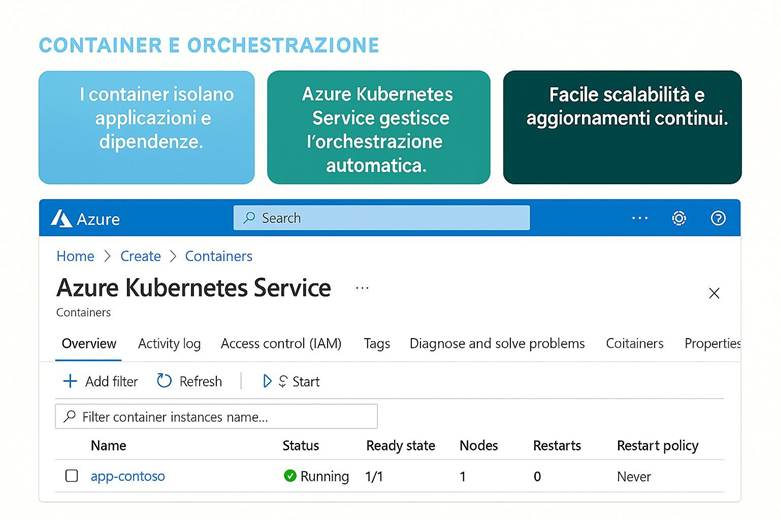
3. Container e orchestrazione con Azure Kubernetes Service (AKS)
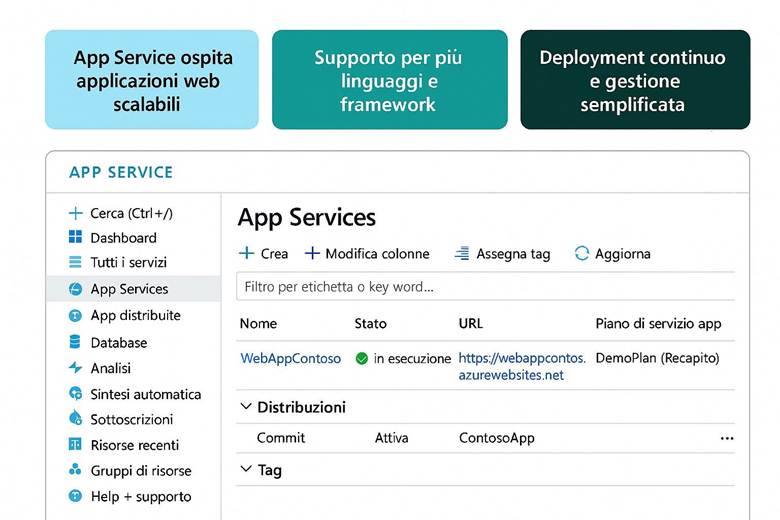
4. Azure App Service – Ospitare applicazioni web e API (PaaS)
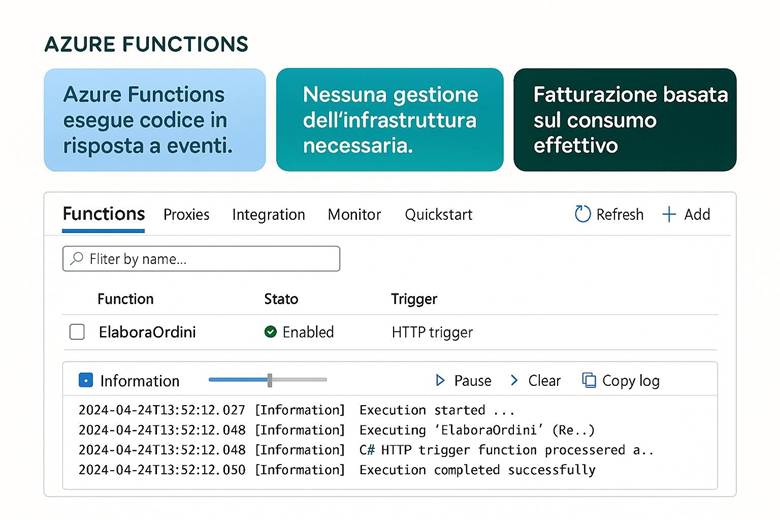
5. Azure Functions – Calcolo serverless basato su eventi
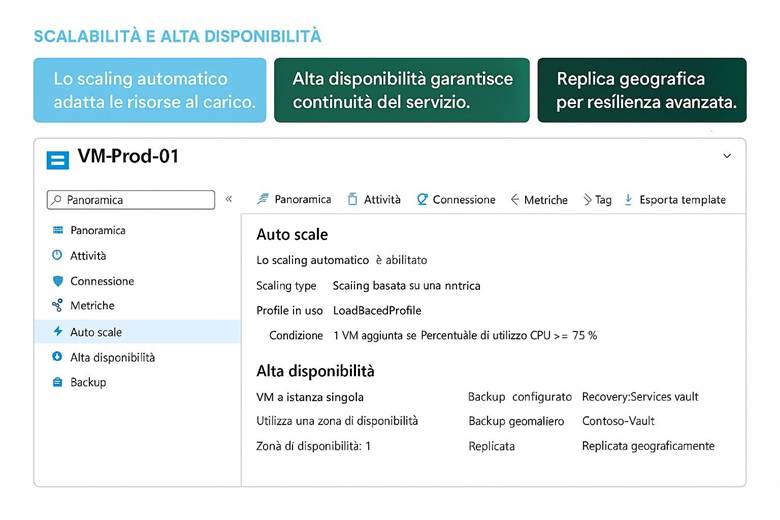
6. Scalabilità e alta disponibilità
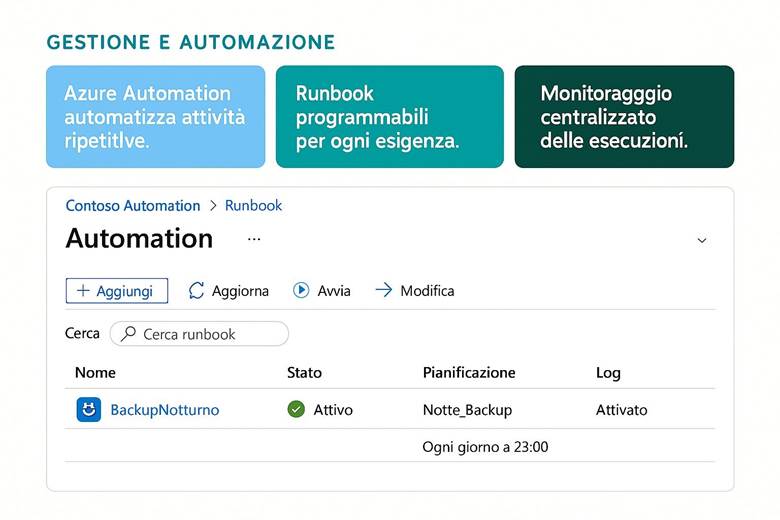
7. Gestione e automazione operativa
9. Casi d’uso e ottimizzazione dei costi
CAPITOLO 4 – Il servizio storage
Inquadramento argomenti del capitolo con slides illustrate
1. Servizi di archiviazione: Blob, File, Code e Tabelle
2. Account di archiviazione e configurazione di base
3. Opzioni di ridondanza dei dati
4. Sicurezza e controllo dell’accesso
5. Tier di archiviazione: Hot, Cool, Archive
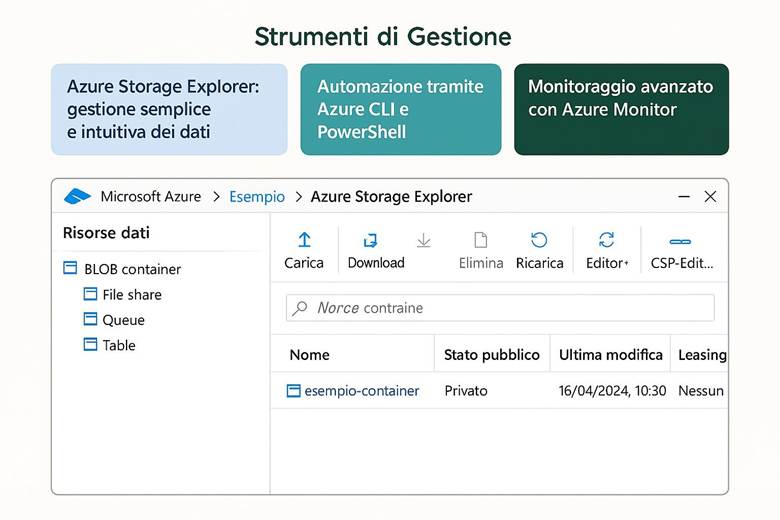
6. Strumenti per la gestione di Azure Storage
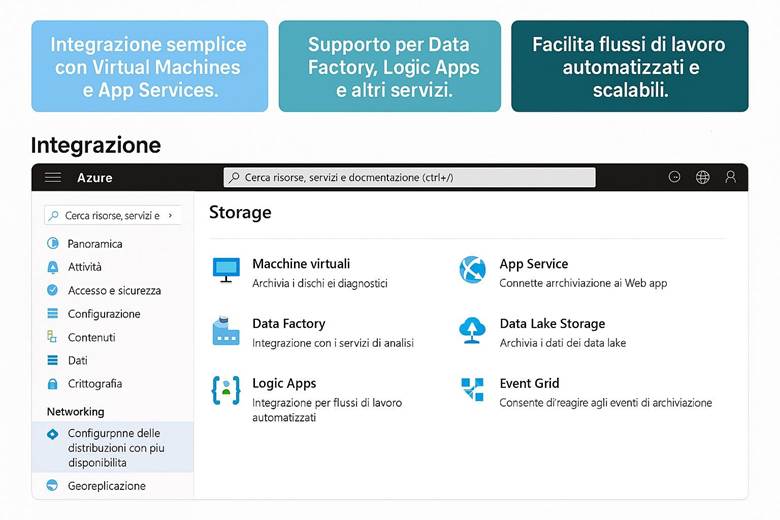
7. Integrazione con altri servizi Azure
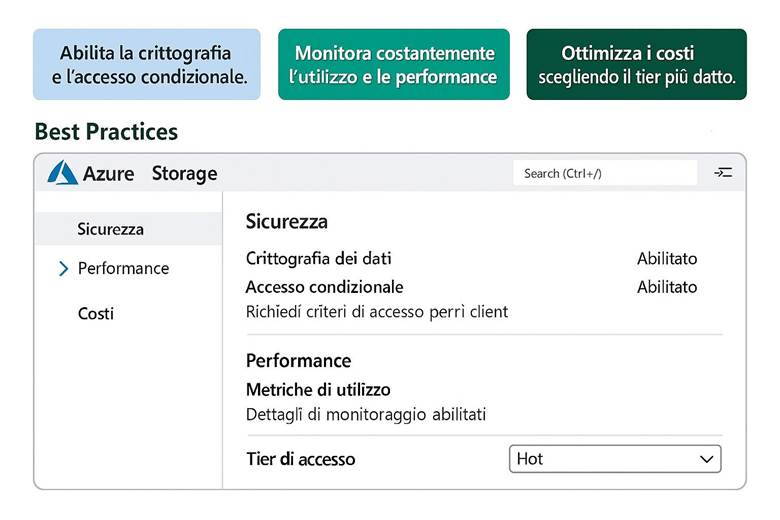
8. Best practice per l’utilizzo di Azure Storage
9. Casi d’uso e scenari pratici
CAPITOLO 5 – Il servizio networking
Inquadramento argomenti del capitolo con slides illustrate
1. Reti Virtuali (Azure Virtual Network - VNet)
2. Subnet (Segmentazione Logica della Rete)
3. Gruppi di Sicurezza di Rete (Network Security Groups - NSG)
4. Connettività Ibrida (VPN Gateway ed ExpressRoute)
5. Bilanciamento del Carico (Load Balancer, Application Gateway, Front Door)
6. Sicurezza Avanzata in Rete (Azure Firewall, Protezione DDoS, Defender for Cloud)
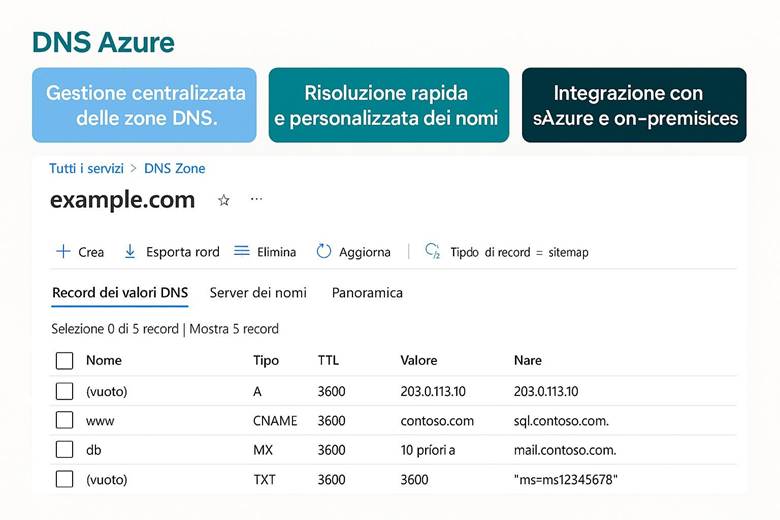
7. Gestione dei Nomi (Azure DNS)
8. Monitoraggio e Risoluzione dei Problemi (Network Watcher)
9. Best practice Architetturali per Azure Networking
10 . Tabella riassuntiva dei servizi di Azure Networking
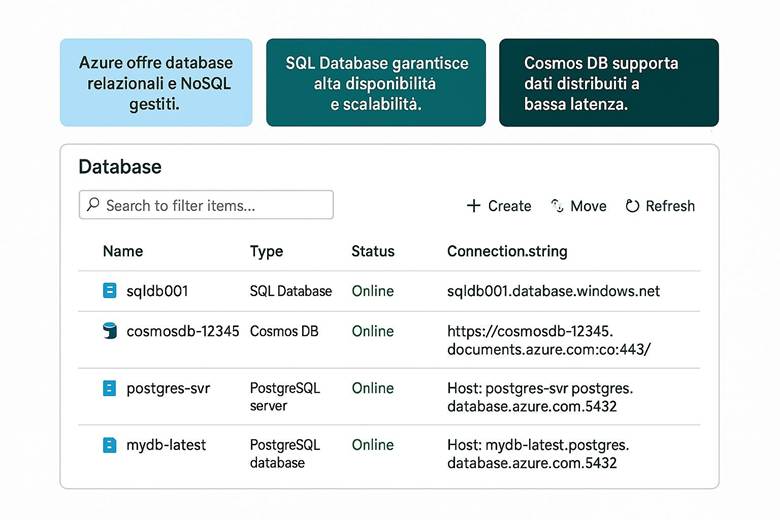
CAPITOLO 6 – Il servizio database
Inquadramento argomenti del capitolo con slides illustrate
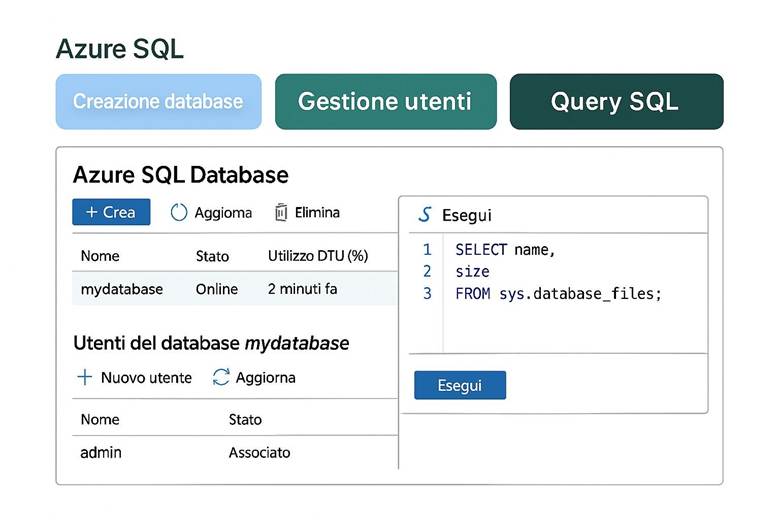
1. Tipi di Database – SQL Relazionali vs NoSQL
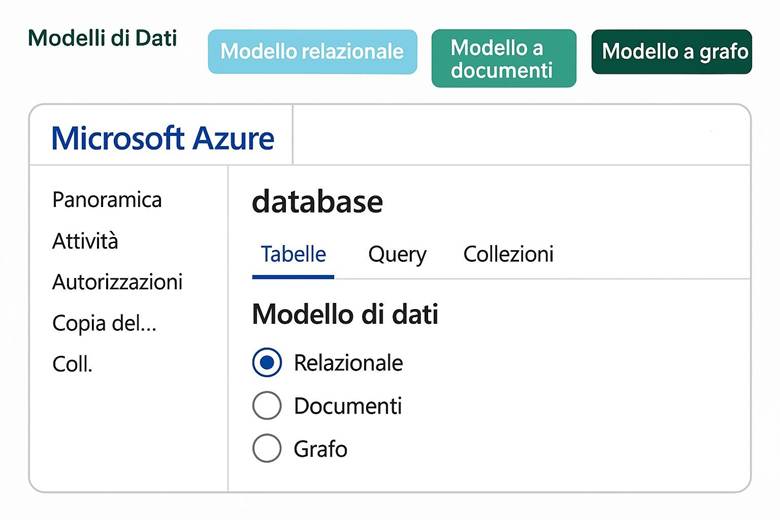
2. Modelli di Dati – Relazionale, Documenti e Grafo
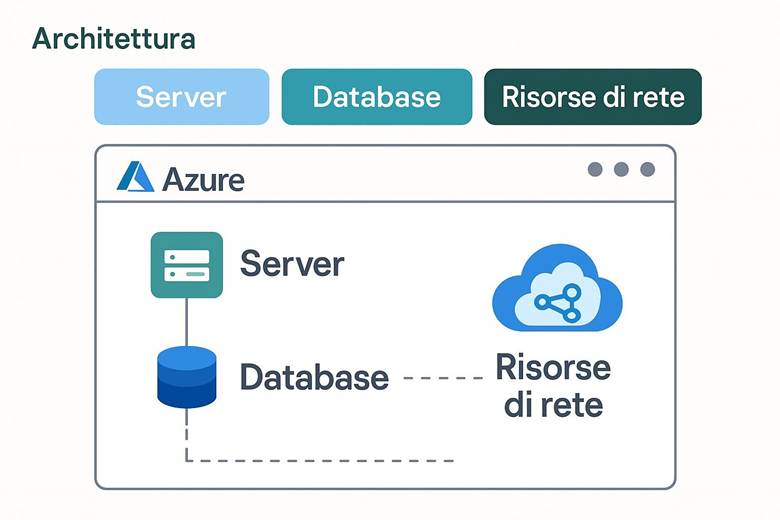
3. Architettura dei Servizi Database in Azure
4. Sicurezza nei Database in Azure
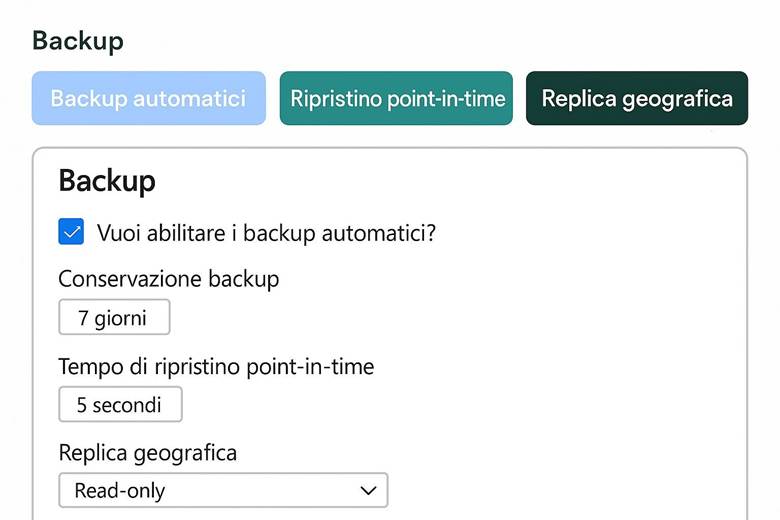
5. Backup e Ripristino (Disaster Recovery)
6. Scalabilità e Monitoraggio delle Prestazioni
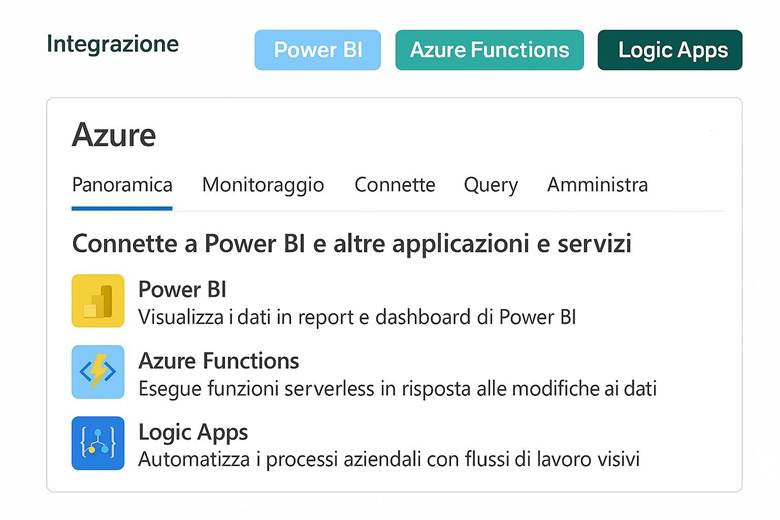
7. Integrazione con Altri Servizi Azure
8. Casi d’Uso – Scenari Applicativi
CAPITOLO 7 – Il servizio di intelligenza artificiale e di machine learning
Inquadramento argomenti del capitolo con slides illustrate
1. Concetti di IA e Machine Learning
2. Tipi di Apprendimento Automatico
3. Architettura del Ciclo di Vita del ML
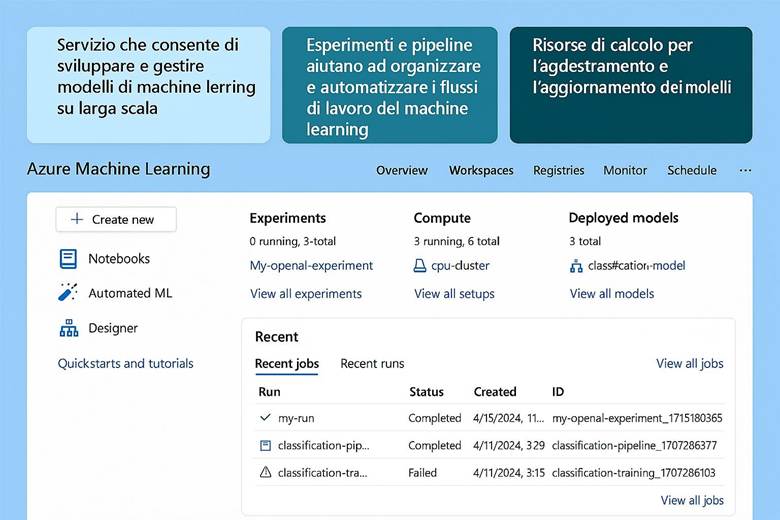
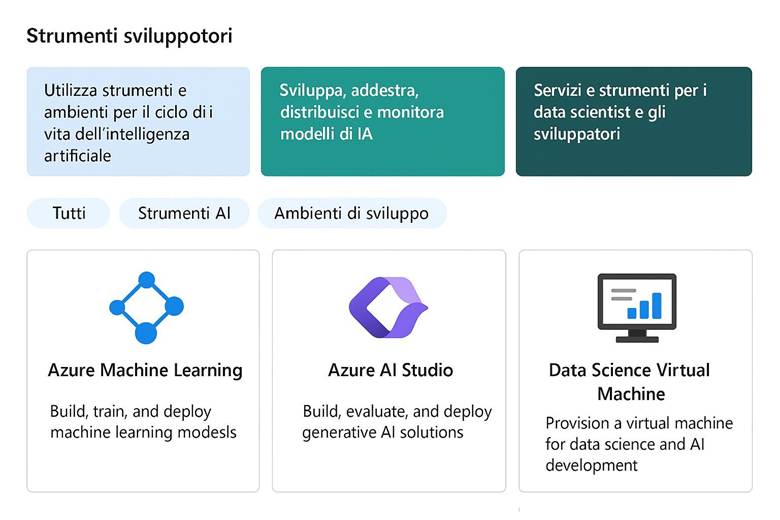
4. Azure Machine Learning: Piattaforma per il Ciclo ML
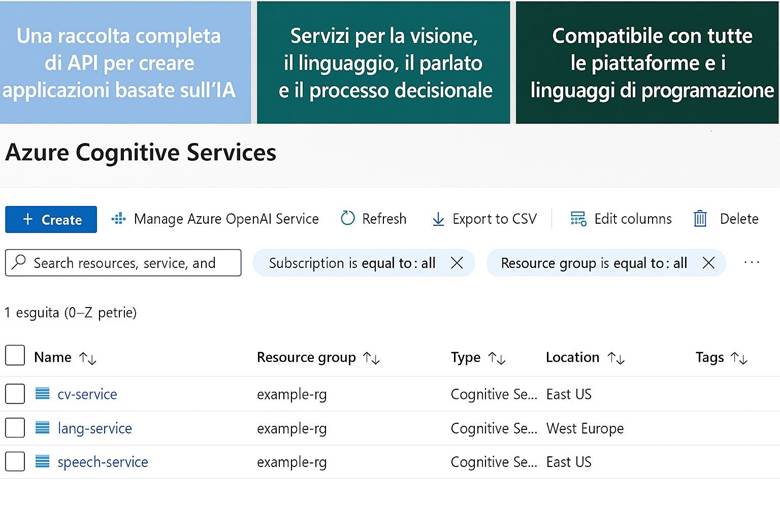
5. Servizi Cognitivi di Azure (Azure AI Services)
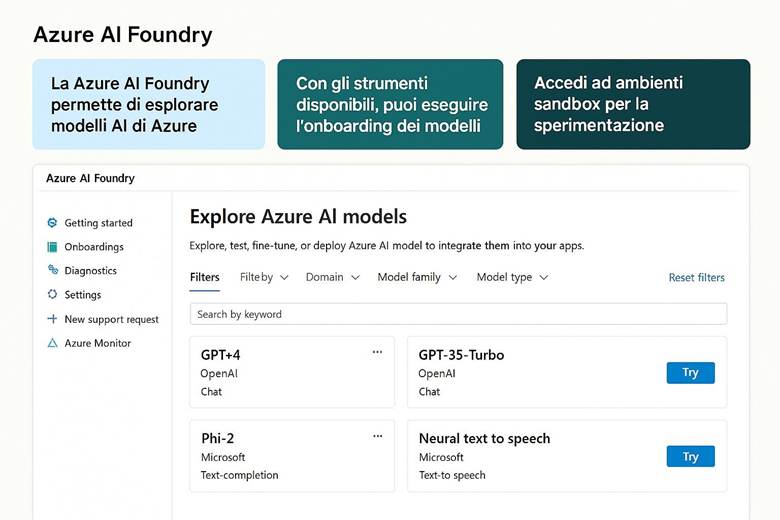
6. Azure OpenAI e Microsoft Foundry: Soluzioni di Generative AI
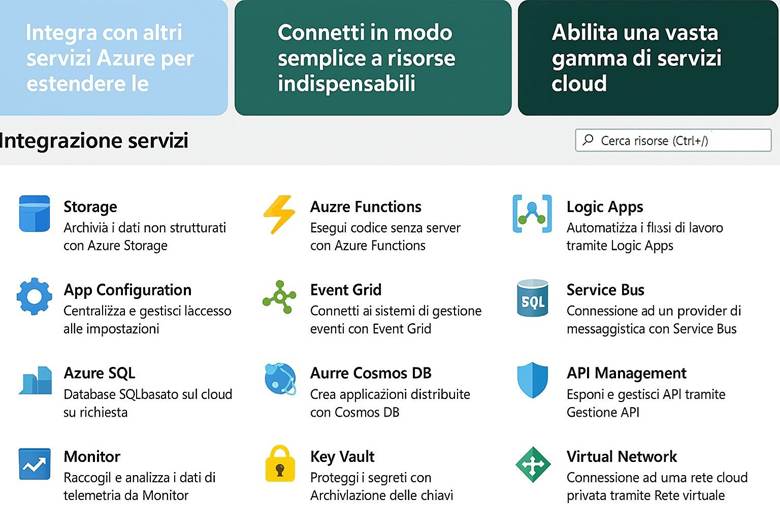
7. Integrazione delle Soluzioni AI con i Servizi Azure
8. Intelligenza Artificiale Responsabile (Responsible AI)
9. Strumenti e Ambienti per Sviluppatori
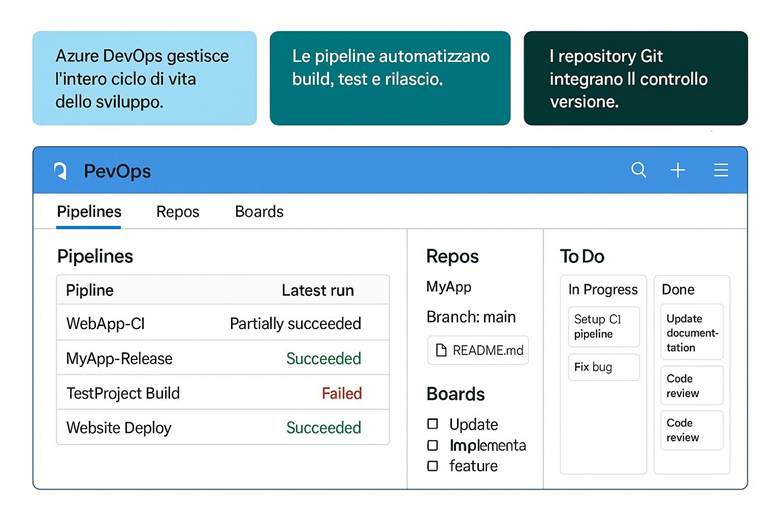
CAPITOLO 8 – Il servizio DevOps
Inquadramento argomenti del capitolo con slides illustrate
1. Azure Repos: Controllo di Versione e Collaborazione
2. Azure Pipelines: Continuous Integration e Delivery Automatizzata
3. Strategie di Rilascio, Approvazioni e Controlli di Qualità
4. Azure Artifacts: Gestione di Pacchetti e Dipendenze
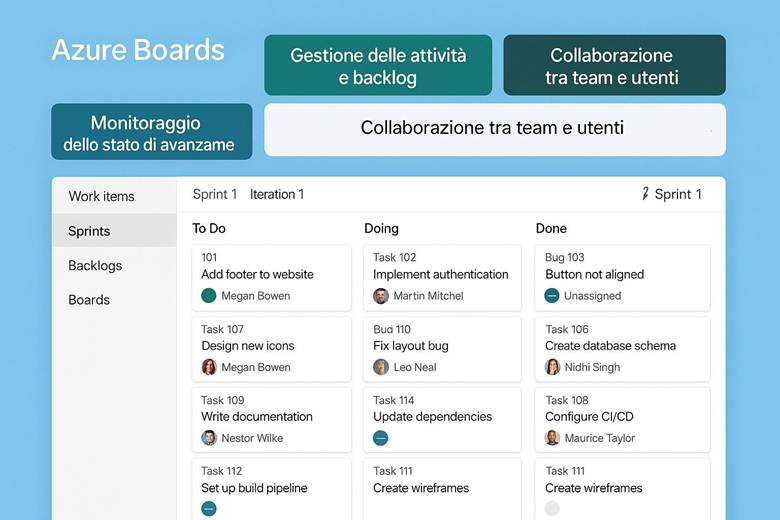
5. Azure Boards: Gestione del Lavoro e Collaborazione Agile
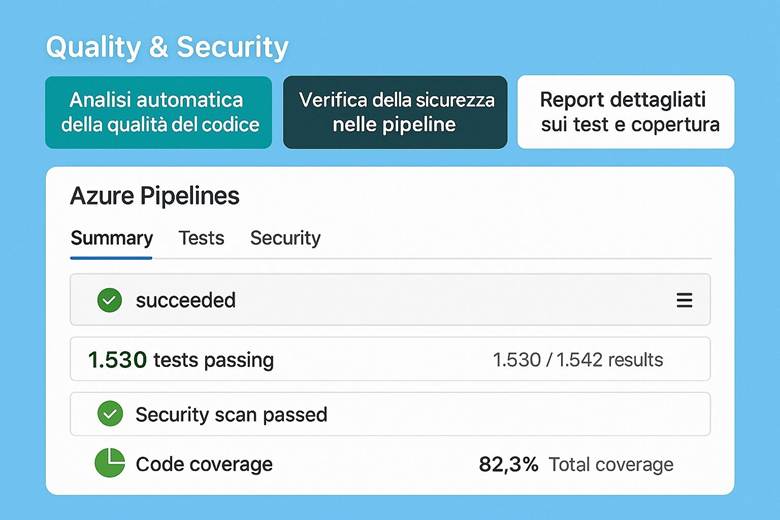
6. Qualità del Codice e Sicurezza nelle Pipeline
7. Infrastructure as Code (IaC) e Configuration as Code (CaC)
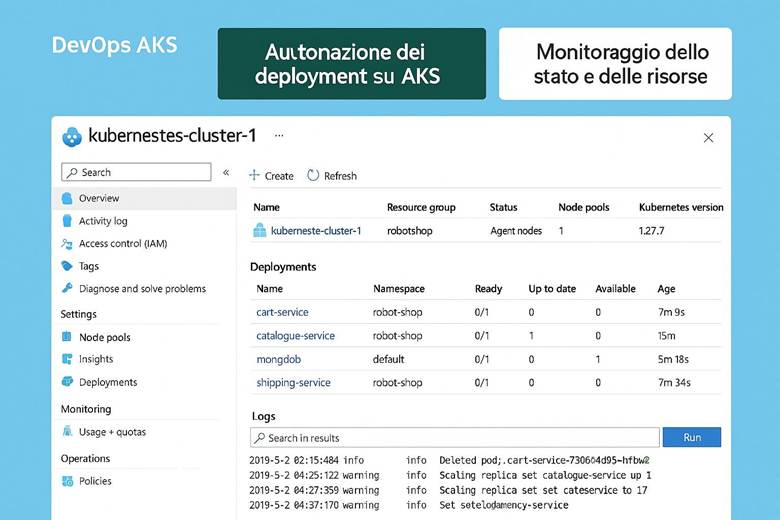
8. DevOps su Azure Kubernetes Service (AKS): Deployment e Osservabilità
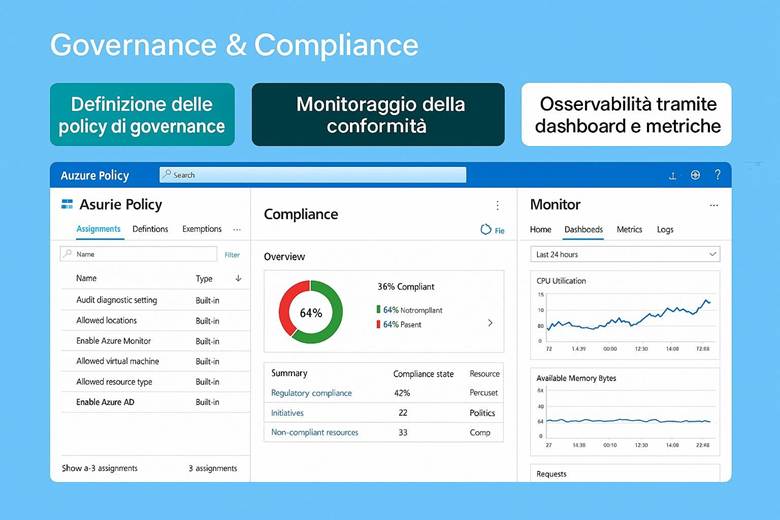
9. Governance e Compliance con Azure DevOps e Azure
10. Organizzazione dell’Account, Permessi e Scalabilità dei Progetti
11. Tabella Riepilogativa dei Servizi DevOps Principali
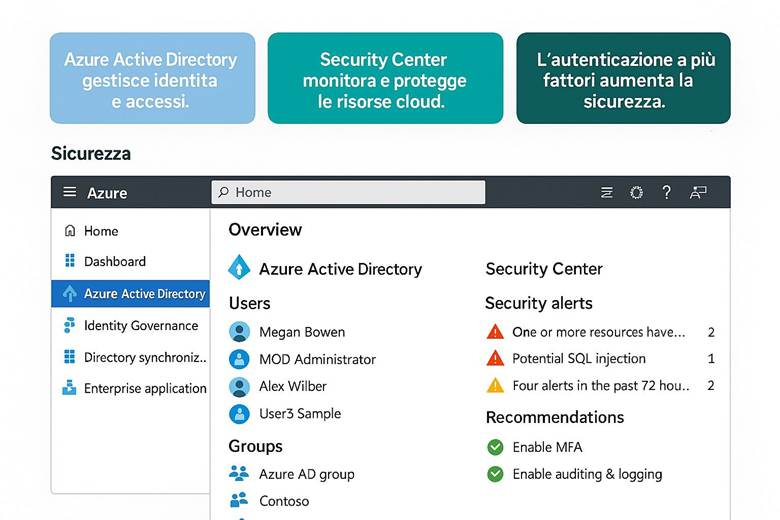
CAPITOLO 9 – Il servizio di sicurezza
Inquadramento argomenti del capitolo con slides illustrate
1. Panoramica e Principi Operativi della Sicurezza in Azure
3. Gestione delle Identità e degli Accessi
4. Crittografia dei Dati e Gestione delle Chiavi
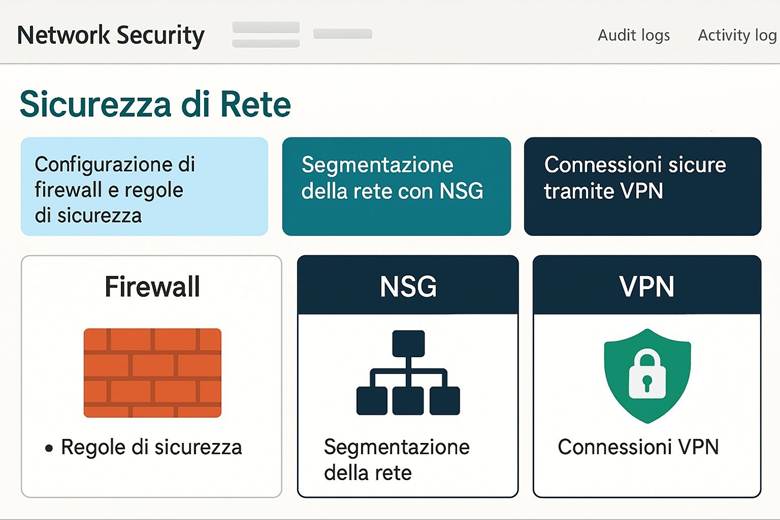
5. Sicurezza di Rete (Firewall, NSG e VPN)
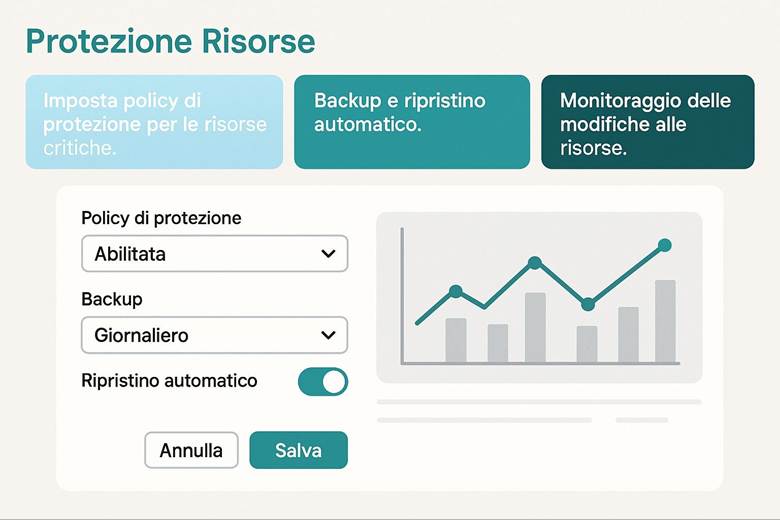
6. Protezione delle Risorse e Backup
7. Monitoraggio e Risposta agli Incidenti
8. Sicurezza delle Applicazioni
9. Conformità e Automazione della Sicurezza
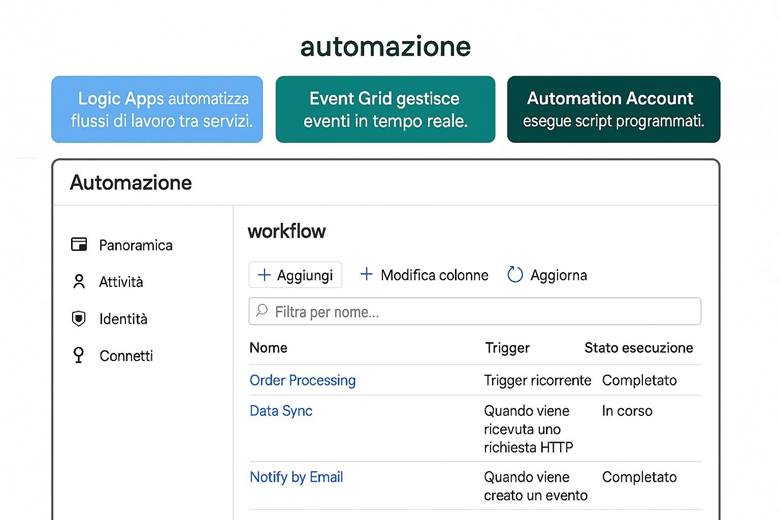
CAPITOLO 10 – Il servizio di automazione
Inquadramento argomenti del capitolo con slides illustrate
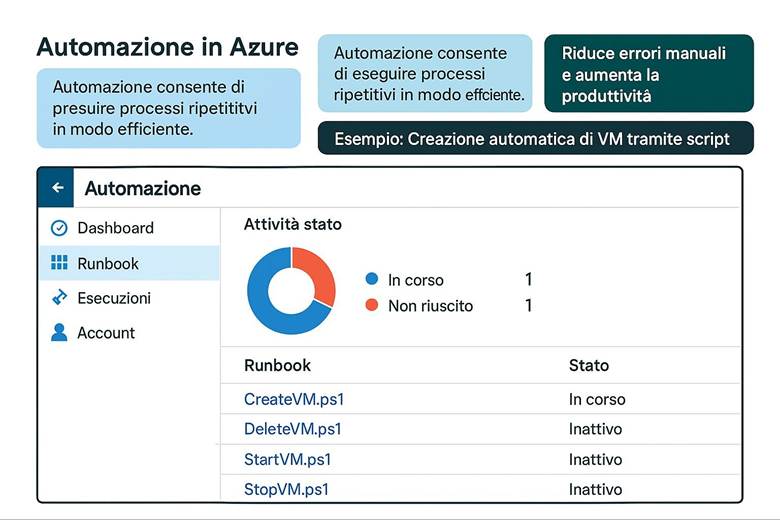
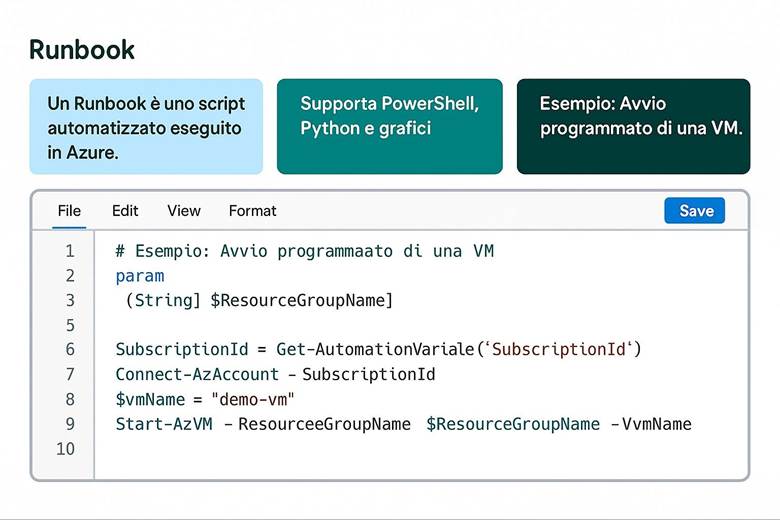
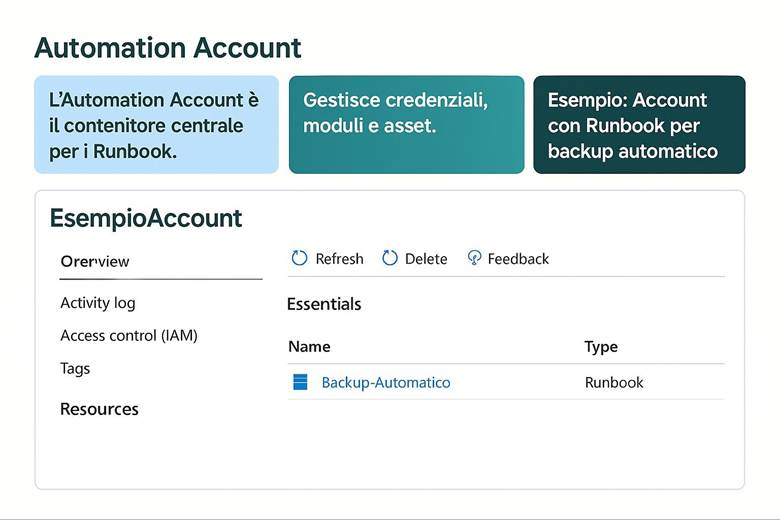
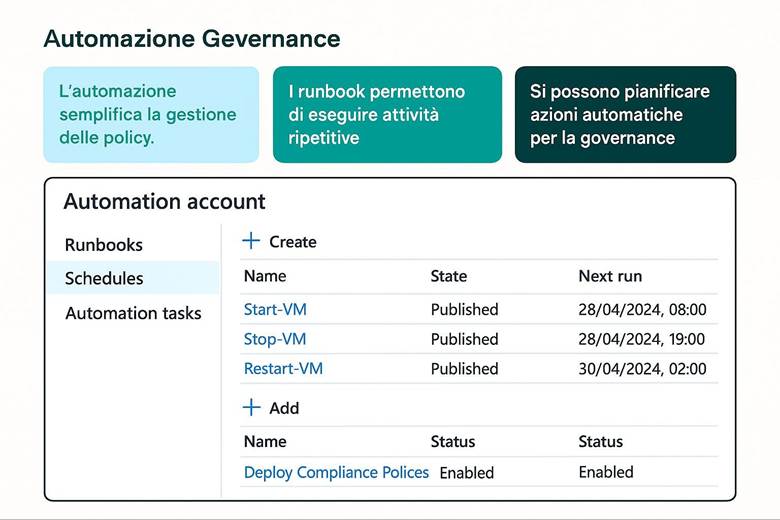
1. Runbook e Automazione delle Attività
2. Automation Account: Il Contenitore Centrale
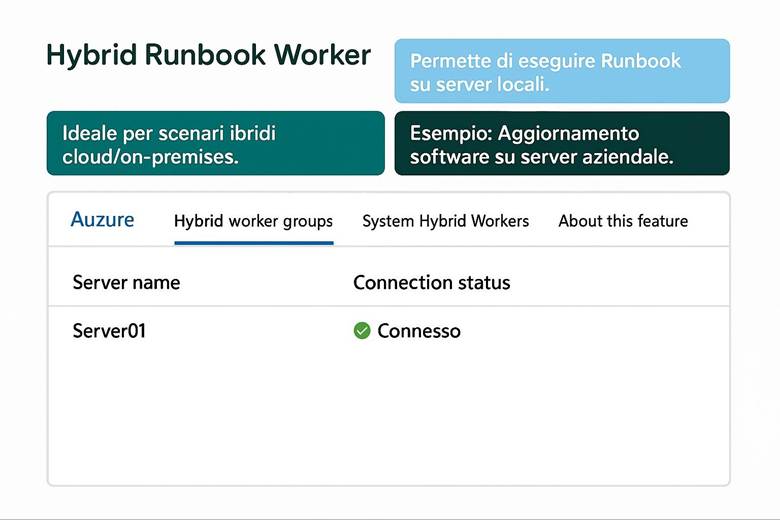
3. Hybrid Runbook Worker: Automazione Ibrida
4. Update Management: Gestione degli Aggiornamenti delle VM
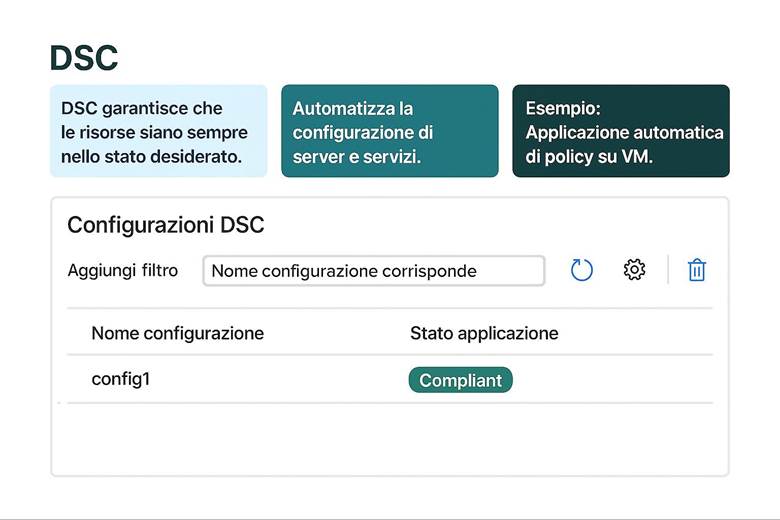
5. Configurazione dello Stato: Azure Automation State Configuration (DSC)
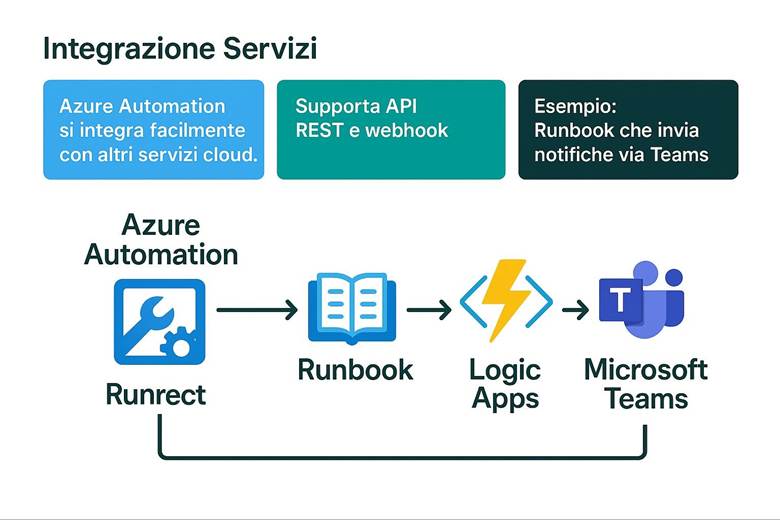
6. Integrazione Runbook con altri Servizi
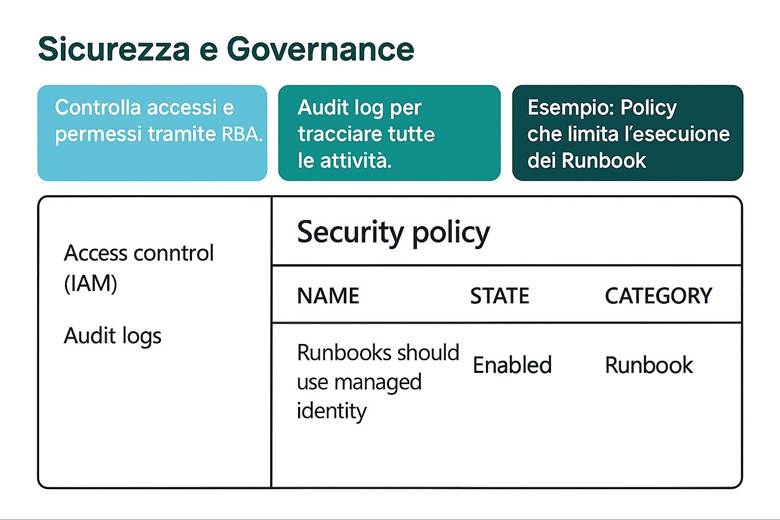
7. Baseline di Sicurezza e Governance per l’Automazione
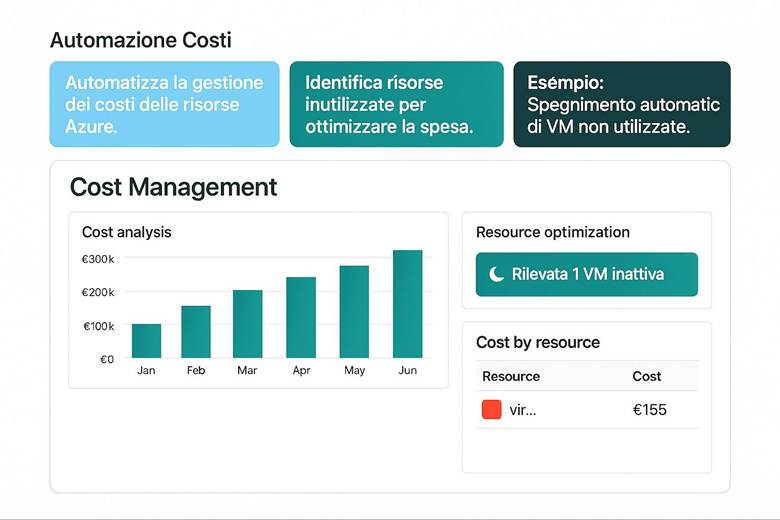
8. Ottimizzazione dei Costi con l’Automazione
9. Migliori Pratiche per Azure Automation e Considerazioni Finali
CAPITOLO 11 – Il servizio di analisi
Inquadramento argomenti del capitolo con slides illustrate
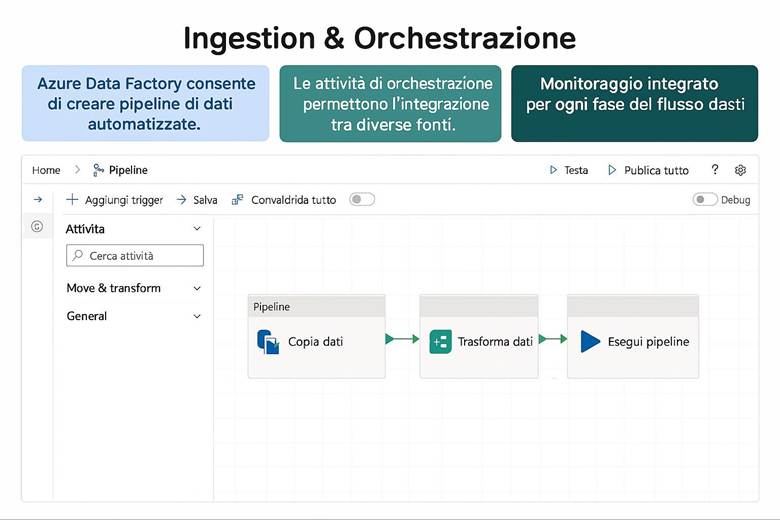
1. Azure Data Factory: Orchestrazione di Pipeline di Dati
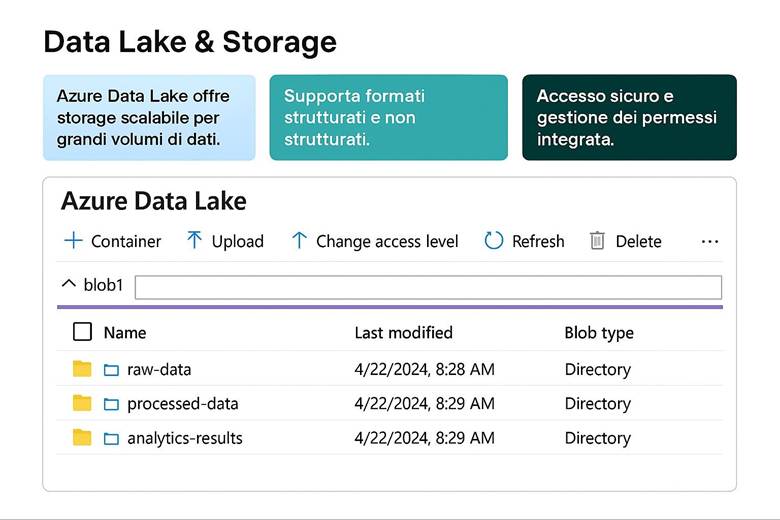
2. Azure Data Lake Storage Gen2: Fondamenti e Best Practice
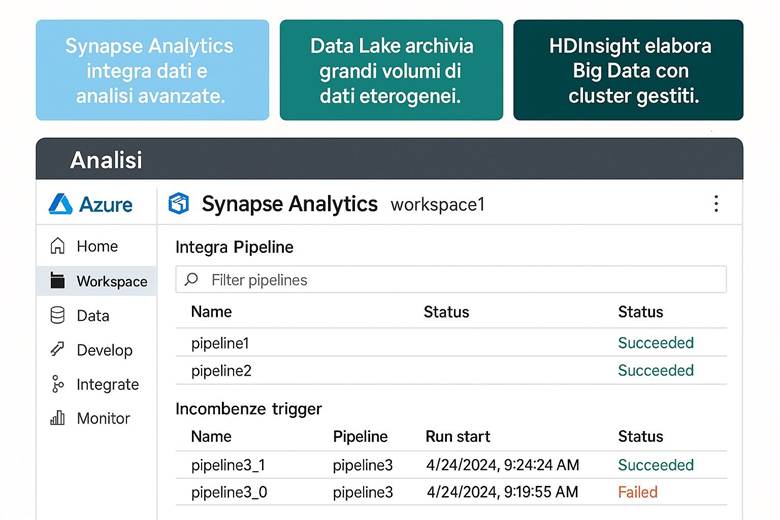
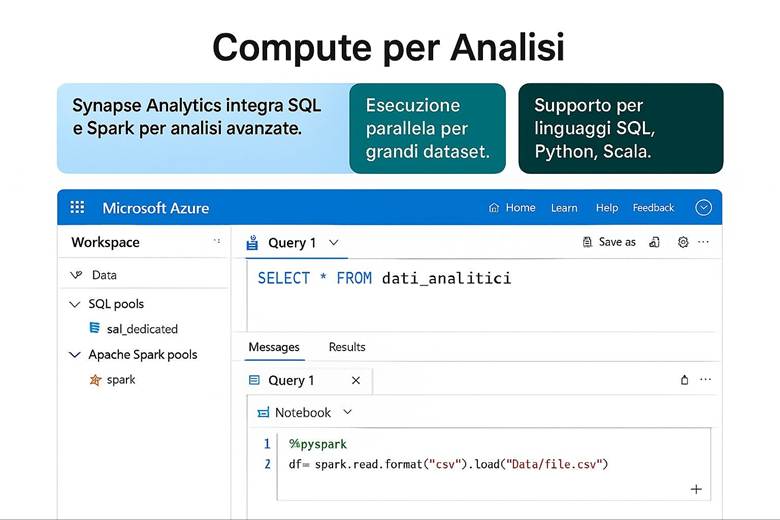
3. Azure Synapse Analytics: Integrazione di SQL e Spark
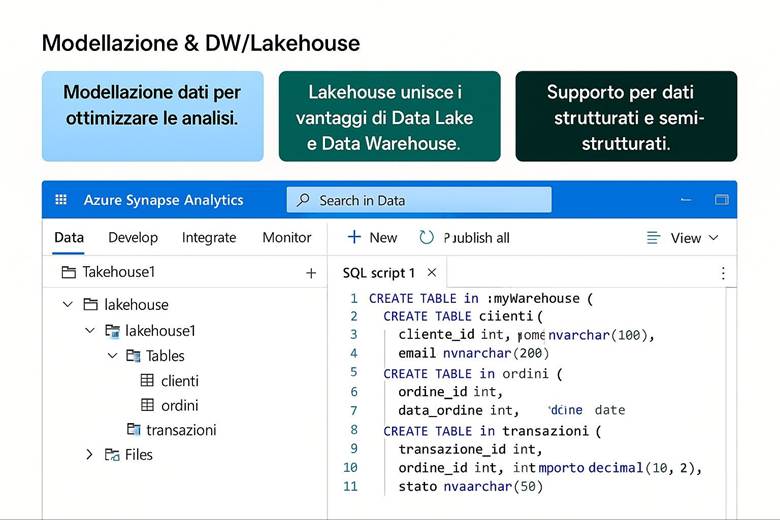
4. Lakehouse e Medallion Architecture: Unire Data Lake e Data Warehouse
5. Azure Stream Analytics: Elaborazione Dati in Tempo Reale
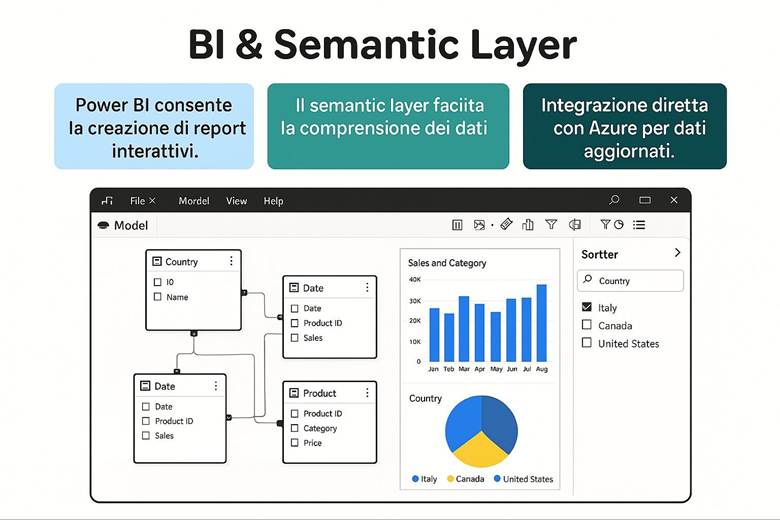
6. Power BI: Modelli Semantici per l’Analisi Self-Service
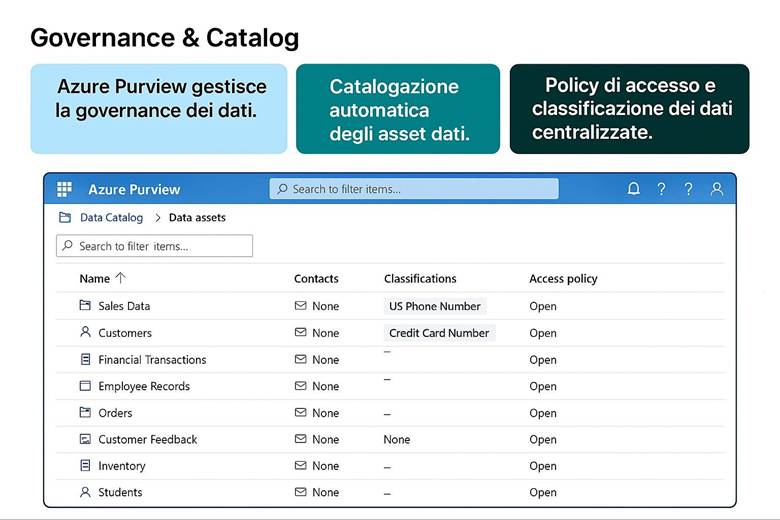
7. Microsoft Purview: Catalogo Dati e Data Governance
8. Mapping Data Flows: Trasformazioni Visive Scalabili
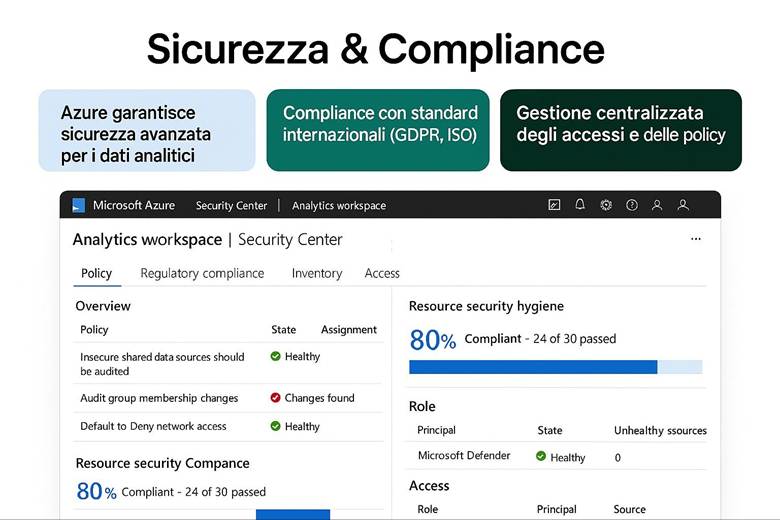
9. Sicurezza dei Dati Analitici in Azure
10. Monitoraggio e Gestione dei Costi in Azure
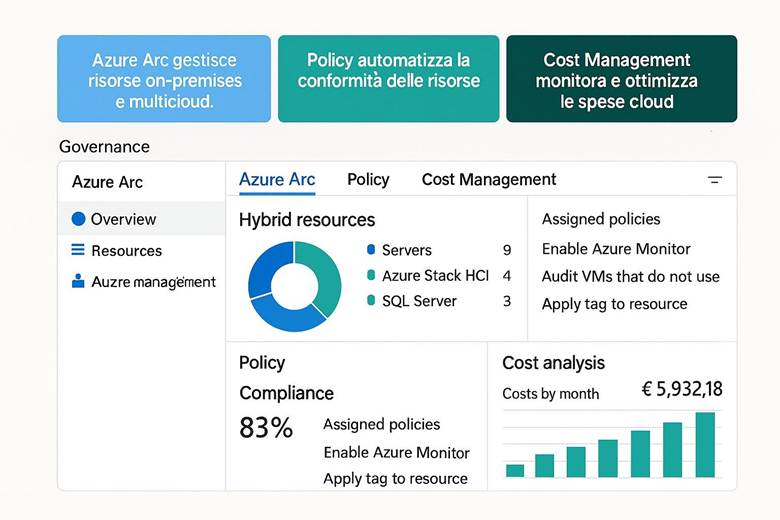
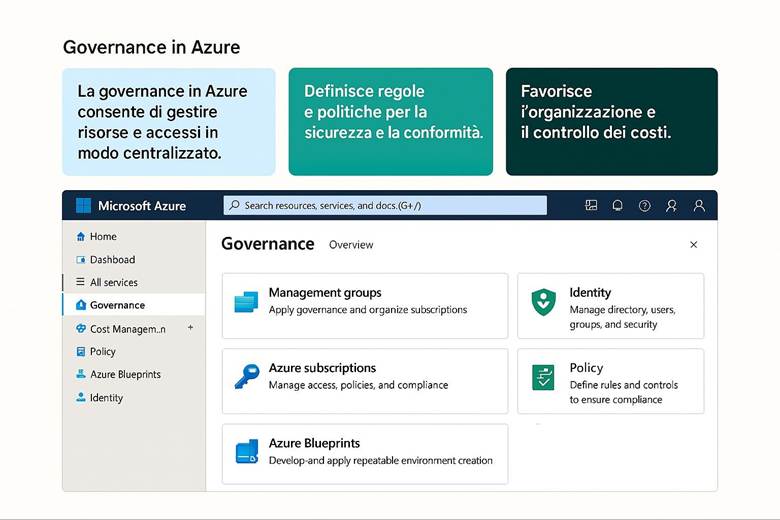
CAPITOLO 12 – Il servizio governance
Inquadramento argomenti del capitolo con slides illustrate
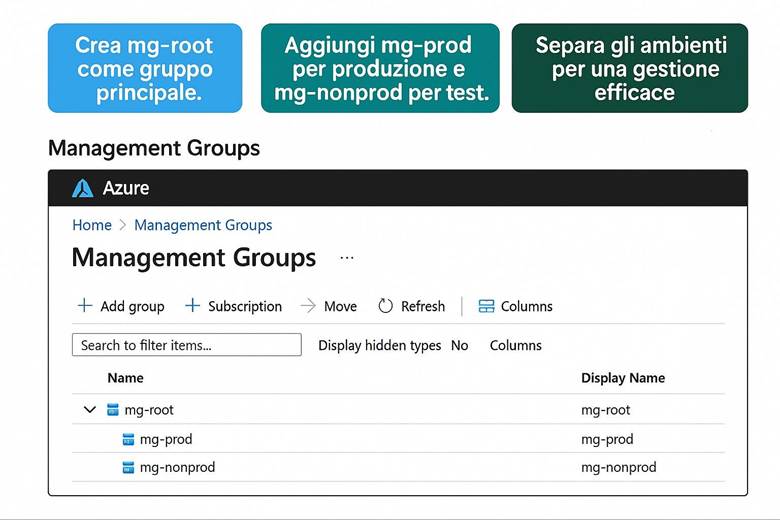
1. Gruppi di gestione (Management Groups)
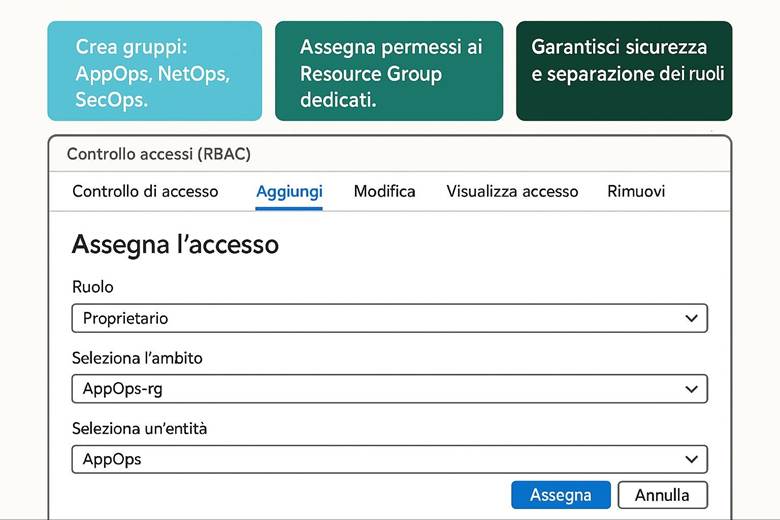
3. Controllo degli accessi (RBAC)
4. Gestione dei costi e budget
7. Monitoraggio, audit e alert
8. Automazione della governance
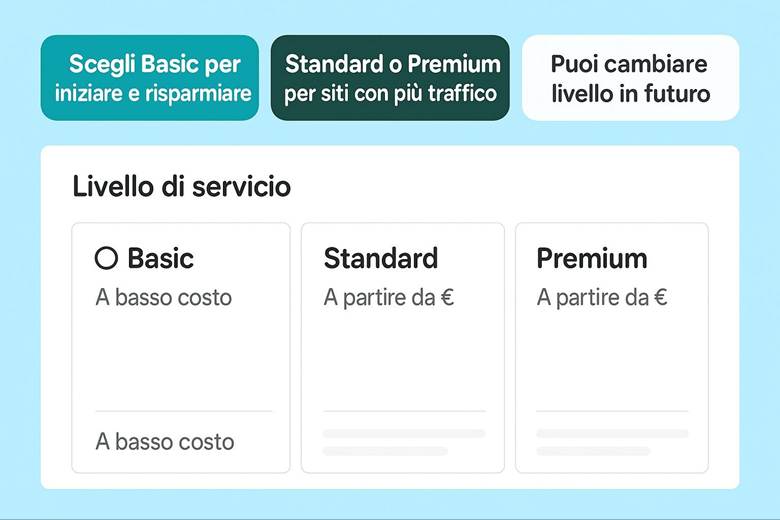
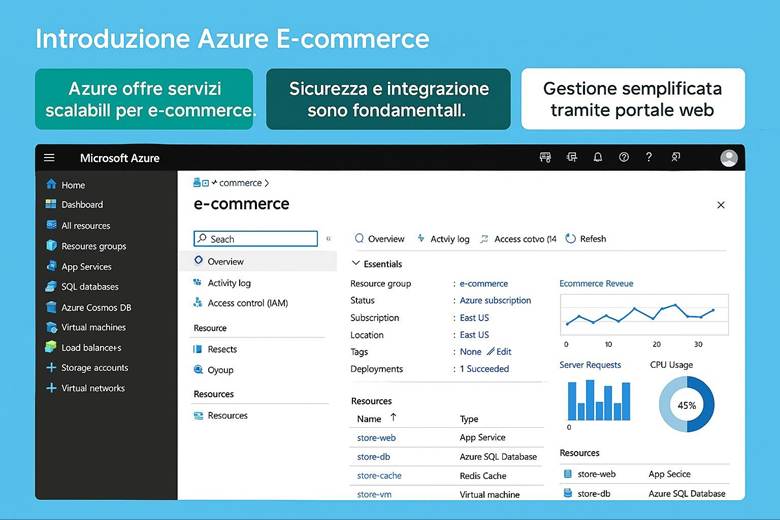
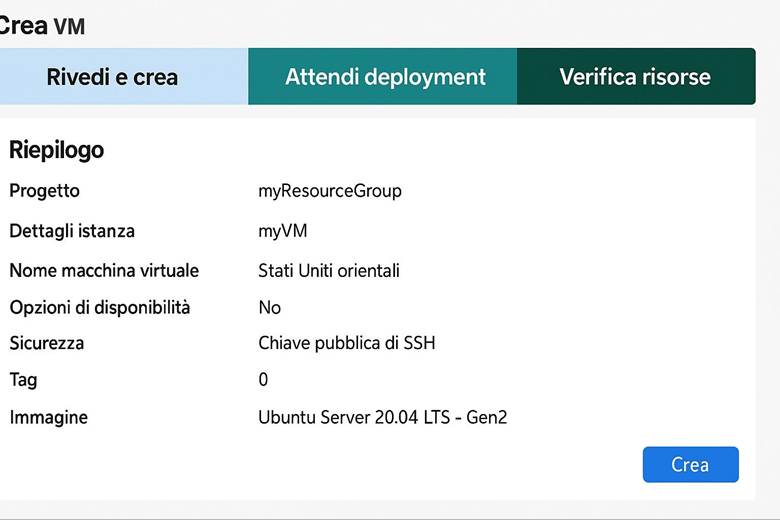
PROGETTO FINALE – Realizzazione di un e-commerce
1. Prepariamo della scatola dove mettere le cose (Governance)
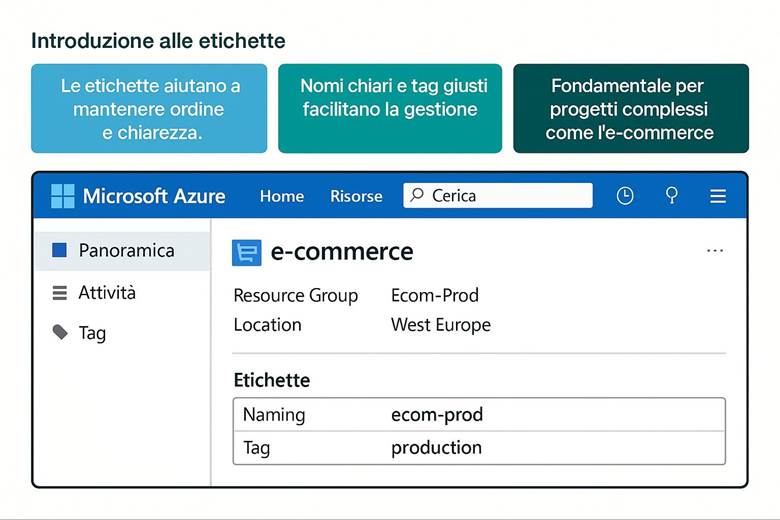
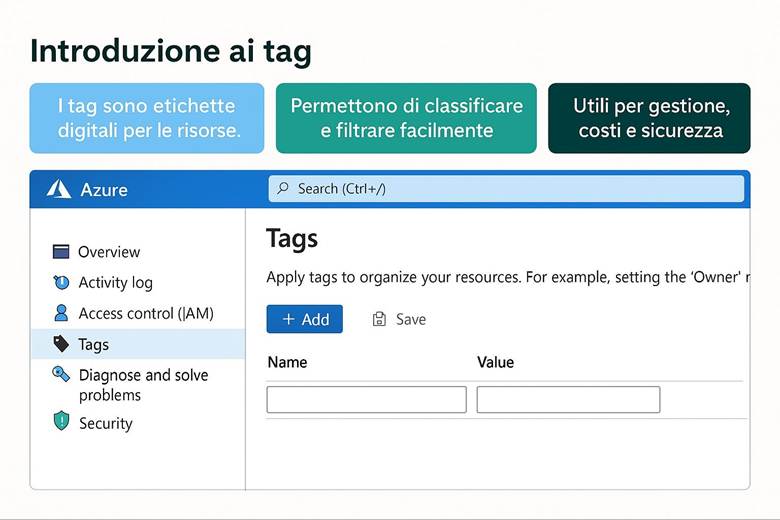
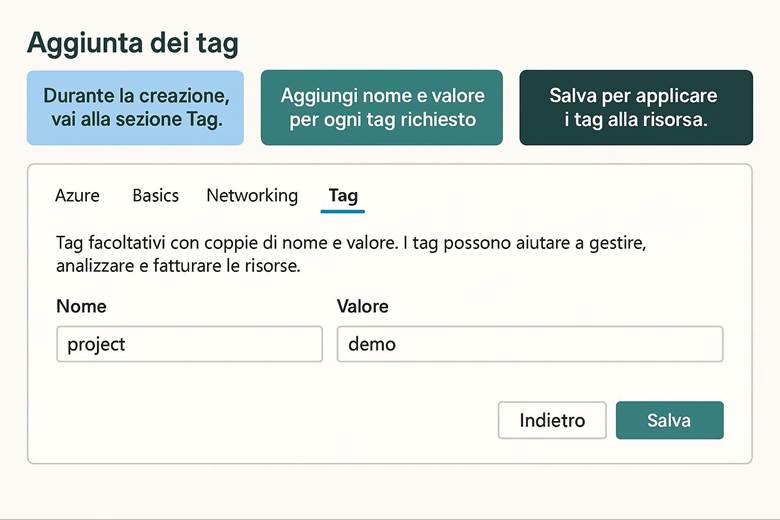
2. Attribuiamo le etichette agli oggetti per riconoscerli (Naming e Tag)
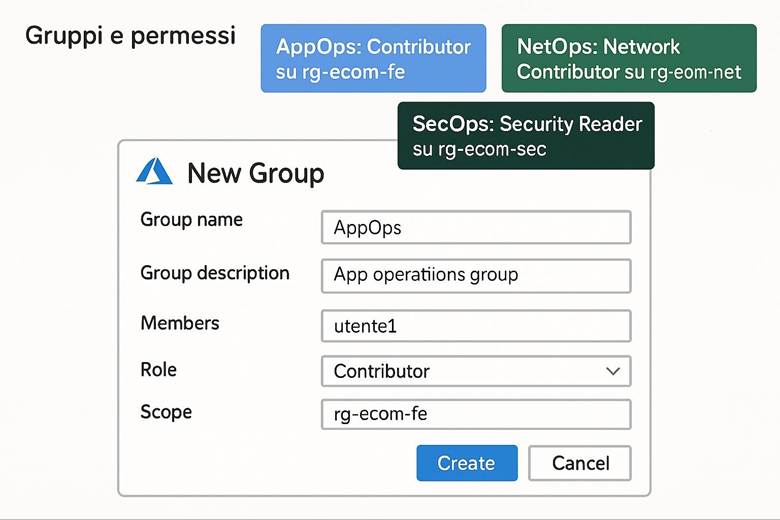
3. Chi può entrare? (Sicurezza e Utenti)
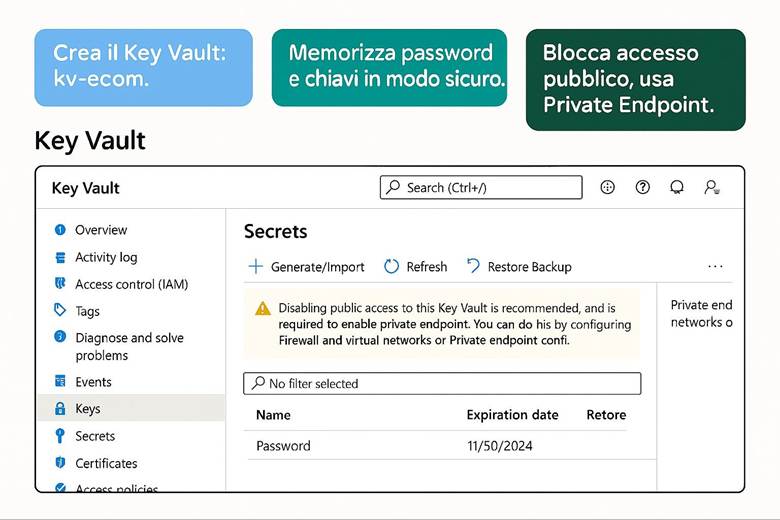
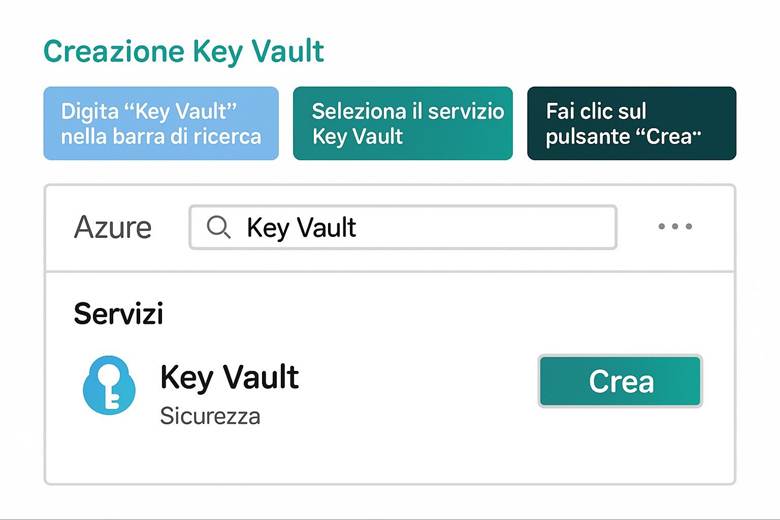
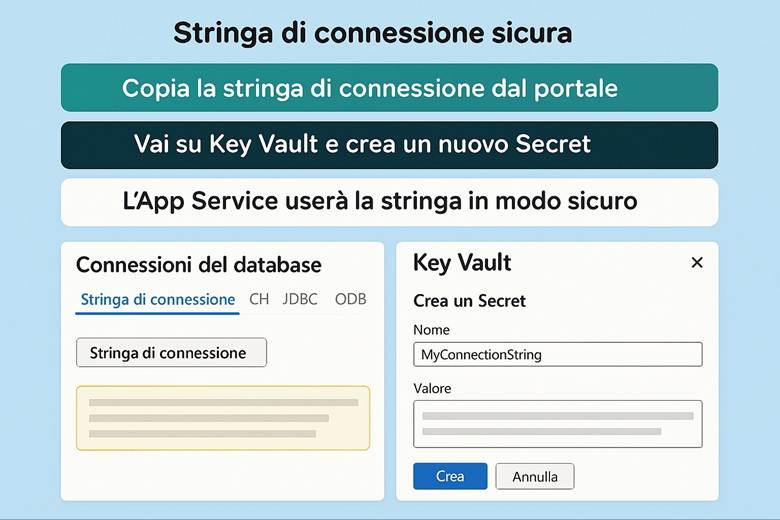
4. Costruiamo una cassaforte per custodire le chiavi (Key Vault)
5. Costruiamo un sistema di difesa (Defender for Cloud)
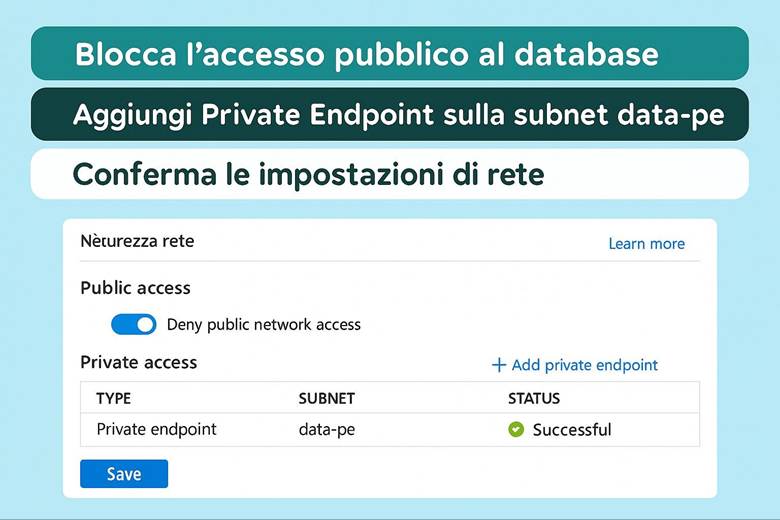
6. Costruiamo le strade che collegano le risorse (Rete)
7. Costruiamo il magazzino per i nostri oggetti (Storage)
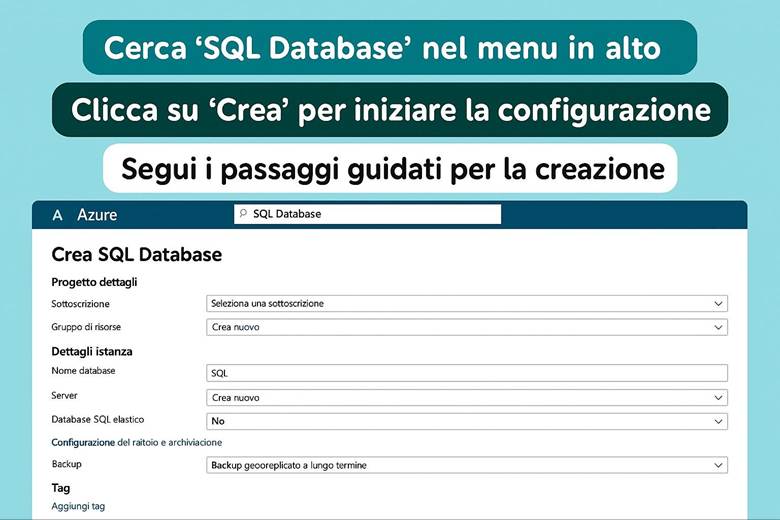
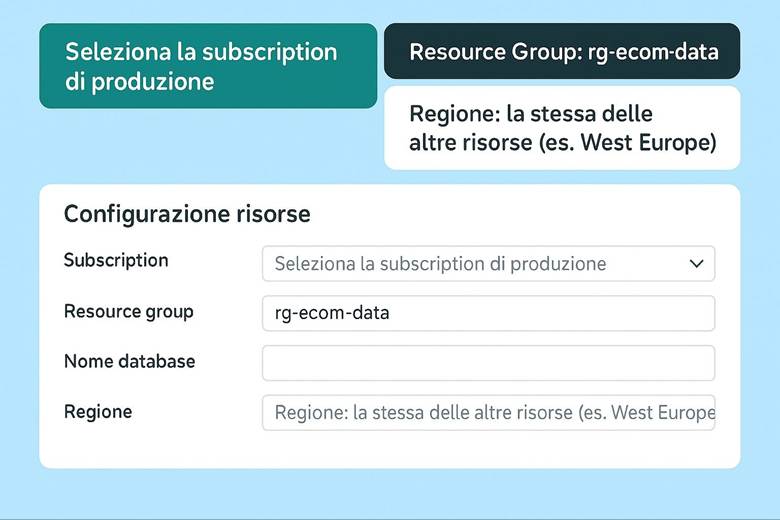
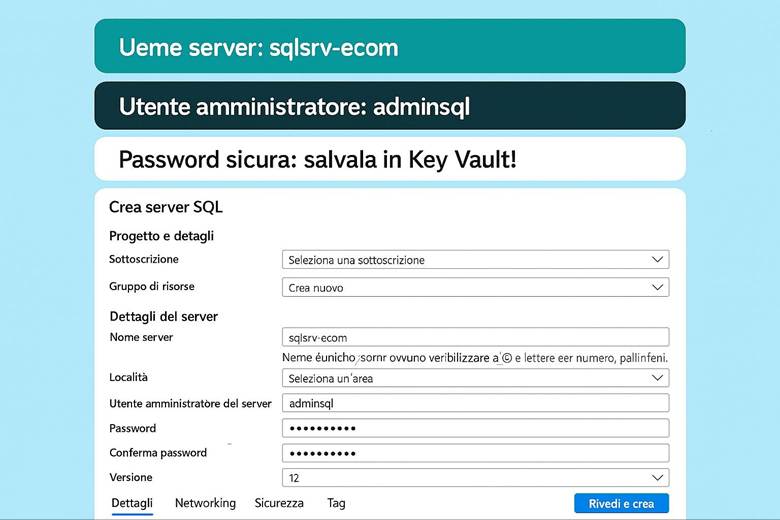
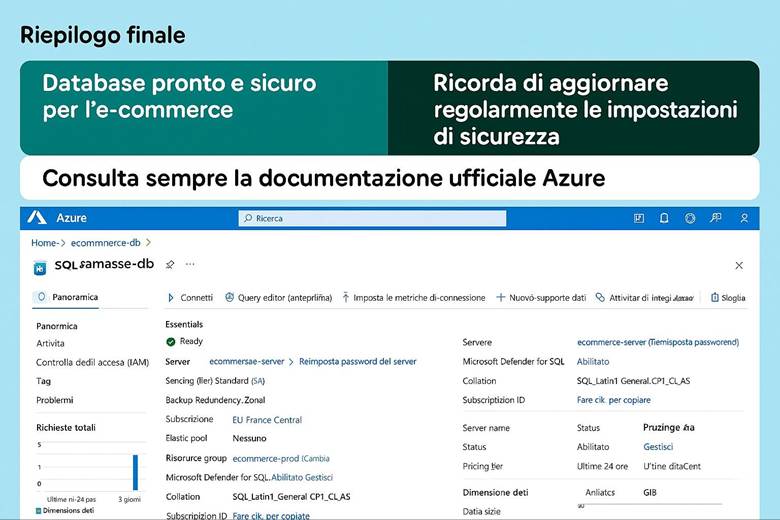
8. Costruiamo il database per prodotti, ordini e clienti (SQL)
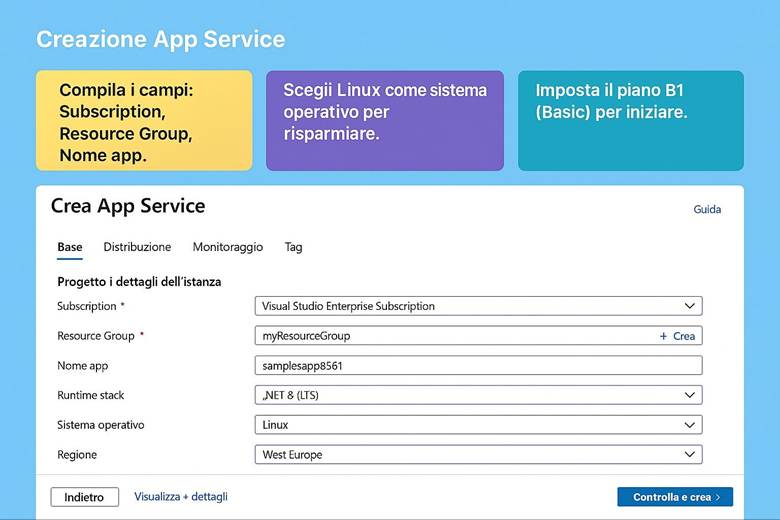
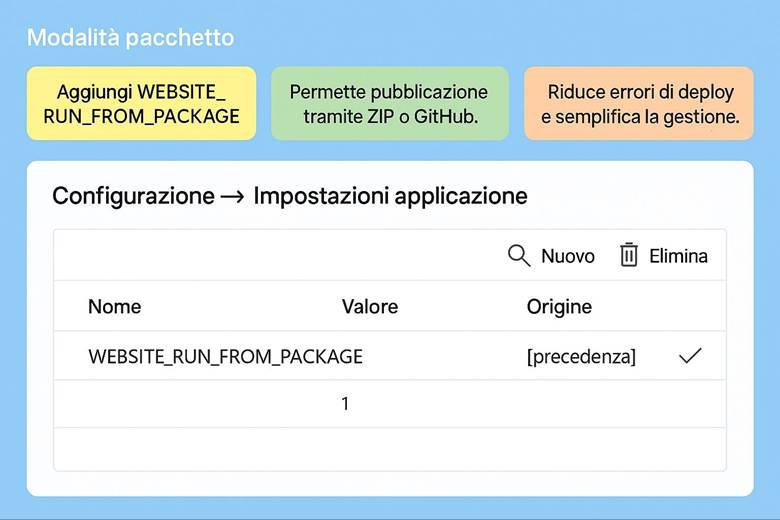
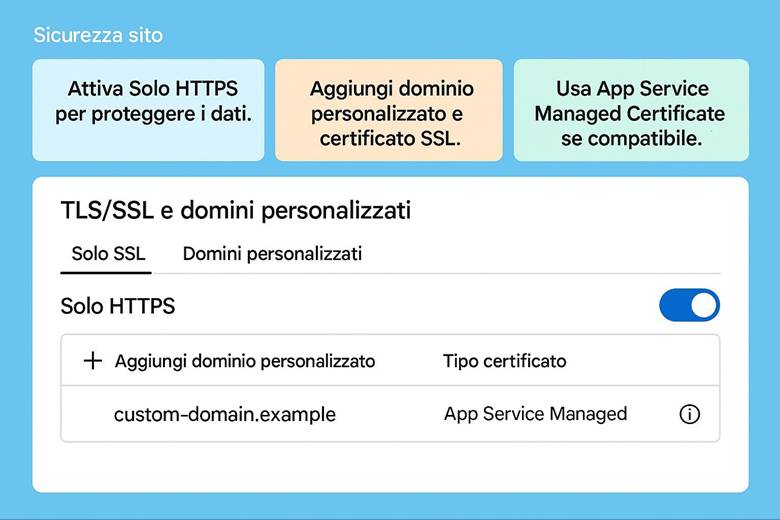
9. Costruiamo il sito: l’interfaccia utente dell’e-commerce (App Service)
10. Aggiungiamo un computer virtuale per le nostre operazioni (VM)
11. Teniamo tutto sotto controllo (Monitor)
12. Teniamo sotto controllo i costi (Cost Management)
1. Cosa si impara e quali posizioni si possono ricoprire a lavoro
2. Profilo LinkedIn – Specialista in Governance Cloud su Microsoft Azure
3. Curriculum vitae basato su queste competenze
Prefazione dell’autore
Viviamo in un’epoca in cui il cloud computing è diventato il motore dell’innovazione digitale. Tra le piattaforme più diffuse e potenti, Microsoft Azure si distingue per la sua flessibilità, scalabilità e capacità di supportare aziende di ogni dimensione nella trasformazione digitale. Ma utilizzare il cloud in modo efficace non significa solo “spostare” le risorse online: significa anche saperle governare.
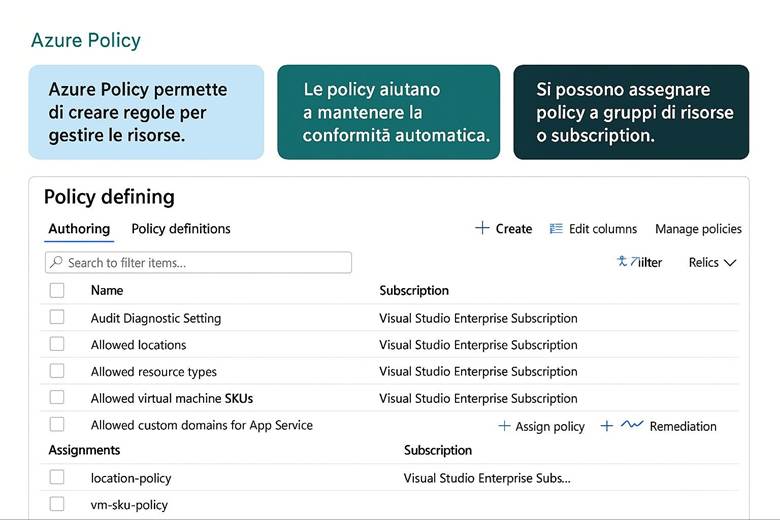
Questo ebook nasce con l’obiettivo di guidarti alla scoperta della governance in Azure, un insieme di strumenti e pratiche che permettono di mantenere il controllo su risorse, costi, sicurezza e conformità. Imparerai come strutturare un ambiente Azure ordinato e sicuro, come applicare regole aziendali attraverso le Azure Policy, come gestire gli accessi con RBAC, come monitorare i costi e come garantire che ogni risorsa sia conforme agli standard richiesti.
Per le aziende, una buona governance in Azure significa ridurre i rischi, migliorare la sicurezza, ottimizzare i costi e garantire che ogni team lavori in autonomia ma nel rispetto delle regole comuni. Per te, lettore, significa acquisire competenze sempre più richieste nel mondo del lavoro, in un settore in continua crescita.
Questo ebook è pensato per studenti, professionisti junior o chiunque voglia avvicinarsi al mondo del cloud con un approccio pratico e strutturato. Ogni capitolo affronta un tema chiave con un linguaggio chiaro, esempi concreti e suggerimenti operativi.
Ti invito ad affrontare la lettura con curiosità e spirito pratico. Non è necessario essere esperti di Azure per iniziare: l’importante è avere voglia di imparare e di comprendere come il cloud può essere gestito in modo intelligente. Alla fine del percorso, avrai una visione completa della governance in Azure e sarai pronto a metterla in pratica nei tuoi progetti o a presentarti con maggiore sicurezza nel mondo del lavoro.
PROGETTO FINALE – Realizzazione di un e-commerce. Breve illustrazione
Non c’è cosa migliore di iniziare a studiare un argomento come questo avendo in mente di poterci realizzare qualcosa che ci piace e che ci può essere utile sul lavoro o per trovare lavoro. Questo ebook su Microsoft Azure è stato pensato proprio con questa filosofia: imparare gli strumenti e i servizi per poi metterli in pratica in un progetto concreto.
Nell’ultimo capitolo troverai il progetto finale, che consiste nella realizzazione di un e-commerce sfruttando tutto ciò che hai appreso. Non si tratta di teoria astratta, ma di passaggi operativi chiari, corredati da immagini esplicative per guidarti passo passo.
Gli step fondamentali che affronterai sono:
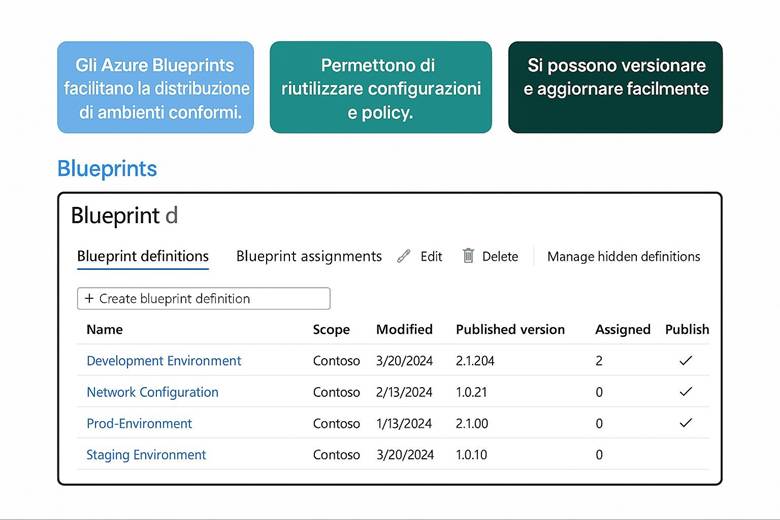
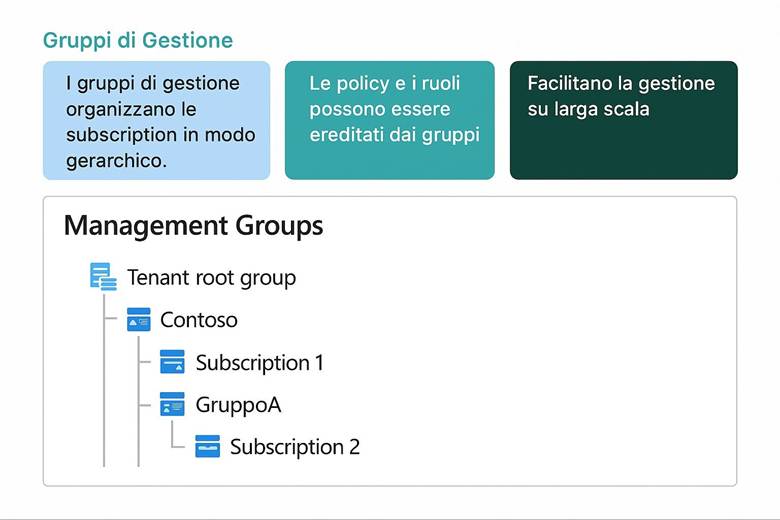
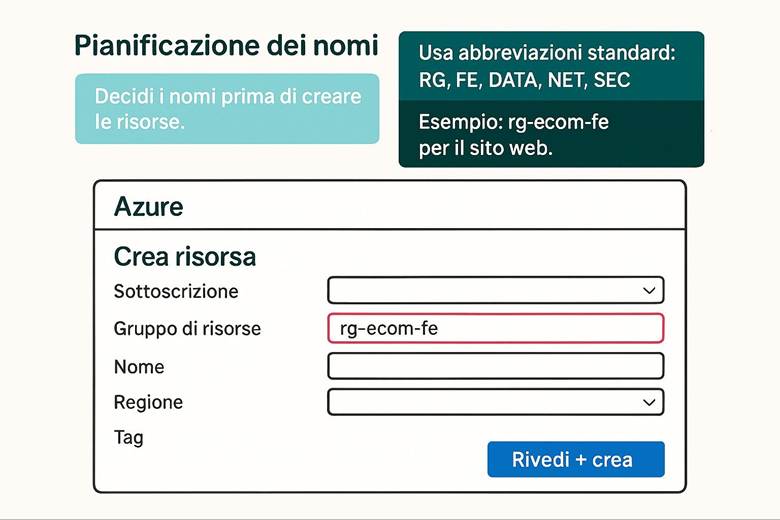
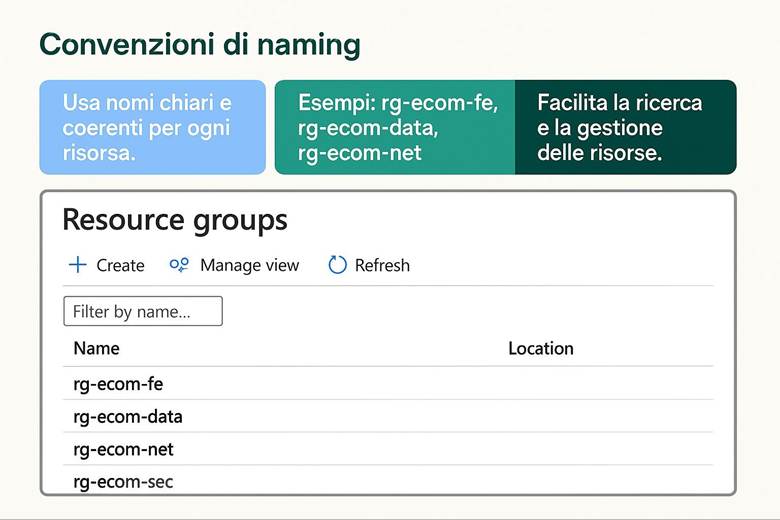
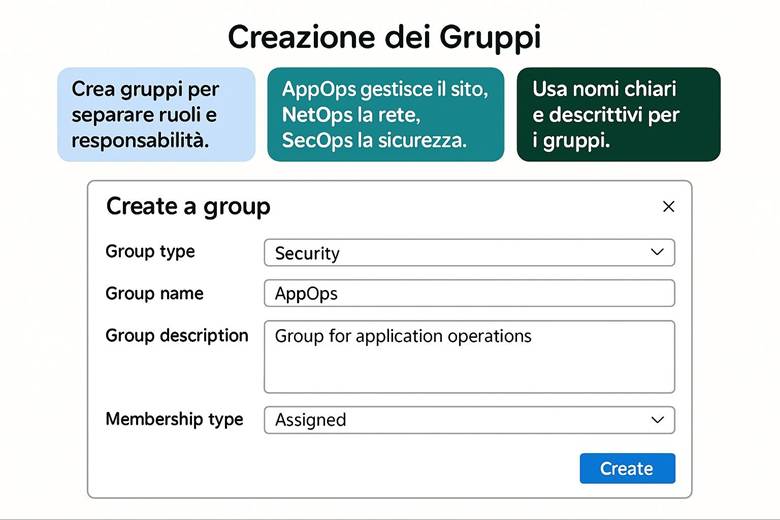
1. Crea le scatole: organizza le risorse con Management Groups e Resource Groups.
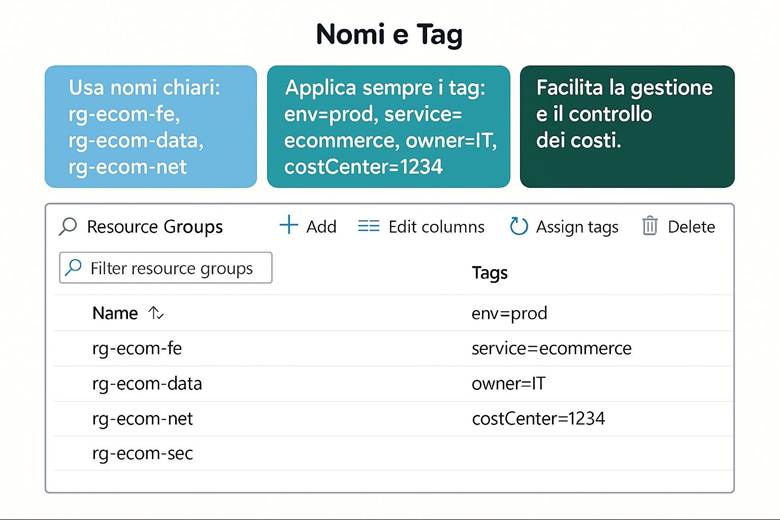
2. Dai nomi e tag: applica una struttura logica e facilmente gestibile.
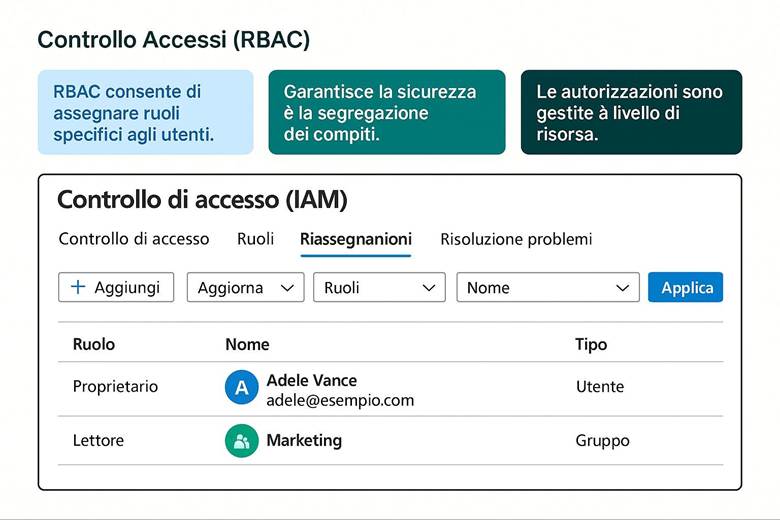
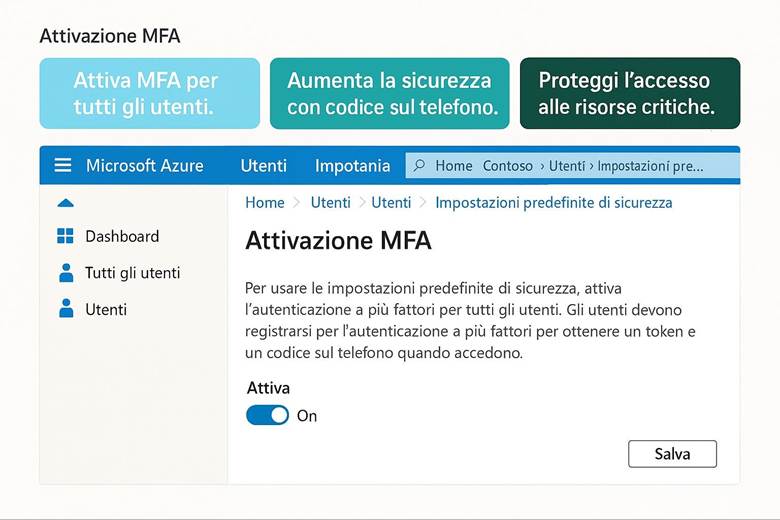
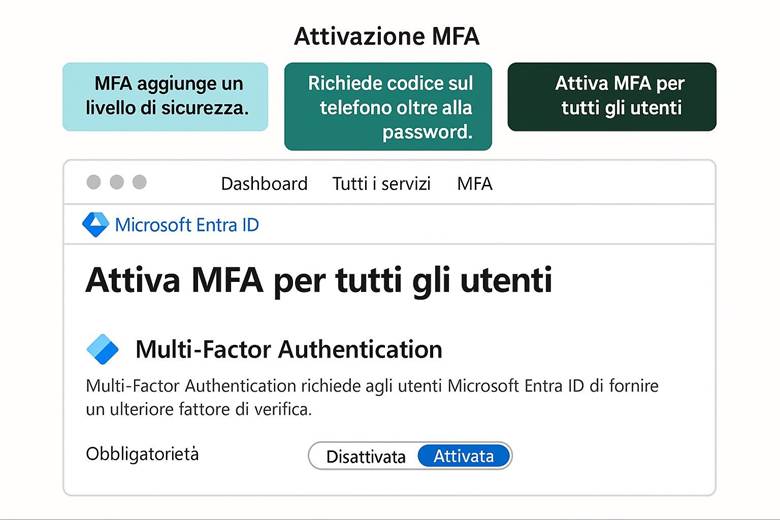
3. Metti regole di sicurezza: configura Entra ID e Multi-Factor Authentication (MFA).
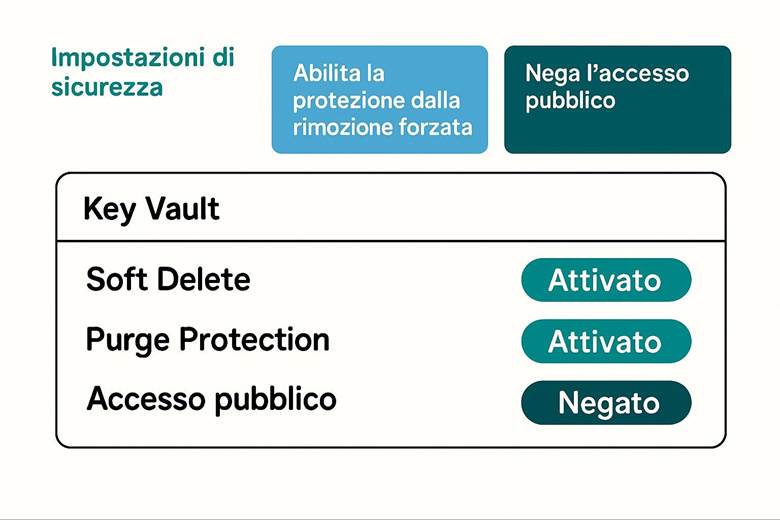
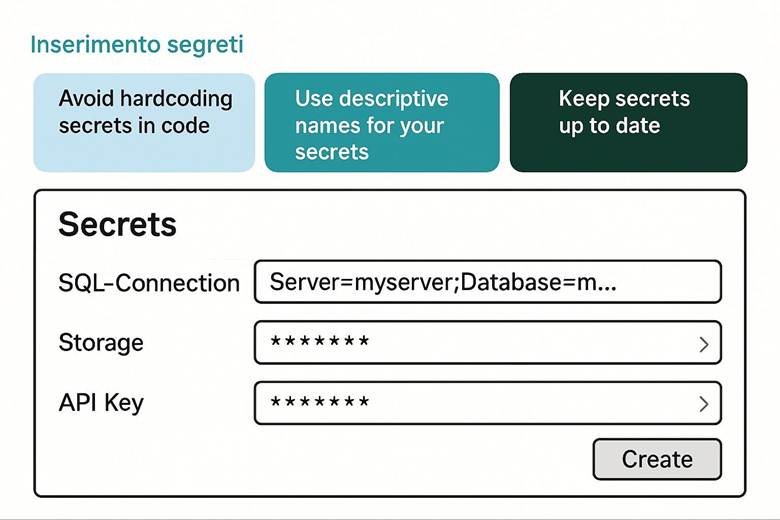
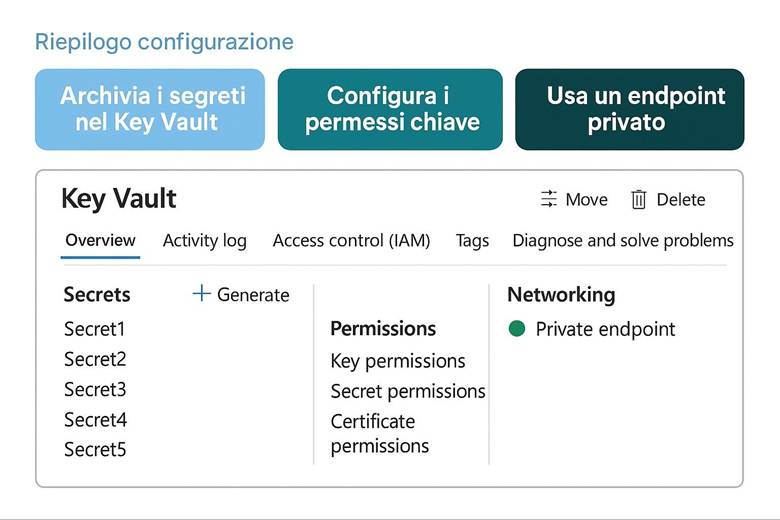
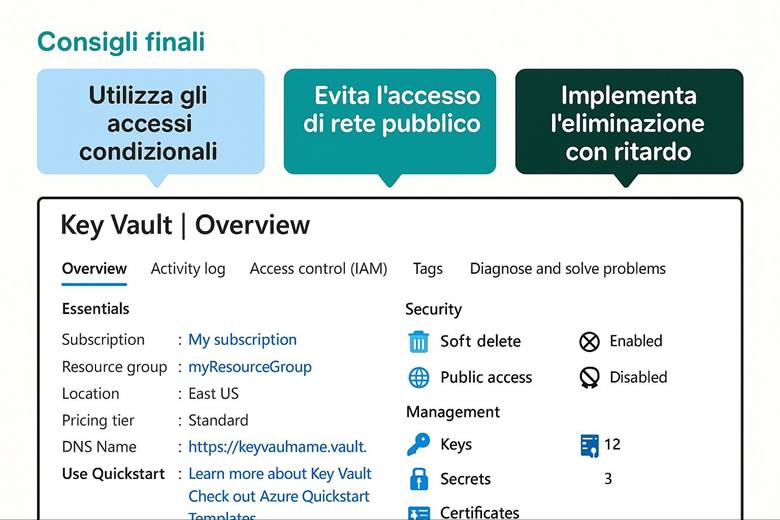
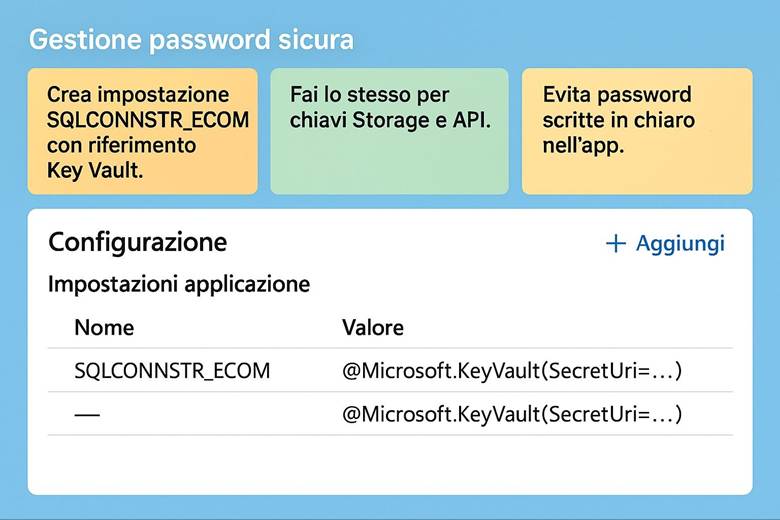
4. Crea il Key Vault: proteggi le chiavi e i segreti.
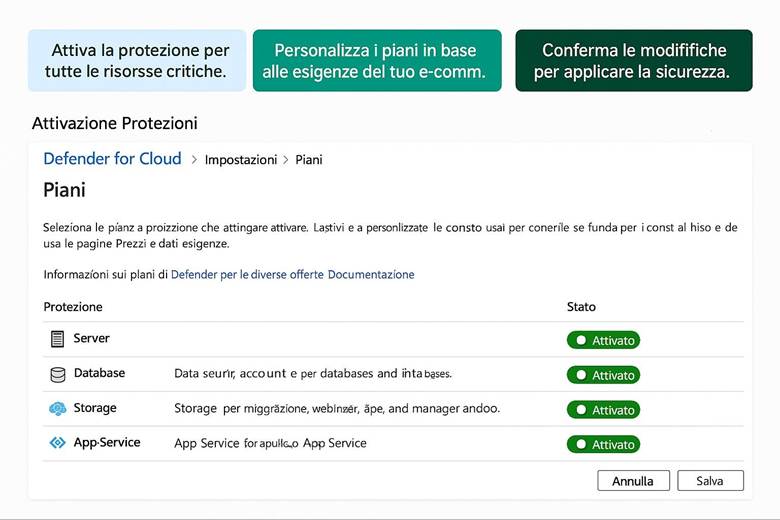
5. Attiva Defender for Cloud: aumenta la sicurezza del tuo ambiente.
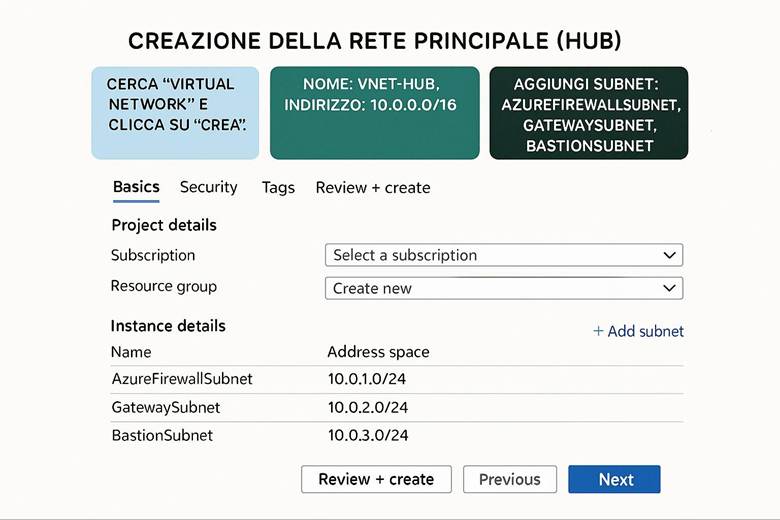
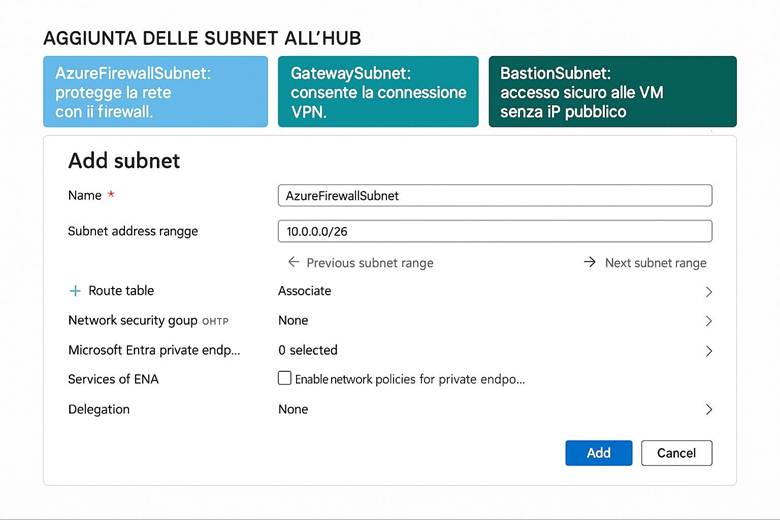
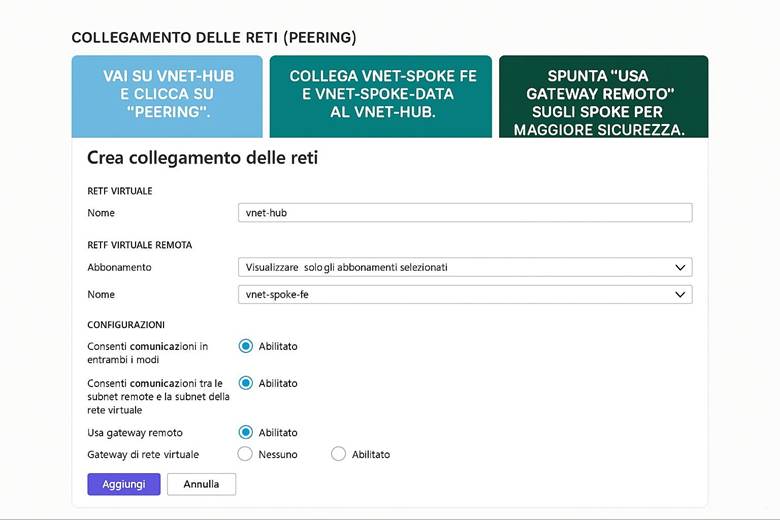
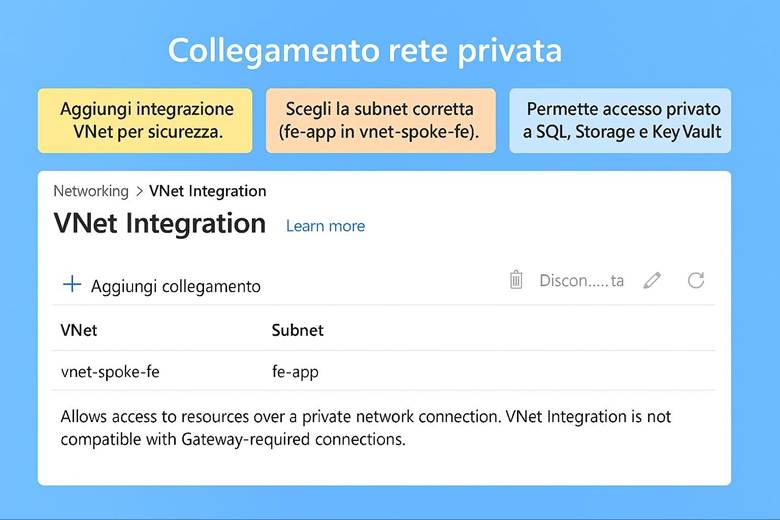
6. Configura le reti: realizza l’architettura hub e spoke e collega tutto.
7. Crea lo Storage: archivia le immagini del tuo e-commerce.
8. Imposta il Database SQL: gestisci i dati dei prodotti e degli ordini.
9. Crea l’App Service: ospita il sito web del tuo e-commerce.
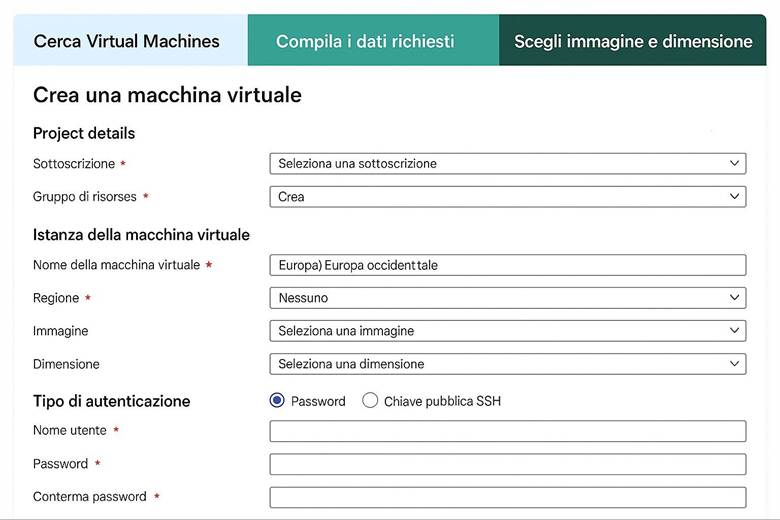
10. Aggiungi VM se serve: per esigenze particolari di calcolo.
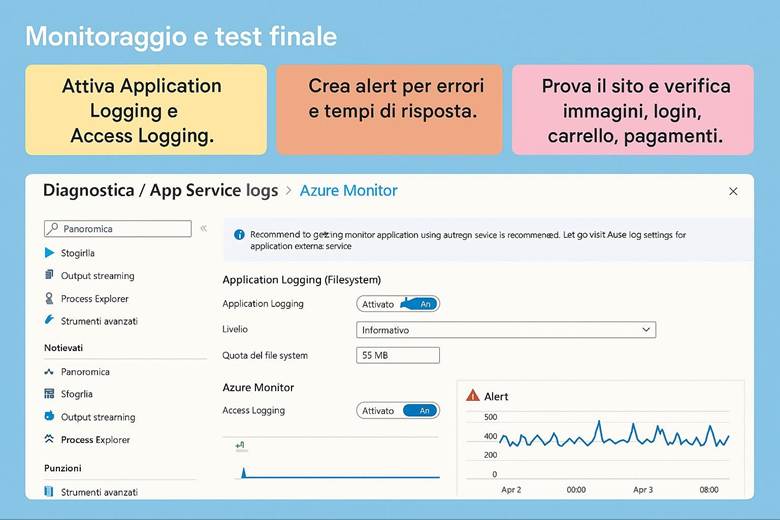
11. Attiva Monitor e alert: controlla lo stato e ricevi notifiche.
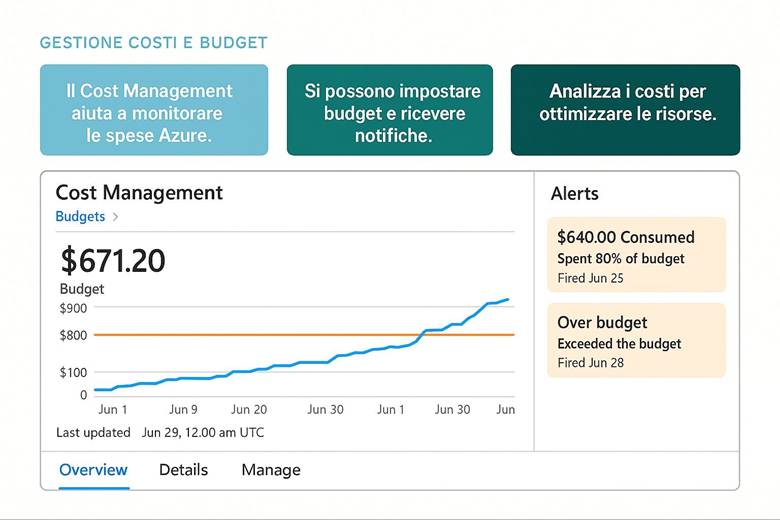
12. Controlla i costi: ottimizza il budget e mantieni la spesa sotto controllo.
Questo percorso ti permetterà di applicare concretamente le competenze acquisite, trasformando la teoria in un progetto reale e utile. Alla fine, non avrai solo imparato Azure: avrai creato un e-commerce funzionante, pronto per essere utilizzato o presentato come portfolio professionale.
CAPITOLO 1 – Panoramica Generale
Introduzione generale su Azure
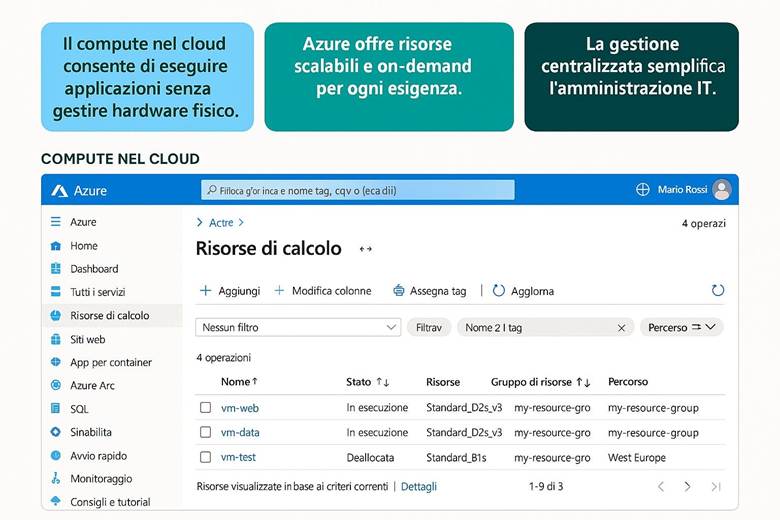
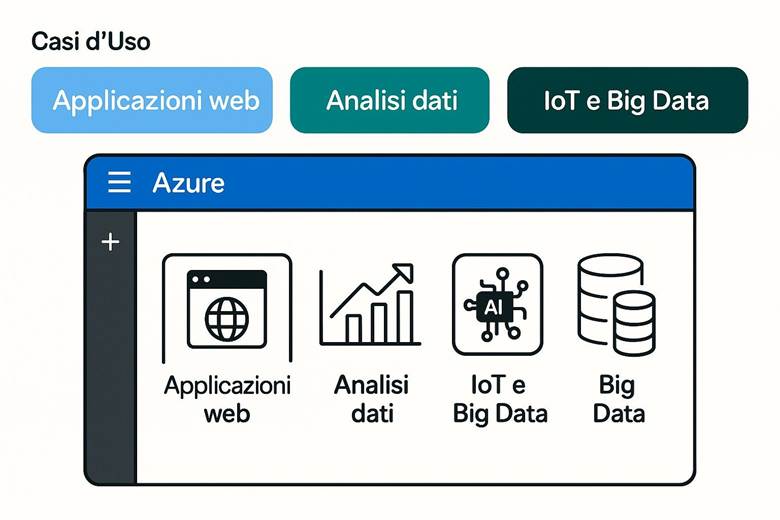
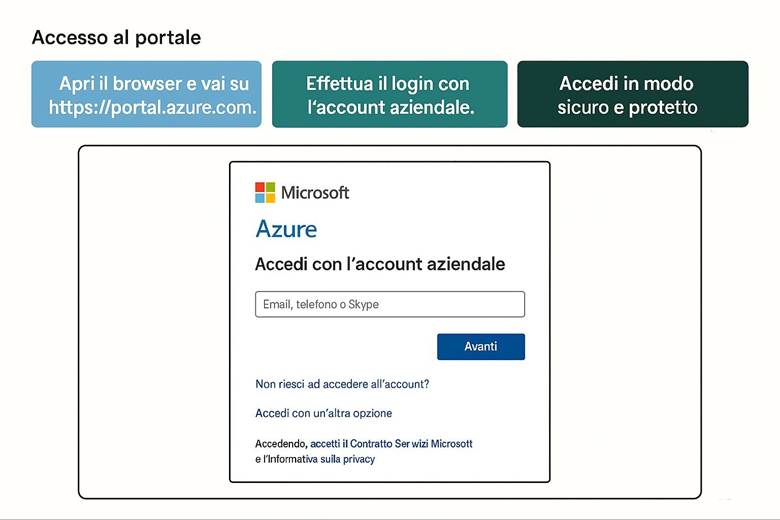
Che cos’è Azure? Microsoft Azure è la piattaforma di cloud computing di Microsoft che offre un insieme vasto di servizi on-demand nel campo del calcolo, dell’archiviazione dati, del networking, della sicurezza e della gestione. Tramite il portale Azure (un’interfaccia web unificata) è possibile distribuire risorse, configurarle e monitorarle centralmente. Rispetto ai data center tradizionali on-premises, Azure garantisce scalabilità elastica (le risorse possono crescere o diminuire in base alle esigenze), alta disponibilità (infrastruttura ridondata globalmente) e modelli di costo flessibili (pagamento in base al consumo, abbonamenti, piani risparmio). In sostanza, Azure consente alle aziende di concentrarsi sullo sviluppo e la gestione delle applicazioni senza preoccuparsi dell’acquisto e manutenzione dell’hardware sottostante.
Pilastri principali di Azure: I servizi di Azure sono organizzati in varie categorie fondamentali (a volte chiamati pilastri). Di seguito i principali pilastri con alcuni esempi di servizi inclusi in ciascuno:
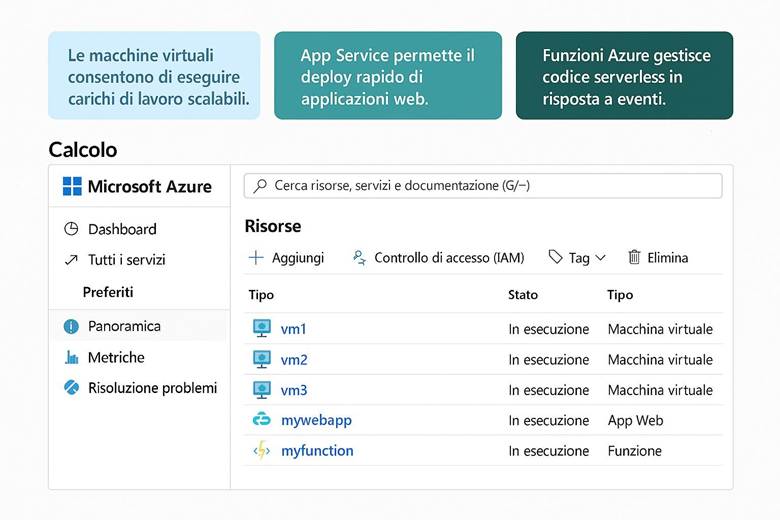
· Compute (Calcolo) – Servizi per eseguire carichi di lavoro: macchine virtuali, container (es. Azure Kubernetes Service), e funzioni serverless (Azure Functions).
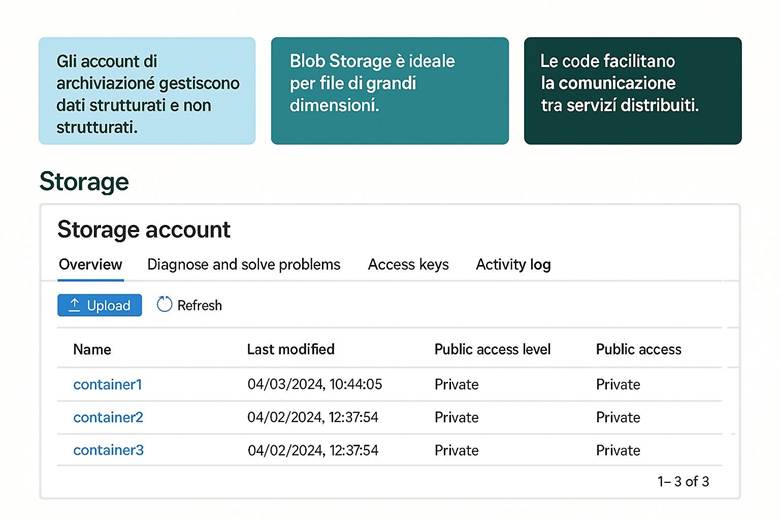
· Storage (Archiviazione) – Servizi di archiviazione dati: oggetti (Blob Storage), file (Azure Files), code di messaggi (Queue Storage), tabelle NoSQL (Table Storage) e dischi gestiti per VM.
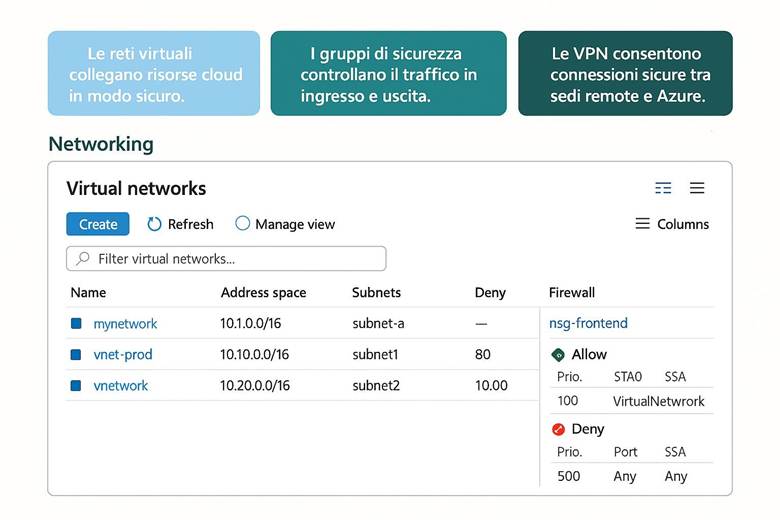
· Networking (Reti) – Servizi di rete: reti virtuali (VNet) per collegare risorse in cloud, bilanciatori di carico, connessioni ibride (VPN, ExpressRoute) per integrare con reti locali.
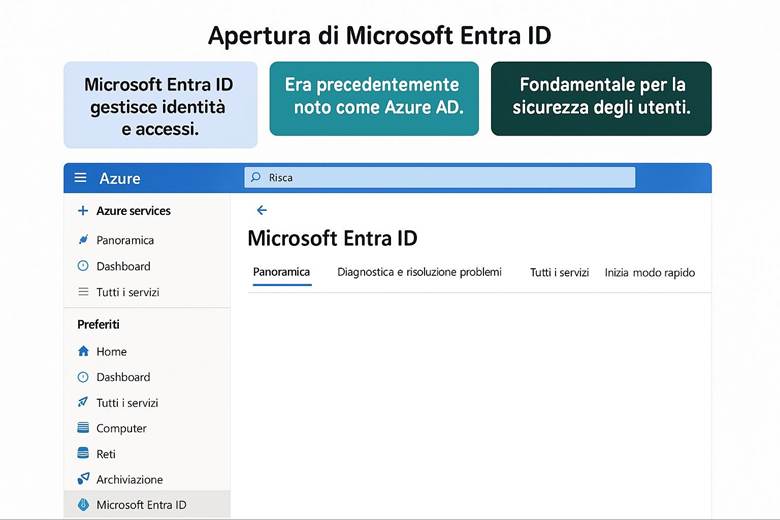
· Sicurezza e identità – Servizi per proteggere risorse e gestire identità: ad esempio Microsoft Defender for Cloud per la postura di sicurezza, Microsoft Entra ID (precedentemente Azure Active Directory) per l’autenticazione e l’autorizzazione, e Key Vault per la gestione di chiavi e segreti.
· Monitoraggio e governance – Strumenti per controllare e ottimizzare l’ambiente: Azure Monitor per raccogliere metriche e log, Azure Policy per l’applicazione di regole aziendali e Azure Advisor per raccomandazioni di ottimizzazione. Esempio pratico: Un’azienda intende pubblicare un portale di e-commerce in Azure senza doversi occupare dell’infrastruttura fisica. Può ad esempio distribuire un servizio App Service per ospitare l’applicazione web, utilizzare un Azure SQL Database gestito per i dati transazionali, archiviare le immagini dei prodotti su Blob Storage, proteggere l’ambiente con Defender for Cloud e monitorare prestazioni e costi tramite Azure Monitor e Cost Management. Tutto questo viene realizzato in Azure on-demand, evitando all’azienda di acquistare e gestire server fisici. Suggerimenti di visualizzazione: Per introdurre Azure e i suoi pilastri, si potrebbe utilizzare uno schema a blocchi che rappresenta i 5 pilastri principali (Compute, Storage, Networking, Security, Management) collegati tra loro da frecce. Questo diagramma mostrerebbe ad esempio il ciclo di vita di una soluzione cloud: deploy delle risorse → applicazione delle misure di sicurezza → monitoraggio continuo → ottimizzazione dei costi.
Inquadramento argomenti del capitolo con slides illustrate
Microsoft Azure è la piattaforma cloud di Microsoft che offre servizi di calcolo, archiviazione, rete, sicurezza e gestione per applicazioni e infrastrutture di qualsiasi dimensione. Dal portale Azure puoi distribuire, configurare e monitorare tutte le risorse. Rispetto ai datacenter tradizionali, Azure garantisce scalabilità elastica, alta disponibilità e modelli di costo flessibili. I cinque pilastri principali sono: Compute, Storage, Networking, Sicurezza e Identità, Monitoraggio e Governance. Per esempio, un’azienda può pubblicare un portale e-commerce usando App Service per il sito web, SQL Database gestito, archiviazione immagini in Blob Storage, protezione con Defender for Cloud e monitoraggio tramite Azure Monitor e Cost Management, senza acquistare hardware.
Le macchine virtuali di Azure offrono calcolo on-demand con controllo su sistema operativo, rete e storage, consentendo la scelta della dimensione in base al carico di lavoro e il pagamento solo delle risorse usate. Gli Storage Accounts forniscono uno spazio per Blob, Files, Queues e Tables, con cifratura, durabilità e scalabilità. Le Virtual Network sono essenziali per collegare in modo sicuro le risorse Azure tra loro, con Internet o ambienti on-premise, supportando subnet, filtri NSG e routing personalizzato. Un esempio pratico è un’app gestionale che usa VM Windows, Azure Files, VNet con subnet separate, NSG per regole di accesso e VPN Gateway per collegare la sede aziendale.
I Resource Group sono contenitori logici che raggruppano risorse correlate, facilitando il deploy, l’aggiornamento e la rimozione coordinata. Un naming coerente, il tagging per ambiente, servizio e dipartimento, e una gerarchia organizzata in Management Groups, Subscription, Resource Group e Resources, aiutano la governance e la gestione dei costi. Ad esempio, puoi separare le risorse con cicli di vita diversi, come un Resource Group per il front-end e uno per i dati, applicando RBAC differenziato.
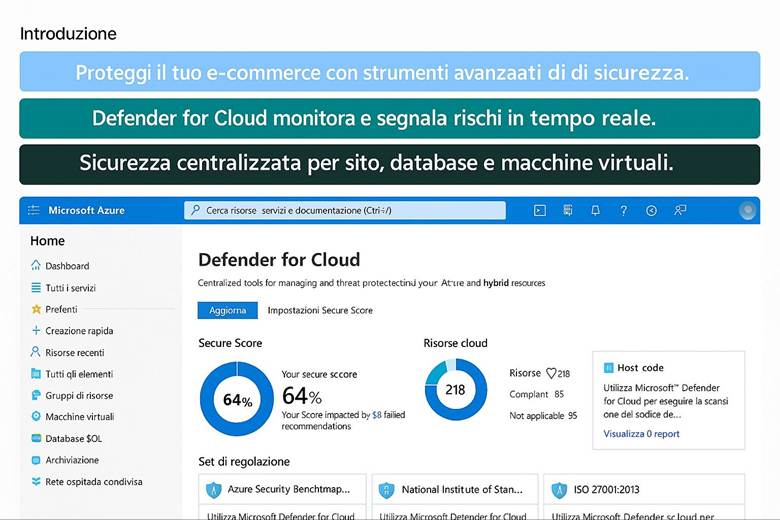
Microsoft Defender for Cloud è una piattaforma CNAPP che unifica la postura di sicurezza, DevSecOps e la protezione dei carichi di lavoro. Fornisce un Secure Score, raccomandazioni, alert e conformità regolatoria. Con Microsoft Entra ID puoi applicare RBAC e principi di Zero Trust, abilitando MFA e Conditional Access. I dati sono cifrati sia at-rest che in transito, e per la gestione di segreti e chiavi si usa Azure Key Vault. Un esempio: abilitare Defender for Servers su un Resource Group di produzione consente valutazioni, scanning agentless, raccomandazioni e integrazione con SIEM come Microsoft Sentinel.
La progettazione della rete in Azure prevede subnet per separare livelli applicativi, NSG per filtrare il traffico, UDR per instradamento personalizzato e Private Link per accesso privato ai servizi PaaS. Per la connettività ibrida si utilizzano VPN Gateway o ExpressRoute, mentre il peering delle Virtual Network permette comunicazione sicura tra regioni. Azure Virtual Network Manager consente la gestione su larga scala tramite topologie hub-and-spoke e regole di sicurezza centralizzate. Un esempio pratico è un’architettura hub-and-spoke con firewall centrale, spoke dedicati e Private Endpoints verso servizi come Storage e SQL.
Azure offre diverse soluzioni di storage: Blob Storage per oggetti, Azure Files per condivisioni SMB o NFS, Queues per messaggistica, Tables per NoSQL semplice e Managed Disks per VM. Gli account GPv2 sono consigliati per la maggior parte degli scenari, mentre Premium offre prestazioni superiori. La ridondanza può essere configurata come LRS, ZRS, GZRS, o RA-GZRS in base alle esigenze. La sicurezza è garantita da cifratura automatica e autorizzazioni granulari tramite Microsoft Entra ID; l’accesso privato avviene tramite Private Endpoints. Un repository immagini può essere configurato con GPv2, ridondanza geografica e policy di lifecycle per ottimizzare costi e prestazioni.
Le VM di Azure sono ideali per applicazioni che richiedono controllo sull’OS o compatibilità con software legacy. Puoi scegliere tra diverse famiglie di VM per ottimizzare risorse e costi, e aumentare la disponibilità tramite Availability Zones o Scale Sets. I costi si riducono con Reserved Instances e Savings Plans, mentre le Spot VMs sono adatte per lavori non critici. Un ambiente CAD, ad esempio, può essere realizzato con NVads v5, dischi Premium SSD, VNet dedicata, accesso sicuro tramite Azure Bastion e monitoraggio completo.
Azure Monitor raccoglie metriche, log e traces da risorse Azure, cloud esterne e on-premise, offrendo visualizzazioni avanzate, alert e automazione. Strumenti come VM Insights, Container Insights e Network Insights facilitano l’analisi delle prestazioni. Puoi configurare Data Collection Rules per inviare log a Log Analytics, impostare alert su soglie critiche e utilizzare workbook per monitorare SLA e tempi di risposta.
Azure Monitor raccoglie metriche, log e traces da risorse Azure, cloud esterne e on-premise, offrendo visualizzazioni avanzate, alert e automazione. Strumenti come VM Insights, Container Insights e Network Insights facilitano l’analisi delle prestazioni. Puoi configurare Data Collection Rules per inviare log a Log Analytics, impostare alert su soglie critiche e utilizzare workbook per monitorare SLA e tempi di risposta.
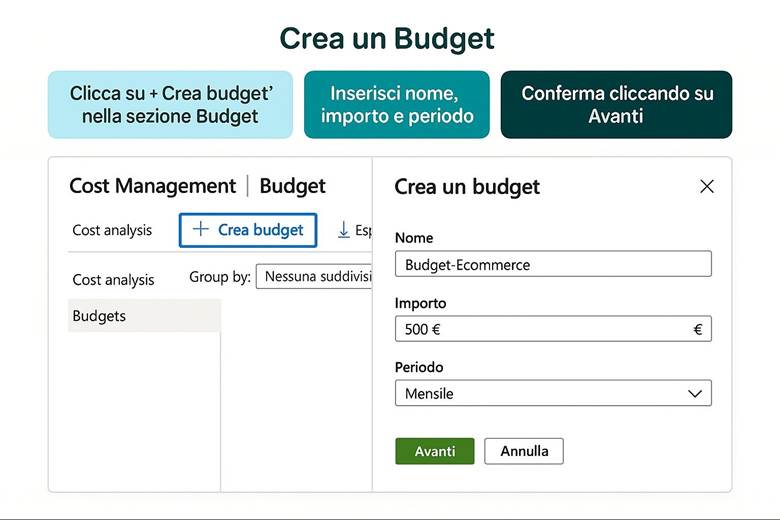
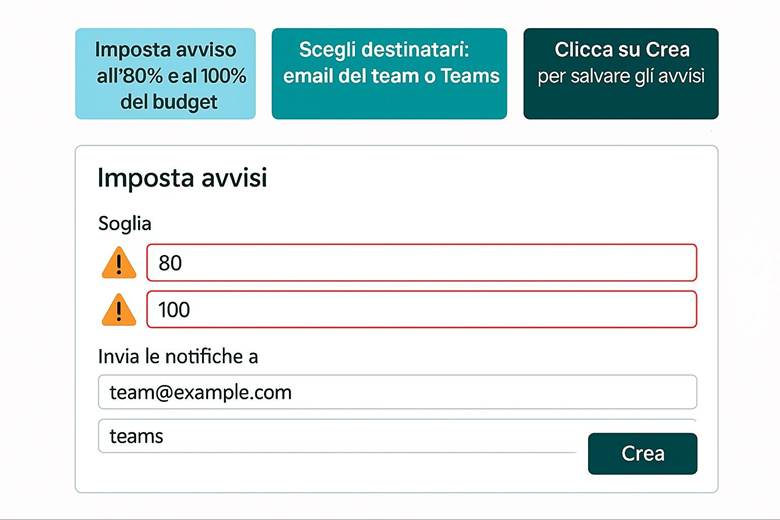
Con Cost Management + Billing puoi analizzare, monitorare e ottimizzare la spesa cloud. È possibile creare budget con alert specifici, visualizzare analisi per risorsa o tag, impostare split dei costi e sfruttare reservations e savings plans. Le best practice includono l’uso di scope e tag, la sorveglianza delle anomalie e il reporting periodico. Un esempio: impostare un budget mensile, ricevere alert all’80% e al 100%, monitorare i costi per servizio e seguire le raccomandazioni di Advisor per ottimizzare le risorse.
1. Servizi principali di Azure – Compute, Storage, Networking
Azure offre tre categorie di servizi cloud fondamentali – calcolo, archiviazione e rete – che costituiscono la base per qualsiasi progetto nel cloud. In questo capitolo esamineremo ciascuna di queste categorie, descrivendone i servizi principali e il loro ruolo.
Compute – Virtual Machines: Le macchine virtuali (VM) di Azure forniscono capacità di calcolo on-demand nel cloud con pieno controllo su sistema operativo, configurazione di rete e storage associato. È possibile scegliere dimensioni e tipi di VM in base alle necessità del carico di lavoro: ad esempio VM General Purpose bilanciate, VM ottimizzate per memoria o per calcolo, oppure VM con GPU per scenari di intelligenza artificiale o rendering grafico intensivo. Le risorse allocate (CPU, RAM, spazio disco) vengono tariffate secondo un modello pay-as-you-go, ovvero in base al consumo effettivo (con fatturazione oraria/minutaria delle VM attive). Azure fornisce inoltre opzioni per scalare il computo in modo elastico: si possono aggiungere o rimuovere VM manualmente, oppure usare servizi gestiti come Virtual Machine Scale Sets per scalare automaticamente in base a regole. (Fonte: Panoramica di Azure Virtual Machines).
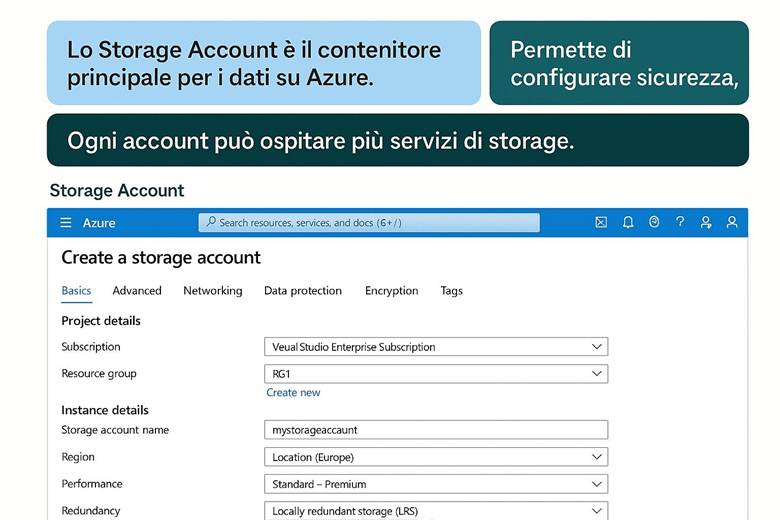
Storage – Account di archiviazione: Un Storage Account di Azure offre un namespace unico nel cloud per diversi servizi di archiviazione: Blob (oggetti), File (condivisioni file SMB/NFS), Queue (messaggistica tra componenti) e Table (archivio NoSQL). Tutti i dati archiviati in Azure Storage sono ridondati e cifrati in modo trasparente per garantire durabilità e sicurezza. Gli account di archiviazione più comuni sono di tipo General-purpose v2 (GPv2), adatti alla maggior parte degli scenari, mentre esistono account Premium ottimizzati per prestazioni elevate e bassa latenza (ad esempio per dischi SSD ultra o file share con IO elevato). Quando si crea un account, è possibile scegliere il livello di ridondanza dei dati (LRS, ZRS, GZRS o RA-GZRS) in base ai requisiti di durabilità e continuità operativa: queste opzioni saranno descritte in dettaglio in un capitolo successivo. È inoltre possibile impostare regole di accesso (ad esempio limitando l’accesso di rete tramite firewall o Private Endpoints). (Fonti: Introduzione ad Azure Storage, Panoramica degli account di archiviazione).
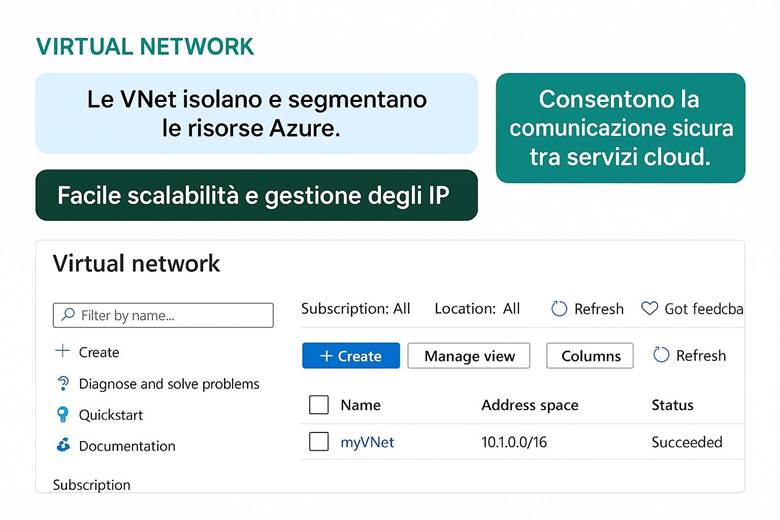
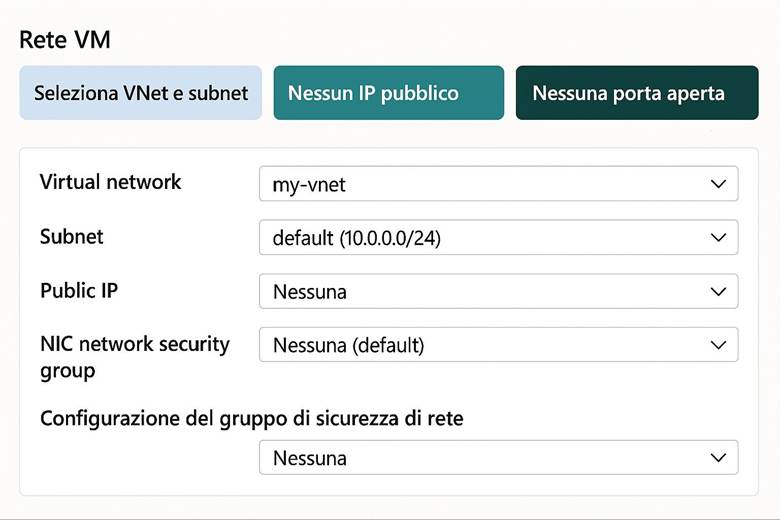
Networking – Rete virtuale (VNet): La Azure Virtual Network (VNet) è il componente base per realizzare reti in Azure. Una VNet consente di collegare in modo sicuro le risorse cloud tra loro, di definire segmenti di rete isolati (subnet) e di controllare il traffico in entrata e uscita attraverso regole del Network Security Group (NSG). Con le VNet si possono inoltre stabilire connessioni con l’esterno: accesso a Internet per le risorse che lo richiedono, peering tra VNet in region diverse, oppure connessioni ibride con la rete on-premises dell’azienda tramite gateway VPN IPSec o collegamenti dedicati ExpressRoute. Le VNet supportano la personalizzazione del routing (User-Defined Routes) e l’integrazione con servizi PaaS tramite Azure Private Link (che consente di accedere ai servizi Azure PaaS attraverso endpoint privati nella VNet, evitando il traffico via Internet). Questo garantisce che il networking in Azure sia flessibile e sicuro, permettendo architetture sia completamente cloud sia ibride. (Fonte: Che cos’è una Rete Virtuale di Azure?)
Esempio pratico: Consideriamo un’applicazione gestionale classica da migrare in Azure. Si può creare una VM Windows in Azure per eseguire l’applicazione legacy, utilizzare Azure Files per spostare nel cloud le condivisioni di file SMB utilizzate dall’app, e configurare una VNet con due subnet separate (ad esempio una subnet per l’applicazione ed una per il database). Le regole di un NSG assicurano che solo l’applicazione possa comunicare col database, innalzando la sicurezza. Infine, per connettere l’ambiente cloud con la sede centrale dell’azienda, si può impostare un VPN Gateway che estende la rete locale alla VNet Azure. In questo modo l’applicativo sul cloud può comunicare con i sistemi ancora presenti on-premises in maniera protetta e trasparente agli utenti.
Suggerimenti visivi: Per rappresentare questi tre servizi principali (Compute, Storage, Networking) e le loro interazioni, si potrebbe mostrare un diagramma a triangolo in cui ogni vertice rappresenta uno dei pilastri (ad esempio un’icona di una VM, un’icona di storage e un’icona di rete). Tra questi, frecce e didascalie potrebbero evidenziare come elaborazione, dati e connettività collaborano nelle soluzioni Azure, sottolineando concetti chiave come la sicurezza integrata, la scalabilità e il modello pay-as-you-go.
2. Organizzazione e gestione delle risorse con i Resource Groups
Un elemento fondamentale della gestione delle risorse in Azure è il concetto di Resource Group (RG). Un Resource Group è essenzialmente un contenitore logico in cui inserire risorse Azure correlate, in modo da gestirle come un’unità coesa durante tutto il loro ciclo di vita. Ad esempio, si possono raggruppare in un unico RG tutti i componenti di una stessa applicazione (VM, database, account di storage, funzionalità di rete, ecc.), facilitando operazioni come il deployment ripetuto, l’applicazione di politiche di accesso o la rimozione completa dell’ambiente.
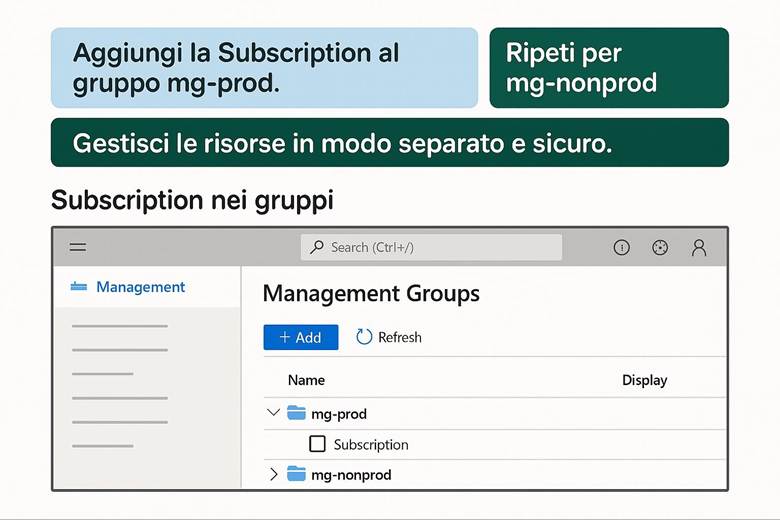
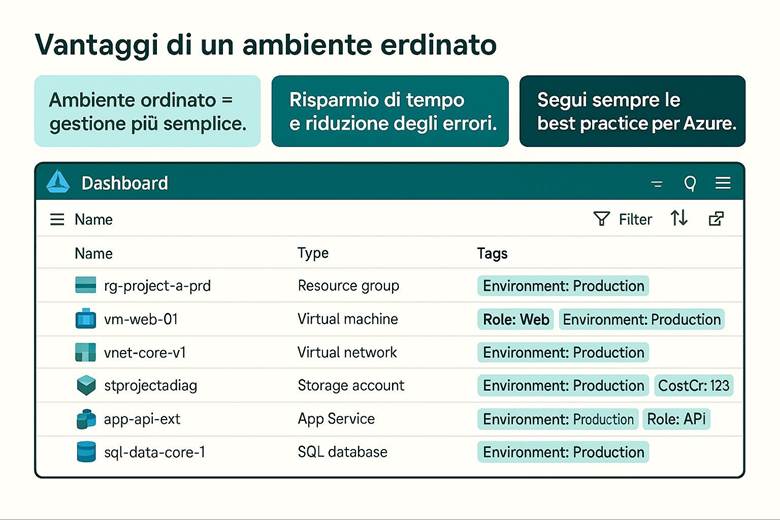
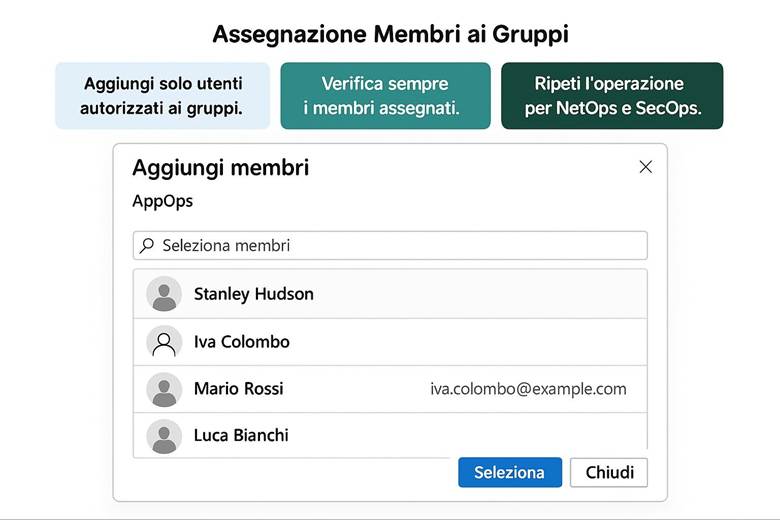
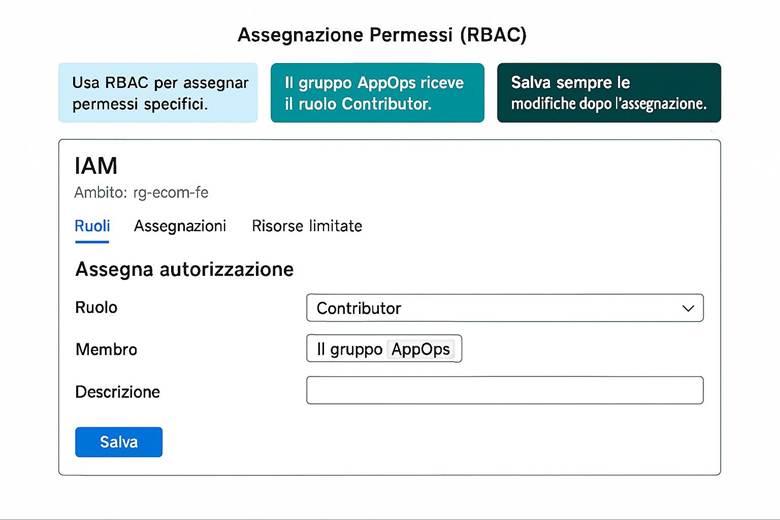
Cos’è un Resource Group: In pratica, un RG raggruppa risorse che condividono uno stesso ciclo di vita e spesso uno stesso scopo applicativo. Le risorse all’interno di un RG possono essere gestite in maniera coordinata: ad esempio, eliminando un RG si eliminano tutte le risorse in esso contenute. Inoltre, i Resource Group costituiscono un confine per controllo degli accessi (possiamo assegnare permessi RBAC su un intero gruppo di risorse) e per l’applicazione di tag (etichette chiave-valore utili per categorizzare risorse per reparto, ambiente, progetto, ecc.). I Resource Group risiedono all’interno di Subscription Azure, e a loro volta le subscription possono essere organizzate in Management Groups per strutturare la governance su scala enterprise. Questa gerarchia (Management Groups → Subscription → Resource Groups → Resources) aiuta a separare ambiti amministrativi, costi e politiche di sicurezza a diversi livelli. (Fonte: Cloud Adoption Framework – Organize resources)
Buone pratiche nella gestione dei RG: Quando si progetta la suddivisione delle risorse in Resource Group, è consigliabile seguire alcune best practice per mantenere ordine e coerenza nell’ambiente cloud:
· Naming consistente: Dare ai Resource Group (e alle risorse) nomi standardizzati e comprensibili. Ad esempio, un convenzione potrebbe essere <prefisso>-<app>-<env>-<regione>-<sequenza>, risultando in nomi come rg-app-prod-euw-01. Un naming solido aiuta a identificare rapidamente scopo e ubicazione di un RG.
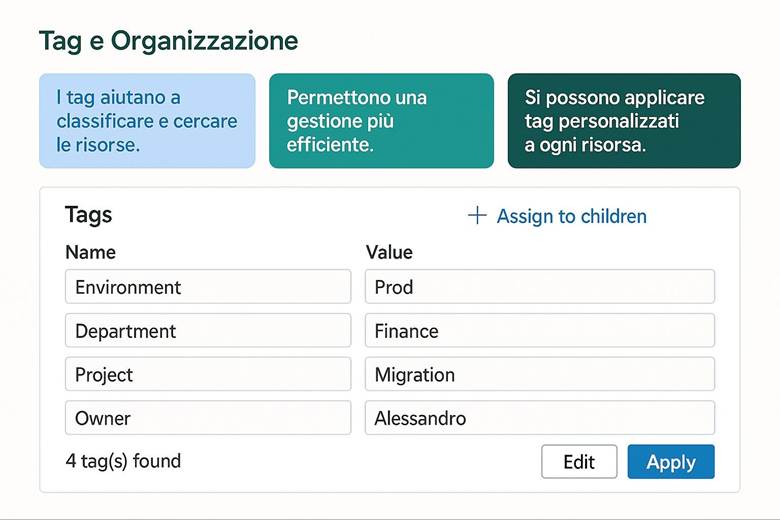
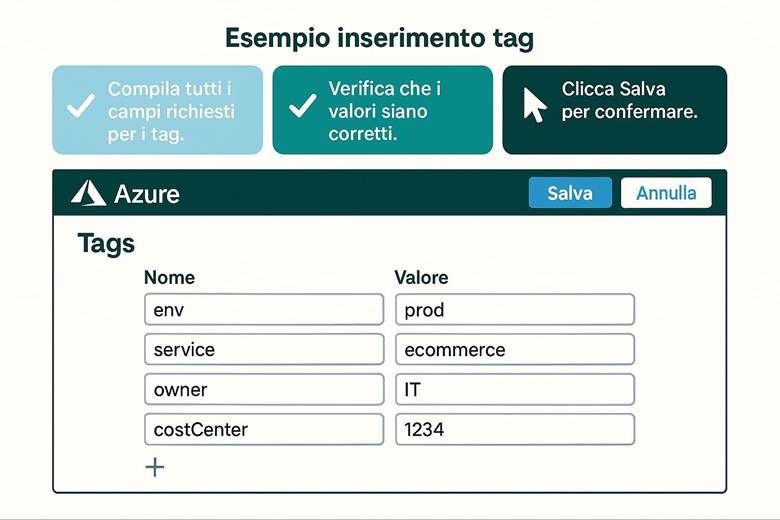
· Uso dei Tag: Assegnare tag a ogni RG (e risorsa) per indicare metadati utili come l’ambiente (env: produzione/test), il servizio o progetto (app: ecommerce), il dipartimento proprietario (dept: marketing) e la regione (region: West Europe). I tag facilitano filtraggio, reportistica dei costi e applicazione di politiche.
· Struttura gerarchica: Organizzare le risorse seguendo la gerarchia di Azure: Management Groups per raggruppare più sottoscrizioni aziendali; Subscriptions separate ad esempio per ambienti (prod, test) o per business unit; all’interno delle subscription creare RG per ciascun sistema/progetto. Questa separazione consente di applicare controlli di governance e budget a livelli differenti (es: policy a livello di management group; limiti di spesa a livello di subscription; RBAC specifico sui RG). (Fonti: Organize resources – naming e tagging) Esempio pratico: Si consideri un’azienda che ha un’applicazione web e un database. Una buona organizzazione potrebbe prevedere due Resource Group distinti: uno per la parte applicativa front-end (es. RG "app-web") che contiene le risorse aggiornate più frequentemente, come l’app service o le VM web, e un altro per la parte dati (es. RG "data-platform") che ospita il database e archivi blob, i quali tipicamente hanno cicli di aggiornamento diversi. In questo modo si possono applicare politiche di controllo degli accessi differenti: ad esempio, il team di sviluppo web avrà permessi completi sul RG dell’app, mentre l’accesso al RG dei dati sarà ristretto agli amministratori di database. Anche il versionamento e la rimozione delle risorse risultano semplificati, potendo agire sui RG separatamente a seconda delle esigenze. Suggerimenti visivi: Per illustrare l’organizzazione tramite Resource Group, è utile uno schema gerarchico che mostri i diversi livelli: ad esempio un diagramma a piramide con in cima i Management Groups, poi le Subscription, sotto ciascuna vari RG e infine le risorse specifiche dentro ogni RG. Inoltre, si potrebbe includere un esempio di tabella di tagging che elenca alcuni Resource Group con relativi tag chiave (come env, dept, owner, ecc.), evidenziando come i tag vengono applicati per classificare le risorse.
3. Sicurezza in Azure – Postura, Identità e Protezione dei Dati
La sicurezza è un aspetto cruciale del cloud Azure: Microsoft fornisce una serie di servizi integrati per proteggere le risorse cloud, gestire le identità degli utenti e salvaguardare i dati, il tutto in linea con principi di Zero Trust e conformità aziendale. In questo capitolo vedremo come Azure affronta la sicurezza su più fronti: monitoraggio della postura di sicurezza, gestione degli accessi e protezione dei dati.
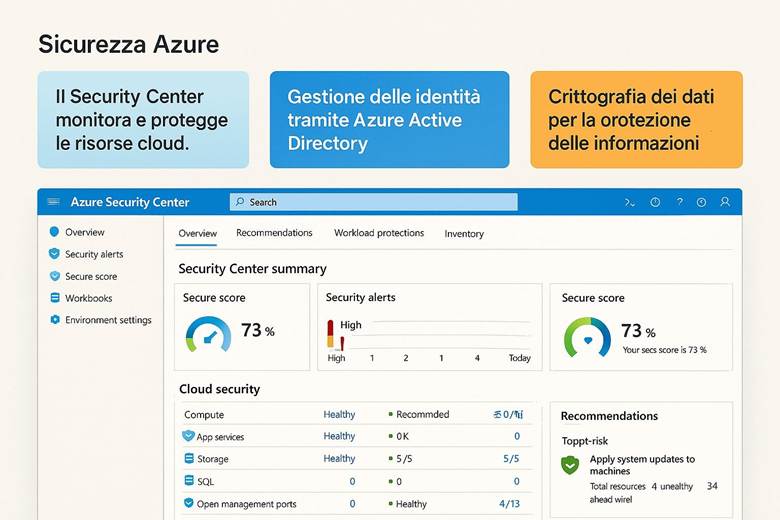
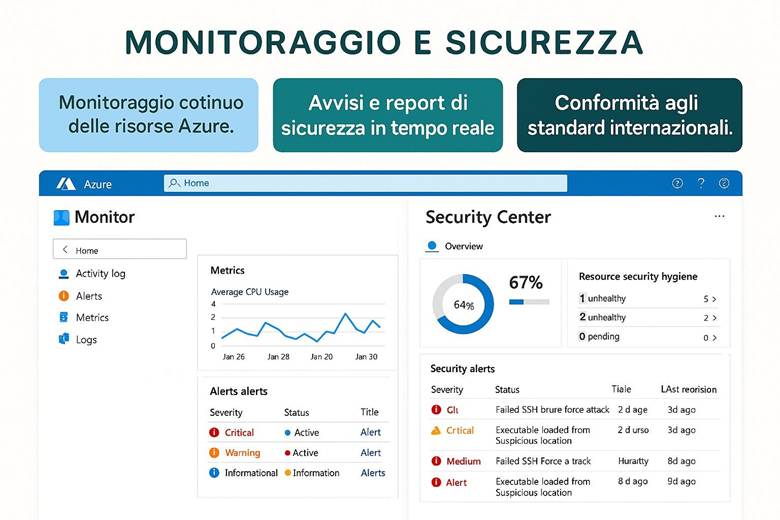
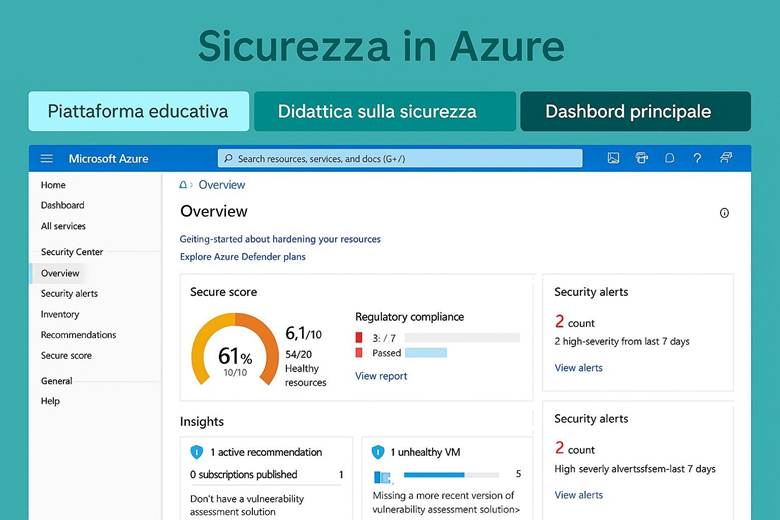
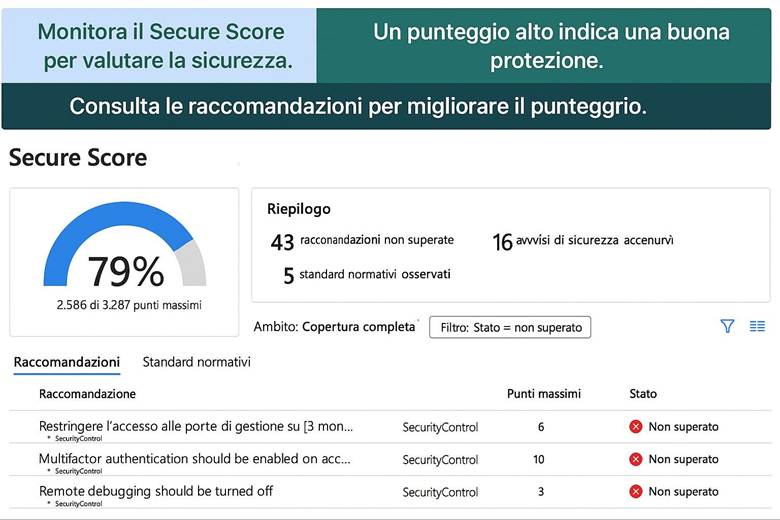
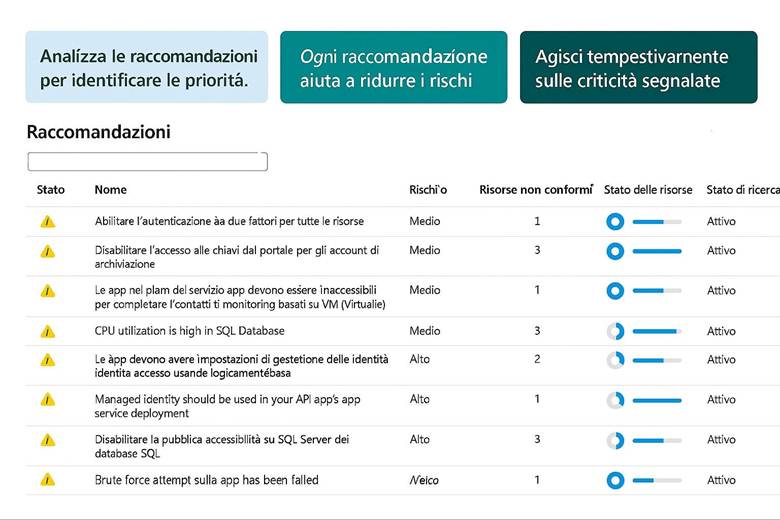
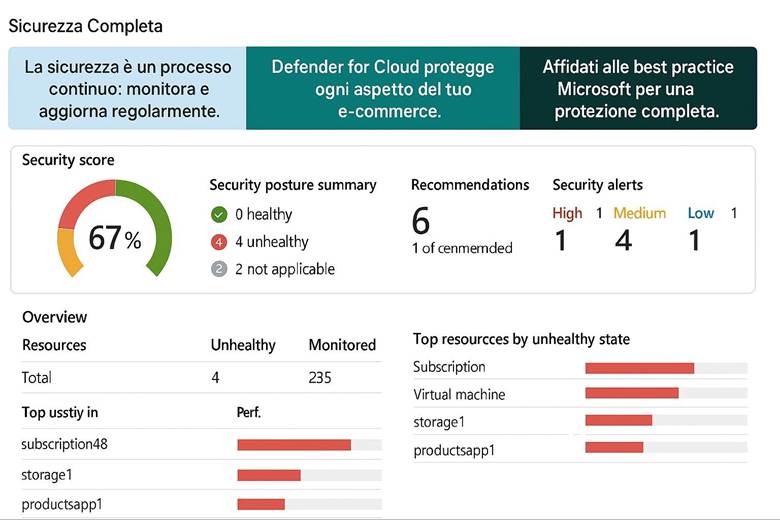
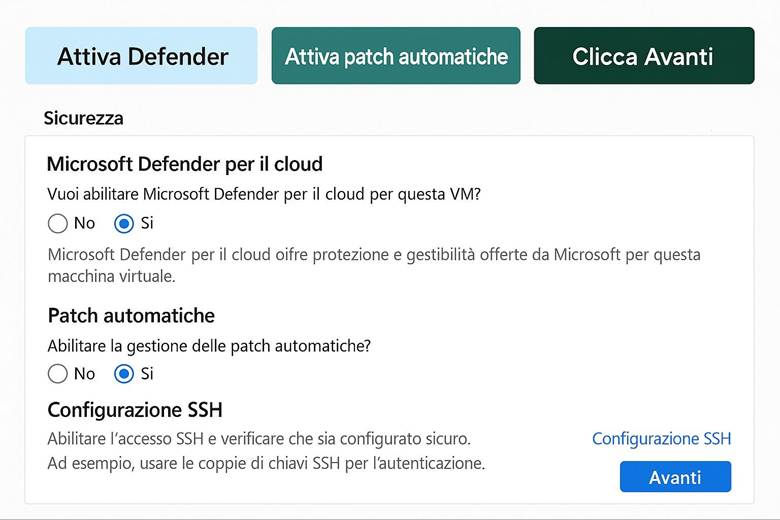
Microsoft Defender for Cloud: È la piattaforma unificata di sicurezza nativa di Azure, classificata come una soluzione CNAPP (Cloud-Native Application Protection Platform). Defender for Cloud include funzionalità di CSPM (Cloud Security Posture Management) per valutare la postura di sicurezza dell’ambiente Azure e di CWPP (Cloud Workload Protection Platform) per offrire protezione attiva dei carichi di lavoro come VM, container, storage e database. Questo servizio fornisce una Secure Score che sintetizza il livello di sicurezza delle risorse, presenta raccomandazioni su configurazioni da migliorare e genera allarmi in caso di rilevamento di minacce o anomalie. Inoltre, consente di verificare la conformità a standard regolamentari o best practice tramite assessment continui. In pratica, abilitando Defender for Cloud su una sottoscrizione Azure si ottiene una vista centralizzata dello stato di sicurezza e protezione di tutte le risorse, con suggerimenti proattivi per ridurre la superficie di attacco (ad esempio macchine virtuali senza patch, account di storage con accesso pubblico, ecc.). (Fonti: Panoramica Microsoft Defender for Cloud, Documentazione Defender for Cloud)
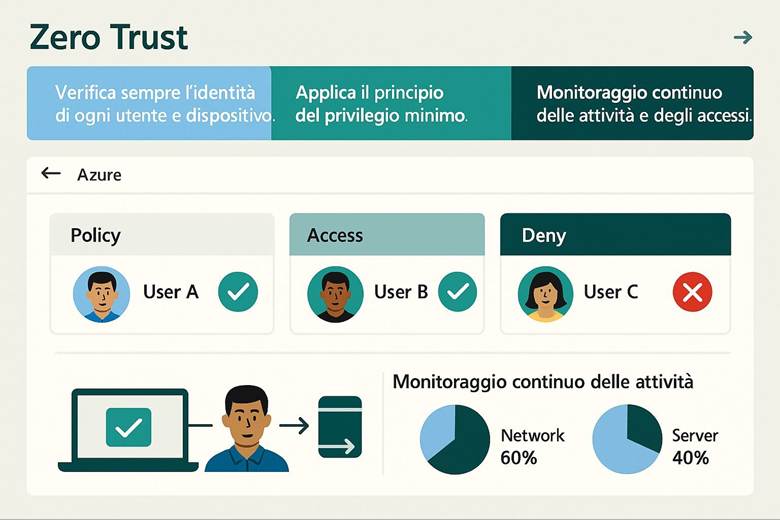
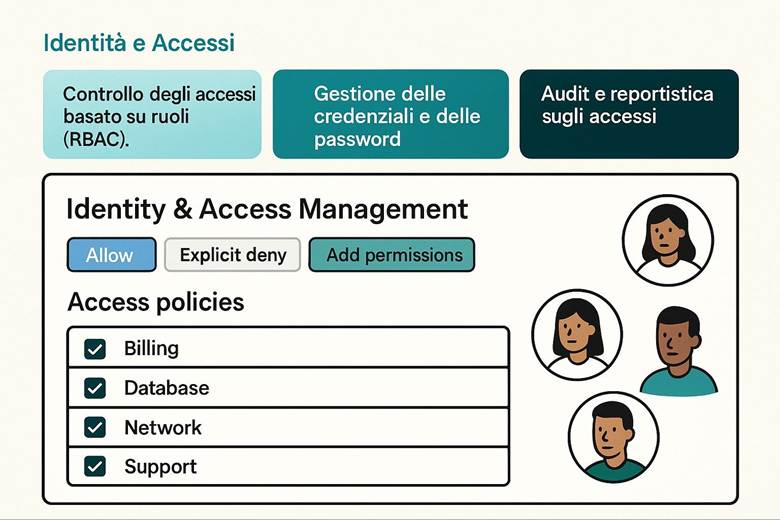
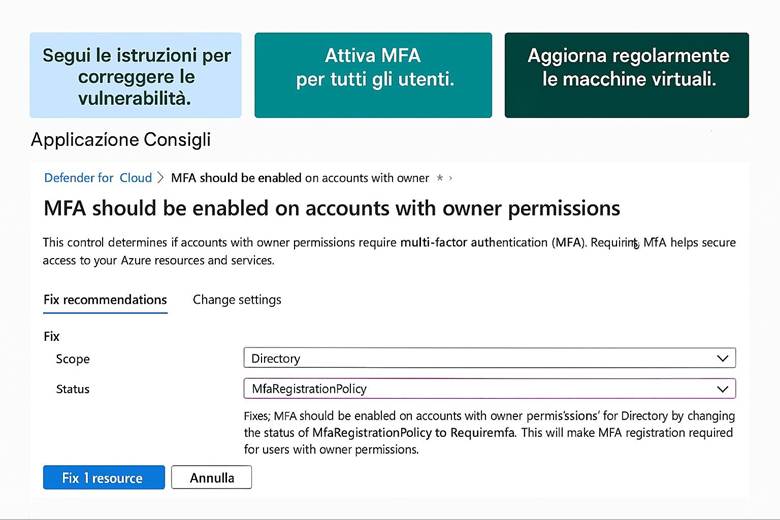
Identità e controllo di accesso: Azure delega la gestione delle identità a Microsoft Entra ID, precedentemente noto come Azure Active Directory. Entra ID gestisce l’autenticazione degli utenti e delle entità di sicurezza e abilita il modello di accesso RBAC (Role-Based Access Control) sulle risorse Azure. Tramite RBAC si assegnano ruoli predefiniti o personalizzati agli utenti/gruppi, garantendo il principio del privilegio minimo. Azure consente di implementare principi di Zero Trust, ad esempio richiedendo MFA (Multi-Factor Authentication) per gli accessi e applicando condizioni tramite Conditional Access (politiche che permettono l’accesso alle risorse solo se certe condizioni sono soddisfatte, come posizione di rete o dispositivo conforme). Oltre a ciò, Azure supporta l’integrazione con identità esterne e la federazione, in modo che gli utenti possano usare le proprie credenziali aziendali o social per accedere alle app Azure, mantenendo un controllo centralizzato. (Fonte: Documentazione sicurezza di Azure – Identità e Zero Trust)
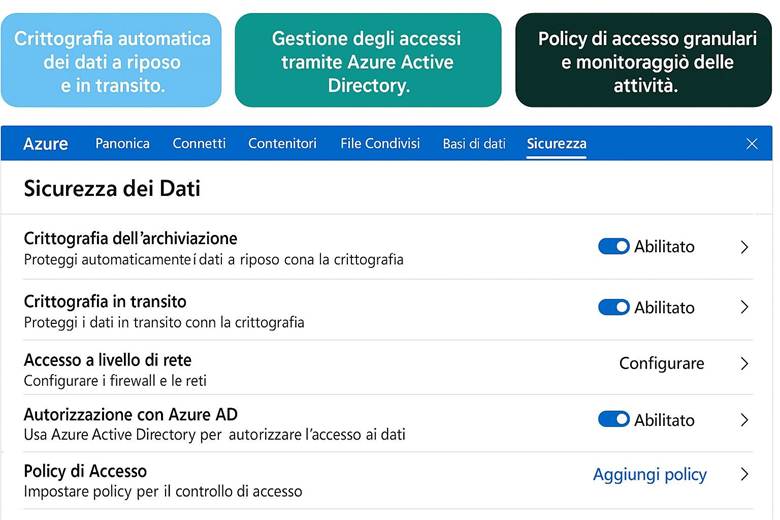
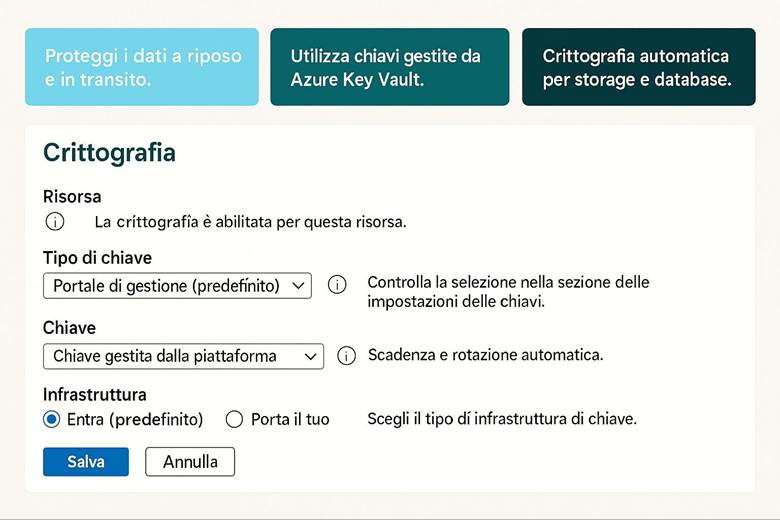
Protezione dei dati: Per tutelare i dati ospitati in Azure, la piattaforma implementa cifratura dei dati a riposo e in transito. Ciò significa che i servizi di archiviazione (dischi, file, database, ecc.) criptano automaticamente il contenuto salvato su disco (data at rest) usando chiavi gestite da Microsoft o, a scelta, chiavi gestite dal cliente tramite Azure Key Vault. Analogamente, le comunicazioni verso e tra i servizi Azure avvengono su canali crittografati (HTTPS/TLS) garantendo la protezione in transit. Azure Key Vault è il servizio dedicato alla gestione centralizzata di chiavi crittografiche, segreti e certificati utilizzati dalle applicazioni: le chiavi possono essere utilizzate per cifrare dati applicativi oppure per gestire la crittografia dei dischi (Azure Disk Encryption) e dei workspace di Log Analytics, mentre i segreti (come stringhe di connessione, password) possono essere richiamati in sicurezza dalle applicazioni runtime. Queste misure assicurano che solo utenti e applicazioni autorizzate possano accedere ai dati sensibili e mitigano i rischi in caso di accessi non autorizzati o compromissioni di account. (Fonte: Azure security documentation)
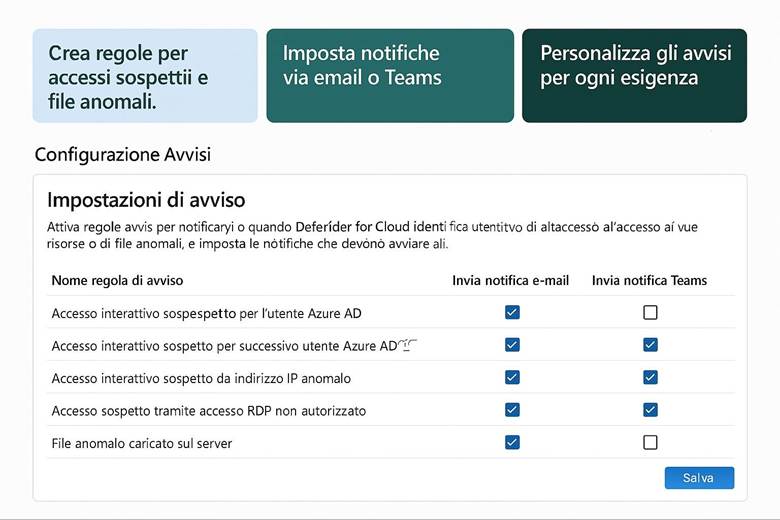
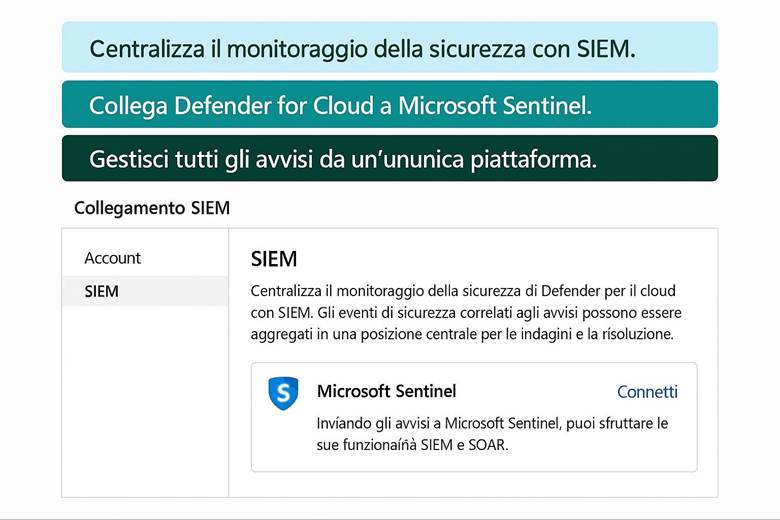
Esempio pratico: Un caso di utilizzo potrebbe essere l’abilitazione di Defender for Cloud su tutti i Resource Group di produzione di un’azienda. Una volta abilitato, Defender esegue la valutazione automatica delle configurazioni (ad esempio controlla che le porte delle VM esposte ad Internet siano protette da NSG, che gli storage account non abbiano contenitori pubblici, ecc.) e avvia anche uno scansione agentless delle VM alla ricerca di vulnerabilità note. Supponiamo che rilevi delle macchine virtuali non aggiornate: la piattaforma fornirà raccomandazioni su come risolvere (ad esempio “Applica le ultime patch di sicurezza”). Inoltre, se abilitiamo anche l’integrazione con un SIEM come Microsoft Sentinel, eventuali allarmi critici (es. tentativi di intrusione, esfiltrazione di dati) vengono inviati a Sentinel per consentire analisi e risposta centralizzate. In parallelo, per l’accesso degli utenti, l’azienda implementa MFA obbligatoria per tutti gli account con privilegi elevati e definisce policy di Conditional Access per limitare, ad esempio, l’accesso al portale Azure solo da reti aziendali o dispositivi conformi. Con queste configurazioni, l’ambiente Azure dell’azienda è protetto su più livelli: configurazioni sicure di base, monitoraggio continuo delle minacce e controlli di accesso stringenti.
Suggerimenti visivi: Per rappresentare la sicurezza in Azure si potrebbe utilizzare un cruscotto di sicurezza come immagine esplicativa. Ad esempio, un dashboard che mostri la Secure Score globale, il numero di raccomandazioni aperte vs risolte, e una panoramica grafica delle risorse coperte da Defender (magari una mappa dell’infrastruttura evidenziando quali risorse hanno allarmi di sicurezza). Un altro elemento grafico potrebbe essere uno schema di Zero Trust, con un flusso che parte dall’utente (a cui viene applicata MFA) e attraversa controlli di Conditional Access prima di arrivare alle risorse interne.
4. Reti in Azure – Connettività sicura e flessibile
Le funzionalità di networking in Azure permettono di costruire infrastrutture di rete complesse e sicure, analoghe a quelle on-premises, ma con la flessibilità tipica del cloud. Azure fornisce strumenti per segmentare il traffico, collegare ambienti differenti e gestire la rete su larga scala. Vediamo alcuni aspetti chiave del networking Azure.
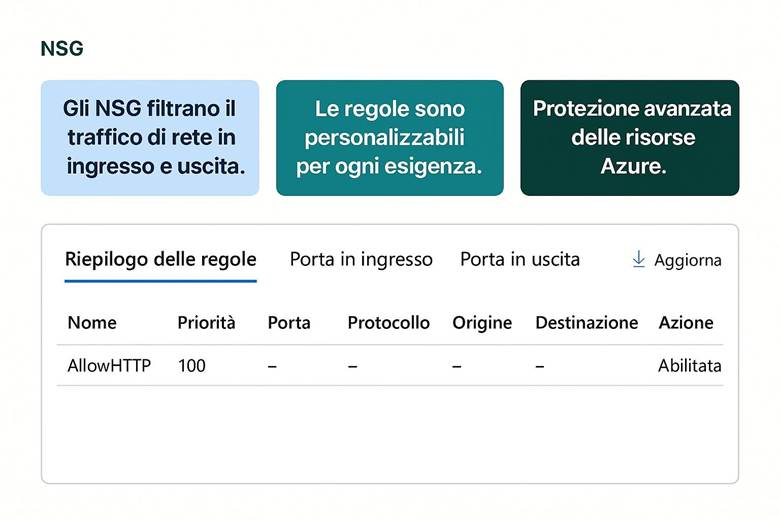
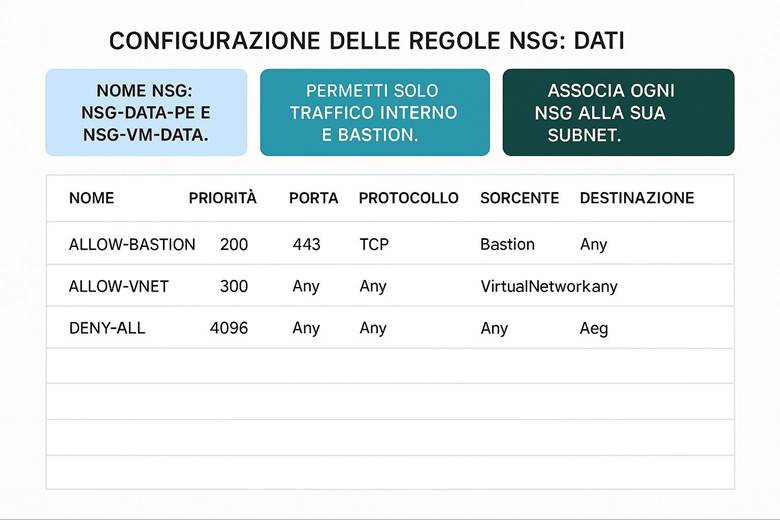
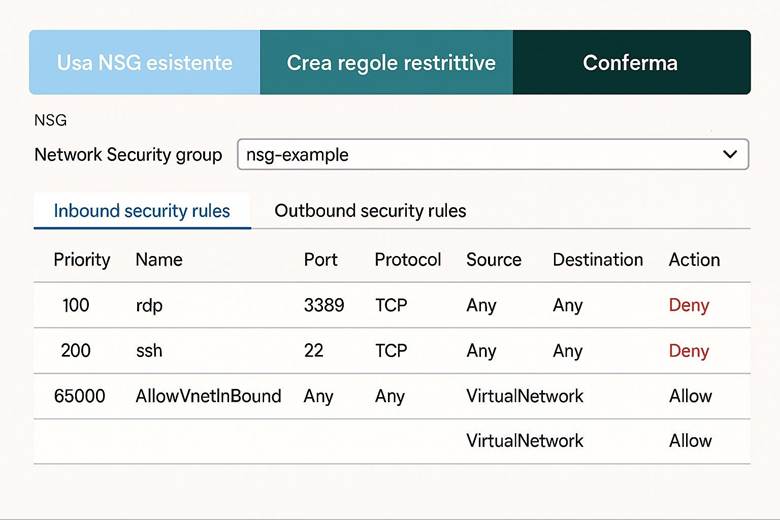
Virtual Network e segmentazione: Come accennato in precedenza, Azure Virtual Network (VNet) consente di creare reti private in Azure in cui posizionare le risorse. All’interno di una VNet, suddividere la rete in subnet aiuta a isolare i diversi livelli applicativi – ad esempio una subnet per i server web, una per i server applicativi e una per i database. A ciascuna subnet si possono associare NSG (Network Security Group) che agiscono come firewall sulle porte e sugli IP: ad esempio, un NSG può permettere accesso HTTP/HTTPS solo alla subnet web e bloccare qualsiasi traffico non autorizzato verso il database. Per controllare il routing del traffico, Azure consente anche route definite dall’utente (UDR), utili ad esempio per instradare il traffico attraverso appliance di rete come firewall di terze parti. Infine, tramite Private Link, si possono mappare servizi PaaS (come Azure SQL, Storage, ecc.) all’interno della VNet, ottenendo punti di accesso privati nel network e impedendo l’esposizione tramite IP pubblici. Tutto ciò permette di costruire architetture a più livelli con una segmentazione granulare della rete, migliorando sia la sicurezza sia la gestione del traffico. (Fonti: Panoramica di Azure Networking, Panoramica di Virtual Network)
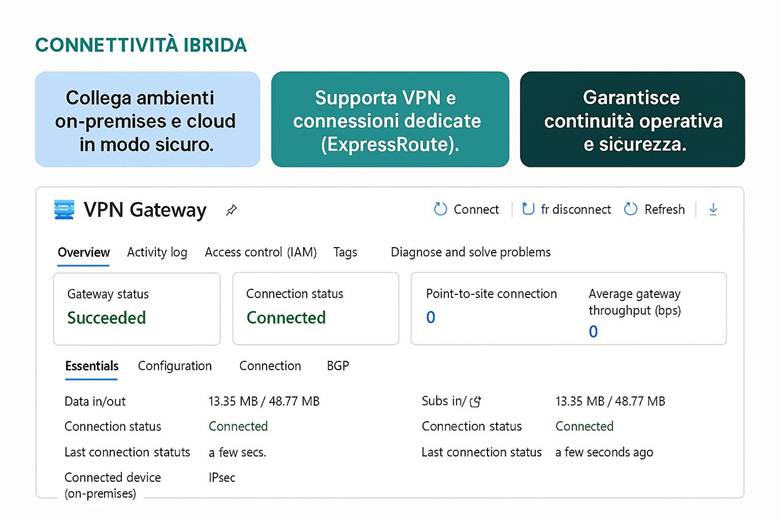
Connettività ibrida e interconnessione: Molte organizzazioni necessitano di collegare l’ambiente Azure con ambienti esterni, come data center aziendali o altre cloud. Azure supporta questo con due principali soluzioni: VPN Gateway e Azure ExpressRoute. Il VPN Gateway crea un tunnel crittografato (IPsec) attraverso Internet tra la VNet Azure e la rete on-premises, offrendo una connessione sicura ma con latenza variabile a seconda di Internet. L’ExpressRoute invece fornisce un circuito dedicato (fornito da un provider telecom) tra l’infrastruttura on-premises e Azure, garantendo una connessione privata ad alta velocità e bassa latenza, ideale per integrazioni strette e trasferimenti di dati ingenti. All’interno di Azure, è possibile collegare tra loro più Virtual Network tramite VNet Peering, anche se si trovano in region differenti, creando di fatto una rete interconnessa globale. Questo consente, ad esempio, a servizi in diverse region geografiche di comunicare tra loro su rete Azure privata senza passare da Internet. (Fonte: Azure Networking fundamentals)
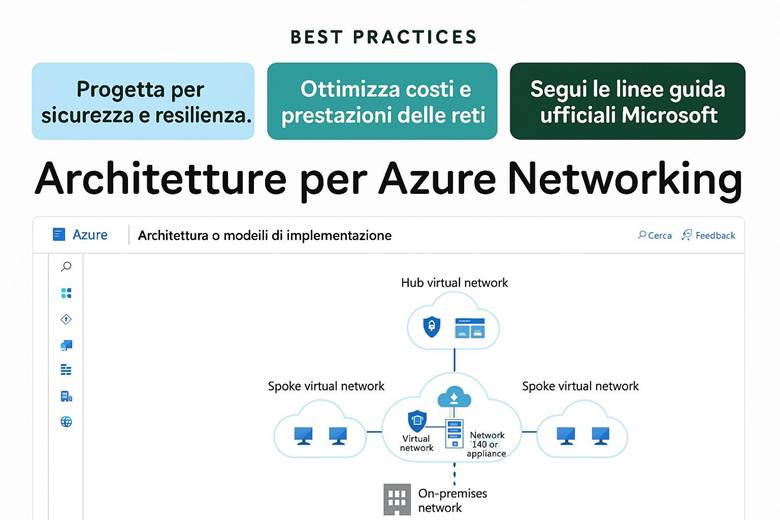
Gestione del networking su larga scala: Quando si hanno decine di VNet e configurazioni di rete ripetitive, Azure fornisce servizi per semplificarne la gestione centralizzata. Azure Virtual Network Manager è uno strumento che consente di applicare configurazioni e policy di rete a più VNet in modo orchestrato. Ad esempio, con Virtual Network Manager si può definire una topologia hub-and-spoke a livello aziendale: nominare una rete hub centrale (dove posizionare servizi comuni come firewall, servizi di gestione, o un gateway verso on-prem) e collegare ad essa varie reti spoke (che ospitano applicazioni isolate per team o dipartimenti). Si possono definire regole di sicurezza amministrativa (Security Admin Rules) applicabili globalmente (ad esempio, vietare completamente traffico RDP/SSH in ingresso su tutte le VNet spoke a prescindere dalle impostazioni locali di NSG). Inoltre il VNet Manager può gestire la connettività tra le spoke, permettendo o negando il traffico in base a criteri centrali. Questo approccio facilita la consistenza delle configurazioni di rete in ambienti complessi e multi-regione. (Fonte: Azure Virtual Network Manager – Panoramica)
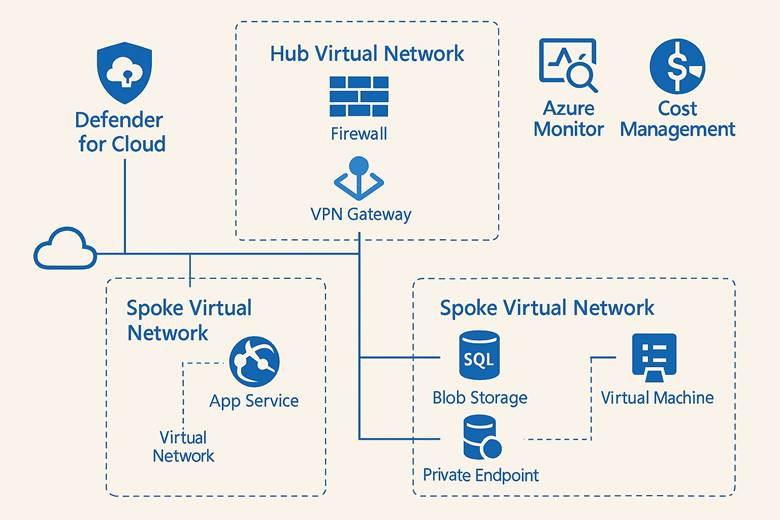
Esempio pratico: Un’architettura di rete cloud comune per una grande organizzazione è il modello hub-and-spoke. Si può implementare definendo una VNet di hub che contiene servizi condivisi come un Azure Firewall o Azure Front Door per la protezione perimetrale e l’esposizione di applicazioni web. Poi si creano più VNet di spoke, ad esempio una per l’applicazione finanziaria, una per il sistema di BI, ecc., ognuna isolata con le proprie subnet e NSG. Le spoke sono connesse all’hub tramite peering o tramite Virtual Network Manager, e l’hub è a sua volta collegato alla rete on-premises via VPN Gateway o ExpressRoute per consentire agli utenti aziendali di raggiungere i servizi cloud. Inoltre, dove necessario, sulle spoke si utilizzano Private Endpoints verso i servizi PaaS (ad esempio un database SQL gestito o un account Storage) per far sì che i dati viaggino solo all’interno della rete privata. Con questa configurazione, qualsiasi traffico tra on-premises e cloud o tra diverse spoke può essere controllato centralmente (passando dal firewall nell’hub), garantendo sia sicurezza sia ottimizzazione del routing.
Suggerimenti visivi: Una rappresentazione efficace per questo capitolo è un diagramma di rete che illustri la topologia hub-and-spoke. Nel diagramma l’hub centrale potrebbe essere evidenziato, collegato a diversi spoke, con simboli per il VPN Gateway e ExpressRoute che connettono l’hub all’esterno. Sulle connessioni potrebbero essere indicati i controlli di sicurezza (es. icona di firewall sull’hub, simboli di NSG sulle subnet delle spoke). Inoltre, si può evidenziare visivamente l’uso di Private Endpoint disegnando un servizio PaaS (es. un database) connesso a una subnet privata all’interno di una spoke, distinto da un ipotetico accesso via Internet (quest’ultimo sbarrato per indicare che non avviene). Questo aiuterebbe a capire come Azure permette una connettività ibrida e segmentata con controllo centralizzato.
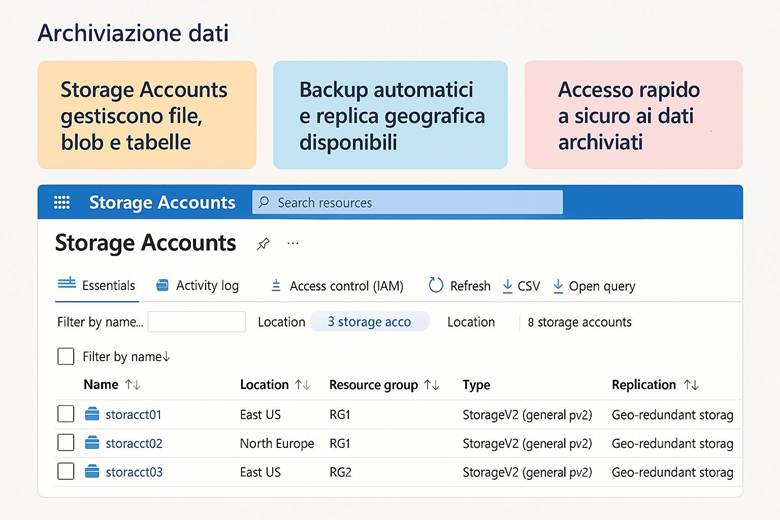
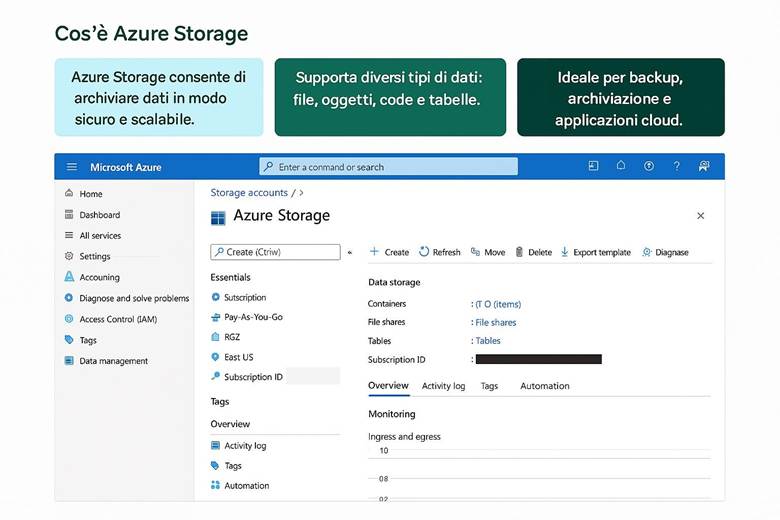
5. Archiviazione dei dati – Tipi di account e ridondanza
La piattaforma Azure offre diverse soluzioni per l’archiviazione dei dati, ciascuna ottimizzata per scenari specifici. Inoltre, Azure Storage consente di configurare vari livelli di ridondanza per garantire la disponibilità e durabilità dei dati anche in caso di guasti. In questo capitolo analizzeremo i principali servizi di archiviazione e le opzioni di resilienza offerte.
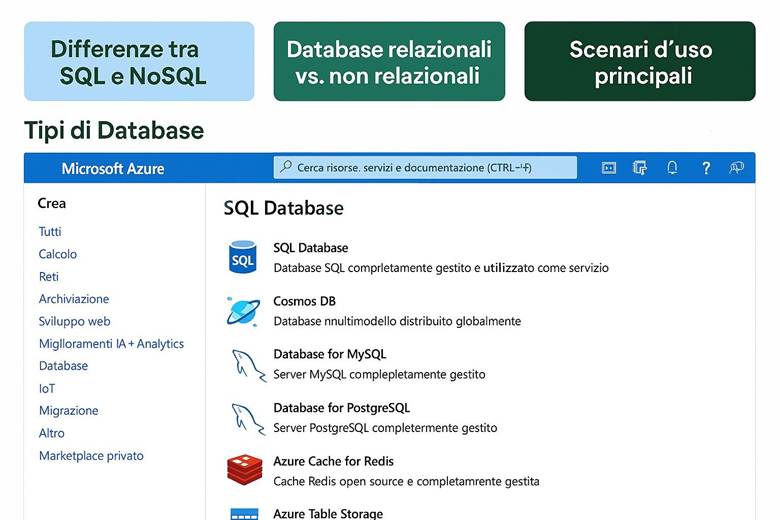
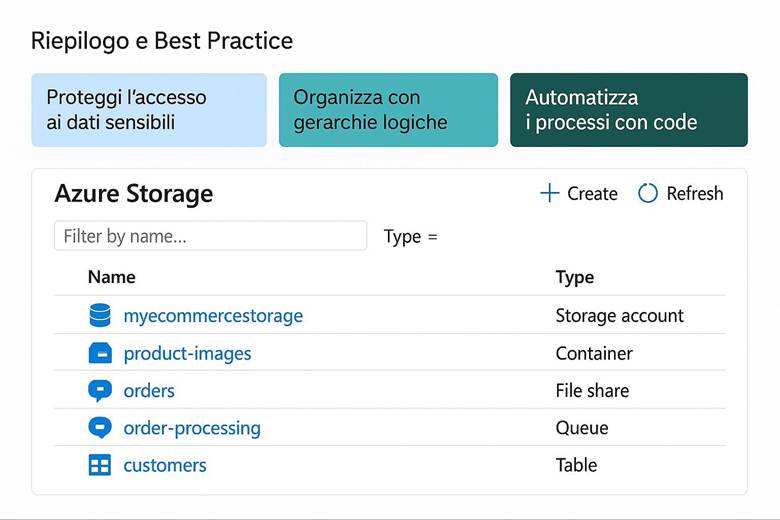
Servizi di archiviazione dati in Azure: Un singolo account di archiviazione Azure può contenere differenti tipi di dati. I servizi di archiviazione principali sono i seguenti:
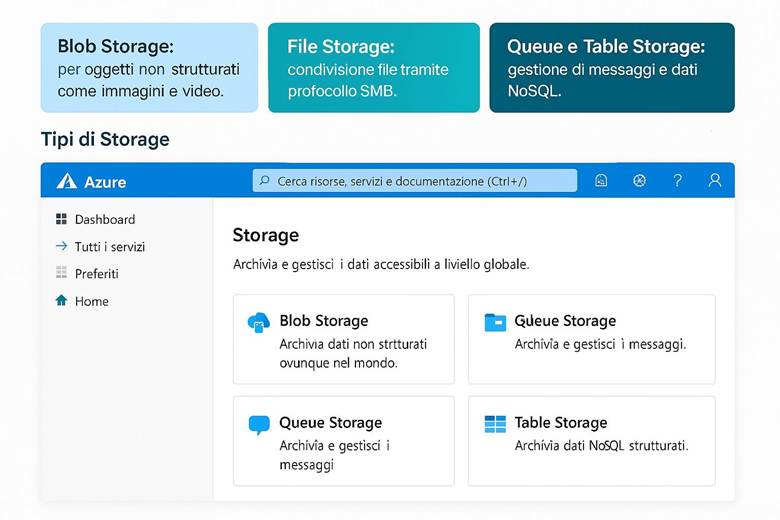
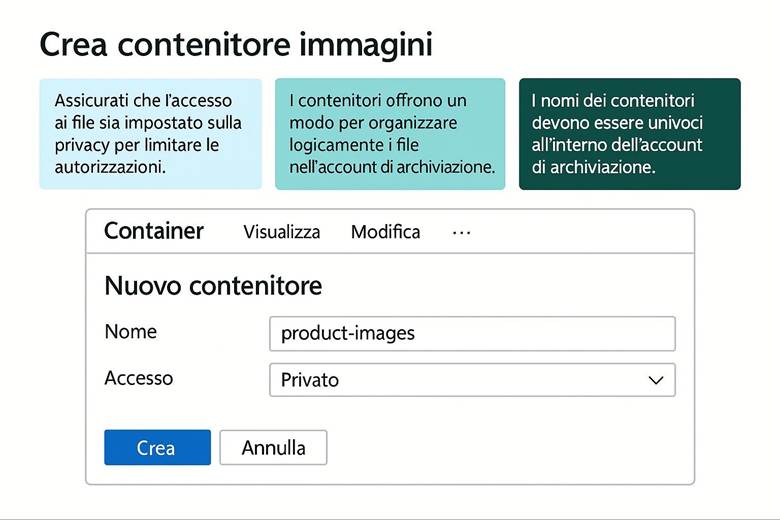
Blob Storage: Archivia oggetti non strutturati come documenti, immagini, video, backup o log. Fornisce storage scalabile a costi contenuti per una grande mole di dati accessibili via protocollo HTTP/HTTPS (ad esempio attraverso REST API). È ideale per contenuti statici di siti web, dati distribuiti tramite CDN, file di log e backup.
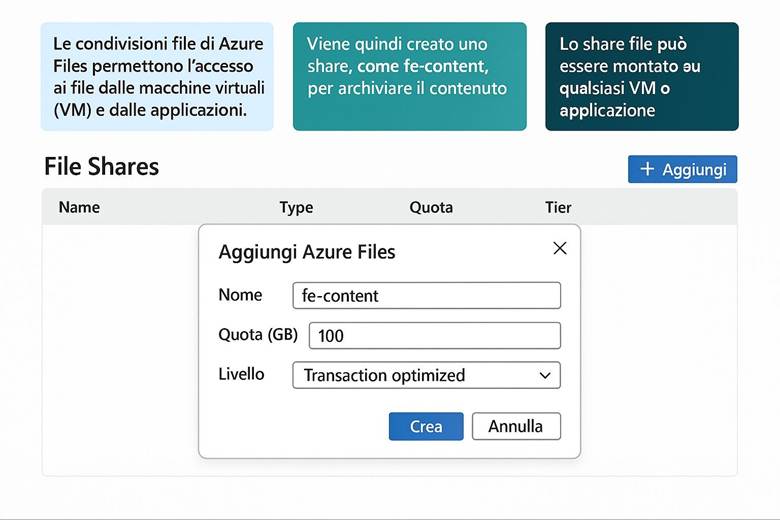
Azure Files: Offre condivisioni file accessibili tramite i protocolli SMB o NFS , rendendo possibile il lift-and-shift di applicazioni che utilizzano file system tradizionali. Si comporta come un file server gestito nel cloud, utile per condividere file tra VM o accedere a file da on-premises senza mantenere un file server locale.
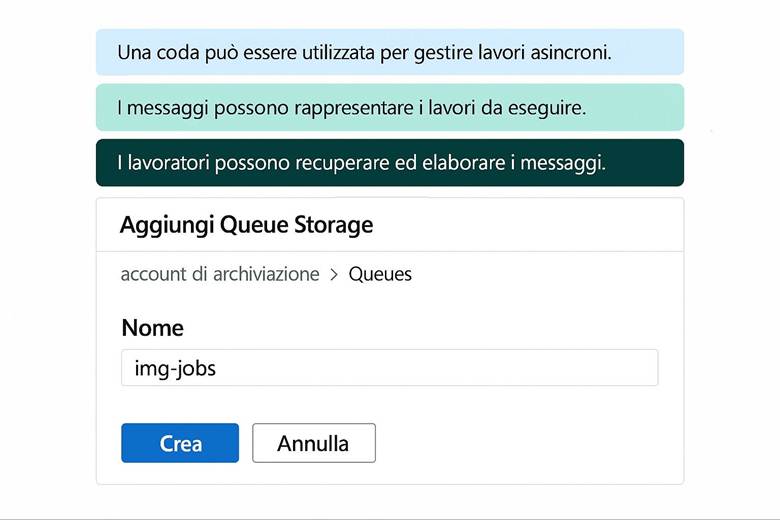
Queue Storage: Fornisce code di messaggi persistenti utilizzate per la comunicazione tra componenti applicative in modo asincrono. È spesso impiegato in architetture decoupled dove un servizio mette messaggi in coda e un altro li elabora in seguito, garantendo affidabilità nello scambio di task o eventi.
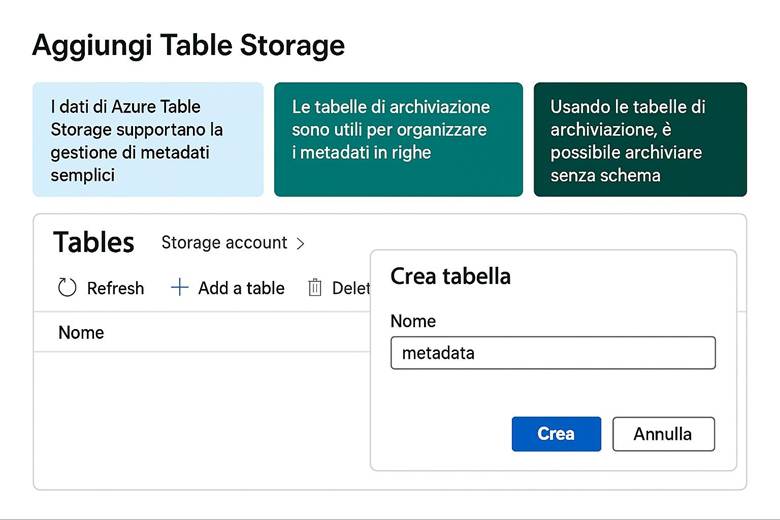
Table Storage Offre un archivio NoSQL a bassa latenza per dati strutturati in forma di tabelle, con un modello chiave/attributo. È adatto per conserve grandi volumi di dati semi-strutturati (ad es. log, dataset di IoT) quando non è richiesta la complessità di un database relazionale.
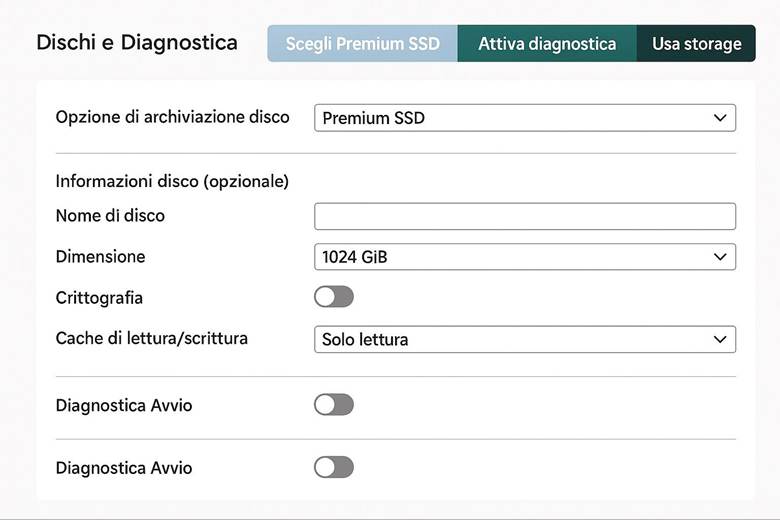
Managed Disks: Fornisce dischi gestiti per le Macchine Virtuali. Si tratta di volumi virtuali (HDD o SSD) che possono essere collegati alle VM Azure come dischi di sistema o aggiuntivi. Azure gestisce automaticamente la resilienza di questi dischi e ne semplifica la scalabilità, offrendo vari tipi (Standard HDD, Standard SSD, Premium SSD, Ultra SSD) per diverse necessità di performance.
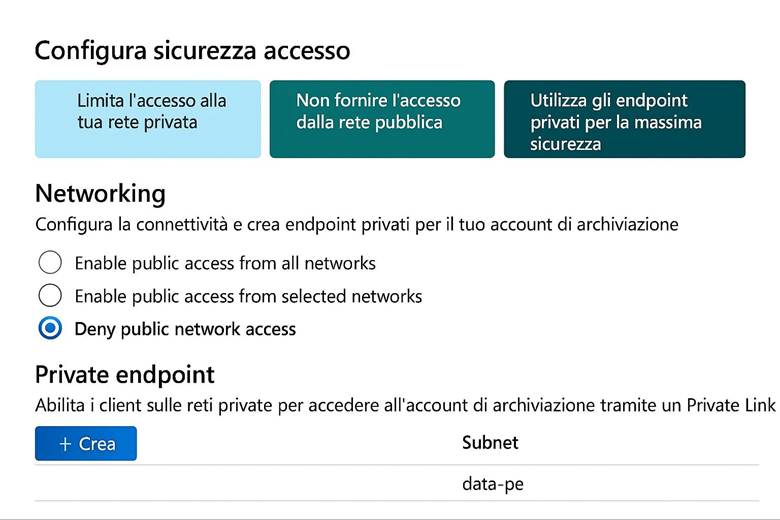
Nota: Tutti questi servizi di archiviazione beneficiano delle caratteristiche intrinseche di Azure Storage, come la cifratura automatica dei dati a riposo e l’integrazione con Microsoft Entra ID per il controllo degli accessi a livello di risorsa (ad esempio controlli di ACL sui file Azure Files, o SAS token e ruoli per l’accesso ai Blob). Inoltre, tramite la funzionalità di Private Endpoint, è possibile accedere a servizi come Blob Storage o Azure Files direttamente da una rete privata Azure (VNet) senza esporli su Internet, aumentando la sicurezza.
Tipi di account di archiviazione e prestazioni: I servizi elencati sopra risiedono in un account di archiviazione, e il tipo di account influenza alcune caratteristiche di performance e fatturazione. Gli account General Purpose v2 (GPv2) sono la scelta predefinita e supportano tutti i servizi (Blob, Files, Queue, Table, Disk) con una combinazione di costi e prestazioni adatta alla maggior parte degli scenari. Invece, gli account Premium sono progettati per scenari con requisiti di alta I/O e bassa latenza: essi utilizzano hardware SSD più performante e sono indicati ad esempio per carichi intensivi su file share o dischi di VM con elevato throughput e IOPS. Gli account Premium hanno costi più elevati e talvolta dimensioni massime inferiori, ma garantiscono prestazioni più costanti. È importante scegliere il tipo di account in base al workload: se dobbiamo supportare un sito di contenuti statici con picchi elevati di richieste, un account GPv2 con blob in hot tier potrebbe bastare; se invece abbiamo un database intensivo su disco, potrebbe servire un disco gestito Premium. (Fonte: Storage account overview)
Opzioni di ridondanza dei dati: Azure Storage offre diversi livelli di replica dei dati per proteggere dall’indisponibilità dovuta a guasti hardware o eventi catastrofici. Le opzioni disponibili, configurabili al momento della creazione dell’account (e modificabili successivamente in alcuni casi), sono:
LRS (Locally Redundant Storage): Replica locale (all’interno di un singolo data center o zona di disponibilità nella regione primaria). Mantiene 3 copie dei dati all’interno della stessa regione</i>. È l’opzione più economica, che protegge da guasti hardware locali (come il crash di un server o un rack) garantendo almeno 11 9’s di durabilità in un anno. Non protegge però da fail di intero data center o regione.
ZRS (Zone-Redundant Storage): Replica zonale (distribuita su più Availability Zone nella regione primaria). Mantiene 3 copie dei dati su data center/zones differenti all’interno della regione. Garantisce che anche se un’intera zona della regione diventa indisponibile (es. blackout in una zona), i dati rimangano accessibili tramite le copie in un’altra zona. Offre 12 9’s di durabilità annuale. Non copre i disastri regionali totali, ma riduce drasticamente il rischio di perdita in caso di problemi in un singolo edificio.
GZRS (Geo-Zone-Redundant Storage): Replica geografica con supporto zonale. Combina ZRS e replica geografica. Mantiene copie su più zone nella regione primaria e** in aggiunta effettua una replica asincrona in una **regione secondaria distante (nel paired region Azure). In totale i dati hanno 3 copie nella regione primaria e 1 (o più) copie nella regione secondaria. Protegge sia da guasti zonali sia dalla perdita dell’intera regione primaria, garantendo durabilità elevatissima (16 9’s). In caso di disastro che colpisce la regione primaria, i dati sono conservati nella regione secondaria (ma non immediatamente accessibili senza failover).
RA-GZRS (Read-Access GZRS): Replica geografica con accesso in lettura alla secondaria. Estende GZRS consentendo accesso in sola lettura alla replica nella regione secondaria in ogni momento. Ciò significa che, anche senza effettuare un failover, le applicazioni possono leggere</i> i dati dalla replica geografica se la regione primaria non è raggiungibile. È utile per scenari di alta disponibilità in lettura. (Analogamente esiste RA-GRS per la replica geo senza zones, ma GZRS ha di fatto sostituito GRS in molti scenari).
Scegliere la ridondanza: La scelta tra queste opzioni dipende dagli obiettivi di durabilità e disponibilità dell’applicazione. In generale, LRS è adatto per dati di cui esiste una copia di backup o che possono essere rigenerati facilmente; ZRS è indicato per applicazioni che richiedono alta disponibilità all’interno di una singola regione (es. sistemi critici dove la perdita di un data center non deve interrompere il servizio); GZRS/RA-GZRS vanno usati per assicurare continuità anche in caso di disastro regionale, ad esempio per dati mission-critical che devono sopravvivere anche a eventi estremi come terremoti o grandi blackout che colpiscano un’intera area geografica. (Fonte: Azure Storage redundancy options – Documentation)
Sicurezza e accesso ai dati: Oltre alla resilienza, Azure Storage offre vari meccanismi per proteggere l’accesso ai dati. Tutti i file e i blob sono cifrati automaticamente con chiavi gestite dal servizio (o con Customer-managed keys in Key Vault, se configurato). Per l’accesso, Azure consente di usare Azure AD/Entra ID per assegnare permessi granulari alle entità (ad esempio un ruolo predefinito “Storage Blob Data Reader” può permettere a un’applicazione di leggere solo i blob di un container). In alternativa o in aggiunta, sono disponibili strumenti come le SAS (Shared Access Signatures), token a tempo limitato che concedono diritti specifici su un oggetto (utile per dare accesso temporaneo a un cliente a un file, ad esempio). Infine, l’uso di reti private (VNet e firewall) garantisce che solo fonti autorizzate possano comunicare con l’account di storage, riducendo la superficie di attacco. (Approfondimenti: Azure Storage security guide – Microsoft Docs)
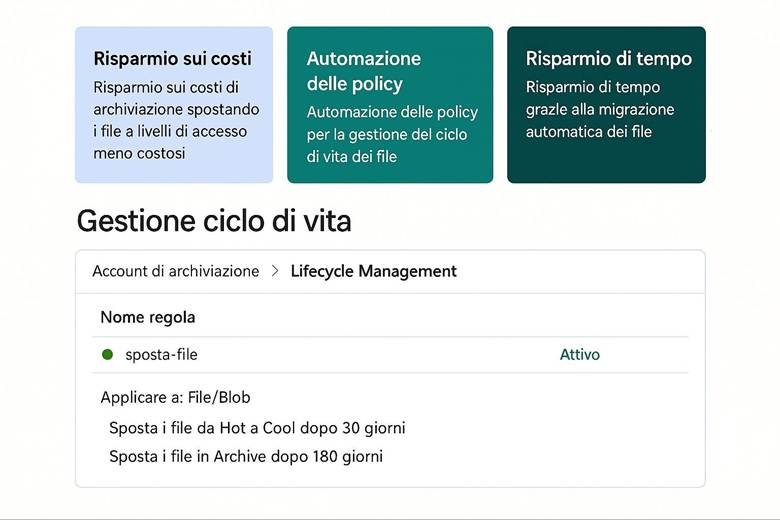
Esempio pratico: Immaginiamo di dover progettare un repository centralizzato per contenere le immagini dei prodotti di un sito di e-commerce, con requisiti di alta disponibilità e distribuzione globale. Potremmo creare un Storage Account GPv2 configurato con RA-GZRS in modo che ogni immagine caricata sia replicata sia in zona locale sia in una seconda regione geografica per sicurezza. Impostiamo inoltre una Azure Storage lifecycle policy per spostare automaticamente le immagini meno recenti su tier di accesso più freddi (ad es. da Hot a Cool e infine ad Archive) così da ridurre i costi di storage a lungo termine man mano che le immagini invecchiano e vengono consultate raramente. Per distribuire queste immagini agli utenti finali sparsi globalmente con latenze ridotte, potremmo sfruttare un CDN (Content Delivery Network) o Azure Front Door, che mette in cache il contenuto nelle POP server vicine ai clienti. In sintesi, con poche configurazioni abbiamo uno storage duraturo (grazie a RA-GZRS), efficiente in termini di costi (tiering automatico) e performante per gli utenti finali (tramite CDN).
Suggerimenti visivi: Per questo capitolo si prestano bene due rappresentazioni: (1) una tabella comparativa delle tipologie di storage (Blob, Files, etc.) con righe “caratteristiche” (ad esempio: tipo di dati, protocollo di accesso, scenari d’uso, prestazioni, limiti) per evidenziare le differenze e aiutare nella scelta del servizio giusto; (2) uno schema della ridondanza geografica: ad esempio una mappa stilizzata con due region Azure collegate, dove nella regione primaria i dati sono replicati su 3 zone (indicando LRS/ZRS) e poi replicati verso la regione secondaria. Accanto, icone di un occhio sbarrato vs aperto potrebbero indicare la differenza tra GZRS (replica ma senza accesso diretto) e RA-GZRS (replica con accesso in lettura nella secondaria). Questo aiuterebbe a visualizzare concretamente cosa succede ai dati in ognuna delle opzioni di ridondanza.
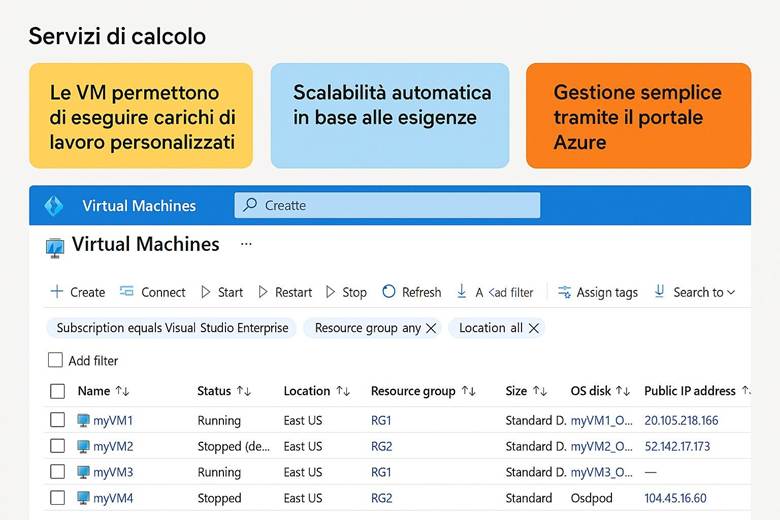
6. Servizi di calcolo – le Macchine Virtuali (VM) in dettaglio
Nel panorama dei servizi di Compute di Azure, le Virtual Machines occupano un ruolo centrale poiché offrono massima flessibilità e controllo. In questo capitolo approfondiremo quando e come utilizzare le VM, come garantirne disponibilità e prestazioni, e come gestirne i costi.
Quando usare le VM: Le macchine virtuali in Azure sono particolarmente indicate in quei scenari dove è necessario avere pieno controllo sull’ambiente operativo, oppure per esigenze di compatibilità con software specifici. Ad esempio, se si ha un’applicazione legacy che deve girare su un certo sistema operativo (Windows Server, Linux particolare) o con driver speciali, una VM permette di installare e configurare tutto come in un server fisico. Anche quando si necessita di configurazioni di rete o di storage molto particolari (ad esempio usando file system specifici, o connettendo interfacce di rete multiple in un modo personalizzato), le VM forniscono la flessibilità necessaria. In generale, uno Use case tipico per le VM è il lift-and-shift di workload esistenti dall’on-premises al cloud, senza doverli riprogettare: basta creare VM simili ai server originari e si mantengono compatibilità e funzionalità. Va tenuto presente però che, rispetto a servizi PaaS gestiti (come App Service per le web app o Azure SQL per i database), le VM richiedono più oneri gestionali (patch del sistema operativo, configurazione backup, etc.). (Fonte: Panoramica Macchine Virtuali Azure)
Scelta del tipo di VM e alta disponibilità: Azure offre un catalogo ampio di SKU di VM, raggruppate in serie caratterizzate da diverse risorse di calcolo. Ad esempio, la serie Dv3/Dv4 è bilanciata per usi generici, la serie Ev3/Ev4 ha memoria maggiorata per database o analytics in-memory, la F privilegia il numero di core CPU per calcoli intensivi, mentre le serie N includono GPU per machine learning o visualizzazioni 3D. Quando si crea una VM si deve scegliere dimensione (es. D2s_v3, E4s_v4, etc.) tenendo conto di vCPU, RAM, throughput disco e caratteristiche necessarie. Per garantire alta disponibilità, Azure consente distribuzione su Availability Options come Availability Set o Availability Zone. Con un Availability Set, multiple VM (ad esempio due VM che fanno parte di un cluster) vengono collocate in fault domain diversi all’interno dello stesso data center, in modo che la manutenzione o un guasto hardware non le colpisca entrambe contemporaneamente. Con le Availability Zone, invece, le VM replicate vengono posizionate in data center fisicamente separati (zone diverse) all’interno della stessa regione, aumentando ulteriormente la resilienza. Inoltre, per scenari di scalabilità automatica, le Virtual Machine Scale Sets permettono di gestire un insieme di VM identiche che possono aumentare o diminuire di numero secondo la domanda (ad esempio, aggiungendo VM quando il carico CPU medio supera un certo threshold). La scelta occulata della famiglia di VM e della strategia di disponibilità è fondamentale per bilanciare costi e SLA del servizio. (Fonti: Documentazione VM (Azure), Azure Architecture Center – VM best practices)
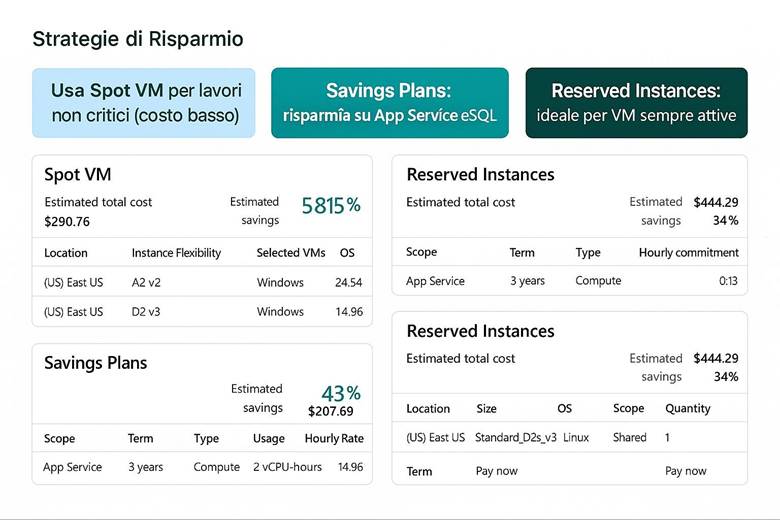
Ottimizzazione dei costi delle VM: Poiché le VM possono rappresentare una voce di spesa significativa in ambiente cloud, Azure fornisce diversi meccanismi per ottimizzarne il costo. Uno dei principali è l’uso di Reserved Instances (RI): si tratta di prenotazioni di capacità di VM per 1 o 3 anni, che in cambio di un impegno di utilizzo offrono sconti notevoli (fino al 70-80% rispetto al pay-as-you-go). Le RI sono convenienti per workload stabili e di lungo periodo (es. un server di produzione sempre acceso). In alternativa, i Savings Plan offrono flessibilità su famiglia e regione di VM, applicando sconti orari in modo più elastico a fronte di un impegno di spesa. Per workload non critici e interrompibili, esistono le Spot VM, che utilizzano capacità inutilizzata di Azure a tariffe fortemente scontate (ma Azure può deallocarle quando ha bisogno di risorse per altri). Le Spot VM sono ideali per job batch, test, o scenari dove un’interruzione non causa problemi seri. Oltre a questi, Azure Advisor nel suo modulo Cost fornisce raccomandazioni, ad esempio segnalando VM con utilizzo CPU molto basso che potrebbero essere ridimensionate (principio del right-sizing), o suggerendo di applicare Azure Hybrid Benefit per risparmiare sui costi di licenza se si hanno già licenze Windows Server o SQL Server attive on-prem. Infine, un semplice accorgimento: arrestare le VM non in uso (soprattutto ambienti di test/dev fuori dall’orario di lavoro) per non pagarne il consumo quando non servono. (Fonte: Azure Cost Management & Billing)
Esempio pratico: Un’azienda che offre servizi di progettazione CAD decide di spostare in Azure il suo ambiente di rendering 3D per sfruttare la scalabilità del cloud. Per questi carichi sceglie VM della serie NVads v5, dotate di GPU ad alte prestazioni, in modo da fornire la potenza grafica necessaria. Ogni VM è associata a dischi gestiti Premium SSD v2 (per assicurare velocità di lettura/scrittura elevate sui dati di progetto) e viene inserita in una rete dedicata con Azure Bastion abilitato, così che i designer possano connettersi alle VM tramite desktop remoto in modo sicuro, senza esporre porte RDP pubblicamente. Per tenere sotto controllo lo stato delle VM, l’azienda abilita Azure Monitor con la soluzione VM Insights, ricavando metriche dettagliate su CPU, memoria e utilizzo GPU, e configura log analytics per tracciare gli eventi di sistema. In base ai dati raccolti, potrebbero impostare alert (ad esempio per notificarli se una sessione di rendering supera un certo tempo o se l’utilizzo della GPU è al 100% per troppo a lungo) e valutare se aggiungere un’altra NVads v5 in un Scale Set per bilanciare il carico. Questo scenario evidenzia come le VM Azure possano soddisfare requisiti molto specifici (GPU, rete sicura, telemetria dettagliata) con un controllo end-to-end da parte dell’azienda, ma richiede parallelamente attenzione nella gestione (monitoraggio continuo e ottimizzazione della spesa, es. usando macchine spot per i job meno urgenti).
Suggerimenti visivi: Un possibile diagramma per questo capitolo potrebbe mostrare un’architettura di deployment tipica con VM. Ad esempio, un disegno con un Load Balancer pubblico che distribuisce traffico su un set di VM in una Availability Zone, con dietro un Azure Scale Set per indicare la possibilità di scalare. Nel diagramma potrebbero comparire anche servizi complementari: un’icona di Azure Key Vault collegata alle VM per la gestione dei segreti (come password o certificati), e un simbolo di Storage che rappresenti i dischi gestiti collegati alle VM (magari distinguendo Premium vs Standard). In aggiunta, si potrebbe mostrare un piccolo riquadro con l’indicazione “Savings: RI/Savings Plan” e “Spot VM” per ricordare i metodi di ottimizzazione dei costi, oppure un grafico a confronto del costo orario pay-as-you-go vs reserved vs spot. Questi elementi aiuterebbero a riassumere visivamente sia l’architettura tecnica che le strategie finanziarie legate alle VM.
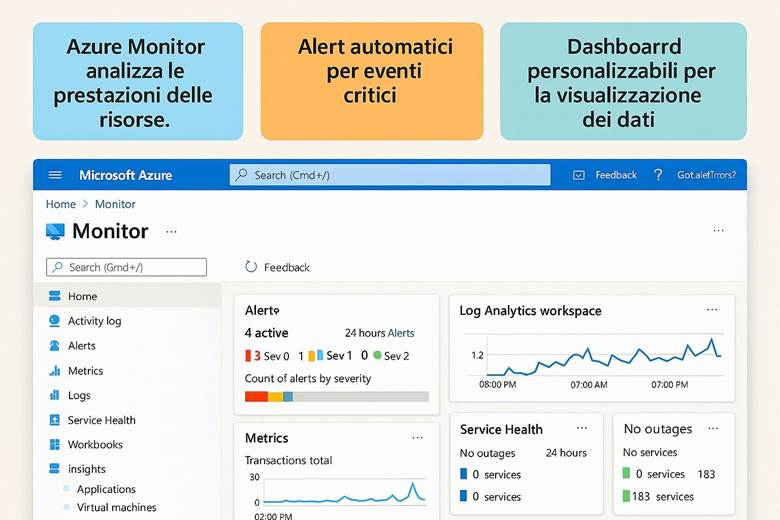
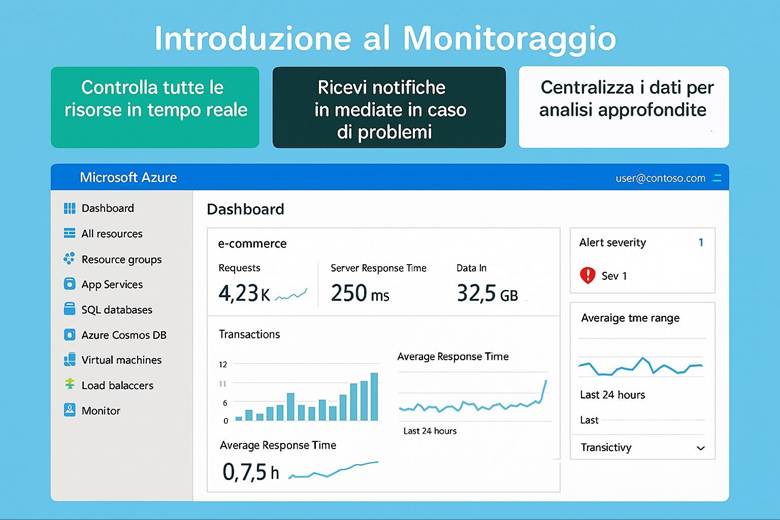
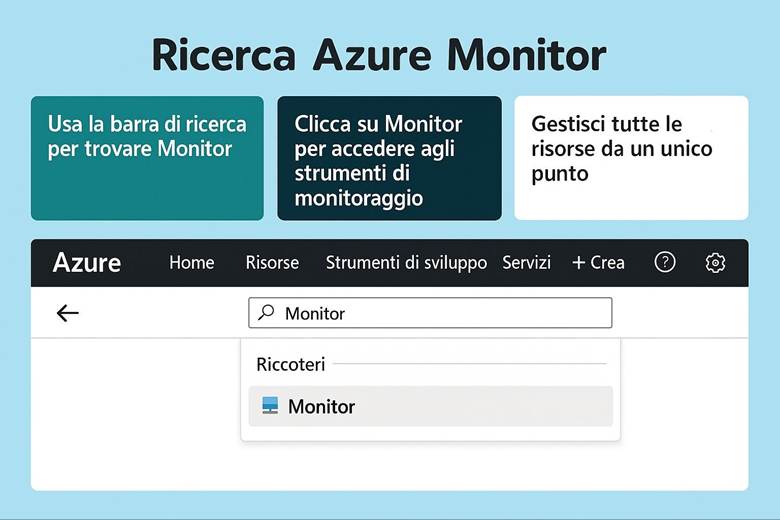
7. Monitoraggio e Osservabilità con Azure Monitor
Quando si gestiscono applicazioni e infrastrutture in Azure (o in generale nel cloud), è fondamentale avere visibilità sul loro funzionamento. Azure Monitor è il servizio integrato che fornisce funzionalità di monitoraggio e osservabilità end-to-end sulle risorse Azure, risorse on-premises estese al cloud e persino su altre piattaforme cloud. In questo capitolo approfondiremo cosa offre Azure Monitor e come aiuta a mantenere sotto controllo l’ambiente.
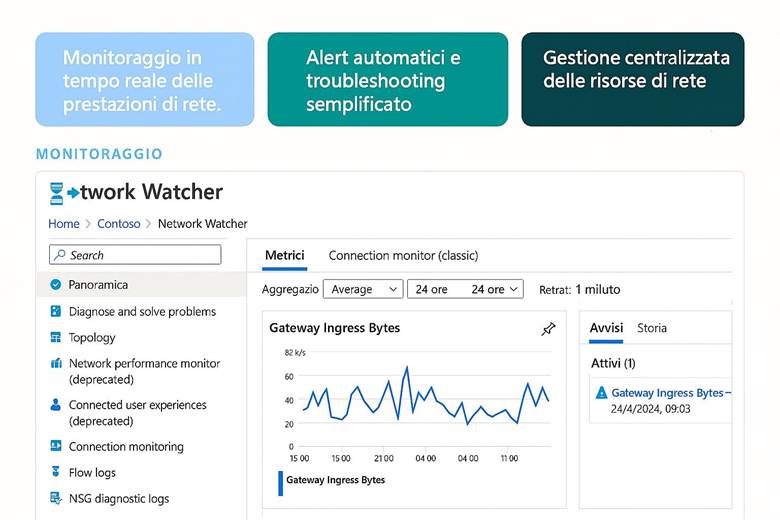
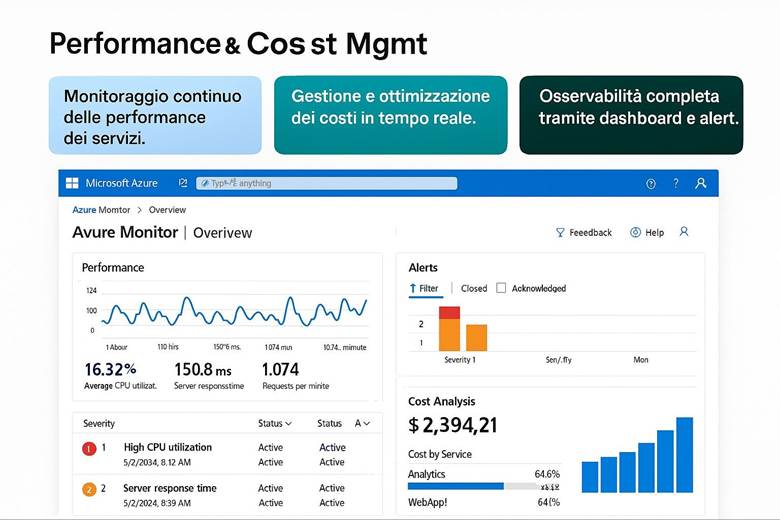
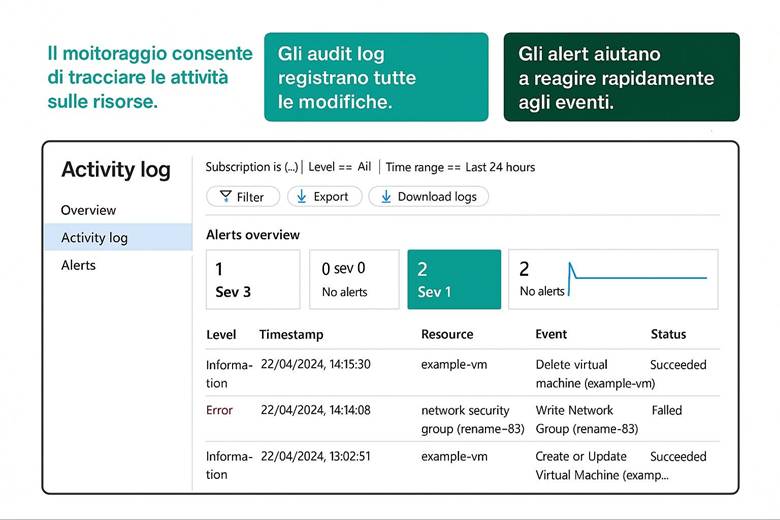
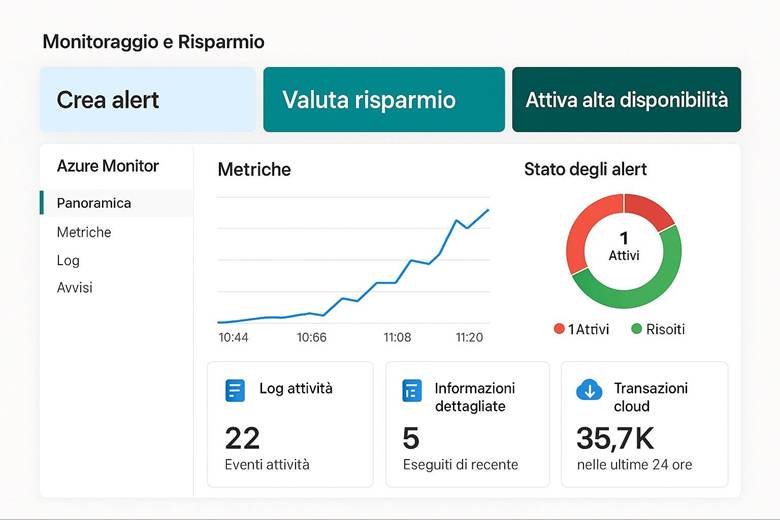
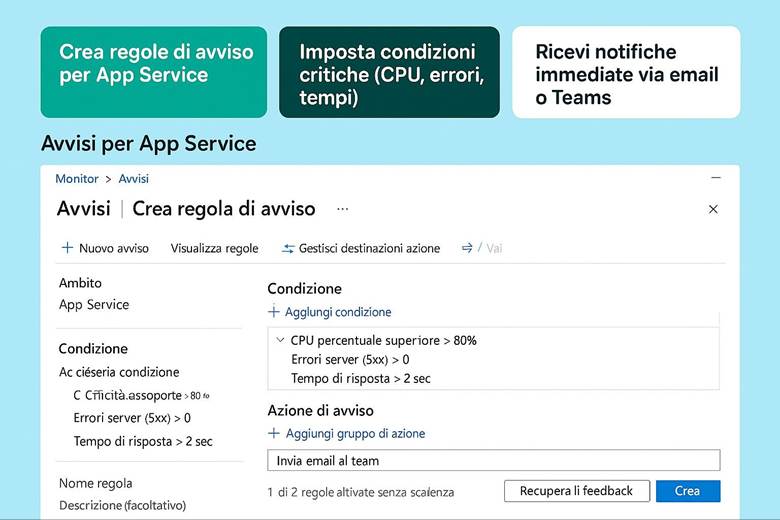
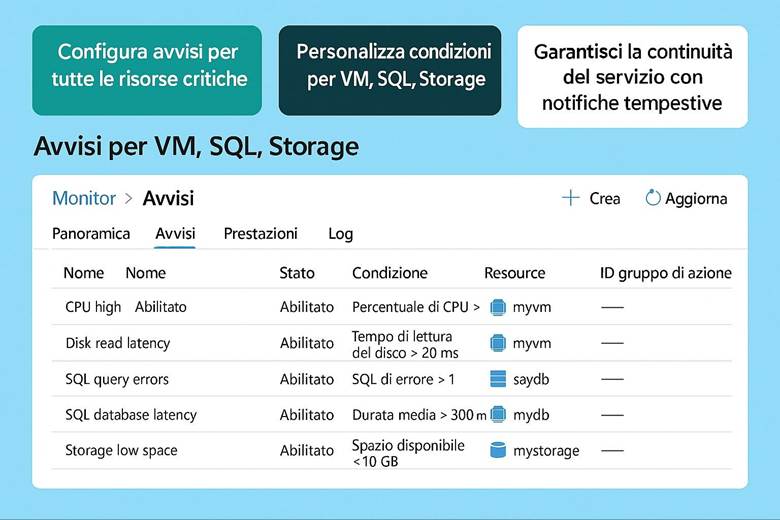
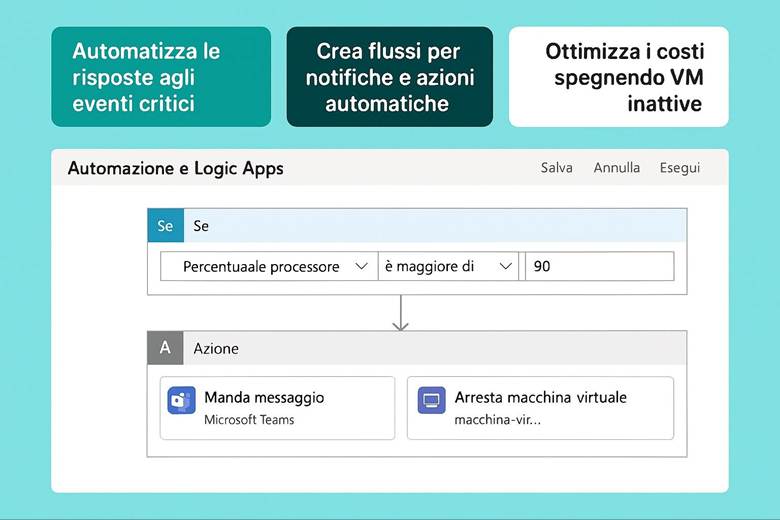
Cos’è Azure Monitor e cosa fa: Azure Monitor raccoglie e centralizza metriche, log e tracce dalle risorse e applicazioni. Le metriche sono valori numerici a intervalli regolari (per esempio CPU utilizzata di una VM, numero di richieste a un’app web al secondo, percentuale di utilizzo di un disco, ecc.), utili per capire le prestazioni in tempo quasi reale. I log sono dati testuali o semi-strutturati che descrivono eventi (ad esempio log di attività di Azure, log di applicazione, eventi di sistema delle VM, ecc.), adatti per analisi dettagliate, auditing e diagnostica. Le traces (tracce) si riferiscono spesso a informazioni di transito di applicazioni, utili soprattutto in contesti di debug o APM (Application Performance Management). Azure Monitor non solo raccoglie questi dati, ma offre strumenti per visualizzarli e agire su di essi: si possono creare dashboard personalizzati e workbook interattivi per rappresentare graficamente l’andamento delle metriche e correlare dati; si possono impostare regole di alert che inviano notifiche o attivano azioni automatiche quando certi valori superano soglie (ad esempio, un alert su “CPU > 80% per più di 5 minuti”); e si integrano servizi come Autoscale (che utilizza metriche di monitor per scalare risorse automaticamente) o Logic Apps/Automation per reagire a eventi specifici. Azure Monitor funge insomma da “occhi e orecchie” dell’operatore cloud, consentendo un approccio proattivo alla gestione: invece di scoprire i problemi dai disservizi, si ricevono avvisi e si osservano trend per intervenire in anticipo. (Fonti: Azure Monitor overview, Data platform – the 3 pillars)
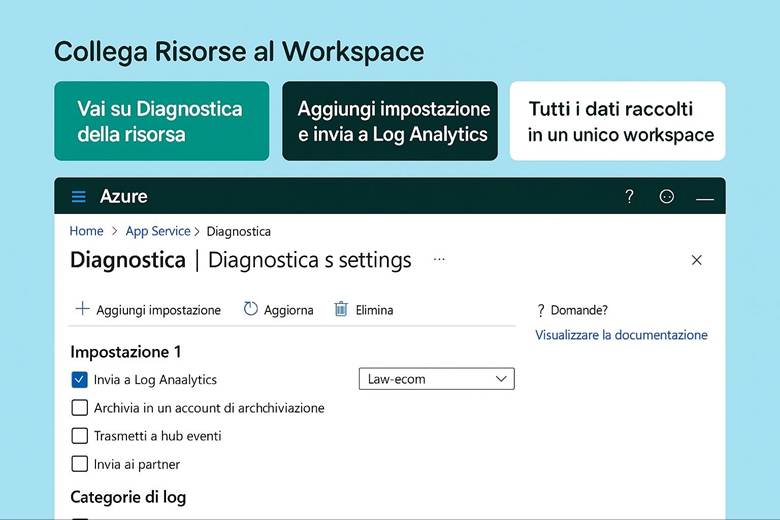
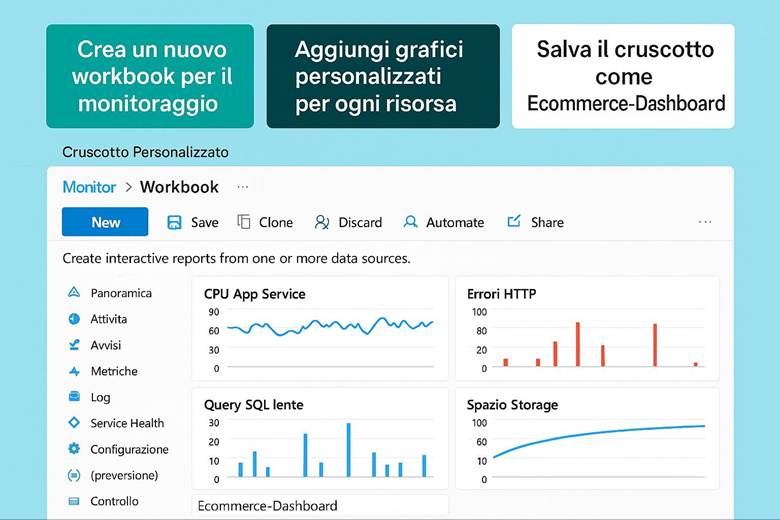
Insights e monitoraggio specializzato: Azure Monitor fornisce delle soluzioni pronte all’uso chiamate Insights per servizi specifici. Ad esempio, VM Insights offre viste specifiche per monitorare macchine virtuali (mostrando immediatamente CPU, memoria, consumo di disco e rete, e identificando le top process che consumano risorse in una VM). Container Insights fa lo stesso per orchestratori come Kubernetes (AKS), dando visibilità su cluster, nodi e performance dei container. Azure Monitor for Networks fornisce mappe e stato di connessione per resource di rete (VPN, ExpressRoute, ecc.). Esistono anche Application Insights, integrata in Azure Monitor, che è una soluzione APM per applicazioni custom: permette di tracciare richieste end-to-end, eccezioni applicative, e analizzare la user experience (ad esempio tempi di caricamento di pagine web, percentuali di errori HTTP). Queste soluzioni insight semplificano il monitoraggio perché offrono dashboard predefiniti e logiche già pronte per l’analisi di quei particolari servizi, senza richiedere all’utente di costruire tutto manualmente. Naturalmente, Azure Monitor rimane estensibile e consente di scrivere query Kusto (KQL) sui log aggregati nel Log Analytics Workspace per fare analisi avanzate, correlare dati di diverse origini (es. log di applicazione con log di infrastruttura) e generare report personalizzati. (Fonte: Azure Monitor Insights overview)
Esempio pratico: Un team DevOps configura Azure Monitor per un’applicazione enterprise composta da più componenti: macchine virtuali, database SQL, e un’applicazione .NET ospitata su App Service. Per prima cosa, abilita Log Analytics Workspace e collega ad esso tutte le risorse – così i log di attività Azure, i log delle VM (tramite l’agente Diagnostics), e i log applicativi (tramite Application Insights per .NET) confluiscono in un unico archivio interrogabile. Quindi creano alcune Metric Alerts: ad esempio un alert critico se la CPU di una VM rimane sopra l’85% per più di 10 minuti o se la DTU (unità di utilizzo) del database SQL supera una certa soglia. Configurano gli alert in modo che inviino notifiche al team via email e Teams, e che eseguano anche una Azure Function che in caso di CPU alta riavvia un processo specifico sulla VM (azione automatica di auto-riparazione). Contestualmente, preparano un Azure Dashboard che mostra: un grafico in tempo reale delle CPU delle VM, un grafico delle latenze medie delle query SQL, e una tabella con eventuali errori applicativi estratti dai log (ad esempio errori 500 dell’app web). Infine, impostano un workbook per le review mensili di performance, includendo le metriche chiave di SLA (uptime, tempi di risposta medi, utilizzo risorse) e correlando i costi – così da vedere in un unico report come l’utilizzo di risorse impatta sulla spesa. Grazie a questa implementazione, il team riesce a individuare velocemente colli di bottiglia (ad esempio, dal dashboard notano che ogni lunedì mattina la CPU del DB va al 90% e hanno un picco di errori – segnale per ottimizzare una query lenta) e a reagire con prontezza agli incident (il sistema di alert li avvisa immediatamente se qualcosa va fuori soglia, garantendo interventi tempestivi e riducendo il downtime percepito).
Suggerimenti visivi: Una dashboard è l’elemento visivo per eccellenza nel monitoraggio. Per questo capitolo si potrebbe presentare un esempio di dashboard di Azure Monitor con vari riquadri: un grafico lineare mostrante l’andamento della CPU di alcune VM e la memoria utilizzata, accanto un grafico a barre della latenza media di un’applicazione web, sotto una tabella di errori recenti (codici di errore e conteggio) e un elenco degli alert attivi con indicazione di severità. Ogni riquadro avrebbe un titolo (es. “CPU Usage”, “Response Time”, “Error Log”, “Active Alerts”). In alternativa, una serie di piccoli screenshot stilizzati di workbook, Application Insights map (che mostra la mappa delle dipendenze di un’app) ecc., per evidenziare la ricchezza degli strumenti di visualizzazione offerti. Queste immagini aiuterebbero a fissare l’idea che Azure Monitor permette di vedere realmente cosa accade nel sistema tramite pannelli e grafici in tempo reale.
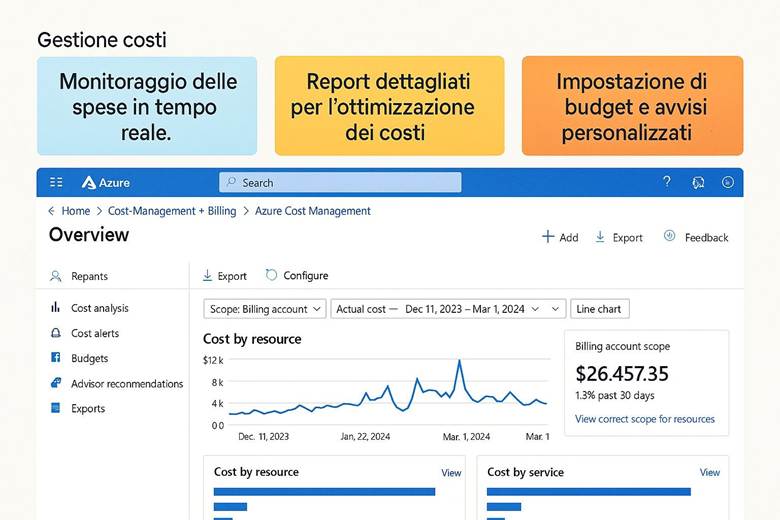
8. Gestione dei costi e Budgeting nel cloud Azure
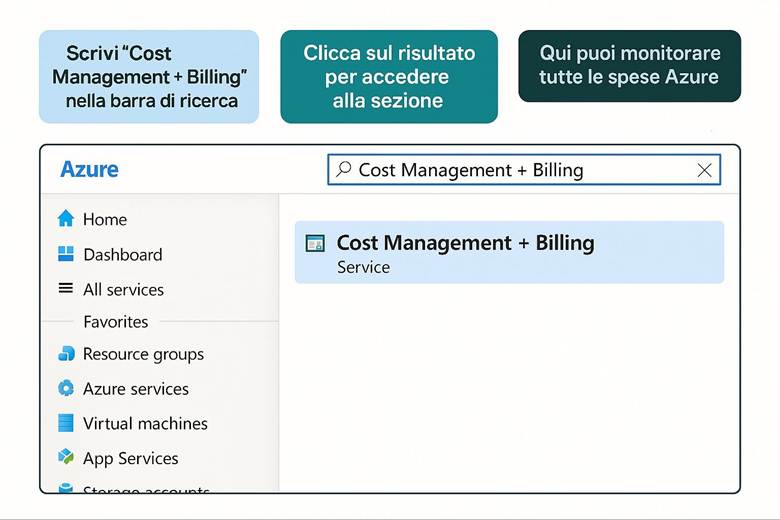
Uno dei vantaggi del cloud è il modello di costo flessibile, ma senza un adeguato controllo il rischio di superare il budget è concreto. Azure fornisce strumenti dedicati al Cost Management e al Billing (fatturazione) per aiutare gli utenti ad analizzare, monitorare e ottimizzare la spesa legata ai servizi cloud. In questo capitolo vedremo come tenere sotto controllo i costi in Azure e adottare pratiche per una gestione finanziaria efficiente.
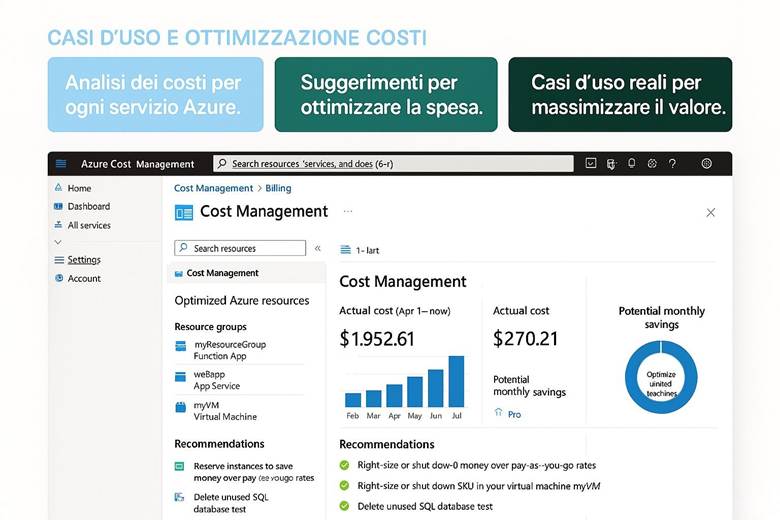
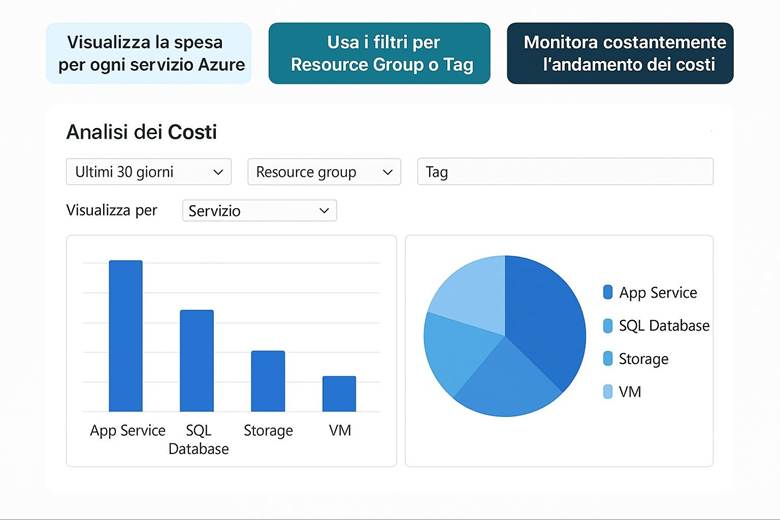
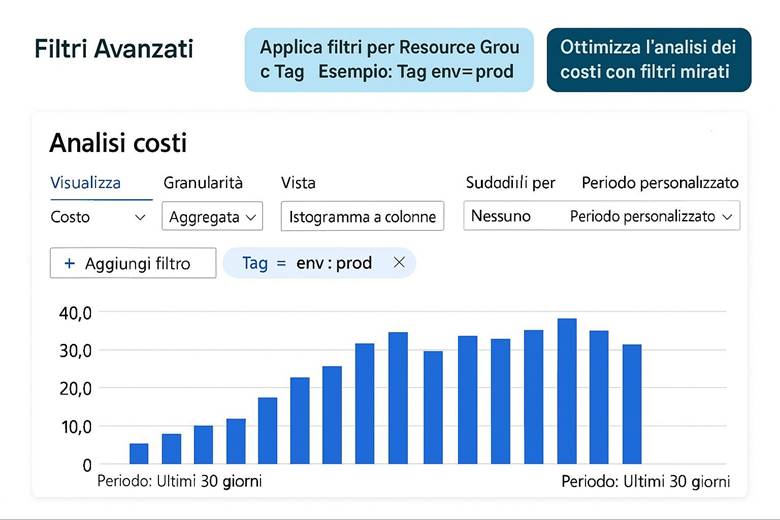
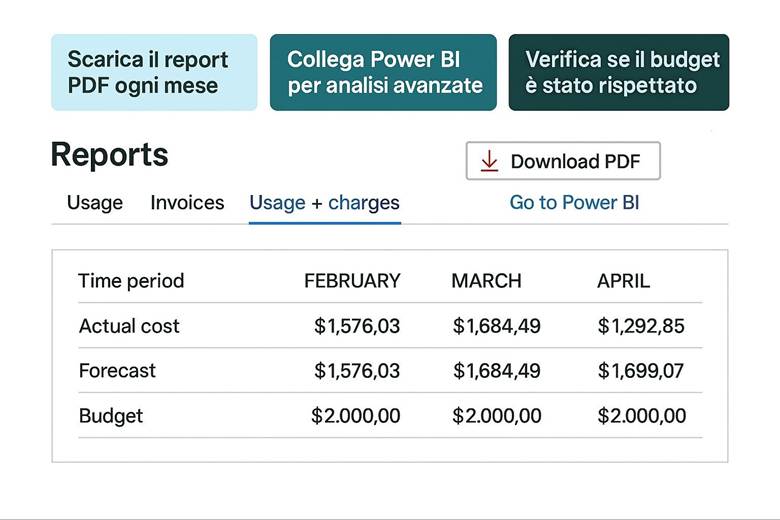
Azure Cost Management + Billing: Questo è il portale e insieme di servizi nativi per il controllo dei costi Azure. Tramite Cost Management è possibile visualizzare la spesa suddivisa per servizio, per risorsa o per gruppo di risorse, e filtrarla per periodi di tempo o per tag. Ad esempio, si può vedere quanto si è speso nell’ultimo mese in Macchine Virtuali, o quanto costa un certo progetto (se tutte le risorse di quel progetto condividono un tag identificativo). Una funzionalità chiave è la creazione di budget: si possono definire soglie di spesa (mensili, trimestrali, annuali) per la propria subscription o RG e ricevere alert quando si supera una certa percentuale di quel budget (ad esempio avviso al 80% e al 100% del budget mensile consumato). Cost Management offre anche viste di riportistica e forecast: proietta la spesa a fine periodo sulla base dell’andamento corrente, aiutando a capire se si rischia uno sforamento. Nella sezione Recommendations vengono inoltre evidenziate opportunità di ottimizzazione collegate ad Azure Advisor – ad esempio suggerisce di deallocare risorse sottoutilizzate o di acquistare riservations/savings plans per workload costanti. La parte Billing permette invece di gestire metodi di pagamento, fatture, e se si è in un contesto enterprise, di suddividere le spese tra diverse unità aziendali o ricevere fatturazione consolidata. (Fonti: Azure Cost Management and Billing docs, FinOps in Azure)
Pratiche consigliate di gestione costi: Per evitare brutte sorprese e assicurarsi che il cloud rimanga conveniente, si raccomanda di seguire alcune best practice:
· Definizione dello scope di analisi: organizza le risorse in modo che sia semplice attribuire i costi. L’uso di tag appropriati (ad esempio tag Department, Project, Environment) e di Resource Group dedicati per progetto/cliente facilita l’analisi granulare. Inoltre, sfrutta la suddivisione in subscription se hai bisogno di separare nettamente ambienti di costo (alcune aziende mettono progetti di clienti diversi in subscription diverse per isolare la rendicontazione).
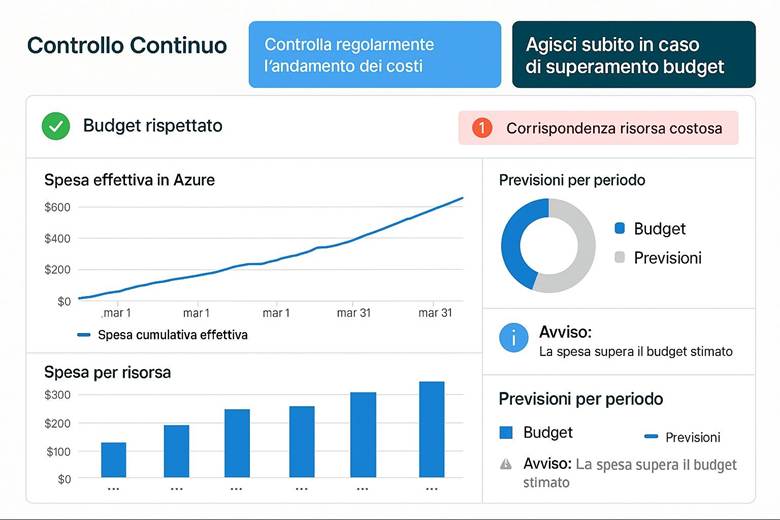
· Monitoraggio proattivo e alert finanziari: non aspettare la fattura a fine mese per accorgerti di anomalie. Imposta budget mensili per progetto e attiva gli alert. Azure può anche rilevare anomalie di costo (spike insoliti) e notificare se ad esempio in un giorno si spende molto più della media – questo è utile per individuare subito problemi, come una risorsa creata per errore che sta generando costi inaspettati.
· Ottimizzazione continua: esamina regolarmente le raccomandazioni di Azure Advisor e di Cost Management. Valuta di applicare Azure Hybrid Benefit se hai licenze Windows/SQL già possedute, così da usarle sulle VM e non pagarle di nuovo (porta risparmi significativi). Fai right-sizing delle risorse: se un database usa solo il 10% delle prestazioni di cui è capace, riduci la sua SKU; se una VM è costantemente sottoutilizzata, spostala a una taglia inferiore o valuta servizi PaaS. Pianifica anche gli orari: spegnere ambienti di sviluppo notturni e nei weekend può tagliare la spesa di un buon 20-30% annuale.
· Visibilità e accountability: condividi con i team i report di costo (magari con dashboard su SharePoint o esportando i dati verso Power BI). Assicurati che ogni team conosca il proprio consumo e responsabilizzali su obiettivi di efficienza. In contesti avanzati di FinOps, si tengono riunioni regolari per rivedere l’andamento dei costi e ottimizzare architetture in ottica cost-aware.
Esempio pratico: Una startup che gestisce una piattaforma SaaS in Azure decide di mettere sotto controllo i costi fin dall’inizio. Crea un budget mensile di, poniamo, 5.000€, e imposta avvisi: uno al raggiungimento dell’80% (4.000€) e uno al 100%. A metà mese riceve un alert dell’80% e questo porta il team a investigare: scoprono che un ambiente di test dimenticato acceso stava esaurendo il budget. Spengono le risorse di test e valutano l’uso di Auto-shutdown pianificato per quelle VM la sera. Inoltre, guardando i report, notano che la voce “Azure App Service” incide molto: approfondendo, vedono che sono attivi istanze in S2 tier per tutti i clienti, anche quelli piccoli. Decidono quindi di passare i clienti minori a un tier più economico S1, riducendo i costi senza impatto. A fine mese restano entro il budget e preparano un dashboard costi per il mese successivo, evidenziando le top 5 risorse per spesa, così da avere immediatamente sotto’occhio dove va la maggior parte del denaro. Inoltre attivano un rapporto programmato settimanale che viene inviato via email ai responsabili, così che non ci siano sorprese. Seguendo questo approccio, la startup adotta una mentalità di continua ottimizzazione: ogni mese investiga la voce di costo maggiore (es. trasferimenti di dati, istanze di database, etc.) e cerca soluzioni per ridurla, come ad esempio utilizzare Reserved Instances per i server sempre attivi (beneficiando di sconti sui loro database di produzione) o sfruttare servizi pass-through come Azure Advisor che suggerisce di eliminare una IP pubblica inutilizzata o di combinare diverse risorse su uno stesso piano tariffario. Queste azioni, sommate, portano risparmi che poi possono essere reinvestiti in nuove funzionalità.
Suggerimenti visivi: Per rappresentare la gestione dei costi, possiamo immaginare tre elementi grafici: (1) un grafico a linea che mostra l’andamento dei costi cumulativi nel mese rispetto al budget (magari con una linea orizzontale che indica il budget e la curva dei costi che si avvicina a quella linea, con un punto evidenziato al superamento di una soglia di alert); (2) una tabella “Budget vs Spesa” in cui si elencano vari budget (per progetto o reparto) affiancati dalla spesa corrente e dalla previsione a fine periodo, evidenziando in rosso quelli che sforeranno; (3) un riquadro con la lista delle raccomandazioni di Azure Advisor per il risparmio – ad esempio: “3 VM sottoutilizzate: potenziale risparmio 200€/mese”, “Abilitare Hybrid Benefit su 2 SQL Server: risparmio 150€/mese”. Questi elementi aiuterebbero a comunicare visivamente l’idea di doversi mantenere entro certi limiti e di avere opportunità concrete di ottimizzazione evidenziate dagli strumenti.
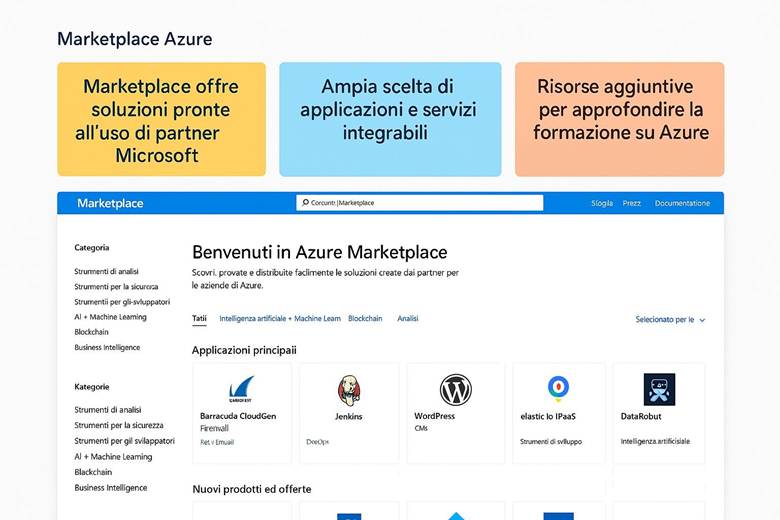
9. Azure Marketplace – Soluzioni pronte dei partner
L’Azure Marketplace è un portale integrato in Azure dove è possibile trovare soluzioni pronte all’uso fornite sia da Microsoft che da partner terzi. In altri termini, è un catalogo online di applicazioni e servizi certificati per essere eseguiti su Azure. In questo capitolo vedremo cos’è il Marketplace, perché può essere utile, e come viene tipicamente utilizzato.
Cos’è Azure Marketplace: Quando si accede al portale Azure e si sceglie “Create a resource”, si sta in effetti consultando l’Azure Marketplace. Questo marketplace include immagini di macchine virtuali preconfigurate, modelli di soluzioni complete (template ARM o soluzioni gestite), servizi SaaS di terze parti integrabili, e anche offerte di servizi professionali (consulenze, supporto) fornite da partner. Esiste anche una versione web pubblica del Marketplace (sito Microsoft) per esplorare le offerte disponibili. Le soluzioni sono categorizzate per tipo (ad esempio: Computing, Networking, Storage, AI + Machine Learning, Security, Databases, DevOps ecc.). Ogni elemento del Marketplace ha una scheda descrittiva con informazioni sul fornitore, sui costi (alcune sono gratuite, altre prevedono costi di licenza o utilizzo), e sulle procedure di installazione. Il Marketplace semplifica la distribuzione di software di terze parti su Azure: invece di dover creare manualmente una VM e installare un software, si può prendere un’immagine già pronta (per esempio un firewall di un certo vendor, o un software open source configurato) e avviarla in pochi clic. (Fonti: Azure Marketplace overview)
Perché usarlo: L’obiettivo del Marketplace è accelerare l’adozione di soluzioni nel cloud. Per le aziende, significa avere a disposizione un ecosistema di soluzioni testate e supportate: si possono trovare database popolari (MySQL, PostgreSQL) già configurati, appliance di sicurezza (come firewall, IPS/IDS) di vendor noti, applicazioni enterprise (SAP, Dynamics) pronte all’installazione, immagini di macchine con software di sviluppo, stack completi (es. LAMP) e molto altro. Usare il Marketplace può far risparmiare tempo perché elimina la necessità di re-inventare la ruota per configurare qualcosa di standard. Inoltre, la fatturazione di queste soluzioni è integrata nella bolletta Azure: se ad esempio si utilizza un firewall di terze parti a pagamento tramite Marketplace, i costi di licenza vengono addebitati sullo stesso account Azure, semplificando la gestione finanziaria. Anche gli aggiornamenti e la compatibilità sono garantiti dal fornitore attraverso il Marketplace, offrendo una maggiore tranquillità rispetto al fai-da-te. Per i partner ISV (Independent Software Vendors), il Marketplace è un canale per raggiungere i clienti Azure con le proprie soluzioni ottimizzate per il cloud.
Esempio pratico: Un team di sviluppo ha bisogno di un sistema di gestione dei contenuti (CMS) per lanciare rapidamente un sito web aziendale. Anziché creare una VM e installare manualmente un CMS open source, decidono di cercare sul Marketplace e trovano una immagine di WordPress ufficiale (offerta dalla community o da Microsoft). In pochi click, l’immagine viene distribuita come Web App con un database MySQL in Azure (o come VM Linux con tutto preinstallato), pronta all’uso. Questo accelera enormemente la messa online. In un altro scenario, un’azienda vuole adottare un’appliance di sicurezza di un partner (ad esempio un firewall Palo Alto Networks): tramite Marketplace può provisioningare il firewall virtuale già pronto all’uso su Azure e poi configurarlo con le regole necessarie. Ancora, si può pensare al caso di integrazione di servizi AI: se un partner offre un API di intelligenza artificiale come servizio, l’azienda può sottoscriverla via Marketplace e la spesa andrà sulla bolletta Azure, evitando contratti separati. Tutto questo evidenzia come il Marketplace aiuti a ridurre la complessità nella fase iniziale di avvio di soluzioni, permettendo di concentrarsi più sulla customizzazione e configurazione applicativa che sull’installazione base.
Suggerimenti visivi: Per rappresentare l’Azure Marketplace, si potrebbe realizzare una griglia di icone suddivise per categorie: ad esempio un riquadro con titolo Database contenente i loghi di MySQL, MongoDB, Cassandra; un riquadro Security con loghi di appliance firewall/popular security solutions; Analytics con icone di piattaforme di BI o big data; AI con icone di servizi cognitivi, e così via. Ogni icona potrebbe avere un piccolo badge Azure per indicare che è un’offerta sul marketplace. Un’altra idea è mostrare uno screenshot semplificato della pagina Marketplace con la barra di ricerca e qualche risultato (es: cercando “WordPress” appare la soluzione WordPress ufficiale). Infine, si potrebbe evidenziare il concetto di “Azure benefit”: alcune offerte Marketplace sono “Azure Benefit Eligible”, significa che se ad esempio si hanno crediti Azure o piani di supporto, certe soluzioni possono sfruttarli – un badge nelle icone potrebbe rappresentare questa caratteristica. Queste immagini aiuterebbero a capire la varietà di soluzioni disponibili e l’immediatezza con cui possono essere adottate attraverso la piattaforma Azure.
Conclusioni
In questa guida abbiamo esplorato una panoramica generale di Microsoft Azure, toccando i concetti fondamentali e i servizi principali organizzati per aree tematiche: calcolo, archiviazione, rete, gestione risorse, sicurezza, monitoraggio, cost management e soluzioni pronte. Azure si presenta come una piattaforma matura e ampia, in grado di supportare dai semplici prototipi fino alle architetture enterprise più complesse, il tutto con un modello operativo orientato al cloud che enfatizza flessibilità, scalabilità e pay-per-use.
Per chi si avvicina ad Azure con conoscenze di base o intermedie di cloud computing, è importante comprendere non solo i singoli servizi, ma anche come integrarli in soluzioni complete. Ad esempio, sapere che esistono VM, storage e database gestiti è utile, ma il vero valore si coglie nel combinarli in un’architettura coerente e nell’utilizzare strumenti come Resource Groups, Policy, Monitor per governarli efficacemente. Speriamo che i capitoli di questo eBook abbiano fornito un orientamento chiaro in tal senso, offrendo sia spiegazioni dettagliate sia esempi pratici e suggerimenti visivi per immaginare meglio l’applicazione reale.
Risorse consigliate per approfondire:
· Documentazione Ufficiale Microsoft Learn: il portale Microsoft Learn offre percorsi guidati e tutorial pratici su Azure. Ad esempio, potete trovare i tutorial introduttivi su Azure, i moduli interattivi per ciascun servizio e percorsi come Azure Fundamentals ideali per chi inizia.
· Azure Architecture Center: una raccolta di best practice, guide e reference architecture per progettare soluzioni Azure solide e ottimizzate. Utile per approfondire come costruire ambienti sicuri, performanti e resilienti.
· Microsoft Azure Blog: per rimanere aggiornati sulle ultime novità della piattaforma (nuovi servizi, aggiornamenti, case study). Azure è in continua evoluzione e tramite il blog ufficiale è possibile seguire i rilasci e capire nuovi scenari d’uso.
· Certificazioni Azure e formazione: se volete attestare e approfondire le vostre competenze, considerate le certificazioni come AZ-900 Azure Fundamentals (base), AZ-104 Azure Administrator, o AZ-305 Azure Solutions Architect. Preparare queste certificazioni aiuta a coprire in modo sistematico molti degli argomenti toccati qui. Microsoft Learn include percorsi di studio dedicati a ciascuna certificazione.
In conclusione, Azure rappresenta un ecosistema ricco dove, una volta apprese le basi presentate in questo ebook, potrete esplorare servizi avanzati (come l’AI, l’IoT, l’analisi dei dati su larga scala, ecc.) e creare soluzioni innovative. Ricordate di fare riferimento alla documentazione ufficiale per dettagli sempre aggiornati e di sperimentare direttamente sulla piattaforma (magari sfruttando l’Azure Free Tier) per rafforzare la comprensione.
Riepilogo capitolo
Microsoft Azure è una piattaforma cloud completa che offre servizi fondamentali di calcolo, archiviazione e rete, oltre a strumenti per la gestione delle risorse, sicurezza, monitoraggio e controllo dei costi. Questa guida fornisce una panoramica dettagliata di questi servizi e delle loro applicazioni pratiche.
· Servizi principali: Compute, Storage e Networking: Azure fornisce macchine virtuali flessibili per carichi di lavoro diversi, account di archiviazione con vari livelli di ridondanza e sicurezza, e reti virtuali per connettere risorse in modo sicuro e scalabile. Le VM possono essere scalate manualmente o automaticamente, mentre lo storage supporta Blob, File, Queue e Table con opzioni di ridondanza LRS, ZRS, GZRS e RA-GZRS. Le Virtual Network consentono segmentazione, peering e connessioni ibride con on-premises.
· Gestione delle risorse con Resource Groups: Le risorse Azure sono organizzate in Resource Group, contenitori logici che facilitano gestione, controllo accessi e applicazione di tag. Questi RG si inseriscono in una gerarchia più ampia con Subscription e Management Groups, supportando una governance strutturata e controlli di sicurezza mirati.
· Best practice per Resource Groups: È importante adottare naming standardizzati, utilizzare tag per categorizzare risorse e seguire una struttura gerarchica che separa ambienti e business unit per facilitare governance, controllo costi e sicurezza.
· Sicurezza in Azure: Microsoft Defender for Cloud monitora la postura di sicurezza e protegge i carichi di lavoro, mentre Microsoft Entra ID gestisce identità e accessi con RBAC, MFA e Conditional Access. I dati sono cifrati a riposo e in transito, con gestione centralizzata delle chiavi tramite Azure Key Vault.
· Networking avanzato: Azure Virtual Network consente segmentazione tramite subnet e NSG, routing personalizzato e integrazione di servizi PaaS con Private Link. Per la connettività ibrida si usano VPN Gateway o ExpressRoute, mentre il Virtual Network Manager facilita la gestione centralizzata di reti complesse, ad esempio con topologie hub-and-spoke.
· Tipologie di archiviazione e ridondanza: Azure Storage offre Blob, Files, Queue, Table e Managed Disks con cifratura automatica e accesso controllato. Gli account possono essere General Purpose v2 o Premium per esigenze di performance. La ridondanza dati varia da LRS a RA-GZRS, garantendo diversi livelli di durabilità e disponibilità geografica.
· Macchine Virtuali in dettaglio: Le VM sono ideali per workload che richiedono controllo completo e compatibilità legacy. Azure offre diverse serie di VM per esigenze specifiche, con opzioni di alta disponibilità tramite Availability Set o Zone e scalabilità con Scale Sets. Per ottimizzare i costi si possono usare Reserved Instances, Savings Plan e Spot VM.
· Monitoraggio con Azure Monitor: Il servizio raccoglie metriche, log e tracce per offrire visibilità completa su risorse e applicazioni. Include soluzioni Insights specifiche per VM, container e rete, oltre a Application Insights per il monitoraggio applicativo. Permette di creare dashboard, alert e automazioni per una gestione proattiva.
· Gestione dei costi e budgeting: Azure Cost Management consente di analizzare la spesa per servizio, risorsa o tag, impostare budget e ricevere alert. Best practice includono organizzazione delle risorse, monitoraggio proattivo, ottimizzazione continua e condivisione dei report per responsabilizzare i team.
CAPITOLO 2 – I principali servizi
Introduzione
Azure è la piattaforma cloud di Microsoft che offre un’ampia gamma di servizi per supportare applicazioni e infrastrutture IT in modo scalabile e flessibile. Questo eBook tecnico, rivolto a studenti con conoscenze informatiche di base, presenta i principali servizi Azure suddivisi per aree tematiche: Calcolo, Archiviazione, Rete, Database, Intelligenza Artificiale, DevOps, Sicurezza, Automazione, Analisi e Governance.
Rimandando per l’approfondimento ai campitoli da 3 a 12, procederemo adesso ad una panoramica sui servizi più importanti di Azure relativi a quell’area, descrivendone le caratteristiche chiave, i concetti fondamentali, esempi pratici di utilizzo e definizioni utili per chiarire la terminologia. Le fonti originali e ulteriori riferimenti sono inclusi per chi desidera approfondire. L’obiettivo è fornire un testo chiaro e dettagliato che aiuti a comprendere i principali servizi Azure in modo tecnico ma accessibile.
Inquadramento argomenti del capitolo con slides illustrate
Azure offre tre principali servizi di calcolo: Macchine Virtuali, App Service e Azure Functions. Le Macchine Virtuali rappresentano l'opzione IaaS, consentendo controllo completo su sistema operativo, rete e dischi, ideali per applicazioni legacy o con esigenze specifiche. App Service è la soluzione PaaS per siti web, API e backend mobili, gestendo hosting, scalabilità e integrazione DevOps. Azure Functions permette invece di eseguire codice in modalità serverless, su evento, con fatturazione a consumo e supporto multi-linguaggio. Un esempio pratico: un portale e-commerce può usare App Service per il front-end, Functions per i pagamenti event-driven e VM con GPU per batch. Ricorda: IaaS offre infrastruttura virtuale, PaaS una piattaforma gestita, mentre Serverless avvia risorse solo quando necessario, ottimizzando costi e scalabilità.
Gli Storage Account di Azure forniscono un namespace globale per gestire Blob, File, Queue e Table: tutto cifrato, durabile e scalabile. Esistono account di tipo GPv2 e Premium, con diversi livelli di ridondanza come LRS, ZRS, GZRS e RA-GZRS. Blob Storage è ideale per file di grandi dimensioni e backup, Azure Files per condivisioni SMB/NFS, Queue per messaggi affidabili tra componenti, e Table per dati NoSQL semplici. Un repository immagini può ad esempio usare Blob con accesso privato e policy di ciclo di vita. Definizioni chiave: una SAS concede accesso temporaneo, mentre i Tier offrono livelli di performance e costo differenti. Consulta sempre la tabella comparativa dei servizi e la mappa di ridondanza per scegliere la soluzione più adatta.
Le Virtual Network, o VNet, sono il fondamento della connettività privata su Azure, collegando risorse tra loro, a Internet e on-premises. Permettono peering, service endpoints e Private Link. I Network Security Group, o NSG, filtrano il traffico in ingresso e uscita su porte, protocolli e origini, applicandosi a subnet o interfacce. Il VPN Gateway abilita la connessione sicura tra sedi tramite tunnel IPsec/IKE, sia site-to-site che point-to-site. Un esempio: subnet dedicate per web, app e database, ciascuna protetta da NSG, e accesso remoto sicuro tramite P2S VPN. Service Tag semplifica la gestione degli intervalli IP, mentre il peering garantisce bassa latenza tra VNets. Valuta sempre uno schema hub-and-spoke per la sicurezza e la resilienza della rete.
Azure SQL Database è un servizio PaaS gestito che garantisce alta disponibilità, backup automatici e patching, con modelli di acquisto vCore o DTU e tier come Hyperscale e serverless. Azure Cosmos DB, invece, è un database NoSQL distribuito, con latenza molto bassa, replica multi-region e diversi livelli di consistenza, compatibile con API come MongoDB e Cassandra. Scegli SQL Database per dati relazionali e transazioni ACID, Cosmos DB per applicazioni globali e schema flessibile. Un'app retail, ad esempio, può memorizzare ordini in SQL Database e profili utenti in Cosmos DB, sfruttando la replica geografica. Hyperscale consente di scalare SQL oltre i 100 TB, mentre la consistenza in Cosmos DB permette di bilanciare correttezza e latenza.
Azure Machine Learning supporta l'intero ciclo di vita del machine learning: training, deployment, MLOps, con endpoint gestiti, AutoML e prompt flow. Il servizio include anche un model catalog con foundation models. Azure AI Services, o Cognitive Services, offre API pre-addestrate per visione, linguaggio, traduzione, voce e decisione, integrabili tramite REST o SDK. Per esempio, puoi creare un classificatore immagini addestrando dati su Blob e pubblicando il modello tramite AutoML e endpoint online, oppure realizzare assistenti testuali con Language e Speech. AutoML automatizza la scelta di algoritmi e iperparametri, mentre gli endpoint gestiti garantiscono inferenza sicura e scalabile. Consulta sempre il flusso ML per una visione completa: dai dati al monitoraggio.
Azure DevOps integra Boards per il work management, Repos per il controllo versione Git, Pipelines per CI/CD, Test Plans e Artifacts. Permette pianificazione agile, code review, build automatizzate, deployment multi-ambiente e gestione della sicurezza. Un esempio pratico: una pipeline YAML compila un'app .NET, esegue test, pubblica artefatti e rilascia su App Service tramite slot di staging e produzione. Boards gestisce backlog e sprint, mentre policy di branch su main assicurano approvazione e scansioni di sicurezza. Ricorda: CI/CD automatizza integrazione e consegna continua, e gli artifact sono pacchetti riutilizzabili nei rilasci. Esamina sempre il workflow CI/CD per visualizzare l'intero processo di sviluppo.
Microsoft Entra ID, precedentemente Azure Active Directory, gestisce identità e accessi, supportando RBAC, MFA, Conditional Access e integrazione con applicazioni e dispositivi. È la base per architetture Zero Trust. Microsoft Defender for Cloud è una piattaforma CNAPP che unifica sicurezza e postura per server, container, storage e database, fornendo raccomandazioni, alert e conformità. Esempi: abilita MFA per gli amministratori, imposta regole di Conditional Access e usa Privileged Identity Management per ruoli temporanei. Attiva Defender for Servers e Storage, correggi raccomandazioni prioritarie e integra con Microsoft Sentinel per il monitoraggio SIEM. Il secure score indica la postura di sicurezza, mentre RBAC controlla gli accessi alle risorse.
Logic Apps consente l'orchestrazione low-code di workflow tra servizi, connettendo facilmente Office 365, SQL, Storage e HTTP. Event Grid gestisce eventi in tempo reale, collegando publisher come Storage o Resource Groups a subscriber come Functions e WebHooks. Automation Account esegue runbook in PowerShell o Python per compiti programmati, aggiornamenti e Desired State Configuration. Esempi: un workflow che, al caricamento di un blob, valida dati, scrive su SQL e invia email; oppure la notifica di cambiamenti infrastrutturali gestita via Event Grid e Functions. Per la manutenzione, puoi pianificare lo spegnimento notturno delle VM tramite script. Consulta sempre diagrammi eventi e flowchart per ottimizzare l'automazione aziendale.
Azure Synapse Analytics è una piattaforma unificata per l'integrazione, il warehousing e l'analisi, con SQL, Spark e pipeline integrate e Data Lake per lo storage analitico. Data Lake Storage Gen2 offre storage scalabile con directory gerarchiche, ACL e alte performance. HDInsight fornisce cluster Hadoop e Spark gestiti per workload Big Data. Un tipico scenario ETL prevede l'ingestione dati da ERP, staging su Data Lake, trasformazioni con Spark o SQL, pubblicazione su data warehouse e creazione di dashboard BI. Per i log IoT, Data Lake funge da data lakehouse, con elaborazioni Spark e tabelle ottimizzate. Consulta i diagrammi di pipeline per visualizzare il ciclo dei dati dall'origine al report.
Azure Arc estende la gestione di Azure a risorse on-premises e multicloud, abilitando policy, monitoraggio, sicurezza e GitOps su Kubernetes, server e SQL ovunque. Azure Policy applica criteri di conformità e governance, generando report di compliance e remediation automatica. Cost Management e Billing analizza le spese, supporta la creazione di budget, alert, cost allocation, e consente risparmi tramite Reservations e Savings Plans. Esempi: registra server on-premises con Arc, applica policy di sicurezza e raccogli metriche centralizzate; imposta iniziative Policy per richiedere Private Endpoints e remediation; definisci budget di progetto, ricevi alert e acquista Reserved Instances per VM stabili. Consulta sempre i cruscotti di compliance, trend di spesa e mappe delle risorse Arc per una governance efficace.
1. Calcolo in Azure (Compute)
I servizi di calcolo in Azure permettono di eseguire applicazioni e workload con diversi modelli di servizio: dall’Infrastructure as a Service (IaaS), che offre macchine virtuali completamente gestibili dall’utente, fino al Platform as a Service (PaaS) per eseguire applicazioni senza preoccuparsi dell’infrastruttura sottostante, arrivando alle soluzioni serverless in cui il codice viene eseguito su richiesta senza dover gestire server. Azure offre sia infrastruttura virtuale, tramite Macchine Virtuali (VM), sia piattaforme gestite come App Service, sia funzionalità serverless con Azure Functions. Queste opzioni coprono un ampio spettro di esigenze di calcolo, garantendo flessibilità, scalabilità ed efficienza dei costi a seconda del modello scelto.
Macchine Virtuali (VM): le VM di Azure sono istanze di computer virtualizzati su cui l’utente ha pieno controllo del sistema operativo, dell’ambiente di runtime e delle configurazioni di rete e storage. Questo servizio IaaS è ideale per eseguire software legacy, applicazioni che richiedono configurazioni personalizzate o quando si necessita di pieno controllo dell’infrastruttura. Azure mette a disposizione molte famiglie di VM (ottimizzate per compute, memoria, GPU, ecc.) e varie dimensioni per adattarsi ai carichi di lavoro più disparati. Le VM supportano inoltre funzionalità di alta disponibilità mediante Availability Zone (zone di disponibilità fisicamente separate all’interno di una regione Azure) e tramite i Virtual Machine Scale Sets (gruppi di VM identiche scalabili automaticamente). In sintesi, le VM offrono la flessibilità della virtualizzazione in cloud, con la responsabilità però di gestire aggiornamenti, patch e manutenzione del sistema operativo. Fonti: Documentazione Panoramica delle macchine virtuali Azure e guida alle Macchine Virtuali su Microsoft Learn.
App Service: Azure App Service è una piattaforma PaaS completamente gestita per l’hosting di applicazioni web, API REST e backend per applicazioni mobili. Con App Service, gli sviluppatori possono distribuire codice in diversi linguaggi (tra cui .NET, Java, Node.js, Python e anche container Docker) senza doversi occupare della gestione di server o macchine virtuali. La piattaforma si occupa automaticamente del provisioning dell’infrastruttura, del bilanciamento del carico, della scalabilità automatica in base al traffico, nonché di funzionalità di sicurezza come l’autenticazione integrata e l’integrazione con servizi CI/CD (Continuous Integration/Continuous Deployment). App Service supporta deployment avanzati (ad esempio tramite deployment slots per effettuare rilasci in produzione senza tempi di inattività) e si integra con altri servizi Azure (come database o reti virtuali). In pratica, questo servizio consente di concentrarsi sullo sviluppo dell’applicazione lasciando ad Azure la gestione dell’ambiente di esecuzione. Fonti: Panoramica di Azure App Service e relativa Documentazione su Microsoft Learn.
Azure Functions: Azure Functions è il servizio di calcolo serverless di Azure basato su un modello event-driven. Consente di eseguire piccoli frammenti di codice o funzioni in risposta a eventi esterni, come richieste HTTP, messaggi in coda, trigger su modifiche di dati o timer programmati. La caratteristica principale di Functions è che scala automaticamente in base al carico e il modello di pagamento è a consumo: si paga solo per il tempo di esecuzione effettivo e le risorse utilizzate dalle funzioni (modalità Consumption), con la possibilità di optare anche per un piano Premium o dedicato per esigenze particolari. Azure Functions supporta diversi linguaggi di programmazione (C#, Java, JavaScript/TypeScript, Python, PowerShell, ecc.) e permette di connettersi facilmente con altri servizi Azure tramite un sistema di bindings (collegamenti preconfigurati a storage, code, database, email, ecc.). Questo approccio consente di costruire architetture applicative altamente modulari e reattive agli eventi, senza dover mantenere un’infrastruttura permanente. Fonti: Panoramica Azure Functions e guida introduttiva “Getting Started” su Microsoft Learn.
Esempi pratici:
· Portale e-commerce: un sito di commercio elettronico potrebbe utilizzare App Service per ospitare il front-end web, mentre le funzionalità di pagamento e conferma ordini possono essere implementate con Azure Functions attivate da trigger HTTP (ad esempio una funzione che si attiva all’arrivo di un ordine). Per compiti intensivi come la generazione di immagini dei prodotti o elaborazioni batch notturne, si potrebbero usare VM specializzate (ad esempio VM con GPU) in grado di eseguire questi carichi di lavoro in maniera isolata. Questo approccio ibrido sfrutta i punti di forza di ciascuno dei servizi di calcolo: App Service per la facilità di gestione del sito web, Functions per l’elaborazione scalabile on-demand e VM per elaborazioni personalizzate o pesanti.
· Integrazione di sistemi: si immagini un processo aziendale dove un ordine inserito debba attivare varie azioni. Una Azure Function potrebbe essere configurata con un binding su una coda (Queue Storage): quando un nuovo messaggio d’ordine viene inserito nella coda, la Function si attiva automaticamente per elaborarlo (ad esempio validando i dati o aggiornando un database). Contestualmente, l’applicazione web per inserire ordini potrebbe risiedere su App Service. Per rendere i rilasci di nuove versioni dell’applicazione web senza interruzioni, App Service offre gli deployment slots (ad esempio uno slot “staging” per testare la nuova versione e poi scambiarlo a caldo con quello “production”). In questo scenario le Functions gestiscono l’elaborazione asincrona e scalabile delle richieste, mentre App Service garantisce un hosting affidabile per l’interfaccia utente e le API.
Definizioni utili:
· IaaS (Infrastructure as a Service): modello cloud in cui le risorse di base (server virtuali, rete, storage) sono fornite come servizio. L’utente ha controllo diretto sul sistema operativo e sulle configurazioni, ma deve gestire manutenzione e aggiornamenti dell’OS e dei middleware. Esempi: macchine virtuali, networking, dischi.
· PaaS (Platform as a Service): modello in cui la piattaforma applicativa è gestita dal provider cloud, e l’utente vi distribuisce le proprie applicazioni. Riduce gli oneri operativi (gestione dell’infrastruttura, patch, scaling) lasciando però meno controllo sull’ambiente sottostante. Esempi: servizi gestiti di hosting web, database gestiti, servizi applicativi come Azure App Service.
· Serverless: modello in cui l’infrastruttura è completamente astratta. Le risorse di calcolo vengono avviate solo quando necessario per eseguire porzioni di codice in risposta a eventi, scalando automaticamente. La fatturazione è basata sul tempo di esecuzione e sulle risorse consumate, senza costi per il tempo di inattività. L’utente non gestisce macchine o OS: l’attenzione è sul codice e la logica applicativa. Esempio: Azure Functions, Azure Logic Apps (per workflow).
2. Archiviazione (Storage)
L’archiviazione dei dati è un’altra componente fondamentale di Azure, fornita attraverso il servizio di Storage Account. Uno Storage Account su Azure rappresenta un contenitore logico che fornisce uno spazio dei nomi unificato a livello globale per diversi tipi di dati: file non strutturati, file system distribuiti, messaggistica e archivi NoSQL semplici. Tutti i dati immagazzinati negli Storage Account sono cifrati automaticamente e replicati per garantirne durabilità e alta disponibilità. Azure offre diversi meccanismi di ridondanza geografica per proteggere i dati da guasti: ad esempio, la replica locale (LRS, Locally Redundant Storage) mantiene diverse copie sincronizzate all’interno del datacenter; la replica ZRS (Zone-Redundant Storage) distribuisce i dati su zone di disponibilità differenti all’interno di una regione; la replica geografica GZRS e la sua variante con accesso in lettura RA-GZRS mantengono copie in più regioni per garantire resilienza anche in caso di disastro regionale, permettendo nella versione RA (Read-Access) l’accesso in sola lettura alla replica secondaria. Esistono inoltre due tipologie principali di account di archiviazione: i General Purpose v2 (GPv2), che sono i più versatili e usati per la maggior parte degli scenari (supportano tutti i servizi di storage con opzioni di tiering dei dati), e gli account Premium, progettati per carichi con elevate richieste di prestazioni costanti (ad esempio per dischi Managed Premium, Azure Files Premium, ecc.).
All’interno di uno Storage Account, Azure fornisce diversi servizi di archiviazione specializzati: Blob Storage, File Shares (Azure Files), Code (Queues) e Tabelle (Tables). Ciascuno di essi è adatto a differenti casi d’uso, come riassunto di seguito.
Tipi di archiviazione e casi d’uso:
· Blob Storage: servizio per archiviare oggetti binari (file) di grandi dimensioni o quantità elevate di dati non strutturati, come immagini, video, log, backup, dati per data lake, ecc. Supporta diversi tier di accesso – Hot, Cool e Archive – che consentono di bilanciare costi e prestazioni a seconda della frequenza di accesso ai dati: ad esempio, dati usati di frequente rimarranno nel tier Hot, mentre quelli di archivio a lungo termine possono essere spostati nel tier Archive a costi ridotti. Blob Storage include anche le funzionalità di Data Lake Storage Gen2, che aggiunge un file system gerarchico (con directory e autorizzazioni POSIX) rendendolo adatto a carichi di lavoro di analisi e Big Data. Fonti: Panoramica e best practice sugli https://learn.microsoft.com/it-it/azure/storage/blobs/storage-blobs-introduction.
· Azure Files: fornisce condivisioni file SMB/NFS totalmente gestite nel cloud, simili a tradizionali share di rete, utili per scenari di lift-and-shift in cui applicazioni esistenti richiedono un file system condiviso. Con Azure Files è possibile migrare applicazioni che usano percorsi di file condivisi senza dover modificare il modello di accesso ai dati. La variante Azure Files Premium offre prestazioni più elevate e IOPS costanti, adatte ad esempio ad applicazioni aziendali con esigenze intensive di I/O.
· Queue Storage: implementa un sistema di messaggistica FIFO semplice ma duraturo tra componenti diversi di un’applicazione. Le code di Azure Storage permettono di decouple componenti di un’app distribuendo messaggi affidabili (fino a 64 KB ciascuno) che possono essere letti da altri servizi o processi in modo asincrono. È utile per costruire architetture distribuite e scalabili, in cui i componenti produttori e consumatori di messaggi possono lavorare in modo indipendente, bilanciando il carico (ad esempio, una web app mette messaggi in coda per un servizio di elaborazione backend).
· Table Storage: fornisce un archivio NoSQL chiave-valore schemaless, a bassa latenza e costo contenuto, adatto a memorizzare grandi volumi di dati strutturati in modo semplice (ad es. log, dati di sensori, dati di sessione). Ogni entità è un insieme di proprietà (colonne) identificata da una chiave di partizione e una chiave di riga. Pur non offrendo le funzionalità avanzate di database relazionali, le Tabelle di Azure sono ottime per dati semplici che richiedono scalabilità orizzontale. (Da notare che Azure Cosmos DB supporta l’API compatibile con Azure Table per scenari che richiedono funzionalità aggiuntive come indici secondari o throughput riservato).
Esempi pratici:
· Repository di immagini: un’applicazione che gestisce un grande numero di immagini (ad esempio una galleria fotografica o un sistema CMS) può archiviare i file in un Blob Storage all’interno di un contenitore impostato come privato. Per distribuire le immagini globalmente con bassa latenza, il Blob Storage può essere integrato con un servizio di CDN (Content Delivery Network). Inoltre, grazie alle politiche di ciclo di vita dello Storage Account, è possibile configurare regole automatiche che spostano le immagini meno recenti su tier di accesso meno costosi: ad esempio, dopo 30 giorni di inattività spostarle dal tier Hot al Cool, e dopo 6 mesi portarle in Archive, riducendo i costi di storage. L’accesso ai blob può essere controllato tramite credenziali Azure AD (Microsoft Entra ID) o generando SAS token temporanei per concedere l’accesso limitato a client esterni.
· Condivisioni di rete aziendali: un’azienda che ha applicazioni legacy ospitate su macchine virtuali potrebbe migrare i propri file condivisi su Azure Files, rendendo disponibile un percorso SMB di rete accessibile dalle VM in Azure o anche dagli utenti in locale via Azure File Sync. In particolare, per un’applicazione line-of-business critica che richiede prestazioni elevate e bassa latenza costante nell’accesso ai file (ad esempio un sistema ERP), si potrebbe adottare Azure Files Premium, che garantisce throughput e IOPS elevati e consistenti. In questo modo si ottiene un file system condiviso altamente disponibile nel cloud, evitando di mantenere un file server on-premises e beneficiando al contempo della scalabilità e resilienza offerte da Azure.
Definizioni utili:
· SAS (Shared Access Signature): è una firma di accesso condiviso, ovvero un token che può essere generato per fornire accesso temporaneo e controllato a risorse di archiviazione Azure (come blob, file, code o tabelle) senza dover condividere le credenziali dell’account. Un SAS incorpora autorizzazioni specifiche (lettura, scrittura, ecc.) e una finestra temporale di validità; è molto utilizzato per concedere a entità esterne (applicazioni client, utenti, servizi) diritti limitati su una risorsa per un tempo definito, in modo sicuro.
· Tier di archiviazione: indica il “livello” associato a un dato archiviato in Azure in termini di frequenza di accesso prevista e, conseguentemente, costi e prestazioni. Nel contesto di Blob Storage, ad esempio, il tier Hot è pensato per dati ad accesso frequente (costo di storage maggiore ma accesso rapido ed economico), il tier Cool per dati a accesso raro (costo storage più basso ma costo leggermente superiore per operazioni di lettura), e Archive per dati di archivio a cui si accede raramente o mai (costo minimo di storage ma i dati vanno rianimati con un’operazione di restore prima di poterli leggere, e le operazioni hanno latenza elevata). Scegliere il tier adeguato consente di ottimizzare i costi di archiviazione secondo il ciclo di vita del dato.
Riferimenti: per maggiori dettagli sull’archiviazione in Azure, consultare la https://learn.microsoft.com/it-it/azure/storage/common/storage-account-overview e l’https://learn.microsoft.com/it-it/azure/storage/common/storage-introduction su Microsoft Learn. Per approfondire le best practice architetturali relative allo storage (replica, progettazione di data lake, ecc.) è utile la guida sul https://learn.microsoft.com/en-us/azure/architecture/guide/storage/storage-start-here e il percorso formativo Microsoft Learn “https://learn.microsoft.com/it-it/training/paths/store-data-in-azure/”.
3. Rete (Networking)
La rete in Azure consente di collegare e proteggere risorse cloud in modo molto flessibile, simulando e ampliando le funzionalità di una rete tradizionale all’interno dell’ambiente Azure. I principali componenti di rete includono le Reti Virtuali (VNet), i gruppi di sicurezza di rete (Network Security Group, NSG) e i servizi di connettività ibrida come il VPN Gateway. Attraverso questi strumenti è possibile creare ambienti isolati nel cloud, definire topologie multi-tier sicure e stabilire collegamenti sicuri tra Azure e l’infrastruttura on-premises.
Virtual Network (VNet): una Rete Virtuale Azure è l’unità di base della rete privata in Azure. Funziona in modo simile a una rete fisica tradizionale, ma con la flessibilità del software: una VNet consente di mettere in comunicazione risorse Azure (VM, container, servizi PaaS) tra loro, di segmentarle in sottoreti (subnet) e di controllare il loro accesso interno ed esterno. Le VNet possono essere connesse ad Internet tramite endpoint pubblici, messe in comunicazione reciproca tramite peering (collegamento diretto a bassa latenza tra due reti virtuali) e possono estendersi alla rete locale aziendale tramite connessioni ibride (VPN o ExpressRoute). Azure offre inoltre funzionalità come i Service Endpoint (per consentire alle risorse in VNet di accedere a servizi Azure PaaS in modo sicuro, attraverso la rete Azure Backbone invece di Internet) e Private Link (per connettere servizi PaaS al VNet tramite un endpoint privato dedicato). In sintesi, la VNet è fondamentale per definire ambienti isolati e sicuri nel cloud dove posizionare le risorse, controllando il loro spazio IP e i percorsi di rete. Fonte: Vedi la https://learn.microsoft.com/it-it/azure/virtual-network/virtual-networks-overview su Microsoft Learn per maggiori dettagli.
Network Security Group (NSG): un NSG è un componente di sicurezza che agisce come un firewall a livello di rete per filtrare il traffico in ingresso e in uscita dalle risorse Azure. Un NSG contiene una serie di regole definite dall’utente, ciascuna con criteri di permesso o negazione basati su: porta di destinazione (o origine), protocollo (TCP/UDP), indirizzo IP di origine e destinazione, e priorità. Le regole vengono valutate in ordine di priorità e determinano quale traffico è consentito o bloccato. Gli NSG possono essere associati sia a subnet intere (applicando le regole a tutto il traffico verso e dalla subnet) sia direttamente alle NIC (schede di rete) di singole macchine virtuali o istanze di servizio. In pratica, con gli NSG si può segmentare la rete applicativa in zone di sicurezza, aprendo solo le porte strettamente necessarie (ad esempio, permettere il traffico HTTP/HTTPS verso le VM web e bloccare qualsiasi altro accesso non autorizzato). Azure fornisce anche oggetti utili come i Service Tag (etichette predefinite che rappresentano gruppi di indirizzi IP di servizi Azure comuni, ad esempio Internet, AzureStorage, AzureSQL, etc.) e gli Application Security Group per semplificare la gestione delle regole NSG in scenari complessi. Fonti: Per approfondire, vedere https://learn.microsoft.com/it-it/azure/virtual-network/network-security-groups-overview e https://learn.microsoft.com/en-us/azure/virtual-network/network-security-group-how-it-works su Microsoft Learn.
VPN Gateway: Azure VPN Gateway è un servizio che permette di creare tunnel di rete crittografati tra Azure e altre reti, utilizzando i protocolli IPsec/IKE. Supporta diversi scenari:
· Site-to-Site (S2S): crea un tunnel VPN tra una rete virtuale Azure e una rete locale on-premises (richiede un dispositivo/servizio VPN anche sul lato locale);
· Point-to-Site (P2S): consente a singoli client (ad esempio laptop di sviluppatori o amministratori) di connettersi via VPN alla rete virtuale Azure da qualsiasi luogo, come se fossero in LAN aziendale;
· VNet-to-VNet: stabilisce una VPN tra due Reti Virtuali Azure, utile per connettere risorse in differenti regioni o tenanti.
Il VPN Gateway supporta modalità di autenticazione flessibili per P2S (certificati, credenziali Microsoft Entra ID/Azure AD, ecc.) e offre throughput scalabile scegliendo SKUs più performanti. In uno scenario di connettività ibrida avanzata, il VPN Gateway può coesistere con Azure ExpressRoute (il servizio di connessione privata dedicata ad alta velocità a Azure) funge spesso da soluzione di backup: se il circuito privato ExpressRoute cade, la VPN pubblica può subentrare per garantire continuità, pur con prestazioni inferiori. Fonti: Maggiori informazioni nella https://learn.microsoft.com/it-it/azure/vpn-gateway/vpn-gateway-about-vpngateways e nel https://learn.microsoft.com/it-it/azure/vpn-gateway/tutorial-create-gateway-portal (portale Azure) su Microsoft Learn.
Esempi pratici:
· Segmentazione a livelli di un’applicazione: si consideri un’app multi-tier classica con livelli Web, di applicazione e di database. In Azure si può creare una singola VNet suddivisa in tre subnet: ad esempio web-subnet, app-subnet e db-subnet. Ogni subnet ospiterà solo le VM o i servizi di quel particolare livello. Applicando un NSG appropriato su ciascuna subnet, si può implementare la segmentazione di sicurezza in modo semplice: ad esempio, il NSG della subnet web permetterà traffico in ingresso sulla porta 80/443 (HTTP/HTTPS) proveniente da Internet, ma non permetterà l’accesso diretto alle VM di quel livello su altre porte; il NSG della subnet applicativa potrebbe consentire traffico solo dalla subnet web (porta ad esempio 1433 se il DB è SQL) e solo verso la subnet database, bloccando qualsiasi altro flusso; la subnet database potrebbe invece consentire ingressi solo dal livello app e negare tutto il resto. Inoltre, per accrescere la sicurezza, le VM del livello database potrebbero non avere IP pubblici e accettare traffico solo tramite Private Endpoints (ad esempio un Private Endpoint per un database Azure SQL o per un account Storage) assicurando che anche i servizi PaaS siano accessibili solo attraverso la rete privata. Questo scenario mostra come combinando VNet, subnet, NSG e Private Link si possano costruire architetture cloud molto simili per sicurezza e isolamento a un tradizionale data center on-premises.
· Accesso remoto sicuro per amministratori: un’azienda potrebbe voler permettere ai propri amministratori di collegarsi ai server Azure in modo sicuro quando lavorano in remoto. Abilitando una VPN Point-to-Site sul VPN Gateway associato alla VNet che ospita i server, ciascun amministratore può instaurare un tunnel VPN dal proprio laptop ed entrare nella rete virtuale Azure come se fosse in ufficio. Utilizzando l’autenticazione tramite Microsoft Entra ID (Azure AD) e l’obbligo di MFA (Multi-Factor Authentication) per la connessione VPN, si aumenta il livello di sicurezza delle connessioni remote. Una volta connessi, gli amministratori possono RDP/SSH nelle VM aziendali tramite gli IP privati. Questo elimina la necessità di esporre le VM su Internet con IP pubblici, riducendo la superficie di attacco e sfruttando Azure come estensione sicura della propria rete interna.
Definizioni utili:
· Service Tag: in Azure, i service tag sono etichette predefinite che rappresentano insiemi di indirizzi IP gestiti da Azure per determinati servizi. Ad esempio, c’è un tag Internet che corrisponde a “tutto il traffico Internet non Azure”, tag come AzureCloud, Storage, Sql che corrispondono agli intervalli IP utilizzati rispettivamente da Azure in generale, dal servizio Azure Storage, dal servizio Azure SQL, ecc. Invece di specificare manualmente decine di indirizzi IP nei NSG, gli amministratori possono usare i service tag (es. permettere traffico in uscita verso Storage) e sarà Azure a mantenere aggiornato l’elenco degli IP effettivi dietro a quel tag.
· Peering: è una connessione diretta tra due Virtual Network in Azure che consente alle risorse in esse (VM, servizi) di comunicare tra loro come se fossero nella stessa rete locale, con latenza molto bassa. Il peering è configurabile tra VNet anche in regioni diverse (VNet peering globale) o in differenti subscription/tenant, purché si abbiano le autorizzazioni necessarie. Importante: il traffico tra due VNet peerate rimane sulla rete backbone di Azure (non passa attraverso Internet), ma le VNet peer non condividono per default gli oggetti come NSG o gateway di rete – ad esempio, se una VNet ha un VPN Gateway, la VNet peer può usarlo solo abilitando l’opzione di gateway transit.
4. Database gestiti
Azure offre servizi di database gestiti che rimuovono molto del carico operativo associato alla gestione di database tradizionali. In particolare, Azure fornisce soluzioni sia per database relazionali che non relazionali (NoSQL), permettendo agli sviluppatori di concentrarsi sui dati e sulle query senza preoccuparsi di installazione, patching del software, gestione di alta disponibilità o backup – gran parte di queste attività sono infatti automatizzate dalla piattaforma. In questa sezione esamineremo due servizi chiave: Azure SQL Database, per esigenze relazionali, e Azure Cosmos DB, per esigenze NoSQL distribuite su scala globale.
Azure SQL Database: è un servizio di database relazionale PaaS basato sul motore Microsoft SQL Server, offerto come istanza completamente gestita nel cloud. Fornisce la piena potenza di SQL Server (transazioni ACID, supporto T-SQL, funzioni relazionali avanzate) senza richiedere la gestione diretta del sistema operativo o del software database – Azure si occupa in autonomia di patch di sicurezza, aggiornamenti, backup automatici e gestione dell’alta disponibilità. Azure SQL DB offre un SLA elevato (fino al 99,99% di disponibilità) e varie opzioni di scalabilità e performance: è possibile scegliere tra modelli di acquisto basati su DTU (un vecchio modello che combina misura di CPU, memoria e I/O in un singolo numero) oppure basati su vCore (core virtuali, che danno più controllo su CPU e memoria allocati). Inoltre esistono diversi tier di servizio, ad esempio General Purpose, Business Critical, nonché opzioni speciali come Hyperscale (un’architettura che separa computing e storage per arrivare a dimensionare un singolo database fino a oltre 100 TB) e la modalità serverless per carichi intermittenti (in cui il database può ridurre automaticamente le risorse quando inattivo). Azure SQL DB può essere usato in modalità database singolo o in pool elastici (dove più database condividono risorse su un pool comune). Fonti: Vedi “What is Azure SQL Database?” su Microsoft Learn per una panoramica completa e la https://learn.microsoft.com/it-it/azure/azure-sql/database/ per guida all’uso.
Azure Cosmos DB: è il database NoSQL multimodello di Azure, progettato per applicazioni distribuite su scala globale che richiedono latenze molto basse e throughput elevato. Cosmos DB è offerto come servizio completamente gestito, con replicazione automatica dei dati attraverso più regioni in tutto il mondo e possibilità di scalare sia in termini di spazio che di operazioni al secondo. Piuttosto che utilizzare il concetto tradizionale di CPU/memoria, Cosmos DB adotta la misura del throughput in termini di Request Unit (RU): ogni operazione (lettura, scrittura, query) consuma un certo numero di RU a seconda della complessità, e si pre-acquista una certa capacità di RU/secondo in modo da garantire prestazioni prevedibili. Una caratteristica distintiva di Cosmos DB è il supporto di API multiple: pur avendo un’implementazione unificata, espone interfacce compatibili con diversi modelli di dati e protocolli, tra cui API Core (SQL) per documenti JSON, MongoDB (protocollo Mongo compatibile), Cassandra (CQL), Gremlin (per grafi) e anche un’API per Table (compatibile con Azure Table Storage) e una per PostgreSQL distribuito (per scenari che richiedono la semantica relazionale su dati distribuiti). Cosmos DB consente inoltre di scegliere tra vari livelli di consistenza per le operazioni distribuite, dalla consistenza Strong (in cui tutte le repliche devono confermare l’operazione, garantendo la massima coerenza a scapito di qualche latenza in più) fino alla Eventual (in cui le repliche si aggiornano con ritardo, accettando dati potenzialmente non allineati temporaneamente in cambio di maggior velocità), passando per livelli intermedi come Bounded Staleness, Session e Consistent Prefix. Questa flessibilità permette di bilanciare il compromesso tra consistenza dei dati e prestazioni secondo le esigenze dell’applicazione. Fonti: Per una panoramica completa si può consultare la https://learn.microsoft.com/it-it/azure/cosmos-db/overview, disponibile anche in italiano.
Quando scegliere quale database:
· Azure SQL Database è indicato quando si lavora con dati relazionali strutturati e si necessita di garantire proprietà transazionali ACID (Atomicità, Coerenza, Isolamento, Durabilità) nelle operazioni. È la scelta ideale per applicazioni line-of-business tradizionali, sistemi di gestione di transazioni (ordini, fatture, etc.), piattaforme che richiedono query SQL complesse o integrazione con strumenti di reporting e BI già basati su SQL. Inoltre, se si proviene da un ambiente SQL Server on-premises, Azure SQL Database facilita la migrazione grazie all’elevata compatibilità (ad esempio modalità di compatibilità, supporto di store procedure T-SQL, driver e ORM che funzionano con SQL Server funzioneranno anche con Azure SQL).
· Azure Cosmos DB è adatto quando si costruiscono applicazioni moderne distribuite, che richiedono bassa latenza di accesso ai dati da diverse parti del mondo, schema flessibile (dati semi-strutturati come JSON) o non schema (key-value, grafi), e scalabilità elastica di throughput. Se il sistema deve gestire grandi volumi di dati non relazionali e servire richieste con tempi dell’ordine di qualche millisecondo, Cosmos DB è una soluzione indicata. È la scelta preferenziale per scenari come: applicazioni IoT con flussi di telemetria, applicazioni web/mobili globali che personalizzano l’esperienza utente memorizzando impostazioni/profili, oppure archivi di dati che devono restare attivi anche se un intero datacenter cade (grazie alla replicazione su più regioni). La scelta di una chiave di partizione appropriata è fondamentale in Cosmos DB per ottenere prestazioni ottimali distribuendo uniformemente i dati tra i nodi.
Esempio pratico
Applicazione Retail ibrida: immaginate un e-commerce internazionale. Per gestire dati finanziari e transazionali critici come ordini, dettagli di fatturazione e transazioni di pagamento, l’applicazione può utilizzare Azure SQL Database, beneficiando di transazioni robuste e schema relazionale (tabelle per clienti, ordini, prodotti, fatture, ecc.). Tali dati richiedono coerenza e integrità (ad esempio, aggiornamenti a più tabelle come ridurre lo stock quando viene inserito un nuovo ordine) e possono sfruttare le funzionalità di SQL Database come gli indici e le procedure memorizzate. Parallelamente, per funzionalità come il carrello shopping cart degli utenti o i profili utente con le preferenze e la cronologia di navigazione, può essere impiegato Azure Cosmos DB usando l’API Core (documenti JSON). Questi dati sono meno strutturati, variano da utente a utente e beneficiano di una bassa latenza: con Cosmos DB è possibile, ad esempio, replicare i dati in più aree (vicine ai principali mercati dell’e-commerce) in modo che ogni utente legga il contenuto del proprio carrello dal data center più vicino, ottenendo tempi di risposta rapidissimi. Inoltre, se il sito scala a livello globale, Cosmos DB garantisce che ogni regione abbia la sua copia dei dati di profilo, mantenuta sincronizzata in background. In questo scenario, l’applicazione utilizza in parallelo servizi diversi per tipi diversi di dati: il database SQL per i dati transazionali strutturati, il database NoSQL Cosmos per dati di sessione e preferenze, ottenendo il meglio da entrambi i mondi.
Definizioni utili:
· Hyperscale: è un’architettura di Azure SQL Database pensata per superare i limiti tradizionali delle risorse di un singolo server. In Hyperscale, il livello di storage è separato dal calcolo ed è altamente distribuito: i dati vengono suddivisi in molteplici nodi di storage (chiamati pagine di estensione) e viene utilizzata una cache su nodi di lettura/scrittura. Ciò permette a un singolo database di crescere fino a dimensioni nell’ordine di decine di terabyte (100 TB e oltre) mantenendo performance elevate, e consente di aggiungere in modo relativamente rapido repliche di sola lettura o di ripristinare database di grandi dimensioni in pochi minuti, dato che il ripristino consiste nel mappare le pagine di dati già archiviate. In breve, Hyperscale offre uno scale-out trasparente dello strato dati per il servizio SQL Database.
· Consistenza (modelli di consistenza): in un sistema distribuito come Cosmos DB, il livello di consistenza definisce quanto fortemente i dati replicati su nodi diversi rimangono sincronizzati dopo un’operazione di scrittura. Cosmos DB offre 5 livelli predefiniti: Strong (forte: dopo una scrittura, tutti i lettori in qualsiasi regione vedono subito quella modifica; massima garanzia di allineamento ma più latenza), Bounded Staleness (obsolescenza limitata: i lettori possono rimanere indietro di al più un dato intervallo di tempo o numero di versioni), Session (consistenza per sessione: un singolo client vede sempre le proprie operazioni in ordine, garantendo letture monotonicamente crescenti nella sua sessione, ma non necessariamente rispetto ad altri client), Consistent Prefix (prefisso consistente: tutti i lettori vedono le scritture nella medesima sequenza in cui sono state effettuate, ma potrebbero non avere tutte le scritture recenti; non si verificano rimescolamenti di ordine, ma può esserci lag), Eventual (eventuale: nessuna garanzia immediata di ordine o freschezza, salvo il fatto che alla fine (eventualmente) tutte le repliche convergeranno; massime prestazioni, minima latenza). Questi modelli permettono di scegliere formalmente il compromesso tra coerenza dei dati e prestazioni/latency in Cosmos DB.
Riferimenti: per approfondire i database gestiti in Azure, si consiglia di leggere la https://learn.microsoft.com/it-it/azure/azure-sql/database/sql-database-paas-overview e la https://learn.microsoft.com/it-it/azure/cosmos-db/overview. Documentazione aggiuntiva è disponibile nei rispettivi hub (ad esempio il https://learn.microsoft.com/it-it/azure/azure-sql/database/ e quello di https://learn.microsoft.com/it-it/azure/cosmos-db/). Inoltre, Microsoft Learn offre moduli didattici sia per SQL Database (anche nell’ambito delle certificazioni Azure Fundamentals e Database Administrator) sia per Azure Cosmos DB (con esempi pratici sull’uso delle diverse API e livelli di consistenza).
5. Intelligenza Artificiale e Machine Learning
Azure dispone di un ricco ecosistema di servizi per l’Intelligenza Artificiale (AI) e il Machine Learning (ML), che spaziano da soluzioni pre-addestrate e pronte all’uso per AI tradizionale, fino a piattaforme complete per sviluppare, addestrare e distribuire modelli personalizzati di machine learning. In questa sezione vedremo due elementi chiave: Azure Machine Learning e i servizi di Azure AI (Cognitive Services), illustrando come permettono rispettivamente di gestire l’intero ciclo di vita dei modelli ML e di integrare intelligenza artificiale nelle applicazioni senza dover addestrare modelli da zero.
Azure Machine Learning (Azure ML): è un servizio Azure che fornisce un ambiente unificato per sviluppare e gestire progetti di machine learning end-to-end, spesso in contesto enterprise. Con Azure ML è possibile: preparare dati e features, addestrare modelli su larga scala sfruttando cluster di calcolo gestiti (inclusi GPU, CPU), effettuare la registrazione dei modelli addestrati in un workspace centralizzato, e infine distribuire questi modelli in produzione attraverso endpoint gestiti con scalabilità automatica. Azure ML supporta flussi di lavoro sia tramite interfaccia visuale (designer) sia via codice (SDK Python, CLI) e consente di implementare pratiche di MLOps (DevOps per Machine Learning) per alimentare un ciclo continuo di miglioramento dei modelli (monitoraggio delle performance del modello in produzione, ri-addestramento su nuovi dati, ecc.). Tra le funzionalità chiave emergenti: AutoML (Automated Machine Learning) permette di generare automaticamente modelli provando diverse combinazioni di algoritmi e iperparametri per problemi di classificazione, regressione o forecasting, riducendo il lavoro manuale; Managed Endpoints offrono un modo semplice di pubblicare un modello come servizio API REST sicuro e scalabile, senza dover configurare container o bilanciatori; inoltre Azure ML si sta arricchendo nel campo dell’AI generativa con il supporto a prompt flow e a un Model Catalog di modelli pre-addestrati (inclusi foundation model di vari provider) che possono essere riutilizzati e personalizzati. In sintesi, Azure Machine Learning è pensato per team di data scientist e sviluppatori ML che vogliono una piattaforma robusta per orchestrare l’intero processo dalla preparazione dei dati al deployment dei modelli. Fonti: Per iniziare, vedere la https://learn.microsoft.com/it-it/azure/machine-learning/overview-what-is-azure-machine-learning e la relativa https://learn.microsoft.com/it-it/azure/machine-learning/ su Microsoft Learn.
Azure AI Services (Cognitive Services): con questo nome si identificano una serie di servizi di intelligenza artificiale pre-addestrati e offerti “as a Service” da Azure. Microsoft ha messo a disposizione modelli AI avanzati addestrati sui propri dati che gli sviluppatori possono utilizzare attraverso semplici chiamate API o SDK, senza dover sviluppare o addestrare modelli da zero. Questi servizi coprono diverse aree dell’AI: Vision (analisi di immagini e video, riconoscimento facciale, OCR per la lettura di testi nelle immagini, analisi di contenuto visivo), Language (analisi del linguaggio naturale, riconoscimento di entità nominate, analisi sentiment, traduzione automatica, Q&A su base di conoscenza, ecc.), Speech (riconoscimento vocale, sintesi vocale text-to-speech, trascrizione di parlato, traduzione vocale), Decision (servizi per prendere decisioni informate come rilevamento anomalie, moderazione contenuti) e OpenAI Service (che fornisce accesso a modelli di generazione di testo e immagini come GPT-4 e DALL-E, in contesto Azure). Sotto il cappello Azure AI rientrano servizi come Azure Cognitive Services, Azure OpenAI, Azure Bot Service, ecc. L’uso di questi servizi è tipicamente tramite chiamate REST o librerie specifiche: ad esempio, un’app può invocare l’API di Vision per ottenere una descrizione automatica del contenuto di una foto, o usare l’API di Language per l’analisi sentiment di recensioni testuali. Queste API sono altamente scalabili e costantemente migliorate da Microsoft; inoltre spesso permettono una customizzazione (ad esempio Custom Vision per addestrare un modello di visione su immagini specifiche dell’utente, Custom Speech per adattare la sintesi vocale a un certo tono). Fonti: Consultare la pagina introduttiva dei https://learn.microsoft.com/it-it/azure/cognitive-services/ su Microsoft Learn per una carrellata completa.
Esempi pratici:
· Classificatore di immagini end-to-end: un team di data science vuole costruire un sistema che classifichi immagini (ad es. foto di prodotti) in categorie. Usando Azure Machine Learning, possono sfruttare AutoML Vision: caricano un dataset di immagini etichettate su un Azure Blob Storage, configurano un esperimento AutoML nel workspace Azure ML per provare diversi modelli di classificazione delle immagini. Il servizio addestra automaticamente vari modelli di deep learning (ad es. rete neurale convolutionale) su GPU, trovando quello con la migliore accuratezza. Il modello migliore viene registrato nel workspace. A questo punto, con pochi clic o comandi, il team può deployare il modello come endpoint online gestito: Azure ML creerà dietro le quinte un container con il modello e un web service per ricevere richieste REST con immagini e restituire la categoria prevista. Il sistema è quindi in grado di scalare automaticamente se il numero di richieste aumenta. Inoltre, grazie a MLOps, si può impostare il monitoraggio continuo delle performance (accuratezza delle predizioni nel tempo) e, se nuove immagini etichettate diventano disponibili, si può programmare un nuovo ciclo di retraining del modello per migliorarlo continuamente.
· Assistente testuale intelligente: un’azienda vuole arricchire la propria applicazione di assistenza clienti con funzionalità AI per analizzare il sentimento delle richieste e trascrivere la voce. Senza addestrare alcun modello da zero, può combinare diversi Azure AI Services: ad esempio, usare il servizio Language (parte dei Cognitive Services) per analizzare le e-mail o i messaggi dei clienti e determinare automaticamente se il tono è positivo, neutro o negativo (sentiment analysis), estrarre entità chiave (nomi di prodotti, numeri di ordine, luoghi) dal testo, e magari eseguire una traduzione se il messaggio non è in italiano. Allo stesso tempo, se l’app include un call center, si può usare Speech to Text per trascrivere automaticamente le chiamate vocali in testo, e poi analizzare anch’esse con i servizi di Language per estrarre dati importanti. Oppure, per fornire risposte automatiche, usare un modello di Azure OpenAI come GPT-4 opportunamente delimitato sulle informazioni aziendali. L’orchestrazione di queste chiamate può essere gestita tramite una Azure Function che riceve ad esempio l’audio o il testo, chiama le API AI appropriate (trascrizione, analisi sentiment) e restituisce un risultato integrato (ad esempio: “Il cliente Chiara Bianchi ha chiamato riguardo al prodotto XYZ, è arrabbiata (sentiment negativo) perché riferisce di un malfunzionamento”). Questo esempio illustra come si possano infondere capacità di AI in applicazioni esistenti sfruttando modelli già pronti di Azure, semplicemente componendo i servizi adatti.
Definizioni utili:
· AutoML (Automated Machine Learning): indica un insieme di tecniche e strumenti che automatizzano in parte il processo di sviluppo di modelli di machine learning. Nel contesto di Azure ML, AutoML permette di definire un problema (es. classificazione binaria, multiclass, regressione o previsione di serie temporali) e lasciare al sistema il compito di provare diversi algoritmi di modellazione (ad esempio alberi decisionali, modelli lineari, reti neuronali) e differenti combinazioni di iperparametri, selezionando automaticamente il modello con le prestazioni migliori sul dataset di validazione. È utile per accelerare la fase di prototipazione quando non si hanno a priori certezze su quale algoritmo funzioni meglio su un dato problema.
· Endpoint gestiti: in Azure ML sono punti di accesso API forniti come servizio per esporre i modelli di machine learning in produzione. Quando si crea un endpoint di inferenza gestito, Azure si occupa di allocare le risorse necessarie (ad esempio istanze di container con CPU/GPU) e di esporre un URL per invocare il modello (tipicamente via HTTP POST con i dati di input). Gli endpoint gestiti semplificano la fase di deployment dei modelli perché integrano automaticamente funzionalità come scalabilità (possono aumentare le istanze con il crescere delle richieste o scalarle a zero se inutilizzate, nel caso di endpoint serverless), autenticazione/autorizzazione, logging delle richieste, e facile rollback in caso si voglia tornare a una versione precedente del modello.
6. DevOps e Application Lifecycle
Azure DevOps è la piattaforma di Microsoft che fornisce un insieme integrato di servizi per gestire l’intero ciclo di vita dello sviluppo software, dalla pianificazione alla scrittura di codice, sino alla build, ai test e al rilascio in produzione. In ambienti aziendali e di team di sviluppo, Azure DevOps funge da collaborative hub centralizzato per implementare metodologie Agile/DevOps garantendo tracciabilità e automazione. I componenti principali di Azure DevOps includono: Azure Boards, Azure Repos, Azure Pipelines, Azure Test Plans e Azure Artifacts.
· Boards: modulo per la gestione di progetti Agile, include bacheche Kanban, gestione di backlog, user story, task, bug, sprint planning e tracking del progresso. Consente ai team di organizzare il lavoro e seguire metodologie Agile/Scrum con strumenti flessibili.
· Repos: è il servizio di controllo versione basato su Git (o Team Foundation Version Control) ospitato sul cloud Azure. Permette ai team di avere repository Git privati e protetti, con funzionalità aggiuntive come pull request integrate, revisione del codice, politiche sui branch (es.: richiedere approvazioni prima di fare merge su main, o attivare build di validazione), e integrazione continua con le pipeline.
· Pipelines: è il sistema di Continuous Integration/Continuous Delivery (CI/CD) che consente di automatizzare le build e i deployment. Si possono definire pipeline di build e rilascio tramite file YAML o tramite interfaccia visuale, specificando passi come compilazione del codice, esecuzione dei test automatici, packaging dell’applicazione e distribuzione su ambienti (dev, test, produzione). Azure Pipelines supporta praticamente ogni piattaforma e linguaggio (ci sono agent per Windows, Linux, macOS) e integra nativamente il deploy verso Azure (App Service, VM, AKS, etc.), ma anche verso altri cloud o ambienti on-premises.
· Test Plans: offre strumenti per definire piani di test, casi di test (anche manuali) e vi eseguire test manuali o automatizzati, integrando i risultati nel ciclo di sviluppo. Utile per gestire la qualità con tracciamento dei requisiti e dei bug.
· Artifacts: fornisce un feed di pacchetti per gestire le dipendenze e gli output di build (artefatti). Supporta formati come NuGet, npm, Maven, Python packages e altri, consentendo ai team di pubblicare e condividere pacchetti di codice riutilizzabili internamente, nonché di conservare gli artefatti delle build (es. file .zip, container docker, ecc.) che poi possono essere usati nelle pipeline di rilascio.
Usando insieme questi servizi, un team può iniziare dal lavoro pianificato su Boards, sviluppare il codice su Repos, attivare automaticamente build e test su Pipelines ad ogni commit, e se tutto passa, distribuire magari in staging e poi in produzione, con monitoraggio continuo della qualità. Azure DevOps è agnostico rispetto alla piattaforma di destinazione e può integrarsi anche con GitHub (ad esempio, usare solo la parte di Pipelines per progetti che stanno su GitHub). Essendo un servizio maturo, supporta anche l’integrazione di controlli di sicurezza (es. scanning del codice, gestione delle dipendenze note vulnerabili) e compliance nel workflow DevOps. Fonti: Per una panoramica generale, vedere “https://learn.microsoft.com/it-it/azure/devops/user-guide/what-is-azure-devops” su Microsoft Learn.
Esempi pratici:
· Pipeline CI/CD per applicazione web: un team sviluppa una web app in .NET. Utilizzando Azure Repos, mantiene il codice sorgente in un repository Git centralizzato. Ogni volta che viene fatto push su il branch principale (main), una Azure Pipeline configurata con un file YAML viene attivata: i passaggi includono (1) build del progetto .NET (compilazione e produzione del pacchetto o della container image), (2) esecuzione dei test automatici unitari e magari di integrazione, (3) se i test passano, pubblicazione di un artefatto (ad esempio un file .zip contenente il deploy web, o una immagine Docker pushata in Azure Container Registry). A seguire, una fase di rilascio (CD) può distribuire automaticamente l’ultima build su un ambiente di staging nell’App Service corrispondente. Grazie agli deployment slots di App Service, la nuova versione viene caricata nello slot di staging; il team può fare verifica manuale e poi tramite la pipeline stessa o manualmente può eseguire uno swap tra slot staging e produzione, rilasciando il nuovo codice in produzione senza downtime. Se qualcosa va storto, App Service consente anche di roll-back rapido (tornare alla versione precedente). Tutti questi passi – build, test, deploy – vengono tracciati nella pipeline CI/CD, e possono essere soggetti ad approvazioni manuali: ad esempio, si può impostare che il passo di deploy in produzione richieda l’approvazione di un responsabile prima di eseguire realmente lo swap. Nel frattempo, il team utilizza Azure Boards per tenere traccia delle feature da sviluppare e dei bug segnalati; ogni commit o pull request può essere associato a un Work Item (es. una user story) in Boards, creando un collegamento tracciabile tra requisiti, codice e release.
· Controllo qualità e sicurezza integrato: un’organizzazione adotta Azure DevOps non solo per automatizzare la consegna del software ma anche per migliorare la sicurezza e la qualità. Ad esempio, su Azure Repos può attivare delle branch policies sul ramo principale: ogni pull request richiede almeno 2 revisori umani (code review) e l’esito positivo di una build di validazione. Nel definire la pipeline di build, il team include anche step di Static Code Analysis con strumenti come SonarCloud o l’analisi degli artifact con Microsoft Defender for DevOps (che controlla segreti nel codice, vulnerabilità note nelle dipendenze, ecc.). Inoltre, usando Azure Artifacts, il team scarica sempre le librerie di terze parti da feed controllati (invece di fonti pubbliche non verificate), avendo così un maggior controllo sulle versioni approvate di componenti open source. Infine, ogni sprint, i tester definiscono su Azure Test Plans dei casi di test per le nuove funzionalità e li collegano ai requisiti su Boards, in modo che quando tutte le suite di test (automatiche e manuali) risultano verdi, il Product Owner possa con confidenza approvare la release. Questo scenario mostra come Azure DevOps aiuti a istituzionalizzare pratiche di quality assurance e DevSecOps (DevOps + Security) nel normale flusso di lavoro degli sviluppatori.
Definizioni utili:
· CI/CD: sta per Continuous Integration e Continuous Delivery/Deployment. La CI è la pratica di integrare frequentemente (anche più volte al giorno) le modifiche di codice nel branch condiviso principale, eseguendo ogni volta una build automatizzata e una suite di test: questo garantisce che le integrazioni tra le modifiche dei vari sviluppatori avvengano regolarmente e che eventuali problemi vengano individuati subito (se qualcosa si rompe, sarà la build continua a fallire, dando feedback immediato). La CD invece riguarda l’automazione della distribuzione delle applicazioni: Continuous Delivery significa avere sempre una build pronta e potenzialmente distribuibile in produzione (anche se magari l’atto di distribuirla può richiedere un’approvazione manuale), Continuous Deployment significa spingere automaticamente in produzione ogni modifica che passi tutti i test e verifiche, senza intervento umano. In entrambi i casi, l’obiettivo è rendere il rilascio di software rapido, frequente e affidabile, eliminando processi manuali soggetti a errore.
· Artifact: nel contesto di DevOps, un artifact è un file o un pacchetto risultante dal processo di build che può essere distribuito o riutilizzato. Ad esempio, compilando un’applicazione Java ottengo un file .jar: quello è un artifact. Compilando un progetto .NET ottengo un .dll o un .zip pronto per il deploy su un server web: anche quello è un artifact. In concetti più ampi, può essere anche un contenitore (Docker image) prodotto che poi viene pubblicato in un registry, o un pacchetto NuGet/NPM generato per essere condiviso. Azure Artifacts è il servizio che permette di conservare e indicizzare questi artifact/pacchetti, versionandoli, per poi riutilizzarli facilmente nelle pipeline di rilascio o come dipendenze in altri progetti.
Riferimenti: per iniziare con Azure DevOps, è consigliabile seguire la https://learn.microsoft.com/it-it/azure/devops/. In particolare, la documentazione “Azure DevOps User Guide” contiene spiegazioni dettagliate di ogni servizio. Sono inoltre disponibili percorsi di apprendimento su Microsoft Learn sia per Azure DevOps che per concetti DevOps generali, ad esempio il percorso relativo all’AZ-400 (certificazione DevOps Engineer) che copre approfonditamente l’utilizzo di Azure DevOps per orchestrare pipeline CI/CD, gestione di repository e test plan.
7. Sicurezza in Azure
La sicurezza nel cloud Azure copre diversi aspetti, dai controlli di identità e accesso fino al monitoraggio continuo della postura di sicurezza delle risorse. In questa sezione tratteremo due macro-aree: la gestione delle identità e accessi, principalmente tramite Microsoft Entra ID (nuovo nome per Azure Active Directory), e la gestione della postura di sicurezza e protezione dei workload tramite Microsoft Defender for Cloud. Entrambi sono servizi fondamentali per implementare il principio di Zero Trust e garantire che gli ambienti Azure siano adeguatamente protetti e conformi alle best practice.
Microsoft Entra ID (Azure Active Directory): Microsoft Entra ID (parte della famiglia Microsoft Entra, precedentemente nota semplicemente come Azure Active Directory) è il servizio di Identity and Access Management (IAM) nel cloud Microsoft. È responsabile di autenticare e gestire gli utenti, le identità applicative, i gruppi e le autorizzazioni di accesso alle risorse. In Azure, ogni utente o applicazione che desidera accedere a una risorsa (macchina virtuale, database, chiave in Key Vault, ecc.) deve essere autenticato da Entra ID e poi autorizzato tramite i ruoli appropriati. Entra ID supporta la definizione di ruoli RBAC (Role-Based Access Control) sulle risorse Azure: ciò significa che si possono assegnare ruoli predefiniti (o personalizzati) agli utenti su specifiche risorse o gruppi di risorse (ad esempio, Mario Rossi è Contributor sul gruppo di risorse XYZ, quindi può creare/modificare qualunque risorsa al suo interno; l’account applicativo di un’app web è Reader su un certo storage, quindi può solo leggere dati). Oltre a RBAC, Entra ID fornisce funzionalità avanzate di sicurezza come l’autenticazione multifattore (MFA) per proteggere l’accesso agli account utente oltre la sola password, e i Conditional Access policies, che permettono di applicare condizioni per l’accesso (esempio: richiedi MFA solo se l’utente accede da un dispositivo non compliant o da una rete esterna, oppure blocca completamente l’accesso se proviene da determinate nazioni). Un’altra componente è il Privileged Identity Management (PIM), che consente di assegnare ruoli amministrativi temporanei agli utenti (invece di fornire diritti elevati permanenti) così da ridurre la finestra di rischio – un amministratore tramite PIM può attivare ad esempio il ruolo di Global Admin solo quando serve, e per poche ore, con approvazione. Microsoft Entra ID è integrato con migliaia di applicazioni (come Office 365, Azure, app di terze parti) per fornire Single Sign-On (SSO) e gestione centralizzata delle identità, ed è un pilastro dell’approccio Zero Trust, in cui ogni richiesta di accesso viene continuamente verificata e nulla è implicitamente fidato anche all’interno della rete aziendale. Fonti: Per approfondire identità e accessi in Azure, si può consultare la sezione Identità della https://learn.microsoft.com/it-it/azure/security/fundamentals/identity.
Microsoft Defender for Cloud: è una soluzione unificata di protezione del cloud, classificabile come una piattaforma CNAPP (Cloud-Native Application Protection Platform) che ingloba funzionalità di CSPM (Cloud Security Posture Management) e di CWPP (Cloud Workload Protection). In parole semplici, Defender for Cloud aiuta sia a valutare continuamente la postura di sicurezza dell’ambiente Azure (e anche di ambienti ibridi o multi-cloud come AWS e GCP) sia a fornire protezione attiva alle risorse in esecuzione (macchine virtuali, container, database, storage). Dal lato CSPM, anche nella versione gratuita, Defender for Cloud analizza la configurazione delle risorse Azure rispetto a un set di best practice e benchmark di sicurezza (ad esempio controlla se le VM hanno porte aperte su Internet, se i database non sono cifrati, se su Storage Account mancano controlli di accesso, ecc.) e calcola un Secure Score aggregato che riflette il livello di sicurezza dell’ambiente: più configurazioni corrette, più alto il punteggio. Fornisce inoltre raccomandazioni dettagliate su come risolvere ciascun problema riscontrato (ad esempio “Abilita la crittografia sul disco della VM X” oppure “Configura MFA per l’account amministratore Y”). Dal lato CWPP, attraverso piani a pagamento denominati Defender plans, il servizio abilita protezioni specifiche per vari tipi di workload:
· Defender for Servers: installa un agente (Azure Monitor Agent con estensioni Defender) sulle VM o macchine fisiche/VM in altri cloud, fornendo funzionalità come l’anti-malware, il file integrity monitoring, il rilevamento di comportamenti anomali, e l’integrazione con Microsoft Defender Endpoint.
· Defender for Storage: analizza i file e i blob nei Storage Account per rilevare malware o attività sospette (ad es. picchi di lettura/scrittura anormali che potrebbero indicare un attacco).
· Defender for SQL/Database, Defender for Containers, Defender for App Service, etc.: moduli che abilitano alert specifici (ad esempio tentativi di SQL injection su un DB gestito, scansioni di vulnerabilità delle immagini container, ecc.).
In aggiunta, Defender for Cloud può integrare con Microsoft Sentinel (il SIEM/SOAR di Azure) per correlare gli alert con altri dati di log e creare un centro operativo sicurezza completo. Utilizzando Defender for Cloud, un’organizzazione ottiene sia una valutazione continua (con quadro compliance e punteggio) sia un rilevamento di minacce su risorse cloud. Fonti: Intro e dettagli sono disponibili nella https://learn.microsoft.com/it-it/azure/defender-for-cloud/defender-for-cloud-introduction.
Esempi pratici:
· Migliorare la sicurezza di identità: una piccola azienda configura Microsoft Entra ID per i propri amministratori e utenti. Come prima cosa abilita l’MFA obbligatoria per tutti gli account con ruoli amministrativi elevati, riducendo drasticamente la probabilità di compromissione di questi account critici anche se una password venisse trafugata. Imposta poi delle Conditional Access policies: ad esempio, permette l’accesso al portale Azure per gli amministratori solo se si trovano sulla rete aziendale o se effettuano MFA, e blocca del tutto l’accesso da paesi dove l’azienda non opera. Inoltre, implementa Privileged Identity Management cosicché i ruoli come “Owner” o “User Access Administrator” sulle subscription Azure non siano tenuti permanentemente: un amministratore per ottenere diritti elevati deve attivare la role elevation tramite PIM, la quale può richiedere un secondo approvatore e scade dopo 4 ore. Queste misure assicurano che l’accesso alle risorse Azure avvenga seguendo il principio del privilegio minimo e con verifiche costanti, in ottica Zero Trust.
· Protezione di workload cloud: un’organizzazione attiva Microsoft Defender for Cloud e sottoscrive i piani Defender for Servers e Defender for Storage per la propria soluzione che prevede VM Linux e Windows e diversi Storage Account. Dopo aver abilitato Defender, il sistema inizia a mostrare nel dashboard Secure Score che ci sono alcune raccomandazioni: ad esempio, indica che su 3 VM manca l’aggiornamento automatico delle patch critiche, oppure che su un Storage Account pubblico non è attivato il logging degli accessi. L’azienda procede a correggere questi punti, migliorando il Secure Score e quindi la postura generale. In seguito, Defender genera un alert segnalando che su una VM è stato rilevato un processo sospetto che potrebbe indicare un tentativo di cryptomining: grazie all’agente di Defender for Servers, l’attività viene bloccata e l’admin riceve l’alert per investigare (scoprendo magari che era stato lasciato aperto l’RDP su quella VM senza MFA). Un altro esempio: su un Storage Account che contiene documenti sensibili, Defender for Storage rileva e avvisa di un accesso massivo insolito, aiutando a scoprire un potenziale abuso di chiavi d’accesso. Grazie a questi strumenti, l’azienda ottiene visibilità e protezione attiva sul proprio ambiente Azure, potendo reagire tempestivamente a incidenti di sicurezza e colmare lacune di configurazione prima che siano sfruttate.
Definizioni utili:
· Secure Score: è un punteggio percentuale assegnato da Defender for Cloud (e visibile anche nel portale Azure Security Center) che riflette il grado di aderenza della configurazione delle risorse alle best practice di sicurezza. Ad ogni raccomandazione viene associato un certo peso; man mano che si risolvono le raccomandazioni (ad esempio abilitare crittografia, correggere configurazioni o abilitare servizi di difesa), il punteggio aumenta. L’idea è fornire un indicatore quantitativo facile da monitorare: un secure score del 100% significherebbe che non ci sono vulnerabilità note nella configurazione. È utile per misurare i progressi nel rafforzare la sicurezza nel tempo e per confronti (benchmark) interni.
· RBAC (Role-Based Access Control): è il modello di gestione delle autorizzazioni usato in Azure (e in molti sistemi) dove l’accesso alle risorse non viene concesso direttamente a specifici utenti caso per caso, ma tramite l’assegnazione di ruoli predefiniti. Un ruolo definisce un insieme di permessi (ad esempio, il ruolo Reader consente sola lettura di una risorsa, Contributor permette di modificarla ma non di gestirne l’accesso, Owner ha controllo completo incluso il managing dei permessi). In Azure, si assegna un ruolo a un principal (utente, gruppo o applicazione di servizio) su un scope specifico (può essere a livello di una singola risorsa, di un gruppo di risorse, o dell’intera subscription). Questo approccio semplifica la gestione in ambienti complessi: invece di creare regole di accesso per ogni utente e ogni risorsa, si definiscono ruoli standard e li si assegna dove necessario.
8. Automazione e Integrazione
Nel cloud, la possibilità di automatizzare processi e orchestrare flussi di lavoro tra servizi diversi è essenziale per creare soluzioni efficienti e reattive. Azure fornisce diversi servizi per implementare automazione e integrazione senza dover costruire tutto con codice infrastrutturale. Tra questi, tre servizi importanti sono Azure Logic Apps, Azure Event Grid e Azure Automation Account (con i runbook). Ciascuno copre un aspetto differente: Logic Apps per orchestrazione di processi low-code, Event Grid per la gestione di eventi in tempo reale, e Automation Account per eseguire script di gestione infrastrutturale in modo pianificato o reattivo.
Azure Logic Apps: è una piattaforma di workflow automation basata su un approccio visivo e a basso codice (low-code). Consente di creare flussi di lavoro integrando diversi servizi e sistemi tramite connettori predefiniti, il tutto definendo una sequenza di azioni e condizioni. In pratica, con Logic Apps si può disegnare un flusso che reagisce a un trigger iniziale (ad esempio l’arrivo di un email, la creazione di un elemento in un database SQL, una chiamata HTTP ricevuta, l’esecuzione pianificata a un certo orario) e poi esegue una serie di azioni preimpostate (inviare un’altra email, inserire un record in un database, chiamare un’API REST, scrivere un file su OneDrive, ecc.) eventualmente con logica condizionale e cicli. Esistono connettori per un’enorme varietà di servizi sia Azure (es: Azure Functions, Service Bus, Blob Storage, Azure AD, Key Vault...) sia esterni/Microsoft 365 (Office 365, SharePoint, Dynamics, Salesforce, Slack, SAP, ecc.), il che fa di Logic Apps uno strumento potentissimo per integrare applicazioni disparate senza dover scrivere codice glue personalizzato. Tipici scenari includono l’automazione di processi aziendali (esempio: quando un modulo viene compilato su un sito web, la Logic App salva i dati su un database, avvisa via email un responsabile e crea un ticket in un sistema gestionale), l’orchestrazione di flussi dati (esempio: trasferire periodicamente file da FTP a Blob Storage e poi notificare un servizio), l’automazione di IT (esempio: se ricevo un certo alert, invia un messaggio Teams e crea un ticket). Logic Apps è serverless – Azure esegue il workflow quando scatenato, scalando all’occorrenza – e consente a sviluppatori e non (anche analisti o IT Pro) di definire integrazioni complesse con una curva di apprendimento bassa. Fonti: Introduzione e dettagli sono disponibili in “https://learn.microsoft.com/it-it/azure/logic-apps/logic-apps-overview” su Microsoft Learn.
Azure Event Grid: è un servizio di routing di eventi totalmente gestito che permette di costruire applicazioni event-driven in modo semplice ed efficiente. In un’architettura orientata agli eventi, componenti producer generano eventi quando qualcosa accade (ad esempio “un nuovo file è stato caricato su un blob storage”, “una VM è stata creata”, “un messaggio è disponibile in una coda”, oppure eventi custom definiti dall’utente), e componenti consumer ricevono questi eventi ed eseguono azioni in risposta. Event Grid funge da bus eventi publish-subscribe: le fonti di eventi (event sources o publisher) pubblicano eventi su Event Grid, e uno o più subscriber (sottoscrittori) si registrano per ricevere specifici eventi (filtrati per tipo, provenienza, soggetto, ecc.). Quando l’evento si verifica, Event Grid lo recapita in modo affidabile ai subscriber, potendo gestire migliaia di eventi per secondo con latenza molto bassa. Molti servizi Azure sono integrati nativamente con Event Grid come emittenti di eventi (ad esempio, un Azure Storage può inviare un evento su Event Grid ogni volta che viene aggiunto un blob; le Resource Group inviano eventi quando una risorsa viene creata/aggiornata/eliminata; IoT Hub invia eventi di telemetria, ecc.). Dal lato subscriber, i tipici handler sono Azure Functions, Logic Apps, WebHook HTTP (endpoint web generici), code di Service Bus o Event Hubs. La differenza rispetto ad esempio a una coda tradizionale è che Event Grid implementa un meccanismo push/pub-sub e può avere più destinatari per lo stesso evento, mantenendo anche funzionalità di filtro incorporato (ad es. invia l’evento solo se il nome del file matcha certe condizioni) e garantendo retry/backoff automatico in caso il subscriber fosse momentaneamente non raggiungibile. In pratica Event Grid facilita la reazione in tempo reale a cambiamenti ed eventi senza bisogno di polling continuo, riducendo la complessità e il carico. Fonti: Vedere “https://learn.microsoft.com/it-it/azure/event-grid/overview” per maggiori dettagli.
Azure Automation Account (Runbook): Azure Automation è un servizio progettato per automatizzare attività di gestione e configurazione all’interno di Azure (e in parte anche su sistemi esterni). Creando un Automation Account, è possibile definire ed eseguire Runbook, ovvero script di automazione scritti in PowerShell, Python, o costruiti tramite un editor grafico. Questi runbook possono essere eseguiti manualmente, schedulati a orari ricorrenti, o attivati da webhook/risposte a eventi. Gli scenari tipici comprendono: automatizzare operazioni di manutenzione su larga scala (accendere o spegnere macchine virtuali in orari programmati per risparmiare costi, pulire log vecchi su storage, riavviare servizi), integrare processi di deploy (ad esempio eseguire script post-distribuzione), o configurare ambienti in modo consistente (tramite Desired State Configuration (DSC), una feature di Automation per applicare configurazioni dichiarative a VM Windows/Linux). Azure Automation fornisce un ambiente gestito in cui questi script vengono eseguiti (in sandbox isolata su worker dedicati), con logging integrato dell’output e possibilità di usare credential e moduli salvati in modo sicuro nell’account. Include anche soluzioni come l’aggiornamento automatico delle patch per VM Windows e Linux e l’inventario/configurazione. In sintesi, è l’equivalente cloud di avere un “job scheduler” o un “automation server” che esegue script di amministrazione sulle risorse, contribuendo a ridurre il lavoro manuale e ad uniformare le operazioni. Fonti: La https://learn.microsoft.com/it-it/azure/automation/automation-intro copre la creazione di runbook PowerShell/Python e l’uso di DSC.
Esempi pratici:
· Workflow di ordine automatico (Logic Apps): un’azienda vuole automatizzare il processo che inizia quando un cliente effettua un ordine sul sito. Invece di implementare tutto a mano in codice, crea una Logic App con il seguente flusso: il trigger è uno webhook HTTP in attesa di dati d’ordine (viene chiamato dall’applicazione e-commerce quando c’è un nuovo ordine). La Logic App, una volta attivata, esegue varie azioni in sequenza: (1) valida i dati dell’ordine (magari usando un connettore per eseguire una query su Azure SQL Database o controllare l’esistenza del cliente), (2) inserisce i dettagli dell’ordine in un sistema CRM o database interno, (3) invia una email di conferma al cliente tramite il connettore di Office 365 Outlook, (4) aggiunge un messaggio in una coda Azure Queue per segnalare al reparto spedizioni di preparare il pacco, e (5) posta un messaggio su Microsoft Teams (tramite connettore Teams) in un canale “nuovi ordini” per notificare il team interno. Tutto questo avviene senza che nessuno scriva codice personalizzato imperativo; il flusso è disegnato e configurato. Se serve modificare una logica (ad esempio aggiungere uno step per generare una fattura PDF e salvarla su Blob Storage), basta aggiungere il connettore corrispondente. Questo esempio illustra come orchestrare facilmente più servizi e azioni business con Logic Apps.
· Gestione eventi infrastrutturali (Event Grid + Functions): immaginiamo di voler monitorare le modifiche di stato delle macchine virtuali (accensione, spegnimento) per mantenere un registro o reagire. In Azure, si può sfruttare Event Grid sottoscrivendosi agli eventi del tipo “Macchina Virtuale avviata/spenta” che Azure pubblica quando un VM cambia stato. Configuriamo quindi un Event Grid Topic che ascolta eventi provenienti da tutte le VM del nostro gruppo di risorse. Come subscriber, registriamo un’Azure Function che verrà invocata ad ogni evento: questa function potrebbe, ad esempio, prendere l’evento e registrare l’operazione in un database log, oppure inviare un avviso email se una VM critica è stata spenta. Grazie a Event Grid, la reazione è immediata e non dobbiamo continuamente interrogare Azure per sapere se la VM è su o giù: è Azure stesso che ci notifica tramite l’evento. Un altro scenario: quando viene caricato un nuovo file in un Blob Storage (evento “Blob Created”), Event Grid invoca automaticamente una Azure Function che elabora il file (per es. genera anteprime se è un’immagine, o trasforma dati). Questo modello event-driven è estremamente efficiente e scalabile, e Azure gestisce tutto il meccanismo di sottoscrizione e consegna eventi per noi.
· Manutenzione pianificata (Automation Runbook): per risparmiare sui costi, un reparto IT vuole spegnere ogni notte le macchine virtuali di sviluppo e riaccenderle al mattino. Con Azure Automation, crea un runbook PowerShell che, dato un elenco/tag di VM, invoca i cmdlet Azure per arrestare le VM. Pianifica poi questo runbook affinché venga eseguito automaticamente ogni sera alle 20:00. Allo stesso modo, un secondo runbook per avviare le VM viene schedulato alle 8:00 del mattino successivo. Una volta testati, questi script funzionano in autonomia giornaliera. Un altro esempio di runbook: ogni settimana eseguire uno script che controlla tutti gli account Storage e cancella i BLOB più vecchi di X giorni in un contenitore di log, per evitare che l’archiviazione cresca indiscriminatamente. Oppure, integrando con servizi on-premises: tramite un Hybrid Runbook Worker (un agente in locale), Azure Automation può eseguire script che interagiscono con sistemi locali, ad esempio per sincronizzare utenti AD on-prem con cloud, o eseguire backup di database on-prem e caricarli su Azure. Tutto questo senza intervento manuale, riducendo gli errori e garantendo che le attività vengano svolte in modo regolare.
Riferimenti: per approfondire l’automazione e integrazione su Azure, vedere: la https://learn.microsoft.com/it-it/azure/logic-apps/ con numerosi esempi di utilizzo di connettori; la https://learn.microsoft.com/it-it/azure/event-grid/ per capire concetti come eventi, temi e sottoscrizioni; la https://learn.microsoft.com/it-it/azure/automation/ per guide su come creare runbook e usare Desired State Configuration. Un buon complemento è anche la sezione Azure Monitor - Alert: molte persone usano un approccio in cui un Azure Monitor Alert (che rileva ad esempio CPU alta su una VM) può avere come azione la chiamata a un webhook o runbook di Automation, ottenendo un altro modo di reagire ad eventi operativi. In generale, Azure offre moltissimi dipartimenti per automatizzare: ad esempio Azure Functions di cui abbiamo parlato in Calcolo, che spesso lavora in tandem con Event Grid e Logic Apps come visto sopra.
9. Analisi dei Dati (Analytics e Big Data)
Con la crescita esponenziale dei dati, Azure fornisce servizi dedicati per l’analisi avanzata, la costruzione di data warehouse su cloud e l’elaborazione di grandi volumi di informazioni (Big Data). Le soluzioni principali in quest’area includono Azure Synapse Analytics, Azure Data Lake Storage e Azure HDInsight, che coprono rispettivamente l’analisi unificata end-to-end, lo storage scalabile per dati analitici, e l’elaborazione di big data con strumenti open-source come Hadoop/Spark.
Azure Synapse Analytics: Synapse è la piattaforma unificata di Azure che combina funzionalità di data integration, data warehousing e big data analytics in un unico servizio. In passato esistevano separatamente Azure SQL Data Warehouse e Azure Data Factory; Synapse li integra aggiungendo anche un ambiente collaborativo per data engineer e data scientist. All’interno di un workspace Synapse si hanno a disposizione:
· Pipelines di integrazione (equivalenti a Azure Data Factory) per orchestrare processi ETL/ELT, spostare e trasformare dati da fonti diverse (connettori per database, file, API, servizi SaaS, ecc.), eseguendo attività in sequenza o parallelo con trigger programmati o attivati.
· Azure Synapse SQL in due modalità: dedicata (un cluster di data warehouse con risorse riservate, adatto a query SQL a elevatissime prestazioni su grandi volumi di dati strutturati) e serverless (un motore SQL on-demand che permette di fare query su file nel Data Lake in formato Parquet/CSV/JSON, pagando per i TB di dati letti, ottimo per esplorazioni ad-hoc senza doversi preoccupare di infrastruttura).
· Apache Spark integrato: nel workspace si possono creare pool Spark ed eseguire job o notebook (compatibili con Databricks in larga parte) per lavorare su dati utilizzando PySpark, Scala, SQL, .NET Spark, con possibilità di accedere direttamente ai dati nel Data Lake o nelle fonti collegate.
· Azure Data Lake Storage Gen2 strettamente integrato: tipicamente ogni Synapse workspace è collegato a un account Data Lake che funge da storage predefinito dove risiedono i dati di interesse (file di big data, output di processi, etc.).
· Studio web integrato: Synapse fornisce un’interfaccia web unica dove è possibile scrivere query SQL, codice Spark, pipeline data factory, e facilmente passare dalla fase di preparazione dati a quella di analisi e visualizzazione (si integra con Power BI per creare report sui dati del warehouse).
In altre parole, Azure Synapse Analytics consente di realizzare un moderno Lakehouse o enterprise data warehouse combinato: i dati grezzi vengono conservati nel Data Lake, si usano pipeline e Spark per pulirli e trasformarli, e si sfrutta poi il motore SQL per aggregare e rendere disponibili i dati a strumenti di BI. Synapse è molto potente perché elimina le barriere tra differenti tipi di analytics (batch, streaming, SQL, noSQL) in un unico luogo. Fonti: Vedere https://learn.microsoft.com/it-it/azure/synapse-analytics/overview per una descrizione più dettagliata.
Azure Data Lake Storage Gen2: è la tecnologia di archiviazione di Azure ottimizzata per i carichi di lavoro di analisi dei dati. In pratica è un’evoluzione di Azure Blob Storage che incorpora un file system gerarchico (simile a HDFS) e funzionalità avanzate per gestire in modo efficiente grandi quantità di file e dati. Data Lake Gen2 è costruito sullo Storage Account di Azure (non è un servizio a parte separato, ma un flag che si abilita su un account di archiviazione) e consente di avere directory e sottodirectory (non solo un container flat di blob), il che facilita l’organizzazione di dataset complessi con struttura annidata (es. /raw/companyX/year=2025/month=11/day=23/datafile.json). Inoltre, supporta ACL posix su file e cartelle, permettendo di definire permessi granulari per utenti/gruppi Entra ID su specifiche directory o file (cosa che il blob storage classico non faceva, essendo a livello di container). Data Lake Storage Gen2 è pensato per scenari in cui si raccolgono dati eterogenei (log, file CSV, immagini, dati IoT, etc.) in quantità massive e poi li si analizza con strumenti come Spark, Hive, U-SQL o Synapse. Ha performance migliorate nelle operazioni tipiche di analytics (ad es. liste di directory numerose) e tariffe speciali per l’operazione append sui file (utili nel caso di streaming). In sostanza, se si deve costruire un Data Lake in Azure, la scelta ideale è usare un account di archiviazione Gen2 come fondazione, approfittando della scalabilità enorme di Azure Storage (capacità in petabyte, throughput elevato) e delle funzionalità di file system. Fonti: La https://learn.microsoft.com/it-it/azure/storage/blobs/data-lake-storage-introduction offre ulteriori informazioni.
Azure HDInsight: è un servizio gestito che offre distribuzioni pronte all’uso di famosi framework open source per big data, come Apache Hadoop, Spark, Hive, HBase, Kafka, Storm, etc., su cluster in Azure. In pratica, HDInsight consente di creare cluster cloud con queste tecnologie senza doversi occupare manualmente di provisioning di VM e installazione del software: con pochi clic si ottiene ad esempio un cluster Spark con N nodi pronto per eseguire job, oppure un cluster Hadoop completo di HDFS e Yarn, o un cluster Kafka per streaming, e così via. Microsoft gestisce patching e monitoraggio del cluster, e l’utente paga per i nodi attivi (potendo anche scalarli). Negli anni, molte funzionalità di HDInsight per Spark/Hadoop sono confluite in alternative come Azure Databricks o Synapse Spark, più integrate; tuttavia HDInsight rimane rilevante per chi ha esigenze particolari di compatibilità open source o vuole usare componenti come HBase (database NoSQL colonnare) o Kafka senza gestirli on-prem. È molto utile per migrare carichi di lavoro Big Data esistenti in Azure, potendo contare su un ambiente familiare (ad esempio portare i job Hive/Hadoop su HDInsight con minima modifica). Inoltre supporta vari linguaggi (Spark in Python/Scala, Hive con HiveQL, streaming con Storm o Spark Streaming, ecc.) e può connettersi a Data Lake Storage come storage di base. Fonti: Per saperne di più: https://learn.microsoft.com/it-it/azure/hdinsight/hdinsight-overview.
Esempi pratici:
· Pipeline di dati con Synapse: una grande azienda ha dati provenienti dal sistema ERP aziendale, e vuole combinarli con dati di telemetria web per analisi avanzate. Utilizzando Azure Synapse Analytics, crea una pipeline (funzionalità di Data Factory integrata) che ogni notte estrae i dati aggiornati dell’ERP (ad esempio vendite, anagrafiche clienti) da un database on-premises tramite un connettore, e li carica nel Data Lake aziendale in formato parquet. Nella stessa pipeline, successivamente vengono eseguite attività di trasformazione: ad esempio lancia un notebook Spark su Synapse che unisce i dati di vendita con i dati di traffico web (già presenti nel Data Lake come file JSON raccolti da Azure Event Hubs), pulisce e aggrega queste informazioni per ottenere una tabella aggregata per analisi (ad es. vendite per regione incrociate con visite al sito). Infine, i risultati vengono scritti in una tabella relazionale all’interno del Synapse SQL pool dedicato (il data warehouse), in modo che gli analisti di business possano collegare Power BI a quella tabella ed ottenere dashboard aggiornate giornalmente. Questo processo ETL end-to-end è tutto orchestrato in Synapse: i dati grezzi risiedono nel Data Lake, la potenza di Spark viene usata per elaborare grandi volumi, e il data warehouse serve la reportistica, il tutto senza bisogno di spostare dati fuori dalla piattaforma.
· Analisi di log IoT in Data Lake: un caso d’uso Big Data comune è raccogliere grandi volumi di dati da sensori IoT per analisi periodiche. Supponiamo di avere milioni di messaggi al giorno da dispositivi che inviano metriche. Questi dati vengono archiviati in un Azure Data Lake Storage Gen2 in formato ad esempio Avro o Parquet, partizionati per data e ora (ciascun giorno ha la sua cartella di file). Per elaborare questi log, si può usare un cluster Azure HDInsight Spark: l’utente avvia un cluster on demand (es. 10 nodi con Spark), esegue uno script PySpark che legge i file dell’ultima settimana dal Data Lake, esegue calcoli (ad esempio calcola medie, deviazioni, individua anomalie per ciascun sensore) e salva il risultato in un’altra area, poi spegne il cluster. Alternativamente, potrebbe usare Synapse Spark o Databricks; l’importante è che Data Lake Storage Gen2 funge da fonte centrale dei dati (“single source of truth”) sfruttabile da molteplici servizi. In un altro scenario, se i dati sono così grandi e complessi da richiedere strumenti specializzati come Hadoop MapReduce o l’ecosistema Hive, si può utilizzare HDInsight Hadoop: si spostano i job Hive esistenti sul cluster HDInsight collegato agli stessi dati nel Data Lake. In questo modo l’azienda sfrutta le competenze e codice open source esistente, ma con la facilità di gestione e scalabilità on-demand del cloud Azure.
10. Governance e Gestione Cloud
Man mano che l’utilizzo del cloud cresce, diventa cruciale avere strumenti per governare in modo efficace l’ambiente, applicando politiche aziendali, controllando i costi e gestendo risorse sia nel cloud Azure sia eventualmente in infrastrutture ibride. Azure offre funzionalità solide in quest’area, tra cui Azure Arc per la gestione unificata di risorse on-premises e multi-cloud, Azure Policy per imporre standard e conformità sulle risorse, e Azure Cost Management + Billing per il monitoraggio e l’ottimizzazione della spesa.
Azure Arc: è una soluzione che estende le capacità di gestione di Azure verso risorse che non si trovano direttamente nel cloud Azure. In pratica, con Azure Arc è possibile connettere e proiettare risorse come server fisici o virtuali on-premises, cluster Kubernetes esterni (anche su altri cloud), database come SQL Server o Azure Data Services in ambienti esterni, all’interno del Portal Azure e del Resource Graph di Azure. Una volta che un server o un cluster è connesso tramite Arc, esso appare come un risorsa Azure a tutti gli effetti (con un ID, un gruppo di risorse, dei tag, ecc.), consentendo di applicarvi Azure Policy, monitoraggio tramite Azure Monitor, scansioni di Defender for Cloud, e persino distribuire applicazioni o configurazioni tramite tecniche come GitOps (soprattutto per i cluster Kubernetes: con Arc for Kubernetes è possibile collegare un cluster K8s e poi distribuire manifest/helm charts da un repo Git in modo dichiarativo). Per i server, Arc installa un agente che li registra su Azure; per i database come SQL Server Arc-enabled, Microsoft fornisce estensioni e gestione centralizzata degli aggiornamenti. C’è anche Azure Arc Data Services che consente di eseguire in ambiente on-prem containerizzato servizi gestiti di dati di Azure come Azure SQL Managed Instance o PostgreSQL Hyperscale. In sostanza, Azure Arc abbatte il confine tra Azure e il resto: se un’organizzazione ha un mix di infrastruttura locale, più cloud e Azure, Arc offre un unico piano di controllo, sebbene logicamente (i workload rimangono dove sono fisicamente). Fonti: https://learn.microsoft.com/it-it/azure/azure-arc/overview.
Azure Policy: è un servizio che permette di definire e assegnare criteri di governance sull’ambiente Azure per assicurare la conformità a requisiti interni o normativi. Con Azure Policy, un amministratore può scrivere regole che specificano come devono essere configurate o limitate le risorse: ad esempio, una policy può imporre che tutti gli storage account debbano avere la crittografia attivata, oppure che nessuna risorsa venga creata al di fuori delle regioni approvate (es. solo “Europe West” e “Europe North”), o ancora che su tutte le VM sia installata l’estensione di monitoraggio, ecc. Azure Policy agisce in due modi: in modalità audit, segnalando (non bloccando) le risorse che violano le regole e producendo così un report di compliance; oppure in modalità deny, rifiutando attivamente le creazioni o modifiche di risorse che non rispettano la policy (ad esempio impedendo proprio al deployment di andare a buon fine se infrange una regola). Esiste anche la possibilità di definire policy di remediation automatica: ad esempio, se la policy richiede che i dischi siano crittografati e ne trova uno non crittografato, può lanciare un’automazione per cifrarlo. Azure fornisce centinaia di definizioni di policy built-in (pronte all’uso, per cose comuni come quelle citate sopra, conformità a CIS benchmarks, tag obbligatori, etc.), e consente di crearne di personalizzate usando un proprio linguaggio JSON di definizione. Le policy possono essere raggruppate in Initiative (insiemi di policy per uno scopo, es. “Iniziativa PCI-DSS compliance” contenente decine di policy). L’adozione di Azure Policy è fondamentale in scenari enterprise per mantenere ordine e standard: ad esempio, un’organizzazione può assicurare che nessuno crei risorse costose fuori controllo, o che certi flag di sicurezza siano sempre abilitati. Nel portale Azure Security Center (ora Defender for Cloud) la sezione Compliancy è alimentata di fatto dalle valutazioni di Azure Policy su determinati set di regole.
Cost Management + Billing: Azure fornisce un insieme di strumenti per monitorare e ottimizzare i costi del cloud. Cost Management (parte integrante del portale Azure, basato su tecnologie di Cloudyn acquisite da Microsoft) consente di visualizzare analisi dettagliate della spesa su Azure: ci sono grafici, report e breakdown per servizio, per gruppo di risorse, per tag, per periodo di tempo. Si possono definire budget mensili/trimestrali/annuali su ambiti (ad esempio budget per sottoscrizione o per gruppo di risorse o per servizio specifico) e impostare alert che notificano via email o sms quando la spesa prevista supera una soglia (es. 80% del budget consumato). Cost Management offre anche raccomandazioni di ottimizzazione: ad esempio, identifica risorse sottoutilizzate (come VM costose con uso CPU molto basso) suggerendo di ridimensionarle, o consiglia l’acquisto di Reserved Instances o Savings Plan per risparmiare sui costi futuri se nota un utilizzo costante di certe risorse (una Reserved Instance permette di pre-acquistare 1 o 3 anni di una VM specifica a costo scontato, portando notevoli risparmi se si prevede di usare quella VM a lungo; i Savings Plan sono simili ma flessibili su famiglie di VM o servizi). Nella parte di Billing, Azure centralizza la gestione delle fatture, metodi di pagamento e gli scope di fatturazione: per grandi aziende magari con contratti Enterprise Agreement, è possibile avere suddivisioni per department o enrollment account e attributi come i Cost Center. In Cost Management, l’uso di tag sulle risorse (esempio tag “Environment: Production” o “Project: XYZ”) consente di generare report per quei tag, utile per riaddebiti interni. In sintesi, Cost Management aiuta a rispondere a domande “Chi sta spendendo quanto? Dove possiamo ridurre costi? Siamo entro i limiti preventivati?”. Fonti: https://learn.microsoft.com/it-it/azure/cost-management-billing/cost-management-billing-overview.
Esempi pratici:
· Gestione risorse ibride con Arc: un’azienda ha ancora molti server on-premises ma vuole consolidare la gestione. Installa l’agente Azure Arc su tutti i server Windows e Linux in datacenter. Ora nel Portale Azure vede ciascun server come “Azure Arc Server” con il proprio nome. L’azienda può assegnare tag a questi server, includerli nei Azure Resource Group insieme a risorse Azure pure, e cosa più importante: applicare Azure Policy centralmente. Ad esempio, definisce una policy Arc per verificare che su ogni server sia installato un certo software di sicurezza, o che i server rispettino una naming convention, e immediatamente ottiene report di quali server non sono compliant. Allo stesso modo, abilita Defender for Cloud sui server Arc: questo fa sì che gli stessi controlli antimalware e raccolta log presenti sulle VM Azure siano estesi alle macchine fisiche, con gli avvisi riportati nel medesimo dashboard di sicurezza. Inoltre, l’azienda sta implementando Kubernetes su AWS: installando Arc for Kubernetes su quei cluster EKS, li gestisce dall’hub Azure, e può persino distribuire configurazioni con GitOps (significa che nel portale Azure crea un Configurazione GitOps indicando un repo Git con manifest YAML, e Arc assicura che su EKS quei manifest siano applicati e sincronizzati). Così, pur avendo risorse sparse, Azure Arc offre un piano unico per governance e operazioni.
· Imposizione di policy di governance: un’organizzazione enterprise vuole assicurare che tutte le risorse create seguano certe regole aziendali. Per esempio, nessun workload di produzione deve stare in regioni diverse da quelle EU per motivi di compliance GDPR. Usando Azure Policy, il team cloud definisce una policy “Allowed Locations” con l’elenco solo di West Europe e North Europe, e la assegna con effetto Deny a tutte le subscription di produzione: da quel momento in poi, se qualcuno prova (anche inconsapevolmente) a creare una VM o un database in East US, il deployment fallirà immediatamente indicando la violazione della policy. Inoltre, per le risorse già esistenti, lo stato di compliance mostrerà quali risorse sono fuori standard (se ce ne erano in disaccordo prima dell’applicazione, risulteranno “non compliant”). Un’altra policy comune è far rispettare convenzioni di tagging: l’azienda impone che ogni risorsa abbia i tag Department e Project compilati, per scopi di rendicontazione. Con Azure Policy può mettere audit su “require tag and its value”: così gli amministratori ricevono liste di risorse sprovviste di tag, da far correggere ai rispettivi proprietari (volendo, potrebbe anche auto-applicare un tag di default con effetto modify). Dal lato sicurezza, definiscono un’iniziativa (collezione) di policy basata sul benchmark CIS Azure: Azure Policy valuterà continuamente la configurazione di tutto (NSG, storage, key vault, ecc.) e segnalerà deviazioni come firewall disabilitati, encryption mancanti, etc. Questi meccanismi aiutano a scalare la governance senza dover controllare manualmente ogni risorsa o affidarsi alla buona condotta di ciascun team.
· Ottimizzazione dei costi: un team Dev ha una subscription Azure per sviluppo e test. Arrivati a metà mese, ricevono un alert email: il budget mensile impostato a $5,000 ha raggiunto l’80%. Aprendo Azure Cost Management, notano che la spesa anomala proviene da una serie di macchine virtuali di test che erano state lasciate accese 24/7. Decidono quindi di spegnerle fuori orario d’ufficio (e eventualmente automatizzare la cosa con un runbook). Inoltre, il grafico dei costi mostra che uno storage account ha generato egress dati notevoli, scoprendo che un collega stava effettuando backup non compressi scaricando decine di TB. Intervengono per bloccare quell’attività, riportando i costi in linea. In un’altra scenario, un’azienda nota che spende costantemente X euro al mese per un set di 20 VM che sono sempre accese per un servizio di produzione. Azure Cost Management raccomanda un Savings Plan o l’acquisto di Reserved Instances per quelle VM per 1 anno, con un risparmio stimato del 30%. Valutato che il servizio continuerà ad essere utilizzato, l’azienda acquista le RI per le VM di quella specifica serie e regione: in questo modo, nei mesi successivi vedrà la spesa effettiva diminuire e restare entro i budget prefissati, senza dover spegnere nulla, grazie allo sconto ottenuto. I report mensili, suddivisi per department (grazie ai tag), vengono inviati automaticamente ai responsabili finanziari così che ciascuno veda quanto il proprio reparto ha consumato in Azure, assicurando trasparenza e responsabilizzazione sui costi IT.
Conclusioni
In questo manuale abbiamo esplorato i principali servizi Azure suddivisi per aree tematiche, evidenziandone caratteristiche, casi d’uso e terminologia chiave. Azure si presenta come un ecosistema ricco e integrato: dai servizi di calcolo e archiviazione di base fino agli strumenti avanzati di intelligenza artificiale e analisi dei dati, senza trascurare aspetti di DevOps, sicurezza e governance indispensabili in contesti reali. Per uno studente o un professionista alle prime armi con il cloud, comprendere questi pilastri permette di avere una visione d’insieme solida e di sapersi orientare nella scelta del servizio giusto per ogni esigenza.
Va sottolineato che l’ambito cloud è in continua evoluzione: nuovi servizi e funzionalità vengono introdotti regolarmente. Pertanto, oltre a questo eBook, è buona pratica consultare la documentazione ufficiale Microsoft e le fonti indicate per approfondire gli argomenti di interesse e rimanere aggiornati sulle ultime novità. Con queste basi, si è pronti per iniziare a progettare e implementare soluzioni su Azure in modo informato e consapevole, sfruttandone al meglio le potenzialità.
Riepilogo capitolo
Il documento fornisce una panoramica dettagliata dei principali servizi offerti da Microsoft Azure, coprendo aree come calcolo, archiviazione, rete, database, intelligenza artificiale, DevOps, sicurezza, automazione, analisi dati e governance cloud. Ogni sezione illustra le caratteristiche, i modelli di servizio, esempi pratici e definizioni utili per comprendere come utilizzare Azure in diversi scenari aziendali e tecnologici.
· Calcolo in Azure: Azure offre servizi di calcolo che spaziano da macchine virtuali IaaS, piattaforme PaaS come App Service, fino a soluzioni serverless con Azure Functions, garantendo flessibilità, scalabilità e modelli di pagamento a consumo per diverse esigenze applicative.
· Archiviazione dati: Lo Storage Account di Azure consente di gestire dati non strutturati, file condivisi, code e tabelle NoSQL con diverse opzioni di ridondanza e tiering per ottimizzare costi e prestazioni. Servizi specializzati come Blob Storage, Azure Files, Queue Storage e Table Storage coprono vari casi d’uso.
· Networking in Azure: Le reti virtuali (VNet), i gruppi di sicurezza (NSG) e il VPN Gateway permettono di creare ambienti cloud isolati, sicuri e connessi sia internamente che con infrastrutture on-premises, con funzionalità avanzate come peering, Private Link e autenticazione multifattore per accessi remoti.
· Database gestiti: Azure SQL Database offre un servizio PaaS per database relazionali con alta disponibilità e scalabilità, mentre Azure Cosmos DB fornisce un database NoSQL multimodello globale con vari livelli di consistenza per applicazioni distribuite e a bassa latenza.
· Intelligenza Artificiale e Machine Learning: Azure Machine Learning supporta l’intero ciclo di vita ML con strumenti di AutoML e deployment di modelli, mentre i servizi AI pre-addestrati (Cognitive Services) offrono API per visione, linguaggio, speech e decisioni, facilitando l’integrazione di AI senza sviluppo da zero.
· DevOps e Application Lifecycle: Azure DevOps integra strumenti per gestione Agile (Boards), controllo versione (Repos), CI/CD (Pipelines), test (Test Plans) e gestione pacchetti (Artifacts), automatizzando il ciclo di sviluppo e migliorando qualità e sicurezza del software.
· Sicurezza in Azure: Microsoft Entra ID gestisce identità e accessi con RBAC, MFA e politiche condizionali, mentre Defender for Cloud monitora la postura di sicurezza e protegge workload con rilevamento minacce e raccomandazioni per la conformità.
· Automazione e integrazione: Azure Logic Apps consente di orchestrare flussi di lavoro low-code, Event Grid gestisce eventi in tempo reale con modello publish-subscribe, e Automation Account esegue runbook per automatizzare operazioni di gestione e manutenzione.
· Analisi dati e Big Data: Azure Synapse Analytics unifica integrazione, data warehousing e big data con SQL serverless e Spark, Data Lake Storage Gen2 offre storage ottimizzato per analytics, mentre HDInsight fornisce cluster gestiti per framework open source come Hadoop e Spark.
· Governance e gestione cloud: Azure Arc estende la gestione a risorse on-premises e multi-cloud, Azure Policy impone regole di conformità e sicurezza, e Cost Management aiuta a monitorare e ottimizzare la spesa cloud con budget, alert e raccomandazioni di risparmio.
CAPITOLO 3 – Il servizio di calcolo
Introduzione
In Azure il termine compute (servizi di calcolo) indica qualsiasi risorsa che permette di eseguire codice: dalle macchine virtuali (VM) IaaS, alle piattaforme PaaS gestite come App Service, fino ai modelli serverless come Azure Functions. L’idea centrale del cloud è che l’utente può eseguire le proprie applicazioni senza gestire direttamente l’infrastruttura hardware sottostante. In altre parole, il cloud provider (Microsoft, nel caso di Azure) si occupa di gran parte della complessità fisica e operativa (data center, hardware, rete, disponibilità), mentre l’utente può concentrarsi sulla configurazione dei servizi e sul codice applicativo. Questa suddivisione delle responsabilità tra provider e cliente è un caposaldo del modello cloud.
Uno dei vantaggi principali del cloud è la scalabilità on-demand: è possibile allocare più risorse o liberarle con pochi clic o automaticamente, in risposta alle esigenze del momento. Inoltre, il modello di pagamento a consumo assicura che vengano addebitate solo le risorse effettivamente utilizzate: non c’è investimento iniziale in hardware e si può adattare la spesa all’andamento reale del carico di lavoro. Tutto questo avviene con un’amministrazione centralizzata: Azure fornisce un portale unificato da cui è possibile impostare criteri di sicurezza, monitorare le prestazioni e automatizzare attività operative su tutte le risorse di calcolo distribuite nel cloud.
Azure mette a disposizione diversi modelli di servizio per il calcolo, che differiscono per il livello di controllo lasciato all’utente e per il grado di gestione automatica offerto dalla piattaforma. In particolare, distinguiamo tre categorie fondamentali:
· IaaS (Infrastructure as a Service): l’infrastruttura virtuale come VM, rete (VNet) e storage (dischi) è fornita dal cloud, ma gestita dall’utente nelle componenti software. L’utente ha massimo controllo sul sistema operativo, sulle configurazioni e sul software installato.
· PaaS (Platform as a Service): una piattaforma gestita che semplifica il deploy e la scalabilità delle applicazioni. Il cloud gestisce automaticamente il runtime, il bilanciamento del carico, i certificati SSL, l’autoscaling, ecc., lasciando allo sviluppatore il compito di occuparsi principalmente del codice applicativo e delle impostazioni della propria app.
· Serverless (Funzioni): un modello in cui l’utente fornisce solo piccoli frammenti di codice o funzioni legate a eventi, e Azure le esegue senza la necessità di gestire alcun server dedicato. L’infrastruttura sottostante è completamente astratta: la piattaforma alloca le risorse automaticamente quando si verifica l’evento, scalando istantaneamente secondo necessità, e la fatturazione è basata esclusivamente sul tempo di esecuzione e sulle risorse consumate da quel codice.
Per chiarire meglio la differenza tra questi modelli, immaginiamo alcuni esempi pratici di scenario:
· Scenario IaaS: un’azienda ha un software gestionale legacy che richiede componenti specifiche e non può essere facilmente adattato a servizi PaaS. In questo caso si può creare una VM Windows dedicata, scegliendo dimensioni adeguate (CPU/RAM) e dischi performanti (es. dischi Premium SSD), il tutto all’interno di una rete virtuale isolata per motivi di sicurezza. In questo modo l’azienda conserva il pieno controllo sull’ambiente (come se fosse un server fisico tradizionale) pur eseguendolo nel cloud.
· Scenario PaaS: per pubblicare un sito web vetrina con un’API back-end, è possibile utilizzare un servizio gestito come Azure App Service. Così si ottiene subito un hosting web scalabile e sicuro, con certificato HTTPS gratuito e funzionalità di autoscale automatico senza dover gestire macchine virtuali sottostanti. Inoltre, grazie all’integrazione nativa con strumenti CI/CD (ad esempio GitHub Actions o Azure Pipelines), il rilascio di nuove versioni dell’applicazione risulta semplificato e rapido.
· Scenario Serverless: per un processo di elaborazione degli ordini in arrivo, si può adottare una soluzione serverless. Ad esempio, implementare una pipeline in cui un’Azure Function si attiva automaticamente al verificarsi di un evento (come l’inserimento di un messaggio in una coda o una chiamata HTTP), elabora l’ordine e lo registra in un database. In questo modello l’azienda paga solo il tempo di esecuzione effettivo della funzione e non deve preoccuparsi di provisioning o gestione di VM: Azure alloca e dealloca le risorse necessarie in maniera completamente automatica.
Questi esempi mostrano come Azure offra soluzioni di calcolo adatte a diverse esigenze: dalle massime prestazioni e controllo di IaaS, alla comodità di una piattaforma gestita PaaS, fino all’agilità delle soluzioni serverless. Nei capitoli successivi approfondiremo ciascuno di questi modelli di servizio e i servizi specifici collegati, analizzandone caratteristiche, vantaggi e best practice d’uso.
Inquadramento argomenti del capitolo con slides illustrate
Nel cloud Azure, il termine compute indica tutto ciò che esegue codice: dalle macchine virtuali, alle piattaforme gestite come App Service, fino ai modelli serverless come Azure Functions. Con il cloud paghi solo ciò che usi e puoi scalare le risorse in pochi clic. Le VM offrono il massimo controllo, mentre App Service e Functions eliminano la complessità infrastrutturale. Tutto si gestisce da una console centralizzata, dove puoi impostare criteri di sicurezza, monitorare le prestazioni e automatizzare le attività. In sostanza, il cloud separa la responsabilità tra provider e utente, semplificando la gestione delle applicazioni. Esempi pratici includono: usare una VM Windows per un gestionale legacy, App Service per un sito vetrina con API, o Functions per un processo di elaborazione ordini. I principali modelli sono: IaaS, ovvero infrastruttura virtuale gestita dall'utente; PaaS, piattaforma gestita che semplifica il deploy; e Serverless, per l'esecuzione a eventi senza server dedicati.
Scegliere tra IaaS, PaaS e Serverless dipende dall'applicazione e dal livello di controllo richiesto. Con IaaS gestisci sistema operativo, patch, rete e storage, ideale per migrazioni o software con dipendenze particolari. PaaS invece semplifica lo sviluppo: la piattaforma gestisce runtime, bilanciamento e certificati, permettendoti di concentrarti sull'applicazione. Serverless consente di definire solo funzioni o eventi: il runtime scala automaticamente e paghi solo per l'esecuzione. Spesso, questi modelli vengono combinati. Esempi: laboratorio di test in VM per IaaS, web app multilingua con autenticazione per PaaS, e elaborazione di file caricati in Blob Storage tramite trigger serverless. Termini chiave sono: autoscale, ovvero la scalabilità automatica delle risorse, e deployment slot, per rilasci senza interruzioni.
Le macchine virtuali in Azure sono utili quando servono componenti o software specifici. Puoi scegliere dimensioni, dischi, rete e disponibilità. Rispetto a PaaS, sei tu a gestire patch, antivirus, hardening e monitoraggio. Le VM possono essere integrate con Scale Sets per l'autoscale e con servizi come Azure Bastion per l'accesso sicuro. Esempi pratici includono: una web farm su VM con Load Balancer e Scale Sets che aumenta le istanze al crescere del carico, oppure una VM grafica con GPU per rendering video. Tra le definizioni importanti: Scale Set, un gruppo di VM identiche che scala automaticamente, e NSG, le regole firewall di rete.
Azure Kubernetes Service, o AKS, è una soluzione gestita che si occupa del control plane, lasciandoti solo il compito di gestire i nodi. Consente deploy dichiarativi, self-healing, scaling orizzontale, rolling updates e gestione dei segreti. AKS semplifica la distribuzione di microservizi, integra la CI/CD e offre osservabilità tramite Container Insights. Per iniziare, puoi definire namespaces, deployments e services, usare ingress per accedere alle app e abilitare autoscaling. Esempi pratici sono l'implementazione di un'applicazione a microservizi con frontend, API e worker, oppure gestire burst di carico con virtual nodes. Alcuni termini chiave: pod, l'unità minima in Kubernetes, e deployment, la risorsa che gestisce repliche e aggiornamenti.
Azure App Service è la piattaforma PaaS per siti web e API. Offre SSL gratuito, integrazione con sistemi di deployment continuo come GitHub Actions e Azure Pipelines, deployment slots per rilasci sicuri e autoscale. Inoltre, puoi integrare l'autenticazione con Microsoft Entra ID, eseguire container personalizzati e proteggere l'app tramite VNet integration. Esempi pratici: API .NET con database SQL sfrutta slot di staging per test e swap verso production; un sito Python può scalare automaticamente e usare CDN per asset statici. Le definizioni da conoscere sono App Service Plan, il profilo di calcolo condiviso da più app, e slot, ambienti paralleli per testare modifiche prima del rilascio.
Azure Functions permette di scrivere piccoli pezzi di logica legati a trigger come HTTP, timer, code, Blob o Event Hub. Grazie ai bindings, puoi collegare input e output senza codice aggiuntivo. I piani Consumption e Premium gestiscono l'autoscale e il cold start; il piano Dedicated è disponibile per esigenze particolari. Le Functions si integrano con Application Insights per monitoraggio e con Durable Functions per orchestrare workflow complessi. Esempi: pipeline ordini che sfrutta trigger HTTP e code, oppure manutenzione automatica con trigger timer. Trigger è l'evento che avvia la funzione, binding è il collegamento a servizi come Queue, Blob o Cosmos DB.
La scalabilità nel cloud Azure si ottiene con Virtual Machine Scale Sets per le VM, autoscale per App Service e Functions, e HPA su AKS. Oltre al classico scale-out e scale-in, Azure offre anche autoscale predittivo, basato su machine learning. Per garantire l'alta disponibilità, si distribuiscono le risorse su Availability Zones, si configurano backup e disaster recovery, e si progettano architetture stateless con bilanciamento del carico e health probes. Le regole di autoscale tipiche sono: aumento delle istanze se la CPU supera il 70% per 10 minuti, riduzione se scende sotto il 30%. HPA è l'autoscaler orizzontale di Kubernetes, mentre Availability Zone indica data center separati nella stessa regione.
Azure Automation consente di automatizzare attività ripetitive tramite runbook scritti in PowerShell o Python. Puoi gestire risorse sia in Azure che on-premises grazie a Hybrid Runbook Worker. Include State Configuration per garantire la conformità delle configurazioni e Update Management per il patching delle VM. I runbook possono essere avviati da Logic Apps, Functions, Azure Monitor o webhook, abilitando flussi DevOps e ITSM. Esempi: spegnimento automatico delle VM non produttive di notte o backup database tramite runbook che avvia la VM, esegue il dump e carica i dati su Blob Storage. Runbook è lo script automatizzato, Hybrid Runbook Worker l'agente che esegue i runbook vicino alle risorse.
Azure Monitor raccoglie metriche, log e tracce da tutte le risorse, sia in cloud che on-premises. Con Application Insights analizzi le performance applicative, mentre gli alert attivano azioni come email, webhook o runbook. Le Insights forniscono visualizzazioni rapide per VM, container e rete. Per la sicurezza, Microsoft Defender for Cloud offre un'unica soluzione per la postura di sicurezza, protezione dei carichi e DevSecOps, calcola il secure score, propone raccomandazioni e verifica la conformità. Integrazione tra Monitor e Defender permette di individuare rapidamente anomalie e vulnerabilità e automatizzare la risposta. Alcuni termini: Log Analytics workspace, l'archivio dei log, e secure score, l'indicatore della postura di sicurezza.
Con Microsoft Cost Management + Billing puoi monitorare e controllare la spesa cloud. Visualizzi i costi per servizio, imposti budget con alert, abiliti l'anomaly detection, e analizzi la copertura di Reservations e Savings Plans. Le pratiche FinOps includono: tagging coerente delle risorse, right-sizing delle VM, spegnimento delle risorse inattive, scelta di piani riservati per carichi prevedibili e valutazione dell'Azure Hybrid Benefit. L'invoice viene generata poche ore dopo la chiusura del mese e i dati possono essere esportati verso Power BI. Esempi: impostare un budget mensile con alert all'80% e 100%, ottimizzare le VM riducendo la dimensione o acquistando riserve per istanze sempre attive. Scope indica il perimetro di analisi, Reservation e Savings Plan sono impegni di spesa che consentono sconti sul compute.
1. Modelli di servizio: IaaS, PaaS e Serverless
Scegliere il modello di servizio adeguato in Azure dipende dal tipo di applicazione che si deve eseguire e dal livello di controllo o intervento che si desidera mantenere sull’infrastruttura sottostante. I tre modelli principali – IaaS, PaaS e Serverless – rappresentano un continuum: si va dall’avere più controllo e responsabilità (IaaS) a meno oneri gestionali e più automazione (serverless). Vediamo in dettaglio ciascun modello:
Infrastructure as a Service (IaaS): Con l’IaaS, Azure mette a disposizione componenti di infrastruttura virtuale di base (server virtuali, rete, storage) che l’utente deve però gestire e configurare quasi come farebbe in un proprio data center. Questo significa che si è responsabili dell’installazione e manutenzione del sistema operativo, dell’applicativo, dell’applicazione di patch di sicurezza, della configurazione della rete virtuale, del firewall e così via. L’IaaS è ideale per scenari di migrazione diretta (lift-and-shift) di applicazioni esistenti, oppure per software che richiedono configurazioni molto particolari o dipendenze non supportate dai servizi gestiti. In cambio di questa maggiore flessibilità, c’è più lavoro amministrativo: l’utente deve amministrare l’istanza come farebbe con un vero server. Esempio tipico: un laboratorio di test per un vecchio ERP aziendale, implementato creando alcune VM in rete isolata, su cui si possono scattare snapshot e su cui si ha il pieno controllo per installare qualsiasi software necessario.
· Platform as a Service (PaaS): Con il PaaS, Azure fornisce un’ambiente applicativo completo e gestito, occupandosi automaticamente di molti aspetti operativi come il runtime, il bilanciamento del carico, la gestione dei certificati TLS/SSL, il sistema di autoscaling e altro. Lo sviluppatore può così concentrarsi sullo sviluppo del codice e sulla configurazione logica dell’applicazione, senza doversi preoccupare di gestire il sistema operativo o l’infrastruttura sottostante. PaaS è l’ideale per aumentare la produttività e ridurre il time-to-market, poiché consente di distribuire applicazioni rapidamente e in modo standard, con alta scalabilità integrata. Tuttavia, rispetto a IaaS, offre meno libertà su alcuni dettagli di configurazione a basso livello (dato che molti elementi sono preconfigurati dalla piattaforma). Esempio tipico: la realizzazione di una web app multi-linguaggio con autenticazione integrata (ad esempio tramite Microsoft Entra ID, ex Azure AD) e funzionalità di deployment slot per gestire ambienti di staging e produzione. In questo scenario, usare App Service (un’offerta PaaS) permette di avere queste funzionalità pronte all’uso: ci sono slot di staging per testare le nuove versioni prima di pubblicarle, supporto integrato per l’autenticazione degli utenti e possibilità di scalare l’applicazione semplicemente variando il piano di servizio.
· Serverless: Nel modello serverless – come implementato da Azure con servizi quali Azure Functions o Azure Logic Apps – il concetto di server su cui gira il codice è completamente astratto. Lo sviluppatore definisce soltanto la logica da eseguire e specifica quali eventi o trigger la attivano; tutta la gestione dell’infrastruttura per eseguire quel codice è responsabilità di Azure. Il serverless è estremamente elastico: il runtime scala automaticamente in base al carico di lavoro (anche fino a zero processi in assenza di eventi), e il costo è calcolato in base alle invocazioni e alle risorse effettivamente utilizzate durante l’esecuzione. Questo modello riduce al minimo gli oneri operativi, ma è adatto principalmente a carichi di lavoro stateless e segmentati in funzioni autonome. Esempio tipico: l’elaborazione di file caricati su uno storage Blob. Si può configurare una Function che si attiva automaticamente ogni volta che un nuovo file viene salvato in un container Blob e processa quel file (ad es. generando anteprime, analizzando contenuti, ecc.). Grazie al serverless, l’elaborazione avviene solo quando necessario e non si paga alcuna VM in standby nei periodi di inattività.
Spesso, nelle architetture cloud più avanzate, i tre modelli coesistono e si integrano: ad esempio, si potrebbe avere un backend di API esposto su una Web App in App Service (PaaS), che invoca funzioni serverless per compiti asincroni o a richiesta, e magari mantenere una VM in IaaS per eseguire un componente legacy o altamente specializzato che non può essere portato su PaaS. Questa combinazione permette di sfruttare il meglio di ciascun modello dove più serve: controllo totale dove indispensabile, gestione semplificata e autoscaling dove possibile.
2. Azure Virtual Machines (IaaS) – Controllo e flessibilità
Le Azure Virtual Machines (VM) sono spesso la prima risorsa a cui si pensa parlando di calcolo cloud, perché offrono un ambiente simile a un server fisico tradizionale ma con tutti i vantaggi della virtualizzazione in Azure. Le VM sono utili quando occorrono componenti specifici, driver particolari o software che non può essere facilmente eseguito in ambienti PaaS o serverless. Con le VM si ottiene il massimo controllo: è possibile scegliere il sistema operativo (Windows o varie distribuzioni Linux), la dimensione in termini di CPU/RAM, tipologia e dimensione dei dischi (Standard HDD, SSD Premium, Ultra SSD, ecc.), la configurazione di rete (ad esempio sottoreti dedicate, NSG per filtrare il traffico) e anche opzioni di disponibilità avanzate come le Availability Zone o i Virtual Machine Scale Sets. In pratica, una VM Azure è l’equivalente di un server nel data center, su cui l’utente ha privilegi di amministratore.
Va ricordato che optare per IaaS (quindi per VM) comporta anche maggiore responsabilità operativa. Rispetto a una soluzione PaaS, usando VM dovremo occuparci di gestire gli aggiornamenti e le patch del sistema operativo, l’installazione e l’aggiornamento degli antivirus, l’hardening della macchina (messa in sicurezza), i backup dei dati applicativi e il monitoraggio dell’interno del sistema operativo (processi, event log, ecc.). Si tratta di attività che in un servizio gestito verrebbero in gran parte curate dalla piattaforma, mentre con le VM spettano all’utente o al team IT, proprio come accadrebbe on-premises. Azure fornisce comunque strumenti per facilitare queste operazioni (ad esempio Azure Automation per il patching automatico, Backup per i backup, Monitor per la telemetria di VM, ecc.), ma è importante essere consapevoli del lavoro aggiuntivo.
Le VM Azure si integrano bene con altri servizi cloud per migliorarne l’utilizzo. Ad esempio, è possibile inserire le VM in Availability Set o usare gli Scale Set per distribuirle su diversi nodi fisici e ottenere alta disponibilità e scalabilità automatica. Uno Scale Set consente di gestire un gruppo di VM identiche che Azure può aumentare o diminuire di numero in base a regole di autoscaling predefinite (ad esempio aggiungendo istanze quando il carico cresce oltre una certa soglia). Per la sicurezza e l’accesso, c’è Azure Bastion, un servizio che permette di connettersi alle VM direttamente tramite il portale Azure (via browser web) in modo sicuro, senza dover esporre porte RDP/SSH pubbliche. Inoltre è prassi configurare appropriate regole di firewall sulle subnet tramite Network Security Group (NSG), che consentono o bloccano il traffico in ingresso/uscita in base a indirizzi, porte e protocolli.
Esempi pratici: Un tipico scenario IaaS è la realizzazione di una web farm su VM. Supponiamo di dover eseguire un’applicazione web ad alto traffico su più istanze per bilanciare il carico. Possiamo creare un set di VM identiche dietro a un Load Balancer Azure (che distribuisce il traffico in ingresso tra le VM) e utilizzare regole di autoscaling su uno Scale Set affinché, se l’uso di CPU su ciascuna VM supera ad esempio il 70% per più di 10 minuti, venga automaticamente avviata un’istanza VM aggiuntiva. Al contrario, se il carico scende sotto una certa soglia, il numero di VM può essere ridotto per risparmiare risorse. Le comunicazioni sono protette da un NSG che filtra l’accesso alle porte dell’applicazione per permettere solo il traffico lecito. Questo garantisce sia scalabilità (adattando le risorse in base al carico) sia sicurezza e isolamento in rete.
Un altro scenario è l’uso di VM specializzate per esigenze particolari di calcolo. Ad esempio, per compiti di rendering video o elaborazioni grafiche intensive, Azure offre VM con GPU potenti (come le serie NVads ottimizzate per grafica). Si potrebbe quindi creare una VM con GPU per eseguire un software di rendering, abbinandola magari a dischi Premium SSD v2 che offrono alta velocità e bassa latenza sullo storage. In questo caso pagheremo solo per il tempo in cui la VM “di calcolo intensivo” rimane accesa, potendola spegnere quando non serve, e avremo comunque un livello di prestazioni elevatissimo grazie all’hardware dedicato, il tutto configurabile in pochi minuti dal portale Azure.
3. Container e orchestrazione con Azure Kubernetes Service (AKS)
Nel panorama del cloud moderno, oltre alle VM, un ruolo fondamentale è svolto dai container e dalle piattaforme di orchestrazione come Kubernetes. Azure offre il servizio Azure Kubernetes Service (AKS), che è una soluzione gestita di Kubernetes: ciò significa che Azure si occupa di preparare e gestire per noi l’infrastruttura del control plane (i nodi master che controllano il cluster), mentre noi dobbiamo occuparci solo dei nodi agent (worker nodes) su cui girano i container, pagando solo questi ultimi in base all’uso. AKS offre quindi tutti i vantaggi di Kubernetes (la piattaforma open-source standard per l’orchestrazione di container) senza il carico di dover gestire manualmente un cluster completo.
Con AKS è possibile effettuare il deploy delle applicazioni in modo dichiarativo (descrivendo lo stato desiderato tramite file YAML), ottenere self-healing (i container vengono riavviati automaticamente se cadono in errore), effettuare scaling orizzontale aggiungendo più istanze di un servizio quando aumenta il carico, gestire rolling updates (aggiornamenti graduali senza downtime significativo) e utilizzare meccanismi di configurazione sicura come le Secret per memorizzare credenziali da usare nei container. Il tutto beneficia dell’ecosistema Kubernetes, per cui AKS è compatibile con strumenti standard e certificato dalla CNCF (Cloud Native Computing Foundation), garantendo conformità e interoperabilità con le applicazioni containerizzate sviluppate secondo gli standard aperti.
Uno dei vantaggi principali di usare AKS su Azure sta nella standardizzazione e automazione: rispetto a distribuire applicazioni container su VM “naked”, AKS fornisce un ambiente coerente dove i microservizi sono gestiti in modo uniforme. Questo semplifica anche la CI/CD (Continuous Integration/Continuous Deployment): combinando AKS con servizi come Azure DevOps o GitHub Actions si può automatizzare l’intero ciclo di build e rilascio di container, sapendo che il cluster applicherà gli aggiornamenti in modo controllato (ad esempio tramite rolling update) e garantirà che il numero desiderato di istanze sia sempre in esecuzione (autoscaling). Inoltre, AKS si integra con Azure Monitor attraverso Container Insights per offrire un’osservabilità approfondita del cluster: log dei container, metriche di performance dei pod, stato dei nodi, ecc., tutto centralizzato per facilitare il monitoraggio. Dal punto di vista della sicurezza, AKS eredita le misure di base di Azure (ad esempio si può utilizzare Azure AD per autenticare le richieste al cluster, gestire i ruoli Kubernetes via RBAC integrato con AD) ed essendo un Kubernetes conforme upstream, permette di applicare politiche di sicurezza e configurazioni avanzate come su qualsiasi cluster Kubernetes standard.
Per iniziare a utilizzare AKS in un progetto, in genere si definiscono innanzitutto i namespace Kubernetes (per isolare gruppi di risorse per ambiente o modulo applicativo), quindi si descrivono i deployment (che specificano l’immagine del container da eseguire, il numero di istanze desiderate e come eseguire gli aggiornamenti) e i service (che espongono i pod su rete rendendoli raggiungibili, ad esempio definendo un load balancer o un cluster IP interno). È comune usare un oggetto Ingress per gestire gli endpoint HTTP/HTTPS verso i servizi applicativi nel cluster, spesso integrato con certificati TLS per la sicurezza end-to-end. AKS supporta anche la configurazione di Horizontal Pod Autoscaler (HPA), che è il meccanismo Kubernetes per aumentare o diminuire automaticamente il numero di pod di un certo deployment al variare di metriche come l’utilizzo di CPU o la coda di messaggi. Naturalmente, per tenere sotto controllo il comportamento e il costo del cluster, è importante integrare tutto con Azure Monitor: i log e le metriche raccolte (tramite ad esempio un Log Analytics Workspace) consentono di impostare alert e di diagnosticare eventuali problemi di performance o errori applicativi all’interno dei container.
Esempi pratici: Consideriamo un’applicazione a microservizi composta da tre componenti: un front-end web, un’API e un servizio di elaborazione in background (worker). Con AKS possiamo deployare ciascuno di questi componenti come un gruppo di container separati (ad esempio un Deployment per il front-end, uno per l’API e uno per il worker), magari all’interno di namespace diversi per organizzazione. Possiamo configurare per ciascun deployment un Horizontal Pod Autoscaler basato su metriche (ad esempio, se la CPU del pod API supera il 70% su intervalli di 5 minuti, l’HPA aggiunge un ulteriore pod). Possiamo impostare un Ingress Controller con certificato TLS che instradi le richieste HTTP verso il servizio giusto (front-end o API). Durante gli aggiornamenti del software, Kubernetes eseguirà rolling update: ad ogni nuova versione del container, i pod vengono aggiornati gradualmente per evitare interruzioni complete del servizio. Se uno dei container si blocca, il meccanismo di self-healing lo riavvierà automaticamente. Questo scenario mostra come AKS consenta di ottenere scalabilità, affidabilità e aggiornamenti senza downtime in modo relativamente semplice, delegando a Kubernetes/Azure molti dei compiti complessi di orchestrazione.
Un altro scenario è la gestione dei carichi variabili o imprevedibili. Immaginiamo un servizio che in condizioni normali usa poche risorse, ma che può avere picchi improvvisi (per esempio un sito web che normalmente ha pochi utenti ma può essere bersaglio di impulsi di traffico in determinate occasioni, come promozioni lampo). Con AKS possiamo sfruttare i virtual nodes, un’integrazione con Azure Container Instances (ACI) che consente di aggiungere in pochi secondi nodi aggiuntivi basati su container serverless quando il cluster AKS si trova a dover gestire un carico eccezionalmente alto. In pratica, durante il picco AKS “estende” il cluster su ACI creando pod aggiuntivi su questi nodi virtuali (che non richiedono di essere pre-provisionati come i nodi standard), e li elimina quando non servono più. Questo permette di assorbire burst di traffico senza dover tenere sempre in esecuzione un numero eccessivo di VM nel cluster (con relativo costo). L’esperienza per l’utente finale rimane stabile, mentre il team tecnico non deve intervenire manualmente: l’orchestrazione auto-scalante di AKS si occupa di tutto.
4. Azure App Service – Ospitare applicazioni web e API (PaaS)
Azure App Service è il servizio PaaS di Azure dedicato all’hosting di applicazioni web, siti e API in modo completamente gestito. Utilizzando App Service, uno sviluppatore può distribuire la propria applicazione web su Azure senza doversi preoccupare di gestire macchine virtuali, di configurare un bilanciamento del carico o di impostare manualmente un server web: la piattaforma fornisce tutto questo come servizio. Tra le funzionalità integrate più apprezzate di App Service ci sono il supporto automatico per HTTPS/SSL (incluso un certificato SSL gratuito fornito da Azure), l’integrazione nativa con servizi di CI/CD come GitHub Actions e Azure Pipelines per automatizzare i deploy, e la disponibilità dei deployment slot per gestire ambienti di staging e produzione senza interruzioni. Ad esempio, si può avere uno slot “staging” su cui pubblicare la nuova versione dell’app, testarla con calma, e poi scambiarlo (swap) con lo slot “production” in modo che la nuova versione diventi attiva in produzione in pochi secondi e senza downtime percepibile. Inoltre App Service supporta la scalabilità automatica: è possibile configurare regole di autoscale in base a parametri come l’utilizzo di CPU o la quantità di richieste, in modo che Azure aumenti o diminuisca il numero di istanze dell’applicazione per gestire il carico.
Quando si crea un’istanza di App Service, si sceglie un App Service Plan, che determina le risorse di calcolo assegnate (quantità di CPU, memoria, spazio su disco, ecc.) e le funzionalità disponibili. Gli App Service Plan sono suddivisi in tier (gratuito, Shared, Basic, Standard, Premium) con caratteristiche crescenti: ad esempio nei tier più alti ci sono funzionalità come il supporto ai domini personalizzati con certificati, l’autoscaling, l’integrazione con la rete virtuale e così via. Più App Service (siti o API) possono condividere lo stesso App Service Plan se devono risiedere sulla stessa infrastruttura e tier di servizio, ottimizzando i costi. Una volta definito il Plan, pubblicare un’app su App Service è questione di pochi passaggi: si possono usare strumenti come git push, FTP, o le pipeline di DevOps per caricare il codice. Azure si occupa di far girare l’applicazione in uno o più container (dietro le quinte) secondo le risorse del piano scelto.
Azure App Service supporta una vasta gamma di tecnologie e linguaggi: .NET, Java, Node.js, Python, PHP, Ruby, e persino container Docker personalizzati. Si può infatti scegliere di eseguire un container personalizzato all’interno di un App Service, puntando a un’immagine Docker ospitata in un registro (Azure Container Registry o Docker Hub), se si ha la necessità di un runtime particolare non fornito nativamente. È anche possibile abilitare la integrazione con la VNet Azure, nel caso serva che l’app acceda in modo sicuro a risorse in una rete virtuale (ad esempio un database SQL Server su VM, o servizi disponibili solo via rete interna). Dal punto di vista operativo, App Service offre opzioni per configurare backup pianificati dell’app (includendo sia il codice sia eventualmente il database collegato), il tutto direttamente dal portale Azure. Inoltre, l’integrazione con Microsoft Entra ID (già Azure AD) consente di gestire facilmente l’autenticazione degli utenti sulle applicazioni web, abilitando login enterprise senza dover scrivere codice di autenticazione.
Esempi pratici: Un esempio comune è l’hosting di una API REST scritta in .NET (ad esempio ASP.NET Core) con database SQL Server. Creando un App Service Plan di livello Standard e un’istanza di App Service, possiamo pubblicare l’API e usufruire subito di funzionalità come la scalabilità automatica (ad esempio impostando che oltre 10 richieste al secondo per istanza venga attivata una seconda istanza) e i deployment slot. Possiamo avere uno slot di staging dove testare nuove versioni dell’API con un piccolo subset di utenti o su cui eseguire test automatici, e poi eseguire uno swap per promuovere la release in produzione senza interruzioni. Durante il processo, App Service può integrarsi con GitHub Actions per prendere automaticamente il codice dalla repository GitHub dell’azienda ogni volta che viene creato un nuovo tag di release, compilarlo e distribuirlo nello slot di staging – realizzando così una pipeline CI/CD completa senza dover mantenere infrastrutture di build separate.
Un altro scenario può essere l’hosting di un sito web in Python (Django o Flask). Supponiamo di avere un sito che subisce picchi di traffico durante eventi particolari (es. una campagna di marketing). Pubblicandolo su App Service, possiamo configurare uno scale-out automatico: ad esempio, aggiungere fino a 3-4 istanze aggiuntive dell’app in orari di punta, e poi tornare a 1 sola istanza nei periodi di calma. Inoltre, per migliorare le prestazioni dei contenuti statici del sito (immagini, file CSS/JS), potremmo attivare una CDN (Content Delivery Network) che funziona in complemento all’App Service, distribuendo quei file da cache di edge nodes globali per ridurre la latenza verso gli utenti. In questo modo, anche un progetto relativamente semplice beneficia di funzionalità enterprise: alta disponibilità, risposta elastica al carico e distribuzione globale dei contenuti, il tutto con sforzo minimo e senza dover amministrare server web manualmente.
5. Azure Functions – Calcolo serverless basato su eventi
Passando al modello serverless, Azure Functions è il servizio di Azure che permette di eseguire funzioni event-driven, ovvero piccoli snippet di codice che si attivano in risposta a eventi o condizioni, senza la necessità di gestire un’infrastruttura server persistente. Con Azure Functions, si definisce una function scritta in linguaggio a scelta (C#, JavaScript/TypeScript, Python, etc.) e la si lega a un trigger che ne causa l’esecuzione. I trigger possono essere di vari tipi: una chiamata HTTP ricevuta, un messaggio inserito in una coda di storage, un file caricato in un Blob Storage, uno schedulatore temporale (timer) che scatta a intervalli regolari, un evento su un Event Hub o Service Bus, e molti altri. Questa architettura consente di costruire applicazioni reattive ed estremamente scalabili, componendo tanti piccoli servizi indipendenti (le funzioni) che si attivano solo quando necessario.
Un aspetto chiave di Azure Functions è il concetto di binding: i binding sono modi dichiarativi per collegare la funzione ad altre risorse per input e output, senza che il codice debba gestire esplicitamente le connessioni. Ad esempio, si può configurare un input binding verso una tabella di database o un output binding verso una coda: all’interno della funzione si interagirà direttamente con un oggetto (es. un oggetto database row o queue message) senza dover scrivere il codice di accesso a quella risorsa – è la piattaforma Functions che si occupa di leggere/scrivere su tali risorse secondo la configurazione fornita. Questo accelera lo sviluppo eliminando molto boilerplate. Le Functions supportano estensioni per binding a tantissimi servizi Azure (Cosmos DB, Storage, SendGrid, etc.), rendendole ideali come glue code per integrare vari servizi.
Dal punto di vista dei modelli di hosting, Azure Functions offre tre piani principali:
· Il Consumption Plan, che è l’impostazione serverless pura: le istanze di funzione vengono create e distrutte dinamicamente in base alla necessità. Si paga solo il tempo di esecuzione e le risorse utilizzate. Questo piano ha anche uno scaling automatico virtualmente illimitato (in base ai limiti interni di Azure) e può istanziare centinaia di esecuzioni parallele se arrivano moltissimi eventi contemporaneamente. Di contro, può soffrire di un leggero cold start (ritardo di avvio) quando una funzione non viene invocata per un po’ e poi deve riavviarsi, perché in quel momento Azure deve allocare un nuovo container per eseguirla.
· Il Premium Plan, che è simile al Consumption (serverless con auto-scale) ma prevede istanze pre-riservate per evitare il cold start e offre maggiori risorse per singola esecuzione. Ha un costo fisso per tenerle sempre pronti, ma utile per funzioni critiche che devono essere più responsive. Anche qui la fatturazione tiene conto delle esecuzioni, ma con un pre-allocato di risorse sempre attivo.
· Il Dedicated (App Service) Plan, in cui le Functions girano su un App Service Plan dedicato, condiviso magari con una Web App. In questo caso non c’è auto-scale automatico basato su eventi (a meno di configurare l’autoscale del Plan), e si paga come un normale App Service Plan (quindi per istanza/vm al mese), ma permette di usare Functions in ambienti dove serve tenere macchine sempre accese o integrarci con reti virtuali senza le limitazioni dei piani serverless. Spesso questo piano è scelto per esigenze particolari di compatibilità o per eseguire Functions in reti isolate.
Le Azure Functions sono pensate per integrarsi bene con gli altri servizi Azure in architetture complesse. Ad esempio, è immediato collegarle con Application Insights, il modulo di Azure Monitor, per ottenere tracce dettagliate e metriche sulle esecuzioni (tempi di esecuzione, errori, conteggio invocazioni, ecc.). Per scenari più avanzati che richiedono workflow multi-step o stato, c’è l’estensione Durable Functions, che permette di orchestrare funzioni e mantenere uno stato fra un’invocazione e l’altra (implementando pattern come function chaining, fan-out/fan-in, orchestrator/actor, utili per processi business più articolati). Il tutto mantenendo il modello di programmazione dichiarativo: ad esempio, definendo nel codice un’orchestrazione Durable, Azure si occupa di chiamare e mettere in attesa le funzioni figlie, persistere lo stato in uno storage e riprendere al momento opportuno.
Esempi pratici: Un classico caso d’uso di Azure Functions è la realizzazione di una pipeline di elaborazione ordini in un e-commerce. Si può strutturare così: una Function esposta via trigger HTTP funge da endpoint per ricevere nuovi ordini; quando viene chiamata, esegue la validazione dei dati e poi inserisce l’ordine in una coda di Azure Storage (questo può avvenire comodamente tramite un output binding). A quel punto un’altra Function, configurata con trigger sulla medesima coda (quindi si attiverà automaticamente per ogni nuovo messaggio), prende in carico l’ordine e svolge operazioni di business logic (ad esempio registra l’ordine in un database, invia una notifica, ecc.). Questa suddivisione consente di assorbire picchi di richieste: la prima funzione risponde subito al cliente mettendo in coda l’ordine, e l’elaborazione avviene in background; se arrivano 100 ordini contemporaneamente, Azure scalerà le funzioni di lavorazione in parallelo senza problemi. Il tutto senza aver allocato preventivamente alcun server – quando non ci sono ordini, nessuna funzione gira e non ci sono costi.
Un altro esempio è un’operazione di manutenzione pianificata: ad esempio, ogni notte si vuole eseguire una pulizia di log o l’invio di un report aggregato. Con Azure Functions, basta scrivere una function con trigger di tipo Timer (ad esempio “ogni giorno alle 3:00 AM”) che esegua il codice desiderato. Azure si occuperà di far partire questa funzione all’orario programmato. Possiamo immaginare una funzione che ogni notte controlla i log di applicazione del giorno precedente, estrae alcune metriche di riassunto e invia un’email con un report. Grazie al modello serverless non c’è bisogno di avere un server Windows schedulato o un cron job su un VM Linux sempre accesa: la funzione “vive” solo quando è il momento di eseguire il task, e poi viene scaricata, con un modello molto efficiente dal punto di vista dei costi.
(Nota: trigger indica l’evento o la condizione che fa scattare l’esecuzione di una Function, ad esempio una richiesta HTTP o un nuovo messaggio in coda; binding indica un collegamento configurato a una risorsa esterna, che semplifica l’accesso a quella risorsa dal codice della Function.)
6. Scalabilità e alta disponibilità
Uno dei pilastri dell’architettura cloud è la scalabilità, ossia la capacità di un sistema di adattare le risorse assegnate in base al carico di lavoro, crescendo (scale-out) o diminuendo (scale-in) automaticamente. Abbiamo già accennato a molte funzionalità di autoscaling nei servizi specifici, riassumiamone i principali meccanismi in Azure:
- Per le VM (IaaS) si utilizzano i Virtual Machine Scale Sets, che consentono di gestire gruppi di VM identiche e definire regole di scalabilità automatica. Ad esempio si può stabilire che se l’utilizzo medio CPU delle VM in un set supera una certa soglia, Azure aggiungerà un’altra istanza al set; viceversa, se il carico cala sotto un livello minimo per un certo periodo, una VM viene spenta.
- Nei servizi PaaS come App Service, l’autoscaling è integrato a livello di piattaforma (App Service Plan). L’utente deve solo definire le regole di autoscale basate su metriche (ad esempio numero di richieste, utilizzo CPU, memoria disponibile) e Azure provvederà a aggiungere o togliere istanze dell’app secondo quelle regole. Si può anche impostare un autoscaling predittivo: Azure Monitor, grazie a algoritmi di Machine Learning, può anticipare i picchi di carico futuri (basandosi su trend storici) e scalare le istanze prima che il picco avvenga, migliorando la reattività. Questa funzionalità di autoscale predittivo è disponibile per alcuni servizi e scenari e rappresenta un’evoluzione interessante verso l’automazione intelligente.
- In AKS (Kubernetes), come visto, si utilizza l’Horizontal Pod Autoscaler (HPA) per scalare il numero di pod (istanze di container) in esecuzione per un certo servizio. Kubernetes inoltre permette di scalare i nodi stessi del cluster (cluster autoscaler) aggiungendo VM quando i pod non trovano spazio sufficiente sui nodi esistenti. Questo significa che in un cluster AKS ben configurato, sia le unità di lavoro (pod) che l’infrastruttura (VM agent) possono espandersi o contrarsi dinamicamente in base alla domanda.
Accanto alla scalabilità, un altro requisito cruciale per i sistemi cloud è l’alta disponibilità (HA), ovvero la capacità di un servizio di rimanere operativo e raggiungibile nonostante guasti o manutenzioni. Azure offre diverse opzioni per ottenere alta disponibilità:
- Distribuire le risorse su Availability Zones all’interno di una regione. Le Availability Zones sono gruppi di datacenter fisicamente separati (diversi edifici, diverse fonti di alimentazione, rete indipendente) ma sempre nella stessa area geografica. Mettendo, ad esempio, metà delle VM di un servizio nella Zona 1 e l’altra metà nella Zona 2, un eventuale guasto grave che colpisca una zona non impatta l’intero servizio, perché l’altra zona continua a servire le richieste.
- Implementare meccanismi di failover e disaster recovery. Azure ad esempio fornisce Azure Backup per eseguire backup automatici di VM, database e altri servizi, e Azure Site Recovery per orchestrare il disaster recovery (ad esempio replicando VM in un’altra regione pronta a subentrare in caso di disastro). Un’architettura ben progettata prevede backup periodici di dati cruciali e, se la continuità del servizio è fondamentale, un piano di DR con risorse di riserva in un altro datacenter o regione.
- Progettare applicazioni stateless e con bilanciamento del carico. Un principio architetturale di base è evitare che una specifica istanza di un servizio custodisca uno stato insostituibile. Se le sessioni utente, ad esempio, sono mantenute su un archivio condiviso (database o cache distribuita) invece che nella memoria locale di una singola VM, allora qualsiasi istanza può gestire qualsiasi richiesta. In questo modo, se una VM o un container si guasta, il carico può essere preso da altri nodi senza perdita di dati di sessione. Azure mette a disposizione Load Balancer (livello TCP/UDP) e Application Gateway (livello HTTP con funzionalità avanzate) per distribuire il traffico in ingresso e health probe per monitorare lo stato delle istanze dietro al bilanciatore, escludendo automaticamente dal traffico quelle non rispondenti. Questo garantisce che l’utente finale riceva risposta anche se uno dei server va offline, perché il carico viene reindirizzato solo verso quelli attivi e sani.
Ottenere la scalabilità e l’alta disponibilità corrette richiede anche attenzione alle politiche di riduzione delle risorse. Ad esempio, quando una regola di autoscaling decide di ridurre le istanze (scale-in), bisogna assicurarsi che non venga rimossa un’istanza che stava ancora elaborando operazioni importanti o che era l’ultima copia di un elemento critico. Azure Scale Set permette di definire politiche di rimozione, ad esempio rimuovere prima l’istanza più vecchia o quella più nuova, o quella che sta su una certa zona, ecc., a seconda di cosa sia più opportuno per l’applicazione. Questi dettagli di tuning spesso fanno la differenza tra un sistema altamente disponibile e uno fragile.
Esempi pratici: Per autoscalabilità, un esempio concreto di regole potrebbe essere: “se l’utilizzo medio CPU delle web app supera il 70% per più di 10 minuti, aggiungi un’istanza; se scende sotto il 30% per 15 minuti, rimuovi un’istanza, mantenendo comunque almeno 2 istanze sempre attive e non più di 10”. Ciò garantisce che il servizio reagisca ai carichi elevati aggiungendo capacità, ma eviti oscillazioni continue (histeresi temporale) e non scenda mai sotto un minimo vitale. Azure consente di impostare facilmente queste regole nell’App Service Plan o nel Virtual Machine Scale Set, e di monitorare in tempo reale quando vengono applicate.
Per l’alta disponibilità e il disaster recovery, immaginiamo un’applicazione critica che gestisce transazioni finanziarie. Possiamo schedulare backup regolari dei database su un Recovery Services Vault (un servizio centralizzato di gestione backup) e attivare Azure Site Recovery per replicare le VM applicative in un’altra regione. Periodicamente eseguiremo un test di failover simulato per verificare che, in caso di emergenza, l’intero sistema possa essere avviato nella regione secondaria in tempi brevi e con consistenza dei dati. Nel frattempo, a livello primario, avremo distribuito le VM su più Availability Zone e impostato health probe sul Load Balancer per assicurare che se una VM in una zona smette di rispondere, il traffico venga subito dirottato su altre VM funzionanti. Il risultato è un’architettura resiliente dove sia i dati (grazie ai backup e alla replica) sia la logica applicativa (grazie a load balancing e zone multiple) resistono ai guasti.
7. Gestione e automazione operativa
Man mano che le applicazioni in Azure crescono di numero e complessità, diventa fondamentale disporre di strumenti per gestire e automatizzare le operazioni di routine, riducendo gli interventi manuali e il rischio di errore umano. Azure fornisce diversi servizi in quest’area, in particolare Azure Automation.
Azure Automation consente di creare ed eseguire runbook, ossia script di automazione (in PowerShell, Python, o grafici con PowerShell Workflow) che possono svolgere praticamente qualsiasi operazione sulle risorse Azure e anche su sistemi on-premises. Ad esempio, si possono scrivere runbook per avviare o arrestare macchine virtuali in base a una pianificazione, per pulire file temporanei da storage, per creare report, per ruotare chiavi di accesso, ecc. Questi runbook vengono eseguiti in un contesto gestito dall’Automation Account di Azure, che può avere permessi su varie risorse. Per includere nelle automazioni anche risorse che si trovano nella rete locale o in altri ambienti fuori da Azure, si può utilizzare un Hybrid Runbook Worker: si tratta di un agente installato su una VM (o server fisico) che si registra con Azure Automation e da cui i runbook possono essere eseguiti localmente, permettendo di toccare anche sistemi on-premises.
Oltre ai runbook personalizzati, Azure Automation offre funzionalità pronte come State Configuration (DSC), che aiuta a garantire che la configurazione dei server rimanga conforme a una definizione desiderata (utile per fare configuration management in stile Chef/Puppet ma nativamente in Azure), e Update Management, che consente di gestire il patching di VM Windows e Linux schedulando l’installazione di aggiornamenti su gruppi di macchine. In questo modo, anche se stiamo usando molte VM IaaS, possiamo automatizzare il loro mantenimento per colmare il divario con le piattaforme PaaS in termini di effort operativo.
Un altro aspetto fondamentale dell’automazione è la possibilità di innescare azioni automatiche in risposta a eventi o condizioni. I runbook di Azure Automation possono essere avviati non solo manualmente o su schedulazione temporale, ma anche tramite webhook (chiamate HTTP esterne) e, soprattutto, integrandosi con altri servizi Azure: ad esempio si possono far partire in reazione a un alert di Azure Monitor, oppure all’interno di flussi di Azure Logic Apps o ancora al termine di una pipeline di Azure DevOps/ GitHub Actions. Questo significa che si può realizzare un flusso operativo completo: monitoraggio che rileva una condizione -> Automazione che interviene per correggerla. Un classico scenario è l’integrazione con sistemi ITSM: un alert critico potrebbe scatenare un runbook che prova una prima azione correttiva e apre automaticamente un ticket su ServiceNow se non riesce a risolvere il problema.
Esempi pratici: Un esempio immediato di automazione è la gestione dei costi: si può creare un runbook che spegne automaticamente ogni sera alle 23:00 le VM di test o sviluppo e le riaccende alle 7:00 del mattino successivo. In questo modo ambienti non produttivi consumano risorse solo quando servono davvero (in orario lavorativo), con grande risparmio. Si può impostare Azure Automation perché esegua questo runbook ogni giorno feriale, e magari tenerlo disattivato nei weekend se quelle macchine non servono mai il sabato e domenica. Tutto avviene in background senza intervento manuale, ma ovviamente con la possibilità di intervenire o escludere facilmente qualche VM dal programma se necessario (basterebbe parametrizzare il runbook).
Un altro esempio è un processo di backup personalizzato: supponiamo di avere un database che, per esigenze di consistenza, vogliamo backuppare a caldo con una procedura specifica. Possiamo creare un runbook che, all’orario stabilito (ad es. di notte), accende una certa VM su cui gira il database o uno strumento di backup, esegue uno script di dump SQL dei dati, carica il file risultante su un Blob Storage come archivio, e infine spegne nuovamente la VM per non avere costi fino al prossimo backup. Questo runbook potrebbe essere schedulato settimanalmente. Inoltre, integrandolo con Azure Monitor, potremmo impostare un avviso: se il runbook fallisce o impiega più del dovuto, invia una mail o apre un ticket per informare il team. In definitiva, con qualche script PowerShell/Python ben scritto, si può automatizzare quasi ogni routine operativa, dal più banale check di sistema fino a complesse sequenze multi-step, garantendo maggiore affidabilità (perché il processo sarà eseguito sempre nello stesso modo) e liberando tempo agli operatori umani per compiti più analitici.
(Nota: runbook indica uno script o processo automatizzato eseguito dal servizio Azure Automation; un Hybrid Runbook Worker è un agente installabile on-prem o su VM, che esegue i runbook nel proprio ambiente locale, permettendo di controllare risorse non esposte direttamente ad Azure.)
8. Monitoraggio e sicurezza
Quando si portano carichi di lavoro significativi in Azure, due aspetti diventano fondamentali per la gestione a lungo termine: il monitoraggio continuo delle risorse e la garanzia di un adeguato livello di sicurezza. Azure offre strumenti molto completi per entrambi questi scopi.
Azure Monitor è il servizio unificato di monitoraggio in Azure. Esso è in grado di raccogliere metriche, log e tracce da praticamente tutte le risorse Azure, oltre che da sistemi on-premises e persino da altri cloud. Le metriche sono valori numerici a intervalli regolari (ad esempio CPU usage di una VM, numero di richieste a un’app, latenza media di un database), mentre i log sono dati non strutturati o semi-strutturati (come log di applicazione, eventi di sistema, audit trail di sicurezza). Azure Monitor centralizza questi dati in Log Analytics Workspace (per i log) e li rende disponibili per analisi e query tramite un linguaggio apposito (Kusto Query Language). Sopra a Monitor ci sono soluzioni mirate, ad esempio Application Insights è una componente di Monitor pensata per le applicazioni, che fornisce analisi di performance a livello di codice (richieste al secondo, tempi medi di risposta, tracce di log applicativo con correlazione di operazioni). Ci sono poi viste preconfezionate chiamate Insights (ad es. VM Insights, Container Insights, Network Insights) che offrono dashboard e modelli di analisi specifici per quei tipi di risorsa, semplificando il lavoro senza dover costruire tutto da zero.
Un valore aggiunto cruciale di Azure Monitor sono gli Alert: possiamo definire regole che, al verificarsi di certe condizioni sui dati raccolti (es: una metrica supera un threshold, o un log specifico compare troppo spesso), fanno scattare un allarme. Gli allarmi possono generare notifiche (email, SMS, chiamate push) o azioni automatiche: ad esempio invocare una Function, eseguire un Logic App, o lanciare un runbook di Azure Automation. Ciò consente di costruire un sistema di osservabilità proattivo, dove non solo si visualizzano i dati, ma si reagisce in tempo reale a problemi. Ad esempio, se un’applicazione web ha errori HTTP 500 oltre un certo rate, può partire un alert che notifica il team di sviluppo e allo stesso tempo incrementa temporaneamente le istanze di App Service in attesa che si risolva il problema, prevenendo il collasso completo.
Dal punto di vista della sicurezza, Azure fornisce un servizio integrato chiamato Microsoft Defender for Cloud (un tempo noto come Azure Security Center). Si tratta di una soluzione di Cloud Security Posture Management (CSPM) e Cloud Workload Protection (CWPP) unificata, spesso indicata come una piattaforma CNAPP (Cloud-Native Application Protection Platform). In parole semplici, Defender for Cloud analizza continuamente le configurazioni delle risorse Azure (e, in certi casi, anche risorse su altri cloud o on-prem) per identificare vulnerabilità, configurazioni errate o rischi di sicurezza, e fornisce una serie di raccomandazioni su come migliorarne la postura. Ad esempio, potrebbe segnalare che una certa VM ha porte aperte su Internet senza necessità, o che un database non ha la crittografia attivata, o che mancano aggiornamenti di sicurezza su alcune macchine. Ogni raccomandazione contribuisce a determinare un Secure Score: Azure calcola un punteggio di sicurezza complessivo dell’ambiente tenendo conto di quanti controlli consigliati sono stati implementati. Più alto il secure score, meglio configurato e protetto è l’ambiente (in teoria). Questo punteggio aiuta a dare priorità agli interventi: ad esempio, migliorare gli elementi che aumentano di più il punteggio perché magari mitigano rischi maggiori.
Defender for Cloud non si ferma alle configurazioni statiche: include anche funzionalità di protezione attiva dei workload. Ad esempio Defender per i Server (macchine virtuali) può eseguire baseline di sicurezza, analisi comportamentali e segnalare attacchi come malware o brute force; Defender per i container analizza le immagini Docker e monitora i runtime AKS; Defender per le risorse PaaS (SQL, Storage, App Service, ecc.) avvisa su anomalie di utilizzo che potrebbero indicare compromissioni. Tutti questi eventi generano allarmi di sicurezza che compaiono in tempo reale. Inoltre la piattaforma aiuta con la compliance: ci sono report predefiniti che indicano quanto l’ambiente è conforme a standard come CIS, PCI-DSS, ISO 27001, etc., evidenziando i controlli mancanti.
L’integrazione tra Monitor e Defender è potente. Spesso le raccomandazioni di sicurezza e gli avvisi di Defender possono essere collegati con gli strumenti di monitoraggio: ad esempio far confluire gli eventi in un SIEM (Security Information and Event Management) come Microsoft Sentinel, oppure reagire immediatamente tramite un playbook di risposta automatico (realizzabile con Logic App). In pratica, Azure fornisce un ecosistema completo dove si può monitorare lo stato di salute e di sicurezza di tutte le componenti, individuare rapidamente anomalie o vulnerabilità, e persino automatizzare la reazione a tali eventi. Ad esempio, un tentativo di intrusione su una VM (rilevato da Defender) potrebbe innescare un alert di Monitor che avvisa il team di sicurezza e contemporaneamente lancia un runbook che cambia temporaneamente le regole del NSG per bloccare il traffico sospetto.
Esempi pratici: Un team DevOps potrebbe realizzare una dashboard operativa aggregando dati da Azure Monitor: ad esempio un’unica schermata in Azure Dashboard o in un Workbook di Monitor che mostri l’utilizzo medio di CPU e memoria di tutte le VM (o App Service), gli errori applicativi raccolti da Application Insights negli ultimi 30 minuti, il numero di richieste a ciascuna API e il tasso di errori, gli ultimi backup eseguiti e magari la latenza di alcune query chiave del database. In aggiunta, potrebbero esserci grafici di SLA (availability) per i microservizi e l’elenco degli alert attivi più severi in questo momento. Questa dashboard offre in un colpo d’occhio lo stato corrente dell’intero sistema e aiuta a individuare comportamenti anomali prima che diventino problemi gravi.
Dal lato sicurezza, un esempio è l’utilizzo di Defender for Cloud per proteggere i carichi di lavoro: abilitando Defender for Servers su tutte le VM, Defender for SQL sui database, Defender for Storage sugli account Storage, ecc., si ottiene una panoramica centralizzata delle raccomandazioni. Ad esempio, Defender potrebbe raccomandare di abilitare la crittografia su un certo storage account, di applicare gli aggiornamenti su una VM Linux, o di disabilitare l’accesso non protetto a un database. Il team di sicurezza può periodicamente esaminare queste raccomandazioni e stabilire un piano di azione per aumentare gradualmente il secure score. Nel frattempo, tutti gli avvisi critici (come rilevamenti di malware, picchi di traffico sospetto, query malevole bloccate sul database) vengono inviati al SIEM aziendale per il tracciamento e la correlazione. Un esempio di flusso: viene rilevato che un container in AKS sta eseguendo un processo insolito – Defender genera un alert di gravità alta; questo alert viene passato a Microsoft Sentinel (SIEM), dove c’è una regola che se coinvolge un container front-end, esegue automaticamente una playbook (Logic App) che invia un messaggio al team su Teams e scala a zero le istanze di quel pod per isolamento. Certo, questo è un scenario avanzato, ma illustra come con Azure si possano collegare monitoraggio e sicurezza per ottenere una capacità di risposta autonoma ad eventi avversi.
(Nota: Log Analytics Workspace è il contenitore in Azure Monitor dove vengono archiviati e gestiti i log raccolti dalle risorse; Secure Score è un indice calcolato da Defender for Cloud che riassume il livello di sicurezza dell’ambiente Azure e aumenta man mano che si implementano le raccomandazioni di sicurezza consigliate.)
9. Casi d’uso e ottimizzazione dei costi
Ultimo, ma non meno importante, aspetto da considerare quando si adotta il cloud è la gestione dei costi e l’ottimizzazione delle risorse per massimizzare il ROI (Return on Investment). Azure fornisce strumenti per monitorare la spesa in modo dettagliato e prendere decisioni informate su come ottimizzare i costi operativi.
Microsoft Cost Management + Billing è il portale integrato per il controllo costi su Azure. Tramite questo servizio è possibile monitorare in tempo quasi reale la spesa su Azure, suddividendola per sottoscrizione, gruppo di risorse, servizio o persino per tag personalizzati. Ad esempio, si possono assegnare tag come Environment:Production o Project:Website alle risorse e poi vedere il costo mensile aggregato di tutti i componenti con quel tag. Si possono impostare budget mensili o trimestrali: un budget definisce una soglia di spesa (ad esempio “non voglio spendere più di 10.000€ questo mese sulla sottoscrizione X”) e permette di configurare avvisi automatici quando la spesa raggiunge certe percentuali di quel budget (es. avviso al 80% e al 100%). Questo aiuta a non avere sorprese in fattura e a intervenire prima che i costi sfuggano di mano.
Cost Management include anche funzionalità di anomaly detection, che analizzano i pattern di spesa e segnalano se in un giorno o una settimana si verifica un costo anomalo rispetto alla media storica – spesso sintomo di risorse lasciate accese per errore o di un uso imprevisto. Nel portale costi si possono inoltre vedere analisi per scope differenti: a livello di tenant (Management Group), di singola subscription o di resource group. Questo è utile in contesti enterprise dove si vuole suddividere la visione dei costi per dipartimento o progetto.
Un’altra componente importante è la gestione delle Reservations e dei Savings Plan. Azure permette, per molte risorse di calcolo (VM, database gestiti, etc.), di acquistare in anticipo una certa quantità di utilizzo su 1 o 3 anni, ottenendo in cambio sconti significativi (spesso dal 20% al 50% in meno) rispetto al pagamento pay-as-you-go. Ad esempio, se si sa che una certa VM sarà usata h24 per i prossimi mesi, si può “riservare” un’istanza di quella VM per 1 anno, pagando un importo upfront o mensile scontato. Le Reservations si applicano a specifiche risorse (es. una certa famiglia di VM in una regione), mentre i Savings Plan sono più flessibili (si acquista un certo ammontare di spesa oraria impegnata su vari servizi). Cost Management aiuta a calcolare la copertura di queste opzioni: ovvero, dato l’uso effettivo, quanti di quegli usi sono coperti da prenotazioni e quanti no. Questo indirizza le scelte di acquisto anticipato per massimizzare il risparmio.
Adottare un approccio FinOps (Financial Operations) in cloud significa anche seguire alcune best practice:
· Utilizzare sistematicamente i tag per categorizzare le risorse per progetto, ambiente e team responsabile, così da poter attribuire i costi facilmente e identificare aree di ottimizzazione.
· Fare periodicamente right-sizing delle VM e degli altri servizi: spesso workload inizialmente stimati per una certa dimensione possono funzionare con meno CPU/RAM, soprattutto dopo ottimizzazioni applicative. Azure Advisor e Cost Management possono suggerire quando una VM è sottoutilizzata e potrebbe essere ridotta di dimensione.
· Spegnere o eliminare le risorse inutilizzate: ambienti di test non più attivi, VM accese oltre l’orario di lavoro, servizi creati per prova e poi dimenticati. Automatizzare lo shutdown quando possibile (come visto con Azure Automation) o pianificare revisioni periodiche delle risorse orfane.
· Utilizzare piani tariffari adeguati: ad esempio sfruttare gli Azure Hybrid Benefit per le VM Windows e SQL Server, che permettono di applicare licenze on-premises esistenti sulle VM cloud evitando di pagare due volte la licenza (questo può ridurre sensibilmente i costi per chi ha Software Assurance).
· Per carichi continuativi, valutare l’acquisto di Reservations/Savings Plans per ottenere sconti. Per carichi invece sporadici o variabili, continuare in pay-as-you-go può essere più conveniente.
· Monitorare costantemente con report automatici e magari esportare i dati costi in strumenti di BI (come Power BI) per incrociarli con metriche di business. Azure consente di esportare giornalmente i dati di costo dettagliati, così che l’azienda possa fare analisi approfondite e previsioni di spesa.
Esempi pratici: Un’azienda può impostare un budget mensile di, ad esempio, 50.000€ sulla propria subscription di produzione. Configura gli avvisi in modo che al raggiungimento dell’80% del budget (40.000€) venga inviata un’email al reparto IT e ai project manager, così da valutare misure correttive se necessario, e un altro avviso al 100% (50.000€) che magari attiva anche una Logic App per notificare su Teams la situazione. Nel portale Cost Management, vengono creati dashboard con grafici di costo per servizio (per vedere quali servizi incidono di più, ad esempio VM vs Database vs Storage) e trend storico (per vedere l’andamento mensile e individuare stagionalità). Questi dati, discussi nelle riunioni mensili, aiutano a capire se la spesa cloud sta portando i benefici attesi e dove si può eventualmente ottimizzare.
In termini di ottimizzazione pratica, un esempio può essere: dopo qualche mese di monitoraggio, il team si accorge che alcune VM di produzione hanno un utilizzo CPU mediamente sotto il 10%. Questo indica una sovra-configurazione. Di conseguenza, si può decidere di passare queste VM a una dimensione inferiore (meno vCPU/RAM) così da ridurre il costo orario, oppure se possibile consolidare più workload su meno VM spegnendone alcune. Inoltre, se ci sono macchine che invece sono essenziali e sempre accese (ad esempio server di dominio, o istanze database primarie), l’azienda valuterà l’acquisto di una Reservation per 3 anni per ciascuna, ottenendo magari un 30% di sconto rispetto al prezzo pieno. Un altro risparmio semplice viene dalle licenze: attivando Azure Hybrid Benefit su tutti i server Windows con licenza coperta da Software Assurance, si elimina la componente di costo legata alla licenza dal conto Azure (pagando solo l’host). Tutte queste azioni combinate possono portare a risparmi significativi, liberando budget che può essere reinvestito in nuove iniziative invece che speso in risorse non ottimizzate.
(Nota: in Cost Management il termine scope indica il perimetro di analisi o applicazione di un’operazione, ad esempio una subscription specifica, un resource group o l’intero tenant. Reservation e Savings Plan indicano invece gli impegni di spesa anticipati per ottenere prezzi scontati sui servizi di calcolo.)
Conclusioni
In questo capitolo abbiamo esplorato i principali servizi di calcolo offerti da Azure e i concetti chiave per utilizzarli al meglio. Siamo partiti dai fondamenti di IaaS, PaaS e serverless, evidenziando come scegliere il modello più adatto in base alle esigenze di controllo e semplicità. Abbiamo visto in dettaglio le macchine virtuali per scenari di massima flessibilità, i container con AKS per orchestrare applicazioni moderne a microservizi, e le piattaforme gestite come App Service e Functions che semplificano lo sviluppo di web app e workflow event-driven.
Attraverso esempi pratici, abbiamo mostrato come implementare scalabilità automatica e garantire alta disponibilità, sfruttando le funzionalità integrate della piattaforma Azure. Abbiamo sottolineato l’importanza della gestione automatizzata e del monitoraggio continuo, usando servizi come Azure Automation per ridurre il lavoro manuale e Azure Monitor insieme a Defender for Cloud per mantenere sotto controllo performance e sicurezza dell’ambiente. Infine, ci siamo concentrati sulle best practice di ottimizzazione dei costi, perché un utilizzo efficiente del cloud include non solo aspetti tecnici ma anche finanziari (il paradigma del FinOps).
Con queste conoscenze, chi si avvicina per la prima volta ai servizi di calcolo Azure dovrebbe avere un quadro chiaro delle opzioni a disposizione e di come pianificare l’adozione del cloud in modo strategico. Il mondo Azure è in continua evoluzione: nuovi servizi e funzionalità vengono aggiunti regolarmente. Tuttavia, i principi di base – scegliere il giusto livello di astrazione, progettare per la scalabilità e la resilienza, automatizzare dove possibile e tenere d’occhio costi e sicurezza – rimangono costanti. Seguendo questi principi e sperimentando con i servizi descritti, sarà possibile costruire infrastrutture cloud solide, sicure ed economicamente sostenibili, beneficiando appieno dell’innovazione offerta da Azure.
Riepilogo capitolo
Il documento fornisce una panoramica dettagliata dei principali modelli di servizio e strumenti offerti da Azure per la gestione di applicazioni cloud, coprendo modelli IaaS, PaaS e serverless, nonché aspetti di scalabilità, sicurezza, automazione e ottimizzazione dei costi.
· Modelli di servizio Azure: I modelli IaaS, PaaS e Serverless rappresentano un continuum dal controllo completo dell’infrastruttura (IaaS) a una gestione completamente automatizzata (serverless). IaaS offre flessibilità e controllo su VM, PaaS fornisce ambienti gestiti per applicazioni web e API, mentre il serverless esegue funzioni event-driven senza gestione server. Spesso si combinano nei sistemi avanzati per bilanciare controllo e automazione.
· Azure Virtual Machines (IaaS): Le VM consentono controllo totale su sistema operativo, configurazioni e software, utili per applicazioni legacy o esigenze specifiche. Richiedono gestione operativa come patching e backup, ma offrono alta flessibilità e integrazione con servizi di scaling e sicurezza come Scale Sets, Availability Zones e Azure Bastion.
· Container e Azure Kubernetes Service (AKS): AKS è un servizio gestito di Kubernetes che facilita il deploy, la scalabilità e l’aggiornamento di applicazioni containerizzate. Offre self-healing, rolling update, integrazione con CI/CD e monitoraggio approfondito tramite Azure Monitor. Supporta anche nodi virtuali per gestire picchi di carico con container serverless.
· Azure App Service (PaaS): Servizio gestito per hosting di applicazioni web e API, con supporto integrato per HTTPS, deployment slot, scalabilità automatica e integrazione con CI/CD. Supporta vari linguaggi e container personalizzati, offre integrazione con reti virtuali e autenticazione tramite Microsoft Entra ID.
· Azure Functions (Serverless): Permette l’esecuzione di funzioni event-driven senza gestione server, con vari trigger e binding per integrare risorse Azure. Offre piani di hosting Consumption, Premium e Dedicated per adattarsi a esigenze diverse. Supporta estensioni come Durable Functions per workflow complessi.
· Scalabilità e alta disponibilità: Azure supporta autoscaling tramite VM Scale Sets, App Service Plan e Kubernetes Horizontal Pod Autoscaler, oltre a distribuzione su Availability Zones per resilienza. Include meccanismi di failover, backup, bilanciamento del carico e politiche di rimozione controllata delle risorse per garantire continuità e reattività ai carichi variabili.
· Gestione e automazione operativa: Azure Automation consente di creare runbook per automatizzare operazioni di routine su risorse Azure e on-premises tramite Hybrid Runbook Worker. Offre anche gestione patch (Update Management) e configurazione (DSC), con possibilità di integrazione con alert e workflow per risposte automatiche a eventi.
· Monitoraggio e sicurezza: Azure Monitor raccoglie metriche e log da risorse Azure e on-premises, permettendo alert e analisi con Application Insights e Insights specifici. Microsoft Defender for Cloud valuta la postura di sicurezza, identifica vulnerabilità e protegge workload con alert in tempo reale, integrandosi con SIEM e automazione per risposte rapide.
· Casi d’uso e ottimizzazione dei costi: Microsoft Cost Management permette il monitoraggio dettagliato della spesa, con budget, avvisi e analisi di anomalie. Azure supporta l’uso di tag per attribuzione costi, right-sizing, spegnimento risorse inutilizzate, e acquisto di Reservations e Savings Plans per risparmiare. Best practice FinOps aiutano a massimizzare il ritorno sull’investimento cloud.
CAPITOLO 4 – Il servizio storage
Introduzione
Azure Storage è la piattaforma di archiviazione cloud di Microsoft progettata per essere altamente scalabile, duratura e sicura. Permette di conservare quantità enormi di dati di ogni tipo in data center Microsoft, garantendo che rimangano disponibili e protetti nel tempo. Un singolo Storage Account fornisce infatti uno spazio dei nomi globale raggiungibile via HTTP/HTTPS all’interno del quale risiedono diversi servizi di archiviazione. In un account di archiviazione possiamo gestire: Blob Storage per dati non strutturati come file binari o documenti, Azure Files per condivisioni file SMB/NFS compatibili con ambienti on-premises, Queue Storage per sistemi di messaggistica affidabile fra componenti applicativi, Table Storage per dati NoSQL schema-less organizzati in coppie chiave-valore, e anche Managed Disks per le macchine virtuali. Grazie a questa varietà, Azure Storage copre molte esigenze: dall’archiviazione di backup e contenuti multimediali, alla gestione di code di comunicazione tra servizi, fino allo storage di dati strutturati semplici.
Tutti i dati in Azure Storage vengono cifrati automaticamente a riposo (encryption at rest) tramite chiavi gestite da Microsoft. In alternativa è possibile usare chiavi gestite dal cliente, ad esempio integrate con Azure Key Vault, per avere un maggiore controllo (inclusa la doppia cifratura e la rotazione periodica delle chiavi). Anche il traffico in transito è cifrato con protocollo TLS: è una buona pratica forzare l’uso di HTTPS e disabilitare eventuali protocolli insicuri o obsoleti per garantire la massima protezione.
Azure Storage offre robusti meccanismi di controllo degli accessi. Si integra con Microsoft Entra ID (in precedenza noto come Azure AD) per l’autenticazione e l’autorizzazione basata su ruoli (RBAC), consentendo di assegnare permessi granulari agli utenti o ai servizi. Oltre all’identità, ogni account dispone di chiavi di accesso che possono essere usate dalle applicazioni per autenticarsi direttamente: queste chiavi vanno protette e ruotate periodicamente per motivi di sicurezza. In scenari di condivisione limitata, è possibile generare SAS (Shared Access Signature), ovvero token d’accesso temporanei con permessi ristretti a specifiche risorse e operazioni, validi per un intervallo di tempo definito. Infine, l’account di archiviazione può essere configurato con endpoint privati (Private Endpoint) o regole di firewall di rete per limitare l’accesso solo a reti o indirizzi IP autorizzati, aggiungendo un ulteriore livello di sicurezza perimetrale.
Dal punto di vista dell’osservabilità, ogni account Storage fornisce log e metriche dettagliate tramite Azure Monitor. Questi dati consentono di tenere traccia delle operazioni effettuate (audit), monitorare parametri come la latenza delle richieste o il volume di dati in ingresso/uscita, e impostare alert automatici su condizioni anomale. Grazie all’integrazione con Azure Monitor e Log Analytics, è possibile impostare avvisi (ad esempio per accessi non autorizzati o errori frequenti) e analizzare le tendenze di utilizzo per ottimizzare prestazioni e costi nel tempo.
Inquadramento argomenti del capitolo con slides illustrate
Azure Storage è la piattaforma di archiviazione cloud di Microsoft, progettata per essere massivamente scalabile, durabile e sicura. Un singolo Storage account offre un namespace globale raggiungibile via HTTP o HTTPS e ospita diversi servizi: Blob Storage per oggetti non strutturati, Azure Files per condivisioni compatibili con ambienti on-premises, Queue Storage per messaggistica affidabile, Table Storage per dati NoSQL chiave-valore e Managed Disks per macchine virtuali. Tutti i dati sono cifrati automaticamente at-rest e l’accesso può essere gestito tramite Microsoft Entra ID, chiavi, SAS e private endpoints. Gli account espongono metriche e log tramite Azure Monitor per osservabilità e auditing. Esempi pratici includono e-commerce che salva immagini prodotto in Blob Storage con URL SAS, gestionali che migrano cartelle in Azure Files con autenticazione Entra ID, e microservizi che usano Queue Storage per disaccoppiare processi. Ricorda: il namespace è lo spazio di nomi unico dell’account, mentre SAS è un token temporaneo che concede permessi granulari. Visualizza la mappa dei servizi con icone per Blob, Files, Queue e Table, collegati agli scenari più tipici.
Azure Storage offre diversi tipi di servizi per esigenze differenti. Blob Storage gestisce oggetti binari e testuali in containers, con tier di accesso, versioning, soft delete e lifecycle policies, oltre a Data Lake Storage Gen2 per analisi Big Data. Azure Files fornisce condivisioni SMB o NFS gestite che sostituiscono i file server tradizionali, con supporto per autenticazione identitaria, snapshots e sincronia on-prem tramite Azure File Sync. Queue Storage offre code FIFO altamente disponibili per la comunicazione asincrona tra microservizi, mentre Table Storage è un archivio NoSQL schema-less, economico per telemetrie e lookup. Se hai bisogno di funzionalità avanzate, considera Azure Cosmos DB. Esempi: un blog usa Blob Storage per asset frequenti, spostando contenuti stagionali verso Cool e storici in Archive; aziende con filiali centralizzano backup con Azure Files e File Sync; sistemi di ordini utilizzano Queue Storage per gestire picchi di richieste. Consulta la tabella comparativa con casi d’uso, protocolli e feature chiave.
Lo Storage account è l’unità di gestione che ospita tutti i servizi di Azure Storage. Durante la creazione puoi scegliere la regione, le prestazioni, la ridondanza, la configurazione di rete e i tag per la catalogazione dei costi. L’account kind moderno è StorageV2 (GPv2), che abilita funzionalità avanzate come tiering, lifecycle e Data Lake Gen2. La scelta della regione e della ridondanza influisce su latenza, disponibilità e costi. Le policy di accesso e la gestione delle chiavi, inclusa la rotazione tramite Azure Key Vault, completano il quadro di sicurezza. Ad esempio, un’app europea può avere l’account in norteurope con ZRS e private endpoints, mentre un data lake globale può usare RA-GZRS per letture durante incidenti. Ricorda: GPv2 è la generazione moderna di account, e Private Endpoint è l’interfaccia di rete privata per accedere al servizio. Segui il flow della scelta dei parametri e osserva gli effetti su SLA, costi e latenza.
Azure Storage garantisce la durabilità dei dati grazie a diversi tipi di replica. LRS (Locally Redundant) mantiene tre copie nello stesso data center, ideale per scenari non critici. ZRS (Zone Redundant) replica su tre zone diverse della stessa regione, proteggendo dall’outage di una zona, perfetto per workload di produzione. GRS (Geo-Redundant) effettua replica asincrona verso una regione paired, mentre RA-GRS e RA-GZRS permettono lettura dall’area secondaria per disaster recovery e scenari active/read. La scelta dipende da RTO, RPO, regolamentazioni, costi e pattern di accesso. Per Blob Storage, GZRS e RA-GZRS combinano ZRS nella primaria con replica geo per la massima resilienza. Esempi: un portale mission-critical usa ZRS e RA-GZRS per oggetti strategici, un archivio normativo si affida a GRS per conformità e ripristino. Visualizza il disegno region, zones e paired region con frecce di replica e icone read-access.
La sicurezza in Azure Storage si basa su diversi livelli. La cifratura at-rest è automatica e può essere gestita con chiavi del servizio o chiavi personali in Azure Key Vault, con supporto per double encryption e rotazione. La cifratura in transito avviene tramite TLS: è buona pratica forzare HTTPS e disabilitare protocolli obsoleti. L’autenticazione e autorizzazione si integrano con Microsoft Entra ID per RBAC e deleghe granulari, SAS per accessi temporanei, e Access Keys che vanno protette e ruotate. Il perimetro di rete si può rafforzare con firewall IP, Private Endpoints per isolamento, e Service Endpoints per VNet. Monitoring e auditing sono gestiti tramite Azure Monitor e Log Analytics per tracce di accesso, metriche e alert. Esempi: repository HR con chiavi CMK in Key Vault, accesso solo da VNet aziendale e SAS limitata; condivisioni file con accesso Entra ID e policy di rete restrittiva. Consulta il diagramma defense-in-depth per visualizzare la catena di sicurezza.
Blob Storage offre tre tier per ottimizzare costi e prestazioni. Il tier Hot è pensato per accesso frequente, con bassa latenza e costi di archiviazione più alti, ideale per file attivi, siti web e log recenti. Il tier Cool è meno costoso per l’archiviazione, ma ha costi di accesso e reidratazione più elevati, adatto a contenuti stagionali o backup consultati sporadicamente. Il tier Archive è il più economico, pensato per dati a lungo termine e compliance, ma richiede reidratazione prima dell’accesso. Puoi impostare lifecycle management per spostare automaticamente i blob tra i vari tier. Esempi: pipeline che sposta i log da Hot a Cool dopo 30 giorni e poi in Archive dopo 180 giorni, media library che archivia asset promozionali e riprese originali nei tier più appropriati. Osserva il grafico costo vs. frequenza di accesso e il tempo di reidratazione.
Gestire Azure Storage è semplice grazie a diversi strumenti. Azure Storage Explorer è un’app desktop che consente di esplorare container, caricare e scaricare dati, gestire snapshots e generare SAS, ideale per operazioni manuali. Azure CLI e PowerShell permettono automazione e Infrastructure as Code per provisioning, policy, assegnazioni di ruolo e regole di rete, utili in pipeline CI/CD. Azure Monitor e Log Analytics raccolgono metriche e log, consentendo la creazione di alert per anomalie e saturazioni. AzCopy è lo strumento ad alte prestazioni per trasferimenti data-intensive come migrazioni e backup. Esempi: script PowerShell per creare container e policy di lifecycle, dashboard di Monitor per egress e latenze, alert su superamento soglie. Consulta la documentazione ufficiale per approfondire. Visualizza lo schema toolbelt con icone e i casi d’uso di ciascun strumento.
Azure Storage è integrabile con molti servizi Azure e abilita architetture moderne. Su Virtual Machines puoi usare dischi gestiti e diagnostic logs su Blob, oppure Azure Files per lift-and-shift. App Service consente la gestione di asset statici su Blob, archiviazione file su Azure Files e connessioni sicure tramite VNet integration. Data Factory e Synapse Pipelines facilitano ingestione e trasformazioni verso Data Lake Gen2. Logic Apps orchestrano workflow low-code che reagiscono a eventi su Blob e Queue, mentre Event Grid abilita architetture event-driven che attivano Functions o webhook su modifiche ai blob. Queste integrazioni permettono ETL, serverless processing, modernizzazione applicativa e data lakehouse. Esempi: pipeline foto che crea thumbnail tramite funzione, ETL mensile con Data Factory e Spark. Visualizza il diagramma event-driven con Storage al centro.
Per ottenere il massimo da Azure Storage, segui le best practices. Per la sicurezza, abilita HTTPS obbligatorio, TLS minimo, private endpoints, RBAC con Entra ID, chiavi CMK in Key Vault, SAS a scadenza breve e principio del privilegio minimo. Attiva soft delete e versioning su Blob. Per la performance, usa ZRS per resilienza, Premium per latenza costante su Files e dischi, struttura container e cartelle in modo efficiente e usa AzCopy per trasferimenti bulk. Monitora la latenza e l’egress con dashboard. Per i costi, applica lifecycle policies per spostare i blob fra i tier, usa reservations su dischi, tagga le risorse per il chargeback, evita egress non necessario e valuta RA-GZRS solo quando richiesto. Esempi: policy automatizzate per lifecycle e alert su performance ed egress. Consulta la checklist sicurezza, performance, costi e il grafico timeline delle policy.
Per ottenere il massimo da Azure Storage, segui le best practices. Per la sicurezza, abilita HTTPS obbligatorio, TLS minimo, private endpoints, RBAC con Entra ID, chiavi CMK in Key Vault, SAS a scadenza breve e principio del privilegio minimo. Attiva soft delete e versioning su Blob. Per la performance, usa ZRS per resilienza, Premium per latenza costante su Files e dischi, struttura container e cartelle in modo efficiente e usa AzCopy per trasferimenti bulk. Monitora la latenza e l’egress con dashboard. Per i costi, applica lifecycle policies per spostare i blob fra i tier, usa reservations su dischi, tagga le risorse per il chargeback, evita egress non necessario e valuta RA-GZRS solo quando richiesto. Esempi: policy automatizzate per lifecycle e alert su performance ed egress. Consulta la checklist sicurezza, performance, costi e il grafico timeline delle policy.
1. Servizi di archiviazione: Blob, File, Code e Tabelle
Azure Storage mette a disposizione quattro servizi principali di archiviazione attraverso uno storage account, ognuno pensato per scenari diversi ma complementari. Di seguito vediamo nel dettaglio ciascun componente:
· Blob Storage – Consente di archiviare oggetti binari o file di qualunque tipo (documenti, immagini, video, backup, ecc.) all’interno di contenitori chiamati blob container. È un archivio di oggetti non strutturati, ideale per contenuti statici e grandi file. Blob Storage supporta diversi tier di accesso (Hot, Cool, Archive) che permettono di bilanciare costi e prestazioni in base alla frequenza di utilizzo dei dati (dettagli sui tier nel Capitolo 6). Dispone inoltre di funzioni avanzate come il versioning (per conservare versioni precedenti di un file), il soft delete (per recuperare dati cancellati entro un certo periodo) e le lifecycle policies (regole automatiche per spostare i blob tra tier in base a età o ultimo accesso). Blob Storage è anche alla base di Azure Data Lake Storage Gen2, una evoluzione pensata per scenari di Big Data analytics: aggiunge un file system gerarchico (directory e sottodirectory) e controlli di accesso a livello di file (ACL), rendendo Azure adatto a carichi di lavoro Hadoop/Spark e analisi di grandi moli di dati. In sintesi, Blob Storage è la destinazione predefinita per dati non strutturati: dai file multimediali per siti web, ai log applicativi, ai backup, fino ai dataset per sistemi di analisi.
· Azure Files – Offre condivisioni file gestite (managed) nel cloud accessibili tramite i protocolli standard SMB (Server Message Block) e NFS (Network File System). In pratica Azure Files permette di creare l’equivalente di un file server tradizionale, ma ospitato nel cloud e completamente gestito da Azure. Le share di Azure Files possono essere montate in lettura/scrittura sia da macchine virtuali Azure che da sistemi on-premises, facilitando scenari di migrazione (lift-and-shift) di applicazioni legacy che usano file share. Azure Files supporta l’integrazione con i servizi di identità: è possibile abilitare l’autenticazione tramite Azure AD DS o Microsoft Entra ID per controllare l’accesso alle share con credenziali aziendali, similmente a quanto avviene con un file server Windows in un dominio. Altre funzionalità includono i file snapshot (istantanee dei file per ripristini veloci) e l’integrazione con Azure File Sync, un servizio che mantiene sincronizzate copie dei file tra la share cloud e i file server locali, permettendo una cache locale per migliorare la latenza e la continuità operativa anche in caso di perdita di connettività. Per esigenze di alte prestazioni, è disponibile il tier Premium per Azure Files, che garantisce throughput e IOPS più elevati e costanti, utile ad esempio per ambienti con accesso intensivo ai file.
· Queue Storage – Fornisce un sistema di messaggistica asincrona basato su code (queue) FIFO durature e altamente disponibili. In una coda di Azure è possibile inserire messaggi (di dimensioni fino a centinaia di KB ciascuno) che verranno elaborati in seguito da processi consumer. Questo meccanismo consente di decouplare i componenti di un’applicazione: ad esempio, un servizio web può accodare le richieste di elaborazione e uno o più servizi di worker in background possono leggere dalla coda ed eseguire le elaborazioni in modo indipendente, garantendo resilienza e scalabilità (i worker possono aumentare di numero nei momenti di picco senza che il sistema perda messaggi). Queue Storage è quindi ideale per implementare buffer di lavoro, task queue e altri pattern di comunicazione asincrona tra microservizi, assicurando affidabilità nella consegna dei messaggi e possibilità di retry in caso di errori temporanei.
· Table Storage – Si tratta di un archivio NoSQL orientato ai documenti a schema flessibile, organizzato in tabelle di entità chiave-valore. Consente di memorizzare in modo molto economico grandi quantità di dati semi-strutturati: ogni entità (record) è identificata da una chiave e può contenere un set di proprietà arbitrario (colonne) senza una definizione schema fissa. Questa struttura lo rende adatto a dati come log, telemetrie, preferenze utente, liste di riferimento e altre informazioni dove è utile un accesso veloce per chiave e non sono necessarie query complesse o relazioni tra tabelle. Table Storage garantisce bassa latenza sulle operazioni di lettura e scrittura delle entità e costi contenuti, soprattutto rispetto a un database tradizionale, grazie al modello di pricing basato sul volume di dati archiviati e sulle operazioni effettuate. Va notato che Table Storage offre funzionalità basiche di query; se occorrono capacità avanzate come indici secondari, distribuzione globale multi-area, query più sofisticate o funzionalità come analisi per similarità/vectore search, conviene considerare Azure Cosmos DB (che infatti supporta un’API compatibile con Table storage ma con molte più feature). Per semplici esigenze key-value, però, Azure Table rimane una soluzione semplice e conveniente.
Esempi pratici di utilizzo dei servizi – I quattro servizi di Azure Storage trovano impiego in molti scenari reali. Ad esempio, un portale di blog multimediale potrebbe salvare le immagini e i video degli articoli su Blob Storage: i file di uso più frequente rimangono nel tier Hot, mentre i contenuti stagionali o meno richiesti vengono spostati in Cool o addirittura in Archive dopo un certo periodo, ottimizzando i costi. Una azienda con filiali distribuite può utilizzare Azure Files per centralizzare i documenti: grazie ad Azure File Sync, ogni ufficio locale mantiene una copia cache dei file più usati per accessi rapidi, mentre la copia master risiede sul cloud garantendo backup centralizzati e consistenza dei dati tra tutte le sedi. In un sistema di gestione ordini basato su microservizi, si potrebbe impiegare Queue Storage per mettere in coda le richieste di ordine man mano che arrivano: i servizi di processing leggono dalla coda ed evadono gli ordini in modo asincrono, consentendo di assorbire picchi di traffico senza perdere ordini e bilanciando il carico di lavoro in maniera efficiente.
2. Account di archiviazione e configurazione di base
Per utilizzare i servizi di Azure Storage è necessario creare uno Storage Account, che funge da contenitore logico per tutte le risorse di storage (blob, file, tabelle, ecc.). Lo storage account definisce un insieme di impostazioni e limiti comuni a tutti i servizi al suo interno. Durante la creazione di un nuovo account di archiviazione bisogna specificare alcuni parametri fondamentali di configurazione:
· Subscription e Resource Group: si seleziona la sottoscrizione Azure su cui addebitare i costi e si inquadra l’account in un gruppo di risorse per organizzarne la gestione insieme ad altre risorse correlate (ad esempio le VM che useranno quello storage).
· Nome univoco e Regione: ogni account deve avere un nome univoco a livello globale (diventerà parte dell’URL pubblico per accedere alle risorse, ad es. .blob.core.windows.net). Si sceglie inoltre la Regione Azure in cui verranno archiviati fisicamente i dati: conviene selezionare una località geografica vicina agli utenti o ai servizi che useranno i dati, per minimizzare la latenza, tenendo conto anche di requisiti di residenza del dato e compliance.
· Performance: Azure Storage offre due modalità di prestazioni per gli account, Standard e Premium. Gli account Standard utilizzano dischi e hardware tradizionali con throughput adatto alla maggior parte degli scenari generici; supportano tutti i tipi di servizi (Blob, Files, Queue, Table) e la fatturazione è generalmente basata sul volume di storage utilizzato e sulle operazioni eseguite. Gli account Premium, invece, utilizzano hardware SSD ad alte prestazioni: sono pensati per scenari con I/O intensivo e bassa latenza. Ad esempio esistono account Premium per Blob (con capacità limitata ma latenza molto bassa, utili per workload di streaming o machine learning con accesso rapido ai file) e per Azure Files (fornendo elevate IOPS e throughput costante paragonabile a storage enterprise). Gli account Premium hanno costi fissi più elevati e talvolta limiti di capacità, ma offrono prestazioni superiori prevedibili.
· Redundancy (ridondanza dei dati): è uno dei parametri chiave di un account, e determina quante copie dei dati vengono mantenute e dove. Azure offre varie opzioni di replica dei dati (LRS, ZRS, GRS, RA-GZRS, descritte nel dettaglio nel Capitolo 4). In sintesi: un account può tenere i dati replicati in 3 copie locali nello stesso data center, oppure in 3 copie distribuite su zone di disponibilità differenti nella stessa regione, oppure mantenere copie di backup anche in una regione geografica secondaria per proteggere dal disastro totale della regione primaria. La scelta dell’opzione di ridondanza avviene alla creazione dell’account (anche se per alcuni tipi di account è modificabile successivamente) e incide su livelli di durabilità, disponibilità dei dati in caso di guasti, nonché sui costi. È importante valutare i requisiti di business in termini di RTO (Recovery Time Objective, tempo massimo accettabile di indisponibilità) e RPO (Recovery Point Objective, quantità di dati che ci si può permettere di perdere in caso di guasto) per scegliere la replica più adatta.
· Networking: durante la configurazione si decide come e da dove sarà accessibile lo storage account. Per impostazione predefinita, un account è raggiungibile tramite endpoint pubblici su internet (con possibilità di limitare l’accesso a determinati IP). In alternativa, è possibile configurare l’account in modo privato, restringendo l’accesso tramite Private Endpoint: in questo caso l’account è mappato su un indirizzo IP privato all’interno di una Virtual Network Azure specificata, risultando isolato da internet e accessibile solo tramite la rete privata (opzione molto usata in contesti enterprise per aumentare la sicurezza). Un’altra opzione di rete è l’uso dei Service Endpoint, che consentono a risorse all’interno di una VNet (come VM o App Service) di accedere allo storage account tramite la backbone Azure piuttosto che uscire su internet, pur senza dover configurare un endpoint privato specifico.
· Tag: facoltativamente, si possono assegnare tag di metadata all’account (coppie chiave-valore utili per classificare la risorsa, ad esempio indicando il progetto, il dipartimento, l’ambiente – produzione vs test – ecc.). I tag aiutano nell’organizzare e filtrare le risorse e soprattutto nel chargeback dei costi (ad esempio è possibile generare report di spesa raggruppando per tag Progetto, per attribuire i costi di quello storage al team responsabile).
Un aspetto importante da notare è che il tipo di account di archiviazione predefinito e più moderno è chiamato General Purpose v2 (GPv2). Gli account GPv2 supportano tutti i servizi (Blob/Files/Queue/Table) e offrono le funzionalità più aggiornate, come i tier di accesso Hot/Cool/Archive, il supporto per Data Lake Storage Gen2, le politiche di lifecycle e così via. (In passato esistevano account di tipo “Blob Storage” o “General Purpose v1” con funzionalità limitate, ma oggi GPv2 è lo standard e conviene usarlo in quasi tutti i casi). Quando si crea un nuovo account tramite il portale Azure o via script, di fatto si sta creando un account GPv2 a meno di esigenze particolari.
In fase di definizione di un nuovo account, la scelta corretta di regione, prestazioni e ridondanza è cruciale perché impatta su tre fattori: latenza (un dato replicato geograficamente lontano dall’utente risulterà più lento da raggiungere rispetto a uno locale), disponibilità e durabilità (maggiori repliche in zone o regioni differenti aumentano la capacità di sopravvivere a guasti gravi), e costi (repliche geografiche e storage premium hanno costi più alti). Oltre a questi parametri di base, la sicurezza dello storage account è rafforzata tramite le policy di accesso (ad esempio l’obbligo di connessione sicura HTTPS, la definizione di firewall e virtual network) e la gestione delle chiavi di crittografia (sia che si usino chiavi Microsoft o chiavi proprie in Key Vault) – aspetti che approfondiremo nel capitolo sulla sicurezza. In sintesi, lo storage account è l’unità fondamentale da progettare attentamente, in cui vengono incapsulate le scelte di ubicazione, prestazioni, resilienza e sicurezza che incidono poi sul comportamento di tutti i servizi di storage utilizzati.
Esempi di configurazione: per chiarire, immaginiamo un’applicazione enterprise che serve utenti in Europa: potremmo creare lo storage account nella regione Nordeuropa (North Europe), scegliendo l’opzione di replica ZRS (Zone-Redundant Storage) per avere i dati ridondati su più zone di disponibilità all’interno della stessa regione – così il servizio resiste alla perdita di un intero data center mantenendo i dati disponibili nelle altre zone. Se l’applicazione è interna e non deve esporre dati su internet, abiliteremo un Private Endpoint collegato alla rete virtuale aziendale, in modo che solo le VM e i servizi di quella rete possano raggiungere lo storage. Invece, per un progetto di data lake globale volto ad analisi multi-regione, potremmo optare per una replica RA-GZRS: i dati sarebbero mantenuti sia con ridondanza zonale nella regione primaria, sia copiati asincronamente in una regione secondaria geograficamente distante, con l’opzione di accesso in lettura alla replica secondaria (Read-Access) in caso di emergenza. Questo garantirebbe la massima durabilità e disponibilità dei dati a livello mondiale, accettando il maggior costo associato.
3. Opzioni di ridondanza dei dati
Una delle caratteristiche chiave di Azure Storage è la capacità di replicare i dati in più copie per assicurare alta durabilità e disponibilità anche in caso di guasti hardware o disastri. Quando si crea un account di archiviazione, come visto, bisogna scegliere una strategia di ridondanza per i dati archiviati. Azure offre diverse opzioni di replica tra cui scegliere, indicate tipicamente con acronimi:
· LRS – Locally Redundant Storage: si tratta dell’opzione di base, nella quale Azure mantiene 3 copie sincrone dei dati all’interno dello stesso data center (ossia nella stessa struttura fisica). Ogni scrittura viene quindi immediatamente replicata su tre dischi diversi nello stesso sito. LRS protegge dai guasti di singolo nodo o drive all’interno di un data center, assicurando che se un server o un disco si rompe esistano comunque copie integre altrove nello stesso edificio. È la soluzione più economica in termini di costo, ma non protegge dal caso estremo di indisponibilità dell’intero data center (ad esempio per un incendio o blackout totale in quel sito). LRS è adatto a scenari non critici, dove si può tollerare la potenziale perdita dei dati in caso di disastro totale del data center, oppure dove magari si gestiscono già backup separati.
· ZRS – Zone Redundant Storage: in questa modalità Azure mantiene sempre 3 copie, ma ciascuna in una zona di disponibilità diversa all’interno della stessa regione. Le regioni Azure infatti, quando supportano la ridondanza zonale, hanno più Availability Zone (tipicamente tre zone), ognuna corrispondente a un data center fisicamente separato ma interconnesso ad alta velocità con le altre nella regione. Con ZRS, i dati scritti vengono replicati sincronicamente tra le zone: ciò significa che i dati sono resilienti alla perdita di un intero data center, perché resteranno comunque disponibili nelle altre zone della stessa regione. ZRS offre quindi un livello di disponibilità più elevato rispetto a LRS, e protezione da fault a scala di zona. È spesso la scelta consigliata per workload di produzione che richiedono alta affidabilità all’interno di una regione, senza dover replicare geograficamente (ZRS evita tempi di latenza più alti, mantenendo le repliche localizzate nella medesima area metropolitana). Il costo di ZRS è leggermente superiore a LRS, ma giustificato dai benefici di resilienza.
· GRS – Geo-Redundant Storage: con GRS Azure aggiunge la replica geografica dei dati. In pratica l’opzione GRS combina LRS con una copia asincrona in un’altra regione: i dati vengono mantenuti in 3 copie locali nella regione primaria (come LRS) e vengono periodicamente replicati (in modo asincrono) in altri 3 duplicati all’interno di una regione secondaria distante, tipicamente la regione “coppia” (paired) predefinita di Azure (ogni regione Azure ha una seconda regione con cui forma una coppia per scenari di disaster recovery, es. West Europe è accoppiata con North Europe, East US con West US, ecc.). Con GRS, se la regione principale subisse un disastro, esisterebbe comunque una copia relativamente recente dei dati nella regione secondaria. Tuttavia, nel modello GRS standard la copia secondaria non è accessibile al cliente salvo durante un failover dell’account dichiarato da Microsoft in caso di disastro grave: ciò significa che normalmente tutte le operazioni di lettura e scrittura avvengono sulla regione primaria; la replica secondaria rimane “dormiente” finché va tutto bene, pronta ad essere attivata solo in scenari di recovery. Questo comporta che eventuali aggiornamenti appena scritti potrebbero andare persi se un disastro colpisce la regione primaria prima che la replica asincrona li abbia copiati (concettualmente, c’è un RPO > 0). Nonostante questo, GRS offre una durabilità estremamente alta (6 copie totali in due location) ed è indicata per dati critici dove è richiesto un backup geografico automatico.
· RA-GRS / RA-GZRS – Read-Access Geo-Redundant Storage: queste varianti, Read-Access, permettono di accedere in sola lettura alla regione secondaria in qualsiasi momento. RA-GRS è la versione read-access di GRS, mentre RA-GZRS è la versione read-access di GRS combinata con ZRS nella regione primaria. Per introdurre RA-GZRS, prima spieghiamo GZRS: GZRS è un’opzione che combina il meglio di ZRS e GRS – in pratica mantiene repliche sincrone su zone nella regione primaria (come ZRS) e in più effettua la replica geo asincrona su una regione secondaria (come GRS), ottenendo 3 copie zonali locali + 3 copie geo-ridondate. RA-GZRS abilita l’accesso in lettura alla replica secondaria di un account GZRS. Queste opzioni RA* sono utili in scenari di disaster recovery avanzati: ad esempio, con RA-GZRS un’applicazione in caso di disastro nella regione primaria potrebbe effettuare operazioni di sola lettura sui dati dalla regione secondaria senza attendere il failover ufficiale, garantendo una continuità operativa (anche se in modalità limitata) durante l’emergenza. Il costo sia di GZRS che di RA-GZRS è ovviamente più elevato (essendo il massimo livello di resilienza offerto), quindi andrebbe scelto solo quando il requisito di avere i dati leggibili anche in uno scenario di regione down è essenziale e giustifica l’investimento.
In sintesi, la scelta di LRS, ZRS o GRS/RA-GZRS dipende dalle esigenze di business in termini di tolleranza ai guasti e requisiti di continuità operativa. Dal punto di vista delle prestazioni, in condizioni normali non si percepisce differenza tra LRS e ZRS (entrambe replicano sincronicamente nella stessa area metropolitana), mentre GRS introdurrà una latenza leggermente maggiore solo per le scritture (dovuta alla necessità di replicare su un altro sito, anche se è asincrona quindi l’impatto è minimo per l’utente). LRS e ZRS hanno throughput identico per lettura/scrittura, mentre le opzioni geo (GRS/GZRS) comportano restrizioni: ad esempio, mentre la regione secondaria non è accessibile in GRS normale, in RA-GRS/RA-GZRS è accessibile in sola lettura ma ovviamente con latenza più alta se l’app risiede dall’altra parte del mondo rispetto alla secondaria.
È importante valutare anche considerazioni di compliance e normative: alcune organizzazioni potrebbero richiedere per policy interne che i dati non escano da una certa nazione o area; in tal caso GRS (che copia i dati fuori area) potrebbe non essere permesso. Altre invece, per obblighi di resilienza, impongono una copia geografica di tutti i dati. Azure fornisce le opzioni tecniche, ma spetta all’architetto scegliere in base a questi vincoli e ai costi: LRS è economico ma meno resiliente, ZRS aumenta resilienza locale, GRS aggiunge sicurezza geografica, RA-GZRS è il top di gamma per chi non può permettersi downtime nemmeno in caso di disastri regionali.
Esempi di scenari di replica – Una web application mission-critical che richiede uptime continuo potrebbe configurare lo storage account in ZRS per i dati transazionali attivi, assicurando ridondanza contro guasti locali, e utilizzare RA-GZRS per determinati dati strategici (ad esempio backup configurati come blob con policy di sola lettura) in modo da poterli consultare anche se l’intera regione primaria non fosse disponibile. D’altro canto, un archivio di dati normativi a lungo termine, meno sensibile alla latenza, potrebbe optare per GRS, accettando che in condizioni normali i dati siano accessibili solo dalla regione primaria, ma garantendosi una seconda copia remota in caso di emergenza per aderire a politiche di conformità e disaster recovery.
4. Sicurezza e controllo dell’accesso
La sicurezza dei dati in Azure Storage è un aspetto fondamentale, ottenuta tramite una stratificazione di misure che proteggono i contenuti a più livelli: cifratura dei dati, controllo delle identità e delle chiavi, sicurezza di rete e monitoraggio.
· Cifratura dei dati a riposo (encryption at rest): Come accennato, qualsiasi dato salvato in Azure Storage viene cifrato automaticamente appena scritto su disco, utilizzando algoritmi standard (come AES-256) gestiti dal servizio. Per impostazione predefinita le chiavi di crittografia sono gestite da Microsoft (Microsoft-managed keys), semplificando la vita all’utente, ma per esigenze avanzate si possono usare chiavi gestite dal cliente (CMK) salvate in Azure Key Vault. Usare chiavi proprie permette ad esempio di esercitare un pieno controllo (revocare l’accesso ai dati cifrati, implementare una periodicità di rotazione delle chiavi secondo policy interne, o averne copie di backup in escrow). Azure Storage supporta anche la doppia cifratura (dati cifrati da Microsoft con una chiave master ulteriore, oltre alla cifratura principale, per aggiungere un layer extra di sicurezza) e naturalmente se si passa a chiavi gestite dal cliente è possibile ruotarle periodicamente per ridurre il rischio in caso di compromissione.
· Cifratura in transito: Tutte le comunicazioni con un account di archiviazione avvengono tramite protocolli sicuri HTTPS/TLS. Azure permette di forzare l’uso di connessioni cifrate, rifiutando qualsiasi tentativo su HTTP non cifrato. Inoltre, è possibile configurare la versione minima di TLS accettata (ad esempio disabilitando TLS 1.0 e 1.1 obsoleti, assicurando che solo client moderni con TLS 1.2/1.3 si possano connettere). Queste impostazioni garantiscono che i dati non viaggino mai in chiaro sulla rete e che vengano usati protocolli robusti, prevenendo attacchi noti su versioni di TLS vecchie.
· Autenticazione e autorizzazione: Azure Storage offre diversi metodi per autenticare le richieste e autorizzare l’accesso solo a chi ne ha diritto. Il metodo più integrato è tramite Azure AD/Microsoft Entra ID: assegnando ruoli di accesso (RBAC) alle identità Azure AD (utenti, gruppi o entità servizio) è possibile controllare in modo granulare chi può leggere, scrivere o eliminare dati in uno storage account o in un contenitore specifico. Ad esempio, si può concedere a un certo gruppo solo permessi di lettura su un container Blob, ad un altro gruppo permessi di contributore (scrittura) su una share Azure Files, e così via, tutto gestito centralmente dalle identità Azure AD e rispettando il principio del minimo privilegio. In parallelo, ogni storage account possiede due chiavi di accesso (Primary e Secondary Key): si tratta di stringhe segrete che fungono da “password master” e consentono accesso amministrativo a tutte le risorse dell’account. È possibile usare queste chiavi in connessione string da fornire alle applicazioni legacy che non supportano Azure AD; tuttavia, il loro uso deve essere limitato e devono essere mantenute segrete e ruotate con regolarità (Azure consente di rigenerare una delle due chiavi in qualsiasi momento, permettendo di aggiornare le applicazioni sulla seconda chiave e poi rigenerare la prima, in modo alternato, per non interrompere i servizi). Per concedere accessi più circoscritti, la strada preferenziale è l’uso delle Shared Access Signature (SAS): una SAS è un token che si può generare a livello di account o di singola risorsa (container, file share, coda, tabella) specificando quali permessi sono consentiti (lettura, scrittura, cancellazione, listare, ecc.) e per quanto tempo. Ad esempio, posso generare una SAS che consente solo la lettura di un particolare file per i prossimi 60 minuti, e fornire quell’URL SAS a un cliente per permettergli di scaricare il file in quel lasso di tempo. Le SAS sono criptograficamente firmate usando le chiavi dell’account, quindi non c’è bisogno di condividere direttamente le chiavi principali nè credenziali; inoltre, si possono revocare indirettamente rigenerando le chiavi di account (il che invalida tutte le SAS create con quelle chiavi). In produzione, si raccomanda di usare SAS con scadenze brevi e diritti limitati, preferendo Azure AD ove possibile per gestire l’accesso continuo.
· Sicurezza di rete e perimetro: Oltre all’autenticazione, Azure Storage può essere protetto limitando da dove avviene l’accesso. Come visto per la configurazione di rete dell’account, si può decidere di consentire solo accessi da specifici intervalli IP (ad esempio gli IP pubblici della propria sede aziendale) oppure di isolare completamente l’account in una rete privata tramite Private Endpoint. Con un Private Endpoint, l’account non ha un endpoint pubblico raggiungibile da internet: tutte le richieste devono passare attraverso la VNet privata associata, che a sua volta può essere collegata alla rete on-premises aziendale tramite VPN o link dedicati (ExpressRoute). Questo azzera la superficie esposta su internet e protegge dai tentativi di accesso malevoli esterni. Un’alternativa un po’ meno radicale è l’uso dei Service Endpoint: in pratica, anche mantenendo l’endpoint pubblico, si può dire che solo richieste provenienti da determinate subnet di una Virtual Network Azure siano accettate dal servizio storage, rifiutando tutte le altre. Questo garantisce che, ad esempio, solo le VM nella VNet X possano parlare con l’account (anche se l’IP pubblico teoricamente sarebbe aperto, Azure effettua un filtro sul lato servizio). Inoltre, per aumentare la sicurezza, conviene abilitare le funzionalità di soft delete (su Blob, File e Queue dove disponibile): il soft delete conserva per un periodo definito (es. 7 giorni) i dati eliminati, prevenendo cancellazioni accidentali o atti malevoli (un attaccante che volesse distruggere i dati dovrebbe attendere oltre il retention period affinchè davvero spariscano). Su Blob, l’abilitazione del versioning aiuta anch’essa a mantenere una traccia di tutte le modifiche e recuperare versioni precedenti se necessario. Infine, per scenari altamente sensibili, è possibile utilizzare funzionalità come immutability policy e legal hold sui container Blob (che rendono i dati non eliminabili o modificabili per un certo periodo, utile in contesti finanziari o legali).
· Monitoraggio e auditing: A completare il quadro di sicurezza, Azure Storage si integra strettamente con Azure Monitor per fornire visibilità su tutte le operazioni effettuate. Tramite i log diagnostici è possibile tracciare ogni accesso, indicando chi ha fatto cosa e quando (audit trail). Si possono collezionare log di Azure Storage e inviarli ad un workspace di Log Analytics, dove è possibile eseguire query per individuare anomalie (ad esempio tentativi di accesso falliti ripetuti, o cancellazioni massive in un breve periodo). Azure Monitor permette anche di impostare alert su metriche e eventi: ad esempio, se un container subisse un numero insolito di letture o scritture, o se venisse superata una certa soglia di errori di autenticazione, un allarme può notificare gli amministratori per intervenire tempestivamente. Questi strumenti di monitoraggio non solo aiutano nella sicurezza proattiva (individuando attività sospette), ma anche nell’ottimizzazione – ad esempio vedendo i trend di utilizzo si può capire se è necessario potenziare la rete, abilitare un CDN, o aggiungere caching per migliorare le performance.
Esempi di soluzioni di sicurezza – Consideriamo un repository di documenti riservati HR ospitato in Azure Storage: potremmo scegliere di proteggere i file con chiave gestita dal cliente (CMK) salvata in Key Vault, in modo che anche Microsoft non possa accedere ai dati senza la nostra chiave. Abiliteremo l’accesso alla storage account solo dalla rete aziendale mediante un Private Endpoint, ed applicheremo una regola firewall per consentire operazioni solo dagli IP del nostro ufficio. Tutti i dipendenti accederanno ai documenti tramite le loro identità Azure AD, con ruoli che consentono solo lettura o scrittura dove necessario. Per condividere temporaneamente un file con un consulente esterno, gli amministratori genereranno una SAS ad hoc valida magari un’ora, limitata al download di quello specifico file. Di notte, i log di accesso verranno analizzati con query automatiche in Log Analytics per verificare che non ci siano stati tentativi sospetti (ad esempio login falliti oltre una soglia). In un altro scenario, immaginiamo delle condivisioni file aziendali migrate su Azure Files: in tal caso integreremo Azure Files con Azure AD per fare in modo che i dipendenti continuino ad usare le loro credenziali di dominio per accedere alle share, e configureremo il servizio in modo che sia raggiungibile solo dalle subnet interne della VNet collegata alla nostra rete (evitando qualsiasi accesso da internet). Inoltre, abiliteremo soft delete per i file per prevenire perdite accidentali e creeremo backup periodici con Azure Backup. Queste misure combinate – cifratura, identity/RBAC, rete privata, monitoraggio – creano una difesa in profondità che mantiene i dati al sicuro in ogni situazione.
5. Tier di archiviazione: Hot, Cool, Archive
Un’altra caratteristica importante di Azure Blob Storage (e in parte Azure Files per i file share) è la possibilità di scegliere tra diversi livelli di accesso (access tiers) per ottimizzare il compromesso tra prestazioni e costi di archiviazione. I tre tier principali offerti per i blob sono: Hot, Cool e Archive.
· Hot Tier: è il livello prestazionale più alto. I dati sul tier Hot sono archiviati su supporti a più rapido accesso e sono immediatamente disponibili per lettura/scrittura con bassa latenza. Questo comporta un costo di storage per GB più elevato, ma costi minimi per le operazioni di accesso. Il tier Hot è ideale per informazioni a cui si accede di frequente o continuamente, come file di uso quotidiano, contenuti di siti web e applicazioni attive, streaming media, database o log recenti. In sintesi, si paga di più per tenere i dati sempre pronti e veloci, ma li si può utilizzare senza penali ogni volta che servono.
· Cool Tier: è pensato per i dati a accesso meno frequente. Archiviare un blob in Cool costa meno (per GB/mese) rispetto a Hot, perché Azure presuppone che quei dati non vengano letti o modificati spesso. Tuttavia, ogni volta che si accede a un dato nel tier Cool si sostengono costi leggermente superiori per operazione, e in generale le performance possono avere una latenza leggermente maggiore rispetto a Hot (pur essendo comunque online e immediatamente accessibili). Inoltre, c’è un costo per effettuare la ri-classificazione di un blob da Cool a Hot e viceversa se si cambia idea prima di un certo periodo minimo (solitamente Azure consiglia di mantenere un blob in Cool per almeno 30 giorni, altrimenti il risparmio non compensa i costi di transizione). Il tier Cool è adatto a file che vanno tenuti per eventualità future ma che non servono nell’operatività quotidiana: ad esempio backup recenti, dati storici di qualche mese fa, documenti di archivio a cui si accede raramente (ma comunque possono dover essere recuperati all’occorrenza in tempi brevi), o contenuti di applicazioni non più attive ma che vanno conservati per un periodo.
· Archive Tier: è il livello più economico in assoluto per conservare dati su Azure, e di converso il meno performante e immediato. Quando un blob viene spostato in Archive, in realtà viene conservato su supporti di archiviazione a freddo (come nastri o storage ottimizzato per capacità) e non è direttamente disponibile per consultazione. Per poter leggere (o modificare) un blob in Archive occorre prima eseguire un’operazione di “riidratazione” (rehydration), ovvero richiederne il passaggio a un tier attivo (Hot o Cool): questa operazione può richiedere diverse ore, finché Azure non ripristina il blob su supporti online. Solo dopo il completamento della reidratazione il blob diventa accessibile. Ciò significa che Archive va usato per dati a cui non si prevede di accedere se non in casi eccezionali, tipicamente per conservazione a lungo termine o per obblighi normativi. In cambio, il costo di storage in Archive è molto basso, permettendo di mantenere petabyte di dati a costi sostenibili. Esempi tipici: dati grezzi di anni passati che servono solo per audit o compliance, backup di lungo termine, log molto vecchi, registrazioni che devono essere tenute ma raramente visionate. Azure richiede spesso di tenere un blob in Archive per almeno 180 giorni per giustificare il costo (spostamenti prematuri a Hot/Cool comportano penali per early deletion).
La gestione manuale di questi tier per ogni singolo blob sarebbe onerosa, così Azure Storage fornisce le Policy di Lifecycle Management: regole configurabili che applicano automaticamente spostamenti di tier o eliminazioni in base a condizioni di età dei dati o periodo di inattività. Ad esempio, si può definire una policy che dica: “dopo 30 giorni dall’ultimo accesso, declassa il blob da Hot a Cool; dopo 180 giorni sposta da Cool a Archive; dopo 7 anni elimina definitivamente”. In questo modo, si può impostare una gestione automatizzata dell’intero ciclo di vita dei file, risparmiando sui costi di storage senza doversi ricordare di fare interventi manuali.
Per scegliere il tier appropriato, bisogna valutare la frequenza di accesso attesa per i dati e i requisiti di disponibilità immediata. Spesso conviene iniziare i nuovi dati in Hot (ad esempio i file appena caricati da un utente o i log del giorno corrente) e poi, tramite policy o script, spostarli su tier più freddi man mano che invecchiano e probabilmente non serviranno. Va ricordato che i tier Hot e Cool sono online (non serve operazione preventiva per leggerli, a parte pagare il costo di accesso), mentre Archive è offline finché non si richiara online. I metadati dei blob (come i loro nomi o attributi) restano comunque visibili anche quando il contenuto è in Archive, quindi si può sapere cosa c’è e decidere se rianimarlo.
Esempi di gestione dei tier – Un tipico scenario di log archiving in un’azienda potrebbe prevedere: i log applicativi vengono scritti quotidianamente in un container Blob con tier Hot; superati i 30 giorni, i log di oltre un mese fa vengono automaticamente spostati in Cool (dato che raramente saranno consultati, ma vanno tenuti ancora per qualche tempo); trascorsi 180 giorni dalla creazione, quei log vengono ulteriormente spostati in Archive (per conservazione storica); infine, dopo alcuni anni (ad esempio 7 anni, come da politiche di compliance), i log vengono eliminati definitivamente. In questo modo il costo dello storage rimane proporzionato al reale utilizzo dei dati nelle diverse fasi del loro ciclo di vita. Un altro esempio: una libreria multimediale di marketing potrebbe tenere i contenuti di campagne attive nel tier Hot (per garantire un’erogazione veloce ai siti web o ai server che li usano). Quando una campagna termina e i suoi materiali non servono spesso, questi file possono essere spostati in Cool, mantenendoli comunque disponibili se il marketing ne avesse bisogno più avanti. Alla fine, i materiali di archivio (video originali, foto ad alta risoluzione non più usate) trascorso un anno vengono messi in Archive per conservazione a lungo termine, sapendo che si potranno recuperare in futuro con un po’ di preavviso se mai dovessero servire di nuovo.
6. Strumenti per la gestione di Azure Storage
Microsoft fornisce diversi strumenti e interfacce per lavorare con Azure Storage, così da soddisfare sia esigenze di gestione manuale (interactive) che di automazione/script. Ecco i principali:
· Azure Storage Explorer: è un’applicazione desktop con interfaccia grafica (GUI), disponibile gratuitamente per Windows, Mac e Linux, pensata per esplorare e gestire visualmente i contenuti di uno storage account. Con Storage Explorer è possibile connettersi ai propri account (autenticandosi con Azure AD o usando le chiavi di accesso/SAS), e una volta connessi navigare tra i container di Blob, le condivisioni File, le code e le tabelle. L’interfaccia permette di caricare e scaricare file tramite drag & drop, creare nuovi blob container o directory, eliminare dati, visualizzare ed eventualmente modificare metadata e proprietà dei file (ad esempio impostare attributi su un blob, o vedere le permissions di un file), e anche generare rapidamente SAS token su una risorsa (c’è una funzione integrata per creare Shared Access Signature per dare accessi temporanei specifici). Azure Storage Explorer risulta molto comodo per operazioni quotidiane e amministrazione manuale, soprattutto per chi preferisce un approccio visuale anziché ricordare comandi script. Supporta anche funzionalità avanzate, come la gestione delle snapshots su Azure Files e Blob (vedere e ripristinare versioni precedenti di un file). Essendo installabile in locale, consente agli amministratori di interagire con lo storage senza dover passare dal portale web Azure per ogni operazione.
· Azure CLI e Azure PowerShell: per automazione e scripting, Azure mette a disposizione strumenti a riga di comando. L’Azure CLI è un’interfaccia testuale unificata con comandi come az storage ... che consentono di creare account, elencare e gestire contenuti, impostare policy e così via. Azure PowerShell offre cmdlet analoghi (New-AzStorageAccount, Get-AzStorageBlob etc.) integrati nell’ambiente PowerShell, molto utilizzati dagli amministratori Windows. Questi strumenti permettono di integrare Azure Storage in script e pipeline di deployment. Ad esempio, con script CLI/PowerShell si possono implementare soluzioni di Infrastructure as Code (IaC) creando storage account, definendo in automatico regole di lifecycle, configurando il firewall, assegnando ruoli RBAC su determinate container e molto altro, il tutto versionabile e ripetibile. In un contesto DevOps, l’uso di CLI/PowerShell consente di includere la gestione dello storage in pipeline CI/CD (Continuous Integration/Continuous Deployment): per esempio, quando si rilascia un’applicazione si potrebbe con uno script creare un nuovo container blob per i file temporanei, oppure aggiornare determinate impostazioni. Oltre alle command-line tools, Azure Storage è supportato da SDK in vari linguaggi di programmazione (per .NET, Python, Java, JavaScript, etc.), il che permette anche agli sviluppatori di scrivere codice che interagisce direttamente con i servizi (upload/download di file, inserimento di messaggi in coda, query sulle tabelle, ecc.) senza passare per il portale.
· Azure Monitor e Log Analytics: più che strumenti di gestione diretta, questi sono servizi di monitoraggio integrati che aiutano ad amministrare gli account di archiviazione tenendo sotto controllo performance e utilizzo. Tramite Azure Monitor, come visto, si possono raccogliere metriche (quantità di dati archiviati, numero di transazioni, latenza media, ingress/egress di rete, percentuale di disponibilità, etc.) e impostare dashboard o grafici temporali per vedere l’andamento di questi indicatori. Con Log Analytics si possono scrivere query per approfondire i log (ad esempio filtrare tutte le operazioni di delete eseguite in un certo periodo, o contare quante richieste 403 (forbidden) ci sono state come possibile segnale di tentativi di accesso non autorizzato). Inoltre, Azure Monitor consente di definire alert automatici: per esempio, se lo spazio usato in un account supera l’80% della quota disponibile, oppure se la latenza del 95° percentile eccede un certo ms per più di 5 minuti, o ancora se un servizio backend smette di leggere messaggi da una coda (coda crescente senza consumer), un allarme può avvisare gli operatori via email/SMS/Teams o eseguire azioni correttive automatiche. In termini di gestione, questo significa poter reagire in tempo reale a condizioni critiche ed evitare disservizi o costi imprevisti.
· AzCopy: è un tool specializzato per il trasferimento efficiente di dati su larga scala da e verso Azure Storage. AzCopy funziona a riga di comando e consente, con pochi parametri, di avviare copie di intere cartelle locali verso un blob container, o viceversa scaricare massivamente dati dallo storage. Supporta trasferimenti paralleli, riprese in caso di interruzione, e ottimizzazioni specifiche per massimizzare la velocità su rete WAN. Viene spesso utilizzato per migrazioni (spostare grandi archivi file sul cloud), per backup massivi, o in generale per spostare terabyte di dati in maniera affidabile e veloce. Ad esempio, AzCopy è lo strumento consigliato per importare un grosso dataset in Azure Blob, rispetto a farlo manualmente file per file. Può integrarsi in script e, dato che è ottimizzato proprio per Azure Storage, conosce le SAS e può usarle per autenticarsi senza esporre credenziali.
In aggiunta a questi, vale la pena ricordare che molte funzionalità di gestione di Azure Storage sono accessibili anche tramite il portale web Azure (Azure Portal), che offre un’interfaccia grafica generalista: tramite il portale si possono creare e configurare gli account di archiviazione e navigare un minimo nei dati (ad esempio c’è un file explorer basilare per blob e file). Tuttavia, per un uso intensivo o professionale, gli strumenti dedicati come Storage Explorer o la CLI risultano più comodi e potenti.
Esempi di utilizzo degli strumenti – Un amministratore potrebbe scrivere uno script PowerShell che automaticamente crea un nuovo container Blob per ogni mese, imposta su di esso una regola di lifecycle (es. sposta i blob in Cool dopo 60 giorni, li elimina dopo 2 anni) e genera una SAS di sola lettura valida 24 ore per consentire a un sistema esterno di scaricare tutti i file di report prodotti quel mese. Questo script potrebbe essere pianificato con Azure Automation o in una pipeline DevOps ogni fine mese, ottenendo così una gestione automatica e ripetibile dello storage. Contemporaneamente, il team di operations può aver impostato una dashboard di Azure Monitor dove vengono visualizzati in tempo reale l’utilizzo di banda (egress/ingress) dello storage account, lo spazio rimanente come percentuale della quota e la latenza media delle richieste. Se uno di questi valori supera una soglia (ad esempio banda in uscita troppo alta che potrebbe indicare un uso imprevisto, o latenza elevata che impatta le applicazioni), vengono generate notifiche di allerta. In caso di migrazione di dati da on-premises, il team potrebbe utilizzare AzCopy per caricare decine di milioni di file: si preparano i comandi AzCopy con le relative SAS per autorizzare l’upload e li si esegue su una macchina dedicata, così da trasferire tutto nel minor tempo possibile e con la certezza che eventuali interruzioni di rete non compromettano l’intero processo (AzCopy ritenta e riprende da dove si era fermato). Tutti questi strumenti insieme forniscono un ecosistema completo per gestire Azure Storage a 360 gradi, unendo facilità d’uso, automazione e controllo.
7. Integrazione con altri servizi Azure
Azure Storage non vive isolato: al contrario, è spesso al centro di architetture cloud ibride e si integra con numerosi altri servizi Azure per costruire soluzioni complete. Vediamo alcune integrazioni tipiche:
· Macchine Virtuali (Azure VM): Le VM in Azure fanno forte affidamento su Azure Storage. Innanzitutto, i dischi delle VM (sia il disco del sistema operativo che eventuali dischi dati aggiuntivi) sono implementati come Managed Disks, che come visto sono archiviati in background su Azure Storage (in formati blob particolari). Quando si crea una VM e le si assegna un disco gestito di tipo Standard o Premium, di fatto si sta usando lo storage cloud con i suoi meccanismi di replicazione e backup. Inoltre, le VM possono utilizzare Azure Files per condividere file tra più VM o con utenti on-premises, ad esempio montando una share come unità di rete su Windows o come punto di mount su Linux. Un altro punto di contatto è che le VM (così come altri servizi) spesso inviano i propri log diagnostici e dati di telemetria su un account di archiviazione: ad esempio, è possibile configurare le diagnostic extension di una VM Windows perché salvino gli event log o crash dump su Blob Storage, così da poterli analizzare a posteriori. In scenari di migrazione lift-and-shift, quando si portano su Azure vecchie applicazioni, è comune mantenere le condivisioni file che esse usano spostandole semplicemente su Azure Files, assicurando così che le VM Azure possano accedere ai file nello stesso modo in cui facevano on-premises.
· App Service e Azure Functions: I servizi di piattaforma come App Service (che ospita Web App, API e applicazioni web in modalità PaaS) e Functions (FaaS/Serverless) possono anch’essi beneficiare di Azure Storage. Per le web app, Azure Storage è spesso utilizzato per i contenuti statici: immagini dei siti, file JavaScript, CSS, video – tutte risorse che possono essere servite direttamente da Blob Storage eventualmente abbinato a un CDN per migliorare le performance globali (vedi più avanti). Inoltre, App Service può montare Azure Files come un volume condiviso, ad esempio per applicazioni che hanno bisogno di condividere risorse o stati tra più istanze (cosa non semplice da fare nell’ambiente PaaS puro, ma Azure Files fornisce un comodo “disco di rete” anche in App Service). Le applicazioni in App Service o Functions spesso accedono a dati su Storage usando le SDK o tramite API REST, quindi l’integrazione a livello di codice è molto semplice. Per quanto riguarda la connettività, App Service e Functions possono essere integrati con una Virtual Network attraverso la VNet Integration (nel caso di App Service) o definendo le function con trigger di Event Grid/Queue che sono intrinsecamente collegati a uno storage account. Ciò consente a queste applicazioni di parlare con lo storage account tramite la rete interna se configurato con un Private Endpoint, mantenendo il traffico isolato da internet.
· Data Factory e Synapse Analytics: Nei flussi di Data Engineering e Big Data, Azure Storage svolge il ruolo di data lake e area di atterraggio per grandi volumi di dati. Servizi come Azure Data Factory o le pipeline di Azure Synapse possono collegarsi a una miriade di origini dati (database, API, sistemi esterni, file FTP, ecc.) e trasferire questi dati su Azure Storage – in particolare su Blob Storage o Data Lake Gen2 – come passaggio di ingestione. Ad esempio, un Data Factory pipeline potrebbe connettersi giornalmente a un server SFTP esterno, scaricare nuovi file CSV e salvarli in un container blob. Una volta che i dati grezzi risiedono su Azure Storage, possono essere elaborati: Synapse e altri servizi analitici possono leggere direttamente dal data lake (ad esempio con i notebook Spark o con PolyBase per le query SQL) e trasformare i dati. Data Factory offre anche le Mapping Data Flow, una funzionalità di trasformazione visiva che legge da Blob Storage/Data Lake Gen2, esegue mapping e conversioni di dati, e riscrive il risultato su destinazione (spesso di nuovo uno storage o un data warehouse). In breve, Azure Storage è un componente essenziale in architetture ETL/ELT, fungendo da repository per staging, archiviazione di dati storici e come fonte dati per analisi batch.
· Logic Apps: Azure Storage può essere integrato anche con soluzioni di workflow e integrazione applicativa come Azure Logic Apps. Logic Apps consente di creare flussi di lavoro low-code che reagiscono a trigger e orchestrano azioni su vari servizi. Ci sono connettori nativi per Azure Storage: ad esempio, si può creare un workflow che si attiva quando arriva un nuovo blob in un container specifico, oppure quando un messaggio compare in una Queue Storage. Una volta scatenato, il workflow può eseguire passi come inviare una mail, chiamare un’API, spostare il file da un container a un altro, tradurre contenuti, e così via – senza scrivere codice server, tutto orchestrato visualmente. Allo stesso modo, Logic Apps può scrivere su Storage come parte di un processo (per esempio, potrebbe estrarre dati da un’email e salvarli in un file su Azure Files). Questa integrazione semplifica la creazione di processi automatizzati e applicazioni serverless che coinvolgono lo storage, ad esempio flussi di approvazione documentale, integrazione tra sistemi (un file caricato scatena un inserimento in un database tramite Logic App), o elaborazioni di immagini al volo.
· Event Grid e Functions: Azure Event Grid è un servizio di routing eventi in tempo reale. Lo storage Azure è strettamente integrato con Event Grid: ogni volta che avviene un certo evento su un account di archiviazione (ad esempio creazione di un nuovo blob, eliminazione di un blob, aggiunta di un messaggio in coda, creazione di un file), questo può generare un evento che Event Grid intercetta. È possibile sottoscriversi a questi eventi e fare in modo che vengano inviati a destinazioni come una Azure Function, una coda, una webhook HTTP, o un Logic App. Ad esempio, registrando un Azure Function come handler per l’evento “Blob creato in container X”, ogni volta che qualcuno carica un file in quel container la Function verrà automaticamente invocata e potrà elaborare il file (ridimensionare un’immagine, processare un documento, ecc.). Questo modello event-driven trasforma Azure Storage in un sistema reattivo: invece di dover continuamente fare polling (controlli periodici per vedere se ci sono nuovi file o messaggi), si può contare sul fatto che lo storage “notificherà” immediatamente il verificarsi di eventi importanti. Ciò consente di costruire architetture serverless molto scalabili ed efficienti, in cui le risorse compute (come le Functions) girano solo quando necessario, innescate dai cambiamenti nel livello storage.
Queste integrazioni rendono Azure Storage non solo un luogo dove mettere dati, ma un nodo centrale del flusso applicativo. Permettono di costruire sistemi completi: pensiamo a una soluzione di elaborazione di immagini – l’utente carica un’immagine su Blob Storage, questo scatena un evento Event Grid che invoca una Function di elaborazione, la quale salva il risultato sempre su Blob e aggiunge un messaggio in coda per notificare che è pronto. Oppure un processo di pipeline ETL – Data Factory sposta dati grezzi su Data Lake (Blob) e avvia un job Spark su Synapse che legge quei file e li elabora, poi un Logic App invia un report via email al completamento, il tutto orchestrato utilizzando Storage come mezzo di passaggio. Azure Storage, grazie a queste capacità di integrazione, è alla base di tantissimi scenari cloud: dalla realizzazione di applicazioni web scalabili (dove i file statici e lo stato vengono messi su storage esterno), a complessi flussi di Big Data e AI (dove enormi dataset vengono alimentati ai calcolatori tramite data lake), fino a soluzioni IoT (raccolta di telemetria su Table/Blob, elaborazione eventi in streaming, ecc.).
Esempi di architetture integrate – Un esempio pratico: immaginiamo una applicazione per la gestione di foto. Un utente carica una foto tramite un front-end web; la foto viene salvata su Blob Storage. L’evento “nuovo Blob caricato” attiva una Azure Function tramite Event Grid, che legge la foto, crea una miniatura (thumbnail) e la salva in un altro container Blob, poi registra i metadati (es. URL della thumbnail, autore, data) in una Table Storage per utilizzi futuri. Contemporaneamente, un messaggio viene inserito in Queue Storage per notificare a un componente di post-elaborazione che la foto è pronta per eventuali ulteriori analisi (es. applicare filtri o analisi AI). Questo scenario sfrutta Blob, Event Grid, Functions, Table e Queue insieme per creare un flusso completamente serverless e scalabile di gestione immagini. Un altro caso: un’azienda implementa un processo ETL mensile in cui un Azure Data Factory raccoglie file CSV da vari sistemi sorgente e li carica su un Data Lake (Azure Data Lake Gen2). Una volta caricati, parte un notebook Spark (ospitato su Azure Synapse Analytics) che legge quei file dal data lake, li unisce e normalizza in un grande dataset, quindi salva il risultato aggregato sempre su Storage. Infine, un Logic App invia una notifica o sposta il file risultante su un FTP aziendale. Qui Azure Storage (in modalità data lake) funge da base per l’analisi big data e da mezzo di output, orchestrando i passi con Data Factory e integrando calcolo (Spark) e integrazione (Logic App).
8. Best practice per l’utilizzo di Azure Storage
Nel progettare e gestire soluzioni con Azure Storage, è utile seguire alcune best practice collaudate che riguardano la sicurezza, le performance e l’ottimizzazione dei costi. Riassumiamo i consigli principali:
· Best practice di Sicurezza: abilitare solo accessi sicuri e applicare il principio del minimo privilegio. In particolare, è fortemente consigliato forzare l’uso di HTTPS (il portale consente una checkbox “Secure transfer required” che andrebbe lasciata attiva, così nessuna chiamata non cifrata verrà accettata). Impostare la versione minima TLS a 1.2 o superiore per evitare protocolli deprecati. Utilizzare quando possibile Private Endpoint o almeno regole di firewall IP per limitare la superficie esposta dello storage account alla sola rete necessaria. Gestire i permessi tramite Azure AD (Entra ID) e ruoli RBAC, evitando di condividere le chiavi dell’account. Se per integrazioni servono le chiavi, ruotarle periodicamente e preferire l’uso di SAS limitate nel tempo e nei permessi per fornire accessi delegati a terze parti. Abilitare funzionalità di protezione come Soft Delete e Versioning su Blob (e soft delete su File e Queue) in modo da mitigare eliminazioni accidentali o atti maliziosi. Se si trattano dati sensibili o critici, valutare l’uso di Customer-Managed Keys (CMK) per la crittografia e di policy di immutabilità (WORM) dove necessario. Inoltre, implementare monitoraggio di sicurezza: ad esempio, attivare i log di Azure Storage e utilizzare Azure Defender for Storage (un servizio che analizza i pattern di accesso allo storage per individuare minacce, come malware che esfiltrano dati o attività anomale).
· Best practice di Performance: per ottimizzare le prestazioni, prima di tutto scegliere il giusto tier di servizio. Se un workload richiede bassa latenza costante e alto throughput (ad esempio un sistema di file sharing intensivo), considerare gli account Premium (es. Azure Files Premium) e la replica ZRS (che garantisce latenze intraregionali minime). In generale, mantenere i dati accanto alle risorse di calcolo che li usano (evitare di avere una VM in Europa che legge continuamente dati da uno storage in USA, perché la latenza rete inciderà). Organizzare i dati in modo efficiente: nel caso di Data Lake Gen2, prestare attenzione alla struttura delle cartelle e al naming dei file perché operazioni come l’enumerazione e il listing possono richiedere tempo su directory affollate; in Blob storage evitare di avere milioni di blob tutti nello stesso container con prefissi simili senza gerarchie, poiché Azure li distribuisce su partizioni in base al nome: un pattern consigliato è inserire segmenti di nome differenziati (ad esempio prefissi basati sulla data, come logs/2025/11/23/...) per migliorare la scalabilità. Per trasferimenti massicci, utilizzare strumenti adeguati come AzCopy o la Data Movement Library, che parallelizzano le operazioni e raggiungono velocità nettamente superiori rispetto a copie seriali fatte da codice non ottimizzato. Monitorare costantemente le metriche di latenza e throughput dello storage: se si notano valori anomali (ad esempio latenza del 95° percentile molto alta), potrebbe indicare un hot spot (una “partizione calda” perché troppi client accedono allo stesso oggetto o prefisso) – in tal caso, valutare tecniche di sharding dei dati (distribuire l’accesso su chiavi diverse, es. usando nomi di blob con hash per distribuirli su partizioni multiple). Per Azure Files, considerare l’uso di più share separate se un’unica share diventa collo di bottiglia, oppure l’upgrade a Premium per ottenere prestazioni migliori. Infine, sfruttare Azure CDN o Azure Front Door per i contenuti statici ad alto traffico globale: servire immagini o video direttamente dallo storage a clienti sparsi nel mondo può soffrire di latenza, mentre integrando una CDN i contenuti saranno cache-ati nei punti più vicini agli utenti con enormi benefici in performance e con minore egress direttamente dallo storage.
· Best practice di Gestione Costi: Azure Storage può diventare oneroso se non gestito bene, quindi implementare misure di ottimizzazione dei costi è fondamentale. In primo luogo, usare i tier di accesso Hot/Cool/Archive in maniera appropriata – archiviare dati raramente usati in Hot è uno spreco, così come tenere dati a cui si accede spesso in Archive non è pratico (oltre che lento); sfruttare le Lifecycle policy per automatizzare lo spostamento dei dati verso tier più economici col diminuire della frequenza di utilizzo. Tenere d’occhio i costi di egress (uscita dati): i dati letti dallo storage e inviati fuori dalla regione o su internet generano costi di banda. Se si hanno molti utenti finali che scaricano file, è opportuno posizionare i dati nelle regioni più vicine al consumo e utilizzare servizi come CDN/Front Door per ridurre l’egress dallo storage (la CDN fa cache e serve ripetutamente i dati senza doverli scaricare ogni volta dallo storage origin). Minimizzare le transazioni inutili: ogni operazione (lettura, scrittura, list, etc.) ha un costo per milione di esecuzioni – scrivere un’app che effettua continui listing di un container o controlla troppo spesso la presenza di un file può generare costi significativi; meglio usare meccanismi di notifica (Event Grid) o caching locale quando possibile. Per risparmiare sui costi a lungo termine, valutare le Azure Reservations per Storage quando disponibili, o i piani di capacità riservata (ad esempio per Azure Files e Azure Blob esistono opzioni di prenotare una certa capacità per 1 o 3 anni a prezzo scontato, utile se si sa di avere sempre almeno X TB occupati). Utilizzare i tag per tracciare la pertinenza dei costi e poi analizzarli con Azure Cost Management: questo aiuta a individuare sprechi (es. un ambiente di test dimenticato con molti dati inutili). Infine, considerare le opzioni di replica solo quando servono: ad esempio, RA-GZRS ha costi maggiori di GZRS che a sua volta è più costoso di LRS – se l’applicazione non ha un reale bisogno di lettura da regione secondaria, evitare di pagare per RA-GZRS e scegliere magari GZRS o ZRS. Allo stesso modo, se certi dati sono veramente non critici, si potrebbe usare LRS e affiancare un flusso di backup specifico invece di pagare per GRS continuamente.
Esempi di best practice in azione – Un amministratore definisce una policy di lifecycle per un importante container Blob di backup: “se l’ultimo modificato supera 30 giorni, passa il blob in Cool; oltre 180 giorni, sposta in Archive; elimina completamente dopo 7 anni”. Questa singola regola garantisce che lo spazio occupato in Hot (il più costoso) sia limitato ai backup recenti, mentre quelli vecchi vengono gradualmente portati su storage più economico e infine rimossi quando non più necessari, il tutto senza intervento manuale. Sul fronte sicurezza, un’azienda abilita l’accesso tramite Azure AD per tutti i servizi: così nessun sviluppatore utilizza direttamente le chiavi dell’account nei codici, ma si usano identità gestite e ruoli (ad esempio un’app web ha il ruolo “Storage Blob Data Reader” solo sul container che le serve). Inoltre, viene impostato che solo TLS 1.2+ è permesso e si disabilita qualsiasi cipher suite debole nelle impostazioni dell’account. Per tenere sotto controllo le performance, il team configura un alert sul 95° percentile di latenza: se per 5 minuti la latenza delle operazioni supera, poniamo, i 200 ms, scatta un allarme. Durante un incidente, questo alert notifica il team, che scopre ad esempio un pattern di accesso inefficiente (molte letture ripetute dello stesso blob da parte di troppe istanze) e decide di inserire una cache applicativa per ridurre il carico. Un altro alert è impostato sul costo di egress mensile: se supera una certa soglia nel mezzo del mese, significa che c’è stato un insolitamente alto traffico in uscita – la causa potrebbe essere un client male configurato che riscarica dati in loop, o un endpoint pubblico che qualcuno sta sfruttando impropriamente. In tal caso si indaga e si corre ai ripari (per esempio, abilitando un CDN o restringendo meglio l’accesso pubblico). Questi esempi mostrano come l’uso combinato di tecniche di configurazione, monitoraggio e automazione permetta sia di prevenire problemi di sicurezza/performance, sia di ottimizzare i costi senza sacrificare le funzionalità del servizio.
9. Casi d’uso e scenari pratici
Azure Storage è estremamente flessibile e può essere impiegato in molteplici scenari. Vediamo tre grandi categorie di utilizzo e come la piattaforma risponde alle relative esigenze, seguite da esempi concreti:
· Backup e Disaster Recovery (BCDR): Una delle applicazioni più immediate di Azure Storage è come destinazione per backup cloud e soluzioni di Business Continuity/Disaster Recovery. Grazie al basso costo dei tier Cool e Archive, e all’elevata durabilità con opzioni geo-ridondate, Blob Storage risulta ideale per conservare copie di backup di file, database, macchine virtuali e altri workload. Strumenti come Azure Backup o Azure Backup Center si integrano nativamente con lo storage: ad esempio, Azure Backup può salvare i backup delle VM direttamente in Vault che sotto il cofano utilizzano Blob Storage (tier Cool/Archive per risparmiare). Inoltre, sfruttando caratteristiche come le immutability policy (WORM), si può garantire che i dati di backup non vengano alterati o cancellati per un certo periodo – creando di fatto un archivio inviolabile, utile contro ransomware o errori umani. In caso di disaster recovery, se si è adottata una replica geografica (GRS/RA-GZRS), i dati critici di backup sono già presenti in un’altra regione pronti per il ripristino. Per proteggersi da cancellazioni accidentali, funzionalità come Soft Delete assicurano che eventuali blob eliminati possano essere recuperati entro il periodo di retention. Quindi, Azure Storage fornisce un’infrastruttura di backup robusta: economica sul lungo termine, sicura grazie alla cifratura e alle policy WORM, e resiliente grazie alla replica geografica.
· Big Data e Analytics: In scenari di Analisi dati, AI e Big Data, Azure Storage gioca il ruolo del data lake. La variante Azure Data Lake Storage Gen2 (basata su Blob) offre un file system Hadoop-compatibile dove depositare dati grezzi, semilavorati e risultati. Grazie al supporto di ACL, directory gerarchiche e throughput elevato, un Data Lake Gen2 su Azure può fungere da fondazione per architetture di tipo lakehouse: i dati raccolti da varie origini (log, transazioni, IoT, etc.) vengono salvati in formato file (CSV, Parquet, JSON) sul data lake; strumenti come Azure Synapse Analytics, Databricks o cluster HDInsight possono accedere direttamente a questi file per eseguire analisi, training di modelli di machine learning, aggregazioni su larga scala con Spark o Hive. Anche servizi come Power BI possono connettersi a file Parquet nel data lake per analisi business intelligence su grandi volumi senza spostare tutto in un database. Azure Storage in questo contesto brilla per la scalabilità massiva (può contenere centinaia di terabyte o petabyte), per il costo contenuto rispetto a mantenere dati in un database transazionale, e per l’integrazione con strumenti batch/elaborazione distribuita. Inoltre, la separazione tra storage e compute tipica del data lake consente di scalare indipendentemente: è possibile avere i dati fermi su storage a basso costo, e accendere potenza di calcolo (Synapse, Databricks) solo quando serve per elaborarli, ottimizzando i costi complessivi della piattaforma dati. Quindi Azure Storage è l’alleato chiave per implementare pipeline ETL/ELT efficienti e data reservoir per analisi avanzate.
· Web App e Content Delivery: Per applicazioni web, mobile e distribuzione di contenuti, Azure Storage fornisce soluzioni semplici e robuste. Un classico Web Application moderno può sfruttare Blob Storage per ospitare tutti i contenuti statici del sito: immagini, file CSS e JavaScript, documenti scaricabili, video di marketing, ecc. Questi blob possono essere serviti direttamente ai client con altissime prestazioni, specialmente in combinazione con servizi come Azure CDN o Azure Front Door, che cache-ano i contenuti statici in nodi globali avvicinandoli geograficamente agli utenti e sgravando il carico sullo storage origin (oltre a fornire funzioni di compressione, HTTPS globale, ecc.). Per la parte applicativa dinamica, servizi come App Service gestiscono il codice, ma possono anch’essi archiviare configurazioni o output su Azure Storage (ad esempio, un web app potrebbe salvare foto profilo utenti su Blob e solo un riferimento nel database). Inoltre, un pattern comune è usare Azure Files come “contenitore condiviso” per applicazioni multiistanza: immaginando un cluster di server web in Kubernetes o VM scale set, questi possono montare una share Azure Files per condividere tra loro file necessari (ad es. immagini caricate dagli utenti, generati dall’app). Azure Storage supporta benissimo anche le architetture a microservizi tipiche delle web app cloud: ad esempio, un e-commerce potrebbe usare Queue Storage per gestire in maniera asincrona le attività (un ordine messo in coda e processato da un servizio di backend), e Table Storage per memorizzare sessioni utente o carrelli in modo veloce senza dover impostare un intero database. Il tutto con la garanzia che l’app può scalare orizzontalmente: aggiungendo più istanze di compute, esse condividono lo stesso depositi di dati su storage, anziché avere file locali da sincronizzare.
Questi casi mostrano come Azure Storage possa adattarsi dal cold storage per backup, al core di piattaforme dati, fino al backend di applicazioni web globali.
Esempi finali di casi d’uso reali – Per concreti contesti combinati: una azienda sanitaria potrebbe utilizzare Azure Storage in questo modo – archiviare le immagini diagnostiche (esami radiologici in formato DICOM) come Blob in un container protetto, applicando una politica di immutabilità WORM per garantire che i referti storici non vengano alterati. Utilizzerebbe inoltre il tier Cool o Archive per i dati più vecchi riducendo i costi, e la replica GRS per avere una copia di emergenza fuori area. I metadati di questi esami (nome paziente, data, tipo di esame) potrebbero essere salvati in una Table Storage per rapide consultazioni. Quando i data scientist dell’azienda vogliono fare analisi aggregate (es. statistiche sugli esiti), potrebbero usare Azure Synapse per eseguire query direttamente sui blob DICOM o sui loro metadati nel data lake. Un altro scenario, un e-commerce globale, sfrutta Azure Storage per vari scopi integrati: i contenuti statici del sito (immagini prodotto, file HTML pre-renderizzati) risiedono su Blob Storage e vengono distribuiti tramite una CDN per servire velocemente clienti in tutto il mondo; le operazioni di ordine sono gestite con un pattern a microservizi dove, quando un cliente effettua un acquisto, i dettagli vengono inseriti in una Queue Storage così che un servizio di order processing li prenda in carico e li elabori (aggiornando magari l’inventario, mandando conferme email, etc.) senza rallentare il front-end; i documenti generati (fatture PDF, etichette di spedizione) vengono salvati su Azure Files, così che diversi moduli (ad es. il sistema di spedizione, il servizio clienti) possano accedere a questi file condivisi facilmente; tutti i log di transazione e i dati grezzi delle vendite giornaliere vengono infine copiati in un Data Lake (blob) dove un processo notturno di analisi li combina con dati di marketing per produrre report di business. Grazie ad Azure Storage, la piattaforma e-commerce ottiene scalabilità (può gestire picchi di traffico delegando a code e storage la resilienza delle componenti), affidabilità (i dati importanti sono su storage duraturo, separati dai server effimeri), e insight (avendo i dati centralizzati, è più facile analizzarli e trarne valore).
In conclusione, Azure Storage rappresenta un fondamentale mattone dell’infrastruttura cloud: con i suoi diversi servizi e opzioni, fornisce uno spazio affidabile dove collocare dati e un insieme di funzionalità per proteggerli, gestirli sul lungo termine e integrarli nel resto dell’ecosistema Azure. Sia che si tratti di un semplice backup, di alimentare un’applicazione web mondiale, o di fare da base a un lago di dati per machine learning, Azure Storage offre gli strumenti e la flessibilità per costruire soluzioni cloud robuste e scalabili.
Conclusioni
In questo capitolo abbiamo visto che Azure Storage è una piattaforma cloud completa che consente di archiviare e gestire dati in modo sicuro e scalabile, supportando scenari che spaziano dal backup alle applicazioni web e big data. I servizi principali includono Blob Storage per dati non strutturati, Azure Files per condivisioni SMB/NFS, Queue Storage per messaggi asincroni e Table Storage per dati NoSQL, ciascuno con casi d’uso specifici. La configurazione di uno Storage Account richiede scelte su subscription, regione, performance, ridondanza e rete, con preferenza per gli account General Purpose v2. Le opzioni di replica, come LRS, ZRS e GRS, garantiscono disponibilità e resilienza, mentre varianti RA-GRS/RA-GZRS offrono accesso in sola lettura alla replica secondaria. La sicurezza è assicurata da cifratura, autenticazione con Azure AD e SAS, firewall, Private Endpoint e funzioni di soft delete e versioning. Blob Storage offre tier Hot, Cool e Archive per ottimizzare costi e prestazioni, con policy di lifecycle automatizzate. Strumenti come Storage Explorer, CLI, PowerShell e AzCopy semplificano la gestione e i trasferimenti, mentre Azure Monitor e Log Analytics supportano il monitoraggio. L’integrazione con altri servizi Azure abilita scenari avanzati come data lake, workflow automatizzati e architetture a microservizi. Le best practice includono l’uso di HTTPS, TLS 1.2+, Private Endpoint, monitoraggio costi e scelta corretta di tier e replica. Infine, i casi d’uso spaziano da backup e disaster recovery a big data e hosting di contenuti statici per applicazioni web.
Riepilogo capitolo
Azure Storage offre una piattaforma di archiviazione cloud completa, con servizi diversificati per gestire dati non strutturati, file, code e tabelle, supportando scenari che vanno dal backup al big data fino alle applicazioni web. La configurazione degli account di archiviazione e le opzioni di ridondanza sono cruciali per garantire performance, sicurezza e disponibilità dei dati.
· Servizi principali di archiviazione: Azure Storage comprende Blob Storage per dati non strutturati e grandi file, Azure Files per condivisioni file gestite con protocolli SMB e NFS, Queue Storage per messaggistica asincrona e Table Storage per dati NoSQL semi-strutturati, ciascuno con caratteristiche specifiche e casi d’uso distinti.
· Configurazione degli Storage Account: La creazione di uno storage account richiede la scelta di subscription, nome univoco, regione, performance (Standard o Premium), ridondanza dati, opzioni di rete (endpoint pubblici, privati o service endpoint) e tag per la gestione, con la preferenza per account General Purpose v2 che supporta tutte le funzionalità moderne.
· Opzioni di ridondanza dati: Azure Storage offre LRS (replica locale in un data center), ZRS (replica sincrona su zone di disponibilità della stessa regione), GRS (replica geografica asincrona in altra regione), e varianti RA-GRS/RA-GZRS che permettono accesso in sola lettura alla replica secondaria, bilanciando costi, durabilità e requisiti di compliance.
· Sicurezza e controllo accesso: La protezione dei dati include cifratura a riposo e in transito, autenticazione tramite Azure AD e Shared Access Signature, restrizioni di rete con firewall e Private Endpoint, funzioni di soft delete e versioning per prevenire perdite accidentali, e monitoraggio con Azure Monitor e Log Analytics per audit e rilevamento anomalie.
· Tier di archiviazione: Blob Storage supporta tier Hot (accesso frequente e veloce), Cool (accesso meno frequente a costi inferiori) e Archive (archiviazione a lungo termine con accesso ritardato), con policy di lifecycle per automatizzare lo spostamento dei dati tra i tier in base all’età o all’uso, ottimizzando costi e prestazioni.
· Strumenti di gestione: Azure Storage Explorer fornisce un’interfaccia grafica per la gestione manuale, mentre Azure CLI e PowerShell supportano automazione e scripting. AzCopy è dedicato a trasferimenti massivi di dati efficienti. Azure Monitor e Log Analytics aiutano nel monitoraggio e nell’alerting per performance e sicurezza.
· Integrazione con servizi Azure: Azure Storage si integra con VM, App Service, Functions, Data Factory, Synapse Analytics, Logic Apps ed Event Grid, abilitando scenari come data lake, elaborazioni serverless, workflow automatizzati e architetture a microservizi scalabili e resilienti.
· Best practice: Si raccomanda di forzare HTTPS e TLS 1.2+, usare Private Endpoint o firewall IP, gestire accessi con Azure AD e SAS, abilitare soft delete e versioning, monitorare costi e performance, scegliere tier e replica in base a requisiti di latenza e durabilità, e utilizzare lifecycle policy per ottimizzare i costi.
· Casi d’uso: Azure Storage supporta backup e disaster recovery con tier economici e immutabilità, funge da data lake per big data e analytics con Data Lake Gen2, e serve contenuti statici e backend di applicazioni web, con esempi concreti in sanità, e-commerce e flussi ETL integrati.
CAPITOLO 5 – Il servizio networking
Introduzione
Azure offre un insieme di servizi di networking che costituiscono i mattoni fondamentali per connettere in modo sicuro e performante le risorse nel cloud e tra cloud e ambienti on-premises. Questi servizi permettono di creare reti private in Azure, estenderle al proprio datacenter, distribuire il traffico in modo efficiente e proteggere le applicazioni da minacce informatiche. I tre obiettivi chiave dell’infrastruttura di rete Azure sono: garantire una connessione sicura tra le risorse cloud e on-premises, abilitare una gestione centralizzata di reti e sicurezza, e offrire scalabilità flessibile per adattarsi alle esigenze di carico. In pratica, Azure mette a disposizione componenti come reti virtuali (VNet), gateway di rete, gruppi di sicurezza (NSG), firewall e molti altri, accessibili e configurabili tramite il portale Azure o API.
Insieme, questi servizi consentono di costruire architetture moderne (ad esempio basate su microservizi, ambienti ibridi o distribuiti su più regioni) riducendo i rischi e migliorando l’esperienza utente. Nelle sezioni seguenti esamineremo i principali componenti del networking di Azure e le loro funzionalità, con titoli e sottotitoli che aiutano a strutturare i concetti. Al termine, una tabella riassuntiva presenterà i servizi principali di Azure Networking con le rispettive funzionalità chiave.
Esempio scenario: una società di retail collega i propri negozi fisici al backend di e-commerce ospitato su Azure: crea una VNet con subnet separate per i livelli web, app e database; stabilisce una connessione VPN site-to-site tra la VNet e la rete della sede centrale; usa un Load Balancer per garantire alta disponibilità delle istanze web; applica NSG per consentire solo le porte e gli indirizzi necessari a ogni subnet; e inserisce un Azure Firewall nel percorso per controllare centralmente il traffico in uscita. Questo esempio racchiude diversi servizi Azure che cooperano per realizzare un’infrastruttura di rete sicura, resiliente e gestibile.
Inquadramento argomenti del capitolo con slides illustrate
Azure Networking fornisce le basi per connettere in modo sicuro e performante le risorse cloud e on-premises. Offre gestione centralizzata di reti e sicurezza, oltre a una scalabilità flessibile. La Virtual Network crea un perimetro privato isolato nel cloud, mentre servizi come VPN Gateway ed ExpressRoute collegano Azure con datacenter e uffici. Il traffico viene distribuito da Load Balancer, Application Gateway e Front Door. La sicurezza è garantita da Network Security Groups, Azure Firewall, DDoS Protection e Microsoft Defender for Cloud. Azure DNS gestisce i nomi e Network Watcher offre strumenti di osservabilità. Questi servizi permettono architetture moderne, riducendo i rischi e migliorando l'esperienza utente. Ad esempio, una azienda retail può collegare negozi all’e-commerce su Azure usando VNet, subnet dedicate, VPN site-to-site, Load Balancer, NSG e Firewall. Consulta il diagramma a blocchi per visualizzare i principali servizi e i flussi tra on-premises e cloud.
La Virtual Network, o VNet, è il dominio di routing privato in Azure. Qui definisci spazio di indirizzi, subnet, route e integrazioni. Puoi distribuire macchine virtuali, AKS, App Service Environments e Private Endpoints di servizi PaaS. La comunicazione tra risorse avviene su IP privati, e l’accesso a Internet è consentito solo tramite configurazioni specifiche come IP pubblici, NAT, o Load Balancer. Le VNet possono collegarsi tra loro con peering, anche tra regioni diverse, e offrire connettività ibrida tramite VPN Gateway o ExpressRoute. Il traffico è controllato tramite NSG e User-Defined Routes. Ad esempio, in un ambiente dev/test puoi creare subnet separate per sviluppo e test, impostare peering verso una VNet shared-services e limitare l’accesso tramite regole NSG. Consulta lo schema per l’indirizzamento IP e il diagramma di peering tra VNet.
Le subnet suddividono la VNet in segmenti logici, migliorando sicurezza e gestione del traffico. Separare web, app e database consente di applicare Network Security Groups mirati, registrare i flussi, ottimizzare le route e assegnare efficientemente gli indirizzi IP. Puoi associare service endpoints o private endpoints per accedere a servizi PaaS tramite la rete privata e usare User-Defined Routes e Network Virtual Appliance per routing avanzato. Le subnet supportano deleghe a servizi specifici e policy di sicurezza. È importante pianificare la capacità e utilizzare nomi coerenti. Un esempio pratico: la subnet web permette solo il traffico HTTP e HTTPS dal Front Door, quella app solo dal livello web, mentre la subnet data usa un Private Endpoint verso SQL. Consulta il diagramma a tre livelli per visualizzare le comunicazioni tra subnet.
I Network Security Groups, o NSG, filtrano il traffico in ingresso e uscita tramite regole personalizzabili su protocollo, porta, origine e destinazione. Le regole hanno una priorità: quelle con numero più basso sono valutate per prime. Puoi associare NSG a subnet o a singole interfacce di rete delle VM. Le regole predefinite negano tutto il traffico inbound esterno e permettono quello intra-VNet. Utilizza service tags e Application Security Groups per semplificare la gestione. Documenta e monitora le regole usando NSG flow logs con Network Watcher. Ad esempio, puoi consentire solo il traffico HTTP e HTTPS dal web verso frontend e negare tutto il resto, oppure permettere l’accesso a database solo dalla app-tier. Consulta la tabella delle regole NSG e il flusso di valutazione delle regole.
Con Azure puoi collegare in modo sicuro ambienti on-premises e cloud tramite VPN Gateway ed ExpressRoute. Il VPN Gateway crea tunnel IPsec/IKE site-to-site tra Azure e firewall o router aziendali, oppure point-to-site per accesso remoto degli utenti. Scegli lo SKU in base alla banda e alle funzionalità richieste. ExpressRoute offre una connessione privata e dedicata alla rete Microsoft, ideale per alti requisiti di latenza e banda. Puoi combinare ExpressRoute con VPN per il failover e usare BGP per lo scambio dinamico delle route. Virtual WAN semplifica la gestione di più siti. Ad esempio, la sede HQ può usare una connessione site-to-site, gli utenti mobili point-to-site e il data center primario ExpressRoute con forced tunneling. Consulta il diagramma per i percorsi di connettività e failover.
Azure Load Balancer, di livello 4, distribuisce traffico TCP e UDP verso macchine virtuali o scale set, utilizzando health probes per verificare lo stato dei backend. È ideale per scenari interni o pubblici ad alte prestazioni. Per il traffico HTTP e HTTPS, Application Gateway opera a livello 7, offre funzionalità avanzate come Web Application Firewall e routing basato su URL o host. Azure Front Door fornisce accelerazione globale, caching e failover geografico. Scegli lo strumento in base alle esigenze: Load Balancer per trasporto, Application Gateway per routing applicativo e protezione, Front Door per performance globali. Ad esempio, una soluzione multi-zona può usare Front Door davanti alle regioni, Application Gateway con WAF in ciascuna regione e Load Balancer interno per comunicazioni tra microservizi. Visualizza la catena di bilanciamento nel diagramma dedicato.
Azure Firewall offre filtraggio stateful, regole applicative e di rete centralizzate, integrazione con Threat Intelligence e funzionalità IDPS avanzate. DDoS Protection Standard protegge dalle minacce volumetriche a livello VNet. Microsoft Defender for Cloud calcola il secure score, fornisce raccomandazioni e protegge carichi di lavoro con piani specifici per VM, container e servizi PaaS. L’approccio Zero Trust richiede il controllo di identità, dispositivi e rete: implementa NSG, Firewall, Private Endpoints, Just-In-Time per accesso amministrativo e Conditional Access. Ad esempio, una VNet hub-security ospita il firewall, mentre spoke app e data indirizzano il traffico outbound tramite UDR verso il firewall. DDoS e Defender sono attivi, con JIT sulle VM admin. Consulta lo schema hub-and-spoke di sicurezza.
Azure DNS gestisce zone pubbliche e private garantendo alta disponibilità e bassa latenza. Le private DNS zones risolvono nomi interni tra VNet collegate, sostituendo spesso server DNS personalizzati. Puoi automatizzare la gestione dei record tramite Azure CLI o PowerShell e integrare DNS con Traffic Manager o Front Door per il routing globale. Per la risoluzione ibrida, Azure DNS Private Resolver consente l’inoltro verso DNS aziendali. Ad esempio, puoi gestire una zona pubblica contoso.com in Azure e una zona privata contoso.local collegata a diverse VNet, usando Private Resolver per l’inoltro. Consulta la tabella dei record DNS e il diagramma pubblico/privato con resolver ibrido.
Network Watcher offre strumenti avanzati per monitorare e diagnosticare la rete. Connection Monitor verifica percorsi e latenza tra endpoint, Topology visualizza le dipendenze tra risorse, NSG flow logs e Traffic Analytics analizzano i flussi di traffico, Packet Capture raccoglie pacchetti su VM per indagini dettagliate. IP Flow Verify e Next Hop aiutano a validare regole e routing. L’integrazione con Azure Monitor abilita alert e dashboard personalizzati. Utilizza questi strumenti durante migrazioni, incidenti e ottimizzazioni. Ad esempio, puoi configurare Connection Monitor tra Application Gateway e backend, abilitare flow logs sugli NSG e analizzare le prestazioni tramite workbook di latenza e errori. Osserva il cruscotto con grafici, mappe topology e tabelle flow logs per un controllo completo.
Quando progetti soluzioni su Azure Networking, segui alcune linee guida fondamentali. Utilizza il modello hub-and-spoke per centralizzare sicurezza e servizi condivisi nel hub, mentre gli spoke ospitano applicazioni e dati. Applica il principio Zero Trust: NSG su ogni subnet, firewall per traffico in uscita, Private Endpoints per servizi PaaS e segmentazione minima necessaria. Per l’alta disponibilità, distribuisci risorse su Availability Zones, usa bilanciatori di carico con health probe e attiva DDoS Standard su VNet critiche. Cura la governance con naming coerente, Azure Policy per i requisiti obbligatori e Blueprint per standardizzare. Mantieni alta l’osservabilità abilitando Network Watcher, log e alert. Ottimizza i costi scegliendo i servizi più adatti e limitando il traffico in uscita. Consulta l’Azure Architecture Center e la documentazione ufficiale per approfondire. Guarda il disegno hub-and-spoke e la checklist delle best practice per una panoramica completa.
1. Reti Virtuali (Azure Virtual Network - VNet)
La rete virtuale Azure, chiamata Virtual Network (VNet), è il componente di base del networking in Azure. Una VNet rappresenta un perimetro di rete privato isolato nel cloud. All’interno di una VNet si definisce uno spazio di indirizzi IP privati (in notazione CIDR) suddivisibile in sottoreti (subnet). In questo spazio, è possibile distribuire macchine virtuali (VM) e altri servizi Azure (come cluster AKS per i container, App Service Environment per le applicazioni web su piattaforma PaaS, e Private Endpoint per connettere in modo privato i servizi PaaS). Tutte queste risorse all’interno della VNet possono comunicare tra loro usando indirizzi IP privati, garantendo isolamento dal traffico Internet pubblico.
Per impostazione predefinita, il traffico Internet in uscita è bloccato a meno che non venga esplicitamente abilitato, ad esempio assegnando alle risorse un IP pubblico o usando servizi come il NAT gateway o un load balancer pubblico. È possibile espandere o integrare una VNet in vari modi:
· Peering tra VNet: consente di collegare due reti virtuali (nella stessa regione o in regioni diverse) in modo che il traffico possa fluire tra di esse con latenza minima e senza passare per Internet. Il peering è utile per costruire architetture complesse multi-rete, ad esempio collegando una VNet di frontend con una VNet di servizi condivisi.
· Connettività ibrida: una VNet può essere collegata alla rete on-premises dell’azienda tramite un VPN Gateway (uso di tunnel criptati IPsec/IKE su Internet) o tramite ExpressRoute (connessione diretta dedicata). Queste opzioni saranno approfondite in seguito, ma in breve permettono di estendere in modo sicuro la propria rete aziendale dentro Azure, come se la VNet fosse una porzione remota del datacenter.
· Controllo del routing: Azure fornisce tabelle di route predefinite per instradare il traffico all’interno della VNet e verso l’esterno. È possibile personalizzare l’instradamento con le User-Defined Routes (UDR), definendo rotte statiche per deviare traffico verso dispositivi specifici (ad esempio verso un’appliance di rete virtuale di terze parti, Network Virtual Appliance). Questo risulta utile in scenari avanzati, ad esempio per forzare il traffico di uscita attraverso un firewall centralizzato.
· Sicurezza integrata: la VNet lavora con i Network Security Groups (NSG) per filtrare il traffico a livello di rete (come vedremo dettagliatamente più avanti). Si possono applicare NSG sia alle subnet che alle singole interfacce di rete delle VM all’interno della VNet, per controllare quali comunicazioni sono permesse o negate.
In sintesi, la VNet offre isolamento, segmentazione e controllo della rete nel cloud Azure: definendo il proprio schema di indirizzamento IP, le subnet interne e le regole di accesso, si ottiene un ambiente sicuro in cui distribuire servizi cloud mantenendo il controllo sulle comunicazioni.
Esempio: in un ambiente Dev/Test aziendale, si può creare una VNet (es. 10.20.0.0/16) suddivisa in due subnet, dev e test, isolate tra loro. Queste subnet possono essere connesse in peering a una VNet separata di shared services (dove risiedono servizi comuni come logging, jump-box Bastion, ecc.). Si applicherebbero NSG a queste subnet per consentire, ad esempio, solo traffico RDP/SSH proveniente dagli IP aziendali verso le VM di sviluppo.
2. Subnet (Segmentazione Logica della Rete)
All’interno di una VNet, le subnet permettono di suddividere la rete virtuale in segmenti logici più piccoli. Questa segmentazione è fondamentale per organizzare i carichi di lavoro e applicare policy di sicurezza mirate. Ad esempio, suddividere la VNet in subnet denominate web, app e database consente di applicare Network Security Group specifici a ciascun livello, registrare separatamente i flussi di traffico e ottimizzare l’allocazione degli indirizzi IP.
Le subnet ereditano lo spazio di indirizzi IP dalla VNet principale, pertanto occorre pianificare attentamente la suddivisione in modo da allocare sufficiente spazio IP a ogni segmento tenendo conto della crescita futura, lasciando un margine di indirizzi inutilizzati per espansioni. È buona pratica definire convenzioni di nomenclatura coerenti per le subnet (esempio: prd-web-subnet1, dev-db-subnet2, ecc.) e per le gamme IP, semplificando la gestione e la comprensione dell’architettura.
Servizi integrati nelle subnet: Azure consente di associare funzionalità specifiche alle subnet:
· I Service Endpoints e i Private Endpoints collegano le subnet a servizi PaaS Azure (come Azure Storage o Azure SQL Database) attraverso la rete privata. Usando un private endpoint, ad esempio, un database SQL in Azure può avere un indirizzo IP privato all’interno della subnet data di una VNet, evitando l’esposizione su Internet e permettendo l’accesso solo dall’interno della rete aziendale.
· Le subnet supportano la delegation a determinati servizi Azure. Ciò significa che una subnet può essere "dedicata" a un servizio gestito (ad esempio Azure Container Instances, Azure NetApp Files, ecc.), consentendo a quel servizio di creare automaticamente risorse di rete all’interno della subnet.
· Su ogni subnet è possibile applicare policy di sicurezza tramite Azure Policy, per assicurare configurazioni conformi (ad esempio, impedire che risorse in una subnet possano avere IP pubblici, o imporre l’uso di NSG).
La segmentazione tramite subnet migliora anche la sicurezza e il controllo del traffico: le regole degli NSG possono essere scritte per permettere comunicazioni solo tra subnet specifiche, limitando ad esempio che i server del livello web possano raggiungere direttamente il livello database se non tramite il livello app. Inoltre, combinando subnet con route personalizzate (UDR) e dispositivi come firewall (Network Virtual Appliance), si può creare percorsi obbligati per il traffico, aggiungendo ulteriori ispezioni o filtri tra le subnet.
Esempio: si consideri una VNet con tre subnet: web (10.10.1.0/24), app (10.10.2.0/24) e data (10.10.3.0/24). La subnet web è configurata con un NSG che consente ingressi sulle porte 80/443 solo dal servizio Azure Front Door (che funge da ingresso HTTP globale) e nega ogni altro traffico in entrata. La subnet app consente traffico in ingresso solo proveniente dalla subnet web (sulla porta appropriata per il servizio applicativo) e niente altro. La subnet data non espone direttamente alcuna porta, ma contiene un Private Endpoint che la collega in modo privato a un database Azure SQL: in questo modo, i server app possono raggiungere il database attraverso l’endpoint privato sulla rete Azure, senza passare per l’esterno.
3. Gruppi di Sicurezza di Rete (Network Security Groups - NSG)
I Network Security Groups (NSG) sono il meccanismo di controllo del traffico a livello di rete in Azure. Funzionano in modo simile ai filtri di firewall L3/L4, applicando regole di permit/deny su traffico in ingresso e in uscita per risorse Azure. Ogni regola di un NSG specifica un criterio basato su: direzione (inbound o outbound), protocollo (TCP, UDP, ICMP o Any), porta (o intervallo di porte), indirizzo origine e destinazione (che possono essere singoli IP, intervalli, oppure tag predefiniti) e un’azione Consenti o Nega. Le regole sono valutate secondo una priorità numerica: i numeri più bassi indicano regole ad alta priorità che vengono valutate per prime. Non appena una regola corrisponde al traffico in esame (match), l’azione viene applicata e la valutazione si interrompe.
Gli NSG possono essere associati a livello di subnet (proteggendo tutte le risorse all’interno di quel segmento) o a livello di scheda di rete (NIC), per definire regole specifiche su singole VM o istanze. Azure fornisce alcune regole predefinite in ogni NSG: ad esempio, tutto il traffico in ingresso da Internet è negato di default, mentre il traffico all’interno della VNet è consentito di default, così come alcune comunicazioni essenziali Azure (come la possibilità per le VM di comunicare con il servizio DNS Azure). Queste regole di default assicurano un livello base di sicurezza; l’utente può poi aggiungere regole personalizzate per permettere i servizi richiesti (ad esempio apertura della porta 443 per un web server).
Per semplificare la gestione di regole su larga scala, Azure offre Service Tags e Application Security Groups (ASG): i Service Tag sono etichette che rappresentano insiemi di indirizzi gestiti da Azure (ad esempio Internet, VirtualNetwork, AzureLoadBalancer, Storage, AzureSQL etc.), utilizzabili al posto di espliciti indirizzi IP nelle regole. Ad esempio, una regola può consentire accesso in ingresso solo se l’origine è ServiceTag:Internet, o può consentire uscita solo verso ServiceTag:AzureSQL (che comprende gli IP dei servizi Azure SQL). Gli Application Security Group, invece, permettono di definire insiemi logici di macchine virtuali (ad esempio un ASG chiamato "web-servers" assegnato a tutte le VM del frontend) e usare questi gruppi come origine o destinazione nelle regole NSG, invece di gestire singolarmente gli IP di ogni VM. Questo facilita l’applicazione di policy uniformi a gruppi di istanze con un ruolo simile.
Una buona prassi è documentare e versionare le regole NSG, soprattutto in ambienti complessi, e utilizzare strumenti di monitoraggio per tenere traccia del traffico filtrato. Azure Network Watcher fornisce i NSG flow logs, log dettagliati del traffico consentito o negato dalle regole NSG, che possono essere analizzati (ad esempio con Azure Monitor o Traffic Analytics) per comprendere i pattern di traffico o diagnosticare problemi di connettività.
Esempio: si hanno due NSG in un’applicazione a più livelli: NSG-web associato alla subnet del frontend web, che consente traffico HTTP/HTTPS (porta 80/443) in ingresso dall’esterno (Service Tag Internet) verso le VM del gruppo web-frontends (un ASG) e verso i servizi di Storage di Azure (Service Tag Storage, per permettere alle web app di accedere a file statici), ma nega ogni altro traffico inbound. Inoltre, NSG-web potrebbe permettere il traffico in uscita solo verso determinati servizi esterni o di Azure necessari, negando tutto il resto. Il NSG-db, associato magari alla subnet database, consente solo la porta 1433 (SQL) in ingresso, e solo proveniente dal gruppo app-tier ASG (ovvero dalle VM del livello applicativo), negando tutto il traffico in uscita diretto a Internet per i server database. In questo modo i database possono essere contattati solo dai server applicativi interni e non possono chiamare servizi esterni se non esplicitamente previsto.
4. Connettività Ibrida (VPN Gateway ed ExpressRoute)
Spesso le risorse in Azure devono integrarsi con reti locali esistenti, come datacenter aziendali o uffici. Per implementare una connettività ibrida (cioè il collegamento sicuro tra la rete on-premises e Azure), si utilizzano principalmente due soluzioni: VPN Gateway ed ExpressRoute.
VPN Gateway (Reti private virtuali tramite VPN)
Il servizio VPN Gateway di Azure permette di creare tunnel VPN criptati tra la VNet Azure e la rete on-premises attraverso Internet. Utilizza protocolli standard IPsec/IKE per stabilire connessioni site-to-site (da un appliance o router VPN nella rete locale verso il gateway in Azure) oppure connessioni point-to-site (P2S) in cui singoli client remoti stabiliscono una VPN verso Azure, utile per telelavoro o accesso degli utenti in mobilità.
Il VPN Gateway viene creato all’interno di una subnet speciale della VNet (chiamata GatewaySubnet) e ha diverse SKU (tier) che ne determinano le capacità in termini di throughput, caratteristiche supportate (ad esempio supporto di connessioni BGP per l’interscambio dinamico di rotte, o ridondanza su zone di disponibilità). La scelta dello SKU dipende dalle necessità di banda e affidabilità richieste. Una volta configurato, il gateway stabilisce il tunnel VPN con l’apparato corrispondente on-premises; tutto il traffico instradato verso la rete locale (secondo le route configurate) verrà cifrato e inviato attraverso questo tunnel, e viceversa.
ExpressRoute (Collegamento dedicato privato)
ExpressRoute è la soluzione per esigenze di connettività ibrida con prestazioni e affidabilità ancora maggiori. Si tratta di un collegamento dedicato privato tra la rete on-premises dell’azienda e la rete globale di Microsoft (che ospita Azure). A differenza della VPN su Internet, con ExpressRoute il traffico non passa attraverso la rete Internet pubblica, ma viaggia su un circuito riservato fornito da un provider partner di Microsoft. Ciò comporta due vantaggi principali: bassa latenza e alta velocità (sono disponibili circuiti di vari tagli, da decine di Mbps fino a 10 Gbps e oltre) e una maggiore sicurezza intrinseca (essendo un circuito privato, è isolato dal traffico Internet globale).
ExpressRoute richiede di attivare un circuito tramite un provider di telecomunicazioni o tramite un exchange partner; una volta attivo, il circuito collega la propria infrastruttura a uno degli ExpressRoute gateway di Microsoft. Da lì, la connessione può essere mappata a una o più VNet Azure. È possibile avere sia peering privato (per connettersi ai servizi Azure all’interno di una VNet) sia peering Microsoft (per raggiungere i servizi Microsoft pubblici come Azure SQL, Azure Storage, ma attraverso il circuito privato invece di Internet).
Un aspetto importante è che ExpressRoute e VPN non si escludono a vicenda: anzi, Azure consente di combinare le due soluzioni in modalità di ridondanza. Ad esempio, si può prevedere un failover in cui, se il circuito ExpressRoute cade, una VPN site-to-site su Internet subentra per mantenere la connessione, anche se con prestazioni inferiori. Inoltre, usando il protocollo BGP, sia ExpressRoute che VPN Gateway possono scambiare dinamicamente le rotte tra Azure e on-premises, facilitando l’amministrazione delle tabelle di routing.
Per ambienti con numerose sedi e reti complesse, Azure offre anche Virtual WAN, un servizio che aggrega e semplifica la gestione centralizzata di molteplici connessioni VPN/ExpressRoute e permette di collegare in modo ottimizzato utenti e filiali distribuite alla rete Azure.
Esempio: un’azienda con sede centrale e filiali può configurare una connessione site-to-site tra il firewall/router della sede centrale (HQ) e un VPN Gateway nella VNet di produzione in Azure, in modo che i due ambienti siano collegati continuamente. Allo stesso tempo, per i dipendenti in viaggio o in smart working, è possibile abilitare l’accesso point-to-site (P2S) al VPN Gateway (ad esempio utilizzando il protocollo OpenVPN supportato da Azure) permettendo ai singoli client di entrare nella rete aziendale su Azure da qualsiasi luogo. Per carichi di lavoro critici che richiedono throughput elevato e latenza minima, l’azienda attiva anche un circuito ExpressRoute verso il proprio datacenter primario; attraverso ExpressRoute viene instradato gran parte del traffico (incluso, potenzialmente, il forced tunneling di tutto il traffico Internet dai server Azure verso il datacenter, per applicare policy centralizzate). In caso di guasto del circuito privato, la VPN su Internet funge da collegamento di backup grazie a un routing di failover configurato con BGP.
5. Bilanciamento del Carico (Load Balancer, Application Gateway, Front Door)
Per garantire la scalabilità e l’alta disponibilità delle applicazioni, Azure fornisce diversi servizi di bilanciamento del carico. Questi distribuiscono il traffico tra istanze multiple di un servizio, evitando punti singoli di fallimento e ottimizzando la risposta agli utenti. Azure offre soluzioni di load balancing sia a livello di trasporto (Layer 4) sia a livello applicativo (Layer 7):
a) Azure Load Balancer (Livello 4)
L’Azure Load Balancer opera al livello 4 (trasporto) del modello OSI, bilanciando traffico TCP e UDP. Esso può distribuire automaticamente le richieste in ingresso su un insieme di destinazioni in back-end, tipicamente macchine virtuali o istanze in un Availability Set o in una Virtual Machine Scale Set (VMSS). Il Load Balancer verifica lo stato delle istanze tramite probe di integrità (health probes): se un’istanza non risponde ai probe, viene temporaneamente rimossa dal pool, così che il traffico sia diretto solo verso istanze sane. [
Azure Load Balancer supporta scenari interni (bilanciamento su reti private per creare, ad esempio, cluster di database o servizi interni altamente disponibili) e pubblici (espone un indirizzo IP pubblico che bilancia verso istanze in subnet private per servizi rivolti agli utenti finali). È ideale per scenari ad alte prestazioni e bassa latenza dove occorre un bilanciamento semplice a livello di porta/protocollo senza introspezione del contenuto delle richieste. Ad esempio, può essere usato per distribuire traffico RDP/SSH su gateway jump-box oppure per bilanciare traffico UDP di sistemi di media streaming.
b) Azure Application Gateway (Livello 7)
L’Application Gateway è il servizio di bilanciamento del carico di Azure operante a livello 7, specificamente progettato per gestire traffico HTTP/HTTPS. A differenza del Load Balancer L4 che è agnostico al contenuto, l’Application Gateway può effettuare routing basato su URL o su intestazioni host, permettendo di instradare le richieste in base al nome del dominio o al percorso richiesto (utile per host multipli sullo stesso IP o microservizi distinti sotto uno stesso dominio). Inoltre, supporta funzioni avanzate tipiche dei load balancer applicativi, come la terminazione SSL (SSL offload) – cioè può gestire la decifratura del traffico HTTPS, riducendo il carico sulle istanze backend – e soprattutto integra un Web Application Firewall (WAF) opzionale. Il WAF protegge le applicazioni web da attacchi comuni (SQL injection, XSS, ecc.) seguendo regole basate sulle OWASP Top 10.
L’Application Gateway è indicato quando occorre protezione e routing intelligente a livello applicativo. Può gestire sessioni cookie, redirezioni HTTPS e altri comportamenti specifici del livello web. È comunemente utilizzato per pubblicare applicazioni web aziendali, anche in combinazione con altri servizi (ad esempio, può lavorare dietro a un Azure Front Door per ogni regione, come vedremo di seguito).
c) Azure Front Door (Distribuzione Globale)
Azure Front Door è un servizio di bilanciamento del carico globale e accelerazione applicativa. Opera anch’esso a livello 7 e utilizza la rete globale per instradare gli utenti alla posizione più vicina in termini di latenza, sfruttando la tecnologia Anycast (un singolo indirizzo IP globale che raggiunge automaticamente il nodo Front Door più vicino all’utente). Front Door può eseguire failover geografico: se un’intera regione Azure diventa irraggiungibile, Front Door può deviare il traffico verso una regione secondaria in pochi secondi, garantendo la continuità del servizio. Inoltre offre funzionalità di accelerazione simili a una CDN, come il caching dei contenuti statici presso i Point of Presence sparsi globalmente, migliorando le performance percepite dagli utenti finali.
Front Door è ideale per applicazioni multi-regione o globali, dove gli utenti sono distribuiti geograficamente e si vuole offrire loro un endpoint unico e vicino. Spesso viene usato in combinazione con Application Gateway: ad esempio, Front Door può instradare il traffico all’Application Gateway di ciascuna regione (che a sua volta smista verso le VM o istanze locali) e agire da primo livello di difesa e ottimizzazione a livello mondiale.
Scelta della soluzione: in sintesi, Azure Load Balancer è adatto al bilanciamento "semplice" a livello rete/trasporto e supporta tutti i protocolli TCP/UDP (ad es. per servizi interni o tier di backend non HTTP). Application Gateway è scelto per scenari web in cui servono routing per URL o protezione WAF direttamente sulle istanze applicative. Front Door viene usato per scenari globali di distribuzione del traffico, miglioramento prestazioni e alta disponibilità cross-region. In un’architettura complessa, non è raro usare tutte e tre le soluzioni in cascata: Front Door come entry point globale, Application Gateway all’interno di ogni regione per la sicurezza a livello applicativo, e Load Balancer interni per bilanciare microservizi o database sul backend.
Esempio: un servizio web multi-zona su Azure potrebbe adottare Azure Front Door come punto di ingresso unico globale. Front Door indirizza ciascuna richiesta alla regione Azure geograficamente più vicina all’utente. In ogni regione, un Application Gateway con WAF gestisce il traffico in entrata, smistando le richieste eventualmente tra più pool (ad esempio differenti microservizi) e filtrando attacchi web comuni. Sul tier di applicazione, se i microservizi comunicano tra loro via gRPC o altri protocolli non HTTP, potrebbero utilizzare un Load Balancer interno per distribuire le richieste tra molte istanze identiche, mantenendo l’elevata disponibilità anche per i servizi di backend.
6. Sicurezza Avanzata in Rete (Azure Firewall, Protezione DDoS, Defender for Cloud)
Oltre agli NSG, Azure fornisce servizi avanzati per migliorare la sicurezza della rete e delle risorse: Azure Firewall per il controllo centralizzato del traffico, DDoS Protection per mitigare attacchi distribuiti, e Microsoft Defender for Cloud per la postura di sicurezza e protezione dei carichi di lavoro.
a) Azure Firewall
Azure Firewall è un firewall cloud completamente gestito, di tipo stateful, che consente di applicare a livello centralizzato regole sia di rete che applicative. A differenza degli NSG (che operano su singole subnet/VM), Azure Firewall viene tipicamente implementato in una subnet dedicata (spesso in una VNet hub di sicurezza) e funge da snodo centralizzato attraverso cui far passare il traffico, specialmente quello in uscita dalle subnet applicative.
Le funzionalità chiave di Azure Firewall includono:
· Filtraggio stateful del traffico L3-L4 e L7.
· Regole di applicazione che consentono o negano richieste HTTP/HTTPS basate su FQDN (nomi di dominio), permettendo ad esempio di consentire l’accesso web solo a domini autorizzati.
· Regole di rete basate su IP/porte/protocolli, simili a quelle NSG ma gestite centralmente.
· Traduzione degli indirizzi: supporto sia per SNAT (far uscire il traffico con IP pubblico del firewall) sia DNAT (pubblicare servizi interni tramite IP/porte del firewall verso l’esterno), semplificando l’esposizione controllata di risorse interne.
· Integrazione con Threat Intelligence: il firewall può bloccare o allertare automaticamente su traffico verso IP/domìni noti come malevoli, utilizzando i feed di threat intelligence di Microsoft.
· Nella versione Premium, dispone di IDS/IPS (rilevamento e prevenzione delle intrusioni) per analisi avanzate del traffico applicativo.
Azure Firewall è un componente fondamentale nelle architetture hub-and-spoke: tutte le connessioni Internet in uscita dai spoke passano dal firewall nell’hub, dove vengono applicate regole uniformi. Questo facilita la gestione centralizzata delle policy di sicurezza e il monitoraggio del traffico attraverso un unico punto.
b) Protezione DDoS
Gli attacchi DDoS (Distributed Denial of Service) mirano a rendere inaccessibile un servizio sovraccaricandolo con enormi volumi di traffico artificiale. Azure offre DDoS Protection Standard, un servizio che, abilitato a livello di VNet, monitora continuamente il traffico verso le risorse pubbliche (ad esempio IP pubblici associati a VM, Load Balancer o App Gateway) e rileva pattern anomali riconducibili ad attacchi DDoS. In caso di attacco, il servizio filtra il traffico malevolo (es. pacchetti volumetrici) prima che raggiunga la VNet, permettendo solo al traffico legittimo di arrivare a destinazione.
La protezione DDoS Standard si appoggia sull’infrastruttura globale Microsoft, potendo assorbire attacchi molto massicci. Si tratta di un complemento al servizio di base (che offre già protezione DDoS a livello infrastrutturale per tutti) ed è raccomandato per applicazioni critiche o esposte su Internet, in quanto fornisce anche telemetria dettagliata, log degli attacchi mitigati e la possibilità di definire politiche personalizzate di mitigazione. Quando si attiva DDoS Standard su una VNet, tutti i risorse con IP pubblici in quella rete sono protette automaticamente.
c) Microsoft Defender for Cloud
Microsoft Defender for Cloud (precedentemente Azure Security Center) non è un controllo di rete diretto, bensì una piattaforma di Cloud-Native Application Protection (CNAPP) che aiuta a monitorare e rafforzare la postura di sicurezza complessiva delle risorse Azure, inclusi aspetti di rete ma anche di altri tipi (sistemi operativi, applicazioni, dati).
Defender for Cloud genera un Secure Score per l’ambiente Azure, valutando la configurazione rispetto a best practice e standard di sicurezza. Fornisce raccomandazioni migliorative (ad esempio: “Abilita la MFA per gli account amministratori”, “Configura un NSG per questa subnet”, “Abilita la crittografia su questo storage account”) e può attivare protezioni mirate tramite piani Defender dedicati a specifici carichi di lavoro: ad esempio Defender for Servers abilita funzionalità di endpoint protection e vulnerability assessment sulle VM, Defender for Storage rileva anomalie di accesso ai dati, Defender for Containers monitora i cluster AKS, ecc.
Per quanto riguarda la rete, Defender for Cloud si integra con i controlli come NSG e Firewall per evidenziare configurazioni deboli (come porte aperte non necessarie) e con i servizi di monitoraggio per rilevare attività sospette sulla rete. Implementare un approccio Zero Trust in Azure – ovvero non fidarsi mai implicitamente di nessun traffico, nemmeno interno – implica usare strumenti come NSG su ogni subnet, Azure Firewall per filtrare attivamente tutto il traffico in uscita, Private Endpoint per i servizi PaaS (in modo che nulla sia accessibile pubblicamente), l’accesso Just-In-Time per le VM (ossia aprire porte di management come RDP/SSH solo temporaneamente quando serve) e l’integrazione con Conditional Access di Azure AD per controllare gli accessi amministrativi. Defender for Cloud aiuta a implementare e verificare queste misure, assicurando che ogni componente – rete, identità, dati – rispetti i principi di sicurezza attesi.
Esempio: un’architettura hub-and-spoke può dedicare una VNet hub-security che ospita un’istanza di Azure Firewall. Tutto il traffico Internet in uscita dalle VNet spoke (ad esempio app e data) è instradato verso il firewall tramite route UDR, così che nessuna VM comunichi direttamente con Internet ma passi attraverso il controllo centralizzato del firewall. Su queste VNet spoke è attiva anche la protezione DDoS Standard, per mitigare attacchi contro i servizi esposti. Inoltre, l’azienda abilita i piani Defender appropriati: ad esempio Defender for Servers sulle VM (che abilita anche il JIT per RDP/SSH), Defender for SQL sui database, ottenendo visibilità attraverso il secure score e alert in caso di comportamenti anomali. In tal modo si realizza una postura Zero Trust dove ogni strato – rete, host, applicazione – è monitorato e protetto.
7. Gestione dei Nomi (Azure DNS)
Nel cloud come on-premises, la risoluzione dei nomi è fondamentale per l’accessibilità dei servizi. Azure DNS è il servizio di gestione del Domain Name System in Azure: consente di ospitare zone DNS sia pubbliche (domini internet classici) sia private (zone DNS interne, visibili solo all’interno delle reti Azure) con l’affidabilità e le prestazioni dell’infrastruttura globale di Microsoft.
Utilizzare Azure DNS per i domini pubblici significa poter gestire record DNS (A, CNAME, MX, TXT, etc.) tramite il portale Azure, CLI o API, beneficiando di una piattaforma highly available e distribuita globalmente, invece di dover mantenere server DNS proprietari. Per i domini interni, le Private DNS Zones di Azure offrono un sistema di nome privato senza dover creare e gestire VM DNS: ad esempio, si può avere una zona privata contoso.local i cui record sono risolti dalle VM nelle VNet Azure associate a quella zona, consentendo ai servizi interni di trovarsi per nome host come farebbero in un datacenter tradizionale. Attraverso i VNet link, si collega una zona DNS privata a una o più VNet, definendo l’ambito di visibilità di quei nomi.
Azure DNS si integra bene con altri servizi: ad esempio può funzionare con Traffic Manager o con Front Door per implementare strategie di routing globale; in tal caso, i record DNS possono indirizzare il client al endpoint migliore (Traffic Manager usa il DNS per reindirizzare al migliore endpoint in base a metriche come latenza o geografia).
Per gli ambienti ibridi, dove esistono già server DNS on-premises, Azure ha introdotto l’Azure DNS Private Resolver: un servizio che permette la risoluzione DNS reciproca tra Azure e on-premises. In pratica, il Private Resolver può inoltrare le query dalla VNet verso i server DNS on-prem (per risolvere nomi della rete locale non noti in Azure) e viceversa, rispondere alle query provenienti da on-premises per i nomi delle zone private Azure, il tutto senza dover gestire VM per eseguire questa funzione. Questo componente semplifica scenari in cui parte dell’infrastruttura DNS è in cloud e parte in locale.
Esempio: un’azienda gestisce il dominio pubblico contoso.com direttamente in Azure DNS, creando record A e CNAME per i servizi web pubblici. Allo stesso tempo, definisce una zona DNS privata contoso.local in Azure per la risoluzione dei nomi interni dei server e database in Azure; questa zona privata è linkata alle VNets di produzione e sviluppo, così che le VM in quelle reti possano risolvere i nomi *.contoso.local tra di loro senza interrogare server esterni. Infine, viene configurato Azure DNS Private Resolver per inoltrare verso i DNS aziendali on-premises qualsiasi richiesta DNS per domini interni legacy, consentendo a una VM su Azure di risolvere ad esempio nomehost.corp.local che esiste solo nei DNS aziendali, e reciprocamente permettendo ai client on-prem di risolvere nomi privati Azure come db01.contoso.local. In questo modo, il namespace DNS risulta unificato tra cloud e on-premises.
8. Monitoraggio e Risoluzione dei Problemi (Network Watcher)
Gestire una rete significa anche monitorarla e poter diagnosticare rapidamente eventuali problemi di connettività o performance. Azure Network Watcher è il toolkit integrato in Azure per il monitoraggio e il troubleshooting della rete. Una volta abilitato in una regione, fornisce diversi strumenti utili agli amministratori di rete:
· Connection Monitor: consente di verificare in continuo la connettività (e misurare latenza, pacchetti persi) tra un endpoint e un altro. Gli endpoint possono essere, ad esempio, una VM in Azure e un indirizzo URL esterno, oppure due VM in reti diverse. Utile per controllare che un’applicazione sia raggiungibile dai vari siti aziendali, o che la latenza rimanga entro soglie accettabili.
· Topology: genera automaticamente una mappa grafica della topologia di rete di una VNet, mostrando le relazioni tra subnet, NIC, NSG, route e altri elementi. Questo aiuta a visualizzare e comprendere la configurazione attuale, rilevando ad esempio se un NSG è associato o meno a una subnet, o come il traffico può scorrere attraverso i componenti.
· IP Flow Verify: consente di testare se una determinata comunicazione sarebbe consentita o bloccata, data la configurazione attuale. Specificando un IP sorgente e destinazione, porta e protocollo, Network Watcher verifica le regole NSG e le route attive per determinare se il pacchetto ipotetico arriverebbe a destinazione o verrebbe filtrato. Allo stesso modo, Next Hop aiuta a capire verso quale destinazione (quale next hop) verrebbe inviato un pacchetto a seconda delle tabelle di routing in vigore (utile per diagnosticare problemi di routing o configurazioni UDR).
· Packet Capture: permette di catturare pacchetti di rete direttamente su una VM Azure (Linux o Windows) e salvarli per l’analisi, in maniera analoga a uno sniffer di rete. Questo strumento è inestimabile quando si devono diagnosticare problemi a livello di pacchetto o analizzare traffico in dettaglio e non si può accedere direttamente alla VM per eseguire un tcpdump o Wireshark.
· NSG Flow Logs e Traffic Analytics: come accennato nella sezione NSG, Network Watcher può registrare i log di flusso di ogni NSG, ovvero l’elenco delle connessioni consentite o negate dalle sue regole. Questi log, salvati in formato JSON su uno storage account, possono essere analizzati manualmente o tramite Traffic Analytics – una soluzione che aggrega e presenta statistiche sui flussi, come volumi di traffico, principali indirizzi di origine/destinazione, porte più utilizzate, e così via. Queste informazioni sono preziose sia per ottimizzare la rete (ad esempio individuare colli di bottiglia, o opportunità di ottimizzare le regole) sia per sicurezza (rilevare traffico anomalo).
Network Watcher si integra con Azure Monitor: ciò significa che si possono impostare alert su certi eventi (es. se la latenza misurata da Connection Monitor supera una soglia, o se un certo tipo di flusso appare nei log). Inoltre, si possono utilizzare Workbook preconfigurati – dashboard interattive – per visualizzare dati di rete (ad esempio una panoramica della latenza delle connessioni, o il conteggio delle minacce bloccate da un NSG).
L’uso di Network Watcher è consigliato durante migrazioni (per confrontare performance pre e post migrazione), in caso di incidenti di rete per avere diagnosi rapide, e per l’ottimizzazione continua dell’ambiente.
Esempio: un amministratore configura Connection Monitor per tenere sotto controllo la connettività tra l’Application Gateway in Azure e i server backend che risiedono on-premises, verificando così costantemente che il percorso ibrido VPN/ExpressRoute sia operativo e misurando latenza e tempi di risposta. Vengono abilitati i NSG flow logs sull’NSG della subnet web e i dati sono inviati a Traffic Analytics per ottenere report mensili sul tipo di traffico generato dagli utenti. In caso di anomalia, l’amministratore può utilizzare IP Flow Verify per testare se una certa porta dovrebbe essere raggiungibile o meno, e Packet Capture per analizzare direttamente il traffico di una VM problematica. Infine, crea una dashboard (Workbook) che mostra la latenza al percentile 95 (p95) delle connessioni e il tasso di errori TCP rilevati, per avere un quadro aggregato della qualità della rete.
9. Best practice Architetturali per Azure Networking
Nell’implementare soluzioni di networking su Azure su larga scala, è importante seguire alcune best practice e architetture di riferimento, sia per ottenere le migliori prestazioni e sicurezza, sia per mantenere la gestione semplificata e ottimizzare i costi. Di seguito sono riportate le linee guida principali da tenere a mente:
- Architettura Hub-and-Spoke: per ambienti aziendali complessi, adotta un modello hub-and-spoke. Crea una VNet centrale hub che funga da snodo per la connettività e la sicurezza condivisa, ospitando componenti comuni come Azure Firewall, Azure Bastion, servizi DNS, e i gateway VPN/ExpressRoute per l’ibrido. Le VNet spoke invece contengono le applicazioni e i dati specifici per dipartimento o progetto, collegandosi all’hub tramite VNet peering o tramite Azure Virtual WAN. Questo modello centralizza i controlli (ad es. il filtraggio firewall) e semplifica la connettività multipunto, evitando collegamenti ridondanti tra tutte le reti.
- Approccio Zero Trust in rete: non dare per scontato che risorse all’interno dello stesso perimetro siano sicure di per sé. Applica NSG su ogni subnet per isolare i segmenti, utilizza un firewall per controllare e registrare il traffico in uscita verso Internet (e tra segmenti critici), preferisci i Private Endpoint invece di esporre servizi PaaS su IP pubblici, e segmenta quanto più possibile limitando le comunicazioni solo a quelle necessarie. Zero Trust significa anche verificare continuamente: combinare la sicurezza di rete con quella applicativa e identitaria (ad esempio con l’MFA e Conditional Access per gli accessi amministrativi).
- Alta Disponibilità: progetta la rete tenendo a mente la resilienza. Distribuisci le risorse critiche in almeno due Availability Zone (laddove disponibile) in modo che un guasto di una zona non impatti l’intera applicazione. Utilizza i load balancer con probe di integrità per ridondare le istanze di servizio. Implementa soluzioni di failover geografico se l’applicazione lo richiede (ad esempio con Front Door o Traffic Manager su più regioni). Abilita DDoS Protection Standard sulle VNet che ospitano front-end esposti, così da avere protezione aggiuntiva contro attacchi che potrebbero compromettere la disponibilità del servizio.
- Governance e Compliance: definisci fin da subito convenzioni di naming e tagging per le risorse di rete (es: prefissi per indicare ambiente/progetto, etc.), questo aiuta nella gestione e nel reporting dei costi. Utilizza Azure Policy per imporre regole aziendali (esempio: impedire la creazione di risorse con IP pubblici non approvati, assicurare che ogni VNet abbia NSG associati, obbligare l’uso di tag per le risorse, etc.). Sfrutta strumenti come Azure Blueprint o le landing zone di Microsoft per distribuire ambienti conformi a standard prestabiliti e ripetibili.
- Osservabilità: non trascurare il monitoraggio. Abilita Network Watcher (o il più recente Azure Monitor Network Insights) in tutte le regioni utilizzate, configura log e diagnostica per i componenti di rete (NSG flow logs, Diagnostic logs per Application Gateway, metriche di VPN Gateway, ecc.) e stabilisci alert proattivi. Prepara dashboard che aggregano le informazioni chiave di rete e sicurezza, e riesamina regolarmente i dati (ad esempio controllare i flussi bloccati più frequenti, per capire se c’è qualche configurazione da ottimizzare).
- Ottimizzazione dei costi: il design di rete può avere impatti sui costi cloud. Scegli il servizio giusto per il giusto scenario: ad esempio, un Azure Load Balancer costa meno di un Application Gateway, quindi se hai solo bisogno di bilanciamento L4 per VM, non impiegare un costoso Gateway L7. Evita trasferimenti di dati non necessari: il traffico egress (uscente da Azure) ha costi, quindi minimizza chiamate dall’Azure verso l’esterno se possibile, e sfrutta caching o servizi interni (ad esempio, un database nella stessa region evita costi di uscita). Se usi molta banda su ExpressRoute o consumi tanti IP pubblici, considera opzioni come ExpressRoute Unlimited (tariffa flat) o l’uso di SKU di IP pubblici riservati che siano più convenienti per volumi elevati. Rivedi periodicamente le risorse di rete inutilizzate (IP non assegnati, gateway non in uso) per evitare costi superflui.
Seguendo questi principi, è possibile costruire ambienti di rete su Azure che siano sicuri, altamente disponibili, gestibili e in linea con le esigenze aziendali. Per ulteriori approfondimenti su architetture di riferimento nel networking Azure e best practice aggiornate, si consiglia di consultare l’Azure Architecture Center e la documentazione ufficiale di Azure Networking.
10 . Tabella riassuntiva dei servizi di Azure Networking
Di seguito una tabella che riepiloga i principali servizi e componenti di Azure Networking trattati, con una sintesi delle loro funzionalità chiave:
Servizio/Componente
Funzionalità chiave
Azure Virtual Network (VNet)
Rete privata isolata nel cloud Azure; definizione di spazio indirizzi IP personalizzato (CIDR) e suddivisione in subnet; supporta peering tra VNet e connessioni ibride (VPN, ExpressRoute) per estendere la rete on-prem; controllo del routing con UDR e integrazione con NSG per la sicurezza
Subnet (in VNet)
Segmentazione logica di una VNet; isolamento del traffico tra livelli (es. web/app/db); applicazione di NSG specifici per controllo accessi; supporto di Service Endpoint e Private Endpoint per accesso privato a servizi PaaS; possibilità di route personalizzate (UDR) e delega a servizi Azure; pianificazione di indirizzi IP per crescita futura
Network Security Group (NSG)
Filtro di sicurezza a livello rete (L3/L4); definizione di regole allow/deny su porte e protocolli verso/da subnet o NIC; priorità delle regole con default che bloccano traffico indesiderato (es. tutto l’inbound da Internet negato di default); utilizzo di Service Tag e Application Security Group per semplificare la gestione delle regole; monitorabile tramite NSG Flow Logs con Network Watcher.
VPN Gateway
Gateway VPN per connettere Azure VNet con reti on-premises tramite tunnel IPsec/IKE; supporta connessioni site-to-site (VPN tra appliance di rete) e point-to-site (VPN client individuali); diverse SKU disponibili in base a throughput e funzionalità (es. BGP, ridondanza di zona); consente di estendere la rete aziendale al cloud in modo sicuro su Internet.
Azure ExpressRoute
Connessione privata dedicata tra la rete aziendale e Azure (non transita su Internet); offre alta banda e bassa latenza per scenari mission-critical; necessita provisioning tramite provider partner; può
Conclusioni
Abbiamo dunque visto come la rete in Azure rappresenta la base per costruire ambienti cloud sicuri, scalabili e integrati con le infrastrutture esistenti. Le Virtual Network (VNet) offrono isolamento e controllo, consentendo di definire spazi IP privati e collegare risorse in modo sicuro, mentre il peering e la connettività ibrida estendono il cloud alle reti aziendali. La segmentazione tramite subnet è essenziale per organizzare i carichi di lavoro e applicare policy granulari, sfruttando funzionalità come Private Endpoint per proteggere i servizi PaaS. La sicurezza è rafforzata dai Network Security Groups (NSG), che filtrano il traffico con regole flessibili, e da strumenti avanzati come Azure Firewall, DDoS Protection e Defender for Cloud, che implementano un approccio Zero Trust. Per garantire disponibilità e resilienza, Azure mette a disposizione soluzioni di bilanciamento del carico su più livelli: Load Balancer per il traffico L4, Application Gateway con WAF per la protezione web e Front Door per la distribuzione globale. La gestione dei nomi tramite Azure DNS semplifica la risoluzione sia per domini pubblici sia privati, integrandosi con scenari ibridi grazie al Private Resolver. Il monitoraggio continuo con Network Watcher e l’analisi dei flussi NSG consentono di diagnosticare problemi e ottimizzare le performance. Le best practice architetturali, come il modello hub-and-spoke, l’adozione di policy di governance e l’osservabilità proattiva, garantiscono ambienti conformi e gestibili. Infine, la scelta oculata dei servizi e delle opzioni di connettività permette di bilanciare sicurezza, prestazioni e costi. In sintesi, Azure Networking non è solo un insieme di componenti tecnici, ma un ecosistema integrato che abilita architetture moderne, sicure e resilienti, fondamentali per supportare applicazioni mission-critical e strategie cloud aziendali.
Riepilogo capitolo
Il documento fornisce una panoramica dettagliata dei principali servizi e concetti di networking in Azure, spiegando come progettare, gestire e proteggere reti virtuali nel cloud con best practice architetturali e strumenti di monitoraggio.
· Reti Virtuali (VNet): Le VNet sono reti private isolate nel cloud Azure che definiscono spazi IP personalizzati e subnet; supportano peering, connettività ibrida con reti on-premises tramite VPN Gateway o ExpressRoute, controllo del routing e sicurezza tramite Network Security Groups (NSG).
· Subnet e segmentazione: Le subnet suddividono una VNet in segmenti logici per organizzare carichi di lavoro e applicare policy di sicurezza specifiche, supportano deleghe a servizi Azure e collegamenti privati a servizi PaaS tramite Private Endpoint.
· Network Security Groups (NSG): Gli NSG filtrano il traffico a livello di rete con regole di allow/deny basate su indirizzi, porte e protocolli; si associano a subnet o interfacce di rete, supportano Service Tag e Application Security Group per semplificare la gestione e sono monitorabili tramite NSG flow logs.
· Connettività ibrida: La connessione sicura tra Azure e reti on-premises si realizza con VPN Gateway, che crea tunnel IPsec/IKE su Internet, ed ExpressRoute, un collegamento privato dedicato ad alta velocità e bassa latenza; possono essere usati insieme per ridondanza e integrazione tramite BGP.
· Bilanciamento del carico: Azure offre Load Balancer (livello 4) per traffico TCP/UDP semplice, Application Gateway (livello 7) con routing basato su URL e Web Application Firewall, e Front Door per bilanciamento globale, failover geografico e accelerazione applicativa.
· Sicurezza avanzata: Azure Firewall gestisce regole centralizzate stateful a livello rete e applicativo; DDoS Protection Standard mitiga attacchi volumetrici proteggendo risorse pubbliche; Microsoft Defender for Cloud monitora la postura di sicurezza integrando controlli di rete e suggerendo best practice.
· Gestione dei nomi con Azure DNS: Azure DNS gestisce zone DNS pubbliche e private con alta disponibilità; Private DNS Zones permettono risoluzione interna; Azure DNS Private Resolver consente risoluzione DNS reciproca tra Azure e on-premises senza server dedicati.
· Monitoraggio e troubleshooting: Azure Network Watcher offre strumenti per monitorare connettività, visualizzare topologie, verificare flussi di traffico, catturare pacchetti e analizzare log NSG, integrandosi con Azure Monitor per alert e dashboard interattive.
· Best practice architetturali: Si consiglia il modello hub-and-spoke per centralizzare la sicurezza e la connettività, adottare un approccio Zero Trust con segmentazione e controlli rigorosi, garantire alta disponibilità con distribuzione multi-zona e failover, applicare governance tramite policy e naming coerenti, monitorare costantemente e ottimizzare i costi scegliendo servizi adeguati.
CAPITOLO 6 – Il servizio database
Introduzione
In questo capitolo ci concentreremo sui servizi di database offerti da Azure, analizzando in modo chiaro e didattico i concetti fondamentali che consentono di progettare e gestire soluzioni moderne nel cloud. I database sono il cuore di ogni applicazione e la loro corretta implementazione è essenziale per garantire prestazioni, sicurezza e affidabilità. Azure mette a disposizione una gamma completa di servizi che coprono esigenze diverse, dai database relazionali tradizionali ai sistemi NoSQL, dai data warehouse per analisi avanzate alle soluzioni in memoria per caching distribuito. Comprendere le differenze tra queste opzioni è il primo passo per scegliere la tecnologia più adatta al proprio scenario. I database relazionali come Azure SQL Database e Azure Database for MySQL o PostgreSQL offrono compatibilità con i motori classici, gestione automatizzata e alta disponibilità, mentre Cosmos DB rappresenta la soluzione ideale per dati distribuiti e scalabili, supportando API multiple e modelli di consistenza configurabili. Per analisi su larga scala, Azure Synapse Analytics consente di creare data warehouse potenti e integrati con strumenti di business intelligence, mentre Azure Cache for Redis accelera le applicazioni riducendo la latenza grazie al caching in memoria. La progettazione di un database in Azure richiede attenzione all’architettura: i servizi PaaS eliminano la complessità della gestione hardware e delle patch, offrendo funzionalità come replica automatica, bilanciamento del carico e aggiornamenti senza interruzioni. La sicurezza è un aspetto cruciale e Azure implementa cifratura dei dati a riposo e in transito, autenticazione tramite Azure Active Directory, firewall per limitare gli accessi e Private Endpoint per evitare esposizione su Internet. Inoltre, strumenti come Defender for SQL e per Cosmos DB rilevano minacce e anomalie, mentre le policy basate su ruoli garantiscono che ogni utente disponga solo dei permessi necessari. Un altro elemento fondamentale è il backup: Azure SQL Database offre backup automatici con retention configurabile e possibilità di ripristino a un punto nel tempo, mentre le opzioni di geo-ripristino assicurano continuità operativa anche in caso di disastro. La scalabilità è uno dei vantaggi principali del cloud: Azure SQL Database supporta modelli di risorse basati su DTU o vCore, mentre Cosmos DB consente scalabilità orizzontale con throughput configurabile. Funzionalità come indicizzazione automatica e partizionamento dei dati migliorano le performance, e l’autoscaling permette di ottimizzare costi e prestazioni in base al carico reale. Per mantenere il controllo sull’efficienza, Azure offre strumenti di monitoraggio come Azure Monitor, Log Analytics e Query Performance Insight, che consentono di analizzare metriche, individuare query lente e impostare alert proattivi. L’integrazione con altri servizi è un punto di forza: i database Azure si collegano facilmente a Azure Functions per elaborazioni serverless, Data Factory per pipeline ETL, Synapse per analisi avanzate e Power BI per la visualizzazione dei dati, creando ecosistemi completi che vanno dall’ingestione alla trasformazione e analisi. I casi d’uso sono molteplici: nel commercio elettronico, Azure SQL Database gestisce cataloghi e ordini mentre Redis accelera le risposte; nella sanità, Cosmos DB archivia dati sensibili in modo sicuro con Private Endpoint; nell’IoT, Cosmos DB raccoglie dati da dispositivi e Data Explorer li analizza in tempo reale; per la business intelligence, Synapse e Power BI offrono insight strategici. Per progettare soluzioni efficaci è importante seguire best practice come l’uso di cifratura e autenticazione forte, l’implementazione di backup e geo-ripristino, il monitoraggio costante delle performance e la scelta del servizio più adatto al tipo di dati e al carico previsto. La governance è altrettanto importante: Azure Policy consente di applicare regole aziendali e garantire conformità, mentre strumenti come il Secure Score di Defender for Cloud aiutano a valutare la postura di sicurezza complessiva. In sintesi, i servizi di database in Azure offrono una piattaforma completa e flessibile che consente di gestire dati in modo sicuro, scalabile e integrato, rispondendo alle esigenze di applicazioni mission-critical e scenari innovativi. Comprendere i concetti chiave e sfruttare le funzionalità offerte da Azure è essenziale per costruire architetture moderne, resilienti e orientate alle best practice, garantendo così valore e affidabilità alle soluzioni cloud.
Inquadramento argomenti del capitolo con slides illustrate
Nel cloud Azure puoi scegliere tra database relazionali e non relazionali, detti anche NoSQL. I database relazionali, come Azure SQL Database, MySQL e PostgreSQL, utilizzano schemi strutturati e il linguaggio SQL per garantire le proprietà ACID, vincoli e relazioni tra tabelle. Sono ideali per transazioni finanziarie, ERP, CRM e reporting affidabile. I database NoSQL, come Azure Cosmos DB, sono progettati per bassa latenza, scalabilità orizzontale e schema flessibile. Supportano diversi modelli, come documenti, key-value, grafo e wide-column, e offrono API compatibili con Core (SQL), MongoDB, Cassandra e Gremlin. La scelta dipende dalla struttura dei dati: usa SQL quando servono vincoli forti e transazioni complesse; scegli NoSQL per throughput elevato, distribuzione globale e agilità dello schema. Spesso le architetture moderne integrano entrambi: il core transazionale su SQL e funzionalità di personalizzazione, telemetria o sessioni su NoSQL. Ad esempio, in un e-commerce gli ordini e pagamenti sono su SQL Database, mentre carrelli e profili utente sono su Cosmos DB, per ottenere latenza minima e distribuzione multi-area. Nei contesti IoT, la grande mole di eventi può essere gestita su Cosmos DB, mentre gli aggregati giornalieri vengono esportati su SQL per analisi tradizionali. Ricorda: ACID garantisce transazioni forti, mentre la scalabilità orizzontale dei NoSQL permette di distribuire il carico su più nodi. Consulta la tabella comparativa per scegliere il modello più adatto al tuo scenario.
I modelli di dati influenzano profondamente la progettazione e le performance dei database. Nel modello relazionale, i dati sono organizzati in tabelle collegate da chiavi e vincoli, ottimo per coerenza e query complesse come join e aggregazioni. Nel modello a documenti, come Cosmos DB API Core (SQL) o MongoDB, i dati sono rappresentati come oggetti JSON annidati, utili per domini con struttura variabile e per uno sviluppo rapido. Il modello a grafo, come Cosmos DB API Gremlin, si concentra sulle relazioni tra entità, ideale per social network, sistemi di raccomandazione e rilevazione frodi. Scegli il modello relazionale se ti servono rapporti rigidi e transazioni multi-riga, il documento se hai bisogno di schemi flessibili e meno relazioni, il grafo quando le relazioni sono il focus e servono traversate efficienti. Ad esempio, per la gestione ordini puoi usare il modello relazionale per ordini e clienti, il modello a documenti per il catalogo prodotti con descrizioni variabili, e il grafo per legami tra prodotti e raccomandazioni. Il documento JSON è indicizzato di default in Cosmos DB, mentre la traversal consente percorsi efficienti nei database a grafo. Consulta i diagrammi per visualizzare le differenze tra i modelli.
Nei servizi dati di Azure, l’architettura minima comprende un’istanza o server gestito, come Azure SQL logical server o Cosmos DB account, uno o più database o contenitori, e l’integrazione con la rete tramite Private Endpoints, firewall IP e VNet. Nei database PaaS come SQL, MySQL e PostgreSQL, si seleziona il livello di calcolo, memoria, storage e ridondanza; il servizio gestisce patching, disponibilità e backup. In Cosmos DB, definisci account, database e container, scegli la partizione e il throughput, con replica automatica tra aree. La progettazione deve includere isolamento di rete, gestione delle identità con Microsoft Entra ID e RBAC, monitoraggio con Azure Monitor e Insights, e strategie di ripristino. Ad esempio, puoi creare un logical server SQL, un database specifico e collegarlo tramite Private Endpoint alla tua VNet, bloccando il firewall per l’accesso Internet. In Cosmos DB, scegli la partition key e il throughput necessario, distribuendo i dati tra regioni. Consulta lo schema che evidenzia le componenti di sicurezza e i flussi di accesso.
Azure SQL Database è un servizio PaaS che offre alta disponibilità, patching e backup gestiti. Al momento della creazione, puoi definire il numero di vCore, il service tier, lo storage e le opzioni di zona. La gestione degli utenti e delle autorizzazioni avviene tramite T-SQL o Microsoft Entra ID. Le query T-SQL funzionano come in SQL Server, e puoi usare views, stored procedures, indici columnstore e Intelligent Query Processing. Per isolamento e performance costante, valuta le opzioni serverless o Hyperscale, che separa logica di storage e compute e permette di scalare oltre 100 TB. Puoi creare utenti con ruolo di sola lettura, definire Elastic Jobs per operazioni ricorrenti e usare Failover groups per il disaster recovery su più regioni. Il vCore rappresenta l’unità di calcolo allocata, mentre Hyperscale consente una gestione avanzata tra compute e storage. Visualizza lo screenshot dell’editor T-SQL e il diagramma delle tier con esempi di workload.
Cosmos DB è un database distribuito multi-modello progettato per offrire latenza di millisecondi a singola cifra e replica globale. Puoi scegliere tra diverse API, come Core (SQL), MongoDB, Cassandra e Gremlin, in base alle esigenze dell’applicazione. La capacità si misura in Request Units per secondo, che possono essere provisioned per garantire un throughput costante, oppure serverless, pagando solo il consumo effettivo. La coerenza dei dati può essere configurata secondo diversi modelli: Strong, Bounded Staleness, Session, Consistent Prefix ed Eventual. Ad esempio, la Session consistency è la scelta predefinita per molte applicazioni. La progettazione della partition key è fondamentale per distribuire il carico e evitare hot partitions. Puoi replicare i dati su più regioni, adeguare le RU automaticamente tramite Autoscale e gestire la coerenza secondo le necessità. Visualizza il grafico coerenza vs latenza e lo schema di replica multi-region.
La sicurezza in Azure Database segue il principio defense-in-depth. La cifratura at-rest viene gestita tramite Transparent Data Encryption per SQL e cifratura per Cosmos DB, con la possibilità di usare chiavi gestite dal cliente in Azure Key Vault. La cifratura in transito è garantita da TLS obbligatorio. L’integrazione con Microsoft Entra ID consente il controllo accessi basato sui ruoli e autenticazione moderna. In SQL puoi abilitare l’AAD Admin e ruoli database, mentre in Cosmos DB si usa il role-based access control e token. Microsoft Defender for SQL rileva vulnerabilità e minacce, mentre Defender for Cloud fornisce raccomandazioni per migliorare la sicurezza. La rete può essere isolata con Private Endpoints, firewall IP e Service Endpoints, consentendo solo subnet autorizzate e segregando ambienti di sviluppo, test e produzione. Esempi pratici includono chiavi CMK in Key Vault con rotazione annuale, Conditional Access per query amministrative e Just-In-Time su VM. Consulta la documentazione Azure security e Defender for Cloud per approfondimenti. Visualizza il diagramma defense-in-depth con i livelli di identità, rete, cifratura, monitoraggio e protezione avanzata.
I backup nei servizi PaaS di Azure sono automatizzati: per SQL Database puoi eseguire ripristino point-in-time verso un preciso punto temporale, utilizzare Long-Term Retention su archiviazione per anni e configurare Active Geo-Replication o Auto-failover groups per il disaster recovery. In Cosmos DB puoi attivare Continuous Backup o backup periodici con retention definita, e ripristinare a livello di item o partizione. È importante stabilire obiettivi di punto di ripristino (RPO) e tempo di ripristino (RTO), verificare regolarmente i processi di ripristino e documentare la conservazione dei backup per la conformità. Esempi pratici includono LTR di 7 anni per il database finance-db, PITR su incidente applicativo e failover group tra regioni con listener globale. In Cosmos DB, Continuous Backup consente il ripristino item-level per specifici container. Consulta la timeline e la mappa geo-replica per comprendere i processi di backup e failover.
La scalabilità di SQL Database può essere verticale, aumentando il numero di vCore e memoria, oppure serverless, con scalabilità automatica utile per carichi intermittenti. Hyperscale consente la separazione tra compute e storage per gestire volumi superiori a 100 TB, con replica di pagine e lettori secondari. In Cosmos DB la scalabilità è orizzontale, sfruttando le partizioni e le RU/s, con Autoscale che adegua il throughput al carico. Il monitoraggio delle prestazioni si effettua tramite Azure Monitor e Insights, che forniscono metriche su uso di DTU, vCore, wait stats, consumo di RU, latenza e tassi di errore. Puoi ottimizzare i costi con reservations per compute e tuning di indici, caching e pattern di accesso. Esempi pratici includono Query Store per analisi performance, alert su soglie di CPU e RU, e workbook con percentili di latenza. Visualizza il cruscotto con grafici di RU/s, vCore usage, latency p95 e la checklist tuning.
Le basi dati Azure si integrano perfettamente con altri servizi della piattaforma. Power BI si collega tramite connettori a SQL e Cosmos DB per creare report e dashboard interattivi. Azure Functions reagisce a eventi su tabelle o cambiamenti, come timer, HTTP, Queue o Change Feed, per implementare logiche serverless e automazioni. Logic Apps orchestra flussi di lavoro con connettori a Office 365, SharePoint, Teams ed ERP, trasformando dati, inviando notifiche e aggiornando record. Per pipeline avanzate si utilizzano Synapse Pipelines e Data Factory per processi ETL/ELT, oppure Event Grid con Change Feed di Cosmos DB per architetture event-driven. Un esempio pratico: Change Feed su ordini in Cosmos attiva una Function che valida e salva su SQL, mentre la Logic App avvisa il team e aggiorna il CRM, e Power BI visualizza i KPI. Visualizza il diagramma event-driven che mostra l’integrazione tra questi servizi.
Le applicazioni web combinano Azure SQL Database per transazioni e Cosmos DB per dati distribuiti, con sicurezza tramite Private Endpoint e monitoraggio con Application Insights. Per l’analisi dati, Synapse e Data Lake gestiscono ingestione e trasformazione, mentre SQL fornisce tabelle curate per BI e conformità. Nell’IoT e Big Data, la telemetria passa da IoT Hub/Event Hubs a Cosmos DB per query operative e a Data Lake per archiviazione storica. Questi pattern integrano servizi PaaS e NoSQL per bilanciare consistenza, velocità e scalabilità. La chiave è definire requisiti di latenza, coerenza, costi e governance, applicando sicurezza, backup e monitoraggio su ogni componente.
1. Tipi di Database – SQL Relazionali vs NoSQL
Nel mondo Azure esistono due grandi categorie di database: relazionali (SQL) e non relazionali (NoSQL). Comprendere le differenze tra queste tipologie è fondamentale per scegliere la soluzione più adatta a un determinato scenario. In generale:
- Database relazionali (SQL): organizzano i dati in tabelle con schemi predefiniti e supportano il linguaggio SQL per l’interrogazione. Offrono proprietà ACID (Atomicità, Consistenza, Isolamento, Durabilità) che garantiscono transazioni affidabili e consistenti. Esempi in Azure includono Azure SQL Database, Azure Database for MySQL e Azure Database for PostgreSQL. I database relazionali sono ideali quando i dati hanno struttura definita, ci sono forti vincoli d’integrità, relazioni tra entità e necessità di unire dati da più tabelle (JOIN) mantenendo la consistenza assoluta – ad esempio in sistemi finanziari, ERP, CRM o applicazioni di reportistica dove è cruciale non perdere nessuna transazione.
- Database non relazionali (NoSQL): memorizzano i dati con schemi flessibili o assenti (schema-less) e privilegiano prestazioni e scalabilità. In Azure l’esempio principale è Azure Cosmos DB, un servizio NoSQL multi-modello che può gestire dati come documenti JSON, coppie chiave-valore, grafi o colonne larghe. I NoSQL sono progettati per bassa latenza e scalabilità orizzontale, cioè la capacità di crescere aggiungendo nodi/server invece di potenziare un singolo nodo. Rinunciano in parte alle rigorose garanzie ACID in favore di una maggiore disponibilità e flessibilità (seguendo spesso il principio "eventual consistency", dove i dati si propagano gradualmente) e supportano varie API di accesso (in Cosmos DB ad esempio: SQL-like, MongoDB, Cassandra, Gremlin per grafi). Sono indicati quando i dati hanno struttura variabile o in evoluzione, quando occorre gestire grandi volumi di dati distribuiti globalmente con alta velocità, ad esempio per applicazioni web a traffico elevato, big data, IoT, contenuti user-generated, o esperienze personalizzate su scala mondiale.
Principali differenze tra SQL e NoSQL – La tabella seguente riassume alcune differenze chiave:
Caratteristica
Database SQL (Relazionale)
Database NoSQL
Schema dei dati
Fisso e predefinito (tabelle con colonne tipizzate). Cambiare schema richiede migrazioni.
Flessibile o assente (documenti JSON, key-value, etc.). Ogni elemento può avere campi diversi; facile aggiungere nuovi attributi.
Linguaggio di query
SQL standard, ottimo per join complessi e query transazionali multi-entità.
No SQL standard unificato. Interrogazioni tramite API specifiche (es. query documentali tipo SQL, interfacce MongoDB/Cassandra, linguaggi per grafi).
Transazioni
ACID complete – forte consistenza, ogni transazione mantiene integrità dei dati.
Generalmente eventual consistency (consistenza eventuale) per performance. Supportano transazioni più limitate o batch; priorità a disponibilità e partizionamento.
Scalabilità
Verticale (scale-up): aumenta risorse sullo stesso server. Il partizionamento è possibile ma complesso; replica per letture.
Orizzontale (scale-out): partizionamento nativo su più nodi. Progettati per distribuire dati e carico su scala globale in modo trasparente.
Latenza e prestazioni
Latenza in genere maggiore su grandi volumi (deve mantenere consistenza forte). Query complesse ottimizzate dagli indici ma possono essere onerose.
Latenza molto bassa anche con grandi volumi (millisecondi a singola cifra in Cosmos DB) grazie a distribuzione e modelli semplificati. Ottimo throughput con hardware commodity.
Casi d’uso tipici
Sistemi finanziari, gestionali, applicazioni line-of-business, dove dati strutturati e consistenza sono critici (es. ordini, fatture, contabilità).
Applicazioni web scalabili, personalizzazione utente, IoT, analisi su dati semi-strutturati, social network, sistemi con dati eterogenei o in rapido cambiamento.
Come regola generale, scegli un database relazionale quando i dati hanno schema ben definito, relazioni complesse e necessiti di vincoli di integrità e transazioni consistenti; scegli un database NoSQL quando hai bisogno di alta velocità, di gestire dati eterogenei o non strutturati su larga scala, con requisiti di schema flessibili e replicazione geografica ampiamente distribuita. Spesso nelle architetture moderne si combinano entrambi: ad esempio, un’applicazione e-commerce può tenere ordini, pagamenti e cataloghi prodotti in un database SQL per garantire consistenza e affidabilità, mentre utilizza un database NoSQL come Cosmos DB per gestire le sessioni utente o i carrelli con bassa latenza e replicazione globale.
Esempio pratico: in un sito di e-commerce, ordini e transazioni finanziarie risiedono su un Azure SQL Database con schema rigido, garantendo che ogni ordine sia conteggiato una e una sola volta; contemporaneamente, le preferenze utente, i carrelli della spesa e le sessioni possono essere archiviati su Cosmos DB (NoSQL) per favorire la rapidità di accesso e la distribuzione dei dati vicino ai clienti nel mondo.
2. Modelli di Dati – Relazionale, Documenti e Grafo
Un modello di dati descrive come vengono organizzati logicamente i dati in un database. Azure supporta vari modelli nei suoi servizi di database, tra cui i modelli relazionale, a documenti e a grafo. La scelta del modello influenza la progettazione dell’applicazione, le prestazioni delle query e le possibilità di analisi. Vediamo i tre principali modelli di dati e in quali scenari si utilizzano:
· Modello relazionale: in questo modello i dati sono organizzati in tabelle fatte di righe e colonne, e le tabelle possono essere collegate tra loro tramite chiavi primarie ed esterne. Le relazioni e i vincoli (chiavi univoche, referential integrity, etc.) garantiscono coerenza tra le entità. Il modello relazionale è efficace per rappresentare dati strutturati con legami chiari – ad esempio anagrafiche clienti, ordini e prodotti – dove si effettuano query complesse che correlano informazioni da più tabelle (JOIN) e si applicano transazioni multi-entità. Azure SQL Database e i database MySQL/PostgreSQL su Azure utilizzano questo modello. Vantaggi: coerenza forte, facilità nel fare query articolate (aggregazioni, join multipli), integrità referenziale automatica. Svantaggi: rigidità dello schema (meno adatto se il formato dei dati cambia spesso) e scalabilità orizzontale non immediata (di solito richiede sharding manuale).
Esempio: un database relazionale per un gestionale scolastico può avere tabelle per Studenti, Corsi e Iscrizioni, assicurando tramite chiavi esterne che ogni iscrizione colleghi uno studente valido a un corso esistente. Query tipiche potrebbero chiedere: “elenca gli studenti iscritti al corso X” unendo le tabelle Studenti e Iscrizioni.· Modello a documenti: adatto a dati semi-strutturati o eterogenei, questo modello memorizza informazioni in formato documento, tipicamente JSON. Ogni documento è un oggetto autodescrittivo che può contenere campi annidati e array. Non c’è un obbligo rigido di uniformità tra documenti: ad esempio, due documenti nella stessa raccolta possono avere campi diversi. I database a documenti consentono di modellare entità complesse come singoli oggetti (ad es. un documento “Ordine” contiene al suo interno la lista degli articoli, i dettagli cliente, indirizzo, ecc.). Azure Cosmos DB (con API Core SQL, o API MongoDB) rientra in questa categoria. Le query possono essere eseguite con sintassi simili a SQL (nel caso di Cosmos DB Core) o con metodi di ricerca propri (nel caso di MongoDB). Vantaggi: grande flessibilità di schema, facile mappare oggetti applicativi direttamente su documenti, ottime prestazioni su lettura/scrittura di un intero documento, scalabilità orizzontale trasparente. Svantaggi: minor efficacia per query molto relazionali (es. aggregazioni che coinvolgono più tipologie di documenti), duplicazione di dati (lo stesso dato può trovarsi in più documenti invece che normalizzato in una relazione), consistenza eventuale di default (in Cosmos DB, la consistenza predefinita a livello sessione bilancia correttezza e prestazioni).
Esempio: un catalogo prodotti di un e-commerce in Cosmos DB potrebbe avere per ogni prodotto un documento JSON con campi diversi per categorie differenti (es. un libro ha autore e ISBN, un telefono ha processore e memoria). Ogni documento è indipendente e può essere recuperato rapidamente per mostrare la scheda prodotto.· Modello a grafo: focalizzato sulle relazioni esplicite tra dati. I database a grafo memorizzano entità come nodi e relazioni come archie (edge); ogni nodo e arco può avere proprietà. Questo modello eccelle quando l’interrogazione riguarda i collegamenti tra elementi più che le proprietà degli elementi stessi. In Azure, Cosmos DB offre un’API per grafi denominata Gremlin, che consente di creare grafi distribuiti. Vantaggi: permette di eseguire operazioni di traversal (attraversamento) di grafo molto efficienti, scoprendo ad esempio connessioni multiple di secondo o terzo grado; è ideale per problemi come suggerire amici in un social network, trovare percorsi ottimali, rilevare pattern di relazione complessi (es. in una rete di frodi finanziarie). Svantaggi: non adatto per transazioni massicce su dati non collegati, e spesso le query di grafo non sono espresse in SQL ma in specifici linguaggi (Gremlin nel nostro caso) che hanno una curva di apprendimento.
Esempio: nell’ambito social network, possiamo modellare utenti come nodi e “amicizie” o “like” come archi tra nodi. Una query di grafo tipica è: “trova il percorso più corto di conoscenze che collega l’Utente A all’Utente B” – un’operazione che un database relazionale faticherebbe a eseguire rapidamente, ma un database a grafo può risolvere esplorando i vicini dei nodi.Riepilogo: la scelta del modello di dati dipende dalle esigenze dell’applicazione. Se servono transazioni complesse e coerenza: modello relazionale. Se servono flessibilità e rapidità nello sviluppo con dati gerarchici o variabili: modello documenti. Se servono analisi di collegamenti e reti: modello a grafo. In Azure Cosmos DB, in particolare, è possibile sfruttare sia modelli a documenti che a grafo (e anche key-value e colonne larghe) usando l’API appropriata, il che lo rende un servizio molto flessibile per diverse necessità.
3. Architettura dei Servizi Database in Azure
L’architettura di un servizio database in Azure definisce come il servizio è strutturato, isolato e collegato all’interno del cloud. Nei servizi Database-as-a-Service (PaaS) di Azure, l’architettura tipica è composta da:
· Istanza o Server Logico gestito – un contenitore che ospita uno o più database. Ad esempio, per Azure SQL Database si parla di Azure SQL Logical Server, per Azure Database for MySQL/PostgreSQL di Server flexibile, e per Cosmos DB di Account. Queste istanze sono gestite da Azure: l’utente non vede il sistema operativo sottostante ma può configurarne alcune opzioni (potenza di calcolo, replica, etc.).
· Database – all’interno del server logico o account, uno o più database (nel caso di Cosmos DB si chiamano database e contengono container o collection a seconda dell’API) che contengono i dati effettivi organizzati secondo un modello (relazionale, documenti, etc.). Ad esempio, potremmo avere un server logico sql-prod-euw con un database chiamato salesdb al suo interno, oppure un account Cosmos DB cosmos-retail con un database profiles che contiene un container users.
· Risorse di rete e sicurezza – ogni servizio database può (e dovrebbe) essere integrato con la rete Azure del cliente: ad esempio tramite Azure Virtual Network (VNet) e Private Endpoints per renderlo accessibile solo da determinate subnet private, oppure tramite firewall IP per limitare gli accessi da Internet. L’architettura include anche l’integrazione con i sistemi di identità (Microsoft Entra ID, precedentemente Azure AD) per l’autenticazione e l’autorizzazione alle risorse database.
In termini di provisioning delle risorse, quando si crea un servizio database Azure occorre specificare capacità e configurazioni che influenzeranno performance e costo:
· Per i database relazionali PaaS (Azure SQL, MySQL, PostgreSQL), si scelgono dimensioni in termini di vCore (unità di CPU/Memory virtuale) o nel vecchio modello DTU, il livello di servizio (General Purpose, Business Critical, Hyperscale per Azure SQL), la quantità di storage e la sua ridondanza. Ad esempio, Azure SQL Database in tier Business Critical offre storage su SSD locale e più replica sincrona per alta resilienza, mentre in tier Hyperscale separa gli strati di calcolo e archiviazione per supportare database di dimensioni enormi (oltre 100 TB). Azure SQL offre anche un’opzione serverless, in cui il database scala automaticamente le risorse in base al carico ed è adatto a carichi intermittenti, con fatturazione in base all’uso.
· Per Azure Cosmos DB (NoSQL), l’attenzione è sulla throughput e la partizione: quando si crea un container su Cosmos, bisogna definire una chiave di partizione (es. /tenantId per separare i dati per cliente, come nell’esempio del container users) e il throughput in termini di Request Unit al secondo (RU/s). Il throughput può essere dedicato (provisioned) – garantendo ad esempio 10.000 RU/s costantemente – oppure serverless/ autoscale, dove paghi solo le RU consumate o hai un range dinamico (es. 400-4000 RU/s come minimo e massimo) che il sistema auto-regola in base al carico. L’architettura Cosmos DB è nativamente distribuita e multi-region: un singolo account può replicare i dati su più data center Azure nel mondo con pochi clic, mantenendo la coerenza scelta (vedi Capitolo 5) e offrendo alta disponibilità e bassa latenza locale.
Un altro aspetto architetturale fondamentale è l’isolamento e la configurazione di rete: per ambienti di produzione è prassi includere il database in una VNet attraverso Private Endpoint (un’interfaccia di rete privata con IP nella VNet che mappa il servizio database), disabilitando l’accesso pubblico internet (firewall impostato su “Nessun servizio esterno”). Questo assicura che solo le applicazioni e i servizi autorizzati nella rete aziendale possano comunicare con il database, riducendo drasticamente la superficie d’attacco. In aggiunta, a livello di identità, Azure permette di usare Azure Entra ID (AD) per autenticare gli utenti e i servizi invece di gestire solo utenti SQL tradizionali: ad esempio si può nominare un Azure AD Admin per un server SQL PaaS e assegnare ruoli database a gruppi AD, o usare i ruoli RBAC in Cosmos DB per concedere accessi in sola lettura/scrittura a determinate collection.
Infine, sul piano architetturale, ricordiamo che essendo servizi PaaS, Azure si occupa automaticamente di molte attività gestionali come l’applicazione di patch di sicurezza al motore di database, gli aggiornamenti, il monitoraggio dell’alta disponibilità (ad esempio Azure SQL Database garantisce un SLA del 99,99% di disponibilità replicando i dati su più nodi nello stesso data center), e la gestione dei backup (trattata nel Capitolo 5). Questo consente al progettista e all’amministratore di concentrarsi più sulla modellazione dei dati e l’ottimizzazione delle query, delegando ad Azure la manutenzione dell’infrastruttura sottostante.
Schema architetturale (descrizione visuale): immagina un disegno a tre livelli: in alto il Server/Account di database (es. un simbolo di database che rappresenta l’istanza logica), sotto di esso uno o più Database/Container come scatole all’interno del server, e sullo sfondo una nuvola che rappresenta la Rete Azure con un lucchetto (a simboleggiare i meccanismi di sicurezza come VNet e firewall). Le frecce indicano che l’applicazione client (fuori dalla nuvola) può accedere al database solo passando attraverso la rete e i punti di accesso sicuri (endpoint privati o pubblici controllati). Questo illustra come ogni chiamata al database transiti per controlli di rete e autenticazione prima di raggiungere l’istanza e infine il database specifico.
4. Sicurezza nei Database in Azure
La sicurezza è un aspetto fondamentale nella gestione dei dati. Azure adotta un approccio a difesa in profondità (defense-in-depth) per proteggere i database su più livelli. In questo capitolo vedremo le principali misure di sicurezza applicabili ai database Azure, tra cui la cifratura dei dati, il controllo di accessi e identità, la sicurezza di rete, e gli strumenti di protezione avanzata e monitoraggio delle minacce.
· Cifratura dei dati (encryption): in Azure i dati vengono cifrati at-rest, ossia quando sono salvati su disco, utilizzando tecnologie integrate. Per i database SQL Azure è abilitata di default la Transparent Data Encryption (TDE), che cripta i file di database e log sullo storage, prevenendo accessi non autorizzati ai dati “a riposo”. Anche Cosmos DB cifra automaticamente i dati salvati. L’utente può opzionalmente gestire le proprie chiavi di cifratura (customer-managed keys) tramite Azure Key Vault, invece di usare le chiavi gestite dalla piattaforma, per avere un ulteriore controllo (ad esempio rotazione periodica delle chiavi, o revoca immediata in caso di necessità). Oltre alla cifratura a riposo, tutti i servizi database Azure richiedono cifratura in transito, ovvero la comunicazione tra client e server avviene tramite protocollo HTTPS/TLS con certificati in modo che i dati siano protetti mentre viaggiano sulla rete. In genere TLS 1.2 è obbligatorio e si può imporre una versione minima.
· Identità e controllo accessi: Azure permette di gestire gli accessi ai database in maniera centralizzata tramite Microsoft Entra ID (Azure AD). Ad esempio, per Azure SQL Database si può impostare un amministratore Azure AD e poi creare account di database mappati su identità Azure AD, assegnandogli ruoli predefiniti (lettura, scrittura, admin). Questo facilita l’uso di credenziali aziendali e abilitazione di autenticazione multi-fattore e condizionale (Conditional Access) a livello AD per accedere ai dati. In Cosmos DB, similmente, esiste un modello RBAC (role-based access control) per cui si possono definire ruoli e permessi granulari sulle risorse (database, container, ecc.) e usare token di accesso legati a identità Azure AD. Naturalmente, restano disponibili anche gli schemi di autenticazione tradizionali: ad esempio SQL Database consente anche account SQL con username e password (ma l’uso di AD è considerato più sicuro e consigliato perché evita credenziali statiche nel codice). La gestione delle identità include anche l’accesso con privilegi minimi: ogni account dovrebbe avere solo i permessi necessari (principio di least privilege).
· Sicurezza di rete: come anticipato nell’architettura, la rete è il primo perimetro di difesa. Firewall a livello di servizio consentono di permettere o bloccare connessioni in base all’IP di provenienza. Più efficaci ancora, gli Azure Private Endpoints permettono di eliminare del tutto l’esposizione pubblica: il database è raggiungibile solo dagli host nella VNet che hanno l’endpoint configurato. Inoltre, con l’isolamento tramite VNet, si possono segregare ambienti diversi (sviluppo, test, produzione) su reti differenti e controllare i flussi di dati tra essi. Per i servizi PaaS, Azure garantisce anche la separazione del traffico di gestione su reti interne, e incoraggia l’uso di Service Endpoints o Private Endpoints per il traffico applicativo. La rete è anche il luogo dove applicare altre misure come WAF (Web Application Firewall) se il database è dietro un servizio web, e l’uso di VPN o Azure ExpressRoute per connettere il cloud alla rete aziendale in modo sicuro.
· Monitoraggio e protezione avanzata: Azure fornisce strumenti specifici per monitorare e rafforzare la sicurezza dei database. Ad esempio Microsoft Defender for SQL (parte di Defender for Cloud) può essere abilitato sia su Azure SQL Database PaaS sia su SQL Server su macchine virtuali: esso esegue valutazioni di vulnerabilità (per esempio individuando configurazioni deboli, software non aggiornato, permessi eccessivi) e monitora attività anomale segnalando possibili minacce (ad es. tentativi di SQL injection, accessi sospetti). Defender for Cloud estende raccomandazioni di sicurezza anche ad Azure Cosmos DB e altri servizi, aiutando a migliorare la cosiddetta secure score (punteggio di sicurezza) dell’ambiente. Oltre a questo, il logging delle attività (ad esempio Azure SQL Auditing per tracciare le query eseguite e gli accessi) e l’uso di servizi di analisi centralizzata dei log (come Azure Monitor e Log Analytics) consentono di avere visibilità su chi sta accedendo ai dati e quando, per individuare tempestivamente comportamenti fuori norma.
Azure adotta dunque un modello di sicurezza a strati: dati cifrati, identità e permessi ben gestiti, rete isolata, monitoraggio continuo e protezione attiva con strumenti intelligenti. Un’analogia utile è pensare alla sicurezza del database come a una fortificazione medievale: non c’è un singolo muro che protegge il castello, ma più cerchie di mura concentriche e guardie (controlli) a ogni cancello. Così, anche se un livello viene superato (es. delle credenziali trapelano), ce ne sono altri a mitigare il rischio (es. quella user ID non ha accesso da fuori rete, o le azioni sospette vengono subito allertate da Defender).
Esempio pratico: un’azienda configura il proprio database finance-db su Azure SQL. Attiva la TDE con chiavi gestite via Key Vault (e decide di ruotarle annualmente). Imposta come amministratore un gruppo Azure AD che include solo gli DBA aziendali e richiede MFA per chiunque tenti di connettersi come admin. Tramite firewall e endpoint privato, fa sì che il database sia accessibile solo dalle VM applicative nella rete di produzione e dagli IP del suo ufficio per manutenzione, bloccando tutto il resto. Inoltre abilita Microsoft Defender for SQL per ricevere alert in caso di query anomale o tentativi di exploit, e controlla periodicamente le raccomandazioni di sicurezza (ad esempio abilitare il TLS 1.2 obbligatorio se non lo fosse già). Con tutti questi accorgimenti, i dati finanziari sensibili hanno molteplici livelli di protezione.
5. Backup e Ripristino (Disaster Recovery)
Anche con tutte le misure di sicurezza, è essenziale prepararsi a situazioni impreviste come errori applicativi, cancellazioni accidentali di dati o guasti catastrofici. Per questo entrano in gioco i backup (copie di sicurezza dei dati) e le strategie di ripristino. Azure semplifica molto questi aspetti nei servizi database PaaS, offrendo backup automatici, capacità di ripristino a un punto nel tempo (Point-In-Time Restore - PITR) e opzioni di replica geografica per il disaster recovery.
· Backup automatici e PITR: Per Azure SQL Database, ad esempio, la piattaforma esegue automaticamente backup completi settimanali, differenziali giornalieri e backup del log frequenti, mantenendoli per un periodo standard (tipicamente 7-35 giorni a seconda delle impostazioni e del tier di servizio). Ciò consente di effettuare un ripristino point-in-time, ovvero ripristinare il database allo stato in cui si trovava in un momento specifico (ad esempio “riporta il database com’era alle ore 10:00 di 3 giorni fa”). Questa funzionalità è utilissima se scopriamo bug o errori che hanno corrotto i dati: possiamo tornare indietro nel tempo prima che l’errore avvenisse. I backup automatici sono gestiti da Azure senza interrompere l’operatività del database, e sono salvati su storage ridondante. In Cosmos DB, similmente, è possibile attivare il Continuous Backup continuo (dove il servizio tiene traccia di tutte le modifiche e consente PITR entro un periodo definito) oppure backup periodici con retention configurabile.
· Ritenzione a lungo termine (LTR): In alcuni casi, come requisiti normativi o audit, bisogna conservare i backup per anni. Azure SQL Database offre la Long-Term Retention (LTR), che permette di conservare copie di backup settimanali su storage di archiviazione per 1, 5 o fino a 10 anni, definendo policy granulari. Così, se tra 5 anni servisse rivedere i dati di fine anno 2025, si potrebbe ripristinare il backup archiviato di quel periodo. È importante però pianificare lo storage necessario e i costi per questi backup di lungo termine.
· Replica geografica e failover: Il backup aiuta per errori puntuali, ma per la continuità operativa in caso di disastri maggiori (ad esempio un’intera regione Azure fuori servizio) conviene avere una configurazione di disaster recovery. Azure SQL Database offre la Active Geo-Replication e i Failover Groups: si possono avere fino a 4 copie read-only del database in altre regioni Azure, aggiornate in modo asincrono. In caso di disastro, l’applicazione può fare failover su una di queste copie secondarie, minimizzando il downtime. I Failover Group permettono anche di avere un endpoint di connessione unico che automaticamente redirige alla replica attiva primaria, semplificando la logica di failover nell’applicazione. Nel caso di Cosmos DB, la distribuzione multi-region è già integrata nel servizio: se replichiamo i dati su, ad esempio, West EU e East US, in caso di problemi su West EU possiamo leggere e scrivere sui dati di East US (a seconda del livello di consistenza scelto, il servizio garantisce che non ci siano conflitti). Cosmos DB inoltre supporta il manual failover tra regioni mediante pochi click o via SDK.
· RPO e RTO: Nel definire la strategia di backup e DR, bisogna stabilire due parametri chiave: il Recovery Point Objective (RPO), cioè quanti dati al massimo possiamo permetterci di perdere (es: RPO di 5 minuti significa che accettiamo di perdere al più 5 minuti di transazioni in caso di incidente, quindi i backup/log shipping devono avvenire almeno ogni 5 minuti); e il Recovery Time Objective (RTO), ovvero quanto tempo al massimo può restare inutilizzabile il servizio prima del ripristino (es: RTO di 1 ora implica che entro un’ora dall’evento dobbiamo essere di nuovo online, magari su una regione secondaria). Azure, con le sue funzionalità, aiuta a ottenere RPO e RTO molto bassi se la soluzione è ben configurata: ad esempio con un failover group attivo, RPO di pochi secondi (dipende dalla latenza di replica georeplicata) e RTO di pochi minuti (il tempo di commutare i riferimenti). Per un semplice ripristino point-in-time, RPO può essere anch’esso di minuti (backup log frequenti) e RTO dipende dalla dimensione del database e dalla velocità di restore (da pochi minuti a qualche ora per DB molto grandi).
Buone pratiche: è fondamentale testare periodicamente i piani di ripristino. Avere backup non serve se poi non sappiamo ripristinarli velocemente all’occorrenza. Quindi, simulare uno scenario in cui si ripristina il database da backup (magari su un’istanza di test) o si effettua un failover controllato su un sito secondario, è parte integrante della preparazione, oltre a monitorare che i backup vengano eseguiti regolarmente. Inoltre, proteggere i backup stessi – ad esempio limitando l’accesso allo storage dei backup, cifrandoli (Azure li cifra già se at-rest), e controllando le identità che possono avviare un restore – fa parte della sicurezza globale.
Esempio pratico: un’applicazione mission-critical su Azure SQL Database mantiene attivi i backup con PITR di 14 giorni. Un bug nel codice elimina per errore alcuni dati ieri sera alle 23:00; accortisi del problema, i tecnici eseguono un Point-In-Time Restore del database a com’era alle 22:55, recuperando i dati persi (gli ultimi 5 minuti di transazioni vengono re-inseriti manualmente dai log applicativi). Inoltre, per resilienza, il database era configurato in un Failover Group con una copia su un altro data center: durante un test di DR, l’IT simula la caduta della regione primaria e verifica che l’applicazione possa connettersi alla replica secondaria in pochi minuti di disservizio. In Cosmos DB, per un’app IoT, si è attivato il Continuous Backup e si prova a ripristinare un singolo elemento (documento) cancellato accidentalmente da uno sviluppatore, sfruttando la funzione di point-in-time restore a livello di item – operazione completata con successo in pochi secondi.
6. Scalabilità e Monitoraggio delle Prestazioni
Le esigenze di un’applicazione possono cambiare drasticamente nel tempo: un database potrebbe dover gestire un numero crescente di utenti, volumi di dati sempre maggiori oppure carichi molto variabili nell’arco della giornata. La scalabilità indica la capacità di un sistema di crescere in potenza all’aumentare del carico, mantenendo performance accettabili. In Azure i servizi database offrono varie opzioni di scalabilità, accompagnate da strumenti di monitoraggio per osservare e ottimizzare le prestazioni.
a) Scalabilità verticale vs orizzontale:
· Scalabilità verticale (scale-up): consiste nel potenziare l’istanza esistente, ad esempio aumentando i vCore, la RAM, o la potenza di I/O disponibili per il database. Azure SQL Database consente di passare a tier superiori (da 2 a 4 vCore, poi 8 vCore, etc.) oppure a macchine con più memoria, per gestire più transazioni al secondo. Questa operazione è spesso semplice (può essere effettuata via portale con uno slider) ma comporta tipicamente un breve riavvio/rialloco del servizio. La scalabilità verticale funziona bene finché esiste un “single instance” che può reggere il carico, ma ha limiti fisici (c’è un massimo di risorse su una singola macchina) ed economici (oltre una certa soglia, aumentare ancora CPU/RAM diventa molto costoso).
· Scalabilità orizzontale (scale-out): consiste nell’aggiungere più istanze in parallelo per dividere il carico. Nel contesto dei database relazionali tradizionali non è banale – si può implementare sharding (partizionare i dati su più database) e replicare per letture, ma l’app deve gestire la logica. Nei database nativamente distribuiti come Cosmos DB invece, la scalabilità orizzontale è un principio base: i dati vengono automaticamente partizionati su più nodi e il servizio aggiunge nodi dietro le quinte all’aumentare del throughput richiesto. Azure Cosmos permette di dimensionare il throughput in RU/s e suddivide quel budget tra le partizioni; con l’opzione Autoscale può adeguare dinamicamente le RU/s disponibili (fino a un massimo definito) in base al traffico, così l’app non subisce rallentamenti durante picchi di carico. Azure SQL non supporta il scale-out trasparente per scritture, ma consente di aggiungere repliche di sola lettura (ad esempio con l’opzione Hyperscale, i secondary replicas per leggere, o in Managed Instance creare scale-out per operazioni di sola lettura). Inoltre alcune funzionalità come gli Elastic Pool di Azure SQL permettono di scalare più database insieme e condividere risorse comuni per gestire carichi variabili tra di essi.
b) Serverless e Hyperscale: Come accennato, Azure SQL Database offre due modalità particolari:
· Serverless: qui la scalabilità è praticamente automatica e verticale dinamica. Si imposta un range minimo e massimo di vCore e il servizio attiva o sospende risorse in base all’attività: se un database è inattivo, riduce le risorse al minimo (persino andando in pausa, con costi quasi zero), quando il carico aumenta scala fino al massimo definito. Questa opzione è ottima per ambienti di sviluppo o applicazioni con utilizzo saltuario, perché ottimizza i costi.
· Hyperscale: è un’architettura di Azure SQL pensata per grandissimi database (centinaia di GB fino a decine di TB). In Hyperscale, il nodo principale delega la gestione dei dati a page servers e tiene più repliche per le letture, separando nettamente compute e storage. Ciò vuol dire che aggiungere spazio non richiede migrazioni (si aggiunge un page server), e si possono scalare le prestazioni aggiungendo reader endpoint. In pratica Hyperscale combina scale-up (il nodo primario può essere di varie dimensioni) e scale-out per letture.
c) Monitoraggio delle prestazioni: Azure fornisce un ricco insieme di metriche e log per monitorare lo stato dei database:
· Per Azure SQL Database si possono monitorare metriche come percentuale di utilizzo CPU, consumo di I/O, memoria, tempo di attesa (wait stats), tassi di transazioni al secondo e utilizzo del log, nonché statistiche a livello di query (grazie a strumenti come Query Performance Insight o Query Store). Le metriche possono essere visualizzate in Azure Monitor con grafici nel tempo, e si possono impostare alert (notifiche) su soglie – ad esempio mandare un avviso se la CPU supera l’80% per più di 5 minuti.
· Per Azure Cosmos DB, le metriche chiave includono consumo di RU (Request Unit) per secondi, latenza delle operazioni (in particolare la percentuale di richieste servite sotto certi millisecondi, es. latenza al 95° percentile), tasso di errori (ad esempio se qualche partizione satura il limite di RU disponibili e genera errori 429 – Too Many Requests). Anche qui si possono impostare alert, ad esempio se il consumo RU supera il 70% della soglia provisioned sostenutamente, segnalando che forse serve aumentare throughput.
· Strumenti come Azure Monitor integrato e Application Insights (dal lato applicazione) permettono di correlare le metriche: ad esempio, un calo di performance dell’app potrebbe corrispondere a un aumento di latenza sul database. Azure SQL Analytics (soluzione su Log Analytics) offre dashboard predefinite per identificare query lente, index tuning, etc.
· Per il tuning, Azure include funzionalità di advisors (consiglieri): ad esempio l’Index Advisor suggerisce indici mancanti per velocizzare certe query, o consiglia di eliminare indici inutilizzati per risparmiare risorse. Query Store in SQL registra le plan di esecuzione e aiuta a individuare regressioni di performance nel tempo. Su Cosmos DB, invece, bisogna progettare bene la chiave di partizione e monitorare l’“skew” (se una partizione riceve molto più traffico delle altre diventando hotspot).
d) Ottimizzazione dei costi e performance
Spesso monitoraggio e scalabilità vanno a braccetto per ottimizzare i costi. Ad esempio, se notiamo che un database SQL è sottoutilizzato la notte, potremmo abbassare manualmente il tier o usare lo scaling programmato (Azure Rest API/Automation) per ridurre i vCore in certi orari. Oppure usare autoscale (per Cosmos DB) per non pagare il massimo di RU 24/7 ma solo quando serve. Un altro esempio: se alcune query sono lente, invece di aumentare a dismisura le risorse (cosa costosa) conviene vedere se mancano indici o se si possono ottimizzare (un approccio “scale smart” anziché solo “scale out”). Azure offre Azure Advisor che periodicamente analizza anche l’utilizzo delle risorse suggerendo dove potresti risparmiare (ad esempio passando a un piano inferiore se l’uso è basso, o acquistando riserve per 1-3 anni per avere sconti se l’allocazione di vCore è stabile).
Esempi pratici:
· Un’azienda di videogiochi online ha un database Cosmos DB per salvare statistiche di gioco. All’ora di punta serale il consumo RU schizza in alto; impostando Autoscale (ad esempio 1000-10000 RU/s), il database scala automaticamente verso l’alto durante il peak e torna a valori minori di RU off-peak, garantendo sia performance che risparmio. Nel monitor, i grafici di RU consumption mostrano picchi al 90% del massimo, ma senza mai toccare il limite (dunque senza errori di throttling).
· Un sito di e-commerce su Azure SQL Database in tier standard nota rallentamenti durante il Black Friday. Prima dell’evento, gli amministratori scalano verticalmente il database dal tier 4 vCore a 16 vCore. Inoltre, attivano Query Store per tracciare le query più lente. Durante il Black Friday, monitorano attivamente CPU e tempi di risposta: vedendo la CPU salire oltre 80%, decidono di aggiungere temporaneamente 2 repliche di sola lettura (in Hyperscale) per distribuire le query di reporting e alleggerire il primario. Ciò consente al sistema di reggere il carico senza downtime. Al termine, riportano la dimensione del database a valori normali per non sostenere costi inutili.
· Un’applicazione vede periodici colli di bottiglia su determinate query SQL. Analizzando i log, scoprono che manca un indice sulla colonna utilizzata da quella query nel WHERE. Aggiunto l’indice, la query diventa 10 volte più veloce e l’utilizzo CPU del database cala sensibilmente, evitando per ora l’upgrade a un tier maggiore.
7. Integrazione con Altri Servizi Azure
I database non vivono isolati: in Azure essi fanno parte di un ecosistema più ampio di servizi cloud. Un grande vantaggio del cloud Azure è la integrazione nativa fra i suoi servizi, che consente di costruire soluzioni end-to-end combinando database con analisi, intelligenza artificiale, servizi applicativi, flussi di dati, ecc. In questo capitolo vediamo alcuni esempi di integrazione tra servizi di database e altri servizi Azure:
· Power BI e BI/Analytics: Azure SQL Database e Cosmos DB possono essere sorgenti dati per Power BI, la piattaforma Microsoft di business intelligence e data visualization. Tramite connettori nativi, Power BI può estrarre dati da Azure SQL in tempo quasi reale per creare report interattivi e dashboard sulle metriche aziendali. Nel caso di Cosmos DB, spesso l’integrazione avviene attraverso l’Analytical Store di Cosmos (nel contesto di Azure Synapse Link) oppure esportando periodicamente i dati verso un database SQL o un Data Lake, dove Power BI li consuma. Un esempio: i dati raccolti in Cosmos DB da un’applicazione IoT possono essere replicati in un ambiente di analisi (Synapse o SQL dedicato) e poi visualizzati su Power BI per mostrare trend e anomalie su larga scala.
· Azure Functions (Serverless compute): Azure Functions consente di eseguire piccole unità di codice in risposta a eventi, senza gestire infrastruttura. I database Azure possono innescare delle funzioni serverless – ad esempio Cosmos DB ha la funzionalità di Change Feed, un flusso di eventi che registra in tempo reale le modifiche (inserimenti/aggiornamenti) su una collection. Si può collegare una Function a questo flusso: ogni nuovo documento inserito in Cosmos attiva la funzione che magari esegue una logica aggiuntiva (es: validare i dati, arricchirli, o sincronizzarli su un altro database). Altri trigger possibili: una Function può essere invocata da un timer (per operazioni schedulate sul database, come manutenzioni) o da code e messaggi (ad esempio un messaggio su una coda Service Bus che indica di fare una certa operazione sul DB). Grazie alle Functions, si implementano facilmente reazioni a eventi nel database in modo totalmente cloud e scalabile.
· Esempio: ogni volta che un ordine viene scritto nella collection orders di Cosmos DB, parte una Azure Function che prende quell’ordine, ne verifica il contenuto e lo scrive su Azure SQL Database (magari per fini di rendicontazione finanziaria). Questo pattern incrocia velocità NoSQL e consistenza SQL.
· Logic Apps: sono il corrispettivo low-code di Azure Functions, orientate all’orchestrazione di workflow integrando vari servizi tramite connettori predefiniti. Una Logic App può reagire a eventi o schedulazioni e coordinare attività come: “quando nel database X compare un nuovo record Y, invia una mail, aggiorna un file su SharePoint e posta un messaggio su Teams”. Nel contesto database, esistono connettori per Azure SQL e per Cosmos DB (tra gli altri), quindi ad esempio una Logic App potrebbe periodicamente leggere righe da una tabella SQL e aggiungere record in una lista SharePoint, oppure ascoltare modifiche su Cosmos (anche qui tramite il Change Feed integrato in Event Grid) e avviare processi di approvazione, ecc.
Esempio: quando un nuovo utente si registra (inserimento nella tabella Users su SQL), una Logic App invia automaticamente un’email di benvenuto e crea una voce corrispondente nel CRM aziendale attraverso il suo connettore API.· Event Grid & Event Hubs (dati streaming e reattivi): Cosmos DB pubblica gli eventi di Change Feed su Azure Event Grid, il servizio di routing eventi globale. Ciò significa che altri servizi possono sottoscriversi agli eventi di modifica del database in maniera reattiva. Ad esempio, una nuova telemetria IoT inserita in Cosmos può generare un evento su Event Grid, che attiva sia una Function (per elaborazione), sia magari notifica un servizio di coda, sia aggiorna una cache. Event Hubs invece è usato per ingestione massiva di dati di streaming (telemetria in tempo reale, log): questi dati spesso vengono poi salvati su database (batch o in streaming analytics). Immaginiamo IoT Hub/Event Hubs che raccoglie milioni di eventi dai sensori e poi li storicizza su un database, oppure li inoltra a Cosmos DB per consultazione immediata su di essi.
· Data Factory e Synapse Pipelines (ETL/ELT): quando si devono spostare grandi volumi di dati tra sistemi, integrare dati da diverse fonti o costruire data warehouse, si utilizzano pipeline di data integration. Azure Data Factory (ADF) o Azure Synapse Pipelines permettono di estrarre dati da database (Azure SQL, Cosmos tramite connettore) e trasformarli: ad esempio prendere dati da Cosmos DB, normalizzarli e caricarli in una tabella Azure SQL per reporting. Oppure effettuare backup logici, migrazioni tra database, caricamento di file bulk su database, etc. Questi strumenti completano la sinergia tra servizi di storage e database.
In sintesi, Azure offre un ecosistema connesso: i dati raccolti e gestiti nei database possono attivare processi serverless, alimentare analisi in tempo reale e in differita, confluire in pipeline automatizzate e infine essere presentati su dashboard interattive. Questo consente di costruire soluzioni complete: ad esempio, una architettura event-driven potrebbe prevedere che ogni modifica nei dati utente su Cosmos DB attivi una Function che aggiorna anche Azure SQL e poi una Logic App per notificare il team e aggiornare un sistema esterno, mentre contemporaneamente i dati vengono resi disponibili per analisi storiche su Synapse, il tutto connettendo servizi diversi senza soluzione di continuità.
Esempio pratico integrato: in una soluzione di e-commerce avanzata, quando un ordine viene confermato su SQL Database, la transazione scrive anche un record su Cosmos DB in una collection orders_feed. Da qui:
· Il Change Feed di Cosmos DB intercetta il nuovo documento.
· Event Grid propaga l’evento a chi è interessato.
· Una Azure Function viene attivata: calcola ad esempio i punti fedeltà per il cliente e li salva sempre su Cosmos DB.
· Una Logic App parallela invia un’email di conferma al cliente e notifica il canale Teams del reparto spedizioni.
· Nella notte, Synapse Pipeline preleva tutti gli ordini del giorno da Cosmos DB e li integra con i dati di fatturato da SQL, salvandoli in un data lake come file parquet.
· Power BI al mattino mostra un report unendo le informazioni (velocità di consegna, dati finanziari, etc.) aggiornato ai dati integrati del giorno prima.
Questo scenario, pur complesso, è reso possibile dall’integrazione nativa tra i componenti Azure. I database sono il cuore dei dati, ma la vera potenza sta nel metterli in comunicazione con funzioni, flussi e strumenti di analisi.
8. Casi d’Uso – Scenari Applicativi
Dopo aver esaminato tecnologie e concetti, vediamo come questi si concretizzano in alcuni casi d’uso reali nel cloud Azure. Presentiamo tre scenari tipici: un’applicazione web, una pipeline di analisi dati, e una soluzione IoT/Big Data. In ognuno, diversi servizi di database e integrazione lavorano insieme.
· Applicazioni Web aziendali: Immagina un portale web di una banca o un e-commerce. Spesso l’architettura prevede un database relazionale per i dati core (conti correnti, ordini, inventario) per garantire consistenza e strutturazione, affiancato da database NoSQL per dati relativi all’esperienza utente o sessioni. In Azure, un’implementazione potrebbe usare Azure SQL Database come repository primario per transazioni finanziarie o ordini, mentre Azure Cosmos DB viene usato per archiviare le sessioni utente, i carrelli temporanei, o i dati di personalizzazione (prodotti visti, preferenze) con replicazione globale per bassissima latenza. L’applicazione (ospitata magari su Azure App Service) si connette a SQL per le operazioni critiche e a Cosmos DB per leggere/scrivere rapidamente informazioni non transazionali. Il tutto è messo in sicurezza con rete privata e Azure AD come visto nei capitoli precedenti, e monitorato con Application Insights. In aggiunta, Azure Cache for Redis potrebbe essere integrato per caching severo di dati letti di frequente.
Benefici: l’utente del sito avrà un’esperienza rapida (grazie al NoSQL distribuito per contenuti volatili) senza compromettere la correttezza dei suoi ordini e pagamenti (gestiti dal SQL con piena ACID). L’azienda può scalare orizzontalmente la parte NoSQL verso altre regioni se apre il servizio in nuovi paesi, mantenendo i dati centrali consolidati.· Analisi Dati e BI: Per applicazioni orientate all’analisi (es. un sistema di reportistica finanziaria o analytics marketing), spesso i dati vengono raccolti da sorgenti operative e poi elaborati in pipeline. Un tipico scenario Azure vede l’uso di Azure Synapse Analytics o Azure Data Lake Storage per raccogliere grandi moli di dati grezzi (log, file CSV, dati storici), successivamente trasformarli e caricarli in un database relazionale che funga da data warehouse per la reportistica. Ad esempio, si potrebbero importare dati di vendite giornaliere da vari negozi in Azure Data Lake, poi usare una pipeline Synapse/ADF per pulirli e calcolare aggregati, infine inserirli in tabelle di Azure SQL Database ottimizzate per le query BI. Parallelamente, se i dati provengono in parte anche in tempo reale (click di utenti sul sito, dati IoT), Cosmos DB potrebbe essere usato per acquisire velocemente questi stream, che poi vengono periodicamente estratti nel sistema di analisi. Infine Power BI si collega al database finale (o direttamente a Synapse) per fornire dashboard sempre aggiornate al management.
Benefici: questa architettura garantisce separazione tra i sistemi transazionali operativi e quelli analitici. I carichi di lavoro di analisi non disturbano le applicazioni live (perché lavorano su copie dei dati), e si può scalare ogni componente indipendentemente (Synapse per elaborazione massiva, SQL per rapidità sulle query BI, etc.). Inoltre, si possono applicare modelli di machine learning ai dati nel lake o in Synapse per estrarre insight aggiuntivi, con i risultati anch’essi memorizzati e resi disponibili via database.· IoT e Big Data in tempo reale: Un caso d’uso moderno è la gestione di dispositivi IoT (Internet of Things) che generano flussi continui di dati (sensori, log di macchinari, telemetria vetture, etc.). In Azure, uno scenario di riferimento prevede che gli eventi dei dispositivi vengano ingeriti ad alta velocità attraverso servizi come IoT Hub o Event Hubs, quindi memorizzati in parte per analisi storica e in parte per accesso immediato. Ad esempio, IoT Hub riceve milioni di messaggi al giorno da sensori; questi messaggi vengono accumulati in un Data Lake per archiviazione storica grezza e batch processing, ma vengono anche inviati a una Azure Function in streaming che li inserisce in Azure Cosmos DB con chiave di partizione per dispositivo e/o timestamp. Cosmos DB in questo modo tiene solo gli ultimi dati o dati operativi utili all’applicazione (per es. lo stato corrente di ciascun dispositivo, o gli eventi delle ultime 24 ore). Se bisogna mostrare su una dashboard IoT lo stato attuale di un sensore, l’app può leggere direttamente da Cosmos DB (che fornisce risposta rapida). Nel frattempo, a valle, processi di aggregazione giornalieri leggono dal Data Lake o direttamente dal Change Feed di Cosmos per calcolare statistiche (es. consumo medio orario, anomalie) che vengono poi salvate su un database relazionale o un modello di analisi per report mensili.
Benefici: questa pipeline sfrutta i punti di forza di ciascun componente – ingestione scalabile (Event Hubs), elaborazione serverless (Functions), archiviazione operativa veloce e distribuita (Cosmos DB) e archiviazione analitica a basso costo (Data Lake + SQL/Synapse). Si ottiene sia la visione real-time (per intervenire subito se un sensore manda un allarme) sia la visione storica (per trend e ottimizzazioni a lungo termine).
Conclusioni
Questi esempi evidenziano un principio chiave: spesso la soluzione migliore non è un solo database, ma una combinazione orchestrata di servizi, ciascuno usato dove rende di più. Azure facilita questo tramite un ventaglio di opzioni (SQL, NoSQL, analitici, streaming) che cooperano tra loro. Quando si progetta un sistema, è importante definire bene i requisiti in termini di latenza tollerata, consistenza necessaria, volume di dati, frequenza di accesso, costi e complessità, e in base a ciò allocare i giusti servizi per ciascun ruolo: un database transazionale per i dati critici, un archivio NoSQL per scala e velocità, eventualmente un data warehouse dedicato per l’analisi, il tutto tenuto insieme da pipeline e API integrate. Inoltre, è fondamentale applicare in modo consistente le pratiche di sicurezza, backup e monitoraggio a tutti i componenti: la robustezza di una soluzione si misura dall’anello più debole, quindi non bisogna trascurare nessuna parte (ad esempio, non avrebbe senso proteggere bene SQL e lasciare pubblico il feed di Event Hubs, o fare backup del database ma non del data lake se contiene dati insostituibili).
Con questa panoramica, uno studente dovrebbe aver acquisito una solida comprensione dei servizi di database Azure e di come usarli in sinergia. Si consiglia di approfondire ciascun capitolo con esercitazioni pratiche: ad esempio provare a creare un database SQL e uno Cosmos e fare query, impostare un backup e poi fare un restore in un ambiente di test, o sviluppare una piccola funzione che reagisca al change feed. L’apprendimento attivo sul campo, unito a quanto appreso in teoria, consoliderà queste conoscenze e preparerà ad affrontare scenari reali nel cloud.
Riepilogo capitolo
Il capitolo fornisce una panoramica dettagliata sui database in Azure, confrontando i modelli relazionali e NoSQL, descrivendo i modelli di dati supportati, l'architettura dei servizi, la sicurezza, il backup, la scalabilità, l'integrazione con altri servizi Azure e casi d'uso applicativi tipici.
· Tipi di database in Azure: Azure offre database relazionali (SQL) con schema fisso e proprietà ACID, ideali per dati strutturati e transazioni critiche, e database NoSQL con schema flessibile e scalabilità orizzontale, come Cosmos DB, adatti a dati variabili e grandi volumi distribuiti globalmente.
· Differenze chiave tra SQL e NoSQL: I database SQL usano schemi rigidi, SQL standard, transazioni ACID e scalabilità verticale, mentre i NoSQL hanno schemi flessibili, linguaggi di query specifici, consistenza eventuale e scalabilità orizzontale nativa, con latenze più basse su grandi volumi.
· Modelli di dati supportati: Azure supporta modelli relazionali (tabelle con chiavi e vincoli), a documenti (JSON flessibile) e a grafo (nodi e relazioni), ciascuno con vantaggi e svantaggi specifici e scenari d’uso dedicati. Cosmos DB consente più modelli tramite API diverse.
· Architettura dei servizi database: I servizi PaaS di Azure includono istanze logiche (server o account), database o container interni, e risorse di rete e sicurezza come VNet e Private Endpoints. La configurazione di capacità (vCore, RU/s) e livelli di servizio influisce su performance e costi. Azure gestisce manutenzione, patch, alta disponibilità e backup.
· Sicurezza nei database: Azure applica cifratura a riposo e in transito, gestisce identità e permessi tramite Azure AD, isola le risorse in rete con firewall e Private Endpoints, e offre strumenti di monitoraggio e protezione avanzata come Microsoft Defender e auditing per rilevare minacce e anomalie.
· Backup e ripristino: Azure automatizza backup completi, differenziali e log per il ripristino point-in-time, con opzioni di retention a lungo termine e replica geografica per disaster recovery. Si definiscono RPO e RTO per stabilire limiti di perdita dati e tempi di ripristino. Testare i piani di ripristino è fondamentale.
· Scalabilità e monitoraggio: Azure supporta scalabilità verticale (aumentare risorse su singola istanza) e orizzontale (aggiungere nodi), con opzioni serverless e Hyperscale per grandi database. Offre strumenti di monitoraggio per CPU, I/O, latenza e throughput, e consigli per ottimizzazione di indici e query. La scalabilità è combinata con strategie di ottimizzazione costi.
· Integrazione con servizi Azure: I database si integrano con Power BI per analisi, Azure Functions e Logic Apps per workflow e automazioni, Event Grid e Event Hubs per eventi e streaming, e Data Factory/Synapse per pipeline ETL/ELT, permettendo soluzioni end-to-end complesse e reattive.
· Casi d’uso applicativi: Scenari tipici includono applicazioni web aziendali che combinano SQL e NoSQL per dati transazionali e sessioni utente, pipeline di analisi dati con separazione tra sistemi operativi e analitici, e soluzioni IoT/Big Data che usano Event Hubs, Cosmos DB e Data Lake per gestione real-time e storica dei dati.
CAPITOLO 7 – Il servizio di intelligenza artificiale e di machine learning
Introduzione
Nel mondo Azure, i servizi di Intelligenza Artificiale (IA) e Machine Learning (ML) si presentano sotto due forme principali: da un lato servizi preconfigurati (soluzioni chiavi in mano per visione artificiale, elaborazione del linguaggio, riconoscimento vocale, traduzione e processi decisionali); dall’altro piattaforme di sviluppo che permettono di addestrare e distribuire modelli personalizzati su larga scala. In Azure, queste due anime coesistono per offrire sia soluzioni immediatamente utilizzabili, sia la flessibilità di creare modelli su misura.
Azure Machine Learning (Azure ML) è il cuore della piattaforma Azure per il ciclo di vita del machine learning. Si tratta di un servizio enterprise che supporta i team in tutte le fasi di un progetto ML: dalla preparazione dei dati all’addestramento del modello, fino alla messa in produzione e al monitoraggio continuo, il tutto con governance e sicurezza integrate. Azure ML consente di utilizzare i più diffusi framework open-source (come PyTorch, TensorFlow, scikit-learn ecc.) e anche modelli pre-addestrati di grande dimensione (foundation models) disponibili nel catalogo modelli di Azure. Inoltre, offre strumenti per orchestrare flussi di lavoro avanzati come quelli basati su prompt (prompt engineering per modelli linguistici) e agenti AI.
Per applicazioni che richiedono funzionalità cognitive pronte all’uso (ad esempio riconoscere immagini, comprendere testi o parlare in linguaggio naturale), Azure mette a disposizione un’ampia gamma di Azure AI Services: API pre-addestrate per Vision, Speech, Language, Decision e Document Intelligence. Questi servizi permettono agli sviluppatori di aggiungere facilmente capacità di vedere, ascoltare, parlare e comprendere alle proprie applicazioni senza dover costruire modelli da zero.
Un’altra componente importante nell’ecosistema Azure AI è Microsoft Foundry, un nuovo portale unificato che semplifica lo sviluppo di soluzioni con modelli di AI generativa e agenti intelligenti. Foundry consente di accedere a un ricco catalogo di modelli (inclusi modelli di Microsoft, OpenAI, Meta, Hugging Face, Cohere e altri), di combinarli con strumenti (tools) come i servizi cognitivi e di applicare controlli di Responsible AI in modo centralizzato. In pratica, Foundry rende più facile integrare modelli di diversi fornitori, costruire agenti AI (sistemi capaci di compiere azioni multi-step utilizzando modelli linguistici e strumenti software) e assicurare che il tutto avvenga in modo etico e sicuro.
Di seguito alcuni esempi pratici che illustrano le possibilità offerte da Azure in ambito AI e ML:
· Esempio 1: Un sito e-commerce può combinare servizi Azure per migliorare l’esperienza utente. Ad esempio, può usare i servizi di Vision per generare automaticamente descrizioni (caption) delle immagini dei prodotti e i servizi di Language per tradurre le recensioni o le descrizioni dei prodotti in più lingue. Inoltre, può sfruttare Azure Machine Learning per sviluppare un sistema di raccomandazione personalizzato che suggerisce prodotti ai clienti in base ai dati di acquisto e di navigazione. In questo scenario, i servizi preconfigurati (Vision, traduzione) forniscono intelligenza immediata, mentre Azure ML consente di addestrare un modello di machine learning specifico sui dati dell’e-commerce per generare suggerimenti mirati.
· Esempio 2: Un ufficio tecnico che lavora con molti disegni o fotografie potrebbe dover catalogare immagini o individuare difetti in foto di componenti. In Azure, potrebbe utilizzare la funzionalità di Data Labeling di Azure ML per etichettare un insieme di immagini (ad esempio indicando per ciascuna se il pezzo è difettoso o meno), addestrare poi un modello di visione artificiale personalizzato (usando magari un algoritmo di classificazione fornito da Azure ML o un modello open-source) e infine pubblicare il modello come servizio tramite un endpoint gestito. Così, una volta in produzione, l’endpoint permetterebbe ad altre applicazioni interne di inviare immagini al modello e ricevere in risposta l’indicazione automatica di “pezzo difettoso” o “pezzo OK”.
Questi esempi mostrano come su Azure sia possibile mescolare approcci: usare API cognitive per funzionalità generali e rapid prototyping, e allo stesso tempo sviluppare modelli avanzati su misura con Azure ML quando serve affrontare problemi specifici con i propri dati.
Categorie di soluzioni AI su Azure
In generale, le soluzioni di intelligenza artificiale su Azure possono essere raggruppate in alcune categorie di workload tipiche, a seconda di come vengono realizzate e utilizzate:
· Machine Learning personalizzato: soluzioni in cui addestri e distribuisci i tuoi modelli usando i dati a disposizione della tua organizzazione. Questo avviene tipicamente tramite Azure Machine Learning, che fornisce l’infrastruttura per esperimenti, training su larga scala e deployment di modelli personalizzati.
· AI predefinita (Cognitive Services): soluzioni che sfruttano modelli pre-addestrati di Azure, esposti come API. Qui rientrano le funzionalità di Vision, Speech, Language, Decision e altri servizi cognitivi. In questo caso non addestri un modello tuo, ma utilizzi direttamente le capacità di AI offerte da Azure (ad esempio per riconoscere volti in una foto, estrarre il testo da un documento, tradurre una frase, ecc.). Il vantaggio è un time-to-market rapido e la necessità di pochissime competenze di machine learning, dato che il modello “sottostante” è gestito da Microsoft.
· AI generativa: soluzioni che coinvolgono modelli di grandi dimensioni (LLM – Large Language Models, o altre reti neurali generative) per produrre testi, immagini, codice e altro contenuto o per comprendere il linguaggio naturale a un alto livello. Su Azure questo è reso possibile tramite Azure OpenAI Service (che offre accesso a modelli come GPT-3, GPT-4, Codex, DALL-E, ecc.) e Microsoft Foundry (che integra non solo i modelli OpenAI ma anche molti altri modelli avanzati, consentendo di orchestrare agenti e flussi di conversazione più complessi). Queste soluzioni spesso prevedono di personalizzare l’output dei modelli generativi integrandoli con informazioni provenienti dai propri dati aziendali (vedremo più avanti la tecnica del Retrieval-Augmented Generation per fare domande ai modelli sui dati aziendali).
· Servizi verticali specializzati: Azure offre anche servizi AI pensati per domini specifici. Un esempio è Azure Video Indexer, un servizio specializzato per analizzare contenuti video estraendo automaticamente metadati utili (facce riconosciute, trascrizioni di dialoghi, rilevamento di scene e oggetti, ecc.). Questi servizi verticali combinano spesso più tecniche di AI (audio, visione, linguaggio) per fornire soluzioni chiavi in mano in ambiti particolari (media, finanziario, sanitario, ecc.).
In questa guida, esploreremo tutti questi aspetti – dai concetti di base di IA e ML, ai servizi concreti offerti da Azure, fino alle buone pratiche e alle risorse per imparare e certificarsi – in modo strutturato e con un taglio didattico adatto a studenti e principianti. Cominciamo chiarendo alcuni concetti fondamentali e la terminologia di base.
Inquadramento argomenti del capitolo con slides illustrate
Nel mondo Azure, intelligenza artificiale e machine learning includono sia servizi preconfigurati – come API pronte per visione, linguaggio, parlato e decisione – sia piattaforme di sviluppo per addestrare e distribuire modelli su larga scala. Il cuore del ciclo di vita del machine learning è Azure Machine Learning, che supporta i team dalla preparazione dei dati fino alla messa in produzione, con governance e sicurezza integrate. Si possono usare modelli open-source come PyTorch, TensorFlow e scikit-learn, oppure foundation models dal Model catalog, orchestrando flussi prompt-based e agentici. Per app che richiedono funzionalità cognitive pronte, Azure AI services offrono API per vedere, ascoltare, parlare e comprendere. Infine, Microsoft Foundry semplifica lo sviluppo di agenti, l’integrazione di modelli multi-fornitore e i controlli di Responsible AI. Ad esempio, un sito e-commerce può usare Azure AI services per image captioning e traduzione automatica, e Azure ML per raccomandazioni basate sui dati di acquisto. Un ufficio tecnico può etichettare immagini con Data labeling, addestrare un classificatore visivo e pubblicare l’endpoint in produzione con managed endpoints. Nel ciclo ML, i dati vengono preparati, usati per il training, valutati, distribuiti e monitorati, con servizi Azure dedicati a ogni fase.
L’intelligenza artificiale crea sistemi capaci di eseguire compiti complessi, mentre il machine learning è una sotto-classe che apprende dai dati. Su Azure, puoi creare modelli con Azure ML sfruttando AutoML, notebook condivisi e pipeline riutilizzabili, oppure utilizzare API pronte di Azure AI services per Vision, Speech, Language e Document Intelligence. Queste capacità si integrano facilmente in applicazioni e flussi come App Service, Functions e Logic Apps. I tipi principali di machine learning sono: supervisionato, non supervisionato e apprendimento profondo. Per esempio, nella classificazione di ticket IT, si parte da un dataset etichettato, si usa AutoML e si distribuisce l’API integrata con Logic Apps per automatizzare l’assegnazione. Il supporto chat può combinare servizi di Language e Speech per rilevare intent e generare parlato, ospitato su App Service. AutoML esplora automaticamente algoritmi e iperparametri, mentre un endpoint gestito consente di distribuire modelli con osservabilità e rollout sicuri. Una tabella può aiutare a confrontare i tipi di machine learning supervisionato, non supervisionato e profondo, associando esempi e servizi Azure pertinenti.
I workload nell’intelligenza artificiale su Azure si dividono in: machine learning personalizzato, dove addestri e distribuisci i tuoi modelli in Azure ML; AI predefinita, che sfrutta API di Azure AI services per vision, speech, language e decision; Generative AI, con modelli di grandi dimensioni tramite Foundry o Azure OpenAI; e servizi verticali come Video Indexer, utile per estrarre metadati da video. L’Architecture Center aiuta a scegliere tra piattaforme gestite come Azure ML, API cognitive, ambienti Spark come Databricks e funzionalità in SQL o Synapse. Per esempio, Custom Vision può essere usato per riconoscere difetti di produzione, con pipeline di retraining pianificato in Azure ML. OpenAI e Foundry consentono domande e risposte su documenti aziendali, integrando Azure AI Search. Il metodo RAG, ovvero Retrieval-Augmented Generation, arricchisce i modelli generativi con documenti indicizzati per risposte pertinenti. Una mappa visiva collega i workload ai servizi: ML con Azure ML, Generative con Foundry/OpenAI, API per Vision/Speech/Language e Media tramite Video Indexer.
Azure Machine Learning è un servizio di livello enterprise che accelera l’intero ciclo ML: dalla fase di sviluppo con notebook condivisi, datasets, environments riproducibili e integrazione Spark/Fabric, al training con compute cluster CPU/GPU, distributed training, AutoML e prompt flow per modelli linguistici. MLOps include tracciamento, model registry, managed endpoints, rollback sicuri e monitoraggio con metriche e alert. Responsible AI offre dashboard di equità, spiegabilità e analisi errori per ridurre bias e aumentare trasparenza. La documentazione ufficiale spiega chi usa Azure ML, come orchestrare ML e LLM e quali garanzie di sicurezza e compliance sono incluse. Ad esempio, è possibile addestrare un modello di previsione vendite con AutoML e distribuirlo come online endpoint, oltre a creare pipeline di retraining mensile. Un managed endpoint offre hosting gestito con telemetria, traffic splitting e rollout graduale. Prompt flow supporta progettazione, valutazione e deployment di flussi LLM all’interno di Azure ML. Un diagramma mostra il ciclo MLOps con blocchi experiment, train, register, deploy e monitor, associati alle icone di Azure ML.
Gli Azure AI services forniscono funzionalità pronte all’uso tramite REST e SDK: Vision per OCR, analisi immagini e face detection; Speech per riconoscimento e sintesi vocale e traduzione; Language per analisi testi, estrazione entità e riassunti; Document Intelligence per estrazione da fatture e moduli; Personalizer e Anomaly Detector per decisioni. Questi servizi riducono il time-to-market senza la necessità di costruire modelli da zero. Con i Foundry Tools, le stesse capacità sono disponibili come strumenti integrabili in agenti. Ad esempio, un portale documentale può sfruttare Document Intelligence per estrarre campi, Language per riassunti e classificazione, e archiviare i dati in SQL. L’SDK sono librerie client in Python, .NET, JavaScript e Java che semplificano la chiamata alle API. Una tabella riassume le capacità e gli usi tipici dei servizi Vision, Speech, Language, Document Intelligence e Decision.
Microsoft Foundry è il portale unificato per modelli, agenti e strumenti. Offre un Model catalog ricco, che include modelli di Microsoft, OpenAI, Meta, Hugging Face, Cohere e DeepSeek, con valutazioni, fine-tuning, deployment e osservabilità. Integra Agent Service per creare agenti con strumenti e workflow, e consente RBAC e policy unificate, con endpoint compatibili OpenAI v1 o REST Foundry. Le guide spiegano architettura, risorse e quickstart per creare progetti e testare modelli o agenti nei playground. Ad esempio, puoi valutare gpt‑4o su dati di FAQ e distribuire un agente con strumenti di ricerca e functions per eseguire task. Un agent è un componente che usa LLM, strumenti e memoria per completare compiti multi-step. Un diagramma mostra il flusso da App ad Agent, Tools e Data, con frecce di chiamata verso endpoint Foundry.
Microsoft definisce Responsible AI secondo sei principi: equità, affidabilità e sicurezza, privacy e sicurezza, inclusività, trasparenza e accountability. In Azure ML esistono strumenti per valutare fairness, spiegabilità e analisi degli errori; in Foundry sono disponibili controlli di Content Safety, tracciamento, valutazioni e integrazioni con Defender for Cloud per rischi e alert. Le linee guida operative seguono le fasi Identify, Measure, Mitigate e Operate, applicabili sia ai modelli generativi sia agli agenti. Ad esempio, si può valutare la disparità con un dashboard di fairness su un modello di rischio credito, applicando mitigazioni come rebalancing e threshold tuning. Content Safety offre filtri e guardrail per ridurre contenuti dannosi. Un’infografica mostra i sei principi e il flusso Identify, Measure, Mitigate, Operate.
Le soluzioni AI su Azure sono estendibili e si collegano facilmente a molte risorse cloud. Puoi esporre modelli tramite API Management, reagire a eventi con Event Grid e Functions, orchestrare flussi con Logic Apps, archiviare dati e embedding in SQL, Cosmos DB o Storage, proteggere segreti in Key Vault e isolare la rete con Virtual Network e Private Endpoints. Le guide ufficiali illustrano i pattern per app moderne, come chatbot e RAG in App Service, agenti e MCP, e workflow AI in Logic Apps. Un esempio pratico è la soluzione RAG: upload su Storage, indicizzazione in AI Search, orchestrazione con Functions, API gateway in APIM e segreti gestiti in Key Vault. MCP, Model Context Protocol, è lo standard per descrivere strumenti e azioni che agenti possono invocare. Un diagramma event-driven mostra il percorso dall’utente al frontend, APIM, agent o functions, data stores e Event Grid.
Gli ambienti e strumenti per sviluppatori su Azure includono Azure Machine Learning, Azure AI Studio e Data Science Virtual Machine. Azure ML offre una piattaforma end-to-end per training, deploy e MLOps con sicurezza e governance. AI Studio e Foundry supportano lo sviluppo di app generative e agenti, l’integrazione di modelli e la valutazione, aiutando a scegliere lo strumento adatto rispetto ad Azure ML. DSVM sono immagini VM pre-configurate, disponibili su Windows o Ubuntu, con strumenti data-science come Jupyter, VS Code e librerie deep learning, utili per sperimentazioni rapide o formazione. Ad esempio, un laboratorio didattico può partire da una DSVM Ubuntu con GPU per workshop di computer vision, portando successivamente il progetto in Azure ML per MLOps. Un compute instance è una VM gestita di Azure ML per notebook collaborativi con SSO. Una tabella confronta i pro e contro tra ML Studio, Foundry/AI Studio e DSVM per diversi scenari.
La certificazione Microsoft Certified: Azure AI Fundamentals, AI‑900, attesta la conoscenza di concetti base di machine learning e intelligenza artificiale su Azure. È adatta sia a profili tecnici che non tecnici e prepara a ruoli come Azure AI Engineer o Data Scientist. Microsoft Learn offre percorsi di apprendimento, practice assessment, exam sandbox e materiali aggiornati. Sono disponibili corsi AI‑900T00 con esercitazioni guidate. Un piano di studio può includere il completamento del percorso Introduction to AI in Azure, la pratica con quiz di autovalutazione, la simulazione dell’esame con sandbox e l’applicazione dei concetti in un mini-progetto Foundry. Practice assessment sono quiz utili per individuare lacune e prepararsi al meglio all’esame. Una timeline mostra le tappe dalla preparazione al badge della certificazione: learning path, pratica, sandbox ed esame.
1. Concetti di IA e Machine Learning
Per iniziare, definiamo cosa si intende per Intelligenza Artificiale e per Machine Learning e perché questi termini spesso vanno a braccetto.
· Intelligenza Artificiale (IA): è il campo dell’informatica che studia come creare sistemi capaci di svolgere compiti che normalmente richiederebbero l’intelligenza umana. Si parla di compiti complessi come riconoscere elementi in un’immagine, comprendere il linguaggio naturale, prendere decisioni in base a dati, giocare a scacchi, guidare un veicolo, e così via. Un sistema di IA cerca quindi di imitare alcune capacità cognitive umane (visione, udito, apprendimento, ragionamento, ecc.) attraverso algoritmi e software.
· Machine Learning (ML): è una sotto-disciplina dell’IA. Invece di programmare esplicitamente tutte le regole per svolgere un compito, nel ML si realizza un sistema che impara dai dati. In pratica, al modello di machine learning si forniscono molti esempi (dati storici, dataset etichettati, ecc.) e attraverso algoritmi matematici il modello “apprende” le caratteristiche e le relazioni presenti nei dati, in modo da poter poi effettuare previsioni o decisioni su nuovi dati. Il ML è diventato il metodo dominante per realizzare sistemi di IA avanzati, perché consente di sfruttare la grande quantità di dati oggi disponibile per addestrare modelli capaci di svolgere compiti complessi senza doverle codificare manualmente.
In altre parole, l’IA è l’obiettivo (far svolgere compiti intelligenti a una macchina), mentre il ML è uno dei mezzi principali per raggiungere quell’obiettivo (imparando dai dati). Non tutta l’IA è machine learning (ci sono tecniche IA basate su regole statiche, algoritmi di ricerca, ecc.), ma quasi tutte le applicazioni avanzate di IA moderna – dal riconoscimento vocale ai veicoli autonomi – fanno pesante affidamento sul machine learning.
Su Azure le due strade per creare applicazioni intelligenti sono:
· sviluppare modelli personalizzati con i propri algoritmi e dati (ML personalizzato),
· oppure utilizzare servizi di IA pre-addestrati forniti da Azure.
Entrambi gli approcci possono coesistere e integrarsi. Ad esempio, potresti usare un servizio pre-addestrato per analizzare del testo e classificare la sua lingua, e poi passare l’output a un tuo modello ML che fa ulteriori analisi specifiche per il tuo dominio.
Un vantaggio della piattaforma Azure è che i modelli e i servizi di IA si integrano facilmente con le altre piattaforme applicative Azure. Ad esempio, puoi ospitare un modello o un servizio di intelligenza artificiale su App Service (un servizio per eseguire applicazioni web/API), oppure chiamare una pipeline di machine learning all’interno di un flusso Azure Functions o Logic Apps (per scatenare azioni di business in risposta a determinati eventi). Questa interoperabilità consente di includere l’AI come componente di più ampie architetture cloud.
Prima di addentrarci nei servizi specifici, è importante conoscere i principali tipi di apprendimento automatico che potresti incontrare o voler implementare. In generale distinguiamo tre categorie fondamentali di machine learning: apprendimento supervisionato, apprendimento non supervisionato e apprendimento profondo (deep learning). Nel prossimo capitolo li esamineremo in dettaglio, con esempi pratici e come queste categorie si riflettono nei servizi Azure.
2. Tipi di Apprendimento Automatico
Nel machine learning, i problemi e le tecniche si suddividono tipicamente in alcune categorie a seconda del tipo di apprendimento coinvolto e della natura dei dati a disposizione. Ecco i tre tipi principali:
· Apprendimento Supervisionato: In questa modalità il modello impara da esempi etichettati. Significa che per ogni dato di input nel set di addestramento, forniamo al modello anche il “risultato corretto” atteso (etichetta). Il modello quindi può aggiustare i propri parametri cercando di riprodurre quei risultati. Questa è la situazione di problemi come la classificazione (ad esempio riconoscere se un’email è spam o no: forniamo molte email già etichettate “spam”/“ham” e il modello impara a distinguere) o la regressione (ad esempio prevedere un valore numerico come il prezzo di una casa data metratura, posizione, ecc.: il modello impara dai dati di case già vendute con relativo prezzo). L’apprendimento supervisionato è molto diffuso perché in molti casi nell’industria si dispone di insiemi di dati storici già classificati o valutati da esseri umani.
· Apprendimento Non Supervisionato: Qui il modello cerca di trovare pattern nei dati non etichettati, ossia senza sapere a priori quale sia il risultato giusto. Un tipico esempio è il clustering, dove l’algoritmo divide i dati in gruppi in base a similarità emergenti (ad esempio segmentare i clienti di un negozio in gruppi con abitudini di acquisto simili, senza avere categorie predefinite). Un altro esempio è il rilevamento di anomalie, dove il modello impara il “comportamento tipico” dei dati e individua punti dati che differiscono significativamente (utile per individuare transazioni fraudolente, guasti da segnali di sensori IoT, ecc.). L’apprendimento non supervisionato è utile quando non si hanno etichette o valutazioni umane, ma si vuole comunque estrarre informazione dai dati (pattern nascosti, correlazioni, outlier).
· Apprendimento Profondo (Deep Learning): Questo non è un tipo diverso basato sulle etichette, ma è una categoria trasversale che indica l’uso di reti neurali artificiali con molteplici strati (da cui “profondo”). Il deep learning ha ottenuto risultati straordinari ed è alla base di molti progressi recenti dell’IA, specialmente in campi come visione artificiale e elaborazione del linguaggio naturale. Si può fare deep learning in maniera supervisionata (es. addestrare una rete neurale convoluzionale su immagini etichettate per riconoscere oggetti) o non supervisionata (es. reti neurali che imparano a comprimere dati, come negli autoencoder, o modelli generativi non supervisionati). Data la sua importanza, spesso lo si menziona separatamente: tipicamente con deep learning si riescono ad affrontare problemi complessi (riconoscimento facciale, traduzione automatica, guida autonoma, chatbots avanzati) a patto di avere grandi moli di dati e potenza computazionale (spesso GPU) per l’addestramento. In Azure, molti servizi cognitivi preconfigurati internamente utilizzano algoritmi di deep learning, mentre il servizio Azure ML consente ai data scientist di progettare e addestrare proprie reti neurali profonde usando framework come TensorFlow o PyTorch.
Riassumiamo questi concetti chiave in una tabella, associando a ciascun tipo di apprendimento alcuni esempi pratici e come Azure supporta quello scenario:
Tipo di ML
Descrizione
Esempio pratico
Servizi Azure correlati
Supervisionato
Il modello impara da esempi con etichetta nota (input -> output atteso). Adatto per compiti di classificazione e regressione.
Classificare automaticamente i ticket IT di assistenza in categorie (“software”, “hardware”, “permessi”) in base alla descrizione, dopo aver addestrato il modello con molti ticket già categorizzati.
Azure ML (esperimenti di training, AutoML per classificazione/regressione), Azure Custom Vision (per classificazione di immagini con etichette), integrazione con Logic Apps o Functions per automatizzare azioni in base alle previsioni.
Non supervisionato
Il modello trova pattern da dati non etichettati, scoprendo strutture nascoste. Usato per clustering, riduzione dimensionalità, anomaly detection.
Analizzare i dati di navigazione di un sito web per individuare segmenti di utenti con comportamenti simili, senza categorie predefinite (il modello potrebbe scoprire cluster di utenti “curiosi”, “acquirenti frequenti”, “visitatori occasionali”).
Azure ML (algoritmi di clustering, ad es. K-Means, in notebook o pipeline), Azure Synapse/Spark (per analisi big data non supervisionate), Azure Anomaly Detector (API pre-addestrata per rilevare anomalie in serie temporali senza fornire esempi di anomalia).
Apprendimento Profondo
Modelli basati su reti neurali multi-strato complesse. Richiede molti dati e risorse computazionali; può essere supervisionato o no. Ottimo per riconoscimento immagini, voce, NLP, generative AI.
Riconoscere elementi in immagini complesse, ad esempio costruire un modello che analizza radiografie mediche per individuare segni di una malattia. Il modello è una rete neurale addestrata su migliaia di immagini etichettate da radiologi.
Azure ML (per addestrare modelli deep learning su cluster GPU, gestione esperimenti), Azure OpenAI Service (per usare direttamente modelli deep pre-addestrati come GPT-4, DALL-E), Azure Cognitive Services come Vision, Speech, Language (forniscono funzionalità basate su modelli deep senza doverli addestrare manualmente).
Come si può notare, Azure fornisce supporto per tutte queste categorie. Ad esempio, per un problema di classificazione (supervisionato) come l’assegnazione automatica di ticket IT:
· si può utilizzare Azure Machine Learning con la funzionalità di AutoML per generare e provare automaticamente molti modelli di classificazione sul dataset etichettato di ticket storici;
· una volta individuato il modello migliore, lo si distribuisce come servizio API;
· poi lo si integra in un flusso, ad esempio con Azure Logic Apps, in modo che ogni nuovo ticket in arrivo venga inviato al modello e, in base alla categoria predetta, la Logic App assegni automaticamente il ticket al team corrispondente (es. ticket di tipo “hardware” -> team IT Hardware).
Un altro esempio, per capire l’integrazione fra servizi, potrebbe riguardare un sistema di supporto clienti intelligente: immagina di voler realizzare un chatbot o un assistente virtuale che smisti le richieste dei clienti e fornisca informazioni vocali. Potresti combinare diversi servizi:
· usare un modello di Language Understanding (servizio Language di Azure) per analizzare il testo delle richieste e identificare l’intento dell’utente (ad es. “segnalare un guasto” vs “richiedere informazioni commerciali”);
· usare un servizio di Speech per convertire in automatico la risposta testuale del bot in voce sintetica da restituire al cliente al telefono;
· il tutto orchestrato su un’applicazione web o un servizio Azure App Service, dove risiede la logica del bot.
Si vede quindi che, grazie ai vari servizi Azure, un progetto AI può spaziare da modelli personalizzati addestrati sui propri dati (richiedendo quindi competenze di ML e data science) fino a soluzioni montate velocemente componendo servizi cognitivi già pronti. Nel prossimo capitolo, approfondiremo come, indipendentemente dal tipo di apprendimento utilizzato, un progetto di machine learning segue un insieme di fasi ben precise, e come queste fasi possano essere gestite con strumenti Azure.
3. Architettura del Ciclo di Vita del ML
Un progetto di machine learning tipico segue un flusso di lavoro (pipeline) costituito da varie fasi sequenziali, che insieme costituiscono il ciclo di vita di un modello ML. Capire quest’architettura di riferimento è fondamentale, perché permette di inquadrare dove e come utilizzare gli strumenti giusti durante lo sviluppo di soluzioni di AI.
Ecco le principali fasi del ciclo di vita di un progetto ML e cosa avviene in ciascuna di esse:
· Raccolta e Preparazione dei Dati: Questa fase iniziale consiste nel raccogliere i dati grezzi da varie fonti (database, file, sensori, ecc.) e prepararli per l’uso nel machine learning. La preparazione include operazioni come pulizia (rimuovere o correggere dati errati o mancanti), trasformazione (normalizzare valori, creare feature aggiuntive, codificare categorie testuali in numeri), ed eventualmente annotazione/etichettatura (se serve creare un dataset supervisionato aggiungendo etichette manualmente). In Azure, i dati possono risiedere in servizi come Azure Storage, Azure SQL Database, Azure Data Lake, ecc., e per la preparazione si possono usare strumenti come Azure Data Factory o Azure Databricks/Synapse per pipeline di data engineering. Anche Azure ML fornisce componenti di data prep (ad esempio dataset registrati e funzionalità di data labeling come visto nell’esempio precedente).
· Addestramento (Training) del Modello: In questa fase si utilizza il dataset preparato per addestrare uno o più modelli di machine learning. L’addestramento implica fornire i dati al modello (che può essere un algoritmo di rete neurale, una foresta casuale, un modello lineare, ecc.) e ottimizzare i parametri interni del modello affinché esso “impari” a fare bene il compito desiderato (prevedere l’etichetta, raggruppare dati, ecc.). Su Azure ML questa fase viene gestita come Esperimento: si definisce uno script di training (in Python, R o usando designer visuale), si esegue su risorse di calcolo (ad es. cluster CPU/GPU) e Azure ML tiene traccia delle metriche di performance ottenute (accuratezza, errore, ecc.). Azure ML supporta anche l’AutoML, che automatizza il processo di provare diversi algoritmi e configurazioni, e il distributed training per gestire dataset molto grandi o modelli molto complessi su più macchine in parallelo.
· Valutazione e Validazione: Dopo (o durante) l’addestramento, occorre valutare le prestazioni del modello su dati che non ha mai visto (dati di test o di validazione). Questo per assicurarsi che il modello funzioni bene non solo sul training set ma in generale su dati nuovi. Si calcolano metriche (es. accuratezza, precision/recall, MSE, a seconda del problema) e si verifica se il modello soddisfa i requisiti. È anche il momento di eseguire analisi di spiegabilità (per capire come il modello sta prendendo decisioni) e di fairness (per vedere se ci sono bias verso certi sottogruppi nei dati). Azure ML fornisce strumenti come Dashboard di spiegabilità (basato ad es. su SHAP) e di equità (Fairness) per aiutare in questa fase. Se il modello non è adeguato, si può tornare indietro: aggiustare i dati, cambiare algoritmo o iperparametri, e riaddestrare (ecco perché è un ciclo iterativo).
· Distribuzione in Produzione (Deployment): Una volta soddisfatti dei risultati, il modello viene distribuito affinché possa essere usato nelle applicazioni reali. “Distribuire” un modello in Azure di solito significa creare un endpoint di inferenza: essenzialmente un servizio web (HTTP API) che incapsula il modello. In Azure ML esiste la funzione di Managed Endpoint (endpoint gestito) che permette con pochi click o righe di codice di prendere un modello registrato e renderlo disponibile come servizio scalabile, con Azure che gestisce per noi l’infrastruttura (container, CPU/GPU, autoscaling, ecc.). In alternativa, si possono esportare i modelli e usarli in contesti diversi (ad esempio in un’app mobile, in un IoT Edge device, ecc., ma nel nostro contesto Azure ci concentriamo su deployment cloud). Spesso insieme al modello si prepara anche un’API o integrazione: ad es. potremmo inserire l’endpoint del modello dietro a Azure API Management per gestire le chiamate in modo sicuro, oppure integrarlo in un bot, in una web app, ecc.
· Monitoraggio e Manutenzione: Dopo il deployment, il lavoro non è finito. Un modello in produzione va monitorato per assicurarsi che continui a funzionare bene nel tempo. Si raccolgono dati sulle richieste reali e sulle risposte fornite, tenendo d’occhio metriche come latenza, throughput, tasso di errore, e anche la qualità delle predizioni (se abbiamo modo di verificarla). Inoltre, i dati in input potrebbero cambiare nel tempo (fenomeno del data drift) e quindi le prestazioni del modello potrebbero degradare. È buona pratica impostare un processo di manutenzione: per esempio, pianificare un ri-addestramento periodico del modello con dati più recenti (Azure ML consente di creare pipeline automatiche che magari ogni mese ritrainano il modello e se la nuova versione supera certi criteri di qualità, la sostituiscono in produzione). Il monitoraggio comprende anche aspetti di logging e alerting (Azure ML può integrare metriche in Azure Application Insights o mandare allarmi se qualcosa va fuori range) e di governance (tenere traccia delle versioni del modello, di chi l’ha approvato per la produzione, ecc., per compliance).
Questo ciclo di vita, spesso chiamato MLOps (Machine Learning Operations), è in parte ispirato alle pratiche DevOps ma adattato al mondo dei dati e dei modelli. Azure Machine Learning è stato progettato proprio per supportare l’intero ciclo MLOps. Nell’immagine concettuale spesso si vedono blocchi come Experiment -> Train -> Register -> Deploy -> Monitor, in un ciclo continuo.
Nel prossimo capitolo vedremo da vicino come Azure Machine Learning implementa e facilita ciascuna di queste fasi, offrendo un ambiente unificato ai data scientist e agli sviluppatori per portare i progetti di machine learning dal prototipo all’uso reale in modo efficiente.
4. Azure Machine Learning: Piattaforma per il Ciclo ML
Azure Machine Learning (Azure ML) è il servizio di Azure pensato per gestire in maniera unificata tutto il ciclo di vita dei progetti di machine learning, come abbiamo descritto sopra. Vediamo le sue caratteristiche salienti e come supporta le diverse fasi:
· Ambiente di Sviluppo Collaborativo: Azure ML fornisce uno workspace centralizzato dove i membri di un team possono lavorare insieme su progetti di ML. All’interno del workspace, è possibile creare e condividere notebook Jupyter (in un ambiente chiamato Azure ML Studio che gira nel browser), permettendo ai data scientist di scrivere codice Python/R per esplorare dati e sviluppare modelli direttamente sul cloud. Si possono registrare Dataset nel workspace, in modo che tutti utilizzino gli stessi dati preparati e versionati. Inoltre, Azure ML consente di definire Environment replicabili: essenzialmente specifiche di ambiente di runtime (sistemi operativi, pacchetti Python, librerie) per garantire che il codice del modello giri sempre in un contesto controllato. Questo risolve il classico “funziona sul mio computer ma non in produzione”, assicurando riproducibilità.
· Addestramento su Scala e Automatizzato: Per la fase di training, Azure ML offre Compute Cluster gestiti, che possono essere di CPU o GPU, su cui lanciare i propri esperimenti di addestramento. È possibile far partire un training distribuendolo su più macchine (utile per reti neurali grandi o grandissimi dataset). Inoltre, la funzionalità di AutoML permette di automatizzare la selezione del modello migliore: tu fornisci i dati e il tipo di problema (es. classificazione multiclasse) e Azure ML proverà numerose combinazioni di algoritmi e configurazioni per trovare quella con prestazioni migliori, restituendoti il modello ottimale. Una novità recente è Prompt Flow, uno strumento integrato in Azure ML per progettare, testare e far girare flussi basati su modelli linguistici (LLM). Questo è particolarmente utile per scenari di AI generativa: ad esempio, potresti voler creare una pipeline che prende un prompt dell’utente, esegue una chiamata a GPT-4, poi passa la risposta attraverso un altro modello o un post-processore, ecc. Prompt Flow ti permette di orchestrare queste operazioni e valutare i risultati, all’interno dello stesso ambiente Azure ML.
· MLOps, Deployment e Gestione dei Modelli: Azure ML include di default pratiche di MLOps. Ogni esecuzione di training (chiamata Run) viene tracciata con le sue metriche e output; puoi registrare un modello salvando nel workspace una versione del modello addestrato (ad esempio “Modello X versione 1.0”). C’è un Model Registry centralizzato dove compaiono tutti i modelli registrati, con i relativi metadata (chi l’ha creato, quando, con che dati, con che metriche di validazione, ecc.). Quando si decide di portare un modello in produzione, Azure ML consente di creare Endpoint gestiti (Managed Endpoints): con pochi passi, scegli un modello dal registro e lo distribuisci come servizio web. L’infrastruttura sottostante è gestita da Azure: tu specifichi solo se ti serve CPU o GPU, quanti replica tenere, e Azure si occupa di creare i necessari container, bilanciare il carico, sostituire incrementalmente le nuove versioni (supporta ad esempio il rollout graduale: puoi distribuire la versione 2 del modello assegnandole inizialmente solo il 10% del traffico, mantenendo il 90% sulla versione 1; se tutto va bene, aumenti al 50%, poi 100%, minimizzando i rischi). Gli endpoint gestiti offrono anche monitoraggio integrato: si possono vedere le richieste effettuate, le latenze medie, eventuali errori, e integrare con sistemi di logging e monitoraggio di Azure.
· Responsible AI integrata: Azure ML ha diversi strumenti per aiutare a implementare pratiche di AI responsabile durante lo sviluppo. Ad esempio, fornisce la Fairness Assessment (un modulo che consente di caricare i dati di output del modello e analizzare se ci sono bias nei confronti di certi gruppi protetti), la Explainability (strumenti per interpretare e spiegare le decisioni del modello, come SHAP values o feature importance, in modo da capire su quali fattori il modello sta basando le sue previsioni) e l’Error Analysis (per vedere sistematicamente su quali dati il modello sbaglia di più e individuare pattern di errore). Questi strumenti aiutano il team a valutare e migliorare il modello non solo sulle metriche classiche, ma anche in termini di equità e trasparenza, seguendo i principi di AI responsabile.
In pratica, Azure Machine Learning punta a essere una soluzione end-to-end: dalla prototipazione iniziale in notebook fino alla gestione di modelli in produzione nel lungo periodo, tutto avviene nello stesso ecosistema. Un esempio di flusso con Azure ML potrebbe essere il seguente:
· Un data scientist prepara un modello di previsione delle vendite utilizzando AutoML su Azure ML, con i dati storici di vendita forniti dal team di business. Dopo qualche ora, Azure ML restituisce il modello migliore trovato (poniamo un modello di regressione basato su un ensemble di alberi decisionali) con un certo livello di accuratezza sulle vendite future.
· Il modello viene registrato e poi distribuito immediatamente come online endpoint per poter essere testato. L’endpoint viene invocato da un’app dashboard interna dove i manager possono inserire alcuni parametri (periodo, regione, tipo di prodotto) e ottenere la previsione di vendite dal modello.
· Si imposta una pipeline automatica in Azure ML che ogni mese riprende il modello, aggiunge i dati di vendita più recenti, ri-addestra il modello e, se le prestazioni migliorano, aggiorna l’endpoint in produzione alla nuova versione. Tutto questo con notifiche e approvazioni eventualmente integrate (ad esempio un membro senior del team deve approvare manualmente il passaggio in produzione della nuova versione se le metriche variano troppo).
· Grazie ai managed endpoints, il team ha anche la tranquillità di poter fare rollback rapido se qualcosa va storto: Azure ML mantiene infatti le vecchie versioni e con un click si potrebbe tornare alla versione precedente del modello se quella nuova desse problemi.
Con Azure ML, aziende di ogni settore accelerano lo sviluppo di soluzioni AI perchè gran parte dell’infrastruttura e della gestione operativa è gestita da Azure, permettendo ai team di concentrarsi sui modelli e i dati, cioè sul valore aggiunto specifico per il proprio scenario.
5. Servizi Cognitivi di Azure (Azure AI Services)
Passiamo ora all’altro grande filone dell’offerta AI di Azure: i servizi cognitivi noti come Azure AI Services. Questi sono servizi cloud pre-addestrati che offrono funzionalità di IA tramite semplici chiamate API o SDK, senza che l’utente debba sviluppare o addestrare alcun modello. Microsoft ha “impacchettato” diverse capacità di intelligenza artificiale in servizi dedicati, che coprono aree differenti. Vediamo le principali categorie di servizi cognitivi Azure e cosa offrono:
· Vision: Servizi per l’analisi di immagini e video. Le funzionalità includono riconoscimento di oggetti, classificazione di immagini, lettura di testo in immagini (OCR), riconoscimento volti con analisi di caratteristiche del volto (età stimata, emozioni di base), e descrizione automatica del contenuto visivo. Esempi di API Vision sono Computer Vision API, Custom Vision (per addestrare modelli di visione personalizzati con pochi clic), Face API, Form Recognizer (quest’ultimo in realtà è parte di Document Intelligence, vedi oltre, ma anch’esso tratta immagini di documenti). Un caso d’uso tipico: un’applicazione che deve catalogare foto potrebbe inviare ogni immagine a Computer Vision API e ottenere come risposta le etichette delle cose presenti (es. “outdoor, two people, smiling”) e usarle per taggare l’immagine nel database.
· Speech: Servizi legati all’audio e alla voce. Azure offre Speech to Text (riconoscimento vocale, converte l’audio in testo trascritto), Text to Speech (sintesi vocale, converte testo scritto in parlato con voce artificiale), Speech Translation (traduzione in tempo reale da una lingua parlata a un’altra, combinando STT e TTS), e anche servizi per creare un Voice Font personalizzato (cioè una voce sintetica addestrata su campioni di voce di una persona, utile ad esempio per automatizzare centralini mantenendo la “voce” dell’azienda). Un esempio pratico: un call center automatico può usare Speech to Text per trascrivere la richiesta dell’utente che parla al telefono, poi elaborare il testo (magari con i servizi Language, vedi sotto) e infine rispondere generando audio con Text to Speech.
· Language: Servizi che comprendono ed elaborano il linguaggio naturale (testo scritto o conversazione). Questi includono Language Understanding (LUIS) o il nuovo Conversation Language Understanding, per riconoscere intenzioni e estrarre entità da frasi; Text Analytics per analisi testuale come estrarre frasi chiave, riconoscere entità nominate (persone, organizzazioni, luoghi, ecc.), rilevare la sentiment (tono emotivo) di un testo, generare il riassunto automatico di un documento (summarization); Translator per tradurre testi da una lingua all’altra. Ad esempio, potresti analizzare automaticamente le recensioni testuali dei clienti: con Text Analytics ottenere per ogni recensione il punteggio di sentiment (positivo/negativo) e le key phrases menzionate (es. “spedizione lenta”, “ottimo servizio clienti”) per capire cosa va bene o male nel prodotto.
· Decision: Questa categoria comprende servizi orientati a supportare decisioni o analisi particolari. Due esempi: Personalizer, che è un servizio di reinforcement learning usato per fare raccomandazioni personalizzate in tempo reale (ad esempio scegliere quale contenuto mostrare a un utente su un sito in base a un contesto e a feedback impliciti); Anomaly Detector, un servizio che analizza serie temporali di dati e segnala automaticamente valori anomali e trend inconsueti (utile per monitoraggio di KPI, rilevamento guasti, sicurezza, ecc.). Questi servizi forniscono intelligenza “verticale” molto specifica: Personalizer evita di dover costruire da zero un motore di raccomandazione online, Anomaly Detector evita di implementare manualmente modelli statistici per trovare outlier nei dati.
· Document Intelligence: In passato noto come Form Recognizer, questo servizio combina visione e linguaggio per estrarre informazioni strutturate da documenti. Ad esempio, può prendere in input un documento PDF o un’immagine di una fattura, e restituire in modo strutturato i campi riconosciuti (intestazione, data, totale, voci di spesa, ecc.). Supporta modelli pre-addestrati per fatture, ricevute, ID, carte di identità, e modelli personalizzati dove puoi caricare qualche esempio dei tuoi moduli e insegnare al servizio a estrarre proprio i campi che ti servono. Questo è utilissimo per automatizzare la digitalizzazione di documenti cartacei o email e inserirli in database senza dover trascrivere a mano.
Tutti questi servizi sono fruibili in due modalità: tramite REST API (chiamate HTTP da qualsiasi linguaggio/piattaforma, passando ad esempio l’URL di un’immagine e ottenendo un JSON con il risultato) o tramite SDK ufficiali (librerie disponibili in Python, C#, Java, JavaScript, etc., che semplificano la chiamata hiding i dettagli REST). Il modello dietro è software-as-a-service: paghi in base al numero di chiamate o alla quantità di dati elaborati, e Microsoft si occupa di aggiornare e migliorare continuamente i modelli sottostanti.
Un vantaggio chiave dei servizi cognitivi è il time-to-market rapido: se oggi ho l’esigenza di tradurre testo in 5 lingue e di estrarre entità nomi di prodotti da delle descrizioni, posso farlo in poche ore integrando Translator e Text Analytics, senza dover raccogliere corpus di dati multilingua e addestrare modelli NLP complessi da zero. Certo, il rovescio della medaglia è che i modelli sono “generici”: non sono addestrati specificamente sui miei dati, quindi potrebbero non catturare perfettamente il mio dominio (ad esempio, un modello generale di estrazione entità potrebbe non riconoscere nomi di prodotti molto specifici della mia azienda). In questi casi, Azure spesso offre possibilità di customizzazione: ad esempio Custom Vision per addestrare un modello di visione con poche immagini, oppure la possibilità in Language di fornire elenchi di entità personalizzate.
Vediamo un esempio concreto di utilizzo combinato di servizi cognitivi in una soluzione:
Esempio pratico: Supponiamo di voler automatizzare l’elaborazione di documenti ricevuti da vari clienti, come moduli d’ordine e feedback testuali, per inserire i dati in un database e ottenere un breve riepilogo. Possiamo costruire un portale documentale intelligente che funziona così:
· L’utente carica un modulo (PDF o immagine) sul portale.
· Il sistema utilizza Azure Document Intelligence per analizzare il documento e estrarre i campi strutturati (ad es. numero ordine, nome cliente, elenco prodotti ordinati, importo totale).
· Dal modulo o da un eventuale testo libero allegato, possiamo usare Azure Language (funzione di sintesi o analisi del sentiment) per riassumere eventuali note testuali o capire l’opinione del cliente (ad esempio “il cliente ha richiesto consegna urgente e ha apprezzato il supporto ricevuto”).
· I dati estratti (campi dell’ordine e riassunto note) vengono poi salvati in un database, ad esempio Azure SQL.
· Tutto questo flusso potrebbe essere orchestrato con una Logic App: trigger sul nuovo file, chiamate ai servizi Document Intelligence e Language, branch logici a seconda dei risultati, quindi salvataggio nel DB o notifica a umani se qualcosa manca.
In questo scenario, grazie ai servizi cognitivi:
· L’estrazione dei dati dal documento è fatta in modo automatico (senza inserimento manuale).
· Il sistema capisce anche il testo libero e lo condensa.
· Il tempo di elaborazione passa da minuti (o ore) manuali a pochi secondi automatizzati.
Vale la pena notare che Microsoft Foundry (di cui parleremo nel prossimo capitolo) integra le stesse capacità dei servizi cognitivi sotto forma di Tools. In pratica, in Foundry quando si crea un agente AI, si possono inserire strumenti come “Vision_AnalyzeImage” o “Language_SummarizeText” che corrispondono dietro le quinte alle API cognitive di Azure. Questo significa che chi sviluppa agenti con Foundry può facilmente arricchirli con funzionalità cognitive senza dover richiamare separatamente le API, ma direttamente dall’ambiente unificato di Foundry.
Riassumendo, i Servizi Cognitivi di Azure rappresentano la via più rapida per infondere intelligenza nelle applicazioni: basta una chiamata API per avere a disposizione anni di ricerca Microsoft in visione, linguaggio, parlato e decision support. Nelle prossime sezioni vedremo come costruire soluzioni AI più complesse sfruttando anche i modelli di AI generativa e orchestrando più servizi insieme.
6. Azure OpenAI e Microsoft Foundry: Soluzioni di Generative AI
Negli ultimi anni ha preso enorme piede l’AI generativa, in particolare grazie all’evoluzione dei Large Language Models (LLM) e di altre architetture avanzate (come le reti generative avversarie, GAN, nel campo delle immagini). Azure si è posizionata come piattaforma di riferimento anche in questo ambito, soprattutto attraverso due offerte strettamente collegate:
Azure OpenAI Service è un servizio di Azure che fornisce accesso ai modelli generativi sviluppati da OpenAI, con tutti i vantaggi di sicurezza, scalabilità e integrazione Azure. Attraverso Azure OpenAI, gli sviluppatori possono utilizzare modelli come GPT-3.5, GPT-4 (per generazione e comprensione del linguaggio naturale), Codex (per generazione di codice a partire da linguaggio naturale) e DALL-E (per la generazione di immagini da descrizioni testuali). L’accesso è controllato (bisogna ottenere l’approvazione per usare il servizio, dati i possibili usi impropri), ma una volta abilitato, si possono chiamare i modelli via API REST o SDK, in modo simile ai servizi cognitivi. Ad esempio, con Azure OpenAI puoi inviare un prompt a GPT-4 e ottenere il completamento/testo generato in risposta, il tutto con la garanzia che l’inferenza avviene sui server Azure (importante per aspetti di compliance e privacy dei dati).
Microsoft Foundry è un portale e servizio unificato introdotto per ampliare l’offerta di Azure OpenAI e integrarla con altre funzionalità. Possiamo considerarlo come un hub per soluzioni AI avanzate. Le sue componenti principali sono:
· Un ricco Model Catalog: dentro Foundry trovi non solo i modelli OpenAI (GPT, DALL-E, ecc.), ma anche molti altri modelli di diversi provider: ad esempio modelli di Meta AI, modelli open-source di Hugging Face o di startup AI emergenti, modelli come Cohere per NLP, DeepSeek ecc. Ogni modello è accompagnato da informazioni, valutazioni, possibilità di fine-tuning (laddove supportato), deployment e monitoraggio. In pratica, Foundry mira a fornire un catalogo centralizzato dove scegliere il modello più adatto alle proprie esigenze, indipendentemente dal fornitore.
· Agent Service: Foundry consente di creare Agenti AI, ossia entità software che combinano un modello (tipicamente un LLM) con una serie di tools e una memoria per poter svolgere compiti complessi suddividendoli in più passaggi. Un agent è quello che in altri contesti potremmo chiamare un bot intelligente, con la differenza che qui l’enfasi è sull’uso di un modello generativo come “cervello” dell’agente. Ad esempio, un agente potrebbe essere progettato per rispondere alle domande dei dipendenti su documenti interni: verrà costruito con un modello linguistico (es. GPT-4) e uno strumento di ricerca nei documenti aziendali (es. usando Azure Cognitive Search), così che quando l’agente riceve una domanda, possa sia ragionare con la propria capacità linguistica sia agiré chiamando lo strumento di ricerca per trovare informazioni pertinenti, e infine restituire una risposta accurata all’utente. Foundry fornisce l’infrastruttura per definire questi agenti, collegare strumenti (ad es. i servizi cognitivi di cui sopra diventano strumenti riutilizzabili dentro l’agente, così come funzioni custom sviluppate dallo user), e gestire conversazioni multi-turno e catene di chiamate.
· Endpoint unificati e gestione: Qualunque modello o agente si crei in Foundry, può essere pubblicato come endpoint API. Foundry supporta sia endpoint compatibili con l’API di OpenAI (utile perché molti software già supportano direttamente la API OpenAI, quindi passando per Foundry puoi spacciarti per un endpoint OpenAI standard) sia endpoint REST personalizzati. Inoltre, Foundry integra la gestione sicura con RBAC (Role-Based Access Control) e policy aziendali unificate: ciò significa che l’accesso ai vari modelli può essere regolato da permessi granulari (es. solo il team X può usare il modello GPT-4 aziendale) e che si possono applicare politiche di contenuto (es. filtri di sicurezza per evitare certi output). Foundry offre anche strumenti di osservabilità: logging dettagliato delle richieste fatte al modello, statistiche d’uso, monitoraggio dei costi, ecc., fondamentali quando in un’azienda si inizia a usare intensivamente modelli generativi.
· Guide, risorse e interfacce user-friendly: All’interno dell’interfaccia di Foundry trovi guide e quickstart che spiegano come creare il tuo primo progetto, come fare fine-tuning di un modello (laddove possibile, ad esempio per alcuni modelli open source), come collegare un nuovo strumento personalizzato al tuo agente, ecc. Ci sono anche playground interattivi per provare i modelli con prompt direttamente dal browser, e workflow visivi per definire le catene di azioni di un agente.
In sintesi, quando usare Azure OpenAI vs Foundry? Azure OpenAI va benissimo se vuoi semplicemente integrare un modello OpenAI nella tua applicazione (es. chiami GPT-4 per generare del testo, fine). Foundry diventa prezioso se:
· vuoi avere accesso a un insieme più ampio di modelli (non solo OpenAI ma anche altri),
· vuoi combinare più modelli o strumenti in qualcosa di più complesso (un agente),
· vuoi un controllo centralizzato e sofisticato su come i modelli sono usati nell’organizzazione (monitoraggio, policy, ecc.).
Vediamo un paio di esempi pratici legati a Foundry e all’AI generativa su Azure:
· Esempio 1: Un team di supporto clienti vuole creare un assistente AI che aiuti a rispondere alle domande frequenti dei clienti. Utilizzando Foundry, potrebbero partire da un modello linguistico potente (diciamo GPT-4 o un modello open-source similare) e specializzarlo caricando i documenti FAQ aziendali. Impostano un agente dotato di un tool di ricerca sui documenti (magari integrando Azure Cognitive Search come strumento per il retrieval dei documenti rilevanti). Quando l’agente riceve una domanda, può cercare nelle FAQ pertinenti e poi formulare una risposta citando le informazioni trovate. Il team può testare questo agente nel playground di Foundry, valutare le risposte, apportare correzioni (ad esempio aggiungendo prompt specifici o ulteriori fonti di conoscenza) e infine distribuirlo come endpoint API. A questo punto possono integrare l’agente in un chatbot sul sito web: ogni volta che un utente chiede qualcosa, la domanda viene inviata all’endpoint Foundry, l’agente la processa e restituisce la risposta pronta da mostrare all’utente – il tutto in pochi secondi e in linguaggio naturale.
· Esempio 2: Un’azienda vuole sfruttare l’AI generativa per automatizzare compiti multi-step. Ad esempio, un agente che riceve una mail, capisce se è un ordine, se sì estrae i dettagli (usando un tool di Document Intelligence magari), verifica in un database la disponibilità (usando un tool che chiama un’API interna), e infine risponde generando una email di conferma. Questo è un flusso complesso che combina NLP, integrazione di dati e generazione di testo. Con Foundry, il team può creare un agente definendo una catena di azioni: action 1: capire l’intento e il tipo di documento, action 2: se ordine, usare Document Intelligence per prendere i dati, action 3: usare un’API per controllare scorte, action 4: formulare la risposta con il modello generativo integrando i risultati. L’agente può usare memoria per mantenere i dati estratti tra un passo e l’altro. Una volta testato, l’agente viene messo su un endpoint e legato al sistema di gestione email dell’azienda. Questo è un esempio altamente personalizzato: costruito su misura con Foundry combinando modelli e strumenti.
Un concetto importante emerso recentemente nel contesto di queste soluzioni generative è il RAG (Retrieval-Augmented Generation). Ne abbiamo di fatto descritto il principio nell’esempio: significa arricchire il processo generativo di un LLM con un passo di retrieval di conoscenza da fonti specifiche. In pratica:
1. Si prende la domanda dell’utente (o altra esigenza di generazione).
2. Si fa una ricerca in una base di conoscenza (documenti, database) per estrarre le informazioni più pertinenti.
3. Si forniscono sia la domanda sia le informazioni estratte al modello generativo.
4. Il modello compone la risposta usando anche le informazioni fornite, garantendo così che la risposta sia rilevante e ancorata a una fonte verificabile.
Azure supporta benissimo questo pattern con servizi come Azure Cognitive Search (per indicizzare documenti e recuperarli via query) combinati con Azure OpenAI/Foundry per la parte generativa. Questo consente di costruire sistemi di Q&A su documenti aziendali, chatbot che sanno accedere a knowledge base, e in generale riduce l’allucinazione dei modelli generativi (il rischio che inventino informazioni) perché li si costringe a basarsi su dati di riferimento.
Infine, è utile sapere che Foundry e Azure OpenAI continuano ad evolvere: Microsoft sta unificando l’esperienza in un Azure AI Studio, di cui Foundry è parte, dove scegliere modelli, effettuare prompt engineering, valutare la content safety, il tutto in un unico posto. Comunque, concettualmente, la combinazione di grandi modelli pre-addestrati + infrastruttura cloud per personalizzarli e integrarli è ciò che abilita oggi scenari di AI prima impensabili. Azure mette queste capacità nelle mani degli sviluppatori con strumenti di alto livello, minimizzando la necessità di competenze troppo specialistiche sull’addestramento di reti neurali gigantesche (cosa che solo pochi attori potrebbero fare in proprio).
7. Integrazione delle Soluzioni AI con i Servizi Azure
Abbiamo esaminato i vari pezzi del puzzle (modelli personalizzati, servizi cognitivi, agenti generativi). Ora è importante capire come inserire questi componenti all’interno di soluzioni complete sfruttando l’ecosistema Azure. In altre parole, la sola intelligenza artificiale raramente basta: serve integrarla con le applicazioni, con i flussi di dati, garantire sicurezza, scalabilità, ecc. Azure offre una miriade di servizi pensati proprio per costruire soluzioni cloud end-to-end; qui ci focalizzeremo su quelli particolarmente rilevanti per collegare la parte AI/ML con il resto del mondo applicativo.
Ecco alcuni modi in cui le soluzioni AI su Azure possono essere integrate e potenziate tramite altri servizi Azure:
· Esposizione delle API tramite API Management: Se avete sviluppato un modello e l’avete pubblicato come endpoint (ad esempio un modello ML su Azure ML o un agente Foundry), probabilmente vorrete che altre applicazioni (interne o esterne) possano consumarlo. Azure API Management (APIM) è un servizio che funge da gateway e “vetrina” per API: potete registrare l’endpoint del modello come API in APIM e sfruttarne le funzionalità di sicurezza (autenticazione, rate limiting, chiavi/API token), monitoraggio, e persino trasformazioni sui dati in ingresso/uscita. In questo modo, ad esempio, un team esterno alla vostra organizzazione potrebbe utilizzare la vostra AI tramite una chiave API pubblicata su APIM, senza accedere direttamente all’endpoint sottostante, e con la sicurezza che APIM regola il traffico e nasconde l’implementazione interna.
· Eventi e trigger con Event Grid e Functions: Molte applicazioni AI beneficiano di architetture event-driven. Ad esempio, potreste voler riaddestrare un modello di ML ogni volta che viene aggiunto un nuovo set di dati significativo, oppure inviare un’allerta se il modello rileva un’anomalia. Azure Event Grid è il servizio che permette di instradare eventi (come “file X caricato in Storage” o “nuova riga aggiunta a database” o eventi personalizzati) verso altri servizi. Azure Functions permette di eseguire codice serverless in risposta a quegli eventi. Combinati: immaginate di caricare ogni giorno dei nuovi dati in un container di Azure Blob Storage; Event Grid può essere configurato per “ascoltare” l’evento di nuovo blob e lanciare una Function, la quale a sua volta potrebbe avviare un Pipeline di Azure ML per aggiornare il modello con i nuovi dati, oppure eseguire direttamente un calcolo di inferenza su quei dati e salvare il risultato. Un altro esempio: un evento di “nuovo stream IoT con dati anomali” può attivare una Function che invia un messaggio su Teams tramite un webhook, informando il team che il modello di anomaly detection ha trovato qualcosa di preoccupante.
· Orchestrazione di flussi con Logic Apps: Azure Logic Apps è il servizio di orchestrazione e workflow low-code. Permette di disegnare flussi di lavoro a blocchi, con condizioni, iterazioni, integrazione con tantissimi connettori (database, email, servizi SaaS esterni…). Per le soluzioni AI, Logic Apps può essere molto utile quando bisogna combinare più passaggi in sequenza, magari coinvolgendo sistemi diversi. Ad esempio, potrei avere una Logic App che esegue questo processo: “Ogni volta che arriva un email a un certo indirizzo, prendi l’attachment PDF -> mandalo al servizio Form Recognizer -> prendi il risultato, se un certo campo è sopra una soglia allora invia notifica via email al responsabile, altrimenti archivia in SharePoint”. Tutto questo senza scrivere codice serverless ma disegnandolo con connettori già pronti (c’è il connettore per Form Recognizer, per Send Email, per SharePoint, ecc.). In pratica, Logic Apps può orchestrare i nostri blocchi di IA (chiamare un servizio cognitivo, poi un altro, poi un modello custom) all’interno di più ampi processi aziendali o applicativi.
· Archiviazione di dati e risultati: Qualsiasi soluzione AI produce o consuma dati: modelli di ML producono previsioni, agenti AI accedono a documenti, servizi cognitivi estraggono informazioni. Bisogna pensare a dove archiviamo sia i dati in input sia i risultati ed eventualmente i dati generati in fase di esecuzione (ad esempio embedding vettoriali per RAG, log delle conversazioni, ecc.). Azure offre molte opzioni di storage:
a) Azure Blob Storage per file generici (inclusi dataset, immagini, modelli esportati).
b) Azure SQL Database o Cosmos DB per dati strutturati (rispettivamente relazionale o NoSQL).
c) Azure Data Lake per grandi volumi di dati grezzi in data lake (spesso usato in fase di preparazione dati ML).
d) Per scenari specifici di AI generativa con RAG, spesso gli embedding testuali vengono salvati in un motore di ricerca come Azure Cognitive Search (che indicizza e consente di cercare vettorialmente i documenti), oppure in un archivio chiave-valore veloce come Redis se si implementano architetture ad hoc. In generale, il consiglio è: utilizzare i servizi di storage esistenti per ciò che sanno fare meglio, invece di cercare di far fare tutto al servizio AI. Ad esempio, se un modello genera 1000 record da salvare, è meglio inserirli direttamente in un DB appropriato per poi interrogarli, piuttosto che far tenere in memoria al modello quei dati.
· Sicurezza e rete: In contesti aziendali, oltre alla logica funzionale, bisogna garantire che le soluzioni rispettino policy di sicurezza e privacy. Azure consente di isolare i servizi di AI all’interno di Virtual Network (VNet) in modo che siano raggiungibili solo dalla rete interna e non da internet pubblicamente. Inoltre, molti servizi supportano i Private Endpoints, ossia interfacce di rete private su VNet che permettono di chiamare, ad esempio, un endpoint di Azure ML o un Azure OpenAI senza che il traffico esca sulla rete pubblica. Per la gestione dei segreti (come chiavi API, password, stringhe di connessione), si utilizza Azure Key Vault: invece di hardcodare credenziali nel codice, le soluzioni AI recuperano da Key Vault i segreti al bisogno. Questo è fondamentale soprattutto quando orchestriamo pipeline con diversi servizi (ognuno avrà magari la sua chiave API, Key Vault le conserva tutte in modo centralizzato e sicuro).
· Pattern architetturali comuni: Microsoft fornisce molte guide ufficiali e reference architecture su come combinare questi servizi per scenari noti. Ad esempio:
a. Un’architettura per chatbot web potrebbe comprendere un Web App in Azure App Service per ospitare l’interfaccia chat, un servizio di Language Understanding per interpretare le domande, una Logic App o Function per orchestrare le risposte e magari l’integrazione con altri sistemi (calendario, database clienti, ecc.).
b. Un’architettura per soluzione RAG (Retrieval-Augmented Generation) coinvolge tipicamente: archiviazione dei documenti in Blob Storage, indicizzazione tramite Azure Cognitive Search, un Azure Function o Azure OpenAI/Foundry agent per gestire la query (che fa: query ai documenti -> chiama modello generativo con contesto), l’esposizione tramite API Management, e magari un front-end su App Service. (Questo è esattamente lo scenario menzionato negli esempi precedenti: Q&A su documenti aziendali).
c. Architetture per Agenti e servizi conversazionali complessi (a volte chiamati MCP - Model Context Protocol, riferendosi allo standard emergente per definire come i modelli e agenti interagiscono con gli strumenti) prevedono l’uso di Foundry per definire gli agenti, Event Grid/Functions per maneggiare eventuali eventi asincroni, e via dicendo.
b) Un esempio concreto di soluzione integrata potrebbe essere utile per fissare le idee.
Esempio: Implementazione completa di RAG (Q&A su documenti) – Immaginiamo di voler realizzare un sistema interno dove i dipendenti possono porre domande del tipo “Qual è la policy aziendale per le ferie?” e ottenere una risposta puntuale ricavata dai documenti del regolamento interno. Ecco come potremmo implementarlo su Azure:
1. Base di conoscenza: Tutti i documenti (PDF, file Word) con le policy aziendali vengono caricati in un container su Azure Blob Storage.
2. Indicizzazione: Utilizziamo Azure Cognitive Search per indicizzare questi documenti. Cognitive Search leggerà i file (ci sono skill che estraggono il testo dai PDF, ecc.), e creerà un indice ricercabile, anche semantico, magari generando embedding per i paragrafi.
3. API di Q&A: Creiamo un agente con Azure OpenAI/Foundry: l’agente avrà un modello linguistico (es. GPT-4) e un tool di ricerca che interroga l’indice di Cognitive Search. Quando riceve una domanda, l’agente usa il tool per ottenere i 3-5 documenti più rilevanti dalla ricerca, poi passa questi documenti (o estratti) insieme alla domanda al modello GPT-4. Il modello genera una risposta in linguaggio naturale, includendo magari riferimenti ai documenti.
4. Orchestrazione: Potremmo incapsulare il passaggio 3 in un’Azure Function se vogliamo gestire manualmente, oppure configurare direttamente l’agente in Foundry. In ogni caso, otteniamo un endpoint (via Foundry o via Function + OpenAI) che date in input le domande restituisce le risposte.
5. Esposizione e Sicurezza: Mettiamo questo endpoint dietro API Management per gestire autenticazione (solo i dipendenti possono accedere, magari integrando Azure AD per l’SSO) e per monitorare l’utilizzo.
6. Front-end: Sviluppiamo una piccola applicazione web (in App Service o static web app) che offre un’interfaccia tipo chat/Q&A ai dipendenti, la quale chiama l’API di cui sopra.
Inoltre, per migliorare la soluzione:
· Usiamo Key Vault per tenere le chiavi di Cognitive Search e OpenAI, che la Function o l’agente recupereranno in modo sicuro.
· Configuriamo monitoring: ad esempio, logghiamo ogni domanda e risposta (attenzione ai dati sensibili) magari su Application Insights, e configuriamo un alert se il tasso di successo scende (ad esempio troppe risposte vuote).
· Se necessario, tramite Event Grid potremmo automatizzare la pipeline: quando un nuovo documento di policy viene caricato nello storage, scatta un evento che invoca un processo di aggiornamento dell’indice di Cognitive Search (che tipicamente ha comunque un indexer programmato).
Questo esempio mostra diversi servizi Azure in concerto: Storage, Search, OpenAI, Functions, APIM, App Service, Key Vault, ecc. Ed è uno scenario attuabile con componenti quasi tutti managed (poco da mantenere in proprio).
In generale, Azure favorisce un approccio modulare: ogni servizio fa la sua parte, e sta al progettista di soluzione orchestrare il flusso giusto. La buona notizia è che esistono tanti esempi e template, e i servizi cloud sollevano dal doversi preoccupare dell’infrastruttura (server, scalabilità, aggiornamenti) permettendo di concentrarsi sulla logica applicativa e AI.
8. Intelligenza Artificiale Responsabile (Responsible AI)
Quando si sviluppano tecnologie di Intelligenza Artificiale – specialmente da utilizzare in contesti reali con utenti, clienti o cittadini – non è sufficiente pensare solo alle prestazioni tecniche. Bisogna assicurarsi che l’AI sia utilizzata in modo responsabile, ovvero rispettando principi etici e minimizzando i rischi di effetti negativi. Microsoft ha definito sei principi di AI responsabile che guidano la progettazione e l’implementazione di sistemi AI:
· Equità (Fairness) – L’AI dovrebbe trattare tutti gli utenti e i gruppi in modo equo, evitando bias e discriminazioni. Ad esempio, un modello di credito non dovrebbe penalizzare o favorire indebitamente un gruppo etnico rispetto ad un altro a parità di condizioni finanziarie.
· Affidabilità e Sicurezza (Reliability & Safety) – I sistemi di AI devono essere robusti e sicuri, funzionare bene nelle diverse condizioni previste e gestire con eleganza eventuali errori o situazioni impreviste. Inoltre, devono essere protetti da attacchi e usi malevoli.
· Privacy e Sicurezza dei Dati (Privacy & Security) – Le soluzioni AI devono garantire la protezione dei dati personali e sensibili. Devono rispettare le normative sulla privacy, minimizzare i dati raccolti, e prevenire fughe di dati o utilizzi non autorizzati. (Microsoft usa “sicurezza” sia per safety che per security, qui li distinguiamo come sicurezza operativa vs sicurezza dei dati).
· Inclusività (Inclusiveness) – L’AI dovrebbe essere inclusiva, ovvero progettata tenendo conto della diversità degli utenti (diverse abilità, culture, background). Ciò significa ad esempio sviluppare interfacce accessibili, e modelli che funzionino bene per gruppi demografici diversi.
· Trasparenza (Transparency) – Bisogna rendere i sistemi di AI quanto più trasparenti possibile nel loro funzionamento e nei loro intenti. Gli utenti dovrebbero sapere quando stanno interagendo con un sistema AI (vs una persona) e avere informazioni su come e perché l’AI ha preso una certa decisione, in modo comprensibile.
· Accountability (Responsabilità) – I creatori e gestori di sistemi AI devono mantenere la responsabilità ultima del loro operato. Significa prevedere meccanismi di controllo umano, auditabilità delle decisioni dell’AI, e in generale assumersi la responsabilità di correggere eventuali conseguenze negative provocate dal sistema.
Seguire questi principi non è solo una questione teorica: bisogna tradurli in pratiche durante lo sviluppo di progetti AI. Microsoft ha elaborato un ciclo operativo in quattro fasi per implementare la Responsible AI: Identify, Measure, Mitigate, Operate:
· Identify (Identificare): Nella fase iniziale di un progetto, identificare i potenziali rischi etici e di sicurezza. Ad esempio, capire se il modello potrebbe avere bias, se le decisioni potrebbero impattare gruppi vulnerabili, quali potrebbero essere gli abusi o usi impropri (misuse) del sistema, ecc. In questa fase spesso si definiscono anche requisiti etici e si pianifica come verificarli.
· Measure (Misurare): Durante lo sviluppo, misurare attivamente le proprietà del modello rispetto ai principi RAI. Per esempio, calcolare metriche di fairness (come parità di falsi positivi tra gruppi), testare l’affidabilità con dati rumorosi o casi limite, verificare i livelli di confidenza del modello, condurre test di sicurezza (attacchi adversarial, ecc.), e così via. Azure ML aiuta qui con tool di fairness e explainability integrati.
· Mitigate (Mitigare): Se dalle misurazioni emergono problemi, applicare strategie di mitigazione. Alcuni esempi: se c’è bias nei dati, si può bilanciare il dataset aggiungendo più esempi del gruppo minoritario o applicando pesi; se il modello è poco interpretabile, si può scegliere un modello più semplice o aggiungere una spiegazione post-hoc; se c’è un rischio di output tossici (nel caso di modelli di linguaggio), implementare filtri o moderazione dei contenuti. La mitigazione è un passo iterativo – spesso richiede di tornare indietro e rifare parte dello sviluppo (feature engineering, training, ecc. con vincoli aggiuntivi).
· Operate (Operare): In produzione, continuare a monitorare e mantenere i principi di AI responsabile. Ciò include il monitoraggio dei modelli per drift nei dati che possano reintrodurre bias, l’aggiornamento delle policy di utilizzo man mano che emergono nuovi scenari, l’addestramento del personale coinvolto sull’uso corretto dell’AI, e la predisposizione di piani di intervento se qualcosa va storto (ad es., se il modello inizia a fare errori gravi, essere pronti a sospenderlo o far intervenire umani).
Azure fornisce strumenti pratici per supportare la Responsible AI sia nella fase di sviluppo che in quella di produzione:
· In Azure Machine Learning, come accennato, ci sono dashboard per analizzare l’equità (Fairness Dashboard che può calcolare metriche come la parità demografica tra sottogruppi), dashboard di spiegabilità (che mostrano l’importanza dei fattori nelle decisioni del modello o spiegazioni locali per singole predizioni), e strumenti di analisi degli errori (per individuare sistematicamente quali caratteristiche dei dati causano più errori). Questi tool permettono ai data scientist di misurare e poi mitigare problemi già a monte.
· In Foundry, lato modelli generativi, Microsoft ha integrato controlli di Content Safety. Questo significa che quando un modello (es. GPT-4) genera del testo, si può attivare un filtro che analizza il contenuto alla ricerca di elementi problematici – come linguaggio offensivo, incitamenti all’odio, contenuti violenti espliciti, informazioni personali sensibili, ecc. – e intraprendere azioni (bloccare o alterare la risposta, segnalare l’evento, ecc.). Content Safety è cruciale soprattutto per agenti che interagiscono in linguaggio naturale con gli utenti, per prevenire output inappropriati.
· Foundry inoltre offre tracciamento e valutazioni delle conversazioni degli agenti, il che permette di tenere un log per audit di quello che gli agenti fanno e come performano. Per esempio, si potrebbe rivedere le sessioni in cui l’agente non ha saputo rispondere correttamente o ha dato risposte insoddisfacenti, per migliorarlo.
· Un altro aspetto di sicurezza è l’integrazione con servizi come Azure Defender for Cloud: esso può essere configurato per monitorare risorse AI per configurazioni insicure o attività anomale. Ad esempio, se qualcuno accede a un workspace Azure ML e scarica grandi quantità di dati, potrebbe far scattare un alert; oppure se un endpoint subisce un numero anomalo di chiamate (possibile abuse), anche questo può essere rilevato. Avere tali integrazioni assicura che l’AI, inserita nel contesto più ampio IT aziendale, rientri nelle pratiche di cybersecurity e compliance già in essere.
Facciamo un esempio di Responsible AI applicata: Immagina di sviluppare un modello di credit scoring (valuta l’affidabilità creditizia dei clienti per decidere se concedere un prestito). Sai che c’è il rischio di bias razziale o di genere se, ad esempio, i dati storici (da cui il modello impara) riflettono pregiudizi umani o storici.
· Durante lo sviluppo, userai il Fairness Dashboard di Azure ML: carichi i dati di output del modello (predizioni di approvazione/rifiuto) assieme alle colonne sensibili (ad es. etnia, genere se disponibili, area geografica). Scopri magari che il tasso di approvazione per un certo gruppo etnico è significativamente più basso rispetto ad altri con profili finanziari simili – indice di possibile bias.
· Per mitigare, decidi di applicare una strategia: ad esempio, usi una tecnica di rebalancing del training set (se un gruppo era poco rappresentato, ne aumenti il peso o i campioni) o applichi una correzione alle soglie di decisione in modo da livellare un po’ le differenze (es. sueprvisioni calibrate per gruppo). Riesegui il modello e controlli di nuovo la fairness finché non rientra in parametri accettabili.
· Inoltre utilizzi l’Explainability: per le decisioni di rifiuto del prestito, fai in modo di estrarre le feature importance locali, così da poter fornire al cliente una spiegazione come “Richiesta respinta perché il reddito annuo era inferiore alla soglia minima e la storia creditizia mostrava 2 ritardi di pagamento negli ultimi 5 anni” anziché un rifiuto opaco. Questo aumenta trasparenza e accountability.
· In produzione, metti in piedi un monitoraggio continuo: se in futuro il modello aggiornato cominciasse di nuovo a mostrare drift (magari i dati dei clienti cambiano e introducono nuove disparità), riceverai un alert e potrai intervenire (magari raccogliendo più dati del gruppo svantaggiato o creando un modello aggiornato).
Un altro esempio: per un agente conversazionale pubblico (che risponde anche a utenti esterni su un sito), configuri il Content Safety in Foundry in modo che qualsiasi output generato dal modello passi per i filtri di moderazione. Un utente malintenzionato potrebbe cercare di far uscire dall’agente contenuti inappropriati (un attacco cosiddetto di prompt injection), ma il filtro intercetta volgarità o insulti e li rimuove. Oppure, se l’utente fa domande su dati personali che l’agente potrebbe conoscere (es. “dimmi l’indirizzo di casa del cliente X”), l’agente è progettato per rifiutare rispondere citando i principi di privacy. Anche definire cosa un agente può o non può fare fa parte del design responsabile: ad esempio, potresti limitare gli strumenti a disposizione dell’agente per evitare che compia azioni potenzialmente dannose (non dargli uno strumento di inviare email a tutta l’azienda, a meno che sia strettamente necessario, e comunque controlla gli output).
In conclusione, Responsible AI non è un elemento separato dalla soluzione: deve essere intrecciato in ogni parte del ciclo e dell’architettura. Azure offre molti guardrail tecnologici per aiutare (filtri, dashboard, permessi, log), ma serve anche la consapevolezza del team di sviluppo: scegliere i giusti casi d’uso per l’AI (dove apporta benefici netti), testare con cura, e mantenere un controllo umano adeguato. Per gli studenti che si avvicinano a questi temi, è incoraggiante sapere che sempre più strumenti automatizzati li aiuteranno a rispettare questi principi, ma è vitale comprenderne il significato e l’importanza sin da subito.
9. Strumenti e Ambienti per Sviluppatori
Azure fornisce diversi ambienti e strumenti per chi deve sviluppare, testare e prototipare soluzioni di AI e Machine Learning. A seconda delle esigenze – progetto in team vs esperimento individuale, soluzione low-code vs codice personalizzato, generazione rapida vs pipeline completa – si può scegliere lo strumento più adatto, o anche usarne più di uno in combinazione. I principali ambienti che incontrerete sono:
· Azure Machine Learning Studio (Azure ML) – Ne abbiamo parlato estensivamente: è sia un servizio backend sia un ambiente web. Dal punto di vista dello sviluppatore, Azure ML Studio è l’interfaccia dove potete gestire tutto: caricare notebook Jupyter e scrivere codice, effettuare esperimenti di training in modo tracciato, usare interfacce visuali come il designer per costruire modelli ML drag-and-drop, creare e monitorare endpoint, etc. È ideale per progetti di data science collaborativi in un contesto enterprise: più persone possono accedere allo stesso workspace con i propri account Azure AD, lavorare sulle stesse risorse, con la sicurezza di un controllo degli accessi e logging di attività. Azure ML è ottimo per sviluppare modelli personalizzati che poi andranno in produzione, assicurando riproducibilità e facilità di manutenzione (MLOps integrato).
· Azure AI Studio / Microsoft Foundry – Questo è l’ambiente pensato per la parte di AI generativa e gestione di modelli pre-addestrati. L’Azure AI Studio è la nuova interfaccia unificata che include anche l’esperienza di Foundry. Qui lo sviluppatore (o anche un power user non sviluppatore) può facilmente provare i modelli (es. sperimentare con prompt diversi su GPT-4), creare canvas di conversazione per definire come un agente deve interagire, aggiungere strumenti agli agenti tramite configurazione, e valutare risposte – molto di questo con un approccio low-code o no-code. Si può pensare allo AI Studio come a un “laboratorio” per costruire app di AI conversazionale senza dover scrivere tutto il codice di chiamata modelli, orchestrazione, ecc., perché è la piattaforma a fornirlo. Per uno studente, questo ambiente è utile per esplorare rapidamente le potenzialità dei modelli generativi e costruire prototipi di chatbot o applicazioni innovative, con poca necessità di conoscere le infrastrutture sottostanti.
· Data Science Virtual Machine (DSVM) – Questa è un’opzione diversa: si tratta di immagini di macchine virtuali (VM) offerte su Azure, preconfigurate con un ricco set di strumenti per data science e deep learning. Puoi scegliere DSVM Windows o DSVM Ubuntu; una volta creata la VM, troverai già installati software come Jupyter Notebook, RStudio, Visual Studio Code, e un gran numero di librerie Python/R per machine learning e deep learning (scikit-learn, PyTorch, TensorFlow, Pandas, etc.), oltre a driver e ottimizzazioni per utilizzare eventualmente GPU Nvidia. La DSVM è un ambiente standalone: a differenza di Azure ML Studio o Foundry, qui hai una macchina vera e propria dove puoi fare quasi tutto manualmente come faresti sul tuo PC, ma con la potenza del cloud (puoi scegliere VM molto potenti, con molte CPU o GPU). È molto apprezzata in contesti di formazione, workshop e prototipazione rapida: ad esempio, in un corso universitario su ML potrei dire agli studenti di attivare ognuno una DSVM (magari da spegnere quando non la usano, per risparmiare).
Conclusioni
L’Intelligenza Artificiale (IA) è dunque l’insieme di tecniche che consentono alle macchine di svolgere compiti tipicamente umani, come riconoscere immagini, comprendere linguaggio e prendere decisioni. Il Machine Learning (ML) è la principale sotto-disciplina dell’IA: anziché programmare regole, i modelli apprendono dai dati per fare previsioni e classificazioni. Azure offre due approcci: modelli personalizzati tramite Azure Machine Learning e servizi cognitivi pre-addestrati, facilmente integrabili con altre soluzioni cloud. I tipi di ML sono tre: supervisionato (impara da dati etichettati, utile per classificazione e regressione), non supervisionato (trova pattern nascosti, come clustering e anomaly detection) e deep learning, basato su reti neurali profonde, ideale per visione artificiale e NLP. Un progetto ML segue un ciclo di vita strutturato: raccolta e preparazione dati, addestramento, valutazione, distribuzione e monitoraggio (MLOps). Azure ML supporta ogni fase con strumenti per training su scala, AutoML, registrazione modelli e deployment sicuro. I servizi cognitivi di Azure (Vision, Speech, Language, Decision, Document Intelligence) permettono di aggiungere funzionalità AI tramite API senza sviluppare modelli complessi. Con Azure OpenAI e Foundry si abilitano scenari di AI generativa, agenti intelligenti e integrazione con retrieval (RAG). L’ecosistema Azure consente di orchestrare soluzioni end-to-end con Logic Apps, Functions, API Management, storage sicuro e governance. Fondamentale è applicare i principi di Responsible AI (equità, trasparenza, privacy, sicurezza) usando strumenti integrati per fairness, explainability e content safety. Infine, Azure mette a disposizione ambienti per sviluppatori come ML Studio, AI Studio/Foundry e DSVM, per prototipare e gestire soluzioni AI in modo collaborativo e scalabile.
Riepilogo capitolo
Il capitolo offre una panoramica completa delle tecnologie di Intelligenza Artificiale (IA) e Machine Learning (ML) su Azure, illustrandone i concetti di base, i tipi di apprendimento, il ciclo di vita del ML, le piattaforme e i servizi disponibili, nonché le pratiche di AI responsabile e gli strumenti per sviluppatori.
· Concetti di IA e ML: L'IA mira a far svolgere compiti intelligenti alle macchine, mentre il ML è una sotto-disciplina che permette ai sistemi di imparare dai dati senza regole esplicite. Su Azure si può scegliere tra modelli personalizzati e servizi pre-addestrati, integrabili tra loro.
· Tipi di apprendimento automatico: Si distinguono apprendimento supervisionato (modelli con dati etichettati), non supervisionato (scoperta di pattern senza etichette) e apprendimento profondo (deep learning con reti neurali multilivello), ognuno supportato da specifici servizi Azure.
· Ciclo di vita del ML: Include raccolta e preparazione dati, addestramento, valutazione, distribuzione e monitoraggio continuo, con strumenti Azure che facilitano ogni fase e supportano pratiche MLOps.
· Azure Machine Learning: Piattaforma unificata per la gestione del ciclo ML, con workspace collaborativi, training su risorse scalabili, AutoML, gestione modelli, deployment con endpoint gestiti e strumenti per AI responsabile come fairness e explainability.
· Servizi Cognitivi di Azure: Offrono funzionalità di IA pre-addestrate per visione, linguaggio, parlato, decisioni e analisi documenti, accessibili tramite API o SDK, ideali per integrazioni rapide senza addestramento.
· AI Generativa con Azure OpenAI e Foundry: Azure OpenAI fornisce modelli generativi come GPT-4 e DALL-E, mentre Foundry offre un hub per modelli multipli, agenti AI complessi e gestione centralizzata con strumenti di monitoraggio e sicurezza.
· Integrazione con servizi Azure: Le soluzioni AI si integrano con API Management, Event Grid, Functions, Logic Apps, vari servizi di storage, sicurezza di rete e Key Vault, permettendo architetture cloud modulari e scalabili.
· Intelligenza Artificiale Responsabile: Microsoft promuove principi etici come equità, trasparenza, sicurezza e accountability, supportati da strumenti Azure per misurare, mitigare e monitorare bias, errori e sicurezza dei modelli.
· Strumenti per sviluppatori: Azure ML Studio per data science collaborativa, Azure AI Studio/Foundry per AI generativa e agenti, e Data Science Virtual Machine per ambienti preconfigurati di sviluppo e prototipazione.
CAPITOLO 8 – Il servizio DevOps
Introduzione
Azure DevOps è una piattaforma offerta da Microsoft che integra una serie di servizi utili a pianificare il lavoro, gestire il codice sorgente, automatizzare build e rilasci, gestire pacchetti e monitorare la qualità del software. In sostanza, Azure DevOps fornisce un ecosistema DevOps completo che permette ai team di sviluppo di collaborare efficacemente e rilasciare software di alta qualità in maniera continua.
Nei team software moderni, il modello DevOps rappresenta un insieme di pratiche e strumenti pensati per unire lo sviluppo (Dev) e le operazioni IT (Ops). L’obiettivo è accelerare il ciclo di vita del software, dalla scrittura del codice fino alla messa in produzione, migliorando allo stesso tempo la qualità e l’affidabilità. Azure DevOps supporta questo approccio fornendo servizi integrati che coprono tutte le fasi: dal controllo di versione del codice e pianificazione del lavoro, fino alla continuous integration/continuous delivery (CI/CD), ai test e al monitoraggio.
I principali servizi inclusi in Azure DevOps sono:
· Azure Repos: un sistema di controllo di versione basato su Git (distribuito) o TFVC (centralizzato) per gestire il codice sorgente e la collaborazione tra sviluppatori.
· Azure Pipelines: un servizio di CI/CD che consente di automatizzare la compilazione, il test e il rilascio delle applicazioni, supportando pipeline definite come codice (YAML) e integrazione con molti ambienti di deploy.
· Azure Boards: uno strumento di project management agile per tracciare il lavoro tramite work item, bacheche Kanban, backlog Scrum, generazione di report sul progresso e collaborazione tra i membri del team.
· Azure Artifacts: un servizio di gestione di pacchetti e dipendenze, che consente di ospitare feed privati per componenti come librerie NuGet, npm, Maven, Python, ecc., favorendo la condivisione e il riutilizzo sicuro del codice.
· Azure Test Plans: (non trattato dettagliatamente in questo ebook) un servizio per la gestione dei test manuali e automatizzati, includendo pianificazione di test case e raccolta di feedback.
Nel corso di questo ebook rivolto a studenti, esploreremo i principali servizi (Azure Repos, Pipelines, Boards, Artifacts) e concetti aggiuntivi correlati, rielaborando il contenuto delle slide fornite. Ogni sezione è dedicata a un argomento chiave e mantiene un tono didattico e informativo, con spiegazioni dei concetti fondamentali, definizioni di termini importanti, esempi pratici toccati con mano, e anche “suggerimenti visivi” descritti tramite testo (ovvero la descrizione di eventuali diagrammi o flussi che possono aiutare la comprensione).
Inquadramento argomenti del capitolo con slides illustrate
Azure Repos è il servizio di versionamento di Azure DevOps. Supporta sia il sistema distribuito Git che il centralizzato TFVC. Con Git hai history locale, branching leggero e pull request per integrare codice dopo revisione. Le branch policy consentono requisiti come code review, build valida e controlli di stato. Le pull request permettono discussioni, suggerimenti di modifica, commenti inline e verifiche automatiche tramite Azure Pipelines. Puoi proteggere il branch principale dai push diretti e usare i fork per collaborare con contributori esterni. I commit possono essere collegati ai work items su Azure Boards e puoi applicare linting e scansioni di sicurezza nelle build. La gestione dei permessi garantisce il minimo accesso necessario. Consulta la documentazione per approfondire Azure Repos e le branch policies.
Azure Pipelines esegue Continuous Integration e Continuous Delivery. Le pipeline sono definite in YAML: vivono nel repository, sono versionate e riusabili. Gli elementi principali includono trigger, stages, jobs, steps, agent pool, variabili e artefatti. Puoi sfruttare templates e condizioni per percorsi diversi, e integrare GitHub o Azure Repos per la validazione delle pull request. Gli status checks bloccano il merge se la build fallisce. Per l'orchestrazione dei container puoi usare pipeline multi-stage con deploy su AKS o App Service. Consulta la documentazione YAML schema e overview Pipelines per dettagli.
Le strategie di rilascio in Azure DevOps definiscono gate e approvazioni tra ambienti Dev, Test e Production. Puoi impostare checks come approvazioni umane, controlli di branch, template richiesti e verifiche sulle risorse. I gate possono includere query sui work items, esiti test e scansioni di sicurezza. Deployment jobs offrono log e lifecycle hooks, mentre le regole di protezione garantiscono i requisiti di qualità. Puoi implementarecanary e blue-green deploy, e automatizzare il rollback in caso di problemi. La documentazione su Environments and checks e Deployment strategies è disponibile per approfondimenti.
Azure Artifacts offre feed privati per NuGet, npm, Maven, Python e Universal Packages. Supporta versioning semantico, retention dei pacchetti e upstream sources per caching dai registri pubblici. Integra le pipeline per pubblicare e consumare pacchetti in modo sicuro. Strumenti come Dependabot e Renovate aiutano a monitorare le versioni, mentre SBOM e scansioni SCA verificano licenze e vulnerabilità. Le Views consentono di promuovere i pacchetti tra ambienti. Consulta la documentazione per approfondire Azure Artifacts e le upstream sources.
Azure Boards consente di gestire work items come Epic, Feature, User Story, Task e Bug, supportando sia Scrum che Kanban. Puoi collegare work items a commit, pull request e build per tracciare tutto il ciclo di vita. Queries avanzate e dashboards mostrano burndown, lead time e qualità. I process templates sono configurabili e la collaborazione è fcilitata da mentions, dipendenze, discussioni e allegati. L'integrazione con GitHub Issues e DevOps Pipelines permette automazioni come la chiusura automatica dei work items. Consulta le guide boards overview e link work items to Git.
Integrare quality gates e security checks nelle pipeline riduce difetti e rischi. Usa test unit e integration con report JUnit o TRX, code coverage, static analysis come SonarQube e CodeQL, e SCA per le dipendenze. Puoi abilitare Microsoft Defender for Cloud per segnalare rischi, e attuare una Secure Supply Chain con firme e attestations. Le policy possono richiedere copertura minima o assenza di vulnerabilità critiche. Consulta le risorse Publish Test Results e Secure DevOps kit per maggiori dettagli.
Con Infrastructure as Code e Configuration as Code puoi descrivere risorse e configurazioni tramite Bicep, ARM, Terraform o Ansible, e rilasciarle con pipeline automatizzate. Bicep semplifica gli ARM template con moduli riusabili e sicurezza sui tipi. Configuration as Code, come Azure App Configuration e Key Vault, gestisce parametri e segreti per ogni ambiente. Puoi integrare validazione, approvazioni e policy per garantire la conformità. Usa Blueprints e Landing Zones per standardizzare, e Drift detection per prevenire divergenze. Approfondisci con la documentazione Bicep overview e Terraform pipelines.
Con Azure Kubernetes Service puoi implementare CI/CD per microservizi: build delle immagini, push su Azure Container Registry e deploy tramite kubectl, Helm o GitOps. Pipeline multi-stage automatizzano build, scan, push e deploy. Azure Monitor Container Insights offre log e metriche, mentre per la sicurezza puoi usare Workload Identity, Network Policies e Azure Policy. L'affidabilità è garantita da readiness e liveness probes, autoscaling e Pod Disruption Budgets. Consulta la documentazione AKS CI/CD e Container Insights per ulteriori dettagli.
La governance assicura che i rilasci rispettino standard di sicurezza e normative. Azure Policy applica regole come private endpoints obbligatori o tag richiesti, e verifica la compliance con report. In DevOps, approvals, template obbligatori e branch policies controllano le modifiche. Auditing e Log Analytics tracciano le attività. L'integrazione con Defender for Cloud DevOps fornisce raccomandazioni di sicurezza, mentre i workbook di Azure Monitor aggregano metriche di build, errori e tempi. Per la privacy, adotta Security Development Lifecycle e gestisci i secret in Key Vault. Consulta le fonti Azure Policy e Defender for Cloud DevOps.
In Azure DevOps l’unità principale è l’organizzazione, che contiene progetti, board, pipeline e test. I permessi si gestiscono per livello tramite security groups e access levels, mentre le service connections autorizzano i deploy. Managed identities e PAT con scadenza aumentano la sicurezza, così come il conditional access a livello tenant. La scalabilità si ottiene separando i progetti, usando Area Paths e Teams, e standardizzando templates e policies. Centralizza artifact feeds e ambienti condivisi per ottimizzare la gestione. Consulta la documentazione Organization overview e Permissions per saperne di più.
1. Azure Repos: Controllo di Versione e Collaborazione
Azure Repos è il modulo di Azure DevOps dedicato al version control, ovvero la gestione delle versioni del codice sorgente. Supporta due sistemi di controllo versione: Git, che è distribuito, e TFVC (Team Foundation Version Control), che è centralizzato. La scelta tra i due dipende dalle esigenze del progetto, ma Git è oggi il sistema più diffuso per la maggior parte dei team grazie alla sua flessibilità e velocità.
a) Concetti Principali di Azure Repos
· Repository Git privati illimitati: Azure Repos permette di creare un numero illimitato di repository Git privati, ospitati nel cloud, dove poter memorizzare il codice. Ogni repository funge da contenitore per la storia del progetto e contiene tutti i commit (storia delle modifiche), i branch (ramificazioni del codice) e i tag relativi alle versioni.
· Branch e Cronologia: La possibilità di creare branch leggeri (ossia economici in termini di risorse) è fondamentale con Git. Gli sviluppatori possono lavorare su branch paralleli, ad esempio creando un branch dedicato per una nuova funzionalità (feature branch), senza intaccare la stabilità del branch principale (spesso chiamato main o master). Tutte le modifiche restano tracciate nella cronologia (history) locale e remota, garantendo tracciabilità completa. Con TFVC, invece, il controllo del codice è centralizzato su un server e spesso i file vengono “presi in carico” (checkout) e rilasciati (check-in); TFVC può essere utile in contesti legacy, ma offre meno flessibilità rispetto a Git.
· Pull Request (PR): Una pull request è una proposta di integrazione di cambiamenti da un branch a un altro (solitamente da un feature branch verso main). Nel flusso di lavoro Git, l’uso delle PR è fondamentale: uno sviluppatore, terminata una funzionalità sul proprio branch, apre una pull request per richiedere che il suo codice venga revisionato ed eventualmente unito al branch principale. Azure Repos fornisce un’interfaccia per le PR che consente ai revisori di esaminare il codice, fare commenti inline (sulle singole righe di codice), proporre modifiche (suggested changes) e approvare o meno la richiesta di merge. Durante la PR si possono attivare anche verifiche automatiche, ad esempio eseguire build e test tramite Azure Pipelines per assicurarsi che il nuovo codice non introduca errori.
· Branch Policies: Per mantenere alta la qualità del codice, Azure Repos permette di definire policy sui branch. Le branch policy sono regole che devono essere soddisfatte prima che una pull request possa essere completata (cioè prima che il codice venga fuso nel branch di destinazione). Esempi di branch policy: richiedere un numero minimo di revisori (ad esempio almeno 2 code reviewer devono approvare), obbligare ad avere un work item (elemento di lavoro) collegato al commit (per tracciare perché quel codice è stato scritto), oppure richiedere che una build di verifica (CI build) passi con successo e che certi status checks (come la copertura di test minima o l’assenza di vulnerabilità note) siano rispettati. Inoltre, con le policy si può proteggere il branch main impedendo i push diretti su di esso: ogni modifica deve passare attraverso PR approvate.
· Collaborazione e Revisione del Codice: Tramite Azure Repos, la collaborazione è semplificata: oltre ai commenti nelle PR, è possibile menzionare colleghi (@mention) per coinvolgerli nella discussione, e le eventuali discussioni rimangono legate al codice e tracciate nella storia del progetto. Azure Repos offre anche la possibilità di utilizzare i fork, ovvero creare una copia di un repository in un proprio spazio (ad esempio per contributori esterni al progetto principale), con la possibilità di proporre cambiamenti tramite PR dal fork verso il repository originale. Questo è utile in progetti open-source o collaborazioni con team esterni.
· Integrazione con Azure Boards: I commit e le PR possono essere collegati ai Work Items di Azure Boards (che vedremo più avanti). Questo crea tracciabilità end-to-end: ad esempio, un requisito o bug tracciato in Boards può essere associato specificamente ai cambiamenti di codice che lo risolvono. Quando la PR viene completata, il work item può essere automaticamente aggiornato (es: segnato come risolto).
· Permessi e Sicurezza: Azure Repos consente di gestire i permessi di accesso a livello di progetto o di singolo repository. È possibile limitare chi può contribuire, chi può approvare PR, chi può creare branch, ecc., seguendo il principio del minimo privilegio (dare accesso solo a chi ne ha bisogno).
b) Esempi Pratici Azure Repos
· Esempio 1: Policy di Branch. Il team Alpha vuole assicurare che ogni modifica sul branch main sia di qualità. Nel progetto, configurano branch policies sul branch main richiedendo che: (a) ogni PR abbia almeno 2 revisori approvanti; (b) sia collegato a un elemento di lavoro (work item) per motivare il cambiamento; (c) la build automatica di verifica passi con successo prima del merge. Inoltre, abilitano l’opzione Auto-complete sulle PR: ciò significa che una volta ottenute tutte le approvazioni e superati tutti i controlli, la PR verrà completata automaticamente, fondendo il codice su main senza intervento manuale.
· Esempio 2: Workflow con Feature Branch. Uno studente sta lavorando su una nuova funzionalità chiamata “Login con OAuth” per un progetto. Crea un branch chiamato feature/oauth-login partendo da develop. Man mano che sviluppa, fa commit sul branch. Quando è pronto, apre una pull request per unire feature/oauth-login dentro develop. Marca la PR come draft (bozza) finché non è completamente pronta, per segnalare ai colleghi che il lavoro è ancora in corso. Dopo ulteriori test, toglie lo stato di bozza, assegna due revisori, e grazie alle policy configurate questi vedono subito che devono approvare e che la build di validazione (eseguita automaticamente da una pipeline CI) è passata. I revisori aggiungono commenti e suggerimenti direttamente sul codice (ad esempio segnalando di rinominare una funzione per chiarezza). Lo sviluppatore applica i suggerimenti e aggiorna la PR. Alla fine, ottenute due approvazioni e verifica automatica, la PR viene completata e il branch feature/oauth-login viene unito in develop. Infine, elimina il branch di feature poiché non serve più, mantenendo il repository pulito.
c) Definizioni Importanti per Azure Repos
· Version Control (Controllo di Versione): sistema che tiene traccia dei cambiamenti nel codice sorgente nel tempo, permettendo di ripristinare versioni precedenti e di lavorare in parallelo su varie funzionalità.
· Git: sistema di controllo di versione distribuito. Ogni collaboratore ha una copia locale completa del repository, inclusa la cronologia. Offre funzionalità avanzate come branching locale, merging, rebase, ecc.
· TFVC: sistema di controllo versione centralizzato tipico di Team Foundation Server/Azure DevOps Server. Il codice risiede principalmente su un server centralizzato; gli sviluppatori estraggono (checkout) i file, li modificano e poi reintegrano (check-in) le modifiche. Meno flessibile di Git per molte situazioni moderne.
· Branch: ramificazione del codice. Consente di separare il lavoro in parallelo; ogni branch ha la propria serie di commit. Il branch predefinito spesso è main (o master), che contiene il codice pronto o rilasciato.
· Pull Request (PR): richiesta di unione delle modifiche da un branch sorgente a un branch di destinazione. Permette la revisione e la discussione sul codice prima che le modifiche vengano integrate permanentemente nel branch di destinazione.
· Merge: l’operazione di unire le modifiche di un branch in un altro branch.
· Branch Policy: regole e requisiti che una PR deve soddisfare per poter essere completata. Aiutano a imporre standard di qualità (es: code review, test passati, ecc.).
· Fork: copia personale di un repository, tipicamente usata per proporre modifiche a progetti a cui non si ha accesso diretto. Nel contesto di Azure Repos, consente di collaborare esternamente mantenendo il repository originale al sicuro.
d) Suggerimento Visivo (Descrizione Testuale)
Immaginiamo un diagramma del flusso di lavoro Git tipico: un grafico che mostra un branch principale chiamato main (protetto), dal quale si dirama un branch develop per integrazione delle funzionalità in corso. Da develop a sua volta si creano branch di funzionalità chiamati per esempio feature/XYZ. Ciascun feature branch segue il ciclo: sviluppo → commit → push sul repository remoto → pull request per unire in develop → code review & build validation nella PR → merge in develop una volta approvato. Alla fine, periodicamente develop viene unito in main passando per un’ultima PR (magari al termine di una release). Durante ogni PR, un sistema CI (Azure Pipelines) esegue automaticamente una build e test suite per assicurarsi che la nuova modifica sia stabile. Questo flusso (conosciuto come Git flow o simili varianti) evidenzia come Azure Repos e Pipelines insieme aiutino a gestire il codice in modo collaborativo e controllato.
2. Azure Pipelines: Continuous Integration e Delivery Automatizzata
Se Azure Repos gestisce il codice, Azure Pipelines è il servizio di Azure DevOps incaricato di automazione di build, test e rilascio. In altre parole, Azure Pipelines implementa la CI/CD: Continuous Integration (Integrazione Continua) e Continuous Delivery/Deployment (Consegna/Distribuzione Continua).
Con Azure Pipelines, i team possono configurare pipeline di build e rilascio che vengono eseguite ogni volta che se ne verificano le condizioni (ad esempio, un commit nel repository). Queste pipeline possono compiere operazioni come la compilazione del codice, l’esecuzione dei test automatici, l’analisi della qualità del codice, il packaging di un’applicazione e persino il deployment verso ambienti come macchine virtuali, servizi cloud o container.
a) Pipeline come codice (YAML)
Uno dei punti di forza di Azure Pipelines è che consente di definire le pipeline “as code”, cioè tramite definizioni testuali in formato YAML memorizzate nel repository stesso. Questo approccio ha vari benefici:
· La definizione della pipeline è versionata insieme al codice: ogni modifica alla pipeline viene tracciata.
· Più pipeline possono condividere configurazioni grazie ai template YAML.
· È possibile riutilizzare definizioni e componenti della pipeline in diversi progetti.
Un file di pipeline YAML tipico contiene:
· Trigger: definisce quando far partire la pipeline. Ad esempio trigger: [ "main" ] indica di eseguire la pipeline ad ogni commit sul branch main. È possibile specificare trigger differenti (anche su tag, o pianificati). Nel caso di pipeline di validazione delle PR, spesso non si usa il trigger sui commit, ma piuttosto la sezione pr: per specificare che la pipeline deve attivarsi su pull request verso determinati branch.
· Variabili: parametri configurabili utilizzati nella pipeline, come ad esempio la versione di un SDK, nomi di ambiente, ecc. Possono essere definite direttamente nel YAML oppure in gruppi di variabili (Variable Groups) gestibili separatamente, e possono anche essere segreti (ad es. password) integrati magari tramite Azure Key Vault.
· Jobs e Steps: il cuore della pipeline. Una pipeline può essere divisa in stages (fasi), ciascuno con uno o più jobs (processi paralleli) che eseguono una serie di steps (passi). Ogni step può essere, ad esempio, l’esecuzione di uno script, l’uso di un task predefinito (come “Build .NET”, “Esegui test”, “Pubblica artefatti”), il deployment su un ambiente, ecc.
· Agent pool: indica dove girano i jobs. Azure Pipelines fornisce degli agent (agenti) ospitati da Microsoft su varie piattaforme (Windows, Linux Ubuntu, macOS) pronti all’uso (Microsoft-hosted agents). È anche possibile configurare agent self-hosted (gestiti dall’utente) per avere maggior controllo o per poter accedere a risorse on-premises.
· Artifacts: possibilità di pubblicare e conservare artefatti di output della pipeline, come pacchetti, file binari, archivi .zip contenenti i risultati della build. Questi artefatti potranno poi essere utilizzati in fasi successive (ad esempio una fase di deploy può prendere l’artefatto prodotto dalla fase di build).
· Strategie di multi-stage: con YAML è possibile definire pipeline multi-stage che includono sia la build (CI) sia la rilasci (CD) in un unico flusso. Ogni stage potrebbe rappresentare un ambiente (Dev, Test, Prod) con logiche di approvazione tra di essi (vedremo i dettagli delle strategie di rilascio in una sezione dedicata).
· Conditional e dipendenze: la pipeline YAML consente di esprimere condizioni (ad esempio, eseguire determinati step solo se la build precedente è fallita o solo su un certo branch) e dipendenze tra stage (es: avviare stage di deploy solo se stage di test è passato).
In alternativa al formato YAML, Azure Pipelines offre anche una interfaccia classica (Classic pipelines) definibile via web UI; tuttavia, l’approccio moderno privilegiato è l’infrastruttura-as-code con pipeline YAML.
b) Integrazione con GitHub e Repos
Azure Pipelines può integrarsi con repository Azure Repos o GitHub. Un caso comune è la validazione continua delle PR: quando c’è una pull request aperta verso main, la pipeline viene eseguita automaticamente su quel branch PR, fornendo feedback immediato agli sviluppatori (ad esempio segnalando se i test falliscono). Nella definizione YAML, questo scenario si configura con:
In questo modo la pipeline parte solo in caso di Pull Request (PR) e non ad ogni commit. I risultati (successo/fallimento) appaiono direttamente nella pagina della PR come status checks obbligatori: se la pipeline fallisce, la PR non potrà essere completata finché il problema non viene risolto.
Azure Pipelines supporta inoltre integrazione con Git in generale: ad esempio, può monitorare un repository GitHub e attivarsi su nuovi commit o nuovi tag. Questo consente l’uso di Azure Pipelines anche per progetti ospitati fuori da Azure DevOps.
c) Esecuzione di Pipeline e Monitoraggio
Una volta definita, la pipeline può essere eseguita manualmente o tramite i trigger configurati. Azure Pipelines fornisce un’interfaccia web per:
· Vedere lo storico delle esecuzioni di pipeline (i vari run con i rispettivi risultati, durata, commit associato, ecc.).
· Osservare i log dettagliati di ogni step di esecuzione (utile per debug in caso di errori).
· Visualizzare gli output e artefatti prodotti.
· Ristartare pipeline fallite e magari riprendere da un certo stage, se previsto.
È anche possibile configurare notifiche in modo che il team riceva avvisi su Teams, email o altri canali quando una pipeline fallisce o quando un deployment va a buon fine.
d) Esempi Pratici Azure Pipelines
· Esempio 1: Pipeline CI con test e artefatti. Un team di studenti sviluppa un’applicazione .NET. Configurano una pipeline YAML che, ad ogni commit su main, esegue i seguenti passi: (a) ripristino dei pacchetti (restore delle dipendenze .NET); (b) compilazione del codice (dotnet build); (c) esecuzione dei test unitari (dotnet test) generando anche un report di code coverage (copertura del codice testato); (d) pubblicazione dei risultati di test e del file di copertura; (e) se i test passano, creazione di un pacchetto di output (ad esempio un file .zip con il prodotto compilato o un container Docker) come artifact; (f) pubblicazione dell’artifact nei risultati della pipeline. Grazie a questa pipeline CI, il team vede subito se un commit causa dei test falliti e ha sempre a disposizione l’ultimo build funzionante dell’app.
· Esempio 2: Pipeline di CD con environment multipli. Dopo la fase di CI del caso precedente, il team vuole automatizzare anche il deployment. Creano così una pipeline multi-stage: la prima stage è la build+test (CI) come su descritto. La seconda stage potrebbe essere di deploy in ambiente Dev (sviluppo), che prende l’artifact prodotto e lo distribuisce, ad esempio, su un servizio Azure App Service o su una VM di test. Una terza stage potrebbe essere il deploy in ambiente di Produzione, ma protetto da un’approvazione manuale: ossia, la pipeline attende che un responsabile approvi manualmente il passaggio prima di eseguire il deploy in produzione. All’interno di questa pipeline multi-stage, il team implementa anche un controllo condizionale: il deploy in Prod avviene automaticamente solo se quello in Dev è andato a buon fine e se, ad esempio, la percentuale di test passati è superiore a un certo livello. In caso contrario, la pipeline si ferma e segnala un errore.
e) Definizioni Importanti per Azure Pipelines
· Continuous Integration (CI): pratica di integrare frequentemente (più volte al giorno idealmente) il codice di tutti gli sviluppatori in un repository condiviso, verificando ogni integrazione tramite una build automatica e test. Ciò permette di individuare rapidamente bug o conflitti.
· Continuous Delivery/Deployment (CD): estensione del CI che automatizza anche la consegna del software in ambienti di staging o produzione in modo continuo. Continuous Delivery implica che il software è sempre in uno stato rilasciabile e le distribuzioni in produzione richiedono comunque un intervento umano di approvazione; Continuous Deployment elimina anche l’intervento umano, distribuendo automaticamente ogni modifica verificata.
· Pipeline: catena automatizzata di passi (build, test, deploy, ecc.) eseguiti in seguito a eventi (es. commit) o manualmente. Rappresenta il flusso di CI/CD.
· YAML: (Yet Another Markup Language) formato di serializzazione di dati leggibile da umani, usato per definire pipeline as code in Azure DevOps.
· Agent (Agente): è il runtime che esegue i job di pipeline. Un agente prende istruzioni (steps) e le esegue su una macchina specifica. Un agent può essere ospitato da Microsoft (in cloud) o self-hosted.
· Artifact (Artefatto): prodotto generato da una pipeline che viene conservato e può essere usato in stadi successivi. Può essere un file eseguibile, un pacchetto NuGet, un container Docker, un archivio con il sito web statico, ecc.
· Stage/Job/Step: livelli di organizzazione di una pipeline. Stage è una fase logica (es: Build, Test, Deploy), un Job è un gruppo di passi eseguiti insieme su un agente, un Step è un singolo comando o task.
· Release (Rilascio): nei contesti di pipeline classiche, un release è una distribuzione del software in un ambiente; con pipeline YAML multi-stage, il concetto di release è integrato nelle stage di deploy.
· Approval (Approvazione): azione manuale richiesta per permettere il proseguimento di una pipeline o il deploy su un certo ambiente. Serve a introdurre un controllo umano in un processo altrimenti automatico.
f) Suggerimento Visivo (Descrizione Testuale)
Immaginiamo una rappresentazione grafica del processo CI/CD: una serie di icone collegate in sequenza. La pipeline inizia con un’icona di un developer che fa un commit di codice su Azure Repos/GitHub. Questo scatena una Build (rappresentata dall’icona di un ingranaggio) su Azure Pipelines, durante la quale il codice viene compilato e testato. Se la build va a buon fine, si passa a un’icona di package (pacchetto): è la fase di packaging in cui si crea un artifact, ad esempio un file .zip o un’immagine Docker. Successivamente, un’icona di deploy su un server/cloud indica il rilascio dell’applicazione sull’ambiente di destinazione. Infine, un simbolo di monitoraggio suggerisce che dopo il deploy l’applicazione viene monitorata (ad esempio tramite Azure Monitor, log, ecc.). Sopra alcune frecce nel diagramma potremmo avere icone di check che rappresentano i controlli di qualità (test unitari passati, verifica della sicurezza) che fungono da gate tra una fase e l’altra. Questo schema illustra la catena automatizzata implementabile con Azure Pipelines dove ogni commit viaggia attraverso build, test e deploy fino all’utente finale.
3. Strategie di Rilascio, Approvazioni e Controlli di Qualità
Una parte importante del ciclo DevOps è la gestione del rilascio sulle varie ambienti (sviluppo, test, produzione) in modo controllato e sicuro. Azure Pipelines (in particolare con le pipeline multi-stage in YAML, o con le pipeline di Release classiche) consente di definire strategie di rilascio avanzate, includendo approvazioni manuali, controlli automatici (quality gates) e strategie di deployment graduali.
a) Fasi (Stages) e Ambienti
Tipicamente, quando si implementa Continuous Delivery, si suddivide il processo in fasi corrispondenti agli ambienti:
· ad esempio Dev (sviluppo), Test (collaudo) e Production (produzione). Ogni fase avrà i suoi jobs di deploy o configurazione specifici. Azure DevOps introduce il concetto di Environment per rappresentare un target di deploy (che può essere un insieme di risorse, una specifica macchina, un cluster Kubernetes, ecc.). Agli environment possono essere associate impostazioni di sicurezza e controlli.
b) Approvals (Approvazioni) e Gates (Gate di controllo)
Per passare da una fase all’altra (ad esempio da Dev a Test, o da Test a Prod), si possono impostare:
· Approvazioni manuali: persone designate (approvers) devono approvare attivamente il passaggio al prossimo stage. Ad esempio, prima di distribuire in produzione, si può richiedere l’approvazione del responsabile QA o del product owner.
· Gates automatici: controlli automatizzati che eseguono delle verifiche prima di permettere il proseguimento. Alcuni esempi di gate:
a) Query di Work Items: controlla che tutti gli elementi di lavoro collegati alla release siano in uno stato appropriato (es: nessun bug attivo ad alta severità aperto).
b) Esiti di test: verifica, ad esempio, che la percentuale di test passati sia sopra una soglia o che non ci siano test critici falliti.
c) Scansioni di sicurezza: integra risultati da strumenti di sicurezza (static code analysis, container scan, ecc.) e blocca il rilascio se sono presenti vulnerabilità gravi.
d) Tempo di esecuzione o intervallo: ad esempio, un gate può imporre di attendere un certo tempo e ricontrollare una condizione (utile per esempio per controllare dopo 1 ora dallo deploy in staging se ci sono errori nei log prima di procedere).
Questi approcci assicurano che l’avanzamento della pipeline di rilascio avvenga solo se certe condizioni di qualità sono rispettate.
c) Deployment Jobs e Controlli negli Ambienti
Azure Pipelines offre i Deployment jobs che sono specializzati per i rilasci: forniscono output di log più dettagliati e consentono di definire azioni pre-deploy e post-deploy (hook di esecuzione prima e dopo il deploy vero e proprio, ad esempio per avvisare gli utenti, prendere snapshot del database prima di un aggiornamento, ecc.). Inoltre, per ogni environment è possibile definire environment protection rules – regole di protezione dell’ambiente – che di fatto funzionano come guardrail: ad esempio, richiedere approvazioni per quell’environment specifico, o assicurare che solo pipeline con certe autorizzazioni possano distribuirvi.
d) Strategie di Rilascio Avanzate
Nei contesti di produzione, spesso non si effettua un deploy diretto a tutti gli utenti contemporaneamente, per ridurre i rischi. Azure DevOps supporta l’implementazione di strategie come:
· Canary release: distribuire inizialmente una nuova versione dell’applicazione solo a una piccola percentuale di utenti o su una porzione di server (es. 5-10%), monitorare il comportamento (errori, metriche) e poi gradualmente aumentare la percentuale al 50% e infine 100% se tutto va bene. Questa strategia riduce l’impatto di eventuali problemi, permettendo di rilevarli su scala ridotta prima di colpire tutti gli utenti.
· Blue-Green deployment: mantenere due ambienti (Blue e Green) dove uno è la versione corrente in produzione e l’altro è la nuova versione. Si distribuisce la nuova versione in uno dei due, si fanno test e poi si scambiano gli ambienti (il routing degli utenti viene indirizzato verso l’ambiente aggiornato). In Azure, ad esempio, sugli App Service si può usare lo slot swap (scambio di slot di deployment).
· Rollback automatico: se dopo un rilascio vengono rilevate metriche oltre soglie critiche (esempio: il tasso di errori supera un certo valore, o il consumo di CPU è anomalo), la pipeline può avviare un rollback automatico distribuendo di nuovo la versione precedente conosciuta come stabile.
Per implementare canary o blue-green su servizi Azure come AKS (Azure Kubernetes Service) o App Service, spesso si orchestrano pipeline con script o estensioni specifiche. Ad esempio, su AKS si potrebbe gestire con gradual increase di pod con la nuova versione in un Deployment Kubernetes; su App Service come detto con gli slots.
Un’altra best practice è conservare sempre gli artefatti versionati dei rilasci precedenti, in modo da poter effettuare una rapida riesecuzione di deployment (re-deploy) di una versione precedente in caso di emergenza.
e) Esempi Pratici di Release Management
· Esempio 1: Approvals e Gates in pipeline. L’azienda XYZ ha una pipeline di rilascio con stage Test e Production. Sul passaggio dalla fase Test a Prod hanno impostato: un’approvazione manuale richiesta al responsabile di reparto (ad esempio il QA lead deve cliccare Approve prima di procedere), e in aggiunta un gate automatico che controlla il risultato di qualità della build. In particolare il gate verifica tramite un’integrazione con SonarQube che la code coverage (copertura del codice) sia almeno dell’80% e che non ci siano vulnerabilità critiche aperte. Solo se entrambe queste condizioni sono vere e si ottiene l’approvazione umana, la pipeline esegue il deploy in Prod.
· Esempio 2: Canary incrementale. Per un importante servizio web, il team adotta una strategia canary sulla fase di produzione. La pipeline di deploy in Prod è configurata in modo che inizialmente aggiorni solo 1 istanza su 10 (10%) con la nuova versione. Poi si ferma per un periodo di monitoraggio di 30 minuti (usando un gate temporizzato). Durante questo tempo, metriche di monitoraggio (tramite Azure Monitor Application Insights) controllano errori e performance. Se non emergono problemi, viene approvata automaticamente (da un gate automatico magari) la continuazione e la pipeline procede ad aggiornare altre istanze fino ad arrivare al 50%. Nuovo controllo, e infine 100%. Se invece durante una di queste fasi un indicatore chiave (per esempio percentuale di errori http 500) supera una soglia, la pipeline fallisce e i responsabili ricevono una notifica. A quel punto possono decidere di effettuare un rollback rapido (manualmente o con pipeline dedicata, che ridistribuisce la versione precedente su tutte le istanze).
f) Definizioni Importanti per Release Strategies
· Stage (Fase): raggruppamento di job in una pipeline, normalmente corrispondente a un ambiente (es: Dev, QA, Prod). Il passaggio tra stage può essere condizionato o manuale.
· Environment (Ambiente): oggetto logico in Azure DevOps che rappresenta la destinazione di un deploy (può mappare un insieme di risorse: VM, container, cloud service, ecc.). Permette di gestire autorizzazioni e controlli specifici per quell’ambiente.
· Approval (Approvazione): consenso esplicito dato da una persona autorizzata per far proseguire una pipeline oltre un certo punto.
· Gate: controllo automatico eseguito da Azure Pipelines per verificare condizioni prima di avanzare. Può essere ripetuto nel tempo, ad esempio per attendere condizioni stabili.
· Canary release (Rilascio canary): strategia di deploy graduale ad una porzione crescente di utenti/istanze, con monitoraggio costante per validare la nuova versione.
· Blue-Green deployment: strategia in cui due ambienti identici (blu e verde) sono usati in alternanza; si rilascia sul “colore” attualmente non in uso e poi si sposta tutto il traffico lì.
· Rollback: tornare a una versione precedente in produzione, tipicamente eseguito se la nuova versione causa problemi.
g) Suggerimento Visivo (Descrizione Testuale)
Immaginiamo un diagramma a blocchi che raffigura tre stage di pipeline in sequenza: Dev -> Test -> Prod. Tra Dev e Test c’è un simbolo di check automatico (un ingranaggio con una spunta) che rappresenta dei gate (ad esempio controllo risultati test). Tra Test e Prod c’è un’icona di persona che dà l’ok che rappresenta l’approvazione manuale richiesta. Nel blocco Prod, per illustrare un canary, potremmo immaginare una torta suddivisa in fette 10%-50%-100% colorata man mano, a indicare che il deploy avviene prima su una piccola percentuale di server (10%), poi metà, poi tutti. Accanto, un grafico di monitoraggio stilizzato mostra una linea stabile (indicando che gli indicatori sono sotto controllo prima di proseguire). Questo disegno mentale evidenzia come su Azure DevOps si possano orchestrare rilasci molto raffinati per minimizzare rischi, con forti controlli di qualità integrati nel processo.
4. Azure Artifacts: Gestione di Pacchetti e Dipendenze
Azure Artifacts è il servizio di Azure DevOps dedicato alla gestione dei pacchetti (package management). In un processo di sviluppo tipico, le applicazioni sono composte da molti componenti e dipendenze esterne (librerie di terze parti, tool, ecc.). Azure Artifacts consente ai team di disporre di feed privati dove pubblicare e condividere in sicurezza i pacchetti, sia prodotti internamente che mirror di pacchetti esterni.
a) Caratteristiche Principali di Azure Artifacts
· Feed di pacchetti privati: Un feed è come un repository di pacchetti. Azure Artifacts permette di creare feed privati per vari tipi di pacchetto, come NuGet (per librerie .NET), npm (per moduli Node.js), Maven (per Java), Python (PyPI), e anche un tipo generico chiamato Universal Packages (per archivi arbitrari). I feed privati permettono al tuo team di pubblicare pacchetti che magari non devono essere pubblici su internet, e di controllarne l’accesso.
· Versioning e Retention: Ogni pacchetto può esistere in diverse versioni (es: 1.0.0, 1.0.1, 2.0.0, ecc. seguendo magari le convenzioni di versionamento semantico). Azure Artifacts può essere configurato per mantenere (retain) solo un certo numero di versioni per pacchetto, ad esempio le ultime 20, eliminando le più vecchie per risparmiare spazio, oppure dopo un certo periodo di tempo (Retention policy).
· Upstream Sources: Caratteristica potente per combinare feed interni con sorgenti esterne. Un upstream source è un collegamento dal feed privato a un registro pubblico (esempio: NPMjs, NuGet.org, Maven Central). Questo consente al team di usare il feed di Azure Artifacts come un proxy con caching: se qualcuno richiede un pacchetto esterno (ad es. Newtonsoft.Json versione X su NuGet) che non è già nel feed, Azure Artifacts lo recupera da NuGet.org e lo tiene in cache nel feed interno. Ciò significa che tutte le dipendenze del progetto (interne o esterne) passano dal feed, dando maggiore controllo e replicabilità (se il registro esterno non fosse disponibile temporaneamente, la copia cache nel feed interno assicura comunque la possibilità di ripristinare il pacchetto).
· Scoping per progetto/team: È possibile controllare la visibilità dei feed, ad esempio creare feed condivisi a livello di organizzazione o feed visibili solo a determinati team o progetti.
· Integrazione con le Pipeline: Azure Pipelines può pubblicare pacchetti su un feed Azure Artifacts come risultato di una build. Ad esempio, al termine di una pipeline di CI di una libreria, si può aggiungere uno step per pubblicare il pacchetto NuGet generato nel feed interno. Nelle pipeline in cui quel pacchetto è necessario, si può aggiungere l’autenticazione al feed e durante il restore delle dipendenze, il sistema preleverà il pacchetto dal feed privato. Inoltre, la gestione delle credenziali è facilitata tramite Service Connections o meccanismi di autenticazione integrati (ad esempio, Azure Artifacts fornisce un’Artifacts Credential Provider per dotnet/nuget e simili, che permette di autenticarci con le credenziali Azure DevOps).
· Strumenti per il monitoraggio delle dipendenze: Pur non essendo una funzionalità “core” del servizio Azure Artifacts stesso, è comune affiancare strumenti come Dependabot (per GitHub) o Renovate che monitorano le dipendenze dichiarate in un repository e propongono aggiornamenti automatici. In sinergia, Azure Artifacts permette di avere un luogo controllato dove arrivano queste aggiornamenti. Inoltre, includere nei processi anche la generazione di un SBOM (Software Bill of Materials, vedremo breve definizione) e l’uso di scanner di SCA (Software Composition Analysis) aiuta a individuare licenze problematiche o vulnerabilità note nelle dipendenze incluse.
· Views (Viste) di promozione: I feed di Azure Artifacts supportano il concetto di views, ad esempio creare una vista “@Local”, “@Prerelease”, “@Release” allo scopo di promuovere i pacchetti attraverso stadi di maturità. Un pacchetto pubblicato inizialmente può apparire solo nella vista di prerelease per essere testato, e poi venire “promosso” alla vista release quando stabile. Questo aggiunge un ulteriore livello di controllo su quali versioni di pacchetto sono considerate affidabili.
b) Esempi Pratici Azure Artifacts
· Esempio 1: Pubblicazione di una libreria interna. Il team Backend sviluppa una libreria .NET interna chiamata Contoso.Utils. Ogni volta che apportano modifiche e incrementano la versione, una pipeline di Azure Pipelines compila la libreria e pubblica il pacchetto NuGet risultante nel feed Contoso-Packages su Azure Artifacts. Il pacchetto inizialmente appare nella vista @Prerelease. Dopo che altri servizi hanno integrato e testato quella versione, il responsabile del pacchetto la contrassegna come valida e la promuove in @Release. In questo modo, gli altri team sapranno che la versione presente in @Release è approvata per l’uso in produzione. Inoltre, è impostata una politica di retention: solo le ultime 5 versioni marcate come release e le ultime 10 prerelease vengono conservate; le altre vengono eliminate automaticamente per non appesantire il feed.
· Esempio 2: Protezione e caching dei pacchetti npm. Un corso universitario fornisce agli studenti un feed Azure Artifacts per Node.js. Gli studenti aggiungono il feed come sorgente npm nel loro file di configurazione. L’università ha configurato un upstream verso npmjs.com, ma con delle regole: se alcune librerie hanno vulnerabilità note o licenze non compatibili, vengono bloccate. Quando uno studente esegue npm install, i pacchetti vengono scaricati dal feed interno: se il pacchetto era già stato scaricato da qualcun altro in passato, viene servito dalla cache interna (velocizzando l’installazione e riducendo il consumo di banda esterna); se è la prima volta, Azure Artifacts lo recupera da npmjs.com, ne tiene una copia e poi lo fornisce allo studente. Questo meccanismo garantisce anche che tutti usino esattamente le stesse versioni (evitando sorprese dovute a cambiamenti a pacchetti esterni se le versioni non sono fissate).
c) Definizioni Importanti per Azure Artifacts
· Package (Pacchetto): archivio che contiene un componente software riutilizzabile (libreria, modulo, etc.), spesso con metadati come numero di versione e dipendenze. Esempi: file .nupkg per NuGet, .jar per Maven, tar.gz per npm, ecc.
· Feed: raccolta organizzata di pacchetti, simile a un repository. Può avere controlli di accesso e sorgenti upstream.
· Upstream Source: collegamento configurato in un feed privato che punta a un registro pubblico o ad un altro feed. Serve per consentire il recupero e caching di pacchetti da fonti esterne tramite il feed interno.
· SBOM (Software Bill of Materials): letteralmente “distinta base del software”, è un elenco dettagliato di tutte le componenti e librerie (con relative versioni) incluse in un prodotto software. Avere uno SBOM aiuta a tracciare rapidamente se un certo sistema è affetto da una vulnerabilità appena scoperta (perché si può controllare se la libreria X versione Y è presente).
· SCA (Software Composition Analysis): pratica e strumenti per analizzare le dipendenze software (e.g. open source) identificando vulnerabilità note, licenze, obsolescenza. Esempi: OWASP Dependency Check, WhiteSource, Black Duck, Snyk, ecc.
· View (Vista): filtro o sottoinsieme di un feed di pacchetti, usato per separare diverse fasi (ad esempio pacchetti in sviluppo vs pacchetti validati).
· Retention Policy: criterio di conservazione che definisce quanti (o per quanto tempo) artefatti o pacchetti vengono conservati prima di essere automaticamente eliminati.
d) Suggerimento Visivo (Descrizione Testuale)
Proviamo a figurare un flusso di pacchetti: Un diagramma semplice potrebbe mostrare tre blocchi: Produzione del pacchetto, Promozione del pacchetto, Consumo del pacchetto. Nel blocco “Produzione”, un ingranaggio rappresenta la pipeline di build che pubblica una libreria ad esempio in versione 1.0.0 nel feed interno. Una freccia poi va verso “Promozione” con due rettangoli: uno Prerelease e uno Release; il pacchetto compare prima nel Prerelease. Dopo test, una freccia indica la promozione verso Release. Infine dal blocco Release partono frecce verso vari progetti applicativi (icona di applicazione) che durante la loro build estraggono quel pacchetto dal feed (Consumo). In parallelo, un cilindro che rappresenta npm/Maven central connesso al feed via upstream mostra che se un progetto chiede un pacchetto esterno, viene servito attraverso il feed interno (con un fulmine che indica il caching). Questo visuale enfatizza come Azure Artifacts funga da nodo centrale per pacchetti interni ed esterni, assicurando controllo delle dipendenze.
5. Azure Boards: Gestione del Lavoro e Collaborazione Agile
Lo sviluppo software non riguarda solo codice e macchine, ma anche persone e processi. Azure Boards è il componente di Azure DevOps pensato per aiutare i team a pianificare, organizzare e tracciare il lavoro in maniera efficiente, supportando metodologie agili come Scrum e Kanban e favorendo la collaborazione.
a) Elementi Fondamentali di Azure Boards
· Work Items (Elementi di lavoro): Sono il cuore di Azure Boards. Un work item rappresenta un’unità di lavoro o informazione che deve essere tracciata. Tipi comuni di work item includono:
a) Epic: un’iniziativa di alto livello che può richiedere settimane o mesi, scomposta in funzionalità più piccole.
b) Feature: una funzionalità di medio livello, spesso composta da più user story.
c) User Story (o Product Backlog Item in Scrum): una descrizione di funzionalità dal punto di vista dell’utente finale (“Come [tipo di utente] voglio [obbiettivo] così che [beneficio]”).
d) Task: un’attività tecnica da svolgere (spesso figlia di una User Story).
e) Bug: la segnalazione di un difetto da correggere.
f) Altri tipi possibili a seconda del template di processo (per esempio nel template CMMI ci sono Requirement, Change Request, ecc.).
· Stati e flusso di lavoro: Ogni work item ha un campo State (stato) che ne indica l’avanzamento (es: New, Active, Resolved, Closed, ecc., a seconda del tipo e processo). I work item seguono un flusso di lavoro definito che stabilisce quali stati esistono e come si può passare da uno stato all’altro (ad es. da Active a Resolved solo se compilati certi campi). I template di processo predefiniti (Agile, Scrum, Basic, CMMI) definiscono questi stati e il flusso, ma è possibile personalizzarli se necessario.
· Backlog e Sprint (Scrum): Per chi adotta Scrum, Azure Boards fornisce il Product Backlog, un elenco ordinato di item da fare (tipicamente Epics, Features, User Stories o PBI). È possibile pianificare iterazioni (Sprint) e assegnare un numero di item a ogni Sprint. Gli strumenti di Sprint Board aiutano a vedere i task previsti per la settimana/periodo e tracciare il completamento.
· Kanban Board: Per chi preferisce Kanban o anche per visualizzare lo stato del lavoro in corso, ogni backlog può essere visualizzato come una bacheca Kanban con colonne che rappresentano stati o fasi del flusso (To Do, Doing, Done, o più dettagliate). Sulla board si possono impostare WIP limits (Work-In-Progress limits) per limitare il numero di elementi in una colonna (ad esempio massimo 3 item in “Doing” per sviluppatore) in modo da evitare di iniziare troppi lavori senza finirne.
· Tag e Filtri: Ai work item si possono assegnare etichette (tag) per categorizzarli (es: “UI”, “Backend”, “Urgent”). È possibile creare query personalizzate per elencare work item specifici (ad esempio “tutte le bug aperte etichettate Urgent assegnate a me”).
· Dashboard e metriche: Azure Boards permette di creare dashboard personalizzate con vari widget, ad esempio un Burndown chart (grafico che mostra quanto lavoro rimanente c’è in uno Sprint nel tempo), oppure grafici di ciclo (lead time, cycle time), torte di distribuzione del lavoro per area, ecc. Queste visualizzazioni aiutano il team a monitorare il proprio processo e identificare eventuali colli di bottiglia.
· Integrazione con Repos e Pipelines: Un aspetto cruciale è che Azure Boards non vive isolato: se uno sviluppatore include nel messaggio di commit o nella descrizione della PR un riferimento al work item (es: “Fixed login bug. Work item #102”), Azure DevOps creerà un collegamento. In questo modo, si può tracciare che il work item 102 (il bug login) è stato risolto dal commit X e dalla PR Y e infine incluso nella build Z. Questa tracciabilità end-to-end consente per esempio di vedere, per ogni release, quali user story e bug sono stati completati. Addirittura, è possibile attivare automazioni: ad esempio, chiudere automaticamente un work item Bug quando la PR associata viene completata.
· Collaborazione nelle discussioni: Dentro ciascun work item c’è uno spazio per commenti e discussion. I membri del team possono scambiarsi informazioni, allegare file, menzionare utenti (@nome) per coinvolgerli, ecc. Tutto questo rimane tracciato nel contesto del item. Ad esempio, se un tester vuole chiarimenti su un bug, può menzionare lo sviluppatore direttamente nel work item bug, e la conversazione successiva rimane loggata lì.
Esempi Pratici Azure Boards
· Esempio 1: Scrum in Azure Boards. Una classe di studenti sta sviluppando un progetto in modalità Scrum con Sprint di 2 settimane. Utilizzano Azure Boards con il processo Scrum. Sul backlog di prodotto hanno elencato 20 User Story, stimate in termini di effort (ad esempio in punti). Pianificano il primo Sprint trascinando le user story più prioritarie nello Sprint 1 e assegnando task ai vari membri sotto ciascuna user story. Durante lo Sprint, usano la Sprint Board che mostra colonne “To Do / Doing / Done” per i task dello sprint corrente. Ogni giorno fanno la stand-up meeting e aggiornano la board: quando uno inizia un task, sposta la card su Doing, e quando lo completa su Done. Così tutti hanno visibilità sullo stato. Verso la fine della sprint, guardano il Burndown Chart fornito automaticamente: se la linea è sopra la traiettoria ideale, significa che sono indietro e devono recuperare o rivedere il scope. Quando chiudono lo sprint, eventuali story incompiute tornano nel backlog o vengono spostate allo sprint successivo.
· Esempio 2: Kanban con WIP limit. Un team adotta Kanban senza iterazioni fisse. Ha creato una Kanban board personalizzata con le colonne: Da Fare, In Corso, In Revisione, Completato. Impostano un WIP limit di 5 nella colonna “In Corso” per evitare di mettere troppi elementi in lavorazione contemporaneamente. Un membro del team prende un nuovo item solo se ce ne sono meno di 5 in corso. Se raggiungono il limite, si concentrano a finire quelli iniziati prima di iniziarne di nuovi. Questo li aiuta a mantenere il focus e ridurre il multitasking. Inoltre, quando un item passa in “In Revisione”, sanno che è in attesa di code review o test, e possono visualizzare facilmente se ci sono molti item bloccati in review, così da dedicarci risorse. Hanno anche definito alcune regole come Definition of Done per sapere quando possono considerare davvero completo un item (ad es. “il codice è mergiato su main, i test passano, la documentazione è aggiornata, e l’item è chiuso nel sistema”).
b) Definizioni Importanti per Azure Boards
· Work Item: elemento di lavoro tracciato (storia utente, bug, task, ecc.).
· Backlog: lista ordinata di work item da completare, tipicamente ordinata per priorità (il più importante in cima).
· Sprint: periodo di tempo (di solito 1-4 settimane) in cui un team Scrum sviluppa un incremento di prodotto. Ha un inizio e fine ben definiti e obiettivi chiari.
· Kanban: metodologia agile focalizzata sul flusso continuo del lavoro, visualizzato su una board. Non prevede iterazioni time-boxed come Scrum, ma enfatizza la gestione continua delle priorità e dei limiti di WIP.
· WIP Limit (Work In Progress Limit): numero massimo di elementi di lavoro che possono essere in uno stato (o assegnati a una persona) contemporaneamente. Serve a evitare sovraccarico e multitasking eccessivo.
· Burndown Chart: grafico che mostra nel tempo quanto lavoro rimanente c’è in uno sprint (o progetto), confrontandolo con il ritmo ideale di completamento. Aiuta a capire se il team è in anticipo, in linea o in ritardo rispetto al piano.
· Dashboard: pannello personalizzabile dove è possibile aggiungere vari widget (grafici, elenchi query, indicatori) per avere una vista d’insieme dello stato del progetto.
Suggerimento Visivo (Descrizione Testuale)
Immaginiamo la bacheca di Azure Boards: una Kanban board virtuale suddivisa in colonne To Do, Doing, Done. Ci sono delle “cards”, ovvero riquadri colorati, ciascuno corrispondente a un work item (story, task, bug). Su ogni card c’è un titolo breve (“Implementare Login OAuth”, “Correggere bug ricerca”, etc.), un’icona o avatar che indica a chi è assegnato (es. l’avatar di uno studente), e magari un’etichetta (tag) colorata per il tipo o la priorità. Alcune card hanno un piccolo icona di collegamento che indica che su quella item c’è associata una Pull Request o un Build; altre magari un’icona a forma di commento che segnala la presenza di discussioni. In cima alle colonne Kanban c’è scritto ad esempio “(WIP: 5/5)” sulla colonna Doing, segnalando che il limite di 5 elementi in corso è stato raggiunto. Ai lati, si possono immaginare grafici come il burndown chart per lo sprint corrente o un grafico a torta che mostra la distribuzione dei tipi di lavoro (X% bug, Y% user story). Questo scenario dipinge come Azure Boards consente al team di visualizzare il lavoro, capire rapidamente chi sta facendo cosa e quanto resta da fare, e di mantenere l’allineamento con gli obiettivi di progetto.
6. Qualità del Codice e Sicurezza nelle Pipeline
Un aspetto cruciale del DevOps è assicurare che la rapida iterazione non comprometta la qualità e la sicurezza del prodotto software. Azure DevOps, attraverso Azure Pipelines e integrazioni con altri strumenti, consente di automatizzare controlli di qualità e scansioni di sicurezza come parte del ciclo di build e release. Ciò riduce i difetti in produzione e previene vulnerabilità, incorporando il concetto di DevSecOps (Development, Security, Operations insieme).
a) Integrazione dei Test e Code Coverage
Durante la fase di Continuous Integration, oltre a compilare il codice è fondamentale eseguire i test automatici. Azure Pipelines supporta l’esecuzione di test unitari, test di integrazione, test UI, ecc., e la pubblicazione dei risultati. Utilizzando formati standard come JUnit, NUnit, TRX, ecc., i risultati dei test vengono aggregati e resi visibili nei dettagli della pipeline (mostrando ad esempio numero di test passati, falliti, ignorati).
Oltre al conteggio dei test, è importante misurare la coverage (copertura del codice): questa metrica indica la percentuale di righe di codice esercitate dai test. Azure Pipelines può raccogliere report di coverage generati da strumenti come Cobertura, JaCoCo, Coverlet e visualizzarli. Ad esempio, può mostrare “Code coverage: 82.3%”. Si possono impostare quality gate basati su questi numeri (ad es: non consentire il merge di una PR se la coverage scende sotto un certo valore).
b) Analisi Statica del Codice (SAST) e Analisi Dipendenze (SCA)
Durante la pipeline di CI, è buona pratica includere analisi statica del codice, ovvero strumenti automatici che analizzano il codice sorgente alla ricerca di code smell, bug potenziali o violazioni di standard di codifica. Strumenti come SonarQube o CodeQL (di GitHub) possono integrarsi in Azure Pipelines:
· SonarQube fornisce ad esempio metriche su duplicazione di codice, regole di qualità non rispettate, e classifica i problemi individuati in base alla severità (blocker, critical, etc.). Offre anche un “Quality Gate” che è una collezione di condizioni (es: almeno 80% coverage, nessun bug di severità alta aperto, percentuale di duplicazione sotto X%) che determinano se la qualità del codice è accettabile.
· CodeQL esegue query di sicurezza sul codice per scovare pattern noti di vulnerabilità (buffer overflow, injection, misconfigurazioni, ecc.), permettendo di rilevare potenziali falle.
Parallelamente, l’analisi delle dipendenze (SCA, Software Composition Analysis) è fondamentale perché molte vulnerabilità risiedono nelle librerie di terze parti. Strumenti e servizi come OWASP Dependency-Check, Snyk, WhiteSource, oppure GitHub Dependabot, verificano le versioni delle librerie usate contro database di CVE note. Azure Pipelines può includere un passo di SCA (ad esempio usando un container OWASP Dependency Check o integrando Snyk CLI) e fallire la build se viene trovata una dipendenza con vulnerabilità ad alto rischio.
c) Container e sicurezza
Se il progetto produce container Docker o OCI, si possono integrare scanner di container come Trivy (open source) o Microsoft Defender for Cloud (che ha una componente di scanning registri container). Questi scanner controllano l’immagine container finale alla ricerca di pacchetti di sistema vulnerabili o configurazioni insicure.
Microsoft ha introdotto Defender for Cloud DevOps (in anteprima) che fornisce un set di raccomandazioni di sicurezza specifiche per pipeline DevOps. Ad esempio, suggerisce di abilitare verifiche su dipendenze, di non avere segreti hard-coded, ecc., e si integra con Azure DevOps fornendo visibilità centralizzata sullo stato di sicurezza delle pipeline.
d) Enforcing Quality Gates
Azure DevOps consente di impostare delle politiche a livello di branch o di pipeline che forzano il rispetto di criteri di qualità. Ad esempio, si può impostare che una pull request non possa essere completata se la pipeline di build che include i test e l’analisi statica non dà esito positivo. Questo significa: niente codice può entrare in main se rompe i test o abbassa la copertura sotto la soglia, o se SonarQube segnala un problema critico.
Inoltre, è possibile far sì che i risultati di alcuni strumenti di sicurezza siano considerati blocking. Ad esempio, se integriamo una scansione CodeQL sulla PR, possiamo configurare che qualsiasi alert di severità alta proveniente da quell’analisi debba essere risolto prima del merge.
e) Secure Supply Chain: dal codice all’eseguibile
Con l’aumentare delle minacce supply chain (es. attacchi in cui qualcuno compromette il processo di build o i pacchetti), nelle pipeline avanzate vengono introdotti concetti come:
· Signing: firma digitale di artefatti prodotti (es. firme su file binari o container) per garantirne l’integrità e provenienza.
· Attestations: record firmati che attestano che un certo processo (build) ha eseguito determinati controlli su un codice. Ad esempio, un’attestazione può affermare “questa build ID 202 su commit ABC ha eseguito i test e li ha passati, ed è stata lanciata da pipeline definita come code in repository XYZ”.
· SBOM: come menzionato prima, generare e allegare uno SBOM all’artefatto permette di sapere esattamente cosa contiene quell’artefatto in termini di componenti software.
Azure Pipelines può generare e allegare queste informazioni e con strumenti come Microsoft DevOps Security Kit (AzSK) o mediante integrazione con sistemi esterni, aiutare il team a costruire una pipeline conforme alle best practice di sicurezza.
f) Esempi Pratici di Qualità & Sicurezza
· Esempio 1: Pipeline con gate di qualità SonarQube. Un progetto open-source gestito dagli studenti è sottoposto a controllo qualità. Hanno un server SonarQube dove la pipeline CI manda risultati ad ogni run. Hanno definito che il Quality Gate di SonarQube richiede almeno 80% di copertura, nessun bug di severità maggiore di Minor, e nessun code smell di tipo critico. Nel file pipeline YAML, inseriscono un passo che attende il risultato di SonarQube e fallisce se il Quality Gate non è passato. Di conseguenza, se uno studente introduce del codice senza test sufficiente o con problemi gravi, la pipeline fallisce e la PR non sarà mergeabile finché non vengono risolti (ad esempio scrivendo test o correggendo il codice).
· Esempio 2: Job di sicurezza su Pull Request. Per un sito web importante, la pipeline CI è stata arricchita con uno stage di sicurezza che viene eseguito su ogni pull request. Questo stage esegue:
a) CodeQL: analisi del codice per vulnerabilità note.
b) Dependency check: scansione SCA delle librerie.
c) Container scan (se produce un Docker image).
d) Se uno qualunque di questi rileva un problema con severità Alta o Critica, lo step segna la build come “failed” e produce un report dettagliato (ad esempio “Individuato uso di libreria Log4j versione vulnerabile – CVE-XXXX”).
e) La PR viene contrassegnata automaticamente con un commento di un bot che allega i risultati e invita lo sviluppatore a risolvere prima di poter procedere. Questo garantisce che nessun codice con vulnerabilità evidenti venga integrato.
g) Definizioni Importanti per Qualità & Sicurezza
· SAST (Static Application Security Testing): analisi statica di sicurezza del codice. Esegue controlli sul codice sorgente senza eseguirlo, individuando pattern insicuri.
· DAST (Dynamic Application Security Testing): analisi dinamica di sicurezza, effettuata eseguendo l’applicazione e testandone il comportamento (es. scanner web).
· SCA (Software Composition Analysis): già definito, analisi delle dipendenze software.
· DevSecOps: filosofia di integrare attivamente pratiche di sicurezza nel flusso DevOps, in modo che la sicurezza sia “built-in” in ogni passo (design, coding, testing, deployment) e non una fase finale separata.
· Quality Gate: insieme di metriche di qualità che devono essere rispettate per considerare accettabile il codice. Termine spesso usato in SonarQube.
· Attestation: attestazione di un fatto; in contesto DevOps è un pacchetto di metadati che attesta che un certo passo è stato completato rispettando certe condizioni (firmato per non poter essere alterato).
· Secure DevOps Kit / AzSK: set di estensioni e script forniti da Microsoft per aiutare a valutare la sicurezza nelle pratiche DevOps (ad esempio controlli di configurazione su Azure, su pipeline, su codice).
· Microsoft Defender for Cloud DevOps: servizio di sicurezza cloud che estende la protezione anche ai pipeline e ai repo, fornendo raccomandazioni su come migliorarne la sicurezza.
h) Suggerimento Visivo (Descrizione Testuale)
Immaginiamo una dashboard di qualità per un progetto: nella pipeline di build completata, vediamo un riquadro che riporta:
· Tests Passed: 1,530 (su 1,530) con un segno di spunta verde.
· Security Scan: Passed con un’icona a scudo verde.
· Code Coverage: 82.3% con un indicatore a barre mostrante l’obiettivo superato (magari soglia 80%). Accanto a questi, un grafico tipo tachimetro per la qualità del codice proveniente da SonarQube, che indica “Quality Gate: OK”. Se fosse visualizzato, vedremmo indicatori come “Bugs: 0, Vulnerabilities: 0, Code Smells: 5 (minor)”. Questa dashboard virtuale rende l’idea di come i risultati di test e sicurezza vengano aggregati e resi facilmente leggibili: in un colpo d’occhio il team vede che la build non solo è passata, ma soddisfa anche i criteri di qualità e sicurezza prefissati prima di procedere al rilascio.
7. Infrastructure as Code (IaC) e Configuration as Code (CaC)
L’efficacia di DevOps si estende oltre al codice applicativo: riguarda anche come gestiamo le infrastrutture e configurazioni su cui girano le applicazioni. Ecco perché nascono concetti come Infrastructure as Code (Infrastruttura come codice) e Configuration as Code (Configurazione come codice). In Azure, questi concetti permettono di automatizzare la creazione e gestione di risorse cloud, mantenendo consistenza tra ambienti e tracciando le modifiche.
a) Infrastructure as Code (IaC)
Infrastructure as Code significa descrivere l’infrastruttura (reti, server, database, servizi cloud, ecc.) con definizioni testuali, analogamente a come si scrive codice applicativo. In pratica, invece di creare manualmente risorse tramite portali o comandi imperativi, si scrivono file di configurazione dichiarativi che specificano lo stato desiderato dell’infrastruttura. Questi file poi vengono applicati attraverso strumenti che si occupano di creare/modificare le risorse per raggiungere quello stato.
Tecnologie comuni per IaC includono:
· ARM Templates: il meccanismo nativo di Azure (Azure Resource Manager Templates) basato su file JSON, che definiscono le risorse e i parametri.
· Bicep: un Domain Specific Language (DSL) per Azure che semplifica la sintassi rispetto agli ARM template JSON. Invece di scrivere JSON verboso, Bicep offre una sintassi più pulita e modulare, pur compilando in ARM template sotto il cofano.
· Terraform: uno strumento open source molto diffuso che consente di definire infrastrutture (non solo Azure, ma multipiattaforma) con un proprio linguaggio dichiarativo (HCL). Terraform tiene traccia dello stato dell’infrastruttura e applica cambiamenti in modo planificato.
· Ansible, Chef, Puppet: strumenti più orientati alla configurazione e automazione su infrastrutture esistenti (Ansible spesso usato come IaC “imperativo” combinato a dichiarativo per provisioning).
In un contesto Azure DevOps, ci si può integrare con questi strumenti facilmente:
· Si possono scrivere file Bicep/Terraform nel repository.
· La pipeline di Azure Pipelines esegue ad esempio az deployment per ARM/Bicep, oppure comandi Terraform (terraform init/plan/apply) per creare o aggiornare l’infrastruttura.
I vantaggi di IaC:
· Ripetibilità: è possibile ricreare ambienti identici partendo dallo script, utile per test e stagings.
· Versionamento: i file di infrastruttura sono nel controllo di versione (es. Azure Repos/GitHub), quindi ogni modifica all’infrastruttura è tracciata, revisionabile e correlata a commit e PR.
· Consistenza: riduce l’errore umano e la deriva configurativa; se c’è differenza tra stato reale e definito (drift), gli strumenti segnalano o correggono.
Configuration as Code (CaC)
Configuration as Code è un concetto complementare in cui anche la configurazione applicativa o di ambiente viene estratta e trattata come codice. Esempi:
· Gestione di parametri di applicazione, feature flag, connection string in sistemi dedicati come Azure App Configuration o file di configurazione versionati.
· Gestione di segreti (password, chiavi API, certificati) in sistemi sicuri come Azure Key Vault e fare in modo che le applicazioni li leggano a runtime o che le pipeline li iniettino quando necessario.
· Utilizzo di strumenti come Helm (per Kubernetes) dove i valori di configurazione per i deployment sono specificati in chart e values file.
In pratica, CaC significa evitare configurazioni manuali ad-hoc su ambienti (che poi andrebbero perse o replicate manualmente) e invece mantenere tali configurazioni dentro file o servizi controllati, con la possibilità di applicare versioning e promuovere cambiamenti in modo tramite pipeline.
b) Integrazione in Pipeline e Controlli
Un tipico scenario DevOps avanzato:
· Pipeline di infrastruttura: un pipeline dedicata che esegue, per esempio, terraform plan per mostrare quali modifiche verrebbero apportate all’infrastruttura, e poi attende l’approvazione di un responsabile (poiché cambiare infrastruttura è delicato) prima di eseguire terraform apply che effettua i cambiamenti. Tali pipeline pubblicano anche i dettagli (come il risultato del plan, log, eventuali output come indirizzi IP creati, ecc.) come artefatti o commenti.
· Validazione e linting: prima di applicare uno script IaC, la pipeline può eseguire una validazione sintattica (es. bicep build giusto per controllare che il file Bicep sia compilabile) e un lint (es. check di policy: Azure Policy può valutare un ARM template prima del deploy per vedere se viola policy aziendali).
· Approvals e Policy: come citato, spesso le pipeline di infrastruttura hanno approvazioni manuali o condizionali. Inoltre, Azure offre Blueprints e Landing Zones che sono collezioni di template, policy e configurazioni raccomandate per creare infrastrutture compliant: in DevOps possiamo incorporare questi concetti definendo che solo blueprint approvati possono essere applicati.
· Drift detection: monitorare se l’infrastruttura reale diverge dal codice dichiarativo. Alcuni tool (Terraform, in combinazione con Azure Policy) possono segnalare se qualcuno modifica manualmente risorse creando un disallineamento. Best practice DevOps vorrebbe che ogni modifica passi dal codice.
c) Esempi Pratici IaC/CaC
· Esempio 1: Pipeline Terraform. Il team Ops scrive configurazioni Terraform per l’infrastruttura di produzione. Creano un pipeline Azure DevOps dedicata: quando c’è una modifica al codice Terraform sul branch main del repo “infra”, la pipeline esegue terraform init (inizializza), terraform plan (calcola il diff). Il risultato del plan viene pubblicato come artefatto e la pipeline si mette in pausa chiedendo approvazione. Un responsabile revisione guarda il plan (che dice ad esempio “verrà creata una nuova VM, modificata la regola di sicurezza X…”) e se tutto è in ordine approva. A quel punto la pipeline procede con terraform apply che realizza i cambiamenti. Questo garantisce controllo umano su modifiche infrastrutturali evitando errori.
· Esempio 2: Gestione centralizzata delle configurazioni. Un progetto multi-ambiente (Dev, Test, Prod) evita di avere nei file di configurazione all’interno del codice le differenze tra ambienti. Invece, utilizza Azure App Configuration per memorizzare le variabili di configurazione (ad es. endpoint di API per Dev/Test/Prod, feature flag abilitate o meno, ecc.) e Azure Key Vault per i segreti (password DB, chiavi). Durante la pipeline di deploy, c’è uno step che effettua il seeding (o verifica) dei valori in App Configuration e Key Vault per l’ambiente target. L’applicazione, quando gira ad esempio in Prod, legge i suoi settaggi direttamente dal servizio di configurazione. Questo assicura che la differenza tra Dev/Test/Prod stia in queste configurazioni esterne e che tali configurazioni siano gestibili versionandole (App Configuration permette di label aggiuntivi per versionare le config) e con controllo di accesso granulare.
d) Definizioni Importanti per IaC/CaC
· IaC (Infrastructure as Code): gestione e provisioning delle risorse infrastrutturali tramite file di definizione di configurazione, applicati con strumenti automatici.
· Bicep: Domain Specific Language per Azure che semplifica gli Azure Resource Manager template. Fornisce una sintassi più leggibile e modulare per definire risorse Azure.
· Terraform: strumento di IaC open-source che supporta molte piattaforme (Azure, AWS, GCP, ecc.). Usa file .tf e un motore di esecuzione che applica le differenze in modo dichiarativo.
· Azure Blueprint: insieme di Artifacts (non confondere con Azure Artifacts) che possono includere template ARM, policy, role assignment, per definire una configurazione base ripetibile (ad esempio un intero setup di landing zone cloud).
· Landing Zone: un ambiente Azure pre-configurato con una architettura standard (reti, sottoscrizioni, policy di sicurezza, monitoraggio) su cui poi costruire le proprie applicazioni. Spesso usato in contesto enterprise come punto di partenza approvato.
· Drift (deriva): differenza tra lo stato dell’infrastruttura documentato nel codice e lo stato reale attuale. Può avvenire se qualcuno modifica manualmente risorse o se script di IaC falliscono parzialmente. Il drift è rischioso perché la definizione IaC non rispecchia più la realtà, e applicazioni successive potrebbero generare inconsistenze.
· Azure Policy: meccanismo in Azure per applicare regole di governance (es: impedire di creare un certo tipo di risorsa, imporre tag obbligatori, etc.). In contesto IaC, le policy possono validare i template prima del deploy o valutare continuamente le risorse esistenti.
e) Suggerimento Visivo (Descrizione Testuale)
Consideriamo uno schema di pipeline di infrastruttura: c’è un flusso che inizia con un’icona di file (un file Bicep/Terraform) passando in un passo di validazione (un ingranaggio che controlla sintassi/policy), poi un passo di plan (un documento con differenze “+ create, ~ modify, - delete”), poi un punto di approvazione manuale (icona di utente che approva). Dopo l’approvazione, c’è un passo di apply che crea effettivamente le risorse (icona di cloud con elementi che compaiono). Infine un simbolo di politica (bilancia) che rappresenta Azure Policy che continua a monitorare che lo stato rimanga conforme. A lato, un archivio di configurazione (icona di database) con etichetta “App Config/Key Vault” alimenta l’applicazione: ciò evidenzia che le configurazioni non sono hardcoded nel codice, ma centralizzate. Questa rappresentazione sintetizza l’approccio DevOps dove infrastruttura e config sono anch’esse trattate con rigore da codice e pipeline.
8. DevOps su Azure Kubernetes Service (AKS): Deployment e Osservabilità
Molte applicazioni moderne adottano architetture a microservizi eseguite in container. Azure offre Azure Kubernetes Service (AKS) per orchestrare container su larga scala. Integrare AKS nel proprio flusso DevOps significa poter costruire e distribuire container in modo continuo, e monitorare efficacemente l’ambiente Kubernetes.
a) Continuous Deployment su AKS
Il tipico flusso CI/CD per un’app containerizzata su AKS comprende:
1. Build dell’immagine container: la pipeline esegue il build di una Docker image (o OCI image) a partire da un Dockerfile (o altra configurazione container) presente nel repository.
2. Scansione di sicurezza dell’immagine: prima di considerare quell’immagine valida, si può fare uno scanning (es: con Trivy o con Azure Security Center/Defender) per assicurarsi che non contenga vulnerabilità note nei pacchetti di sistema.
3. Push al registro container: l’immagine viene inviata (push) a un registry. Azure offre Azure Container Registry (ACR) come registro privato per le immagini. L’immagine viene taggata con un tag di versione (ad esempio v1.2.3 o l’ID del commit).
4. Deployment su AKS: ci sono vari metodi:
o Usare kubectl con manifest YAML Kubernetes tradizionali (Deployment, Service, etc.) che sono versionati nel repo. La pipeline applica (kubectl apply) i manifest aggiornati (ad esempio aggiornando l’immagine alla nuova versione).
o Usare Helm charts se la configurazione Kubernetes è complessa; la pipeline esegue helm upgrade --install per rilasciare la nuova versione del chart con i valori appropriati (ad esempio passandogli il nuovo tag di immagine).
o Usare un approccio GitOps: in questo caso la pipeline non distribuisce direttamente su AKS, ma aggiorna un repository di configurazione (manifests GitOps) e poi un operatore nel cluster (es. Flux o Argo CD) rileva il cambiamento e sincronizza il cluster a quello stato. GitOps delega al cluster la responsabilità di applicare le modifiche osservando la sorgente dichiarativa.
5. Service Mesh / Additional steps: in contesti avanzati, potrebbero esserci step per interagire con un service mesh (es. Linkerd, Istio) o aggiornare configurazioni di routing, etc., se l’ambiente lo richiede.
b) Monitoraggio e Diagnostica su AKS
Una volta che l’applicazione è in esecuzione su AKS, Azure fornisce strumenti per l’osservabilità:
· Azure Monitor for Containers (Container Insights): integrabile con AKS, raccoglie log (ad esempio, log dei container, log di sistema Kubernetes) e metriche (utilizzo CPU/memoria per pod, numero di pod in un deployment, stato nodi, ecc.). Questo permette di avere nei log analytics e nei grafici di Azure Monitor una visibilità su come sta andando il cluster e le applicazioni.
· Prometheus e Grafana: AKS può essere configurato con l’addon di Container Insights che esporta dati in un workspace Log Analytics, ma alcuni preferiscono usare il classico stack open-source: Prometheus per raccogliere metriche dal cluster e dalle app (spesso con exporter), e Grafana per visualizzarle. Azure Monitor può comunque consumare metriche Prometheus grazie a configurazioni integrate oppure tramite Managed Grafana.
· Dashboard Kubernetes: esiste una dashboard web di Kubernetes (che però su AKS va abilitata e protetta opportunamente), anche se molte info possono essere ottenute tramite Azure Portal che mostra informazioni sul cluster e i nodi, e tramite Visual Studio Code con plugin k8s per sviluppatori.
c) Considerazioni di Sicurezza su AKS
· Workload Identity: tradizionalmente, le applicazioni su AKS usavano un approccio chiamato Managed Identity (o pod identity via add-on) per accedere in sicurezza ad altre risorse Azure (come Key Vault). Recentemente, si spinge per l’adozione di Workload Identity integrato con Azure AD (Microsoft Entra ID): in breve, i pod Kubernetes possono ottenere un’identità federata con Azure AD e ottenere token accesso a risorse senza bisogno di segreti statici. Questo aumenta la sicurezza eliminando la necessità di conservare credenziali nel cluster.
· Network Policies: in AKS (soprattutto su network plugin Azure CNI) si possono utilizzare network policy (Calico, Azure NP) per controllare la comunicazione tra i pod su layer di rete, migliorando l’isolamento (ad es. definire che il pod del database accetta traffico solo dal pod dell’app e non dagli altri).
· Azure Policy for AKS: Azure Policy offre degli add-on per AKS che possono, ad esempio, impedire la creazione di pod privilegiati, assicurare che certi label siano presenti, o che i container non usino immagini da registri non autorizzati. Ciò integra la governance anche a livello cluster Kubernetes.
· Aggiornamenti e Scalabilità: conviene mantenere AKS aggiornato alle ultime versioni stabili di Kubernetes (Azure fornisce upgrade semi-automatici). Per la scalabilità, AKS supporta Horizontal Pod Autoscaler (HPA) per scalare automaticamente il numero di pod in base a metriche (es: CPU, o metriche custom come lunghezza di coda richieste), e il Cluster Autoscaler per aggiungere/rimuovere nodi a seconda del carico.
Esempi Pratici DevOps su AKS
· Esempio 1: Pipeline con build e deploy su AKS. Per un progetto di microservizi, la pipeline CI/CD esegue per ogni servizio: build immagine Docker, push su ACR, poi utilizza kubectl per aggiornare i manifest Kubernetes in un repository di manifest (opzione GitOps) o direttamente applica su cluster dev. Hanno predisposto un chart Helm per facilitare il deploy: la pipeline esegue helm upgrade --install nomeapp chart/ --set image.tag=abc12345 (dove abc12345 è il tag dell’immagine corrispondente al commit corrente). Dopo il deploy, chiamano un job che esegue test endpoint sull’application appena deployata (smoke test) per verificarne la salute. I log del deploy e degli eventuali rollback (Kubernetes in caso di problemi può fare rollback se un readiness probe fallisce troppo a lungo) sono collezionati negli output.
· Esempio 2: GitOps puro. Un altro team preferisce GitOps: hanno un secondo repository chiamato “prod-config” dove vivono i file YAML che descrivono lo stato desiderato di tutti i servizi in produzione. Quando la pipeline di build di un servizio produce una nuova immagine, invece di distribuire direttamente, apre in automatico (con uno script) una pull request sul repo “prod-config” modificando il tag dell’immagine da v1.2.2 a v1.2.3. Il team ops revisa quella PR e la unisce. Un operatore Flux installato sul cluster AKS monitorizza il repo “prod-config” e vede la modifica: in pochi minuti, applica la nuova configurazione al cluster (scarica la nuova immagine e aggiorna il deployment). Questo metodo assicura che lo stato dichiarato (il repo config) sia sempre la fonte di verità di cosa dovrebbe girare sul cluster, e ogni modifica è tracciata via PR.
d) Definizioni Importanti per DevOps su AKS
· AKS (Azure Kubernetes Service): servizio Azure che fornisce un cluster Kubernetes gestito (Azure gestisce il control plane, l’utente gestisce i nodi workernode). Permette di eseguire container su larga scala orchestrati.
· Docker/OCI Image: pacchetto immutabile che contiene l’applicazione e l’ambiente di runtime necessario (sistema base, dipendenze). OCI è uno standard che include Docker come implementazione. Le immagini sono versionate con tag.
· Azure Container Registry (ACR): registro privato cloud per immagini container e altri artifact OCI, integrato con Azure (per autenticazione, scanning, georeplica, webhooks).
· Helm: gestore di pacchetti per Kubernetes. Un Helm chart è un pacchetto che contiene templati YAML Kubernetes parametrizzabili, utile per distribuire applicazioni complesse configurandole con un file values.
· GitOps: modello operativodove lo stato desiderato del sistema (infrastruttura o applicazioni) è rappresentato in un repository Git. Qualsiasi modifica a tale repo, soggetta a controllo di versione, viene automaticamente applicata al sistema attraverso un processo di sincronizzazione continua. FluxCD e ArgoCD sono popolari implementazioni per Kubernetes.
· HPA (Horizontal Pod Autoscaler): componente Kubernetes che regola automaticamente il numero di pod in esecuzione per un deployment a seconda di metriche (es: aumenta i pod se CPU > 70% per più di X minuti, riduci se < 30%, etc.).
· Readiness/ Liveness probe: controlli definiti per i container: i readiness probe indicano se un container è pronto a ricevere traffico (il kube-proxy lo escluderà dal servizio finché non è pronto), i liveness probe indicano se un container è vivo o bloccato e permettono a Kubernetes di riavviare quel container automaticamente se falliscono.
· Pod Disruption Budget (PDB): regola che indica a Kubernetes quanti pod possono essere contemporaneamente down durante operazioni pianificate (es: drain di nodi) per assicurare che un numero minimo rimanga sempre up. Utile per mantenere alta disponibilità durante manutenzioni.
e) Suggerimento Visivo (Descrizione Testuale)
Possiamo immaginare un disegno che collega pipeline e cluster: a sinistra un flusso CI produce un’immagine container (rappresentata da un cubo con il logo Docker), questa viene pushata ad un Container Registry (un cilindro con il logo ACR). In seguito, una freccia porta a un’icona del Cluster Kubernetes (AKS). Sopra questa freccia ci sono icone di scudo (per il passo di scanning sicurezza) e un ingranaggio (per il deploy applicativo). Il cluster AKS è disegnato come un insieme di tre macchine/nodi su cui girano diversi container (piccoli cubi colorati) chiamati cart-service, catalogue-service, etc., con indicatori verdi “Ready”. Accanto al cluster c’è un grafico e lente di ingrandimento a indicare monitoraggio, e un simbolo di rete con lucchetto a indicare policy di sicurezza. Questo mostra come il codice passa da sorgente a container, viene distribuito sul cluster, e poi viene monitorato e governato in esecuzione, tutto orchestrato da pipeline DevOps integrate con Azure.
9. Governance e Compliance con Azure DevOps e Azure
Implementare DevOps su scala aziendale implica non solo automatizzare, ma anche mantenere il controllo su cosa viene fatto, da chi e in che modo. Governance e Compliance sono termini che indicano, rispettivamente, la gestione di linee guida/criteri per l’IT e l’aderenza a norme interne o esterne (sicurezza, normative legislative, standard industriali). Azure DevOps insieme ad Azure offre strumenti per assicurare che i processi di sviluppo e rilascio rispettino tali regole.
a) Policy e Controlli su Azure
Azure Policy è un servizio di Azure che permette di definire e applicare regole a livello di sottoscrizione o gruppo di risorse. Ad esempio:
· Consentire solo la creazione di risorse con private endpoint (niente accessi pubblici su database).
· Richiedere che tutte le risorse abbiano certe tag (es: “costCenter” per la contabilità).
· Impedire l’uso di tipi di risorsa o SKU specifici (es: macchine virtuali di serie non approvata).
· Forzare la crittografia di dischi o il geo-redundancy su storage.
Azure Policy valuta continuamente lo stato delle risorse e fornisce una percentuale di compliance (conformità) rispetto alle regole assegnate. Ad esempio, si potrà vedere che su 100 risorse, 64% sono conformi e 36% non conformi a una certa iniziativa (insieme di policy). Questo appare su cruscotti e permette di individuare deviazioni.
b) Governance in Azure DevOps
All’interno di Azure DevOps, esistono meccanismi di governance:
· Branch policies e approvazioni di cui abbiamo parlato, che sono un tipo di governance tecnica sulla qualità del codice.
· Required Templates: Azure DevOps può richiedere che in una cartella repository siano presenti file specifici (ad esempio un file di sicurezza) o che le pipeline includano determinati template prima di poter operare. Questo può essere considerato come linee guida imposte centralmente (ad esempio: “ogni pipeline deve importare il template di sicurezza standard”).
· Apertura controllata: Non tutti possono fare tutto: Azure DevOps ha permission granulari per chi può creare pipeline, chi può modificarle, chi può accedere a feed di pacchetti, ecc. Un buon setup di governance definisce ruoli e permessi in modo rigoroso (esempio: solo il DevOps lead può creare pipeline di deploy in produzione, gli sviluppatori normali possono eseguire ma non modificarle).
· Auditing: Azure DevOps fornisce un log di audit (tracciamento) delle azioni importanti: es. chi ha cambiato i permessi, chi ha cancellato un pipeline, chi ha aggiunto un nuovo variabile segreta, ecc. Questo è utile per investigare incidenti o garantire accountability.
c) Monitoraggio e Osservabilità dei Processi DevOps
Su Azure si può abilitare la diagnostica per Azure DevOps (che essendo un servizio cloud, di base è fuori dai classici log di Azure, ma fornisce integrazioni) e inviare log a Azure Monitor/Log Analytics:
· Si possono creare Workbooks su Azure Monitor che combinano dati: ad esempio, incrociare dati di pipeline (es: frequenza di fallimento delle build) con metriche di infrastruttura (es: correlare se i fallimenti aumentano quando c’è bassa memoria disponibile su agent self-hosted, etc.).
· Monitorare i deployment: contare quante release sono state fatte nell’ultimo mese, quante di successo vs fallite.
· Monitorare i repository: es, numero di commit per settimana, numero di PR aperte/chiuse, tempo medio di code review (questo con Azure DevOps APIs e poi visualizzando con PowerBI o workbooks).
Defender for Cloud DevOps (menzionato anche prima) fornisce un layer di raccomandazioni: ad esempio, evidenzia se in un repo ci sono credenziali in chiaro, se una pipeline usa token con privilegi eccessivi, se mancano check di qualità, etc. Questo fa parte della governance della supply chain.
d) Sicurezza e Minimo Privilegio
Un principio di compliance importante è Least Privilege (Minimo privilegio): ogni utente o servizio dovrebbe avere accesso solo a ciò che gli serve. In Azure DevOps, questo significa:
· Usare Service Connection specifiche con scope limitato per pipeline che devono distribuire su Azure (es: una service connection config di solo contributo su un gruppo risorse e non su tutta la sottoscrizione se possibile).
· Preferire meccanismi temporanei per accessi: ad esempio, usare token di accesso personale (PAT) con scadenza breve per script, oppure Managed Identities invece di chiavi statiche per far comunicare pipeline e Azure.
· Abilitare Conditional Access e autenticazione Multi-Factor per gli utenti che accedono all’organizzazione Azure DevOps, soprattutto se si gestiscono asset critici.
· Gestire bene i gruppi di sicurezza (Project Collection Admins, Project Admins, Contributors, Readers, ecc.) assicurando che le persone siano nei gruppi corretti e rimuovendo accessi non necessari tempestivamente.
e) Esempi Pratici Governance & Compliance
· Esempio 1: Policy e compliance. L’IT di un’azienda impone che tutte le risorse cloud abbiano un tag Environment (Dev, Test, Prod) e un tag Owner. Creano in Azure Policy una definizione che neghi la creazione di risorse che non hanno quei tag. Questo implica che se una pipeline di IaC di uno sviluppatore tenta di creare una risorsa senza tag, Azure la rifiuterà, forzando il team a conformarsi. Sul portale Azure, l’ufficio IT controlla regolarmente il compliance report: idealmente 100% delle risorse rispettano la policy; se qualcosa è non compliant (ad es. una risorsa creata prima della policy e senza tag) viene sanata aggiungendo il tag mancante.
· Esempio 2: Audit in Azure DevOps. Dopo un incidente (es: è stato cancellato per errore un feed di Artifacts interno causando disservizi), il team vuole capire cosa è successo. Usano la funzionalità di audit log di Azure DevOps e scoprono che l’account di uno stagista, per un misunderstanding, ha eseguito l’azione. Grazie all’auditing sanno esattamente quando e chi. Questo evento porta a migliorare la governance: lo stagista viene tolto dal gruppo di permessi che consentiva di eliminare feed, lasciandogli solo permessi di lettura. Inoltre abilitano notifiche per certe azioni critiche (ad esempio se viene creato/eliminato un progetto o un feed, un amministratore riceve un alert).
· Esempio 3: Monitoring DevOps process. Il team DevOps crea un workbook su Azure Monitor che mostra: “Tempo medio di esecuzione delle pipeline di build”, “Numero di rilasci in Prod questo mese”, “Percentuale di compliance Azure Policy delle risorse di Prod”, tutto in un’unica pagina. Notano ad esempio che quando la compliance scende (qualche risorsa non compliant), spesso coincide con un aumento di errori nelle pipeline (forse perché qualcuno ha creato risorse manualmente senza seguire il processo, causando incoerenze). Così possono puntare i riflettori su quegli eventi e intervenire in futuro con formazione o ulteriori automatismi.
f) Definizioni Importanti per Governance & Compliance
· Governance: insieme di processi, regole e controlli con cui un’organizzazione gestisce e controlla le risorse IT in accordo con le proprie politiche e regolamentazioni necessarie.
· Compliance (Conformità): lo stato di allineamento a tali regole/policy. In Azure, spesso espresso in percentuale di risorse che rispettano le policy.
· Azure Policy: servizio di Azure per definire regole di governance applicate sulle risorse cloud.
· Auditing (Audit log): registro delle azioni compiute in un sistema, utile per verifiche e indagini a posteriori.
· Security Development Lifecycle (SDL): processo di sviluppo software con sicurezza integrata in tutte le fasi (dai requisiti, design, implementazione, test, release). Microsoft ha un SDL adottato internamente che fissa linee guida.
· Least Privilege: principio del minimo privilegio, ovvero dare agli utenti/sistemi solo i permessi strettamente necessari e niente di più, per limitare i danni potenziali di errori o compromissioni.
· Workbook Azure Monitor: strumento interattivo di Azure Monitor per creare report e dashboard personalizzati a partire dai dati di log, metriche e altre origini (può combinare testo, grafici, query log in un unico display).
Suggerimento Visivo (Descrizione Testuale)
Per rappresentare visivamente governance e compliance, immaginiamo un cruscotto stile gestore IT:
· Da un lato, un grafico a barre mostra Compliance 64% magari in giallo, e un elenco di policy con segni rossi per quelle violate da qualche risorsa.
· Dall’altra, un grafico a linee mostra l’andamento dei deploy (es: numero di release al mese).
· In mezzo, un icona di scudo con ingranaggio rappresenta Defender for Cloud DevOps, e un libro aperto stilizzato rappresenta un Workbook combinato.
· Inoltre, potremmo vedere una tabella “Utente – Azione – Data” che richiama l’audit log.
· In un angolo, il logo di Azure DevOps con un lucchetto sopra a simboleggiare le permission e il controllo accessi. Questa composizione dà l’idea che oltre a sviluppare e rilasciare velocemente, stiamo mantenendo d’occhio che tutto avvenga secondo regole, in modo trasparente e controllato.
10. Organizzazione dell’Account, Permessi e Scalabilità dei Progetti
L’ultimo tassello del panorama Azure DevOps riguarda come strutturare e amministrare l’ambiente DevOps stesso quando i team crescono e i progetti si moltiplicano. Azure DevOps è una piattaforma flessibile che può supportare dall’hobbista con un singolo progetto, fino a organizzazioni enterprise con decine di team e centinaia di progetti.
a) Organization e Projects
Il contenitore principale in Azure DevOps è chiamato Organization. Quando si crea un account Azure DevOps si ha almeno una Organization (spesso nominata con il nome dell’azienda o team). All’interno di un’Organization, si possono creare uno o più Project. Un Project è una unità separata che contiene i propri repository, pipeline, boards, artifact feed, ecc. I progetti sono utili per isolare contesti: ad esempio, un’azienda può avere un progetto per ogni prodotto o linea di business. All’interno dello stesso progetto, è facile collegare elementi tra loro (es. commit e work item) e condividere risorse; tra progetti diversi, la separazione è più netta (anche se esistono meccanismi per collegare ad esempio work item tra progetti o usare feed artifact cross-progetto, previa autorizzazione).
b) Security e Accessi
I permessi in Azure DevOps sono granulari e ereditabili. Si basano su:
· Scope (ambito): c’è una gerarchia di ambiti: Organization -> Project -> (all’interno di Project: repos, pipelines, artifacts feed, boards area paths, ecc.).
· Gruppi di Sicurezza: Azure DevOps definisce gruppi built-in (es. Project Collection Administrators a livello org, Project Administrators a livello progetto, Contributors, Readers, Build Administrators, ecc.). Si possono creare anche gruppi custom e includere utenti o gruppi Azure AD.
· Access levels: i singoli utenti inoltre hanno un livello d’accesso licenziato: ad esempio Basic (standard per sviluppatori, permette accesso completo a tutto di quell’organizzazione per cui hanno permessi), Stakeholder (gratuito ma limitato: accesso solo a work item e poche altre funzionalità, pensato per membri non tecnici come manager, clienti per veder lo stato), o livelli avanzati (Basic+TestPlans se servono le funzionalità di test avanzate).
Un esempio: uno sviluppatore classico ha Access Level Basic, ed è messo nel gruppo Contributors del progetto X. In quel progetto, avrà i permessi predefiniti di contributor: può contribuire al codice, modificare work item, eseguire pipeline, ma non potrà ad esempio cancellare il progetto, cambiare impostazioni di repository protetti, o cambiare i permessi per altri.
Le pipeline e gli altri service possono avere identità di servizio. Ad esempio una Service Connection per Azure è essenzialmente un’identità (come un’app registrata in Azure AD con certificato o un Service Principal) con permessi su risorse Azure, memorizzata in DevOps per l’uso nelle pipeline. Queste connessioni sono a livello progetto o org e anch’esse hanno controlli (es: un admin deve autorizzare l’uso di una nuova service connection in una pipeline la prima volta).
È importante anche gestire PAT (Personal Access Token) e altri token con scadenza e rotazione, e preferire meccanismi integrati (ad esempio usare Oauth integrato con Azure AD per non usare credenziali fisse nelle pipeline).
Azure DevOps supporta l’integrazione con Azure AD per controllare l’accesso (ad es. fare in modo che solo persone nel tenant aziendale possano accedere all’organizzazione, usare conditional access policies come MFA, ecc.). È possibile anche usare gruppi Azure AD direttamente per assegnare ruoli (invece di gestire utenti singolarmente).
c) Organizzare molti Team
Dentro un progetto, specialmente se grande, si possono definire Area Path e Iteration Path per organizzare il lavoro di team differenti o componenti differenti, pur restando nel medesimo progetto. Ad esempio, il progetto “App Web” potrebbe avere area path “Frontend” e “Backend” e team separati che filtrano i work item in base all’area. Oppure un area path per ogni gruppo di componenti. Le Iterations invece definiscono calendari di sprint o milestone.
Quando serve, però, separare il lavoro in progetti diversi può essere utile per isolare permessi (es: un fornitore esterno lavora solo sul progetto X e non vede nulla del progetto Y), o per evitare che troppi artefatti diversi siano mischiati (ogni progetto genera proprie pipeline, backlog, ecc. e non “inquina” la vista degli altri).
d) Riutilizzo e Scalabilità
In ambienti complessi, per evitare duplicazione e facilitare standard:
· Si possono creare template di pipeline riutilizzabili (YAML template) che vivono in un repo centralizzato, cosicché tutti i team li importano. Esempio: un template di pipeline standard per build .NET, un template per scanning sicurezza, ecc. Quando bisogna aggiornarlo (es: aggiungere un nuovo step di sicurezza), basta modificare il template centralizzato e tutti i pipeline che lo includono beneficeranno del cambiamento.
· Artifact feeds condivisi: magari tutti i progetti usano un feed di artifact comune per condividere librerie. Questo feed può risiedere in un progetto dedicato “Central Packages” e gli altri progetti vi accedono con permessi di sola lettura.
· Environments e approvazioni centralizzate: se più progetti devono distribuire su un medesimo ambiente Prod (ipotizziamo microservizi su un cluster condiviso), quell’environment Prod in Azure DevOps può essere definito a livello di org e condiviso, e un gruppo di approvatori unico definito per esso. In questo modo, qualunque pipeline di qualunque progetto che vuole rilasciare su quell’ambiente attiverà lo stesso meccanismo di approvazione e logging.
Azure DevOps è progettato per scalare: tanti team possono lavorare in parallelo, e tramite la personalizzazione di processi e ruoli, ciascuno vede e interagisce solo con ciò che gli è pertinente.
e) Esempi Pratici di Organizzazione & Permessi
· Esempio 1: Progetti e Team. Una software house ha 3 prodotti, crea 3 Project separati: Prodotto A, Prodotto B, Prodotto C. Tutti gli sviluppatori sono nella stessa Azure DevOps Organization (ACMECorp). Alcuni sviluppatori lavorano su più progetti, altri solo su uno. I permessi vengono gestiti con gruppi: es. gruppo “Team A Devs” con accesso di Contributor al Progetto A, “Team B Devs” per Progetto B, e così via. Così se uno sviluppatore cambia team, basta spostarlo di gruppo. I manager di ciascun prodotto sono messi come Project Administrators nel rispettivo progetto, così possono gestire backlog e permessi del loro progetto ma non toccare quelli degli altri. Un feed di pacchetti centralizzato “ACME Shared Libraries” è creato nel Progetto A e condiviso in lettura a Progetto B e C, perché library comuni risiedono lì.
· Esempio 2: Stakeholder e Access Levels. Un professore che fa da cliente per un progetto studentesco vuole solo visualizzare l’andamento: viene aggiunto come utente di tipo Stakeholder (non conta sulle licenze a pagamento) e riceve permessi di leggere il progetto. Può vedere le Boards (backlog, sprint, work item) e i risultati delle pipeline, ma non può modificare codice né lanciare pipeline. Questo è sufficiente per fare review delle user story implementate e commentare priorità, senza rischi.
· Esempio 3: Service Connection e Managed Identity. Una pipeline di deploy su Azure necessita di permessi su una risorsa (es: fare web deploy su un App Service). Invece di utilizzare username/password pubblicate negli script (sarebbe pericoloso), il team crea una Service Connection in Azure DevOps di tipo Azure Resource Manager collegata ad una Managed Identity appositamente creata su Azure con permessi solo sul resource group dell’App Service. La prima volta che la pipeline userà questa service connection, un admin l’autorizza. Da quel momento la pipeline può effettuare il deploy e Azure DevOps penserà a gestire il token per l’identità, la pipeline non espone mai segreti.
f) Definizioni Importanti per Organizzazione & Permessi
· Organization (Org): livello più alto di contenimento in Azure DevOps, può contenere più progetti, utenti e gruppi.
· Project: unità in Azure DevOps che contiene repository, pipeline, boards, artifact feed, ecc. isolati. I nomi dei progetti sono univoci per org.
· Security Group: insieme di utenti con ruoli predefiniti (Contributors, Readers, ecc.) o personalizzati, a cui sono associati permessi su uno scope.
· Access Level: licenza/diritti generali dell’utente (Basic, Stakeholder, ecc.) che ne abilitano o meno certe funzioni (Stakeholder ad esempio non può vedere i codici sorgente né eseguire build).
· Service Connection: configurazione sicura in Azure DevOps per collegare pipeline a servizi esterni (Azure, GitHub, Docker registries, ecc.) memorizzando le credenziali in modo protetto.
· Managed Identity: identità gestita da Azure associabile a risorse (VM, App Service, o entità logiche), che consente a quell’entità di autenticarsi senza avere chiavi statiche. In DevOps, spesso la service connection può assumere una managed identity per eseguire operazioni su Azure senza gestire segreti.
· Conditional Access: funzionalità di Azure AD per imporre condizioni addizionali all’accesso (es: richiedi MFA, limita l’accesso da reti corporate, ecc.) che possono essere applicate anche agli utenti Azure DevOps se l’organizzazione è collegata all’AD.
· Area Path/Iteration: categorizzazioni usate in Boards per suddividere lavoro per aree funzionali (area path) o per cicli temporali (iteration/sprint).
g) Suggerimento Visivo (Descrizione Testuale)
Possiamo sintetizzare la struttura e permessi in una matrice mentale: Immagina una tabella con righe per Org, Project A, Project B e colonne per Admin, Contributor, Reader. Nelle celle ci sono alcuni nomi di utenti o gruppi: es. alla riga Org/Admin c’è il team IT, alla riga Proj A/Admin c’è Alice (project manager di A), Proj A/Contributor ci sono Dev Team A, Proj B/Reader c’è un stakeholder esterno, ecc. Questo visualizzerebbe la matrice di permessi. Accanto, un diagrammino a blocchi: un blocco grande “Organization” che contiene due blocchi “Project A” e “Project B”. Nel blocco Org c’è un simbolo di globo (impostazioni globali, collection admin), nei blocchi Project compaiono icone per Repos, Pipelines, Boards, etc. Un’icona indica che c’è un feed Artifacts nel Progetto A che è condiviso con B (freccia da A a B). Questo comunica come è organizzato l’ambiente Azure DevOps e come i ruoli si distribuiscono per garantire che la collaborazione avvenga in modo ordinato e sicuro.
11. Tabella Riepilogativa dei Servizi DevOps Principali
Di seguito una tabella che riepiloga i principali servizi di Azure DevOps trattati e le loro funzionalità chiave:
Servizio Azure DevOps
Scopo Principale
Caratteristiche Chiave
Azure Repos
Controllo versione del codice (Git/TFVC)
Repository Git privati illimitati; gestione branch (branch policy, protezione branch); pull request con code review; integrazione con work item; supporto TFVC centralizzato per progetti legacy.
Azure Pipelines
Continuous Integration/Delivery (CI/CD)
Pipeline di build e release (YAML as code o classiche); agent cloud o self-hosted; integrazione con GitHub/Azure Repos (trigger CI, PR validation); multi-stage deploy su ambienti; gestione variabili e segreti; pubblicazione artefatti; supporto test e analisi qualità integrata.
Azure Boards
Project management Agile
Work item tracciabili (Epic, User Story, Task, Bug); backlog e sprint planning (Scrum); bacheche Kanban con WIP limit; dashboard e report (burndown, lead/cycle time); collegamento tra commit/PR e work item per tracciabilità; notifiche e discussioni integrate.
Azure Artifacts
Gestione pacchetti e dipendenze
Feed privati per pacchetti (NuGet, npm, Maven, Python, Universal); controllo versioni pacchetti e retention policy; upstream sources per caching registri pubblici; integrazione con pipeline (pubblica e utilizza pacchetti in CI/CD); viste (prerelease/release) per promuovere pacchetti; controllo accessi sui feed per team/progetti.
Nota: Azure DevOps include anche Test Plans (per gestione test manuali e di accettazione) che non è stato approfondito in questo ebook. Inoltre, molte funzionalità trasversali (come il controllo di qualità, la sicurezza, la gestione di infrastruttura) sono potenziate integrando servizi Azure (es. Azure Policy, Key Vault, etc.) con i processi orchestrati via Azure DevOps.
Conclusioni
Adottare Azure DevOps come piattaforma per il ciclo di vita del software porta numerosi benefici ad un team, specialmente per studenti che si affacciano al mondo dello sviluppo professionale:
· Flusso unificato e coeso: Tutti gli strumenti necessari (coding, planning, building, releasing) sono raccolti in un’unica suite integrata. Questo significa meno tempo speso a “incollare” strumenti diversi e più coerenza nei processi. Ad esempio, un work item su Boards è collegato direttamente ai commit su Repos e alle build su Pipelines, dando visibilità end-to-end.
· Automazione e velocità: Con Pipelines, attività che prima richiedevano interventi manuali (eseguire build, test, deployment) vengono automatizzate e ripetute in modo affidabile. Ciò riduce gli errori umani e permette rilasci più frequenti e regolari. Per una squadra di studenti, automatizzare build/test significa spendere più tempo a programmare e meno a configurare ambienti a mano.
· Migliore qualità del software: Grazie a meccanismi come code review (pull request), continuous testing, analisi statica e policy di qualità, i problemi vengono intercettati prima che il codice raggiunga l’utente finale. L’integrazione di test e verifiche di sicurezza nel processo standard garantisce che la qualità non sia un ripensamento ma un elemento integrato.
· Collaborazione effettiva: Azure DevOps è progettato per supportare il lavoro di squadra. Che si tratti di commentare del codice in una PR, di discutere un bug in Boards, o di condividere un pacchetto via Artifacts, la piattaforma facilita la comunicazione contestuale. Questo è formativo per studenti: imparano pratiche di collaborazione simili a quelle che troveranno nel mondo del lavoro IT.
· Trasparenza e tracciabilità: Ogni modifica, ogni commit, ogni build è tracciata e collegabile a motivi e persone. Per un project leader o un insegnante, è facile vedere lo stato di avanzamento, capire cosa è incluso in una determinata release (grazie ai collegamenti work item-commit) e verificare il contributo di ciascuno.
· Flessibilità e estensibilità: Azure DevOps si adatta sia a piccoli progetti singoli, sia a organizzazioni con centinaia di sviluppatori. I team possono iniziare semplici (ad esempio con una pipeline base e un solo repo) e poi crescendo attivare funzionalità più avanzate (multi-repo, microservizi, compliance rigida, ecc.). Inoltre, la piattaforma è estendibile: esistono marketplace di estensioni per integrare strumenti di terze parti, e API per automatizzare o personalizzare flussi particolari.
· Adozione di DevOps culture: Forse il beneficio più grande è l’impatto culturale: strumenti come Azure DevOps incoraggiano ad adottare mentalità DevOps – ossia, abbattere i silos tra dev e ops, prendere responsabilità condivisa per il prodotto finito, iterare rapidamente ma in modo controllato e misurabile. Gli studenti usando Azure DevOps imparano non solo la tecnica, ma anche un modo di lavorare collaborativo e orientato al miglioramento continuo.
In sintesi, Azure DevOps offre un ecosistema completo per implementare DevOps. Dall’idea iniziale (work item) fino al deployment in produzione e oltre (monitoraggio e feedback), tutti i passi possono essere gestiti con un elevato grado di automazione e controllo. Ciò si traduce in software consegnato più velocemente, con meno difetti e in modo prevedibile. Per gli studenti, acquisire padronanza di questi strumenti significa prepararsi a entrare in team aziendali già allineati a queste pratiche, portando valore aggiunto con la capacità di navigare e ottimizzare pipeline di sviluppo moderne.
Azure DevOps sposa la filosofia per cui “ogni azienda è un’azienda di software”: fornisce i mezzi per realizzare questa visione, dove la collaborazione è al centro, sostenuta da processi solidi e tecnologia all’avanguardia. Che si tratti di un progetto accademico, di una startup, o di una grande impresa, l’adozione di un approccio DevOps con Azure abilita a essere più agili, responsivi e focalizzati sulla qualità, caratteristiche fondamentali per avere successo nel panorama tecnologico odierno.
Riepilogo capitolo
Il capitolo fornisce una panoramica dettagliata dei principali servizi di Azure DevOps, spiegando le funzionalità di controllo versione, integrazione continua, gestione del lavoro, gestione pacchetti, qualità del codice, infrastruttura come codice, DevOps su Kubernetes, governance e organizzazione degli account.
· Azure Repos e controllo versione: Azure Repos supporta Git e TFVC per la gestione del codice sorgente, offrendo repository Git privati illimitati, gestione di branch, pull request con revisione del codice e branch policy per garantire qualità e sicurezza. Si integra con Azure Boards per tracciare il lavoro associato ai commit.
· Azure Pipelines e CI/CD: Azure Pipelines automatizza build, test e rilascio con pipeline definite in YAML versionate insieme al codice. Supporta agent cloud o self-hosted, integrazione con GitHub e Azure Repos, multi-stage deploy, gestione di variabili, segreti e artefatti. Permette il monitoraggio dettagliato delle esecuzioni e notifiche.
· Strategie di rilascio e controlli di qualità: Le pipeline multi-stage consentono di definire fasi di deploy su ambienti diversi (Dev, Test, Prod) con approvazioni manuali, gate automatici e strategie di rilascio avanzate come canary release, blue-green deployment e rollback automatico per minimizzare i rischi.
· Azure Artifacts per pacchetti: Gestisce feed privati per pacchetti NuGet, npm, Maven, Python e Universal, con versioning, upstream sources per caching di pacchetti esterni, viste di promozione (prerelease/release) e integrazione con pipeline per pubblicazione e consumo sicuro dei pacchetti.
· Azure Boards e gestione agile: Strumento per pianificare e tracciare il lavoro tramite work item (Epic, Feature, User Story, Task, Bug), backlog, sprint planning Scrum, Kanban board con limiti WIP, dashboard e integrazione con commit e PR per tracciabilità completa. Supporta discussioni e collaborazione integrata.
· Qualità del codice e sicurezza nelle pipeline: Azure Pipelines integra test automatici, code coverage, analisi statica del codice (SAST), analisi delle dipendenze (SCA) e scansione container per garantire qualità e sicurezza. È possibile imporre quality gate per bloccare merge di codice non conforme e integrare firme digitali e attestazioni per la supply chain sicura.
· Infrastructure as Code e Configuration as Code: Descrive l'automazione della gestione infrastrutturale tramite file dichiarativi (ARM Templates, Bicep, Terraform) e la gestione delle configurazioni applicative/versionate (Azure App Configuration, Key Vault). Le pipeline eseguono validazioni, approvazioni e applicano policy per garantire coerenza e sicurezza.
· DevOps su Azure Kubernetes Service (AKS): Gestione del ciclo CI/CD per applicazioni containerizzate su AKS con build immagini, scanning sicurezza, deploy tramite kubectl, Helm o GitOps, monitoraggio con Azure Monitor, Prometheus e Grafana, e sicurezza tramite Workload Identity, network policies e Azure Policy.
· Governance e compliance: Azure Policy applica regole di governance su risorse cloud, mentre Azure DevOps gestisce permessi granulari, auditing e controllo accessi per garantire conformità e sicurezza. Vengono enfatizzati i principi di minimo privilegio e monitoraggio continuo dei processi DevOps.
· Organizzazione, permessi e scalabilità: Azure DevOps struttura l'ambiente in Organization e Project con gruppi di sicurezza e livelli di accesso (Basic, Stakeholder). Supporta la gestione di team multipli, riutilizzo di template pipeline, feed condivisi e approvazioni centralizzate per ambienti comuni, garantendo collaborazione sicura e ordinata.
CAPITOLO 9 – Il servizio di sicurezza
Introduzione
Questa guida didattica si propone di accompagnare lo studente in un percorso chiaro e completo attraverso le principali tematiche di sicurezza informatica in ambiente Microsoft Azure, partendo dai concetti generali per arrivare alle pratiche più avanzate. La sicurezza nel cloud è oggi una priorità assoluta e Microsoft Azure offre strumenti e metodologie che, se compresi e applicati correttamente, consentono di ridurre i rischi e garantire la protezione dei dati e delle risorse. Il primo passo è comprendere i principi operativi della sicurezza, ovvero l’importanza di un approccio proattivo e multilivello che non si limiti a difendere il perimetro ma consideri ogni componente come potenziale punto di vulnerabilità. Da qui nasce il modello Zero Trust, un paradigma che si basa sull’idea che nulla deve essere considerato sicuro per impostazione predefinita, nemmeno gli utenti interni, e che ogni accesso deve essere verificato costantemente. Zero Trust in Azure si traduce in controlli rigorosi, autenticazioni multifattoriali e monitoraggio continuo delle attività, elementi che permettono di ridurre drasticamente il rischio di compromissione. Un altro pilastro fondamentale è la gestione delle identità e degli accessi, che in Azure si realizza attraverso Azure Active Directory e strumenti correlati. La corretta configurazione delle identità, l’uso di criteri di accesso condizionale e la segmentazione dei privilegi sono pratiche essenziali per evitare che un singolo account compromesso possa mettere a rischio l’intero ambiente. La crittografia dei dati rappresenta un ulteriore livello di protezione: in Azure è possibile cifrare i dati sia a riposo sia in transito, utilizzando chiavi gestite dal servizio o chiavi personalizzate, garantendo così la riservatezza delle informazioni anche in caso di accesso non autorizzato. La sicurezza di rete è un aspetto altrettanto cruciale e include l’implementazione di firewall, regole di filtraggio, segmentazione tramite reti virtuali e l’uso di VPN per connessioni sicure. Proteggere le risorse significa anche predisporre strategie di backup e politiche di ripristino che assicurino la continuità operativa in caso di incidenti o attacchi. Azure offre soluzioni integrate per il backup e il disaster recovery, che devono essere configurate e testate regolarmente per garantire la loro efficacia. Il monitoraggio e la risposta agli incidenti completano il quadro operativo: strumenti come Microsoft Defender for Cloud e Azure Monitor consentono di rilevare anomalie, generare avvisi e avviare azioni correttive in modo tempestivo. La sicurezza delle applicazioni è un altro tema centrale, poiché le vulnerabilità nel codice possono rappresentare una porta d’ingresso per gli attaccanti. Azure fornisce servizi per la gestione sicura delle applicazioni, come l’analisi delle dipendenze, la protezione delle API e l’uso di container sicuri. Infine, la conformità e l’automazione in ambito cloud sono elementi che permettono di mantenere standard elevati nel tempo: Azure mette a disposizione strumenti per verificare la conformità alle normative e per automatizzare processi di sicurezza, riducendo il rischio di errori umani e migliorando l’efficienza. Ogni sezione di questa guida è pensata per spiegare i concetti in modo semplice e accessibile, con esempi pratici che mostrano come applicare le soluzioni nella realtà operativa. L’obiettivo è fornire una base solida di conoscenze che consenta di operare in sicurezza su Azure, comprendendo sia gli strumenti offerti dalla piattaforma sia le buone pratiche da adottare. Attraverso questo percorso lo studente acquisirà competenze utili non solo per gestire l’infrastruttura cloud ma anche per affrontare le sfide quotidiane della sicurezza informatica con consapevolezza e professionalità, integrando teoria e pratica in un approccio coerente e orientato alla protezione dei dati e delle risorse aziendali.
Inquadramento argomenti del capitolo con slides illustrate
Azure adotta un modello di sicurezza condiviso tra provider e cliente. Microsoft protegge l'infrastruttura, l'hypervisor e i servizi gestiti, mentre l'organizzazione gestisce identità, rete, dati e applicazioni. Lo strumento centrale è Microsoft Defender for Cloud, una piattaforma CNAPP che offre secure score, raccomandazioni di sicurezza, piani di protezione per macchine virtuali, container e database, e integrazione con Microsoft Sentinel. Il secure score misura la postura rispetto alle best practice, mentre la sezione Regulatory compliance mappa i controlli tecnici agli standard principali e permette piani di miglioramento. La dashboard degli alert evidenzia minacce e configurazioni rischiose, mentre gli insights suggeriscono azioni prioritarie come abilitare MFA o impostare backup immutabili. Formazione e cultura sono fondamentali: la security awareness riduce l'errore umano, come phishing o uso scorretto delle credenziali. Esempi pratici includono l'analisi del secure score, l'applicazione delle raccomandazioni ad alto impatto e la governance tramite policy e management group. Un cruscotto con indicatori chiave e una mappa delle subscription aiutano il monitoraggio continuo.
Il modello Zero Trust si basa su tre principi: verifica esplicita, privilegio minimo e assunzione di violazione. In Azure, verificare esplicitamente significa usare MFA, Conditional Access e valutazioni di rischio. Il privilegio minimo si ottiene tramite RBAC, Privileged Identity Management per ruoli temporanei e revisioni periodiche degli accessi. L'assunzione di violazione implica segmentazione della rete con NSG e firewall, monitoraggio continuo con Azure Monitor e Sentinel, e playbook di risposta agli incidenti. Praticamente, si possono concedere ruoli amministrativi elevati solo con PIM per un tempo limitato, MFA obbligatorio e motivo documentato. La segmentazione di rete limita i flussi tra subnet e servizi. Un diagramma a tre pilastri con esempi pratici e flussi di autenticazione rappresenta visivamente questi principi.
Microsoft Entra ID, precedentemente Azure Active Directory, è il servizio di identità per autenticare utenti e applicazioni. Tramite Conditional Access, si definiscono regole basate su utente, gruppo, rischio di accesso, conformità del dispositivo e posizione. L'abilitazione di MFA rafforza la sicurezza, utilizzando diversi metodi come Authenticator, SMS, voce o FIDO2, e ove possibile, si adotta il passwordless. I ruoli amministrativi vengono assegnati in modo granulare e preferibilmente tramite PIM. I gruppi consentono deleghe e assegnazioni RBAC sulle risorse, mentre per le identità esterne si definiscono criteri specifici. Managed Identities permettono l'autenticazione dei servizi Azure senza segreti statici. Esempi includono criteri di accesso con MFA obbligatorio in caso di rischio medio, assegnazione di ruoli Security Reader per auditing e Application Administrator ai responsabili delle app. Una tavola mappa ruoli e responsabilità e gruppi e risorse.
In Azure, la cifratura at-rest è abilitata di default su molte risorse, con chiavi gestite da Microsoft. È possibile passare a chiavi gestite dal cliente tramite Key Vault, per maggiore controllo, rotazione e revoca. Per i dati in transito, si utilizza TLS obbligatorio, impostando la versione minima e forzando HTTPS. SQL usa Transparent Data Encryption per i file a riposo, mentre Storage supporta anche la double encryption. Key Vault fornisce chiavi protette da HSM, access policy, RBAC e logging. È importante progettare la gerarchia delle chiavi, definire la rotazione e integrare la gestione dei segreti nelle pipeline. Esempi includono la creazione di una chiave in Key Vault per Storage, abilitazione dell'auto-rotazione e logging, e l'impostazione di Minimum TLS 1.2 su App Service. Uno schema mostra i flussi tra Key Vault e i servizi.
Il controllo degli accessi in Azure si basa su RBAC, che assegna permessi a vari livelli: management group, subscription, resource group o singola risorsa. Si usano ruoli predefiniti come Contributor, Reader e Owner, oppure ruoli personalizzati minimali. L'uso dell'explicit deny è raro, ma si strutturano access policy specifiche per servizi come Key Vault o Storage, preferendo l'accesso basato su RBAC moderno. Le credenziali vengono gestite con Key Vault, Managed Identity ed Entra ID, riducendo i segreti di lunga durata. È fondamentale abilitare revisioni periodiche degli accessi e audit log per tutte le operazioni, collegandoli ad Azure Monitor o Sentinel per rilevare escalation di privilegi o attività insolite. Esempi pratici sono l'assegnazione di Contributor al team applicativo, Reader al supporto e Owner solo al team di piattaforma, oltre a revisioni trimestrali e rimozione automatica degli utenti inattivi. Una matrice scope per ruolo e un flusso di richiesta, approvazione e scadenza illustrano il processo.
La sicurezza di rete in Azure combina controlli di livello 4 e 7. I Network Security Group applicano regole allow e deny su porte, protocolli, origine e destinazione a livello di subnet o NIC. Azure Firewall offre filtro stateful, DNAT e SNAT, regole applicative e threat intelligence. Per accessi ibridi si usano VPN Gateway o ExpressRoute. Private Endpoints permettono di esporre servizi PaaS su IP privati, mentre la protezione DDoS Standard si abilita sulle reti critiche. Il monitoraggio dei flussi avviene tramite Network Watcher e Azure Monitor per alert su latenza o porte aperte. Esempi pratici includono la configurazione di regole per consentire HTTPS solo da Front Door, SQL solo da app a database, e deny all inbound da Internet. L'accesso amministrativo tramite VPN P2S utilizza certificati e MFA. Un diagramma hub-and-spoke mostra firewall nel hub, NSG negli spoke e connessioni VPN e Private Endpoints.
La protezione delle risorse Azure si basa su policy di sicurezza, backup e change tracking. Con Azure Policy si impongono requisiti come l'obbligo di Private Endpoints o di tag, misurando la compliance. Backup Center gestisce backup giornalieri, immutabilità per Blob, retention a lungo termine per SQL e restore puntuale. Il change tracking tramite Azure Automation permette di monitorare configurazioni e patch, e si possono applicare auto-remediation dove possibile. Backup regolari e disaster recovery garantiscono resilienza contro ransomware ed errori umani. Esempi includono soft delete e versioning su Blob, policy immutabili per archivi critici, backup con Point-in-Time Recovery e test di restore semestrale. Una timeline di backup e retention e una matrice policy-risorse aiutano il controllo della conformità.
Un programma di monitoraggio efficace utilizza Azure Monitor per metriche, log e trace, Log Analytics workspace per query, e Microsoft Sentinel come SIEM e SOAR per correlare eventi e automatizzare la risposta. Si configurano alert su segnali chiave come creazione di account privilegiati, traffico anomalo o fallimenti MFA. I workbook danno visibilità in tempo reale, mentre i piani di incident response definiscono ruoli, runbook e comunicazioni. Esercitazioni periodiche e review post-incident migliorano la risposta. Defender for Cloud invia alert specifici a Sentinel per correlazioni multi-sorgente. Esempi pratici sono playbook SOAR che gestiscono alert di impossible travel e workbook di sicurezza su accessi falliti e utenti a rischio. Un flusso visualizza le fasi di gestione dell'incidente, dagli alert alle lessons learned.
La sicurezza delle applicazioni prevede autenticazione robusta tramite OIDC o OAuth2 con Entra ID, Managed Identity per i servizi, e autorizzazione granulare tramite ruoli e claim. Si effettuano scansioni di vulnerabilità regolari, sia statiche che dinamiche, e si mantiene l'observability tramite audit log. In Azure, App Service, AKS e Functions integrano l'identità e il networking privato; si utilizza Web Application Firewall su Application Gateway o Front Door per la protezione L7. Le dipendenze vengono gestite tramite SBOM e scanner come Defender for DevOps e CodeQL, con aggiornamento regolare dei pacchetti. Le autenticazioni e le azioni sensibili vengono loggate e inviate a Log Analytics o Sentinel. Esempi includono API protette con Entra ID e scopes, accesso role-based, rate limiting su Front Door, pipeline di build con SAST e SCA e blocco merge in presenza di vulnerabilità critiche. Uno schema rappresenta il flusso utente, WAF, applicazione e logging.
La compliance in Azure viene gestita tramite Defender for Cloud e Azure Policy, che applicano e misurano i controlli tecnici. I workflow automatizzati, come Logic Apps, Functions o Runbook, consentono di trasformare le raccomandazioni in azioni concrete: tagging automatico, chiusura porte, applicazione di criteri, provisioning di Private Endpoints e rotazione segreti. Cost Management aiuta a controllare l'impatto economico della sicurezza, mentre i report periodici documentano la conformità. La continuous compliance si integra nel ciclo DevOps con policy as code, test di conformità, drift remediation e l'uso di blueprint e landing zone. Esempi pratici includono repository di iniziative, pipeline che applicano policy a ogni deploy e report trimestrali con stato dei controlli e azioni correttive pianificate. Un diagramma rappresenta il ciclo DevOps e compliance, collegato ai servizi Azure.
1. Panoramica e Principi Operativi della Sicurezza in Azure
In Azure la sicurezza è affrontata come responsabilità condivisa tra il provider cloud (Microsoft) e il cliente. Microsoft garantisce la protezione dell’infrastruttura cloud sottostante – includendo datacenter, hardware, rete fisica e servizi gestiti di base – mentre il cliente (l’organizzazione che usa Azure) è responsabile di configurare in modo sicuro tutto ciò che costruisce nel cloud: identità e permessi degli utenti, rete virtuale, configurazione dei servizi, protezione dei dati e delle applicazioni hostate. Questo modello impone quindi all’azienda utilizzatrice di Azure di adottare best practice di sicurezza sulle risorse che crea o gestisce nel cloud, sfruttando al massimo gli strumenti di protezione che la piattaforma mette a disposizione.
Un elemento centrale per la sicurezza in Azure è Microsoft Defender for Cloud, una soluzione classificata come CNAPP (Cloud-Native Application Protection Platform). Defender for Cloud offre una dashboard unificata con indicatori chiave dello stato di sicurezza dell’ambiente Azure. Tra questi indicatori spicca il Secure Score, una percentuale che misura la postura di sicurezza delle risorse rispetto alle best practice e alle politiche applicate: più il punteggio è alto, più l’ambiente è aderente agli standard di sicurezza consigliati. Un altro pannello importante è la sezione Regulatory Compliance, che fornisce una vista sul livello di conformità dell’ambiente rispetto ai principali standard normativi e di settore (come ISO 27001, SOC 2, PCI DSS, HIPAA, ecc.), mostrando quali controlli tecnici sono soddisfatti e quali necessitano di intervento. Oltre a ciò, Defender for Cloud elenca le security alerts (avvisi di sicurezza) generate da rilevamenti di minacce o configurazioni a rischio, e offre raccomandazioni (insights) con azioni prioritarie per migliorare la sicurezza, ad esempio abilitare l’MFA su account importanti, chiudere porte di rete inutilizzate o configurare backup immutabili.
È importante sottolineare che una strategia di sicurezza efficace non si basa solo su strumenti tecnici, ma anche su processi e cultura aziendale. Azure fornisce molti mezzi tecnici per proteggere sistemi e dati, ma se gli utenti e gli amministratori non sono formati e consapevoli delle minacce (es. phishing, uso corretto delle credenziali, social engineering), il rischio di incidenti rimane elevato. Investire in security awareness – ovvero programmi di formazione e sensibilizzazione alla sicurezza per tutto il personale – è essenziale per ridurre la componente di errore umano.
Esempi pratici:
· Miglioramento continuo: utilizzare il Secure Score come guida prioritaria. Ad esempio, se Defender for Cloud indica un punteggio basso a causa di alcune raccomandazioni ad alto impatto non applicate, come abilitare l’MFA per tutti gli account amministrativi o chiudere porte RDP/SSH aperte al mondo, queste azioni dovrebbero essere intraprese subito. Dopo averle implementate, si può osservare l’incremento del Secure Score e monitorare i progressi mese per mese.
· Governance centralizzata: definire Azure Policy a livello di Management Group (il livello più alto che raggruppa tutte le sottoscrizioni Azure dell’organizzazione) per applicare controlli uniformi. Ad esempio, si possono assegnare policy che impongono l’uso di endpoint privati e vietano IP pubblici sui servizi, assicurando che tutte le subscription sottostanti rispettino tali requisiti. Inoltre, Azure permette di raggruppare più policy in una Initiative (iniziativa) dedicata a uno standard di conformità – ad esempio un’iniziativa che copre i controlli richiesti dallo standard ISO 27001 – facilitando così la gestione della conformità normativa su larga scala.
2. Modello Zero Trust
Una delle fondamenta della sicurezza moderna, adottata anche in Azure, è il modello Zero Trust. Contrariamente alla sicurezza tradizionale perimetrale (dove tutto ciò che è all’interno della rete aziendale è considerato implicitamente affidabile), Zero Trust parte dal presupposto opposto: non fidarsi mai implicitamente di nulla e verificare esplicitamente ogni accesso. In sintesi, Zero Trust si basa su tre princìpi cardine:
a) Verifica esplicita (Verify Explicitly) – Ogni richiesta di accesso deve essere autenticata e autorizzata in base a tutti i dati disponibili (identità dell’utente, dispositivo utilizzato, posizione geografica, orario, sensibilità della risorsa richiesta, livello di rischio rilevato, stato di conformità del dispositivo, etc.). In Azure questo principio si traduce nell’uso diffuso dell’autenticazione multifattore (MFA), di controlli di Accesso Condizionale (Conditional Access) e di sistemi di valutazione del rischio di identità: ad esempio, se un login proviene da un dispositivo non conforme o da una località insolita, al richiedente può essere chiesto un fattore aggiuntivo di autenticazione o può essere negato l’accesso.
b) Accesso con privilegio minimo (Least Privilege Access) – Ogni utente o entità dovrebbe avere solo i permessi minimi necessari per svolgere il proprio lavoro, soltanto per il tempo necessario. Questo limita l’impatto di eventuali credenziali compromesse o errori umani. In Azure ciò viene implementato tramite l’assegnazione rigorosa di ruoli in base al principio del RBAC (Role-Based Access Control) sulle risorse cloud. Inoltre, per gli account altamente privilegiati si utilizza PIM (Privileged Identity Management): gli amministratori ottengono privilegi elevati solo temporaneamente, su richiesta e approvazione, e tali privilegi decadono automaticamente dopo un periodo definito. Si effettuano anche revisioni periodiche degli accessi per revocare quelli non più necessari.
c) Presunzione di violazione (Assume Breach) – Bisogna presumere che una violazione possa sempre avvenire e progettare di conseguenza misure di contenimento e piani di risposta. In pratica, si segmentano le reti e le risorse in modo granulare così che anche se un segmento viene compromesso, il resto rimane isolato (principio di micro-segmentazione). Inoltre, si attivano sistemi di monitoraggio continuo e logging avanzato: servizi come Azure Monitor e Microsoft Sentinel raccolgono e analizzano costantemente i log, così da individuare comportamenti anomali e generare alert in caso di possibili incidenti. Infine, si predispongono piani di risposta agli incidenti (Incident Response) dettagliati per reagire rapidamente e in modo coordinato a qualsiasi breach, con procedure di isolamento, analisi forense e ripristino.
Azure incorpora questi concetti di Zero Trust in molti dei suoi servizi e funzionalità. Ad esempio, per verifica esplicita offre Azure Conditional Access nell’ambito di Entra ID (Azure AD), che permette di definire regole sofisticate basate su condizioni; per privilegio minimo fornisce il modello RBAC con centinaia di ruoli predefiniti e la possibilità di definirne di personalizzati, oltre a strumenti come PIM per gestire gli amministratori ad elevati privilegi; per assumere la violazione mette a disposizione risorse come i Network Security Group (NSG) e gli Azure Firewall per segmentare e filtrare il traffico, e servizi di monitoraggio avanzato e analisi delle minacce come Sentinel.
Esempi pratici:
· Accesso amministrativo Just-in-Time: un’azienda implementa PIM per gli account amministrativi in Azure. Quando un operatore IT necessita di diritti di Global Administrator o di Owner su una risorsa, deve attivare una richiesta attraverso PIM. La piattaforma concede il ruolo per, ad esempio, 2 ore dopo aver ricevuto l’approvazione di un responsabile, e solo se l’utente ha eseguito l’MFA. Ogni attivazione richiede inoltre di specificare una motivazione documentata. Passato il periodo di 2 ore, i privilegi scadono automaticamente. In questo modo, anche se un account amministrativo venisse compromesso, l’aggressore avrebbe una finestra temporale ristretta (o nessun privilegio elevato se il ruolo non è attivato) per causare danni, limitando il potenziale impatto.
· Segmentazione della rete: un’architettura di rete in Azure è progettata secondo Zero Trust separando i livelli applicativi. Si possono avere ad esempio tre subnet: web, app e database. Alle risorse di ogni subnet si associano NSG con regole tali che: la subnet web accetta traffico in ingresso solo sulla porta HTTPS (443) proveniente dall’esterno; la subnet app accetta traffico solo dalla subnet web (ad es. chiamate API) e solo su porte specifiche necessarie; la subnet database accetta connessioni soltanto dalla subnet app sulla porta del database (es. 1433 per SQL Server). Tutto il resto del traffico, in qualunque direzione non esplicitamente permessa, è negato. In aggiunta, si configurano log dei flussi di sicurezza e monitoraggio delle connessioni anomale, in modo da rilevare e bloccare tempestivamente tentativi di movimento laterale o esfiltrazione di dati.
3. Gestione delle Identità e degli Accessi
In un ambiente cloud, le identità digitali (utenti, servizi, dispositivi) sono il nuovo perimetro da difendere. Azure offre un servizio dedicato per la gestione centralizzata delle identità: Microsoft Entra ID, in precedenza noto come Azure Active Directory (Azure AD). Questo servizio si occupa di autenticare utenti e applicazioni, e di governare chi può accedere a cosa. Tramite Entra ID, gli amministratori possono creare e gestire utenti e gruppi, assegnare ruoli e definire criteri di accesso condizionale in modo uniforme per l’intera organizzazione.
Un concetto chiave è l’Accesso Condizionale (Conditional Access). Ciò consente di impostare policy che valutano condizioni al momento dell’accesso e applicano controlli aggiuntivi o restrizioni. Ad esempio, si può richiedere obbligatoriamente l’MFA (Multi-Factor Authentication) se il sistema di Entra ID rileva che l’accesso proviene da un luogo insolito o se il rischio di accesso calcolato per l’utente è elevato (Azure AD analizza vari segnali di rischio, come autenticazioni da nuove posizioni o da dispositivi potenzialmente compromessi). Altre condizioni possono essere lo stato di conformità del dispositivo (ad esempio consentire l’accesso solo da PC aziendali aggiornati e con antivirus attivo) o il tipo di applicazione a cui si sta accedendo. Con l’MFA abilitata – utilizzando metodi come l’app di autenticazione sul telefono, SMS, chiamate vocali o dispositivi FIDO2 per accesso senza password – si aggiunge un livello di sicurezza fondamentale: anche se la password di un utente venisse carpita, l’attaccante difficilmente avrebbe anche il secondo fattore necessario per accedere. Microsoft sta promuovendo sempre più soluzioni passwordless, ossia l’autenticazione senza password tradizionale, affidandosi a fattori biometrici o dispositivi sicuri registrati.
La gestione delle autorizzazioni avviene tramite il modello RBAC (Role-Based Access Control) di Azure. RBAC consente di assegnare ruoli agli utenti, ai gruppi o alle identità di servizio, determinando a quali risorse Azure possono accedere e con quali privilegi. I ruoli possono essere assegnati a diversi livelli di scope (ambito): a livello di Management Group (ereditando su tutte le subscription dell’organizzazione), di Subscription singola, di Resource Group o di singola risorsa. Azure fornisce decine di ruoli predefiniti – ad esempio Owner (pieno controllo di tutte le operazioni su un certo scope), Contributor (capacità di creare e modificare risorse ma non gestire i permessi di altri), Reader (sola lettura), oltre a ruoli specifici per servizi particolari – e offre la possibilità di creare ruoli personalizzati per esigenze più granulari. Una buona prassi di sicurezza è assegnare agli utenti il ruolo più restrittivo possibile che permetta comunque loro di svolgere le attività richieste (principio del privilegio minimo). Si dovrebbe evitare il più possibile di concedere privilegi eccessivi come Owner sull’intera subscription, se non quando strettamente necessario.
Per aumentare la sicurezza nella gestione dei ruoli elevati, Azure Active Directory (Entra ID) include anche la funzionalità PIM (Privileged Identity Management). Con PIM, gli utenti non hanno sempre assegnato il ruolo amministrativo elevato, ma possono richiederlo per un tempo limitato (just-in-time) e solo previa approvazione. Come descritto nella sezione Zero Trust, un amministratore può diventare temporaneamente Global Administrator o avere privilegi da owner su una risorsa per la durata strettamente necessaria, dopodiché i diritti scadono. Ogni attivazione viene registrata nei log e può richiedere MFA e la motivazione. Questo riduce la finestra temporale in cui un account con alti privilegi potrebbe essere compromesso, migliorando significativamente la sicurezza.
Oltre agli utenti umani, Azure AD gestisce anche identità per i servizi. Le Managed Identities sono identità gestite dal sistema che possono essere assegnate, ad esempio, a una macchina virtuale o a un’applicazione Azure, permettendo a quella risorsa di autenticarsi su altri servizi Azure (come una database o un Key Vault) senza dover memorizzare credenziali nel codice o nei file di configurazione. In pratica, invece di salvare username e password (o chiavi segrete) per far comunicare due componenti, si usa un’identità gestita: Azure la riconosce e consente l’accesso in base ai permessi che le sono stati assegnati. Questo elimina il rischio associato a segreti statici, che potrebbero essere rubati o non rinnovati in tempo.
Parallelamente, per risorse specifiche, Azure offre meccanismi di Access Policies. Ad esempio, un servizio come Azure Key Vault (dove si custodiscono chiavi crittografiche e segreti) può utilizzare Access Policies dedicate per definire chi può leggere, scrivere o cancellare segreti nel vault. Tuttavia, anche in questi casi, la tendenza attuale è di utilizzare RBAC unificato su Azure per controllare l’accesso ai vault e ad altre risorse, così da avere un modello consistente ovunque.
Un ulteriore aspetto fondamentale della gestione degli accessi è il monitoraggio e la revisione. Azure registra dettagliatamente nei log di audit tutte le operazioni rilevanti di gestione delle identità e delle risorse – ad esempio l’assegnazione o la rimozione di un ruolo, la creazione di un nuovo utente, etc.. Questi log dovrebbero essere periodicamente analizzati, preferibilmente integrandoli con Azure Monitor o inviandoli al SIEM Microsoft Sentinel, in modo da generare allarmi se avvengono azioni anomale (come l’assegnazione improvvisa di privilegi elevati a un account che prima ne era privo, oppure una serie di login falliti che potrebbero indicare tentativi di intrusione). Inoltre, è buona pratica attivare Access Reviews periodiche, ossia campagne di revisione durante le quali gli owner dei vari gruppi o ruoli verificano se gli utenti ancora assegnati a quei ruoli ne abbiano effettivamente bisogno. Azure AD facilita questo processo offrendo funzionalità di revisione automatizzata: ad esempio, si può configurare una revisione trimestrale di tutti gli utenti con ruolo Contributor o superiore su un certo scope, e rimuovere automaticamente quelli che non confermano (o il cui responsabile non conferma) la necessità di tali accessi. In aggiunta, si possono impostare criteri per rimuovere automaticamente account o accessi inattivi da un certo tempo, così da mantenere il principio del privilegio minimo in maniera dinamica.
Esempi pratici:
· Criterio di accesso condizionale adattivo: un’università che utilizza Azure AD per gli studenti imposta una policy di Conditional Access che obbliga l’MFA quando gli studenti accedono ai servizi universitari da fuori campus o da reti non affidabili, oppure se il rischio di accesso calcolato da Azure AD è medio o alto (ad esempio, perché l’account ha avuto tentativi di accesso falliti recentemente). Inoltre, la sessione può essere limitata: se si accede da un dispositivo non gestito, la policy potrebbe impedire il download di file sensibili o imporre la riesecuzione del login dopo un breve periodo (session control).
· Assegnazione granulare di ruoli: un’azienda assegna il ruolo di Security Reader al team di audit, così i revisori possono vedere configurazioni e report di sicurezza senza poter modificare nulla. Allo stesso modo, il ruolo di Application Administrator viene dato solo ai responsabili delle applicazioni, permettendo loro di registrare applicazioni in Entra ID ma non di avere accesso ad altri ambiti di amministrazione. In questo modo ogni gruppo di utenti ha solo i privilegi necessari al proprio lavoro.
· Accesso al database con RBAC: invece di condividere tra sviluppatori le credenziali amministrative di un database, un’azienda crea un Resource Group per il progetto e vi colloca il database. Al gruppo di sviluppatori dell’applicazione viene assegnato il ruolo Contributor su quel Resource Group, così possono gestire il database (ad esempio applicare schemi, gestire i dati) senza però avere diritti di modifica sulle impostazioni di sicurezza a livello di subscription. Il team di supporto IT ottiene solo il ruolo Reader sul Resource Group, sufficiente per monitorare lo stato del DB e leggere i log, ma non per effettuare cambiamenti. Il ruolo Owner rimane esclusivo del team di piattaforma o dei senior administrator, che lo usano solo per operazioni straordinarie.
· Revisione periodica degli accessi: un’organizzazione imposta una revisione trimestrale per tutti gli utenti che hanno ruoli amministrativi elevati (es. Owner, Contributor su ambienti di produzione). Ogni tre mesi, i responsabili devono approvare la permanenza dei propri membri nei rispettivi ruoli; il sistema rimuove automaticamente chi non è confermato o chi risulta inattivo da tempo. In uno di questi cicli di revisione, ad esempio, si scopre che un ex-progettista era ancora nel gruppo con ruolo di Owner su alcune risorse: grazie alla revisione, il suo accesso viene revocato prevenendo potenziali abusi involontari.
4. Crittografia dei Dati e Gestione delle Chiavi
La crittografia è un pilastro fondamentale per proteggere i dati sia quando sono archiviati (at rest) sia quando sono trasmessi in rete (in transit). Azure adotta un approccio estensivo alla cifratura dei dati a riposo: molti servizi Azure infatti crittografano automaticamente i dati archiviati utilizzando chiavi gestite da Microsoft. Ad esempio, i file e i blob in Azure Storage, i database in Azure SQL Database e Cosmos DB, e i dischi delle macchine virtuali sono cifrati di default senza intervento dell’utente. Questo garantisce che, anche in caso di accesso non autorizzato ai supporti fisici o ai file di backup, i dati risultino illeggibili. Tuttavia, per esigenze avanzate di sicurezza e conformità, un’organizzazione potrebbe voler avere un controllo granulare sulle chiavi di cifratura: Azure consente infatti di passare da chiavi gestite dal servizio (Microsoft-managed keys) a chiavi gestite dal cliente (Customer-Managed Keys, CMK). Utilizzando Azure Key Vault, il servizio di gestione di chiavi e segreti, l’azienda può generare o importare le proprie chiavi crittografiche e configurare i servizi Azure (Storage account, SQL, ecc.) affinché utilizzino quelle chiavi per cifrare i dati. In questo modo, il cliente mantiene il pieno controllo sulle chiavi (può ruotarle, revocarle, definirne gli accessi) e soddisfa requisiti normativi che impongono la gestione interna delle chiavi di cifratura.
Per i dati in transito, la regola generale è di cifrare sempre le comunicazioni utilizzando protocolli sicuri. Azure permette (e talvolta impone) l’uso di TLS (Transport Layer Security) per i servizi web. Ad esempio, per le applicazioni web ospitate su Azure App Service è possibile (ed è considerata una best practice) disabilitare completamente le connessioni non cifrate HTTP e accettare solo HTTPS, magari impostando anche la versione minima di TLS supportata (oggi almeno TLS 1.2). Molti servizi Azure gestiti, come Azure SQL, richiedono connessioni cifrate oppure le supportano nativamente. Un caso particolare di cifratura at-rest/in-transit integrata è la Transparent Data Encryption (TDE) per Azure SQL Database: TDE cifra “sul disco” i file dei database e dei log automaticamente, mentre le connessioni al database vengono cifrate via TLS.
Azure Key Vault gioca un ruolo cruciale nella gestione delle chiavi di crittografia e dei segreti. Key Vault è un servizio che offre uno storage sicuro per chiavi, segreti e certificati. Le chiavi possono risiedere in moduli hardware sicuri (HSM, Hardware Security Modules) gestiti da Microsoft, garantendo un alto livello di protezione. Tramite Key Vault si possono controllare finemente gli accessi alle chiavi (ad esempio solo certi servizi o identità possono usare una chiave per decrittare dati), si possono effettuare operazioni crittografiche (signing, encryption) senza esporre il materiale della chiave, e si ottiene un completo audit log di ogni accesso o utilizzo di ciascuna chiave. È buona pratica progettare una gerarchia di chiavi: ad esempio, avere una chiave principale (master) utilizzata solo per cifrare a sua volta chiavi secondarie (data encryption keys) che vengono usate per i dati veri e propri. Ciò semplifica la rotazione delle chiavi: si può periodicamente cambiare le chiavi secondarie e ricifrare i dati, mantenendo stabile la chiave master (o ruotandola con cadenze più lunghe e procedure controllate). Azure Key Vault supporta la rotazione automatica delle chiavi (configurabile ad esempio affinché una nuova versione della chiave venga generata ogni 90 giorni) e invia notifiche o attiva allarmi se le chiavi stanno per scadere.
In sintesi, con Azure si dovrebbe sempre: cifrare i dati a riposo (usando chiavi proprie se necessario), cifrare i dati in transito (usando TLS ovunque, anche tra servizi interni se possibile) e proteggere le chiavi in un vault sicuro, con accessi ristretti e loggati.
Esempi pratici:
· Chiavi gestite dal cliente su Storage: per un’applicazione che archivia dati sensibili su Azure Blob Storage, l’azienda crea una nuova chiave crittografica in Azure Key Vault (o ne importa una generata dal proprio HSM on-premises). Configura poi l’account di Storage in modo che utilizzi quella chiave del Key Vault per crittografare tutti i blob. Abilita inoltre la rotazione automatica della chiave nel Key Vault (ad esempio ogni 6 mesi) e attiva il logging degli accessi al Key Vault. Così, se un dipendente dovesse accedere ai dati sullo storage fuori dalle policy aziendali, i file rimarrebbero cifrati e l’accesso alla chiave verrebbe tracciato (o addirittura negato se non autorizzato).
· Enforce TLS: un sito web aziendale è pubblicato su Azure App Service. Gli amministratori impostano la “Minimum TLS Version” a 1.2 e abilitano l’opzione HTTPS Only, in modo che qualsiasi richiesta via HTTP venga automaticamente reindirizzata ad HTTPS. Inoltre caricano sul servizio un certificato SSL valido per il dominio del sito. Così tutte le comunicazioni tra gli utenti e il sito (e tra il sito e eventuali API backend) risultano cifrate. Allo stesso modo, per un’applicazione interna che comunica con un database Cosmos DB, viene abilitata la cifratura end-to-end e forzata la validazione del certificato del server, assicurando che i dati in transito sulla rete siano sempre protetti.
5. Sicurezza di Rete (Firewall, NSG e VPN)
La sicurezza delle reti in Azure si ottiene combinando controlli a livello 4 (trasporto) e livello 7 (applicazione) del modello OSI. I due strumenti principali offerti dalla piattaforma per filtrare il traffico sono i Network Security Group (NSG) e Azure Firewall, coadiuvati da altri servizi per specifici scenari (ad esempio le VPN Gateway o Azure DDoS Protection).
Network Security Group (NSG): è un componente che si applica a una subnet della rete virtuale o direttamente a una scheda di rete (NIC) di una VM e contiene regole di sicurezza di base. Ogni regola definisce se permettere (allow) o negare (deny) un certo tipo di traffico, specificando la porta o l’intervallo di porte, il protocollo (TCP/UDP), l’indirizzo di origine e di destinazione. Ad esempio, una regola NSG può permettere il traffico in ingresso alla porta 80 TCP solo se proviene da un certo range IP (o da una subnet interna) e bloccare tutto il traffico da altre fonti. Le NSG operano a livello 4 (e parzialmente livello 3 per gli indirizzi) e sono simili ai firewall stateless tradizionali; non analizzano il contenuto del payload ma solo intestazioni di base. Hanno il vantaggio di essere molto specifiche e veloci, e vengono usate per segmentare e isolare il traffico all’interno della Virtual Network Azure.
Azure Firewall: è un servizio gestito di firewall stateful (cioè che tiene traccia delle connessioni e può applicare regole con contesto). Azure Firewall opera come un’appliance centralizzata (tipicamente posizionata in una rete hub in topologie hub-and-spoke) e offre funzionalità avanzate: può fare NAT (Network Address Translation) in ingresso e in uscita (DNAT/SNAT) per pubblicare servizi interni o per garantire che tutto il traffico verso Internet esca con un certo IP. Supporta regole a livello applicativo (L7), ad esempio permettendo o negando richieste HTTP verso certi domini (FQDN) indipendentemente dall’IP, e integra feed di Threat Intelligence per bloccare automaticamente indirizzi noti come maligni. In pratica, Azure Firewall può filtrare in modo più intelligente e centralizzato rispetto alle NSG, ed è spesso usato in combinazione con queste ultime: le NSG proteggono ogni singola subnet/VM, mentre il Firewall applica politiche generali su tutto il traffico che attraversa i perimetri tra le reti (ad es. tra la rete Azure e Internet, o tra Azure e la rete on-premises).
VPN e connettività ibrida: in molti scenari, la rete Azure non è isolata ma deve comunicare con l’esterno, ad esempio con la rete aziendale on-premises. Azure offre VPN Gateway per creare connessioni Site-to-Site (S2S) cifrate tra la rete locale dell’azienda e Azure tramite Internet (utilizzando protocolli come IPsec/IKE). Inoltre, supporta connessioni Point-to-Site (P2S) per consentire a singoli client (come laptop di dipendenti fuori sede) di entrare nella rete virtuale Azure in VPN. Un’alternativa alle VPN su Internet è Azure ExpressRoute, un servizio che fornisce un collegamento dedicato e privato (tramite un provider di connettività) tra la rete on-prem e Azure, con ampiezza di banda garantita e bassa latenza, spesso usato per esigenze enterprise avanzate.
Private Endpoint: per migliorare la sicurezza delle comunicazioni verso i servizi PaaS di Azure (come Azure Storage, Azure SQL, ecc.), esiste la possibilità di utilizzare i Private Endpoints. Un Private Endpoint è essenzialmente un’interfaccia di rete privata nella VNet del cliente che si collega internamente al servizio PaaS, dandogli un IP privato. In questo modo, ad esempio, invece di accedere a un database Azure SQL tramite il suo hostname pubblico, l’applicazione può connettersi all’IP privato interno assegnato come Private Endpoint, evitando che il traffico passi per Internet. Ciò incrementa la sicurezza perché elimina esposizioni pubbliche indesiderate.
Protezione DDoS: Azure include di default una protezione base contro attacchi DDoS (Distributed Denial of Service) sulle risorse pubbliche. Per ambienti mission-critical, è consigliato attivare Azure DDoS Protection Standard su determinate Virtual Network: questo servizio avanzato, a pagamento, rileva e mitiga attacchi DDoS su larga scala con policy su misura e con soglie di intervento personalizzabili, garantendo la continuità dei servizi anche sotto attacco.
Monitoraggio della rete: per tenere sotto controllo ciò che avviene a livello di rete, Azure fornisce strumenti come Network Watcher. Esso consente, ad esempio, di abilitare i Network Security Group Flow Logs, cioè i log di tutto il traffico consentito o negato dalle NSG, che possono poi essere analizzati (anche con tool di analisi o SIEM) per identificare tentativi di intrusione o configurazioni errate. Network Watcher offre anche funzionalità come la visualizzazione topologica della rete (per vedere a colpo d’occhio come sono connesse le subnet, i peerings, i gateway), test di connettività fra punti della rete, e monitoraggio delle connessioni per rilevare se certe rotte o end-to-end path sono interrotti. Integrando questo con Azure Monitor, si possono impostare alert per condizioni anomale, ad esempio se una VM comincia a ricevere traffico su porte che dovrebbero essere chiuse o se la latenza di una connessione VPN supera una certa soglia.
Esempi pratici:
· Regole di filtraggio multi-livello: un’applicazione web aziendale è esposta su Internet tramite un servizio gestito di Azure chiamato Front Door. Per garantire la sicurezza, si adottano più livelli di filtro: in Front Door stesso (che funge da entry point globale) si accettano solo connessioni HTTPS e si instrada il traffico verso un pool di server web nella VNet. Nella VNet, le NSG della subnet web permettono solo il traffico proveniente da Front Door sulla porta 443. La subnet app (che ospita i server applicativi) accetta solo traffico dalle VM web sulla porta applicativa specifica e blocca qualsiasi traffico diretto da Internet. La subnet db consente connessioni solo dalla subnet app sulla porta del database (ad esempio 1433). Inoltre, tutte le NSG hanno una regola Deny All finale che blocca qualsiasi altro traffico non esplicitamente consentito. In parallelo, un Azure Firewall nel hub effettua ispezione del traffico in uscita: ad esempio impedisce ai server di contattare domini esterni noti per malware.
· Accesso amministrativo via VPN P2S: per gestire in sicurezza le macchine virtuali e gli altri servizi all’interno della rete Azure, un’azienda evita di esporre porte di management (SSH, RDP) su Internet. Invece, i tecnici usano una VPN Point-to-Site per entrare nella rete da remoto. Ogni tecnico possiede un certificato client installato sul proprio dispositivo e deve autenticarsi con MFA per stabilire la VPN. La VPN è configurata in modalità split-tunnel, inviando nel canale cifrato solo il traffico destinato alle subnet di gestione su Azure, mentre il resto del traffico internet dei client segue il percorso normale. In questo modo, la gestione avviene attraverso un canale sicuro e controllato, riducendo la superficie di attacco delle macchine rispetto ad accessi pubblici.
6. Protezione delle Risorse e Backup
Oltre a prevenire gli attacchi, un buon programma di sicurezza garantisce anche la resilienza in caso di incidente. In Azure, questo significa mettere in atto misure di protezione dei dati e delle configurazioni, tra cui l’uso di policy preventive, di backup regolari e di tracciamento dei cambiamenti, così da poter ripristinare rapidamente la normalità se qualcosa va storto.
Azure Policy e Compliance: Azure offre il servizio Azure Policy per definire ed applicare criteri di sicurezza in modo coerente su tutte le risorse. Con Azure Policy, un’azienda può impostare regole del tipo: “non permettere la creazione di risorse X senza crittografia attivata”, oppure “richiedere che tutte le risorse abbiano un tag di appartenenza a un progetto”, o ancora “vietare l’esposizione di porte perilose su macchine virtuali”. Le policy possono sia negare configurazioni non conformi (prevenendone proprio la creazione o l’aggiornamento), sia semplicemente segnalare le risorse fuori standard. Inoltre producono una valutazione di compliance: nel portale Azure è possibile vedere quanti e quali risorse sono conformi o meno a ciascun controllo definito. Ad esempio, se esiste una policy che richiede l’abilitazione dei Private Endpoint su tutti i database, la dashboard di compliance mostrerà la percentuale di database che rispettano questa regola e l’elenco di quelli da correggere.
Backup e ripristino: La Backup Center di Azure consente di centralizzare e gestire i backup di varie tipologie di risorse – dalle macchine virtuali ai database SQL e ai file – definendo policy di backup per eseguire copie giornaliere (o con altra frequenza) dei dati. Un elemento chiave di una strategia di backup moderna è l’immutabilità: Azure Blob Storage, ad esempio, supporta la configurazione WORM (Write-Once, Read-Many) che impedisce la modifica o la cancellazione dei dati salvati per un periodo stabilito, garantendo che i backup non possano essere compromessi nemmeno se un attaccante ottenesse privilegi elevati (un tipico attacco ransomware è cancellare o alterare i backup; con l’immutable storage ciò diventa impossibile per il periodo di retention definito). Per i database SQL, oltre ai backup giornalieri, Azure offre la PITR (Point-In-Time Restore), ovvero la possibilità di riportare un database allo stato in cui si trovava in un qualsiasi momento degli ultimi X giorni (tipicamente 7, 14 o 35 giorni a seconda del tier di servizio) tramite log delle transazioni continuo. Inoltre c’è la possibilità di configurare LTR (Long-Term Retention) per conservare backup mensili o annuali per molti anni (ad esempio per ottemperare a obblighi normativi). Nel caso di macchine virtuali, si possono programmare backup della VM intera (snapshots) e conservare anche qui più versioni.
Site Recovery (DR): La Disaster Recovery è resa possibile da servizi come Azure Site Recovery, che orchestrano la replica di macchine virtuali e applicazioni da una region Azure a un’altra (o da on-premises ad Azure) così che, in caso di guasto catastrofico di un’intera area geografica o data center, le macchine possano essere avviate nella sede secondaria. In combinazione con backup e politiche di failover (ad esempio i failover group per i database), questo assicura che anche eventi estremi come disastri naturali o attacchi massivi non interrompano l’operatività critica oltre un minimo tollerato.
Change Tracking e Auto-remediation: Azure mette a disposizione strumenti per tracciare i cambiamenti di configurazione delle risorse. Ad esempio, usando Azure Monitor e Azure Automation, si può abilitare il Change Tracking delle macchine virtuali: ogni modifica a software installati, a configurazioni importanti o a impostazioni di sistema viene registrata, così se un problema compare improvvisamente si può controllare cosa è cambiato di recente su quella VM. Similmente, il log delle attività Azure (Azure Activity Log) registra tutte le modifiche “infrastrutturali” fatte sulle risorse (creazione, modifica impostazioni, scaling, etc.). Sulla base di questi dati è possibile impostare anche correzioni automatiche (auto-remediation): ad esempio, se una policy segnala che qualcuno ha creato una VM senza tag obbligatori, si può configurare la policy stessa perché aggiunga automaticamente il tag mancante; oppure, se un log rileva che un servizio critico è stato fermato, uno script di automation può tentare di riavviarlo senza attendere l’intervento manuale.
In sostanza, combinando prevenzione (policy che evitano configurazioni insicure), cura (backup regolari e piani di ripristino) e monitoraggio dei cambiamenti, si riesce a costruire un ambiente Azure resiliente, dove gli errori vengono evitati o rilevati subito e i dati possono sempre essere recuperati.
Esempi pratici:
· Protezione dei dati su Blob Storage: per un archivio di dati importanti su Azure Blob (ad esempio log aziendali o documenti finanziari), l’azienda abilita le funzionalità di Soft Delete e Versioning. La Soft Delete fa sì che, se un blob viene cancellato per errore o per malizia, esso rimane recuperabile per un certo periodo (ad esempio 14 giorni). Il versioning invece tiene automaticamente traccia di ogni modifica ai blob, conservando le versioni precedenti. Inoltre, per i container più critici, viene applicata una policy di immutabilità impostando, ad esempio, che tutti i blob scritti siano immutabili per 30 giorni. Così, nemmeno un amministratore con accesso al storage account potrebbe eliminare o alterare quei dati entro il periodo stabilito.
· Piano di backup per database con test di ripristino: un’azienda ha un database SQL in Azure su cui risiede un’applicazione fondamentale. Viene impostata una policy di backup con PITR che consente il restore a qualsiasi ora degli ultimi 14 giorni e una LTR che conserva i backup di fine mese per 7 anni. Ogni sei mesi, il team IT esegue un test di disaster recovery: utilizza Azure Backup per ripristinare il database in un ambiente di test, seguendo un runbook (procedura automatizzata) che configura una nuova istanza del database e reindirizza l’applicazione di test. Questo esercizio assicura che i backup siano realmente utilizzabili e che il team sappia come procedere velocemente in caso di emergenza.
7. Monitoraggio e Risposta agli Incidenti
Implementare controlli di sicurezza riduce il rischio di incidenti, ma non li elimina completamente. È quindi indispensabile avere un sistema robusto di monitoraggio continuo e capacità di risposta agli incidenti (Incident Response) in Azure, per rilevare tempestivamente le minacce e reagire in modo coordinato.
Azure Monitor e Log Analytics: Azure Monitor è il servizio centrale per raccogliere metriche e log da tutte le risorse Azure. Permette di aggregare dati sulle prestazioni (CPU, memoria, utilizzo disco, latenza delle richieste, ecc.) e eventi (log di applicazioni, log di sistema, attività Azure). I dati di log possono essere inviati a un Log Analytics Workspace, dove tramite il linguaggio KQL (Kusto Query Language) possono essere interrogati e correlati. Ad esempio, si può usare Log Analytics per cercare in tutti i log di accesso chi ha generato errori 403 su un certo servizio, o per contare quante VMs hanno avuto un riavvio negli ultimi giorni. Azure Monitor consente anche di configurare alert su qualsiasi metrica o log: ad esempio, si può impostare un alert che scatti se il numero di login falliti su Azure AD supera una certa soglia in un’ora, o se una VM viene arrestata fuori orario, o se il traffico in ingresso su un’applicazione aumenta improvvisamente (potenziale segnale di DDoS).
Microsoft Sentinel (SIEM/SOAR): Per una visione unificata della sicurezza, Azure offre Microsoft Sentinel, un servizio di SIEM (Security Information and Event Management) e SOAR (Security Orchestration, Automation, and Response). Sentinel può aggregare dati da Azure Monitor/Log Analytics, ma anche da fonti esterne (ad esempio log di sistemi on-premises, feed di threat intelligence, log di servizi di terze parti tramite connettori). Sentinel viene utilizzato per definire regole di correlazione che identificano condizioni di potenziale incidente di sicurezza: ad esempio, la combinazione di un evento di creazione di un nuovo utente con privilegi elevati, seguito da un’attività anomala su una VM, potrebbe generare un incidente nel SIEM. Ogni incidente aggrega i vari eventi correlati e può essere analizzato dagli operatori della sicurezza. La parte SOAR di Sentinel permette di associare playbook di risposta automatici (spesso realizzati tramite Azure Logic Apps) agli incidenti: per esempio, se scatta un alert di “Impossible Travel” (ovvero un utente che esegue due accessi in rapida successione da luoghi geograficamente distanti, indicando un possibile furto di credenziali), si può automatizzare un playbook che resetta le credenziali di quell’utente, forzando un cambio password, invia una notifica al team SOC (Security Operations Center) e magari blocca temporaneamente l’account finché non si verifica l’attività.
Piani di risposta agli incidenti: Tecnologia a parte, è fondamentale avere un processo definito di Incident Response. Un buon piano di risposta prevede ruoli e responsabilità chiari (ad esempio, su modello RACI, definendo chi è Responsabile, chi deve Approvare, chi Consultare e chi Informare per ogni tipo di incidente), procedure dettagliate per varie categorie di incidenti (violazione di dati, ransomware, indisponibilità servizio, etc.) e strumenti predisposti per la comunicazione interna ed esterna durante la crisi. Azure può facilitare questo includendo runbook di Automation per compiti ripetitivi e integrando servizi come Azure DevOps o Teams per tracciare e comunicare lo stato degli incidenti.
Regolarmente, dovrebbero essere svolte delle esercitazioni (ad esempio table-top exercises) in cui il team di sicurezza e IT simula un attacco o un malfunzionamento grave e segue il piano di risposta, così da testarne l’efficacia e abituare il personale. Dopo ogni vero incidente o simulazione, un post-incident review dovrebbe identificare cosa ha funzionato e cosa no, in modo da migliorare continuamente il processo.
Integrazione con Defender for Cloud: i sistemi di monitoraggio includono anche le soluzioni specifiche per workload. Ad esempio, Microsoft Defender for Cloud (menzionato nella sezione panoramica) non solo dà raccomandazioni, ma genera allarmi di sicurezza quando rileva attività sospette su risorse come macchine virtuali, container, database, IoT, ecc. È importante integrare questi avvisi con il processo generale: Defender for Cloud infatti può essere configurato per inviare automaticamente gli alert a Microsoft Sentinel, così da unificare il trattamento degli incidenti in un’unica console. [
Esempi pratici:
· Applicazione di un playbook SOAR: come accennato, se Sentinel genera un incidente per Impossible Travel (un utente che risulta loggato da due paesi diversi a distanza di mezz’ora), un playbook automatico può scattare. Ad esempio: il playbook disabilita immediatamente l’account dell’utente sospetto e ne richiede il reset della password, invia un messaggio via email o Teams al team di sicurezza con i dettagli dell’alert, e crea un ticket sull’help desk per tracciare l’evento. In parallelo, attiva una funzione Lambda/Logic App che cerca nei log di accesso altri indizi (quali indirizzi IP usati) e aggiorna il ticket con queste informazioni. Questo tipo di automazione limita i danni potenziali in attesa che un operatore umano prenda in carico l’analisi approfondita.
· Dashboard di sicurezza e monitoraggio: un SOC aziendale realizza una workbook (dashboard interattiva) su Azure Monitor/Sentinel per avere visibilità in tempo reale su parametri di sicurezza chiave. Ad esempio, nella dashboard vengono mostrati: il numero di accessi falliti al sistema nelle ultime 24 ore, il conteggio di nuovi endpoint registrati con MFA, la lista degli utenti ad alto rischio identificati da Azure AD Identity Protection e i cambiamenti recenti alle regole degli NSG o dei firewall. Ogni elemento ha indicatori che segnalano se il valore è fuori dalla norma (ad esempio un picco di accessi falliti rispetto alla media). Questo consente al team di individuare rapidamente comportamenti anomali anche senza aspettare un alert formale.
8. Sicurezza delle Applicazioni
La sicurezza non riguarda solo l’infrastruttura, ma anche le applicazioni eseguite in Azure. Proteggere le applicazioni cloud richiede attenzione su più fronti: autenticazione e autorizzazione degli utenti, sicurezza del codice e delle dipendenze, configurazione sicura dei servizi applicativi e monitoraggio delle attività applicative.
Autenticazione e autorizzazione nelle applicazioni: Idealmente, le applicazioni non dovrebbero implementare meccanismi di autenticazione “fatti in casa”, ma integrare servizi di identità robusti. In Azure, le applicazioni possono usare Microsoft Entra ID (Azure AD) per autenticare gli utenti tramite protocolli standard come OAuth2 e OIDC (OpenID Connect). Ad esempio, una web app può utilizzare Entra ID per il login degli utenti aziendali, sfruttandone le funzionalità di MFA e Conditional Access automaticamente. Per i servizi all’interno dell’architettura (ad es. microservizi che comunicano tra loro), è consigliabile usare le Managed Identities e i token di Azure AD anziché condividere segreti statici. L’autorizzazione dovrebbe essere granulare: utilizzare ruoli applicativi o claims nei token JWT emessi da Azure AD per determinare cosa ogni utente o componente può fare (ad esempio un claim “role: approver” che l’app legge per consentire l’accesso a certe funzionalità).
Sicurezza del codice e DevOps: Le applicazioni vanno difese anche dalle vulnerabilità nel codice e nelle librerie utilizzate. Una buona pratica è adottare il modello DevSecOps, incorporando controlli di sicurezza nel ciclo di sviluppo. Ad esempio, si dovrebbero eseguire regolarmente scansioni del codice statico (SAST) per individuare bug di sicurezza (SQL injection, XSS, etc.) e scansioni delle dipendenze (SCA) per identificare librerie di terze parti affette da vulnerabilità note. Azure offre strumenti come Defender for DevOps che si integrano con sistemi di CI/CD (GitHub Actions, Azure DevOps pipelines) per eseguire queste analisi, oppure si possono usare tool open-source come CodeQL o Trivy. È importante anche generare un SBOM (Software Bill of Materials), ossia un elenco di tutte le componenti software e relative versioni, in modo da sapere rapidamente se un certo prodotto è affetto da una minaccia nota (ad esempio la libreria Log4j nel caso di Log4Shell). Se vengono trovate vulnerabilità critiche (CVE di severità alta), il processo di build dovrebbe segnalarle e potenzialmente bloccare la messa in produzione finché non sono risolte o mitigate.
Configurazione sicura dei servizi applicativi: Molte applicazioni in Azure girano su servizi gestiti come App Service, Azure Functions o su cluster di container come AKS (Azure Kubernetes Service). Queste piattaforme offrono integrazioni native con i servizi di sicurezza Azure: ad esempio, App Service e Functions possono essere isolati in una rete virtuale e accedere a database solo tramite Private Endpoint; AKS può usare soluzioni come Network Policies per filtrare il traffico tra pod e integrare Azure AD per l’autenticazione alle API del cluster. Quando le applicazioni espongono interfacce web, andrebbe sempre considerato l’uso di un Web Application Firewall (WAF). In Azure si può abilitare un WAF sulle istanze di Application Gateway o Azure Front Door, definendo regole che bloccano attacchi a livello applicativo come SQL injection, XSS, richieste a URL malevoli, ecc.. Un WAF ben configurato può fermare molte categorie di attacco prima che raggiungano proprio l’applicazione.
Protezione dei dati applicativi e dei segreti: Le applicazioni spesso hanno bisogno di chiavi API, stringhe di connessione, certificati – tutti dati sensibili che vanno protetti. La regola aurea è di non inserire mai segreti nel codice o nei file di configurazione in chiaro. Azure Key Vault dovrebbe essere usato per fornire questi segreti in modo sicuro: ad esempio, un’app web può recuperare al volo la stringa di connessione al database dal Vault, oppure meglio ancora usare una Managed Identity per connettersi al database senza avere una password. Questo è il concetto di secret-less: evitare la gestione manuale di password/segreti, affidandosi a meccanismi più sicuri come identità gestite e vault centralizzati.
Logging e monitoraggio applicativo: Le applicazioni dovrebbero generare log, soprattutto riguardo a eventi di sicurezza: ad esempio log di autenticazione utente, log di operazioni sensibili (come la modifica di dati critici, reset di password effettuati, ecc.). Questi log vanno inviati ad Azure Monitor/Log Analytics e potenzialmente a Sentinel per poter essere analizzati in caso di incidenti. Strumenti come Application Insights aiutano a raccogliere telemetria e tracciare errori applicativi, che spesso possono indicare tentativi di exploit (esempio: continui errori 401/403 potrebbero segnalare scansioni di endpoint non autorizzati).
Esempi pratici:
· API sicura con Entra ID e rate limiting: si sviluppa una API REST che deve essere utilizzata da client e applicazioni di terze parti. Invece di gestire account separati, gli sviluppatori integrano Azure AD: ciò significa che le entità che chiamano l’API ottengono un token OAuth2 da Entra ID con determinati scope (ambiti) o ruoli. L’API valida il token in ingresso su ogni chiamata, garantendo che l’utente o l’app chiamante sia autenticato e autorizzato a compiere quella specifica operazione. Inoltre, davanti all’API viene configurato Azure Front Door con WAF: questo permette di abilitare regole di rate limiting, ad esempio limitando il numero di richieste al secondo che ogni client può fare, prevenendo abusi o tentativi di brute force. Il WAF inoltre blocca automaticamente noti pattern di attacco applicativo.
· Pipeline CI/CD con controlli di sicurezza: il team DevOps configura la pipeline di build e release in modo che ad ogni commit di codice vengano eseguiti dei test di sicurezza. Per esempio, utilizzando plugin nell’agente di build, viene lanciata una scansione SAST del codice sorgente alla ricerca di vulnerabilità e una scansione SCA che analizza i pacchetti NPM/nuget/PyPI o i container base usati per vedere se contengono CVE note. Se, poniamo, viene trovata una vulnerabilità nota con severità High in una libreria, la pipeline può segnare il build come fallito e notificare gli sviluppatori che devono aggiornare quel componente prima di poter procedere al deploy. Soltanto dopo che il codice supera tutti i test (inclusi quelli di sicurezza) l’applicazione viene distribuita ad Azure, riducendo di molto la probabilità che vengano introdotte falle nel sistema in produzione.
9. Conformità e Automazione della Sicurezza
Man mano che l’infrastruttura Azure di un’organizzazione cresce, diventa fondamentale assicurarsi che tutte le regole di sicurezza vengano applicate consistentemente e che l’azienda riesca a dimostrare la conformità a standard interni o esterni. In parallelo, l’uso di metodologie DevOps e di automazione può aiutare a mantenere alto il livello di sicurezza riducendo gli sforzi manuali e gli errori.
Dashboard di conformità: Come accennato in precedenza, Microsoft Defender for Cloud include una sezione di Regulatory Compliance che mostra lo stato rispetto a vari standard. Per esempio, se l’organizzazione deve essere conforme al GDPR, ISO 27001 e CIS Benchmark, la dashboard evidenzierà per ciascuno di questi qual è la percentuale di controlli soddisfatti nell’ambiente Azure e quali controlli richiedono azioni. Questa visibilità è molto utile per audit e verifiche: invece di controllare manualmente decine di configurazioni, si ha un report centralizzato. Azure Policy è strettamente legata a questo, perché molti controlli di conformità si traducono in Policy Azure implementate (es: “Crittografia attiva su tutti i dischi” può essere una regola di ISO 27001 – Azure Policy può verificarlo automaticamente su tutte le VM).
Automazione dei rimedi: Affidarsi solo a verifiche manuali può essere inefficiente; Azure permette di automatizzare molte azioni di sicurezza. Ad esempio, con Azure Logic Apps o Functions si possono creare workflow che reagiscono a determinati eventi o raccomandazioni di sicurezza. Se Defender for Cloud segnala che una VM ha aperta la porta 22 (SSH) su Internet, si potrebbe avere un processo automatico che chiude la porta immediatamente e avvisa l’amministratore. Oppure, se una nuova risorsa viene creata senza i tag obbligatori, una funzione automatica potrebbe aggiungerli evitando di lasciare l’elemento non conforme. L’Automation Account di Azure consente di eseguire runbook (script PowerShell o Python predefiniti) in risposta ad eventi; così se un backup fallisce, si può tentarne un altro automaticamente, o se un utente è aggiunto a un gruppo privilegiato, si può notificare immediatamente il team di sicurezza. In pratica, ogni fase ripetitiva o standardizzata del ciclo di vita della sicurezza può essere orchestrata da strumenti di automazione, riducendo il tempo di reazione e assicurando che nessun passaggio critico venga dimenticato.
Controllo dei costi della sicurezza: L’implementazione di controlli di sicurezza in cloud può avere impatti sui costi (ad esempio, abilitare log dettagliati ovunque, tenere macchine di analisi accese h24, mantenere dati per lungo tempo). Azure offre Cost Management + Billing, uno strumento per monitorare e gestire i costi, che può essere usato anche per la sicurezza. Ad esempio, si può tenere traccia di quanto si spende in servizi di sicurezza (Sentinel, Defender for Cloud, backup, ecc.) e ottimizzare l’allocazione del budget. Spesso, però, i costi di sicurezza vanno visti come investimenti: un dashboard di cost management può aiutare a evidenziare come l’aumento di spesa in sicurezza (es. più logging) corrisponde a una riduzione del rischio o a evitare costi ben maggiori legati ad incidenti.
DevSecOps e Policy as Code: Per gestire la sicurezza in ambienti cloud molto dinamici, si adottano pratiche di continuous compliance integrate nel ciclo DevOps. Un esempio è il concetto di Policy as Code: le Azure Policy e le configurazioni di sicurezza vengono gestite come codice versionato (ad es. file JSON delle definizioni di policy tenuti in un repository Git). Ogni modifica a queste policy passa attraverso code review e pipeline di CI, e quando approvata viene distribuita in Azure (magari su un ambiente di test prima, poi in produzione). Questo garantisce che le regole di sicurezza siano soggette allo stesso rigore del codice applicativo e che qualsiasi modifica sia tracciabile. Inoltre, nelle pipeline di rilascio delle applicazioni si possono inserire test di conformità: ad esempio, prima di fare il deploy di una nuova infrastruttura (usando IaC, Infrastructure as Code, come Bicep o Terraform), eseguire una scansione con strumenti di compliance (come terraform compliance o gli Azure Resource Manager policy alias) per assicurarsi che quello che si sta per creare rispetti tutte le policy aziendali. Se qualcosa è fuori standard, la pipeline lo segnala o blocca il deploy. Questo modo di agire proattivo previene la creazione di risorse non conformi sin dall’inizio.
Blueprint e landing zone: Microsoft fornisce concetti come Azure Blueprints e landing zones, che sono modelli riutilizzabili di ambienti Azure con governance preimpostata. Un blueprint può contenere definizioni di policy, ruoli, e risorse base; applicandolo si crea un nuovo ambiente (ad esempio una subscription per un nuovo progetto) già configurato con tutte le regole di sicurezza richieste, senza doverle applicare a posteriori.
Report e audit: Infine, è importante predisporre report periodici sulla postura di sicurezza. Ad esempio, un rapporto trimestrale al management potrebbe includere il trend del Secure Score, il numero di incidenti avvenuti e risolti, lo stato di conformità rispetto agli standard chiave, e le azioni correttive intraprese. Questi report, oltre a soddisfare eventuali audit esterni, aiutano anche a mantenere alta l’attenzione dell’organizzazione sul tema e a prendere decisioni informate (come dove investire per migliorare ulteriormente la sicurezza).
Esempi pratici:
· Implementazione di “Policy as Code”: un team cloud crea un repository Git dedicato alle regole di governance Azure. Al suo interno ci sono file JSON di Azure Policy e Initiative (insiemi di policy) che definiscono requisiti come “tutti i dischi devono essere criptati con CMK” o “vietato creare NSG con regole troppo permissive”. Ogni modifica a questo repo viene sottoposta a code review. Una pipeline automatizzata controlla la sintassi delle policy e poi le distribuisce nelle subscription di destinazione usando script Azure CLI. Inoltre, per ogni applicazione nuova che viene rilasciata, si esegue uno step di pipeline che importa queste policy in modalità di sola valutazione sul modello delle risorse che l’app andrà a creare, segnalando in anticipo se qualcosa violerebbe le regole. Solo se l’infrastruttura “passa” i test di compliance, l’app viene effettivamente creata. Questo assicura che sviluppatori e team di progetto aderiscano alle politiche di sicurezza dall’inizio, integrandosi fluidamente nel processo DevOps.
· Reporting e miglioramento continuo: il responsabile della sicurezza cloud prepara un report trimestrale per l’ufficio rischi dell’azienda. Dal Secure Score di Defender for Cloud, risulta ad esempio che si è passati dal 65% all’80% nell’ultimo trimestre, grazie all’implementazione di 10 raccomandazioni ad alto impatto (dettagliate nel report). Viene allegato l’elenco dei controlli critici ancora non conformi (ad esempio la necessità di abilitare MFA per alcuni account esterni o di mettere in atto la crittografia su un paio di storage account legacy) e per ognuno è pianificata un’azione correttiva con relativo owner e data prevista. Questo processo formalizzato di rendicontazione aiuta a mantenere un ciclo di miglioramento continuo, in cui la postura di sicurezza viene regolarmente misurata, riferita e migliorata.
Conclusioni
La sicurezza in Azure è dunque un viaggio continuo che coinvolge tecnologie, persone e processi. In questa guida abbiamo esplorato come Azure fornisca una vasta gamma di strumenti e servizi per proteggere infrastruttura, identità, rete, dati e applicazioni, e come queste componenti possano essere orchestrate secondo principi di best practice (Zero Trust, minima privilegi, cifratura end-to-end, monitoraggio proattivo). Per uno studente o un professionista alle prime armi, il mondo della cloud security può sembrare complesso: il consiglio è di affrontarlo in modo strutturato, partendo dai concetti di base (come la responsabilità condivisa e i principi Zero Trust) e via via approfondendo gli aspetti più specifici (identità, rete, dati, applicazioni). È importante anche sperimentare: Azure offre ambienti di apprendimento e tier gratuiti con cui provare a impostare una rete sicura, a applicare una policy, a generare un alert su Sentinel, ecc. Solo con la pratica si riuscirà a comprendere davvero come questi elementi si integrano. Ricordiamoci infine che la sicurezza non è un prodotto che si compra ma un processo: richiede attenzione continua, aggiornamento costante sulle nuove minacce e sulle nuove difese, e una cultura diffusa che coinvolga tutti (dai manager agli sviluppatori, dagli amministratori agli utenti finali). Con le conoscenze di base acquisite da questa guida, si è pronti per approfondire ulteriormente e affrontare sfide pratiche nel campo della sicurezza su Azure.
Riepilogo capitolo
Il capitolo fornisce una panoramica completa delle pratiche e degli strumenti per garantire la sicurezza nell'ambiente cloud Azure, coprendo aspetti dalla gestione delle identità alla protezione delle reti, dalla crittografia dei dati al monitoraggio e risposta agli incidenti, fino alla conformità normativa e all'automazione.
· Modello di responsabilità condivisa: Microsoft protegge l'infrastruttura cloud, mentre il cliente è responsabile della configurazione sicura delle risorse create, con strumenti come Microsoft Defender for Cloud che monitorano la postura di sicurezza e la conformità normativa.
· Modello Zero Trust: Si basa su verifica esplicita degli accessi, principio del privilegio minimo e presunzione di violazione, implementati tramite MFA, RBAC, PIM, segmentazione di rete e monitoraggio continuo con servizi come Azure Sentinel.
· Gestione delle identità e accessi: Microsoft Entra ID gestisce utenti, gruppi e policy di accesso condizionale con MFA e privilegi temporanei tramite PIM, oltre a identità gestite per servizi e revisione periodica degli accessi per mantenere il principio del minimo privilegio.
· Crittografia e gestione chiavi: Azure cifra automaticamente i dati a riposo e in transito, con possibilità di usare chiavi gestite dal cliente tramite Azure Key Vault, che offre sicurezza, controllo degli accessi, rotazione automatica e audit completo.
· Sicurezza di rete: La protezione si basa su Network Security Group per regole di base, Azure Firewall per filtraggio avanzato, VPN per connettività sicura, Private Endpoint per accessi privati ai servizi PaaS, protezione DDoS e strumenti di monitoraggio come Network Watcher.
· Protezione risorse e backup: Azure Policy applica criteri di sicurezza e compliance, mentre Backup Center gestisce backup con caratteristiche di immutabilità e ripristino point-in-time; Azure Site Recovery abilita la disaster recovery e strumenti di change tracking con auto-remediation migliorano la resilienza.
· Monitoraggio e risposta incidenti: Azure Monitor raccoglie metriche e log, mentre Microsoft Sentinel integra SIEM/SOAR per correlare eventi e automatizzare risposte tramite playbook; piani di incident response e esercitazioni periodiche garantiscono prontezza operativa.
· Sicurezza delle applicazioni: Le app devono integrare Entra ID per autenticazione e autorizzazione, adottare DevSecOps con scansioni di sicurezza, configurare servizi gestiti in modo sicuro, proteggere segreti con Key Vault e monitorare attività tramite log e Application Insights.
· Conformità e automazione: Defender for Cloud e Azure Policy assicurano visibilità e applicazione coerente delle regole di sicurezza; l'automazione tramite Logic Apps e runbook riduce errori; pratiche DevSecOps e Policy as Code integrano la sicurezza nel ciclo di vita; report periodici supportano miglioramento continuo.
CAPITOLO 10 – Il servizio di automazione
Introduzione
Azure Automation è un servizio cloud gestito di Microsoft Azure che consente di automatizzare attività ripetitive e orchestrare flussi di lavoro su ambienti Azure e ambienti ibridi (ossia combinazioni di cloud e infrastrutture locali). In pratica, l’automazione permette di trasformare operazioni manuali – come l’avvio e l’arresto di macchine virtuali, la pulizia periodica di risorse inutilizzate, l’esecuzione di backup o la rotazione regolare di segreti e password – in runbook (script automatizzati) riutilizzabili e pianificabili.
Attraverso Azure Automation, un’azienda può conseguire diversi benefici chiave:
· Efficienza operativa: le attività ripetitive vengono eseguite automaticamente, liberando tempo agli operatori umani per compiti più complessi.
· Affidabilità: i processi automatizzati riducono gli errori umani e garantiscono risultati coerenti; uno script esegue sempre gli stessi passi, nello stesso ordine, assicurando omogeneità nelle operazioni.
· Governance e audit: ogni azione eseguita dai runbook viene tracciata nei log, permettendo audit dettagliati. Si può sempre risalire a chi o cosa ha eseguito una determinata operazione e quando, utile per controlli di sicurezza e conformità.
· Maggiore sicurezza: l’automazione può applicare regole di sicurezza in modo sistematico (ad es. spegnere automaticamente risorse critiche fuori dall’orario di lavoro per ridurre la superficie di attacco, o ruotare le chiavi di accesso a intervalli regolari). Inoltre, gestendo le attività tramite identità e permessi controllati, si evitano azioni manuali potenzialmente rischiose.
· Integrazione con altri servizi Azure: Azure Automation si integra con molti altri servizi (come Monitoraggio, Archiviazione, Database, ecc.), permettendo di innescare script in risposta a eventi (es. un evento di allarme) e di interagire trasversalmente con vari componenti dell’infrastruttura.
Un esempio concreto di ciò che si può fare con Azure Automation è la gestione automatizzata del ciclo di vita delle macchine virtuali (VM). Normalmente, un amministratore cloud potrebbe avviare o arrestare manualmente una VM tramite il portale Azure; con l’automazione, invece, queste azioni possono essere programmate e standardizzate. Immaginiamo di avere una serie di runbook con nomi indicativi come CreateVM.ps1, DeleteVM.ps1, StartVM.ps1 e StopVM.ps1. Ciascuno di essi svolge rispettivamente la creazione di una nuova macchina virtuale, l’eliminazione di una VM, l’avvio di una VM esistente e l’arresto di una VM. Questi runbook possono essere pianificati per funzionare automaticamente in base a una pianificazione (per esempio, CreateVM.ps1 può essere eseguito ogni lunedì alle 9:00 per creare una VM di test, e DeleteVM.ps1 ogni venerdì alle 18:00 per eliminarla; oppure StartVM.ps1 ogni mattina prima dell’orario di lavoro per accendere determinate VM, e StopVM.ps1 la sera per spegnerle e risparmiare costi). In aggiunta, ogni esecuzione lascia una traccia consultabile: ad esempio, l’avvio di una VM tramite StartVM.ps1 registrerà un log con l’orario di avvio e l’esito dell’operazione.
Come funziona internamente Azure Automation? Un’illustrazione tipica mostrerebbe che tutto parte da un evento o una pianificazione: questo evento attiva un runbook specifico; il runbook esegue una serie di azioni (ad esempio interagire con l’API Azure per avviare una VM o modificare un servizio); infine tutta l’attività viene registrata in un log per audit e monitoraggio futuro. Nel diagramma concettuale si vedono spesso icone di una VM, di un account di archiviazione (Storage), di un servizio di gestione dei segreti come Azure Key Vault, e di un servizio di monitoraggio. Queste icone indicano che l’automazione coinvolge diversi tipi di risorse: ad esempio, un runbook potrebbe avviare una VM (icona VM), leggere o scrivere file di configurazione su uno Storage account (icona Storage), recuperare una password o un certificato da Key Vault (icona Key Vault) e infine inviare i log ad Azure Monitor o Log Analytics (icona Monitoraggio).
In sintesi, Azure Automation offre un ambiente centralizzato dove definire e controllare script automatizzati, con l’obiettivo di rendere più snella, sicura e governata la gestione operativa di infrastrutture cloud anche complesse. Nei capitoli successivi esploreremo in dettaglio i vari componenti e funzionalità di questo servizio, mostrando come realizzare concretamente tali automazioni.
Inquadramento argomenti del capitolo con slides illustrate
Azure Automation è un servizio gestito che permette di eseguire attività ripetitive, orchestrare flussi operativi e applicare configurazioni su ambienti Azure e ibridi. L'automazione consente di trasformare operazioni manuali, come l'avvio e l'arresto delle VM, la pulizia delle risorse, il backup e la rotazione dei segreti, in runbook riutilizzabili e pianificati. I benefici principali includono efficienza operativa, affidabilità, governance attraverso audit e sicurezza, e integrazione con altri servizi Azure. Un esempio concreto è la creazione automatica di macchine virtuali tramite script, come visibile nella dashboard con i runbook CreateVM.ps1, DeleteVm.ps1, StartVm.ps1 e StopVm.ps1. Diagrammi visivi mostrano il flusso: evento, runbook, azione e logging, con icone per VM, Storage, Key Vault e Monitor.
Un runbook è uno script automatizzato che incapsula una procedura operativa. In Azure Automation, puoi creare runbook in PowerShell, Python o come grafici visuali, offrendo flessibilità per diversi livelli di esperienza. I runbook possono essere avviati manualmente, tramite pianificazione, webhook o integrati con servizi come Logic Apps. La gestione delle variabili, delle credenziali e dei moduli è essenziale, così come l'uso di Managed Identity per l'accesso sicuro alle risorse. È importante che i runbook siano idempotenti, ossia possano essere rieseguiti senza effetti collaterali. Un esempio pratico è l'avvio programmato di una VM dieci minuti prima dell'inizio del turno, con controllo dello stato e notifica a Teams. I diagrammi suggeriscono un flowchart che parte dall'input dei parametri, passando per autenticazione, validazione dello stato, azione e infine log e notifica.
L'Automation Account è il contenitore centrale che ospita runbook, schedule, variabili, connection, certificati, credenziali e moduli. Qui si definiscono le identità gestite, le autorizzazioni tramite RBAC e IAM, e si integrano i log con servizi come Log Analytics. Le best practice prevedono la separazione degli account per diversi ambienti e workload, l'abilitazione delle impostazioni diagnostiche, la versionatura dei runbook e l'utilizzo di Key Vault per la gestione sicura dei segreti. Un esempio pratico è l'account Ops-Prod, che accede a Storage e Key Vault e limita l'esecuzione alle reti autorizzate tramite Private Endpoint. Lo schema visivo mostra l'Automation Account al centro, con asset periferici collegati e flussi verso Log Analytics.
Il Hybrid Runbook Worker consente di eseguire runbook su server locali, sia on-premises che VM in altri cloud, mantenendo orchestrazione e logging in Azure. È ideale quando l'automazione deve accedere a risorse interne o seguire policy aziendali che richiedono azioni all'interno della rete privata. La configurazione prevede l'installazione dell'agente, la registrazione del server nel gruppo HRW e la selezione dell'esecuzione Hybrid nei runbook. Occorre considerare la latenza, la disponibilità della macchina, la gestione delle patch e il principio del least privilege per le credenziali. Un esempio pratico è l'avvio di un installer MSI su Server01 e la scrittura dei log su Log Analytics. Il diagramma mostra il flusso tra Azure Automation e il server HRW, con comando, esecuzione, logs e restrizioni di rete.
Update Management in Azure Automation permette di rilevare, pianificare e applicare patch a VM Azure e server on-premises, sia Windows che Linux. È possibile creare pianificazioni di deployment, definire inclusioni ed esclusioni di aggiornamenti, impostare script pre e post applicazione e generare report di conformità. L'automazione delle patch riduce l'esposizione a vulnerabilità e garantisce la compliance con le policy. Si integra con Maintenance Configuration per coordinare i riavvii e con Change Tracking per monitorare le variazioni. Esempi pratici includono patch mensili pianificate con controlli pre e post applicazione, ed eccezioni per driver instabili. La timeline visiva mostra le fasi di scansione, pianificazione, applicazione, validazione e report, con indicatori di successo o fallimento.
Azure Automation State Configuration estende PowerShell DSC con un servizio cloud pull, permettendo di distribuire configurazioni e moduli, registrare nodi e monitorare la conformità. Con DSC si dichiara la configurazione desiderata, mentre il Local Configuration Manager applica e mantiene lo stato corretto nel tempo, correggendo eventuali drift. È ideale per hardening di sistema, installazione di feature applicative e impostazione di parametri standard come TLS e audit. Gli esempi includono la definizione di criteri di sicurezza e la configurazione di application server come IIS in modo dichiarativo. Lo schema visivo mostra LCM su ogni nodo, con frecce verso il pull server Automation e il pannello di conformità.
I runbook di Azure Automation possono essere integrati in flussi più ampi tramite Logic Apps, Power Automate e API REST o webhook. Questo consente scenari come gestione on-call, ticketing ITSM, notifiche operative e approvazioni. È possibile chiamare runbook da applicazioni personalizzate, inviare Adaptive Cards su Microsoft Teams o reagire a eventi Event Grid. Tra i pattern comuni: notifica e approvazione via Teams, incident automation su alert e rotazione di segreti in Key Vault. Un esempio pratico è il runbook che spegne VM di sviluppo, pubblica il riepilogo su Teams e archivia i log. Il diagramma mostra la sequenza: alert, Logic App, approvazione Teams, runbook e aggiornamento CMDB.
Applicare una security baseline è fondamentale nell'automazione Azure. Si utilizzano RBAC e IAM per assegnare ruoli minimi, Managed Identity per autenticare i runbook senza credenziali hardcoded, e audit log per tracciare le attività e cambiamenti. Le policy impongono l'uso di MSI e la configurazione obbligatoria dei diagnostic settings. Le iniziative di policy possono essere collegate ai management group per garantirne l'applicazione sistematica. Gli esempi pratici includono la definizione automatica di policy che impediscono il deploy non conforme e report mensili sull'affidabilità dei job. La checklist visiva include RBAC, Identity, Logs, Policy e un diagramma di flusso che collega job, log, workbook, alert e revisione.
Con Cost Management + Billing integrato ad Automation, è possibile creare runbook che ottimizzano i costi spegnendo VM inattive, ridimensionando SKU e archiviando storage su tier più economici. Si possono leggere i dati di costo via API o export, generare report e alert su budget superati. Le buone pratiche prevedono il tagging coerente delle risorse, la pianificazione degli spegnimenti per ambienti non produttivi e la verifica degli impatti sui SLA. Gli esempi mostrano runbook che analizzano metriche di utilizzo prima di deallocare, inviano riepiloghi a Teams e spostano blob datati in Archive. Il diagramma visualizza la policy di costo, con input da Cost Management, regole, azioni e feedback.
Le migliori pratiche per Azure Automation includono la documentazione dettagliata dei runbook e delle procedure, il test in ambienti separati prima della produzione e l'uso di variabili di ambiente per maggiore flessibilità. È importante mantenere README e note con obiettivi, prerequisiti e scenari di errore, collegare i runbook ai work items, usare versionamento e revisioni PR, e rilasciare solo dopo test di integrazione. La configurabilità si ottiene spostando i parametri in variabili, Key Vault o App Configuration ed evitando hardcoding. La sicurezza si garantisce con Managed Identity, RBAC minimo e rotazione dei segreti, mentre l'affidabilità richiede runbook idempotenti e strategie di ripristino. La governance dei costi si realizza automatizzando la pulizia delle risorse orfane e lo shutdown programmato. Lo schema visivo mostra una checklist pronta all'uso e un workflow CI/CD per runbook, con le fasi di lint, test, import, deploy e monitor.
1. Runbook e Automazione delle Attività
Il runbook è il cuore dell’automazione in Azure Automation. Un runbook è essenzialmente uno script automatizzato che racchiude al suo interno una procedura operativa. In termini più semplici, è una sequenza di comandi o istruzioni (che può includere logica condizionale, cicli, chiamate ad altri servizi, etc.) progettata per svolgere un compito specifico senza intervento manuale, o con intervento minimo.
All’interno di Azure Automation, esistono varie tipologie e formati di runbook: è possibile crearli usando linguaggi di scripting come PowerShell (molto comune in ambiente Microsoft) o Python, oppure attraverso un’interfaccia grafica che permette di costruire runbook sotto forma di diagrammi di flusso (i cosiddetti runbook grafici o visuali). Questa flessibilità consente a figure con competenze diverse di utilizzare il servizio: l’amministratore esperto di PowerShell potrà scrivere script complessi, mentre chi preferisce un approccio più visuale potrà trascinare attività predefinite in un workflow grafico.
Modalità di esecuzione dei runbook: una volta creato, un runbook può essere eseguito in diversi modi:
· Manualmente: un operatore può avviare un runbook su richiesta, ad esempio dal portale Azure o via PowerShell, quando serve.
· Pianificazione programmata (Schedule): si può impostare un orario e una frequenza (ad esempio: ogni giorno a mezzanotte, oppure ogni lunedì alle 7:00) per eseguire automaticamente il runbook. Questa è una delle forme più potenti: consente di creare veri e propri job ricorrenti per manutenzioni o controlli periodici.
· Webhook e API: Azure Automation permette di esporre i runbook tramite URL unici (webhook) o chiamate API REST. In questo modo, sistemi esterni o applicazioni custom possono attivare i runbook inviando semplicemente una richiesta HTTP. Ad esempio, un sistema di ticketing potrebbe inviare una chiamata API a un runbook per effettuare una verifica appena viene aperto un ticket.
· Integrazione con altri servizi (es. Logic Apps): un runbook può essere avviato come parte di un flusso orchestrato da servizi come Azure Logic Apps o Power Automate (vedremo dettagli nel Capitolo 7). Questi servizi possono fungere da “regista”, chiamando runbook come sotto-attività all’interno di processi aziendali più ampi.
Gestione degli asset di automazione: per scrivere runbook efficaci, Azure Automation fornisce anche spazi per gestire asset come Variabili, Credenziali, Certificati e Moduli:
· Le variabili sono utili per memorizzare dati a cui i runbook possono accedere e che potrebbero cambiare col tempo (per esempio, il nome di un ambiente, un valore di configurazione, ecc.), senza dover modificare il codice dello script.
· Le credenziali (e certificati) servono a memorizzare in modo sicuro informazioni sensibili come username e password o chiavi che i runbook useranno. Azure Automation consente di gestire queste credenziali criptandole e riferendole nello script senza esporle in chiaro.
· I moduli sono librerie o pacchetti aggiuntivi (ad esempio moduli PowerShell) che possono essere importati nell’ambiente di Azure Automation per estendere le funzionalità disponibili nei runbook. Per esempio, esistono moduli specifici per interagire con servizi Azure (Azure Az Modules), con Office 365, con SQL Server, ecc. Importando questi moduli, i runbook potranno utilizzare cmdlet e funzioni aggiuntive specifiche.
Sicurezza nell’esecuzione dei runbook: un concetto fondamentale nella gestione dei runbook è l’uso delle Managed Identity (identità gestite) di Azure. Una Managed Identity è un’identità fornita automaticamente da Azure ad un servizio (in questo caso all’account di automazione o al runbook stesso) per consentirgli di autenticarsi presso i servizi Azure senza bisogno di memorizzare credenziali nel codice. In pratica, invece di inserire nel runbook una password o una chiave di accesso (cosa sconsigliata e poco sicura), si assegna un’identità gestita: Azure dietro le quinte fornirà un token di autenticazione quando il runbook dovrà, ad esempio, interagire con una macchina virtuale o leggere un segreto in Key Vault. Ciò migliora la sicurezza, perché elimina la necessità di segreti statici nello script e facilita la gestione dei permessi attraverso Azure Active Directory e RBAC (Role-Based Access Control).
Idempotenza e robustezza: è considerata una buona pratica scrivere runbook idempotenti, cioè progettati in modo che se vengono eseguiti più volte, l’effetto finale sia lo stesso della singola esecuzione, senza effetti collaterali indesiderati. Ad esempio, un runbook che si occupa di accendere una VM dovrebbe prima controllare lo stato della VM: se è già accesa, potrebbe evitare di eseguire nuovamente il comando di avvio, oppure eseguirlo comunque ma il risultato netto rimane “VM accesa”. Ciò evita problemi qualora, per errore o necessità, un runbook venga lanciato più volte di quanto previsto. Allo stesso modo, in caso di errore a metà esecuzione, un runbook ben progettato dovrebbe poter essere rilanciato una volta risolto l’errore, senza causare incoerenze (ad esempio evitando di creare duplicati di una risorsa se la prima creazione era fallita a metà).
Esempio pratico: consideriamo il caso di un’azienda che vuole assicurarsi che una certa macchina virtuale sia pronta e funzionante ogni mattina prima dell’inizio del turno lavorativo. Senza automazione, un tecnico dovrebbe ricordarsi di accedere e avviare la VM manualmente ogni giorno. Con Azure Automation, si può creare un runbook (es. StartWorkVM.ps1) che:
1. Controlla l’ora corrente e la confronta con l’orario di inizio turno (ad esempio 9:00).
2. Se mancano 10 minuti all’inizio del turno, verifica lo stato attuale della VM (è spenta?).
3. Se la VM risulta spenta, procede ad avviarla; se è già accesa, non fa nulla (comportamento idempotente).
4. Dopo aver avviato (o se era già avviata), invia magari una notifica su Microsoft Teams o via email ai responsabili, per comunicare che “La VM X è accesa e pronta all’uso”.
L’esecuzione di questo runbook può essere pianificata ogni giorno feriale alle 8:50, in modo che compia automaticamente la procedura. Notiamo alcuni aspetti del design: il runbook potrebbe utilizzare una variabile per la ID della VM o il suo nome, in modo da poter riutilizzare lo stesso script anche per altre VM semplicemente cambiando la variabile; utilizzerà le credenziali o la Managed Identity associata per ottenere i permessi di accendere la VM; includerà controlli sullo stato attuale della VM per essere idempotente; infine userà l’API di Teams o email (fornendo opportuni moduli e credenziali) per inviare la notifica finale.
Diagramma di flusso tipico di un runbook: il funzionamento interno di un runbook può essere rappresentato tramite un flowchart. Immaginiamo il diagramma menzionato nella slide: esso parte da un input di parametri (ad esempio il nome della VM da gestire o altri parametri contestuali), poi passa per uno step di autenticazione (il runbook ottiene i permessi necessari, ad esempio tramite Managed Identity, per interagire con le risorse Azure), quindi esegue una validazione dello stato (controllo condizioni iniziali, ad esempio verifica se la VM è spenta prima di tentare di avviarla), procede con l’azione vera e propria (accendere la VM), e infine effettua operazioni di log e notifica (scrive nei log l’esito dell’operazione e invia eventualmente notifiche). Questo schema di base – input, autenticazione, condizione, azione, output – si ritrova in molti runbook e aiuta a progettarli con chiarezza.
In conclusione, i runbook sono lo strumento fondamentale per automatizzare le attività: comprendere come scriverli, parametrizzarli, securizzarli e integrarli con il resto dell’ambiente Azure è essenziale per sfruttare appieno Azure Automation. Nei prossimi capitoli vedremo dove risiedono (Automation Account), come possono essere eseguiti in ambienti ibridi e come interagiscono con altre funzionalità.
2. Automation Account: Il Contenitore Centrale
Tutti i runbook e le configurazioni di cui abbiamo parlato devono risiedere da qualche parte all’interno di Azure. In Azure Automation, quell’unità organizzativa centrale è l’Automation Account. Un Automation Account è un’entità Azure (creata tipicamente tramite il portale Azure o script di provisioning) che funge da contenitore per tutto ciò che riguarda l’automazione in uno specifico contesto. Pensiamo all’Automation Account come al “quartier generale” in cui vivono e vengono gestiti i runbook e gli elementi correlati.
All’interno di un Automation Account si trovano infatti:
· I Runbook stessi, che vi vengono creati o importati. Essi risiedono nell’account, possono essere organizzati, editati e avviati da lì.
· Gli Schedule (pianificazioni) associati: è possibile definire nell’account orari ricorrenti o singoli in cui eseguire determinati runbook. Ad esempio, un schedule “Ogni giorno alle 8:00” può essere creato e poi associato a un runbook per attivarlo a quell’ora.
· Le Variabili, Credenziali, Connection (ovvero definizioni di connessione a servizi esterni), i Certificati e i Moduli di cui si è detto nel capitolo precedente. Tutti questi asset vengono gestiti centralmente nell’Automation Account, permettendo ai runbook in esso contenuti di accedervi.
· Le impostazioni di identità gestita (Managed Identity) dell’account: è possibile abilitare un’identity di Azure AD per l’Automation Account stesso, cosicché tutti i runbook al suo interno possano utilizzarla per accedere alle risorse Azure con i permessi assegnati a tale identità.
· Le configurazioni di logging e diagnostica: un Automation Account può essere connesso ai servizi di log e monitoraggio (come Azure Monitor Logs, conosciuto anche come Log Analytics) per registrare tutte le esecuzioni dei runbook, gli output generati, eventuali errori, ecc. Ciò è fondamentale per tenere traccia delle attività e per debugging.
Tramite il controllo degli accessi (IAM – Identity and Access Management – integrato con Azure RBAC), possiamo inoltre definire chi all’interno dell’organizzazione ha accesso all’Automation Account e a cosa. Ad esempio, potremmo dare a un team di sviluppatori il ruolo di “Automation Runbook Contributor” permettendo loro di creare e modificare runbook, ma magari non il ruolo di “Automation Operator” se non vogliamo che li eseguano in produzione; oppure potremmo limitare che solo alcuni utenti possano aggiornare le credenziali salvate. Azure RBAC consente di assegnare ruoli granulari su risorse Azure, incluso l’Automation Account e i suoi componenti.
Best practice nella gestione degli Automation Account: poiché l’Automation Account è un contenitore così critico, vi sono alcune linee guida che conviene seguire per un utilizzo ottimale:
· Separazione degli ambienti: è consigliabile creare Automation Account separati per ambienti diversi, ad esempio uno per l’ambiente di Produzione e uno per quello di Sviluppo/Test. In questo modo, i runbook di test possono essere provati senza interferire con quelli di produzione, riducendo il rischio di eseguire accidentalmente script in ambienti sbagliati. Allo stesso modo, se diverse unità di business o progetti hanno esigenze di automazione diverse, si potrebbero separare per tenere il tutto organizzato e applicare regole specifiche a ciascuno.
· Impostazioni diagnostiche abilitate: sin dalla creazione dell’Automation Account, è bene attivare la raccolta dei log diagnostici verso un Log Analytics Workspace o un account Storage. Ciò include log di job (esecuzione dei runbook), log di aggiornamento (se si usa Update Management), log di errori, ecc. Avere questi dati consente di monitorare e generare alert su runbook che falliscono, su job che impiegano troppo tempo, ecc., garantendo visibilità sull’automazione.
· Versionamento dei runbook: quando si modificano runbook complessi è utile mantenere versioni o backup. Azure Automation in sé offre la distinzione tra bozza (draft) e pubblicato (published) per i runbook, ma per maggiore controllo spesso gli script sono gestiti esternamente con sistemi di controllo versione (Git). Integrando un flusso DevOps (vedremo un cenno nel capitolo 10), si può fare in modo che ogni modifica sia tracciata e testata prima di essere aggiornata nell’Automation Account.
· Uso di Azure Key Vault per segreti: se i runbook hanno bisogno di password, chiavi o certificati, una best practice è non solo usare l’area Credenziali dell’Automation Account, ma valutare di collegare l’account con Azure Key Vault, il servizio specializzato nella gestione sicura dei segreti. In tal modo, i runbook possono recuperare al volo segreti aggiornati dal Key Vault (ad esempio password ruotate periodicamente) senza che tali valori siano mai visibili o memorizzati staticamente nell’Automation Account. Questo aggiunge un ulteriore livello di sicurezza e centralizzazione nella gestione delle chiavi.
· Principio del minimo privilegio: l’Automation Account (e la sua identità gestita) dovrebbe avere accesso solo alle risorse strettamente necessarie per i runbook che contiene. Ad esempio, se i runbook in un dato account si occupano solo di gestire macchine virtuali in una specifica Resource Group, l’identità associata dovrebbe avere permessi limitati a quel Resource Group e magari solo azioni specifiche (es. avviare/arrestare VM). Così, in caso di problemi o abuso, si limita l’impatto potenziale.
Esempio pratico: immaginiamo un Automation Account chiamato Ops-Prod utilizzato dal team operativo per le attività sull’ambiente di produzione. Seguendo le best practice:
· L’account Ops-Prod è stato creato separatamente da Ops-Test (usato per test interni). Entrambi hanno runbook simili, ma puntati a risorse diverse.
· Su Ops-Prod è stata abilitata una Managed Identity con i ruoli RBAC minimi necessari (ad esempio “Contributor” su alcune risorse chiave di produzione).
· I runbook in Ops-Prod utilizzano variabili e credenziali protette per riferire risorse di produzione (come stringhe di connessione, nomi di server, ecc.), e alcuni valori sensibili li prendono dal Key Vault aziendale.
· Le impostazioni diagnostiche dell’Automation Account inviano tutti i log su Log Analytics, dove il team di monitoraggio ha impostato alert che notificano se un job fallisce oppure se un runbook impiega più di X minuti (potrebbe indicare un hang o un problema).
· L’account Ops-Prod è configurato per funzionare solo su reti autorizzate: mediante l’uso di un Private Endpoint, le comunicazioni dall’Automation Account verso i servizi di Azure (per eseguire runbook su macchine in una Virtual Network specifica) sono limitate a livello di rete virtuale. Ciò significa che i runbook non possono interagire con risorse al di fuori della rete aziendale designata, aggiungendo un ulteriore controllo di sicurezza e conformità alle policy aziendali.
· Dal punto di vista organizzativo, solo i membri del team di operazioni hanno accesso di contributor a Ops-Prod, mentre altri team possono avere accesso in sola lettura per vedere i log ma non per eseguire o modificare runbook.
Diagramma concettuale: il diagramma di questa sezione mostrava al centro un blocco “Automation Account” circondato da icone che rappresentano i vari asset: runbook, schedule, variabili, credenziali, moduli, ecc., tutti collegati a questo contenitore centrale. Da Automation Account partono inoltre frecce verso un simbolo di Log Analytics, indicando che i log e i dati diagnostici vengono inviati a un sistema di monitoraggio centralizzato. L’insieme delle icone suggerisce come l’Automation Account sia l’hub in cui convergono sia elementi in entrata (definizioni di runbook, asset, configurazioni) sia in uscita (log, output).
In sintesi, l’Automation Account è il fondamento sul quale costruire la strategia di automazione: una configurazione accurata e conforme alle best practice di questo elemento garantisce che i runbook possano operare correttamente e in sicurezza, fornendo allo stesso tempo i meccanismi di controllo e monitoraggio necessari.
3. Hybrid Runbook Worker: Automazione Ibrida
Azure Automation è un servizio cloud, ma spesso esiste l’esigenza di automatizzare operazioni che devono avvenire fuori dal cloud o comunque all’interno di ambienti locali o ristretti. Pensiamo ad attività che coinvolgono server fisici nel datacenter aziendale, oppure macchine virtuali che risiedono in altri cloud o in reti isolate con accesso limitato a Internet. Per estendere la potenza di Azure Automation anche a questi scenari, esiste la funzionalità chiamata Hybrid Runbook Worker (HRW).
Un Hybrid Runbook Worker è un agente che si installa su una macchina (può essere un server on-premises, ovvero fisico o virtuale nel data center locale, oppure anche una VM ospitata in un altro ambiente cloud o in Azure stessa ma che funge da “ponte” verso una rete privata). Questo agente registra la macchina come un worker ibrido presso un Automation Account. Da quel momento, l’Automation Account sarà in grado di inviare i runbook da eseguire direttamente su quella macchina, anziché eseguirli nel cloud Azure.
Cosa comporta questo? In pratica abbiamo due modalità di esecuzione dei runbook:
a) In cloud (Azure): dove i runbook girano all’interno dell’ambiente Azure Automation cloud (sui worker gestiti da Azure). È l’impostazione predefinita ed è ideale per compiti che interagiscono con servizi Azure o comunque non richiedono accessi a risorse che stanno dietro il firewall aziendale.
b) Ibrida (Hybrid Worker): dove i runbook girano sul computer locale su cui l’agente è installato. In questo caso Azure funge solo da orchestratore: dice al worker “esegui questo runbook”, e il worker lo esegue localmente sulla sua macchina, mantenendo però il collegamento con Azure per riportare output, log e stato dell’esecuzione. Dal punto di vista dell’utente, si continua a gestire tutto dall’Automation Account (si lancia un runbook come al solito), ma in realtà “dietro le quinte” quell’esecuzione avviene altrove.
Quando usare un Hybrid Runbook Worker? I casi tipici includono:
· Accesso a risorse on-premises: se un runbook deve interagire con un database o un sistema che risiede solo nella rete locale (ad esempio, spegnere un server fisico via comando IPMI, leggere un file condiviso su un file server interno, o eseguire script su un server che non è esposto a Internet), allora quel runbook dovrà essere eseguito da dentro la rete locale. L’HRW consente questo, fungendo da “braccio esteso” di Azure Automation dentro la rete on-prem.
· Requisiti di compliance o policy: alcune organizzazioni hanno regole che impediscono l’esecuzione di certi script in cloud per motivi di riservatezza o controllo; con l’HRW, lo script risiede ed esegue localmente, ma beneficia comunque del coordinamento centralizzato.
· Multi-cloud o ambienti ibridi complessi: l’azienda potrebbe avere infrastrutture distribuite su Azure, AWS, server fisici e altro. Azure Automation con HRW può fungere da singolo punto di gestione per script che agiscono in tutti questi luoghi diversi, tramite agenti installati dove serve.
Come si configura un Hybrid Runbook Worker? I passi essenziali sono:
· Sul server (Windows o Linux) scelto per agire come worker, si installa il Microsoft Monitoring Agent (MMA) o l’agente specifico di Azure Automation (in passato l’HRW usava MMA, oggi la funzionalità è integrata nel nuovo agente Azure Monitor per macchine Arc). Durante l’installazione, si forniscono le credenziali di registrazione per l’Automation Account a cui connettere il worker.
· All’interno dell’Automation Account, si definisce un gruppo di Hybrid Worker e si registra il server appena installato a questo gruppo. È possibile avere più server nel gruppo per resilienza o per suddividere carichi.
· Quando si crea o modifica un runbook, si può scegliere di eseguirlo su un Hybrid Worker invece che sul cloud. Ciò può essere fatto specificando il nome del gruppo HRW come destinazione di esecuzione.
· Da quel punto in poi, l’esecuzione del runbook avviene sul server locale: l’agente scarica dallo Automation Account il codice del runbook, lo esegue sulla macchina e comunica costantemente con Azure per inviare i log ed esito. Se apriamo il portale Azure per vedere il job, lo vedremo comunque simile agli altri, con i suoi output, solo contrassegnato come eseguito su un determinato Hybrid Worker.
Cose da tenere a mente con HRW:
· Latenza e connettività: l’esecuzione dipende dalla connessione tra il server on-prem e il servizio Azure Automation. Il server (tramite l’agente) deve poter raggiungere Azure (uscendo verso Internet sui punti di ingresso di Azure Automation). Questo introduce una latenza leggermente maggiore rispetto all’esecuzione in cloud locale ad Azure, quindi runbook che richiedono bassa latenza o interazioni molto rapide devono tenerne conto.
· Disponibilità del worker: se il server che funge da Hybrid Worker è spento, offline o ha problemi (es. manutenzione, crash, rete giù), i runbook destinati a quel worker falliranno perché non c’è nessuno a eseguirli. È quindi importante monitorare la salute dei worker e magari averne più di uno per compiti critici (ridondanza).
· Manutenzione del worker: i server HRW vanno gestiti come qualsiasi altro server, assicurandosi che siano aggiornati con le patch (paradossalmente, Azure Automation potrebbe aiutare a tenere patchati anche questi server stessi tramite Update Management di cui parleremo nel capitolo 5), che abbiano risorse adeguate per eseguire gli script (CPU, RAM), e che l’agente sia aggiornato.
· Sicurezza e permessi: il runbook eseguito su un Hybrid Worker gira sotto un certo contesto di sicurezza locale. Se è un server Windows, di solito viene eseguito come servizio sotto Local System o un utente specifico configurato. Bisogna assicurarsi che quell’account locale abbia i permessi minimi necessari (principio del minimo privilegio) per compiere le azioni richieste sul server o sulla rete interna. Ad esempio, se il runbook deve accedere a un database interno, l’account con cui gira dovrà avere le credenziali giuste per quel database. Inoltre, dal lato Azure, l’identità del Automation Account potrebbe comunque essere usata in combinazione (ad es. il runbook per contattare Azure continuerà ad usare la Managed Identity di Azure per risorse cloud, mentre per risorse locali userà permessi locali).
Esempio pratico: un’azienda ha un’applicazione legacy installata su un server on-premises, e per aggiornare tale applicazione bisogna periodicamente eseguire un installer (.msi) sul server. Questo processo può essere automatizzato con un runbook, ma essendo il server on-prem, useremo un Hybrid Worker:
· Installiamo l’agente HRW su Server01 (il server locale dove avviene l’installazione).
· Registriamo Server01 nel gruppo di Hybrid Worker dell’Automation Account Ops-Prod.
· Creiamo un runbook chiamato InstallAppUpdate.ps1 che copia il nuovo file .msi (magari prelevandolo da uno storage interno o da un pacchetto) e lo esegue sul server, attendendone il completamento. Poi il runbook potrebbe verificare se l’installazione ha scritto correttamente certi file o chiavi di registro come controllo.
· Pianifichiamo questo runbook per esecuzione mensile, oppure lo lanciamo manualmente quando necessario. Al momento dell’esecuzione, Azure Automation invia il job a Server01. L’agente su Server01 esegue InstallAppUpdate.ps1: questo script opera localmente, installa l’applicazione, e infine invia i log (esito installazione, eventuali messaggi) al servizio Azure Automation. Nei log centralizzati (Log Analytics) avremo traccia di questa operazione come di consueto.
· In caso di successo, possiamo vedere nel portale che il job ha terminato correttamente; in caso di errore (es. l’installer ha dato un errore), il log catturerà l’errore e potremo intervenire di conseguenza.
Diagramma esplicativo: l’immagine della slide mostra l’interazione: un lato c’è Azure Automation (il cloud) e dall’altro un server etichettato come Hybrid Runbook Worker. Si vede una freccia di comando che parte da Azure Automation verso il server HRW (indicando l’invio del runbook da eseguire), poi una freccia di esecuzione sul server che rappresenta lo svolgimento del compito localmente, quindi una freccia di ritorno con i log dall’HRW verso Azure (i risultati inviati al cloud). Inoltre, sono disegnate delle barriere o icone di rete privata a indicare che il server HRW sta all’interno di una rete aziendale protetta: solo il canale con Azure Automation (uscente) è aperto, mentre l’Automation Account rispetta i limiti di quella rete (ad esempio, se su Server01 c’è un firewall, l’uscita verso Azure è autorizzata ma nessun traffico entrante da Azure direttamente, perché è l’agente che fa polling verso il cloud). Questo garantisce che l’apertura di sicurezza minima è dalla rete interna verso Azure su porta HTTPS, senza richiedere inbound pubblici.
In sintesi, l’Hybrid Runbook Worker estende il potere di Azure Automation ad ambienti che altrimenti ne sarebbero esclusi, offrendo un mix di flessibilità (posso automatizzare praticamente qualsiasi sistema ovunque si trovi) e centralizzazione (mantengo un unico punto di controllo in Azure). È però essenziale mantenere questi agenti connessi, sicuri e aggiornati per assicurare che le automazioni ibride siano affidabili quanto quelle interamente cloud.
4. Update Management: Gestione degli Aggiornamenti delle VM
Mantenere i sistemi aggiornati con le ultime patch e aggiornamenti di sicurezza è una parte cruciale dell’amministrazione di sistemi IT. Azure offre una soluzione integrata per automatizzare la gestione delle patch su macchine virtuali, chiamata Update Management, che fa parte della piattaforma Azure Automation. Update Management consente di controllare in modo centralizzato lo stato di aggiornamento di macchine virtuali Azure e anche di server fisici o VM on-premises (o in altri cloud) purché registrati, sia su sistemi Windows che Linux.
In pratica, Update Management scansiona le macchine per vedere quali aggiornamenti (di sistema operativo, patch di sicurezza, aggiornamenti critici) non sono ancora installati, e fornisce gli strumenti per pianificarne e gestirne l’installazione automatica.
Funzionalità principali di Update Management:
· Rilevazione degli aggiornamenti mancanti: quando una VM è abilitata per Update Management (tramite l’agente di Log Analytics o Azure Monitor), Azure Automation periodicamente compie una scansione della macchina per determinare quali aggiornamenti sono disponibili ma non ancora applicati. Questo crea un report di conformità indicando, ad esempio, che la VM X ha 5 aggiornamenti critici e 2 facoltativi in sospeso.
· Pianificazione delle distribuzioni di patch: l’operatore può creare uno o più schedule di deployment in cui specificare quando applicare gli aggiornamenti su gruppi di macchine. Si può per esempio pianificare che il gruppo di VM del reparto vendite venga aggiornato il terzo sabato del mese alle 02:00 di notte. In ogni pianificazione si specifica: quali macchine coinvolgere, quali categorie di aggiornamenti includere (critici, di sicurezza, tutti, oppure escludere certi aggiornamenti specifici se si sa che possono creare problemi), se riavviare automaticamente le macchine se necessario, e una finestra temporale massima per l’operazione.
· Inclusioni ed esclusioni: a un livello granulare, si può definire che in un deployment di aggiornamento alcune patch particolari non vadano installate (es. escludere un determinato aggiornamento cumulativo se è noto che causa incompatibilità con un software presente) oppure al contrario includere solo certe classi di aggiornamenti. Questo dà controllo fine sull’applicazione delle patch.
· Script pre e post aggiornamento: una funzionalità molto utile è la possibilità di eseguire script personalizzati prima e dopo l’installazione delle patch. Ad esempio, prima di applicare gli aggiornamenti si può voler eseguire uno script “pre-patch” che ferma in modo ordinato un servizio applicativo, così che l’aggiornamento del sistema operativo non interferisca con processi in corso; dopo il riavvio e l’installazione, uno script “post-patch” potrebbe avviare di nuovo quel servizio e fare un controllo di salute dell’applicazione. Questi script assicurano che la manutenzione sia coordinata con le necessità specifiche delle applicazioni in esecuzione su quelle macchine.
· Report di conformità e tracking: dopo l’esecuzione di un ciclo di patch, Azure Automation genera report dettagliati. È possibile vedere quali aggiornamenti sono stati installati su ogni macchina, quali eventualmente sono falliti e perché, e lo stato complessivo della conformità (es. “Tutte le macchine sono aggiornate al più tardi a 30 giorni fa” oppure “Ci sono macchine con patch critiche vecchie di oltre 2 mesi”). Questo permette di dimostrare la compliance rispetto a policy aziendali o normative (molte normative richiedono di applicare patch entro un certo tempo dal rilascio).
Vantaggi dell’automazione delle patch: automatizzare le patch significa ridurre l’esposizione a vulnerabilità (le patch di sicurezza vengono applicate tempestivamente riducendo il tempo in cui un sistema rimane vulnerabile) e garantire la compliance con eventuali normative di sicurezza o policy interne. Inoltre, toglie agli amministratori il carico operativo di dover collegarsi a decine di server e aggiornarli manualmente o con script isolati, centralizzando il processo.
Integrazioni con altre funzionalità Azure: Update Management non vive isolato, si integra infatti con:
· Maintenance Configuration: in Azure esiste la possibilità di definire finestre di manutenzione (soprattutto per macchine Azure dedicate o host dedicati) e controllare i riavvii. Update Management può rispettare questi orari preferenziali di riavvio, ad esempio applicando patch solo all’interno di una maintenance window definita, così da coordinarsi con le finestre di servizio concordate.
· Change Tracking and Inventory: un’altra funzionalità di Azure Automation che tiene traccia di quali cambiamenti di configurazione avvengono sulle macchine (ad esempio modifiche al registro di Windows, ai file, ai servizi, installazione/disinstallazione di software). Dopo aver applicato patch, Change Tracking può evidenziare esattamente cosa è cambiato sul sistema, come quali nuovi aggiornamenti compaiono nella lista programmi o quale versione di un certo file DLL è stata aggiornata. Questo arricchisce la visibilità, permettendo di diagnosticare meglio problemi successivi (sapendo quali patch sono entrate) e di avere un audit trail dei cambiamenti.
Esempio pratico: supponiamo di gestire un parco di server Windows in Azure, e di voler implementare un ciclo di patching mensile:
· Configuriamo tutte le VM per l’Update Management (basta associarle a un workspace Log Analytics e abilitare la soluzione Update Management).
· Creiamo una schedule di aggiornamento chiamata “Patch mensile – server Windows” che si attiva ogni primo sabato del mese alle 3:00. In questa schedule includiamo tutte le VM di produzione Windows, scegliendo di installare solo aggiornamenti classificati come “Critici” o “Di sicurezza”, escludendo per esempio gli aggiornamenti facoltativi o i driver (magari vogliamo evitare di aggiornare driver hardware automaticamente per non incorrere in problemi, a meno che non sia necessario). Impostiamo anche “Riavvia se necessario” con un timeout di, ad esempio, 30 minuti di tempo consentito per i reboot.
· Aggiungiamo uno script pre-patch: questo script potrebbe, ad esempio, controllare che certe applicazioni custom siano ferme o in uno stato di quiescenza, e potrebbe prendere nota dei servizi attivi. Mettiamo anche uno script post-patch: ad esempio, dopo l’aggiornamento, controllare che il servizio “ServizioApplicativoXYZ” sia in esecuzione, e in caso contrario provare a riavviarlo, e magari inviare un avviso se non parte.
· La notte programmata, Azure Automation esegue la procedura: su ogni macchina target, prima esegue lo script pre, poi installa le patch secondo i criteri scelti, riavvia la macchina se richiesto da qualche patch, poi una volta ripartita esegue lo script post. Tutto questo avviene in parallelo secondo le configurazioni date.
· Al mattino, il team può controllare il report generato: supponiamo che su 50 server, 48 siano riusciti ad aggiornarsi completamente, mentre 2 abbiano avuto dei problemi (magari uno non si è riavviato perché c’era un processo bloccato, un altro ha fallito l’installazione di un update). Dal report vediamo quali patch non sono state applicate e gli eventuali messaggi di errore, così da poter intervenire manualmente su quei 2 server (ad esempio riprovare l’update o aprire un ticket con Microsoft se necessario). Nel frattempo, i 48 server aggiornati garantiscono che la stragrande maggioranza dell’infrastruttura è protetta dalle ultime minacce.
Diagramma illustrativo: la slide proponeva una timeline delle fasi di Update Management: inizio con Scansione (detect dei necessari aggiornamenti), poi Pianificazione (schedule definita dall’utente), quindi fase di Applicazione degli update in sé (patching), seguita da Validazione (verifica post-installazione, eventualmente script di controllo), e infine Report. Lungo la timeline sono evidenziati dei checkpoint con indicatori di successo o fallimento: ad esempio, dopo la fase di applicazione, se questa è completata con successo appare un check verde, se fallisce appare un indicatore di errore rosso sul report. Questo evidenzia che ad ogni fase è possibile determinare se l’operazione è andata a buon fine o no, e intraprendere azioni di conseguenza (in molti casi, gli errori nella fase di applicazione potrebbero far scattare degli alert automatici, per esempio).
In conclusione,** Update Management** è uno strumento potente per garantire che le macchine rimangano aggiornate in modo consistente e documentato. Integrato nel contesto di Azure Automation, beneficia della centralizzazione e delle capacità di scheduling e logging avanzate. Nel prossimo capitolo vedremo un altro aspetto dell’automazione, relativo alla configurazione coerente dei sistemi (Azure Automation State Configuration).
5. Configurazione dello Stato: Azure Automation State Configuration (DSC)
Oltre all’automazione di task puntuali o schedulati, Azure Automation offre anche funzionalità per gestire in modo dichiarativo la configurazione costante dei sistemi. Questo è realizzato tramite Azure Automation State Configuration, che è fondamentalmente l’implementazione cloud di Azure del concetto di PowerShell DSC (Desired State Configuration).
Cos’è PowerShell DSC? È una tecnologia Microsoft che consente di definire, attraverso codice dichiarativo, come deve essere configurato un sistema (Windows o anche Linux tramite DSC per Linux). Invece di scrivere uno script imperativo che esegue passi per configurare una macchina, con DSC si scrive una sorta di “documento di configurazione” che elenca le impostazioni desiderate: per esempio, “sul server X il ruolo IIS deve essere installato, il servizio Y deve essere in esecuzione, il file Z deve esistere con questo contenuto, ecc.”. Questo documento viene poi applicato alla macchina da un agente speciale chiamato LCM (Local Configuration Manager). L’LCM sul nodo gestito ha il compito di:
· Applicare la configurazione iniziale (portare il sistema allo stato desiderato, installando ciò che manca, configurando parametri, avviando servizi, ecc.);
· Monitorare la divergenza (drift): a intervalli regolari ricontrollare lo stato attuale e, se qualcosa è cambiato rispetto alla configurazione desiderata (ad esempio un servizio che doveva essere “Avviato” risulta “Arrestato” perché qualcuno l’ha fermato manualmente, oppure un file di configurazione è stato modificato manualmente), intervenire per correggere e riportare il sistema allo stato voluto.
In ambienti tradizionali, DSC può funzionare in modalità push (un server orchestratore invia la config ai nodi) o pull (i nodi vanno a prendere la config da un server centrale periodicamente). Azure Automation State Configuration fornisce appunto un pull server cloud: i nodi registrati nel servizio andranno a prendere la loro configurazione dal Automation Account e riporteranno la loro conformità.
Come funziona Azure Automation State Configuration:
· Nell’Automation Account, si importano o creano delle configuration DSC. Queste sono degli script PowerShell .ps1 speciali che definiscono, usando il linguaggio DSC, uno stato desiderato per certi tipi di nodi. Ad esempio, potremmo avere una configurazione chiamata “WebServerConfig” che definisce che il ruolo IIS sia installato e un sito web con certe caratteristiche sia presente. Oppure una configurazione “BaselineSicurezza” che imposta alcune policy di sicurezza di Windows (es: livello di auditing, impostazioni avanzate di firewall, ecc.).
· Una volta definita la configuration (che è generica), la si può compilare in Azure Automation per generare le configurazioni MOF specifiche per i nodi. Si definiscono poi nodi (o macchine) target iscritti: queste macchine (che possono essere VM Azure o server on-premises con l’agente Azure DSC) vengono registrate con l’Automation Account e associate a una certa configurazione. Ad esempio, potremmo dire che la VM “ServerWeb01” e “ServerWeb02” adottano la configurazione “WebServerConfig”; mentre la macchina “DomainController01” adotta la configurazione “BaselineSicurezza”.
· Ogni nodo ha eseguito su di sé un Local Configuration Manager (LCM), configurato per contattare regolarmente il servizio Azure Automation (ad es. ogni 15-30 minuti). Quando contatta Azure, se c’è una configurazione assegnata o aggiornata, la scarica (pull) e la applica.
· Il nodo poi invia a Azure lo stato di conformità: praticamente un report che indica se la configurazione è Compliant (tutto in regola) o se c’è una Non-compliance (ad esempio, non è riuscito ad applicare una parte, oppure qualcuno ha fatto un cambiamento locale che viola la configurazione e il nodo l’ha corretto o tenta di correggerlo).
· Nel portal Azure, sezione State Configuration dell’Automation Account, si può vedere l’elenco dei nodi, quale configurazione hanno, e se sono Compliant (verdi) o hanno errori (rosse), con dettagli sullo scostamento eventualmente rilevato.
Vantaggi di un approccio dichiarativo (DSC) rispetto a script imperativi tradizionali:
· Coerenza nel tempo: una volta che si dichiara lo stato desiderato, il sistema DSC continua a mantenere quella configurazione nel tempo. Se qualcuno manualmente modifica qualcosa su un server (volontariamente o accidentalmente), DSC lo rileverà e lo correggerà, riportando la conformità. Invece uno script tradizionale potrebbe essere eseguito una tantum e poi il sistema può divergere. DSC garantisce la deriva zero (o spegne rapidamente derive accidentali).
· Riutilizzo e standardizzazione: una configurazione DSC può essere applicata a decine o centinaia di server, garantendo che tutti abbiano esattamente la stessa configurazione. Questo è particolarmente utile per applicare baseline di sicurezza (es: tutti i server Windows devono avere certe impostazioni di audit e firewall attive) o per configurare ruoli server (es: ogni nuovo server web deve avere installato IIS con certe caratteristiche, facilitando l’onboarding di nuovi server).
· Dichiarativo vs Procedurale: pensando in modo dichiarativo, l’amministratore specifica cosa deve essere presente o quale stato deve esserci, delegando al sistema la logica di come ottenerlo. Questo porta a definizioni più chiare e meno errori rispetto a dover scrivere complesse procedure che gestiscono numerosi casi (ad esempio, un blocco DSC potrà dire “assicurati che il servizio X sia Running”; starà poi all’agente capire di volta in volta se deve avviarlo perché è fermo, o reinstallarlo se manca, etc.).
· Integrazione con infrastruttura-come-codice: DSC si sposa bene con concetti DevOps, perché le configurazioni (script DSC) possono stare in un repository, essere versionate, testate e distribuite come codice, allineando configurazioni e codice applicativo.
Scenari tipici di Azure Automation State Configuration:
· Hardening e baseline di sistema: applicare configurazioni di sicurezza uniformi (ad es. policy di password, impostazioni di registro per disabilitare protocolli insicuri come TLS 1.0, abilitare logging avanzato, impostare banner di accesso, etc.).
· Installazione di funzionalità o software: definire che su un server deve esserci installata una certa funzionalità di Windows (ruolo server) o un certo pacchetto. DSC provvederà a installarlo se mancante. Per Linux, può assicurare che certi pacchetti siano presenti o che certe configurazioni di sistema (file sotto /etc) siano definiti in un certo modo.
· Configurazioni applicative ripetitive: ad es., definire via DSC che su tutti i server web sia presente un sito di default con una certa configurazione o che un certo file di config applicativo sia sempre allineato. Se qualcuno cambia manualmente quel file, DSC può riportarlo alla versione desiderata (sebbene per configurazioni app complesse a volte ci si integri con strumenti più specifici come Chef o Ansible; DSC comunque può coprire molti casi base).
· Compliance e audit: anche se le configurazioni fossero gestite da altri strumenti, registrare i nodi in Azure Automation DSC consente quantomeno di monitorare la compliance rispetto a un set di requisiti (immaginiamolo come uno strumento di auditing automatico: se un nodo risulta non compliant su un certo setting, appare subito in rosso e si può intervenire).
Esempio pratico: la divisione IT vuole assicurarsi che tutte le VM Azure di tipo server web rispettino alcune regole di sicurezza e configurazione:
· Si scrive una configurazione DSC chiamata WebServerBaseline. All’interno, ad esempio, si indica:
a) Feature “IIS” deve essere Presente (quindi se la VM non ha il ruolo web server, verrà installato).
b) Servizio “IIS Admin” deve essere in stato Running e impostato su “Automatic”.
c) Protocollo TLS1.0 deve essere disabilitato nel registro di sistema (chiave di registry XYZ impostata).
d) Il file “C:\inetpub\wwwroot\welcome.html” deve esistere con un certo contenuto standard (es: un banner di benvenuto o informativa standard).
· Questa configurazione viene caricata nell’Automation Account e assegnata a tutte le VM che fanno parte del pool web (es: VM1, VM2, VM3). Ogni VM è configurata con l’agente DSC locale.
· Appena assegnata, ciascun nodo la scarica e la applica: se su VM2 non era installato IIS, lo installerà; su VM1 se TLS1.0 era abilitato, l’agente lo disabiliterà, ecc. Nel processo, se qualche step fallisce (magari l’installazione di IIS fallisce per mancanza di internet, per dire), il sistema segnala la non-compliance.
· Successivamente, dopo l’applicazione iniziale, ogni nodo continuerà a fare check periodici. Se, ad esempio, un amministratore su VM3 attiva erroneamente TLS1.0 un mese dopo, il prossimo check DSC troverà che la configurazione non è conforme (TLS1.0 dovrebbe essere disabilitato, invece è abilitato): segnalerà la differenza e proverà a correggerla disabilitando di nuovo TLS1.0, riportando la VM in conformità automatica. Il team così vede magari una notifica che c’è stato un drift corretto o comunque nel report comparirà un evento di correzione.
Diagramma illustrativo: l’immagine nella slide mostrava tanti server (nodi) con sopra un piccolo ingranaggio indicante l’LCM su ciascun nodo. Ogni LCM ha una freccia che punta verso un iconcina che rappresenta il pull server (Azure Automation State Configuration), significando “il nodo chiede al server la config”. Dal server tornano frecce verso i nodi con la configurazione. Poi dal nodo parte un’altra freccia di ritorno verso un pannello di conformità (nel portale Azure) dove si vede un indicatore se il nodo è compliant o no. In sostanza, il diagramma sottolinea la relazione uno-a-molti del servizio: un unico Automation Account distribuisce configurazioni a molti nodi e centralizza lo stato di tutti.
In conclusione, Azure Automation State Configuration permette di implementare politiche di configurazione dichiarativa e auto-ripristinante sui propri server, elevando il livello di automazione dalla semplice esecuzione di script al mantenimento continuo di uno stato desiderato. È un’arma importante per garantire standardizzazione, sicurezza e stabilità nei propri ambienti, soprattutto se combinata con le altre funzionalità viste (runbook per operazioni immediate e DSC per coerenza di lungo periodo).
6. Integrazione Runbook con altri Servizi
Le automazioni realizzate con Azure Automation, in particolare i runbook, non sono entità isolate: possono essere innescate e collegate ad altri servizi e flussi di lavoro, permettendo scenari avanzati in ambito DevOps e IT Operations. In questo capitolo esamineremo come i runbook possano integrarsi con strumenti di orchestrazione e comunicazione come Azure Logic Apps, Power Automate, API e webhook, nonché con ecosistemi di gestione delle operazioni (alert, sistemi ITSM, notifiche Teams, ecc.).
a) Azure Logic Apps e Power Automate:
Azure Logic Apps è un servizio cloud che consente di creare flussi di lavoro automatizzati tramite un’interfaccia grafica, integrando diversi servizi e sistemi tramite connettori predefiniti. Microsoft Power Automate offre funzionalità simili orientate più all’utente finale e all’integrazione con applicativi Microsoft 365, ma concettualmente i due servizi si sovrappongono molto. Entrambi possono orchestrare processi complessi composti da più passi e chiamare servizi esterni (o interni) tramite connettori o HTTP.· Un scenario tipico è quello di un flusso di lavoro che reagisce a un certo evento o trigger (ad esempio: quando arriva un’email su una certa casella, oppure quando un item viene creato in un sistema di helpdesk, o quando un alert di monitoraggio scatta). Questo flusso può prevedere passaggi di trasformazione dei dati, invio notifiche, e – grazie al connettore specifico – esecuzione di un runbook di Azure Automation. Logic Apps ha un connettore predefinito per Azure Automation, che consente di dire: “Esegui il runbook XYZ su questo Automation Account, eventualmente passando questi parametri e attendine il completamento”.
· Al contrario, anche un runbook potrebbe chiamare una Logic App o un flusso Power Automate, se ha bisogno di sfruttare connettori particolari, ad esempio per interagire con servizi per cui esiste un connettore (cosa meno comune, in genere è la Logic App che chiama il runbook e non viceversa).
· Power Automate apre la porta anche all’integrazione con ambienti come Microsoft Teams, SharePoint, approvazioni utente, ecc., e può essere utilizzato da personale meno tecnico (ad esempio, un analista può creare un flusso che alla pressione di un pulsante in Teams avvia un certo runbook senza scrivere codice).
b) Webhook e API REST:
Azure Automation permette di esporre direttamente i runbook tramite webhook, ovvero URL pubblici (protetti con un token lungo) che quando vengono richiamati fanno partire il runbook associato. Questo è un modo semplice e diretto per integrare runbook con qualunque sistema in grado di fare richieste HTTP. Ad esempio, un tool di terze parti che non ha un connettore pronto potrebbe fare una POST all’URL del webhook passando eventualmente un payload JSON: Azure Automation riceve la richiesta e avvia il runbook designato, fornendogli come input quel payload. Questo consente di integrarsi praticamente con qualsiasi cosa, dal pulsante di un portale self-service, a un evento in un altro cloud, etc., senza dover passare per Logic Apps, se non necessario.
Inoltre, Azure Automation ha delle API REST (parte delle API generali di Azure) che permettono di avviare runbook, recuperare lo stato dei job, ecc., programmaticamente. Queste richiedono però autenticazione Azure AD (quindi qui non parliamo di webhook anonimi, ma di chiamate API autenticate), e possono essere usate in scenari in cui un’applicazione interna, con le giuste credenziali, fa partire un runbook come parte del suo processo.c) Scenari di utilizzo dell’integrazione:
· Gestione on-call e incident: immagina di avere un sistema di monitoraggio (come Azure Monitor o un altro software) che genera un allarme alle 2 di notte perché un server non risponde. Invece di chiamare immediatamente l’ingegnere reperibile, potremmo avere una Logic App che intercetta l’alert, avvia automaticamente un runbook di primo tentativo di risoluzione (ad esempio un runbook che riavvia un servizio sul server e controlla se torna su), e allo stesso tempo invia una notifica su Microsoft Teams o via SMS al personale on-call. La Logic App potrebbe attendere l’esito del runbook; se il runbook risolve il problema, magari aggiorna un sistema di ticket dicendo “Risolto automaticamente alle 2:05”; se non risolve, allora allerta un umano. Questo alleggerisce il carico sul personale reperibile e riduce il downtime.
· Integrazione con ITSM (IT Service Management): si possono integrare runbook con strumenti tipo ServiceNow, BMC Remedy, o il centro assistenza di Azure (Azure DevOps, GitHub Issues, ecc.). Ad esempio, l’apertura di un ticket ad alta priorità può scatenare un flusso che esegue alcuni controlli automatici (tramite runbook) e aggiorna il ticket con le informazioni raccolte; oppure un tecnico dal ticket può premere un pulsante che chiama un webhook di Azure Automation per effettuare un’azione (come raccogliere log da un sistema).
· Processi di business e automazione di processo: oltre ai contesti IT, i runbook possono integrarsi in flussi più ampi. Per esempio, un processo di onboarding di un dipendente potrebbe includere un passo in cui un runbook crea automaticamente una macchina virtuale o un ambiente di sviluppo per il nuovo assunto, dopo che in un form sono stati raccolti i requisiti.
· Notifiche operative e approvazioni: spesso alcune operazioni automatiche potrebbero richiedere un controllo umano prima di effettuare cambiamenti irreversibili. Ad esempio, spegnere tutte le VM di un reparto per fine mese può essere automatizzato, ma si vorrebbe magari una conferma da parte di un responsabile. Con l’integrazione di Teams, è possibile inviare una Adaptive Card (scheda interattiva) su un canale Teams o in chat a una persona, chiedendo: “Vuoi approvare lo spegnimento delle VM X, Y, Z?” con bottoni Approva/Rifiuta. L’utente clicca Approva, l’approvazione torna alla Logic App, che a quel punto esegue il runbook che effettua lo spegnimento. Questa combinazione di notifica + approvazione umana + esecuzione automatica consente di implementare workflow di autorizzazione su operazioni IT in maniera elegante e auditabile.
Esempio pratico di integrazione: consideriamo uno scenario completo:
Una macchina virtuale di sviluppo non dovrebbe restare accesa fuori dall’orario d’ufficio per risparmiare costi, ma occasionalmente un team può chiedere un’estensione oraria se stanno lavorando a un test lungo. Possiamo costruire un flusso che:· Ogni giorno alle 19:00, una Logic App si attiva e controlla quali VM di sviluppo sono accese. Per ciascuna, invia sul canale Teams del team di sviluppo un messaggio (Adaptive Card) elencando le VM accese e chiedendo: “Vuoi spegnere ora queste VM? Se hai bisogno che rimangano accese per qualche ora in più, clicca Posticipa.”.
· Se nessuno interagisce entro 30 minuti, la Logic App procede ad avviare il runbook Stop-DevVMs che spegne automaticamente tutte le VM di sviluppo accese.
· Se invece qualcuno clicca “Posticipa per 2 ore” sulla card di Teams, la Logic App riprogramma lo spegnimento a più tardi (ad esempio alle 21:00).
· Quando il runbook Stop-DevVMs viene eseguito (sia alle 19:30 in assenza di risposta, sia posticipato), questo spegne ogni VM interessata e, per ciascuna, archivia i log (ad esempio scrivendo su un file di log centralizzato quante VM e quali sono state spente, e l’ora) e invia un messaggio di riepilogo su Teams: “Sono state spente 3 VM di sviluppo: VM1, VM2, VM3 alle ore 19:30. Buona serata!”.
· Inoltre, potrebbe aggiornare un database di configurazione (CMDB) o un log interno per tracciare che quelle risorse da quell’ora non sono più in esecuzione.
In questo scenario abbiamo: un trigger programmato, un intervento potenziale umano via Teams (grazie all’integrazione di Logic App con Teams e Adaptive Cards), un runbook eseguito come parte finale per compiere l’azione hard IT (spegnimento VM), e poi notifiche finali.
Diagramma della sequenza integrata: l’immagine mostrata corrisponde a un flusso simile:
· Si vede un’icona di Alert o evento iniziale (può essere un alert di monitoraggio ad esempio).
· Segue un blocco Azure Logic App, che elabora l’evento.
· Da Logic App parte una freccia verso il logo di Teams per un’approvazione (nel diagramma appare la parola approvazione vicino a Teams, indicando che c’è un passo di approval su Teams).
· Dopo l’approvazione via Teams, una freccia porta all’esecuzione del runbook di Azure Automation (icona ingranaggio di runbook).
· Infine, un ultimo blocco indica l’aggiornamento di CMDB (Configuration Management Database) o sistemi di record. In altre parole, il diagramma condensa uno scenario di incident management: un alert, poi un’automazione (Logic App + Teams per approvazione), quindi l’azione su Azure (il runbook che attua la risoluzione), e poi la registrazione dell’azione compiuta nel sistema di configurazione aziendale.
In conclusione, la vera potenza dell’automazione si esprime quando i runbook vengono messi a fattor comune in flussi aziendali più ampi: ciò permette reazioni automatiche ad eventi, snellisce processi che coinvolgono persone e sistemi diversi, e colma gap tra piattaforme (grazie alla flessibilità dei webhook e delle API). Per uno studente o un professionista che apprende Azure Automation, è importante capire non solo come scrivere un runbook, ma anche come inserirlo nel più ampio ecosistema cloud e on-premises per creare soluzioni end-to-end.
7. Baseline di Sicurezza e Governance per l’Automazione
Quando si implementano soluzioni di automazione su vasta scala, sicurezza e governance diventano aspetti fondamentali. Azure Automation, se da un lato offre grandi vantaggi operativi, dall’altro deve essere gestito con attenzione per evitare di introdurre vulnerabilità o perdite di controllo. In questo capitolo tratteremo come impostare una solida security baseline per Azure Automation e come governare le attività automatizzate in modo conforme alle policy aziendali.
a) Sicurezza dei Runbook e degli Automation Account:
· RBAC (Accessi basati sui ruoli): come già accennato nel capitolo sull’Automation Account, è essenziale applicare il principio del minimo privilegio a tutti gli elementi coinvolti. Ciò significa assegnare agli utenti umani ruoli adeguati (es. un operatore può eseguire runbook ma non modificarli, uno sviluppatore può crearli ma non necessariamente eseguirli in produzione, ecc.) e soprattutto assegnare all’identità con cui i runbook operano solo i permessi strettamente necessari sulle risorse Azure. Ad esempio, se un runbook deve solo riavviare macchine in un certo resource group, l’identità gestita dovrebbe avere permesso di riavvio su quelle VM, ma non permessi globali sull’intera sottoscrizione. Azure offre ruoli predefiniti e la possibilità di crearne di personalizzati per ottenere questo scopo.
· Managed Identity obbligatoria: è vivamente consigliato (e in alcuni contesti imposto) che ogni Automation Account abbia una Managed Identity abilitata, così da evitare l’uso di credenziali statiche all’interno dei runbook. Inoltre, i runbook dovrebbero usare identità gestite ogni volta che interagiscono con servizi Azure. Per casi in cui proprio serve una credenziale (es. per sistemi esterni non integrabili con Azure AD), valutare l’archiviazione nel servizio credenziali dell’Automation Account o in Key Vault e non dentro lo script.
· Protezione delle credenziali: qualora si usino asset di tipo Credenziali nell’Automation Account, assicurarsi che siano protetti da adeguati controlli d’accesso (ad esempio solo determinati runbook o utenti possono vederle/usarle) e rotazione periodica delle stesse se possibile.
· Network Isolation: per aumentare la sicurezza, soprattutto in contesti ibridi o di grandi aziende, si può isolare l’esecuzione dei runbook su reti private. Abbiamo menzionato l’uso di Private Endpoint per l’Automation Account; inoltre, i Hybrid Runbook Worker eseguiti on-prem rispettano già le protezioni di rete esistenti (quindi niente porte aperte dall’esterno). Questo assicura che eventuali azioni malevole o errori grossolani non possano propagarsi liberamente in Internet o in ambienti non controllati.
b) Audit e logging:
· Audit Log Azure: Azure mantiene un Audit Log di ogni cambiamento significativo. Per Azure Automation, ciò includerà eventi come la creazione, modifica e cancellazione di runbook, la modifica di configurazioni (es. aggiunta di credenziali), l’avvio di job manualmente, ecc. Questi audit log devono essere rivisti regolarmente o integrati con sistemi SIEM per individuare attività anomale (per esempio, se qualcuno crea un runbook non autorizzato o lo esegue a un’ora insolita).
· Job logs e output: l’output dei runbook e i log di esecuzione (compresi errori con stack trace) vengono inviati al Log Analytics (se configurato) o sono comunque disponibili nell’account. Questi log operativi possono essere analizzati per vedere cosa è stato fatto. A fini di governance, si potrebbero impostare workbook o report mensili che mostrino ad esempio quante modifiche a risorse sono state fatte via runbook, quante volte un certo runbook è fallito (affidabilità), ecc.
· Tracciabilità end-to-end: è utile correlare i log di Azure Automation con quelli di altri sistemi. Ad esempio, se un runbook viene avviato in risposta a un alert di monitoraggio, includere nei log un riferimento all’alert ID, in modo che leggendo i log di quell’esecuzione si possa risalire facilmente all’evento scatenante. Viceversa, quando un runbook compie un’azione su una risorsa, quella risorsa avrà nei suoi Activity Log un’operazione eseguita dall’identità del runbook. Garantire che quell’identità abbia un nome chiaro (es. “Automation-VM-Shutdown-Prod”) aiuta a capire subito, leggendo i log di una VM spenta, che lo spegnimento è stato fatto da quell’identità quindi presumibilmente da un runbook noto, e non da un intruso.
c) Azure Policy per Azure Automation
Azure Policy è il servizio che permette di enforzare regole e configurazioni sulle risorse Azure. Si possono definire policy specifiche anche per Azure Automation, e in generale per gli scenari di automazione, ad esempio:
· Una policy potrebbe richiedere che tutti gli Automation Account abbiano le Diagnostic Settings abilitate verso un Log Analytics (per assicurare che i log non vadano persi e siano centralizzati). In caso contrario, l’account è non compliant e si può far sì che la policy lo metta in conformità automaticament (deployIfNotExists).
· Una policy potrebbe proibire la creazione di runbook non conformi a certi criteri; ad esempio, delle policy custom potrebbero analizzare il contenuto dei runbook (questo è avanzato, non nativo, ma in teoria si può fare con Azure Automation e Azure Policy in combinazione con script esterni) o più realisticamente proibire di creare Automation Account in region non approvate, o di non associare un’identità.
· Importante, come citato nella slide: policy per imporre l’uso di Managed Identity e di parametri di sicurezza. Ad esempio, un set di policy iniziative potrebbe imporsi che: ogni Automation Account deve avere una identità gestita attiva; ogni runbook che interagisce con Key Vault deve usare quell’identità (queste cose a volte vengono implementate con controlli manuali e automatizzati).
· Policy su risorse controllate da runbook: altra sfaccettatura è usare Azure Policy per governare l’effetto dei runbook. Se si creano runbook che ad esempio distribuiscono risorse, è bene che esistano policy attive che garantiscano che quelle risorse rispettino certi parametri (tag, naming convention, posizionamento, ecc.). Quindi l’automazione dovrebbe lavorare insieme alle policy: i runbook possono addirittura essere scritti per remediare risorse non conformi segnalate da Policy. Ad esempio, se c’è una policy che indica “tutte le VM devono avere il tag ‘Owner’ “, potremmo avere un runbook che periodicamente cerca risorse non conformi e applica rimedi (invia segnalazioni o aggiunge tag provvisori).
d) Esempi di iniziative di sicurezza e governance con automazione:
· Policy di blocco deploy non conformi: un’azienda può definire un set di policy tali per cui se qualcuno cerca di creare una risorsa che non rispetta le regole (non ha certi tag obbligatori, oppure prova a creare un tipo di risorsa vietato in quell’ambiente), Azure Policy automaticamente rifiuta l’operazione (effetto deny). Legando ciò all’automazione: se un runbook mal configurato o un utente tramite runbook provasse a creare qualcosa di non permesso, la policy lo impedisce. In più, i runbook stessi possono essere usati per distribuire e aggiornare queste policy (tramite automazione dell’infrastruttura).
· Report mensili sull’affidabilità dei job: dal punto di vista governance, può essere utile monitorare quanto bene stanno funzionando le automazioni. Un esempio citato è generare un report mensile che analizza tutti i job eseguiti dai runbook e calcola degli indicatori di affidabilità: ad esempio, tasso di successo vs fallimento, tempo medio di esecuzione, principali cause di errore. Questo può essere fatto importando i log di Azure Automation in un tool di reporting o anche con un runbook dedicato che estrae i dati dal Log Analytics e manda via email un report. Avere questi report inseriti in un processo di revisione mensile aiuta a identificare runbook problematici (che falliscono spesso), capire se servono ottimizzazioni o se va rivisto qualcosa nei permessi.
Visualizzazione della baseline di sicurezza: la slide presentava una sorta di checklist e un diagramma: i punti fondamentali (RBAC, Identity, Logs, Policy) elencati come elementi di un elenco di controllo per l’automazione sicura. E un diagramma che collegava job -> log -> workbook (dashboard) -> alert -> review. Questo mostra come un ciclo virtuoso: ogni job produce log, i log alimentano dashboard o report (workbook), i quali possono far scattare alert se qualcosa è fuori norma (es. troppi errori, tempi eccessivi), e a valle c’è una revisione umana di questi indicatori per prendere decisioni (es. migliorare un runbook, aggiungere risorse se un job impiega troppo, ecc.). Governance significa proprio avere queste catene di controllo che assicurano che l’automazione rimanga sotto controllo e allineata agli obiettivi.
In definitiva, per utilizzare Azure Automation in produzione, soprattutto in contesti aziendali, bisogna investire nella definizione di una chiara baseline di sicurezza (chi può fare cosa, con quali identità, quali log vengono raccolti) e in meccanismi di governance che monitorino e impongano le buone pratiche (policy, audit, reportistica). In ambienti enterprise spesso ci sono team di sicurezza e compliance: Azure Automation, se ben configurato, non è un ostacolo per loro, anzi può diventare uno strumento in più (si pensi ai runbook che correggono configurazioni non conformi automaticamente), ma va trattato con lo stesso rigore di qualsiasi altra risorsa critica.
8. Ottimizzazione dei Costi con l’Automazione
Uno degli obiettivi spesso perseguiti nel cloud computing è la riduzione dei costi operativi. Azure offre strumenti di Cost Management e Billing per monitorare e pianificare la spesa, ma l’automazione può portare la gestione dei costi ad un livello successivo, agendo proattivamente per ottimizzare l’uso delle risorse. In questo capitolo vedremo come Azure Automation possa essere utilizzato per creare processi che aiutano a ridurre e ottimizzare i costi cloud.
a) Scenari di ottimizzazione tramite runbook:
· Spegnimento di risorse inattive: Un classico esempio è lo spegnimento automatico di macchine virtuali che non sono utilizzate. Molte organizzazioni, ad esempio, spengono le VM dei test, sviluppo o demo al di fuori dell’orario lavorativo, poiché tenerle accese 24/7 sarebbe uno spreco di denaro. Un runbook può essere programmato per spegnere (deallocare) determinate VM alle 20:00 e riaccenderle alle 7:00 del mattino seguente, dal lunedì al venerdì. Oppure può spegnere VM che rileva in stato di idle (basso utilizzo CPU/RAM) per un certo tempo.
· Ridimensionamento automatico: Allo stesso modo, i runbook possono aiutare a cambiare SKU o livello di servizio di risorse a seconda dell’utilizzo. Ad esempio, se un database SQL in Azure è scarsamente utilizzato, si potrebbe scalare a una tier inferiore nelle ore di bassa attività e riportarlo su una tier superiore negli orari di punta. Questo può essere orchestrato con runbook che schedulano i cambi di SKU basandosi su metriche di utilizzo ottenute tramite le API di monitoraggio.
· Pulizia di risorse inutilizzate: Spesso in ambienti cloud rimangono risorse cosiddette “orfane” – dischi non collegati, IP pubblici non assegnati, istanze di sviluppo dimenticate, file di log vecchi etc. Queste risorse, anche se non attivamente utilizzate, possono generare costi (es. storage, IP riservati). Un runbook può periodicamente scansionare la sottoscrizione alla ricerca di tali risorse e generare un report o eliminarle automaticamente secondo regole predefinite. Ad esempio, cancellare automaticamente i backup più vecchi di X giorni se non più necessari.
· Tiering dello storage: per i dati che devono essere mantenuti ma non acceduti di frequente, Azure offre livelli di storage (Hot, Cool, Archive) con costi decrescenti. Un runbook può analizzare i blob in uno storage account e spostare automaticamente quelli non modificati da molti mesi nel tier Archive (che costa molto meno), lasciando solo i dati recenti in Hot. Questo avviene via API di Azure Storage e può far risparmiare molto su archivi di grandi dimensioni.
· Schedulazione avanzata in base a costi: integrandosi con l’API di Azure Cost Management, i runbook potrebbero addirittura reagire a soglie di budget. Immagina di avere un budget mensile per una sottoscrizione: un runbook può controllare ogni giorno quanto budget è stato consumato e, se si sta superando una certa soglia (ad es. il 90% a metà mese), intraprendere azioni correttive come spegnere risorse non critiche, o inviare notifiche ai team per ridurre l’uso.
b) Accesso ai dati di costo: Azure mette a disposizione dati sui costi e utilizzo tramite:
· Cost Management API: un’API che fornisce dati di costo aggregati (ad esempio spesa per servizio, per risorsa, trend temporali). Un runbook può chiamare queste API se autorizzato (serve di solito l’accesso ai dati di billing, che può essere concesso tramite l’account di automazione con permessi di Cost Management Reader).
· Esportazioni di costo: Azure può generare file (CSV) giornalieri con il dettaglio dei costi. Un runbook potrebbe caricare questi dati ed elaborarli, ad esempio per individuare la risorsa che sta costando di più e non dovrebbe, ecc.
· Metriche di utilizzo: per alcune ottimizzazioni (come decidere se spegnere una VM per inattività), più che i costi serve guardare le metriche di performance (CPU, rete, etc.). Queste sono disponibili da Azure Monitor. Un runbook può recuperare la % di CPU di una VM nell’ultima ora e, se sotto una soglia, decidere di spegnerla.
Best practice per automazione orientata ai costi:
· Tagging coerente delle risorse: un elemento cruciale è l’uso di tag sulle risorse Azure. I tag (es. "Environment:Dev", "Owner:TeamA", "Criticality:High/Low") permettono di categorizzare le risorse. I runbook di ottimizzazione costi dovrebbero usare i tag per capire cosa fare: ad esempio, spegnere solo le VM non produttive ("Environment:Dev" o "Test"), e magari lasciare sempre accese quelle con "Criticality:High". Oppure spostare su Archive solo i blob con tag "ArchiveEligible:Yes". Insomma, i tag guidano l’automazione a sapere cosa può toccare senza rischio.
· Programmare operazioni di costo in orari appropriati: ad esempio, le attività di spegnimento conviene pianificarle fuori orario di utilizzo (spegnere di notte, accendere al mattino). Le attività di analisi costi e spostamento dati possono essere fatte giornalmente di notte o nel weekend, per non interferire con le prestazioni percepite dagli utenti.
· Valutare impatto su SLA e operatività: non tutte le risorse possono essere spente senza impatto. Esempio: spegnere una VM di produzione di un database per risparmiare costi è raramente fattibile perché interrompe un servizio critico. Quindi, l’automazione deve essere ben calibrata a intervenire solo dove c’è un margine (ambienti di test, risorse ridondanti, servizi di backup, etc.). Inoltre, ridimensionare al ribasso troppe risorse potrebbe degradare performance; bisogna trovare un equilibrio e magari applicare soglie (es. non scendere mai sotto un certo SKU, ecc.).
· Monitorare e notificare: ogni azione di cost optimization dovrebbe essere tracciata e comunicata. Se un runbook spegne delle VM, è opportuno che invii un’email o notifica ai responsabili con l’elenco delle risorse spente e il calcolo stimato del risparmio ottenuto (“Spegnendo queste 3 VM dalle 20:00 alle 8:00 risparmiamo circa X euro al giorno”). Questo sensibilizza tutti e crea fiducia nel processo automatico, oltre a fornire un log consultabile.
c) Esempi pratici:
· Un team DevTest vuole ridurre sprechi: crea un runbook AutoShutdownNonProd che ogni sera spegne tutte le VM con tag Environment=Test o Dev nel loro subscription. Questo runbook invia poi un messaggio Teams al gruppo “DevTest Team” con scritto “Le VM di test sono state spente. Risparmio stimato: 50€ se restano spente fino a domattina”.
· Un altro runbook OptimizeStorageCosts gira mensilmente: legge dal Cost Management l’elenco dei storage account con costo maggiore di, poniamo, 100€ e controlla quanti dati stanno in Hot vs Cool vs Archive. Per ciascuno, se vede che ci sono almeno 500 GB di dati non modificati da > 6 mesi in Hot, li sposta in Cool o Archive. Poi invia un report con “Spostati 500GB di dati di log dall’account X a Archive, risparmio mensile stimato: Y€”.
· Un runbook possibile è anche impostare alert di budget: Azure nativamente permette di configurare alert al superamento di certe soglie di budget. Ma potremmo anche voler automatizzare la risposta a un budget sforato: ad esempio, se la spesa mensile supera il budget assegnato all’ambiente QA, un runbook potrebbe automaticamente scalare down alcune risorse (ridurre il numero di VM nel cluster di test, sospendere ambienti di lab, ecc.) per rientrare nel budget. Questo è delicato perché tocca priorità aziendali, ma è fattibile con le giuste regole.
d) Diagramma di ottimizzazione costi: l’immagine allegata illustrava un ipotetico flusso di costo:
· Input da Cost Management (che fornisce dati di spesa e utilizzo),
· regole logiche (in un runbook o workflow) che decidono le azioni (spegnere VM, ridurre SKU, archiviare dati),
· esecuzione di queste azioni,
· e un feedback loop magari con persone o sistemi (ad esempio, notifica che l’azione è stata intrapresa, oppure se le azioni hanno avuto successo o se c’erano impedimenti). Questo è un ciclo continuo: ogni mese o settimana, in base ai dati di cost e utilizzo aggiornati, si prendono decisioni per ottimizzare e poi si misurano i risultati.
In sintesi, Azure Automation può diventare un prezioso alleato del Cloud Cost Management, attuando decisioni che altrimenti resterebbero manuali o richiederebbero un intervento costante. Automatizzare la governance dei costi consente di risparmiare senza doversi ricordare ogni volta di fare quelle azioni ripetitive di housekeeping, e assicura che l’utilizzo delle risorse cloud rimanga allineato alle necessità, evitando sprechi.
9. Migliori Pratiche per Azure Automation e Considerazioni Finali
Giunti all’ultimo capitolo, riassumiamo alcune migliori pratiche generali per utilizzare Azure Automation in modo efficace e sicuro, molte delle quali sono emerse nei precedenti capitoli, e aggiungiamo considerazioni finali. Queste best practice coprono aspetti di metodologia, gestione del ciclo di vita dell’automazione, qualità del codice, e strategie operative per assicurare che l’automazione porti benefici senza introdurre regressi.
a) Documentazione e mantenibilità:
· Documentare i Runbook: Ogni runbook dovrebbe contenere descrizioni chiare del suo scopo, dei parametri che utilizza, dei prerequisiti e di eventuali effetti collaterali. Questo può essere fatto inserendo commenti all’inizio dello script (per i runbook PowerShell/Python) o mantenendo un file README separato. In ambienti complessi, può essere utile anche avere una sorta di wiki o database dove per ogni runbook si registra chi l’ha scritto, quando, a cosa serve, chi contattare per domande, e magari un link al codice sorgente se tenuto in repository esterno.
· Note su obiettivi e scenari di errore: Nella documentazione conviene includere anche quali risultati ci si aspetta (ad esempio “questo runbook deve ridurre il numero di VM di test, se ne trova più di 5 ne spegne fino a tornare a 5”), e come il runbook si comporta in caso di problemi (es. “se la VM non risponde, ritenta 3 volte poi genera un alert”). Questo aiuta chi leggerà i log a capire se il comportamento osservato è voluto o no.
· Collegamento a work items: Se l’organizzazione utilizza sistemi di tracking (Azure Boards, GitHub issues, Jira), è una buona pratica collegare ogni modifica ai runbook a un work item (ticket/bug/feature). Ad esempio, se si migliora un runbook per aggiungere una funzionalità, quell’informazione dovrebbe risultare tracciata. In tal modo, se in futuro sorge un dubbio “perché questo runbook fa così?”, si può risalire alla discussione nel work item e capire le ragioni storiche.
b) Sviluppo e testing delle automazioni (DevOps per runbook):
· Ambienti separati per test: Non testare mai direttamente in produzione. Creare un Automation Account di test o usare l’ambiente di sandbox/test per provare nuovi runbook o modifiche. Popolare l’ambiente di test con risorse dummy o di test su cui i runbook possano agire senza causare impatto reale. Ad esempio, se sviluppiamo un runbook che spegne VM, nel test useremo VM di test, non quelle di produzione.
· Pipeline CI/CD per runbook: Trattare i runbook come codice vero e proprio (Infrastructure as Code). Ciò significa idealmente memorizzare gli script in un repository (Git). Da qui, implementare una pipeline di CI/CD (Continuous Integration/Continuous Deployment):
o Lint/Validation: strumenti automatici controllano la sintassi dei runbook, ad esempio PSScriptAnalyzer per PowerShell (linting, best practice statiche) o analisi di stile.
o Test: se possibile, scrivere test automatizzati per i runbook. Non è sempre facile fare unit test di script infrastrutturali, ma si possono simulare alcune parti (moking di cmdlet Azure) o eseguire il runbook in modalità “WhatIf” se supportato. In alternativa, almeno test manuali approfonditi in ambiente di test per vari scenari (inclusi casi di errore).
o Import e versione: la pipeline potrebbe automatizzare l’importazione/aggiornamento del runbook nell’Automation Account di test, e successivamente, se i test passano, nell’Automation Account di produzione. Azure ha API per aggiornare runbook, quindi questo può essere scriptato.
o Review (PR): ogni modifica significativa dovrebbe essere revisionata da un collega (pull request code review), specialmente per runbook critici, per cogliere errori o implicazioni sfuggite all’autore.
· Rilasci solo dopo integrazione: Una volta che un runbook è testato isolatamente, considerare anche test di integrazione se interagisce con altri processi (es. se un runbook viene chiamato da una Logic App, provare l’intera catena in staging). Solo quando si ha confidenza che tutto funzioni come atteso, distribuire in produzione (magari inizialmente monitorando strettamente le prime esecuzioni, o rilasciandolo disabilitato e poi attivandolo in un momento controllato).
c) Configurabilità e flessibilità:
· Evitare valori hardcoded: non “imbullonare” nello script valori che potrebbero cambiare. Se un runbook deve operare su una risorsa specifica (es. un nome di macchina virtuale, un percorso, un indirizzo email per notifiche), meglio passarlo come parametro o metterlo in una variabile dell’Automation Account. Ciò consente di riutilizzare il runbook in contesti diversi e adattarlo facilmente.
· Usare Key Vault e variabili per info sensibili: come già detto, qualunque stringa sensibile (password, chiavi) non deve comparire nel codice. In più, anche parametri come stringhe di connessione o URL dovrebbero poter essere cambiati senza editare il runbook. L’uso di variabili globali o l’integrazione con un Key Vault rende i runbook più generici.
· Parametrizzare l’ambiente: se lo stesso runbook viene usato in Dev e Prod, potrebbe comportarsi leggermente diverso (es. in Dev magari manda notifiche a un canale Teams di test, in Prod a un canale reale, oppure in Dev lavora su un subscription differente). Si possono usare variabili d’ambiente o naming convenzioni per far sì che il runbook “scopra” in che contesto gira e adatti il suo comportamento. Ad esempio, potremmo avere una variabile booleana IsProduction nell’account di Prod settata a true, e false in test, che lo script può leggere per decidere se realmente eliminare risorse o solo simularlo.
· Gestione delle dipendenze: mantenere aggiornati i moduli importati (le librerie) e caricare solo quelli necessari. Eliminare moduli obsoleti dall’Automation Account per ridurre possibili conflitti. Questo rientra nella manutenzione e pulizia periodica dell’ambiente di automazione.
d) Sicurezza e affidabilità nel codice:
· Managed Identity e secret rotation: assicurarsi che i runbook non usino credenziali statiche a lungo termine. Se proprio devono (per servizi esterni), prevedere un meccanismo per aggiornare tali credenziali (rotazione) e magari integrarlo nel runbook stesso (ad esempio un runbook che ruota una password ogni tot giorni). Meglio però delegare a Key Vault e identità gestite dove possibile.
· Runbook idempotenti e con retry: ribadiamo l’idempotenza: prevedere controlli di stato all’inizio. Inoltre, implementare strategie di ripristino: se un passo fallisce per un errore temporaneo (es. una chiamata API che time-out), il runbook potrebbe attendere alcuni secondi e ritentare un paio di volte prima di arrendersi, per gestire transitori. Se un runbook interagisce con molti elementi, considerare di continuare oltre gli errori non critici, magari accumulando un report finale di quali sub-operazioni sono riuscite e quali no, invece che abortire tutto al primo errore (questo dipende dal contesto).
· Transazioni e compensazioni: per attività che modificano più risorse, pensare a cosa succede se il runbook si interrompe a metà. Ad esempio, se un runbook crea 3 risorse e fallisce sulla 3°, le prime 2 rimangono orfane? Potrebbe essere utile implementare una logica di compensazione (nel catch di errore, eliminare ciò che era stato creato prima, per lasciare l’ambiente pulito, oppure segnare chiaramente necessità di intervento manuale). Questo è difficile ma è ciò che distingue un runbook robusto da uno base.
e) Controllo dei costi e risorse orfane:
· Automatizzare la pulizia: come discusso nel capitolo 9, far sì che l’automazione stessa sia soggetta a controllo di costi: evitare di avere Automation Account inutilizzati (costano pochi euro ma comunque), moduli superflui, etc. Pianificare runbook che spengono ciò che non serve, anche relativo ai test (es. se ci sono Hybrid Worker di test accesi inutilmente).
· Monitorare l’utilizzo: capire come e quanto i runbook vengono usati. Ad esempio, se ci sono runbook mai eseguiti da mesi, valutare se ancora servono o se vanno aggiornati.
6. Cultura e processi:
· Formare gli utenti: chiunque abbia accesso a creare o modificare runbook dovrebbe ricevere linee guida su queste best practice. Ad esempio, un developer inesperto potrebbe scrivere un runbook che funziona ma non segue regole di sicurezza (inserisce una password hardcoded). Una buona governance passa anche per training e checklist di revisione interna.
· Procedura di emergenza: considerare cosa fare se un runbook finisce in un loop o produce effetti indesiderati a catena. Avere un modo rapido per disabilitare tutti i schedule (Azure non ha un “panic button”, ma un admin potrebbe manualmente disabilitare i schedule se si accorge che qualcosa sta andando storto, oppure disabilitare l’Automation Account temporaneamente). Simulare scenari di disastro (ad es. “e se un runbook sbagliato spegne tutte le VM di prod, come ce ne accorgiamo e come reagiamo?”) e preparare contromisure (alert, step manuali).
f) Epilogo e schema visivo:
Nella slide finale, come descritto, c’era un riassunto visivo: una checklist di punti da ricordare (doc, test, sicurezza, ecc.) e un flusso CI/CD che mostra come adottare un ciclo virtuoso nello sviluppo dei runbook. I passi del workflow CI/CD illustrato includono:
· Lint: controllo statico del codice (best practice enforcement).
· Test: esecuzione di test automatici.
· Import: caricamento del runbook nell’ambiente (di test, poi prod).
· Deploy: attivazione in produzione, magari con esecuzione schedulata o integrata.
· Monitor: monitoraggio continuo del funzionamento con logging e alert.
Questo ciclo continuo di integrazione e deploy assicura che le automazioni rimangano affidabili nel tempo e possano evolvere senza rompere nulla.In conclusione, Azure Automation è un ecosistema ricco che, se sfruttato a pieno, consente di ottenere un’infrastruttura autosufficiente su molti aspetti operativi, dall’orchestrazione alla configurazione allo shutdown dei costi. Ma questo potenziale va incanalato con disciplina: l’attenzione alle migliori pratiche sopra elencate farà la differenza tra un set di script isolati e una vera piattaforma di automazione solida a livello enterprise. Per uno studente o professionista che arriva al termine di questa guida, l’auspicio è che abbia gli strumenti concettuali per iniziare a implementare automazioni Azure in contesti reali, con cognizione sia delle opportunità che delle responsabilità che esse comportano.
Conclusioni
Azure Automation rappresenta pertanto un pilastro per la gestione intelligente delle infrastrutture IT, consentendo di ridurre interventi manuali e aumentare efficienza. I runbook sono il cuore dell’automazione: script o flussi grafici che eseguono procedure in modo sicuro e ripetibile, con possibilità di integrazione tramite API, webhook e Logic Apps. La progettazione idempotente e l’uso di Managed Identity garantiscono robustezza e sicurezza, evitando credenziali statiche. L’Automation Account funge da contenitore centrale per runbook, asset e configurazioni, con best practice che includono separazione degli ambienti, logging avanzato e integrazione con Key Vault. La funzionalità Hybrid Runbook Worker estende l’automazione a sistemi on-premises e multi-cloud, mantenendo il controllo centralizzato. Con Update Management, la piattaforma automatizza patching e compliance, riducendo rischi e carico operativo. La State Configuration (DSC) introduce un approccio dichiarativo per garantire configurazioni coerenti e auto-ripristinanti nel tempo. L’integrazione con servizi esterni e flussi approvativi (Teams, ITSM) amplifica il valore dei runbook in scenari complessi. Sicurezza e governance sono imprescindibili: RBAC, audit, policy e monitoraggio continuo prevengono abusi e garantiscono conformità. L’automazione diventa anche leva di ottimizzazione dei costi, con runbook che spengono risorse inattive, ridimensionano servizi e gestiscono storage. Infine, adottare pratiche DevOps, versionamento e CI/CD per i runbook assicura qualità, tracciabilità e scalabilità. In sintesi, Azure Automation non è solo uno strumento tecnico, ma un ecosistema strategico che, se governato correttamente, abilita efficienza, sicurezza e innovazione nei processi IT.
Riepilogo capitolo
Il capitolo offre una guida dettagliata su Azure Automation, spiegando come automatizzare attività operative, gestire risorse e garantire sicurezza, governance e ottimizzazione dei costi in ambienti cloud e ibridi.
· Runbook e automazione: I runbook sono script automatizzati in Azure Automation che eseguono attività senza intervento manuale. Possono essere scritti in PowerShell, Python o creati visivamente, eseguiti manualmente, pianificati, via webhook o integrati con altri servizi come Logic Apps. Gestiscono variabili, credenziali, moduli e usano Managed Identity per la sicurezza, favorendo runbook idempotenti e robusti. Un esempio pratico è l’avvio automatico di una VM prima dell’inizio del turno.
· Automation Account: È il contenitore centrale che ospita runbook, schedule, variabili, credenziali, moduli e gestisce identità e logging. Si consiglia di separare gli ambienti di produzione e test, abilitare diagnostica, versionare i runbook e integrare Azure Key Vault per la gestione sicura dei segreti, applicando il principio del minimo privilegio. Un esempio è un Automation Account dedicato all’ambiente di produzione con Managed Identity, logging centralizzato e restrizioni di rete tramite Private Endpoint.
· Hybrid Runbook Worker: Permette di eseguire runbook su macchine locali o in altre reti isolate tramite un agente registrato nell’Automation Account. Utile per accesso a risorse on-premises, requisiti di compliance o ambienti multi-cloud. L’agente esegue localmente i runbook, comunicando con Azure per log e stato. È importante monitorare la connettività, la disponibilità e la sicurezza dei worker. Un esempio è l’automazione di installazione di aggiornamenti su un server on-premises tramite Hybrid Worker.
· Update Management: Automatizza la gestione delle patch su VM Azure e server on-premises. Consente di rilevare aggiornamenti mancanti, pianificare deployment, escludere patch specifiche e eseguire script pre/post aggiornamento. Fornisce report di conformità e si integra con altre funzionalità come Change Tracking. Un esempio è un ciclo mensile di patching con script di arresto e avvio servizi applicativi e report di successo o errore.
· Azure Automation State Configuration (DSC): Implementa configurazioni dichiarative e auto-ripristinanti tramite PowerShell DSC, mantenendo coerente lo stato dei sistemi nel tempo. I nodi scaricano la configurazione da Azure Automation e riportano la conformità. Utile per hardening, installazione di ruoli e compliance. Un esempio è la configurazione di server web che assicura IIS installato, TLS1.0 disabilitato e file standard presenti, con correzione automatica di eventuali derive.
· Integrazione con altri servizi: Runbook possono essere innescati o orchestrati da Logic Apps, Power Automate, webhook e API REST, permettendo scenari complessi come automazione on-call, integrazione con sistemi ITSM, processi di business e workflow con approvazioni umane via Teams. Un esempio è un flusso che spegne VM di sviluppo con notifica e possibilità di posticipa tramite Adaptive Card su Teams.
· Sicurezza e governance: È fondamentale applicare RBAC con minimo privilegio, usare Managed Identity, proteggere credenziali, isolare reti con Private Endpoint e monitorare tramite audit log e job log. Azure Policy può imporre configurazioni e compliance sugli Automation Account e risorse gestite. Si raccomanda reportistica sull’affidabilità e controllo continuo per mantenere sicurezza e conformità.
· Ottimizzazione costi: Azure Automation aiuta a ridurre sprechi spegnendo risorse inattive, ridimensionando SKU, pulendo risorse orfane e spostando dati su tier di storage più economici. Può integrare dati di Cost Management e metriche di utilizzo, agendo su soglie di budget. Best practice includono tagging coerente, pianificazione in orari appropriati e monitoraggio con notifiche. Esempi pratici includono spegnimento VM di test e archiviazione dati non usati.
· Migliori pratiche: Documentare runbook, usare ambienti di test, adottare pipeline CI/CD con linting, test e revisioni, parametrizzare script, usare Key Vault, garantire idempotenza e retry, gestire dipendenze, automatizzare pulizia e monitoraggio, formare utenti e preparare procedure di emergenza. Un ciclo virtuoso di sviluppo assicura automazioni affidabili e sicure.
CAPITOLO 11 – Il servizio di analisi
Introduzione
Quando si parla di integrazione e orchestrazione dei dati nel cloud, Azure Data Factory rappresenta uno degli strumenti più potenti e versatili a disposizione. In un contesto in cui le aziende generano e raccolgono informazioni da fonti eterogenee – database relazionali, file CSV, API, sistemi ERP e CRM – la sfida non è solo acquisire questi dati, ma trasformarli, consolidarli e renderli disponibili in modo coerente e automatizzato per analisi e processi decisionali. Azure Data Factory nasce proprio con questo obiettivo: offrire una piattaforma serverless capace di orchestrare pipeline di dati complesse senza che l’utente debba preoccuparsi dell’infrastruttura sottostante. Il concetto di pipeline è centrale: immaginatela come una catena di montaggio in cui ogni fase corrisponde a un’attività specifica, dalla copia dei dati alla loro trasformazione, fino alla pubblicazione in una destinazione finale. La forza di ADF sta nella sua flessibilità: è possibile definire pipeline parametrizzabili, pianificarne l’esecuzione con trigger basati sul tempo o sugli eventi, integrare script personalizzati e persino orchestrare flussi che coinvolgono servizi esterni. Tutto questo avviene in un ambiente scalabile, dove Azure si occupa di allocare risorse e garantire performance ottimali. Pensiamo a un esempio concreto: un’azienda che ogni giorno deve elaborare i dati di vendita provenienti da un ERP, normalizzarli e caricarli in un data lake per poi renderli disponibili a strumenti di business intelligence. Con ADF, questo processo diventa completamente automatizzato, riducendo errori manuali e tempi di lavorazione. L’approccio modulare e la possibilità di utilizzare parametri rendono le pipeline riutilizzabili e adattabili a diversi scenari, mentre l’integrazione con servizi come Azure Key Vault e le identità gestite assicura la protezione delle credenziali e la conformità alle best practice di sicurezza. Inoltre, il monitoraggio dettagliato delle esecuzioni consente di analizzare le performance e individuare eventuali colli di bottiglia, garantendo un controllo costante sull’intero flusso. In sintesi, Azure Data Factory non è solo uno strumento tecnico, ma un abilitatore strategico per costruire architetture dati moderne, capaci di supportare analisi avanzate, machine learning e processi decisionali basati su informazioni affidabili. Comprendere il suo funzionamento significa acquisire una competenza chiave per chiunque voglia operare nel mondo della data integration e dell’analytics su scala enterprise.
Inquadramento argomenti del capitolo con slides illustrate
Azure Data Factory consente di creare pipeline automatizzate che orchestrano ingestione, trasformazione e pubblicazione dei dati. Una pipeline è un contenitore logico di attività come copy, data flow, notebook e web activity, che possono essere pianificate, parametrizzate e monitorate come un’unica unità. Le attività si suddividono in movimenti di dati, trasformazioni e controllo. Questo approccio separa la logica dall’infrastruttura, permettendo di scalare in modo serverless. Esempi pratici includono l’ingestione giornaliera da ERP verso Data Lake, normalizzazione di file CSV e orchestrazione end-to-end con trigger pianificati e parametri per gestire ambienti e variabili. Le pipeline run sono istanze di esecuzione identificate da un Run ID, mentre i trigger avviano le pipeline secondo una pianificazione, una finestra o un evento. Dataset e Linked Service sono astrazioni per dati e connessioni. Le buone pratiche prevedono pipeline modulari, uso di parametri, isolamento delle credenziali con Entra e Key Vault, attivazione del Time To Live per cluster, e monitoraggio dettagliato tramite l’icona del piano di esecuzione. Il diagramma mostra il flusso orchestrato: Copy, Data Flow, Publish, e una tabella dei trigger con i loro casi d’uso.
Azure Data Lake Storage Gen2 fornisce uno storage scalabile, economico e sicuro per dati strutturati e non strutturati, basato su Azure Blob Storage con hierarchical namespace, ACL POSIX e driver ABFS compatibile HDFS. È il fondamento della medallion architecture: bronze, silver, gold. Esempi pratici sono la strutturazione dei container in raw-data, processed-data e analytics-results, integrazione con Spark/Synapse tramite URI abfss, e gestione dei permessi granulare con ACL e ruoli Entra per separare domini come vendite e finance. Il hierarchical namespace abilita directory e operazioni atomiche su file, mentre ABFS è il driver ottimizzato per big data. Delta e Parquet sono formati colonnari per performance e transazionalità. Le buone pratiche includono l’abilitazione del namespace gerarchico, l’uso di Parquet e Delta, una naming convention coerente, data retention controllata, soft delete, versioning e separazione delle aree di lavoro per il least privilege. L’albero delle cartelle rappresenta i livelli bronze, silver e gold con regole di ACL per gruppi.
Azure Synapse Analytics integra SQL, sia serverless che dedicated pools, e Apache Spark per analisi parallele su grandi dataset, lavorando nativamente con ADLS Gen2. Spark offre calcolo distribuito in memoria e supporta Python, Scala e SQL. Alcuni esempi pratici sono la data preparation con notebook PySpark e salvataggio in tabelle Delta, query interattive con serverless SQL su file Parquet o CSV nello storage, e integrazione tra Spark e Dedicated SQL pool tramite connettore ad alte prestazioni. Spark pool è un cluster gestito con autoscale e TTL, serverless SQL è un motore pay-per-query, e il Connector Spark-SQL consente scambio efficiente fra motori. Le buone pratiche includono l’uso di Delta Lake per affidabilità transazionale, partitioning, caching, separazione dei workload interattivi da batch, e gestione delle workspace e linked services con identità gestite. Il diagramma mostra l’integrazione tra ADLS, Spark e Dedicated SQL, con percorsi di lettura, scrittura e caching.
Il lakehouse combina la flessibilità del data lake con la struttura e le performance del data warehouse, solitamente su formati Delta e con endpoint SQL di sola lettura. In Synapse e Fabric, la medallion architecture guida la progressiva qualità dei dati attraverso bronze, silver e gold. Esempi pratici includono la definizione di tabelle dimension e fact con chiavi surrogate e star schema, la generazione di viste gold per KPI, e l’esposizione dell’endpoint SQL analytics del lakehouse per interrogazioni T-SQL e collegamento diretto a Power BI tramite DirectLake. Lo star schema è il modello ottimizzato per analisi, Delta Lake è il formato transazionale, e l’SQL analytics endpoint è l’interfaccia di sola lettura su tabelle Delta. Buone pratiche prevedono la riduzione della complessità del modello, la normalizzazione delle dimensioni, l’utilizzo di surrogate keys e SCD, e la documentazione accurata di campi e relazioni, oltre all’applicazione di data contracts e controlli di qualità sui layer. Il diagramma mostra la medallion architecture e il mapping di tabelle dimension, fact e flussi di qualità.
Azure Stream Analytics è un servizio PaaS per elaborazione in streaming di dati da IoT Hub, Event Hubs o Kafka, con output verso Power BI, ADLS, SQL e Cosmos DB. Supporta un linguaggio SQL-like con windowing, join con reference data e funzioni geospaziali. Tra gli esempi pratici, la rilevazione di soglie di temperatura per alert real-time e dashboard Power BI live, sliding windows per calcolare medie mobili, e join con reference data per arricchire gli stream. Le Streaming Units rappresentano le risorse di calcolo e memoria, le window functions consentono aggregazioni temporali, e reference data sono dataset statici per lookup. Le buone pratiche suggeriscono la progettazione di query idempotenti, gestione dei dati in late arrival e dei fusi orari, uso coerente del partitioning in input, monitoraggio delle metriche di job e attivazione di alert; per carichi intensi si consiglia ASA cluster dedicati con VNET e Private Link. Il diagramma mostra la pipeline dallo stream di IoT Hub o Event Hubs, passando per la query ASA, fino a Power BI o ADLS, con esempio di query e finestra temporale.
Power BI offre un semantic model che descrive misure, gerarchie e relazioni per report interattivi e analisi self-service. I modelli possono essere Import, DirectQuery, Composite e, in Fabric, DirectLake su Delta. Esempi pratici sono la creazione di un modello con tabelle dimension e fact come Date, Product e Sales, misure DAX come Revenue e Margin%, uso di gerarchie temporali e descrizioni per usabilità, e condivisione di modelli certificati fra workspace. Il semantic model è la struttura dati pronta per la visualizzazione, lo star schema è raccomandato per prestazioni e semplicità, mentre la build permission controlla chi può creare contenuti dal modello. Buone pratiche sono denominazione leggibile delle entità, nascondere colonne tecniche, centralizzare misure, usare la role-level security, validare con Performance Analyzer e adottare modelli condivisi certificati. Lo schema mostra la stella con relazioni one-to-many e un elenco di misure DAX documentate.
Microsoft Purview offre data governance moderna con catalogo unificato per asset come tabelle, file e report, Data Map per scansione metadati multicloud, glossari, domini di governance e data products che raggruppano asset utili per specifici casi d’uso. Esempi pratici sono la scansione automatica di ADLS, Synapse e Power BI per popolare il catalogo, la creazione di un data product come 'Vendite Retail' che aggrega tabelle gold e report KPI con ownership e policy di accesso, e la valutazione della data quality con regole low-code e scoring per colonne, asset e prodotti. Il governance domain definisce confini organizzativi per regole e proprietà, data product è un gruppo di asset con contesto e policy, e il glossary è il vocabolario business condiviso. Le buone pratiche prevedono governance federata con regole comuni centrali e responsabilità ai domini, documentazione di termini e definizioni, gestione dell’accesso secondo il least privilege e monitoraggio di qualità e metadati. Lo screenshot mostra catalogo, classificazioni, policy e collegamenti a owner, con mappa dei domini.
Mapping Data Flows in Azure Data Factory e Synapse consentono trasformazioni visuali scalabili con Spark gestito: filtri, standardizzazioni, join, aggregazioni, arricchimenti e scritture su destinazioni. Offrono monitoraggio dettagliato del piano di esecuzione, tuning e parametri. Esempi pratici includono la standardizzazione di date e importi, gestione di valori null, deduplicazione e arricchimento con anagrafiche, implementazione di controlli di qualità tramite regole di validazione, error handling e reject sinks, e ottimizzazione delle performance con broadcast join per tabelle piccole e repartition su dati sbilanciati. L’Integration Runtime TTL riduce i tempi di startup dei cluster, broadcast join distribuisce dimensioni piccole su tutti i nodi, e l’execution plan mostra le fasi/stage con tempi e conteggi. Le buone pratiche suggeriscono preferenza per Parquet e Delta, monitoraggio delle quattro fasi critiche, evitare sort non necessari, source partitioning, logging limitato e isolamento delle trasformazioni pesanti. Il diagramma mostra le trasformazioni dalla sorgente al sink, con pannello di monitoraggio.
La sicurezza dei dati analitici in Azure è garantita da controlli nativi come criptazione at-rest e in-transit, RBAC, Private Endpoints e Defender for Cloud. Microsoft Defender for Cloud valuta la postura rispetto a standard e framework come ISO/IEC 27001 e GDPR, fornendo raccomandazioni e report. Esempi pratici sono l’abilitazione dei criteri di Regulatory compliance per la sottoscrizione e il monitoraggio dei controlli falliti, l’integrazione con Microsoft Purview Compliance Manager per una vista centralizzata, l’applicazione di Managed Identities e Key Vault per la gestione dei segreti, e l’isolamento della rete sui servizi dati. Gli standard di sicurezza sono insiemi di controlli mappati come iniziative di Azure Policy, MCSB è il benchmark di sicurezza cloud di Microsoft, mentre il Compliance dashboard mostra la percentuale di controlli passati o falliti. Le buone pratiche sono il principio del least privilege, uso di Private Link e VNET integration, automazione della remediation e conservazione dell’audit trail. La mappa mostra i controlli di Identity, Network, Data Protection e Monitoring, con link a raccomandazioni tipiche.
Azure Monitor fornisce metriche, log e alert per osservabilità end-to-end, mentre Microsoft Cost Management abilita analisi, budget e ottimizzazione dei costi secondo il modello pay-as-you-go, pagando per ingestione e retention dei log, alert e metriche avanzate. Esempi pratici sono la creazione di budget alerts per controllare la spesa mensile con notifiche email o segnali al superamento di soglie, la configurazione di anomaly alerts per variazioni inusuali, e l’ottimizzazione della raccolta log riducendo quelli superflui, usando sampling e retention differenziata. Il Log Analytics workspace è il contenitore per log con query KQL, cost scopes definiscono il perimetro di analisi, e vari tipi di alert possono essere impostati su budget, credito o dipartimento. Le buone pratiche sono l’etichettatura delle risorse per cost allocation, l’esportazione dei costi su Power BI, l’uso di reserved instances e savings plans dove compatibile, e il monitoraggio costante tramite dashboard. Il dashboard mostra metriche chiave come CPU, Throughput, Failures e il grafico di consumo e costi con soglie di budget.
1. Azure Data Factory: Orchestrazione di Pipeline di Dati
Immaginiamo di dover raccogliere e trasformare dati da diverse fonti ogni giorno in modo automatico: Azure Data Factory (ADF) è lo strumento di Azure pensato per orchestrare questi processi. ADF consente di costruire pipeline di dati automatizzate che gestiscono l’ingestione, la trasformazione e la pubblicazione di dati provenienti da sorgenti eterogenee. Grazie ad Azure Data Factory, possiamo progettare flussi complessi di dati in modo serverless, ovvero senza preoccuparci dell’infrastruttura sottostante: Azure fornirà le risorse necessarie e scalerà automaticamente in base al carico.
Cos’è una pipeline? Si tratta di un contenitore logico di attività di elaborazione. Pensiamo a una pipeline come a una catena di montaggio per i dati: al suo interno si possono definire diversi passi o attività (activities) come la copia di dati da una fonte a un’altra (Copy), l’esecuzione di trasformazioni complesse su grandi volumi di dati (Data Flow), l’avvio di un notebook o script personalizzato per elaborazioni specifiche, oppure l’attivazione di chiamate a servizi web esterni (Web activity). Queste attività vengono orchestrate e gestite con un’unica pipeline, che si può pianificare (schedulare nel tempo), parametrizzare (rendere flessibile con parametri configurabili) e monitorare come un’entità unica.
Le attività in una pipeline ADF si classificano in tre categorie principali:
· Movimenti di dati: attività che spostano o copiano dati da un sistema all’altro (ad esempio da un database a un data lake).
· Trasformazioni: attività che modificano o elaborano i dati (come attività di data flow, script su Spark, stored procedure, etc.).
· Controllo: attività di controllo del flusso, ad esempio condizioni, cicli, o chiamate a funzioni esterne, che aiutano a definire la logica di orchestrazione (per esempio attendere il completamento di un processo, oppure diramare il flusso in base a un risultato).
Questa suddivisione separa la logica di processo dall’infrastruttura: significa che chi progetta la pipeline si concentra sul cosa fare ai dati, lasciando ad Azure il come eseguire queste operazioni in modo efficiente e scalabile. In pratica ADF garantisce che anche flussi complessi possano scalare in modo elastico (aggiungendo potenza di calcolo all’occorrenza) senza che l’utente debba gestire manualmente server o macchine virtuali.
Vediamo un esempio pratico per comprendere l’utilità di Azure Data Factory: supponiamo di avere un’azienda con un sistema ERP che ogni giorno genera file CSV con le vendite giornaliere. Con ADF, possiamo creare una pipeline che ogni notte si avvia automaticamente, preleva il file CSV generato dall’ERP, lo ingestisce caricandolo in un Data Lake di Azure (uno spazio di archiviazione dati), poi avvia una trasformazione per normalizzare i dati (ad esempio convertire le date in un formato standard, calcolare il totale vendite, pulire eventuali valori anomali) e infine pubblica i dati puliti inserendoli in un database relazionale o li prepara per la visualizzazione in un report. Tutto questo accade senza intervento manuale, grazie alla pipeline definita. Un altro esempio: con ADF è possibile orchestrare un flusso end-to-end che integra dati da diverse fonti (ERP, CRM, file di log) e al termine genera un output unico pronto per l’analisi, utilizzando trigger pianificati (ad esempio ogni ora o ogni giorno a mezzanotte) e parametri che consentono di riutilizzare la stessa pipeline in diversi ambienti (sviluppo, test, produzione) o per diversi intervalli di date.
Alcuni concetti chiave di Azure Data Factory sono:
· Pipeline run: ogni esecuzione (run) della pipeline è un’istanza di esecuzione distinta, identificata da un Run ID. Questo è utile per monitorare e distinguere i vari avvii della pipeline (ad esempio, per controllare lo storico delle esecuzioni giornaliere e verificarne l’esito).
· Trigger: è il meccanismo che avvia l’esecuzione di una pipeline. I trigger possono essere di vario tipo, tipicamente basati sul tempo (ad esempio un trigger programmato che fa partire la pipeline ogni giorno a una certa ora), basati su finestre temporali ricorrenti (ad esempio ogni ora dalle 9:00 alle 18:00, tipico per elaborazioni di streaming a micro-batch), oppure basati su eventi (ad esempio l’arrivo di un nuovo file in uno storage che fa scattare l’esecuzione della pipeline). Grazie ai trigger, le pipeline possono essere eseguite automaticamente senza intervento umano.
· Dataset e Linked Service: questi sono oggetti di configurazione in Azure Data Factory che servono a rappresentare, rispettivamente, i dati e le connessioni alle fonti/destinazioni. Un Linked Service è essenzialmente una definizione di connessione a una risorsa esterna (come un database SQL, un’istanza di storage, un data warehouse, un’API, ecc.), comprensiva di stringhe di connessione e credenziali. Un Dataset invece rappresenta un particolare insieme di dati all’interno di una fonte o destinazione (ad esempio una tabella specifica in un database o un percorso di file in uno storage). In una pipeline, le attività di copia o trasformazione definiscono quale dataset di input leggere e dove scrivere l’output (dataset di output), usando i linked service per collegarsi fisicamente a quelle risorse. Questa astrazione rende le pipeline più riutilizzabili e gestibili: si possono cambiare i collegamenti alle risorse (ad esempio passare da un database di test a quello di produzione) semplicemente modificando il linked service, senza alterare la logica della pipeline.
Buone pratiche e consigli d’uso: per progettare pipeline efficaci con Azure Data Factory conviene seguire alcune linee guida. È raccomandabile suddividere i processi complessi in pipeline più modulari, magari suddividendo per aree funzionali o per fasi di elaborazione, e farle interagire se necessario (ad esempio una pipeline principale può chiamare pipeline secondarie per specifiche sotto-attività). Si dovrebbero usare ampiamente i parametri nelle pipeline e nei dataset, in modo da rendere le soluzioni flessibili e adattabili (per esempio, passare parametri come la data da elaborare, il nome del file di input, ecc.). Per gestire le connessioni e le credenziali in sicurezza, è preferibile utilizzare Azure Entra ID (precedentemente noto come Azure Active Directory) e Azure Key Vault: si possono configurare i Linked Service con autenticazione tramite identità gestite di Azure (Managed Identity) così da non dover inserire password nei parametri, e memorizzare eventuali segreti (chiavi di accesso, stringhe sensibili) nel Key Vault, isolando le credenziali dal codice. Quando si usano attività di Data Flow (trasformazioni big data su cluster Spark), è importante considerare di attivare il TTL (Time To Live) sui cluster di integrazione dati: questa impostazione permette al cluster Spark di rimanere attivo per un breve periodo anche dopo il completamento di un job, così che esecuzioni ravvicinate possano riutilizzare lo stesso cluster senza doverlo riavviare da zero ogni volta (risparmiando tempo, soprattutto in scenari di esecuzioni frequenti). Infine, Azure Data Factory fornisce un ottimo sistema di monitoraggio: tramite l’interfaccia di monitoraggio è possibile seguire il piano di esecuzione delle pipeline e vedere per ogni attività i tempi, eventuali errori e altri dettagli. Un consiglio pratico è di controllare spesso l’icona del piano di esecuzione dettagliato (un’icona a forma di occhio o lente nell’interfaccia di monitoraggio) per analizzare le performance della pipeline e identificare colli di bottiglia o errori in specifiche attività.
Con Azure Data Factory, il risultato è che l’infrastruttura passa in secondo piano: lo sviluppatore di dati può concentrarsi sulla logica di business e sulla trasformazione dei dati, lasciando ad Azure il compito di orchestrare e scalare il processo in maniera affidabile. In questo capitolo abbiamo visto come ADF renda possibile definire flussi di dati complessi e automatizzati, fondamentali per costruire soluzioni di data integration e business intelligence moderne.
2. Azure Data Lake Storage Gen2: Fondamenti e Best Practice
La crescita esponenziale dei dati richiede un sistema di archiviazione scalabile, economico e sicuro. Azure Data Lake Storage Gen2 (ADLS Gen2) risponde a questa esigenza fornendo uno storage ad alte prestazioni per dati sia strutturati (per esempio tabelle, CSV) sia non strutturati (immagini, file di log, dati JSON, ecc.). ADLS Gen2 è costruito sul servizio Azure Blob Storage, ma ne estende le funzionalità introducendo un namespace gerarchico e altri miglioramenti che lo rendono simile a un file system tradizionale ed efficiente per carichi di Big Data.
Una caratteristica chiave di ADLS Gen2 è il namespace gerarchico: attivando questa opzione (che di solito è disponibile al momento della creazione dello storage account, spuntando l’opzione "Enable hierarchical namespace"), il data lake supporta strutture di directory e file con comportamento atomico sulle operazioni di file. In altre parole, possiamo organizzare i dati in cartelle e sottocartelle, e le operazioni come rinominare o spostare file saranno atomiche (ovvero o falliscono o riescono completamente, senza stati intermedi incoerenti), cosa che in un blob storage tradizionale non è garantita. Questo consente di gestire i dati in modo più naturale e con performance migliori in scenari di analisi, poiché molte applicazioni big data (come Hadoop) si aspettano una struttura di tipo file system. Inoltre, ADLS Gen2 implementa delle ACL (Access Control Lists) in stile POSIX, ovvero meccanismi di permessi avanzati che permettono di definire accessi in modo granulare su file e cartelle (ad esempio potremmo dare a un certo gruppo di Azure AD il permesso di leggere una cartella specifica ma non un’altra). Queste ACL completano il modello di sicurezza basato sui ruoli Azure (RBAC), offrendo un duplice livello di protezione: da un lato si può controllare l’accesso a livello di container e account tramite i ruoli Azure, dall’altro dettagliare i permessi a livello di file system con le ACL.
Per interagire con ADLS Gen2 in modo efficiente, Azure fornisce un driver specifico chiamato ABFS (Azure Blob File System). ABFS è un driver compatibile con HDFS (Hadoop Distributed File System), ottimizzato per grandi volumi di dati. Questo significa che strumenti di analisi big data (come Apache Spark, Hive, Azure HDInsight, Azure Synapse) possono leggere e scrivere su ADLS Gen2 utilizzando percorsi che iniziano con abfss:// come se stessero accedendo a un file system Hadoop. L’integrazione è nativa e performante, facilitando l’adozione di ADLS Gen2 come base per qualsiasi progetto di data lake.
Nel contesto architetturale, ADLS Gen2 è spesso il fondamento della cosiddetta medallion architecture (architettura “a medaglioni”), che prevede la suddivisione dei dati in tre livelli o “medaglie” chiamati Bronze, Silver e Gold. Ciascun livello rappresenta uno stadio di lavorazione e qualità del dato:
· Bronze è il livello grezzo (raw), dove i dati vengono depositati esattamente come arrivano dalle sorgenti, senza trasformazioni significative. Qui troveremo ad esempio tutti i file originali appena estratti dai sistemi sorgente (dump di database, file CSV esportati, dati di sensori IoT, ecc.). L’idea è di avere uno storico completo e immodificato dei dati sorgente.
· Silver è il livello intermedio (talvolta detto anche cleaned o refined), in cui i dati bronze vengono processati per correggere errori, arricchiti con informazioni aggiuntive, normalizzati in formati strutturati omogenei. In quest’area i dati sono puliti e parzialmente elaborati, pronti per analisi più specifiche. Ad esempio, nel livello Silver potremmo avere i file bronze CSV importati in formato Parquet, con campi ripuliti e codifiche uniformi, oppure tabelle normalizzate.
· Gold è il livello del dato curato e pronto per l’analisi finale. Qui i dati sono ad alta qualità e aggregati o trasformati esattamente nel modo richiesto dalle analisi di business o dai report finali. Tipicamente il livello Gold contiene tabelle relazionali o viste pronte per la business intelligence, calcoli già eseguiti (come indicatori KPI) e dati disponibili per l’uso da parte di strumenti come Power BI, applicazioni di data science o altri consumer finali.
Questa architettura a tre livelli aiuta a gestire la complessità: ogni livello medallion ha i suoi scopi e i suoi responsabili, e si applicano controlli di qualità man mano più stringenti salendo dai bronze ai gold. Azure Data Lake Storage Gen2, con i suoi container e directory, consente di implementare facilmente questa suddivisione: una prassi comune è creare container o directory separate per i dati bronze, silver e gold. Ad esempio, il data lake di un’azienda potrebbe avere tre macro-cartelle: /raw-data (bronze), /processed-data (silver), e /analytics-results (gold). Ciascuna di queste può avere sottocartelle ulteriormente organizzate per dominio di dati o per soggetto (es: vendite, logistica, marketing) e su ognuna possono essere impostate ACL in modo che solo i team autorizzati accedano al livello appropriato (ad esempio il team di data engineering ha accesso in scrittura al bronze e silver, mentre i data analyst possono accedere in sola lettura al gold).
Esempi pratici di utilizzo di ADLS Gen2: un tipico scenario è l’integrazione con sistemi di analisi distribuita come Azure Synapse Analytics o Azure Databricks. Utilizzando il driver ABFS, un data scientist può montare il data lake nel suo cluster Spark e accedere ai dati con un semplice path come abfss://processed-data@mystorage.dfs.core.windows.net/vendite/2025/. In questo modo, può leggere dati silver per analizzarli o scrivere i risultati nel livello gold. Un altro esempio pratico è la gestione di permessi per separare ambienti o dipartimenti: ad esempio, i dati del reparto Finanza potrebbero risiedere in una cartella dedicata accessibile solo al personale finanziario, separata dai dati del reparto Vendite. Grazie alle ACL POSIX si può realizzare questa separazione anche all’interno dello stesso account di storage, garantendo che un data engineer di un’area non legga accidentalmente dati di un’altra area senza autorizzazione. Dal punto di vista prestazionale, formati di file colonnari come Parquet e sistemi di formato transazionale come Delta Lake sono fortemente consigliati su ADLS Gen2: Parquet organizza i dati per colonne e permette compressione ed elaborazioni molto più rapide su grandi dataset, mentre Delta Lake aggiunge capacità ACID (transazioni atomiche, versionamento dei dati, gestione di time-travel sui dati) mantenendo i dati su storage Parquet. Azure Data Lake Storage Gen2 supporta pienamente entrambi, rendendo possibili analisi più veloci e affidabili.
Best practice per ADLS Gen2: ci sono alcune linee guida da seguire per sfruttare al meglio un data lake su Azure. Prima di tutto, abilitare il namespace gerarchico è quasi sempre raccomandato per ottenere i benefici descritti (a meno di specifiche esigenze di compatibilità). È opportuno adottare una naming convention coerente per cartelle e file, ad esempio includendo nelle cartelle Bronze/Silver/Gold anche l’indicazione del dominio dei dati e la data di competenza, così da trovare facilmente i dataset (es: /raw-data/vendite/2025/01/ per i dati raw di vendite di gennaio 2025). La retention dei dati va pianificata: ADLS supporta funzionalità di soft delete (cancellazione logica con possibilità di recupero entro un certo tempo) e versioning (mantenere più versioni dei file mano a mano che vengono modificati). Abilitare queste funzioni aiuta a prevenire perdite di dati dovute a cancellazioni accidentali o corruzioni. Naturalmente, occorre monitorare i costi di storage e magari implementare politiche di retention che eliminano dopo X anni i dati che non servono più, soprattutto nel livello bronze che può crescere molto. Dal lato sicurezza, oltre alle ACL, è bene sfruttare i ruoli di Azure Active Directory per il principio del privilegio minimo (least privilege): ciascun utente o applicazione dovrebbe avere accesso solo alle aree del data lake indispensabili al proprio lavoro, minimizzando l’esposizione del dato. Infine, per ambienti complessi, può essere utile tenere separati diversi workspace o account di storage per diversi scopi (ad esempio sviluppo vs produzione, oppure diversi account per linee di business differenti), in modo da isolare i dati e ridurre rischi di mescolamento.
Azure Data Lake Storage Gen2 è quindi la spina dorsale di una soluzione di data lake in Azure: offre la scalabilità del cloud (possiamo memorizzare petabyte di dati pagando solo ciò che usiamo) unita a funzionalità di file system e sicurezza avanzata, risultando uno strumento essenziale per gestire e organizzare grandi moli di dati in ambito aziendale e accademico.
3. Azure Synapse Analytics: Integrazione di SQL e Spark
Nell’era dei Big Data, analizzare grandi moli di informazioni richiede strumenti flessibili che combinino tecnologie disparate. Azure Synapse Analytics è la risposta di Microsoft a questa esigenza: una piattaforma unificata che integra motori di analisi SQL (sia in modalità serverless che con pool dedicati) e il motore Apache Spark per l’elaborazione distribuita, il tutto strettamente integrato con i dati archiviati in Azure.
In Azure Synapse convivono due anime: da un lato un tradizionale data warehouse (con SQL pools), dall’altro un ambiente big data (con Spark pools), il tutto orchestrabile e gestibile da un unico studio. Synapse permette di lavorare nativamente con i dati in Azure Data Lake Storage Gen2: ciò significa che tanto le query SQL quanto i job Spark possono accedere agli stessi file e dati nel data lake senza doverli duplicare o spostare. Questa vicinanza tra data warehouse e data lake è una caratteristica chiave di Synapse, che lo distingue dalle soluzioni tradizionali.
Vediamo più nel dettaglio i due componenti principali:
· SQL Pools: in Synapse troviamo sia SQL dedicati (anche noti come Synapse Dedicated SQL Pools, in passato Azure SQL Datawarehouse) sia SQL serverless. I pool SQL dedicati sono cluster di data warehouse a scalabilità orizzontale, dove l’utente alloca in anticipo una certa capacità (misurata in unità di performance chiamate DWU o in istanze fornite) e può caricare dati in tabelle distribuite, eseguendo query T-SQL ad alte prestazioni su dataset di grandi dimensioni. Il modello serverless invece non richiede allocazione preventiva: consente di eseguire query SQL on demand direttamente sui file nel data lake (ad esempio su file Parquet, CSV o JSON) pagando in base ai dati letti da ogni query. Questo è molto utile per esplorazione interattiva di dati o per scenari in cui non si vuole importare tutto in un database.
· Apache Spark Pools: Synapse integra Apache Spark, uno dei framework più diffusi per l’elaborazione di big data. Lo Spark di Synapse è completamente managed, significa che con pochi clic si può creare un pool (un cluster) di Spark specificando dimensioni e configurazione, e Azure si occupa di gestirne l’infrastruttura. Spark in Synapse supporta i principali linguaggi usati nei notebook di data science e data engineering: Python (con PySpark), Scala, SQL Spark e anche .NET (C#) se necessario. I pool Spark possono essere configurati con autoscale (ovvero possono aumentare o diminuire il numero di nodi in base al carico) e con un TTL (Time to Live) che determina il tempo di inattività dopo il quale il cluster si spegne automaticamente per non consumare risorse inutilmente.
L’integrazione stretta di questi due mondi consente scenari davvero potenti. Esempi pratici: un data engineer potrebbe usare un notebook PySpark in Synapse per fare data preparation: supponiamo di avere dati grezzi (bronze) nel data lake, come file di log; con Spark si potrebbero pulire e trasformare questi file, aggregare informazioni, e poi salvarli in formato Delta come tabelle silver nel data lake. Subito dopo, un analista potrebbe eseguire una query SQL serverless su quei file Delta per controllare i risultati, o addirittura connettere un tool di BI per leggere direttamente quelle tabelle. In un altro scenario, immaginiamo di avere un grande dedicated SQL pool con dati aziendali storici (data warehouse consolidato) e di ricevere dati freschi tramite Spark (ad esempio streaming di dati IoT elaborato in tempo reale). Synapse permette di integrare Spark e SQL: esiste un connector ad alte prestazioni che consente a Spark di scrivere direttamente sulle tabelle del dedicated SQL pool, oppure viceversa di leggere da esse. Ciò significa che flussi di lavoro prima complessi da collegare ora sono fluidi: ad esempio, i risultati di un calcolo in Spark (come un modello predittivo applicato a dati grezzi) possono essere scritti immediatamente in una tabella del data warehouse dedicato, unendo il mondo dello storage file (datalake) con quello relazionale (data warehouse) senza dover lasciare la piattaforma Synapse.
Azure Synapse fornisce inoltre strumenti di gestione integrati: un’interfaccia unica (Synapse Studio) dove è possibile scrivere codice SQL, sviluppare notebook Spark, costruire pipeline di orchestrazione (Synapse integra funzionalità simili ad Azure Data Factory per creare pipeline ETL), e monitorare il tutto. Il Spark pool come detto è managed, quindi non dobbiamo occuparci manualmente di configurare ad esempio l’ambiente Yarn/HDFS come faremmo on-premise; in pochi secondi possiamo lanciare un cluster Spark. Il serverless SQL invece è sempre pronto, non richiede provisioning: ogni volta che scriviamo una query sui file, Synapse dietro le quinte alloca risorse e la esegue restituendoci i risultati rapidamente.
Best practice e considerazioni d’uso: sfruttando al massimo Synapse, conviene adottare qualche accorgimento. Uno è l’utilizzo di Delta Lake come formato per le tabelle sul data lake (specialmente per i livelli Silver e Gold): come spiegato, Delta fornisce affidabilità transazionale, versionamento e prestazioni nelle letture, il che è ideale in un contesto dove Spark e SQL devono condividere dati. Un altro consiglio è partizionare i dati dove possibile: ad esempio, se salviamo grosse tabelle in Parquet sul data lake, definire partizioni (per data, per regione, per categoria) migliora tantissimo le performance sia di Spark che delle query serverless, perché consente di leggere solo i file rilevanti alla query. Caching: Spark consente di mettere in cache in memoria dataset utilizzati spesso; se abbiamo dati chiave che vengono riutilizzati in più calcoli, usare il cache su Spark può ridurre i tempi di esecuzione. Dal punto di vista architetturale è bene separare i workload interattivi da quelli batch: Synapse permette di avere più pool Spark e naturalmente distingue anche il caso di query interattive ad-hoc (serverless) da quelle in produzione (dedicated). Questo significa che conviene tenere distinti, ad esempio, un cluster Spark dedicato a elaborazioni pesanti notturne da un cluster più piccolo riservato ad analisi esplorative dei data scientist durante il giorno. In questo modo i carichi non competono per le stesse risorse e si può gestire meglio costi e performance. Per quanto riguarda la sicurezza e la governance, Synapse consente di usare Managed Identity di Azure e integrare Linked Services (collegamenti a fonti dati esterne) in modo sicuro. Una best practice è centralizzare l’accesso alle risorse attraverso queste identità gestite, evitando di usare credenziali hard-coded. Infine, è importante monitorare l’utilizzo delle risorse di Synapse: come qualsiasi servizio potente, un uso inefficiente può portare costi elevati. Synapse fornisce monitor e logging per le query SQL (è possibile vedere quanto hanno elaborato e quanto sono costate le query on demand) e per i job Spark (log applicativi, tempi di esecuzione di ogni fase, utilizzo CPU/memoria per eseguire il tuning se necessario).
In sintesi, Azure Synapse Analytics rappresenta un ecosistema all-in-one per l’analisi di dati su Azure: la sua forza sta nel poter eseguire, in un’unica piattaforma, analisi SQL su scala da data warehouse e analisi distribuite con Spark su scala da data lake, sfruttando al massimo lo storage unificato su ADLS Gen2. Per uno studente, Synapse incarna i concetti sia di data warehousing sia di big data processing, offrendo un terreno pratico dove applicare entrambe le competenze senza dover saltare tra strumenti completamente diversi.
4. Lakehouse e Medallion Architecture: Unire Data Lake e Data Warehouse
Negli ultimi anni, l’evoluzione delle architetture dati ha portato alla convergenza tra i tradizionali data warehouse e i data lake, dando origine al concetto di Lakehouse. Un lakehouse è essenzialmente un data lake con caratteristiche tipiche di un data warehouse: offre la flessibilità di archiviare dati eterogenei come un data lake, ma al contempo garantisce la qualità dei dati, la struttura (schema) e le performance tipiche di un data warehouse. In pratica, il lakehouse mira a essere un “unico luogo” dove risiedono sia i dati grezzi che quelli raffinati, consentendo sia approcci esplorativi (tipici dei data lake) sia analitici strutturati (tipici dei DW).
Una tecnologia chiave abilitante per i lakehouse è l’uso di formati di file e sistemi di gestione che portano ACID transactions e gestione dello schema sui file nel data lake. Il più diffuso di questi è Delta Lake (originariamente sviluppato da Databricks e ora aperto come formato), che funziona sopra file Parquet gestendo commit atomici, versionamento dei dati e schema enforcement (controllo dello schema). Con Delta Lake, un data lake diventa in grado di comportarsi più come un database (accettare transazioni, garantire consistenza), pur mantenendo la scalabilità e il costo ridotto dello storage di oggetti.
In Azure, sia Synapse sia la nuova piattaforma Microsoft Fabric abbracciano il concetto di lakehouse. In Synapse, il paradigma si vede con l’integrazione di Spark e SQL serverless sul medesimo data lake (come descritto nel capitolo precedente). In Fabric, esiste proprio un oggetto chiamato “Lakehouse” che consente di caricare dati su Delta e li rende simultaneamente disponibili via un endpoint SQL.
La Medallion Architecture, di cui abbiamo già parlato, si sposa perfettamente con il concetto di lakehouse: i livelli Bronze, Silver, Gold diventano fasi dentro il lakehouse stesso. Nel contesto lakehouse, spesso il livello Gold viene modellato in modo simile a un data warehouse tradizionale, con schemi a stella (star schema) o a fiocco di neve (snowflake schema), tabelle dimensioni e fatti, e così via, ma mantenendo i dati nel formato file (es. tabelle Delta nel data lake) e offrendo un endpoint SQL di sola lettura per accedere a tali dati.
Esempi concreti: prendiamo un progetto analitico in cui vogliamo analizzare le vendite di un’azienda al dettaglio (retail). Nel data lake (lakehouse) saranno arrivati dati raw (Bronze) dalle casse dei negozi e dal sito e-commerce. Dopo una fase di pulizia e arricchimento (Silver), potremmo progettare il modello dati finale (Gold) come segue: creiamo una tabella fact Sales (fatto delle vendite) dove ogni riga rappresenta una singola transazione di vendita con riferimenti a varie dimensioni, e diverse tabelle dimension (dimensioni) ad esempio DimDate per le date, DimStore per i negozi, DimProduct per i prodotti, ciascuna con una chiave primaria surrogata (cioè una chiave artificiale, di solito numerica incrementale, che usiamo per collegarla alla fact) e tutti gli attributi descrittivi (la dimensione prodotto avrà nome prodotto, categoria, prezzo, ecc.). Questo modello a stella (una tabella di fatti centrale collegata a molte tabelle dimensionali) è il tipico star schema ottimizzato per le query analitiche: permette di fare aggregazioni e filtrare i dati in modo efficiente. Una volta create queste tabelle nel nostro lakehouse (in formato Delta sul layer Gold), possiamo generare delle viste o tabelle aggregate per i nostri KPI (Key Performance Indicators, indicatori chiave di performance), ad esempio una vista che calcola le vendite totali e margine per prodotto e mese.
Il bello del lakehouse è che queste tabelle sono su file (Delta), quindi ci manteniamo nei costi e flessibilità di un data lake, ma allo stesso tempo possiamo esporle attraverso un endpoint SQL come se fossero in un database relazionale tradizionale. Azure Synapse serverless, ad esempio, può fungere da endpoint di lettura: creiamo nel serverless SQL delle viste esterne sulle tabelle Delta e consentiamo agli utenti di interrogare con T-SQL. In Microsoft Fabric, addirittura, il Lakehouse ha un componente integrato chiamato SQL Endpoint che appare come un database, mediante il quale si può fare query con T-SQL ed ottenere risultati direttamente sui dati Delta.
Un altro vantaggio è l’integrazione con strumenti di BI come Power BI: con l’approccio lakehouse, è possibile collegare Power BI direttamente ai dati Delta del Gold layer. DirectLake è una funzionalità emergente (in Fabric) che consente a Power BI di leggere i dati dal lakehouse in modo diretto, bypassando i classici import o direct query e garantendo prestazioni elevate (caricando i dati in memoria in modo ottimizzato). Ciò significa che un report Power BI può riflettere i dati aggiornati nel lakehouse quasi in tempo reale, senza doversi appoggiare a un data warehouse separato.
Best practice e aspetti importanti: progettare un lakehouse richiede di tenere a mente sia le regole del data lake che quelle dei data warehouse. Ad esempio, è fondamentale tenere sotto controllo la complessità del modello: avere troppe tabelle e relazioni complicate può rendere difficile la comprensione e la manutenzione, quindi è bene semplificare dove possibile, magari denormalizzando leggermente quando non impatta negativamente. Le dimensioni dovrebbero essere ben normalizzate internamente per evitare ridondanze (ad esempio, separare la dimensione data dalla dimensione ora se necessario, piuttosto che avere tutte le informazioni di tempo replicate su ogni record di fatto). L’utilizzo di surrogate keys è raccomandato: queste sono chiavi surrogate, tipicamente interi, che fungono da chiavi primarie nelle dimensioni e vengono incluse nelle fact come chiavi esterne; ciò indipende dalle eventuali chiavi naturali (ad esempio il codice prodotto originale) rendendo il modello più robusto a cambiamenti dei sistemi sorgente. Inoltre, per gestire la storico delle dimensioni (ad esempio se il nome di un prodotto cambia nel tempo, oppure se un negozio cambia area di appartenenza), nei data warehouse si usano le tecniche di Slowly Changing Dimensions (SCD): anche in un lakehouse è bene applicare concetti simili, ad esempio mantenendo le versioni dei record nelle dimensioni con date di validità, così da poter analizzare i dati di vendita in relazione alla dimensione corretta per quel periodo storico.
Dal punto di vista della governance e affidabilità, ogni layer (Bronze, Silver, Gold) dovrebbe avere dei data contract e controlli di qualità. Significa definire chiaramente cosa ci si aspetta dai dati a quel livello (schema, qualità, regole di business) e far sì che ogni pipeline di trasformazione verifichi queste regole, magari producendo report di data quality. Strumenti come Azure Data Factory/Synapse Pipelines possono implementare step di controllo o usare servizi come Great Expectations o le regole stesse di Purview (di cui parleremo nel capitolo successivo) per assicurare che i dati passino gli standard attesi prima di promuoverli da un livello al successivo. È buona pratica inoltre documentare accuratamente campi e relazioni: poiché in un lakehouse gli utenti finali (analisti, data scientist) andranno a consumare i dati spesso direttamente, è fondamentale che capiscano il significato di ogni colonna, le unità di misura, le relazioni tra tabelle. Un catalogo dati o un glossario (come vedremo in Purview) può aiutare, ma anche commenti sui campi o documenti interni al team.
In sintesi, una Lakehouse architecture su Azure combina i benefici dei data lake e dei data warehouse. Per gli studenti che si avvicinano all’analisi dei dati, capire questo paradigma significa comprendere come progettare sistemi in cui la pipeline dei dati fornisce dati grezzi, puliti e poi modelli analitici, tutto all’interno dello stesso ambiente scalabile. Questo capitolo ha evidenziato l’importanza di strutturare i dati (medallion architecture, schema a stella) anche in un contesto di file system distribuito, per ottenere sia la flessibilità che la performance richiesta dall’analytics moderno.
5. Azure Stream Analytics: Elaborazione Dati in Tempo Reale
Nel mondo di oggi, molte applicazioni generano stream di dati continui: sensori IoT che inviano misurazioni ogni secondo, log di applicazioni che fluiscono costantemente, dati di trading finanziario in tempo reale e così via. Azure Stream Analytics (ASA) è il servizio PaaS di Azure progettato per gestire proprio questi flussi, permettendo di analizzare e reagire ai dati in tempo reale, senza dover allestire e gestire manualmente complessi cluster di streaming (come quelli basati su Spark Streaming o Flink).
Azure Stream Analytics funziona in modo che tu definisca una query di elaborazione continuativa, simile a una query SQL, che viene applicata agli eventi in ingresso. Questi eventi possono provenire da varie sorgenti di streaming, tipicamente: Azure IoT Hub (per scenari IoT, ingestione di dati da dispositivi), Azure Event Hubs (per stream generali, come logs applicativi, telemetrie, code di eventi) o anche Kafka (Azure offre un’interfaccia Kafka compatibile su Event Hubs, quindi ASA può leggere da endpoint Kafka). La query definita in ASA può fare filtri, aggregazioni, join e molto altro sui dati in volo, e mano a mano che produce risultati, li invia a uno o più output configurati – che possono essere servizi come Power BI (per visualizzare risultati in diretta su dashboard), Azure Data Lake Storage (per storicizzare i risultati su file), database SQL (per memorizzare eventi elaborati), Cosmos DB (per risultati a bassa latenza in un database NoSQL) e altri.
Il linguaggio di query di Stream Analytics è familiare per chi conosce SQL, ma con estensioni per gestire la natura temporale dei dati in streaming. Ad esempio, ASA introduce il concetto di finestra temporale (window) nelle query, per poter calcolare aggregazioni su finestre mobili o fisse di tempo. Ci sono diversi tipi di finestre supportate, come tumbling window, hopping window e sliding window. Una tumbling window è una finestra fissa che si sussegue senza sovrapposizioni (es: finestre da 1 minuto che partono ogni minuto esatto: 12:00-12:01, 12:01-12:02, ecc.); una hopping window è simile ma può sovrapporsi (es: una finestra di 5 minuti che inizia ogni minuto – quindi 12:00-12:05, poi 12:01-12:06, ecc., usata per medie mobili); una sliding window è definita dall’evento, in pratica l’aggregato su un intervallo relativo a ogni evento (ad esempio “per ogni evento, calcola la media dei 5 minuti precedenti a quell’evento”). Questi concetti permettono di esprimere logiche come "dimmi il numero di eventi negli ultimi 10 secondi aggiornato ogni secondo" o "se la temperatura media negli ultimi 5 minuti supera una soglia, genera un allarme".
Esempi pratici di ASA: un caso classico è il rilevamento di anomalie o soglie. Immaginiamo una catena del freddo con sensori di temperatura sui frigoriferi: i sensori inviano letture continuamente all’IoT Hub. Possiamo impostare una query ASA che per ogni sensore calcoli la temperatura media su una finestra mobile (ad esempio 5 minuti) e verifichi se supera una certa soglia. Se sì, la query può emettere un evento di allarme che viene inviato, ad esempio, a un dashboard Power BI in tempo reale e a un servizio di notifica (o un database che registra l’evento). In questo modo, se un frigorifero sta salendo di temperatura oltre il limite, nel giro di pochi secondi il sistema lo segnala e si può intervenire tempestivamente. Un altro esempio è l’arricchimento di stream con dati statici: supponiamo di ricevere ID di prodotto e quantità vendute in streaming da vari punti vendita. Da soli, questi ID non sono molto informativi, ma ASA consente di fare un join dello stream con dati di riferimento statici (ad esempio una tabella CSV di prodotti con nome e categoria). Possiamo caricare questa tabella di riferimento staticamente e la query ASA, man mano che arrivano gli eventi, può unire ogni evento con le informazioni del prodotto corrispondente, producendo in output uno stream già arricchito con nomi e categorie. Questo è potentissimo per evitare di dover fare post-elaborazioni: i risultati in streaming sono già completi.
Azure Stream Analytics offre inoltre funzioni geospaziali per lavorare con coordinate geografiche, dunque è possibile, ad esempio, rilevare se un oggetto entra o esce da una certa area geografica (funzionalità di geofencing) usando direttamente il linguaggio di query.
Dal punto di vista delle risorse, ASA introduce il concetto di Streaming Unit (SU), che rappresenta l’insieme di CPU e memoria allocato per eseguire le query. Più SU assegniamo al job ASA, più eventi al secondo può gestire e più complessa può essere la query. L’allocazione va dimensionata in base al throughput: durante lo sviluppo è comune partire con 1-3 SU e poi eventualmente aumentare quando il carico sale.
Buone pratiche per ASA: scrivere query di streaming richiede attenzione per garantire accuratezza e performance. Una prima linea guida è progettare query idempotenti ove possibile: ciò significa che se per qualche motivo un evento venisse elaborato due volte (cosa che in teoria non dovrebbe accadere in ASA in condizioni normali, ma potrebbe succedere in scenari di recovery), l’effetto finale non dovrebbe duplicare risultati. Un esempio è evitare di effettuare semplici conteggi cumulativi senza finestre, che accumulerebbero in caso di rielaborazione. In generale, l’uso appropriato delle finestre temporali aiuta a suddividere lo stream in porzioni maneggevoli e a ragionare su quelle. È importante gestire i dati in ritardo (late arrival): ASA ha impostazioni che definiscono un periodo di tolleranza per eventi che arrivano in ritardo rispetto alla loro timestamp (ad esempio un evento generato alle 10:00 che arriva solo alle 10:05 per latenza di rete). Possiamo specificare nelle query come comportarsi in questi casi (includerli comunque nella finestra, scartarli, ecc.). Bisogna anche gestire correttamente i fusi orari nelle analisi temporali, spesso convertendo i timestamp in UTC per coerenza. Inoltre, se le fonti di dati sono partizionate (ad esempio Event Hubs permette partizioni), è bene sfruttare in ASA la stessa chiave di partitioning per le query, così da garantire che gli eventi correlati vengano elaborati dallo stesso nodo e mantenere l’ordine locale quando serve.
Il monitoraggio è cruciale: Azure Stream Analytics offre metriche (visibili nell’Azure Monitor) come eventi al secondo in ingresso e in uscita, latenze di elaborazione, utilizzo di SU, ecc. Configurare degli alert su queste metriche può aiutare a scoprire se, ad esempio, il throughput sta saturando le risorse (indicando che potremmo dover aumentare le SU) o se il job è in errore. In produzione, per carichi molto elevati e scenari mission-critical, Azure offre anche la modalità di Azure Stream Analytics Cluster: un cluster dedicato esclusivamente ai tuoi job ASA, isolato, con capacità fissa su cui puoi distribuire più job. Questo permette di avere anche funzionalità avanzate come l’integrazione in una Virtual Network (VNet) per isolare la rete e l’uso di Private Link per connettere le fonti e destinazioni in modo privato, senza passare da endpoint pubblici – migliorando la sicurezza.
In conclusione, Azure Stream Analytics è uno strumento prezioso per costruire pipeline di real-time analytics senza doversi immergere nei dettagli complessi di piattaforme open source di streaming. Per uno studente, imparare ASA significa capire come esprimere logicamente in SQL-like delle operazioni su flussi di dati continui e imparare a ragionare in termini di temporali (cosa non banale inizialmente), il che è una competenza sempre più richiesta nell’analisi dati moderna.
6. Power BI: Modelli Semantici per l’Analisi Self-Service
Power BI è una piattaforma di Business Intelligence di Microsoft molto diffusa, nota per la sua capacità di creare visualizzazioni interattive e dashboard con facilità. Ma dietro la semplicità dell’interfaccia si cela un componente fondamentale per analisi efficaci: il modello semantico. In Power BI (e in generale nei servizi Analysis Services), il modello semantico è lo strato dove si definiscono le tabelle di dati, le relazioni tra di esse, le misure calcolate e altri oggetti come gerarchie e indicatori KPI. In questo capitolo esploreremo come funziona il modello di dati di Power BI e perché è così importante per un’analisi self-service di successo.
Quando importiamo dati in Power BI (ad esempio da Excel, da un database, da un data lake, etc.), questi vengono strutturati in una serie di tabelle all’interno del modello. Possiamo immaginare il modello come un piccolo database in memoria: le tabelle possono avere relazioni (join) tra loro, in genere relazioni uno-a-molti che connettono tabelle di dimensione (es: la tabella delle date, la tabella dei prodotti) alla tabella di fatto (es: le vendite). Questo è esattamente lo schema a stella di cui abbiamo parlato nel capitolo precedente, applicato all’interno di Power BI.
La differenza è che in Power BI il modello semantico non è solo uno schema dei dati, ma anche un livello dove si creano le misure (measures) e si definiscono le calcolazioni dinamiche mediante il linguaggio DAX (Data Analysis Expressions). Ad esempio, potremmo avere nel modello una misura chiamata Revenue che somma il campo delle vendite, e una misura Margin% che divide il margine per il ricavo, eventualmente con delle formule più complesse che rispettano filtri di contesto (DAX permette di definire calcoli che rispondono ai filtri applicati nelle visualizzazioni in modo intelligente, come “Year-to-Date”, valori rispetto all’anno precedente, etc.). Le gerarchie (ad esempio una gerarchia data -> mese -> trimestre -> anno) possono essere impostate nel modello per facilitare la navigazione drill-down nei grafici.
Power BI supporta diversi modi di importare i dati nel modello:
· Import mode (importazione): i dati vengono effettivamente importati e memorizzati nel file/report di Power BI (nel motore Vertipaq in memoria). Questo offre in genere le migliori prestazioni in query, perché i dati sono in-memory e compressi in modo ottimizzato, ma richiede di avere abbastanza memoria per contenerli e i dati possono diventare obsoleti se non vengono aggiornati regolarmente.
· DirectQuery: i dati rimangono alla fonte (per esempio nel database SQL aziendale) e Power BI al momento dell’interazione dell’utente manda query in tempo reale a quella fonte per ottenere i risultati. Questo garantisce dati sempre freschi e non richiede importazione, ma può essere più lento ad ogni azione e dipende molto dalle performance del sistema sottostante e dalla latenza di rete. Conviene usarlo su fonti che riescono a reggere carichi di query frequenti, su dataset relativamente ottimizzati.
· Composite model: è una combinazione delle due modalità precedenti. Permette ad esempio di importare alcune tabelle (magari quelle piccole o usate spessissimo) e tenerne altre in DirectQuery (magari quelle grandissime o con dati sensibili che non vogliamo duplicare). Il modello gestisce questa dualità, ma introduce una certa complessità.
· DirectLake: questa modalità è nuova e disponibile nell’ecosistema Fabric; consente a Power BI di accedere direttamente a dati su un lakehouse in formato delta senza passare per un dataset internal standard. Si potrebbe definire come un’evoluzione del DirectQuery ottimizzata per data lake, usando caching intelligente per avere performance vicine all’import. Per uno studente alle prime armi con Power BI, DirectLake potrebbe non essere immediatamente disponibile a meno che non si usi Fabric, ma vale la pena menzionarlo come direzione futura.
Indipendentemente dalla modalità, il semantic model in Power BI agisce come un singolo punto di verità per i calcoli. Un grande vantaggio di Power BI e in generale dei modelli analitici è che una volta definita una misura (esempio: Totale Vendite = somma della colonna importo nella tabella vendite) si può riutilizzare quella misura in tutti i grafici e analisi, e Power BI automaticamente la ricalcolerà in base ai filtri applicati (es: se metto un grafico con le vendite per regione, applicherà la somma su gruppi di regioni; se filtro per un anno, restringerà i dati all’anno corrente, e così via). Questo incoraggia la centralizzazione delle misure: conviene definire tutte le misure importanti nel modello una volta e lasciare che gli utenti creino i propri report partendo da quelle, così da avere coerenza (ad esempio “Margine Operativo” calcolato allo stesso modo in tutti i report).
Esempio pratico di costruzione di un modello in Power BI: immaginiamo di voler analizzare le vendite. Importiamo una tabella vendite (che contiene: data, codice prodotto, quantità, prezzo, ecc.), una tabella prodotti (codice prodotto, nome, categoria), e una tabella date (elenco di date con info come mese, trimestre, anno, festività, ecc.). Nel modello colleghiamo la tabella vendite con prodotti tramite il codice prodotto, e vendite con date tramite la data. Ora costruiamo qualche misura DAX: ad esempio Totale Vendite = SUM(Vendite[Prezzo] * Vendite[Quantità]) se i dati richiedono un calcolo del ricavo; oppure se c’è già un campo totale possiamo fare Totale Vendite = SUM(Vendite[Importo]). Creiamo Totale Quantità = SUM(Vendite[Quantità]). E magari Margine % = DIVIDE(SUM(Vendite[Margine]), SUM(Vendite[Importo])) supponendo di avere un campo margine. Possiamo anche aggiungere misure come Vendite YTD = TOTALYTD([Totale Vendite], 'Date'[Date]) per calcolare il cumulato da inizio anno, o altre metriche avanzate. Una volta creato questo modello, gli utenti possono trascinare “Totale Vendite” su un grafico a colonne per vedere le vendite, e farsi filtri per categoria prodotto (grazie alla relazione con la tabella Prodotti) e per anno (grazie alla tabella Date). In pratica hanno un’esperienza self-service perché non devono scrivere query SQL: il modello semantico risponde per loro in base alla selezione di filtri e visualizzazioni.
Best practice per i modelli Power BI: un modello ben fatto è cruciale per performance e manutenibilità. Un primo consiglio è dare nomi leggibili e significativi a tabelle, colonne e misure. Spesso quando si importa da fonti grezze ci si trova con nomi tecnici o codici; conviene rinominarli nel modello in qualcosa di comprensibile (es: prod_id diventa ID Prodotto, sales_amt diventa Importo Vendite, ecc.), soprattutto se il report sarà usato da persone non tecniche. Inoltre, colonne che non servono ai fini dell’analisi andrebbero nascoste: capita di importare tabelle da database con molti campi, ma magari al business interessano 10 colonne su 50; le altre possono essere nascoste nel modello così non creano confusione. Per ottimizzare le query, è importante impostare correttamente il direzionale dei filtri sulle relazioni (in Power BI di default è “single” cioè uno-molti unidirezionale, il che va bene nella maggior parte dei casi con schema a stella; la filtro bidirezionale va usato solo quando necessario per calcoli particolari come in presenza di tabelle di bridge).
Le misure DAX vanno scritte avendo cura di verificarne le prestazioni su volumi grandi: conviene usare strumenti come il Performance Analyzer integrato in Power BI Desktop per vedere se una visualizzazione impiega troppo tempo (sintomo che c’è una misura complessa da ottimizzare, o magari un problema di modellazione). Spesso il segreto è pre-aggregare dati se la granularità è troppo fine, oppure creare misure intermedie per semplificare calcoli annidati.
Un altro aspetto importante è la sicurezza a livello di riga (RLS): Power BI consente di definire ruoli per cui determinati utenti vedono solo un sottoinsieme dei dati (ad esempio, un responsabile di area geografica vede i dati solo della propria area). Implementare la RLS nel modello (tramite filtri sulle tabelle dimensione tipicamente) fa sì che un singolo report possa servire utenti diversi mostrando a ciascuno solo ciò che è autorizzato a vedere, molto utile in contesto aziendale.
Infine, quando l’organizzazione cresce, è utile promuovere i modelli fatti bene a modelli certificati o condivisi. In Power BI Service, si può pubblicare un dataset (modello) nel workspace e contrassegnarlo come certificato o promosso, in modo che altri analisti sappiano che è una fonte affidabile e lo possano riusare per nuovi report invece di ricreare da zero. Questo incarna un po’ il concetto di “unica versione della verità”: meglio avere un dataset vendite unico e ben curato, piuttosto che ogni team ne faccia uno proprio con possibili discrepanze.
In sintesi, Power BI e i suoi modelli semantici rappresentano la parte di presentazione e fruizione dei dati nel nostro ecosistema. Per uno studente, imparare a modellare dati in Power BI significa acquisire la capacità di trasformare tabelle grezze in informazioni strutturate pronte per l’analisi, imparando un linguaggio come DAX per calcoli avanzati e comprendendo come le scelte di modellazione impattano sull’efficienza e correttezza dei report creati.
7. Microsoft Purview: Catalogo Dati e Data Governance
Man mano che un’organizzazione accumula dati in vari sistemi (data lake, database, report, ecc.), diventa sempre più importante sapere che dati si hanno, dove si trovano, chi li possiede, e come sono definiti. Entra in gioco la data governance, ovvero l’insieme di processi e strumenti che assicurano la gestione controllata e di qualità del patrimonio informativo. Microsoft Purview è il servizio Azure progettato per data governance, che offre un catalogo unificato degli asset dati e potenti funzioni di classificazione, ricerca e controllo.
Il cuore di Purview è il Data Catalog: esso consente di registrare e consultare tutti gli “asset” dati dell’azienda. Un asset può essere una tabella in un database, un file in un data lake, un report di Power BI, e molto altro. Ciò è possibile grazie al Data Map, un componente che effettua scansioni (scans) sulle fonti dati e raccoglie i metadati (nomi tabelle, colonne, tipologia di dati, posizioni, lineage cioè tracciamento delle origini dei dati, etc.). Purview può connettersi a una vasta gamma di fonti (Azure SQL, Azure Data Lake, Azure Synapse, Salesforce, Amazon S3, ecc.) per estrarre queste informazioni. Ad esempio, potremmo configurare Purview per scandire il nostro Azure Data Lake Storage e tutte le istanze di database Azure che abbiamo: automaticamente creerà voci nel catalogo per ogni file e tabella trovati, registrandone schema, percorso e anche statistiche come il volume di dati.
Una volta popolato il catalogo, gli utenti (tipicamente data engineers, data stewards, analisti) possono cercare i dati in Purview come farebbero con un motore di ricerca. Ad esempio, potrebbero cercare “cliente” e trovare tutte le tabelle nei vari database che hanno a che fare con i clienti. Ogni asset nel catalogo può essere arricchito con metadati descrittivi: c’è la possibilità di associare termini di glossario, note, e indicare chi è l’owner (proprietario responsabile) di quel dato. Il Business Glossary di Purview è un glossario aziendale dove i termini di business (es: "Ordine", "Cliente Attivo", "Spesa IT") vengono definiti formalmente e possono essere collegati agli asset dati per chiarire di cosa si tratta. Questo aiuta a risolvere ambiguità: se ho una tabella cust_id e la collego al termine di glossario “Cliente”, tutti sapranno che quella colonna rappresenta il cliente secondo la definizione standard condivisa.
Oltre al catalogo, Purview introduce il concetto di domini di governance e data products. Un governance domain è un raggruppamento logico di risorse e regole, spesso allineato con la struttura organizzativa o con aree tematiche (es: un dominio “Finanza”, un dominio “Risorse Umane”). Ciò consente di delegare alle singole unità (domini) la responsabilità sui propri dati, pur mantenendo alcune regole globali definite dal team di governance centrale. Questo approccio segue il principio della governance federata: alcune policy e linee guida sono comuni (ad es. classificazione dei dati sensibili, conformità GDPR), ma la gestione di dettaglio è in mano ai domini, che hanno conoscenza più diretta dei loro dati.
Un data product in Purview è un concetto che raggruppa vari asset dati (potenzialmente di diverso tipo) che insieme forniscono valore per un certo scopo o caso d’uso. È un po’ come creare un pacchetto di dati utile a un particolare scenario. Ad esempio, l’azienda potrebbe creare un data product chiamato “Vendite Retail” in cui inserisce alcune tabelle gold dal data lake relative alle vendite nei negozi, più alcuni report Power BI collegati, più magari il dataset in Power BI, definendo chiaramente chi è il responsabile di questo prodotto (owner), quali policy di accesso si applicano, e garantendo che sia documentato. L’idea è ispirata agli approcci di Data Mesh, dove si incoraggia la condivisione di dati come prodotti riutilizzabili.
Esempi pratici di Purview: un caso d’uso tipico è la mappatura degli asset per la conformità e la scoperta. Ad esempio, l’azienda vuole essere conforme al GDPR e assicurarsi di sapere dove risiedono i dati personali. Configurando Purview, può fare una scansione di tutti i database e data lake e usare le classificazioni automatiche: Purview ha una libreria di riconoscimento di tipi di dati sensibili (numeri di carta di credito, email, indirizzi, codici fiscali, etc.) e può taggare automaticamente le colonne che sembrano contenere quei dati. Successivamente, tramite il catalogo, i compliance officer possono cercare “email” e vedere tutte le colonne o file che contengono indirizzi email personali, per assicurarsi che siano protetti adeguatamente. Un altro esempio è la costruzione di un glossario centralizzato: supponiamo che da anni i reparti usino termini come “cliente attivo” con definizioni leggermente differenti tra marketing e supporto. Usando Purview, il team di governance può definire ufficialmente “Cliente Attivo” nel glossario (es: “Cliente con almeno un acquisto negli ultimi 12 mesi”) e collegare al glossario tutte le tabelle/colonne nei vari sistemi che rappresentano i clienti attivi. Così, chiunque apra un dataset su clienti in Purview vedrà collegato il termine e la sua definizione, chiarendo eventuali dubbi. Ancora, come accennato, si può creare un data product: ad esempio il team dei dati di Vendite crea il prodotto “Vendite Retail Q3 2025” dove aggrega i dataset di vendite, anagrafiche prodotti, e report standard sul quarter, e lo rende disponibile ai manager di business attraverso Purview (che mostra i dettagli, i contatti di chi l’ha prodotto, e magari lo stato qualitativo di quei dati).
Purview include anche funzionalità per valutare e seguire la data quality: attraverso integrazioni (ad esempio con Azure Data Factory o altri strumenti) si possono catturare informazioni sulle regole di qualità applicate e sui punteggi di qualità ottenuti per ogni dataset (es: percentuale di valori nulli, aderenza al formato previsto, etc.). Purview può mostrare tali metriche e dare un rating ai dataset in base alla loro qualità. Questo è utilissimo per capire se un certo data product è affidabile oppure se ha problemi in certe colonne.
Best practice di data governance con Purview: implementare uno strumento come Purview è efficace solo se accompagnato da processi e ruoli organizzativi chiari. Un suggerimento è adottare un approccio di governance federata: cioè nominare dei data steward all’interno di ogni dominio aziendale, i quali saranno responsabili di curare i metadati e la qualità dei dati del proprio dominio in Purview. Nel frattempo, un piccolo team centrale di governance definisce gli standard (ad esempio quali classificazioni usare, quali termini di glossario creare, come valutare la qualità). In questo modo Purview non diventa un catalogo “statico”, ma una risorsa viva mantenuta nel tempo. Documentare termini e definizioni è un altro punto cruciale: il glossario dovrebbe essere popolato e aggiornato con il contributo delle unità business, e idealmente integrato con la formazione interna in modo che tutti usino Purview come riferimento. Dal lato accessi, Purview stesso non gestisce i permessi di accesso ai dati (non è un firewall), ma traccia le policy di accesso: conviene registrare in Purview quali policy o controlli di accesso (ad esempio mascheramento dei dati sensibili) sono attivi su ciascuna fonte, così da avere un quadro completo.
Infine, l’integrazione con altri strumenti Microsoft aiuta ad avere un ecosistema coeso: Purview può collegarsi con Microsoft Priva o Compliance Manager per la parte di conformità (ad es. spingendo l’inventario di dati personali verso questi strumenti per valutare il rischio privacy), e con Azure Data Factory per spingere lineage (tracciamento dei dati dalle fonti agli output). Monitorare metadati e qualità attraverso Purview significa anche attivare notifiche o dashboard interni sui trend (es: quante asset scansionati, quanti aumentati nell’ultimo mese, quanti con problemi di qualità).
In poche parole, Microsoft Purview fornisce l’infrastruttura per “dare un senso” al patrimonio di dati di un’azienda. Per uno studente, capire Purview significa avvicinarsi alla dimensione della governance, spesso trascurata rispetto alla tecnologia ma vitale: i dati hanno valore solo se sappiamo trovarli, capirli e fidarci di essi, e strumenti come Purview sono lì per garantire proprio questo.
8. Mapping Data Flows: Trasformazioni Visive Scalabili
Nel capitolo su Azure Data Factory abbiamo accennato ai Mapping Data Flow come una delle attività disponibili per trasformare dati su larga scala. Approfondiamo ora cosa sono e come funzionano. I Mapping Data Flow (d’ora in avanti MDF) in Azure Data Factory e in Synapse Pipelines offrono un approccio visuale e dichiarativo per costruire trasformazioni dati complesse, eseguite su cluster Spark gestiti dietro le quinte. In poche parole, permettono di creare, tramite interfaccia grafica, flussi di trasformazione (diagrammi) composti da sorgenti di dati, una serie di passaggi di trasformazione, e dei sink (destinazioni), il tutto senza scrivere codice, ma ottenendo performance da big data.
Un MDF si presenta come un canvas dove possiamo trascinare componenti. Si inizia definendo una Source (ad esempio un file Parquet nel data lake, una tabella in SQL, ecc.), poi si aggiungono trasformazioni come Filter (per filtrare righe in base a condizioni), Select/Derived Column (per selezionare colonne o crearne di derivate da espressioni), Aggregate (per aggregazioni tipo somma, media, conteggi su gruppi), Join (per unire due flussi di dati in base a chiavi comuni), Sort o Alter Row, Union, Lookup (simile ad un join con dataset di riferimento), e infine definire un Sink dove scrivere i risultati (può essere anch’esso vari tipi di destinazione: file CSV/Parquet/Delta sul data lake, tabella SQL, ecc.). Ogni trasformazione è configurabile con condizioni ed espressioni, e Azure genera automaticamente sotto il cofano il codice Spark necessario.
La potenza dei Mapping Data Flow sta nell’unire la semplicità visuale con la scalabilità di Spark. Non si deve pensare alla gestione del cluster: quando un data flow viene eseguito come parte di una pipeline ADF/Synapse, dietro le quinte Azure avvia (o riutilizza) un cluster Spark ottimizzato per Data Flow noto come Azure Integration Runtime in modalità Data Flow, e traduce le trasformazioni configurate in job Spark in linguaggio Scala. Questo significa che potenzialmente si può elaborare un file da 100 milioni di righe con join e aggregazioni semplicemente disegnando il flusso, e Azure lo eseguirà distribuendo il carico su più nodi. Durante lo sviluppo, c’è anche la possibilità di usare un Debug mode con un cluster di debug attivo, che permette di vedere anteprime dei dati a ogni passaggio per verificare che le trasformazioni facciano ciò che ci si aspetta.
Esempi di cosa si può fare con Mapping Data Flows: immaginiamo di avere un dataset di transazioni finanziarie in cui i campi importo a volte sono scritti con la virgola decimale, a volte col punto, e alcuni record hanno valori nulli o formattazioni strane per la data. Possiamo creare un data flow che prenda questi dati grezzi, li passi attraverso una trasformazione di standardizzazione (ad esempio usando espressioni per rimuovere simboli non numerici dagli importi e convertirli a numero, e trasformare le date nel formato ISO standard), poi applicare un filtro per scartare le transazioni il cui importo risulta zero o non valido. Successivamente potremmo fare un lookup su una tabella di riferimento con i tassi di cambio per aggiungere, per ogni transazione internazionale, il corrispondente importo in valuta locale. Potremmo anche voler identificare duplicati: aggiungendo un passaggio di aggregazione che conta quante volte appare lo stesso ID transazione e poi un filtro per isolare quelli con conteggio > 1, scrivendoli magari in un sink di eccezioni (un file di log degli errori). Tutto questo flusso si disegna e configura facilmente, e il risultato potrebbe essere uno stage arricchito e pulito delle transazioni pronto per essere caricato nel livello Silver/Gold del data lake.
Un altro esempio: supponiamo di dover unire e trasformare dati da due fonti: un file CSV di clienti e un file JSON di ordini, per produrre un output combinato di analisi. In un data flow si può inserire due sorgenti (clienti, ordini), fare eventuali trasformazioni individuali (es: selezionare solo alcune colonne, calcolare colonne derivate come “anno dell’ordine” o “cliente VIP sì/no” in base a criteri), poi fare un join tra i due flussi sul customerID per associare le informazioni cliente ad ogni ordine, e infine scrivere il risultato in un nuovo file Parquet pronto all’uso. Nel processo potremmo aggiungere un calcolo di aggregazione per sommare il totale ordini per cliente e magari segnare quelli sopra una certa soglia come “top client”.
Una cosa utile dei MDF è che includono meccanismi per gestire gli errori: ad esempio c’è la possibilità di impostare nei sink la destinazione di righe che falliscono la scrittura (i cosiddetti reject row, come se fosse un output secondario per gli errori, spesso usato per tenere traccia di dati che non hanno passato certe regole di qualità). Questo consente di costruire pipeline robuste: invece di bloccarsi in caso di dati sporchi, possiamo isolare quegli specifici record in un log, e far completare comunque la pipeline con tutto il resto dei dati corretti.
Monitoraggio e ottimizzazione: quando si esegue un Mapping Data Flow, Azure offre un dettaglio di monitoraggio molto interessante: l’execution plan del data flow. È possibile vedere una rappresentazione grafica delle fasi di esecuzione (stages) con informazioni sui tempi spesi e sul numero di record elaborati in ogni stadio. Questo è utile per capire viste le prestazioni dove la pipeline spende più tempo: ad esempio potremmo notare che il join impiega molto tempo rispetto ad altre operazioni, e scoprire magari che è dovuto al fatto che la distribuzione dei dati è sbilanciata (skew) su una certa chiave. Per aiutare in questi casi, i data flow offrono opzioni di tuning: ad esempio il broadcast join può essere abilitato quando una delle due tabelle è piccola – in questo modo quella tabella verrà inviata (broadcast) a tutti i nodi, rendendo il join più efficiente (i piccoli dati sono replicati e i grandi non devono essere risuddivisi pesantemente). Oppure si può impostare manualmente la chiave di partizionamento prima di un join o un aggregation, in modo da controllare come i dati vengono distribuiti sui cluster (questo è utile se si sa che un certo campo è meglio bilanciato di un altro). L’Integration Runtime su cui girano i data flow può avere un TTL (Time to Live) come già accennato, il che riduce i tempi di avvio se eseguiamo più data flow ravvicinati: in pratica il cluster Spark resta caldo e pronto per un certo tempo.
Buone pratiche per i Mapping Data Flow: innanzitutto, se l’obiettivo è la performance, è consigliabile usare formati efficienti come Parquet o Delta per input e output (rispetto a CSV non compresso, Parquet consente lettura/scrittura molto più rapide e compressione sullo storage). Monitorare attentamente le quattro fasi critiche di un data flow è utile: in generale possiamo pensare che le fasi sono l’avvio del cluster, la lettura dei dati dalle fonti, l’elaborazione delle trasformazioni, e la scrittura sui sink. Ognuna di queste può diventare un collo di bottiglia a seconda del caso (per esempio, se i dati sorgente sono su un sistema lento a rispondere, la fase di reading sarà il limite; se la trasformazione è molto complessa o con skew, sarà la fase di calcolo; se il sink ha latenza, scrivere può accumulare ritardi). Avere visibilità su questi stadi permette di individuare dove ottimizzare. Evitare ordinamenti (sort) non necessari: l’ordinamento globale dei dati è un’operazione costosa in ambienti distribuiti, quindi a meno che davvero serva (ad esempio quando si vuole un output ordinato per un motivo specifico), è meglio evitarlo; spesso le aggregazioni o i join non richiedono un ordinamento globale, e se serve ordinare per definire rank o simili esistono funzioni analitiche che possono essere alternative più economiche. Sfruttare il source partitioning: se la fonte supporta la lettura parallelizzata (ad esempio un database con partizioni, o un insieme di file su più cartelle), configurare la sorgente per leggere in parallelo su più partizioni può ridurre i tempi di lettura. All’opposto, limitare il logging a ciò che serve: il debug mode con eccessiva log detail aiuta a capire cosa succede, ma una volta in produzione conviene tenere log solo essenziali, perché scrivere log per ogni record processato (per esempio) rallenterebbe enormemente. Infine, se un data flow sta diventando molto complesso e difficile da mantenere, considerare di isolare trasformazioni pesanti: è possibile spezzare un flusso in due, scrivendo un output intermedio, per poi leggerlo e continuare con le restanti trasformazioni. Questo può aiutare anche a rieseguire solo una parte in caso di errori o a parallellizzare i flussi.
Per i principianti, i Mapping Data Flow rappresentano un modo intuitivo di avvicinarsi ai concetti di ETL/ELT su big data: si può imparare cosa fa un join, un’aggregazione, una trasformazione di dati vedendolo visivamente, e nel contempo capire che dietro c’è un motore come Spark che esegue il lavoro. È un ottimo punto di incontro tra il mondo no-code/low-code e il mondo big data engineering.
9. Sicurezza dei Dati Analitici in Azure
Quando si costruiscono soluzioni dati in Azure, dagli ingest di Data Factory alle analisi di Synapse fino ai dashboard Power BI, bisogna considerare con attenzione la sicurezza e la compliance. Azure fornisce una serie di controlli nativi per proteggere i dati analitici, assicurarsi che solo le persone/servizi autorizzati possano accedere a certe informazioni e che si rispettino normative e best practice di sicurezza. In questo capitolo esamineremo alcuni degli strumenti e approcci principali per mettere in sicurezza un’architettura di dati su Azure, con un occhio ai servizi specifici di cui abbiamo parlato nei capitoli precedenti.
Sicurezza a riposo e in transito: per prima cosa, Azure di default protegge i dati at-rest (a riposo, cioè salvati su disco) tramite crittografia. Servizi come ADLS Gen2, Azure SQL, Azure Synapse, hanno la crittografia automatica dei dati sul disco (usando chiavi gestite da Microsoft, con l’opzione di fornirne di proprie). Quindi i file e i database sono cifrati, e se qualcuno ottenesse fisicamente i dischi non potrebbe leggerli senza la chiave. Analogamente, la comunicazione in-transit (in movimento) verso questi servizi avviene tipicamente su protocolli cifrati SSL/TLS (HTTPS per lo storage, etc.), assicurando che intercettare il traffico di rete non riveli dati in chiaro. Questi meccanismi sono spesso trasparenti per l’utente – è bene solo verificare che vengano lasciati attivi (Azure consente di disabilitare la crittografia in alcuni casi per retrocompatibilità, ma normalmente non c’è motivo di farlo).
Controllo degli accessi (identità e rete): Azure implementa il classico modello RBAC (Role-Based Access Control) su praticamente ogni servizio: si tratta di assegnare a identità (utenti, gruppi, o identità applicative come Managed Identity, Service Principal) dei ruoli predefiniti oppure custom che determinano cosa possono fare su una risorsa. Ad esempio, sul Data Lake possiamo dare a un certo gruppo il ruolo “Data Reader” in sola lettura, e a un servizio ETL un ruolo “Data Contributor” per leggere e scrivere; su un workspace Synapse possiamo dare a un data scientist i permessi per eseguire notebook ma non per pubblicare pipeline, e così via. È fondamentale applicare il principio del least privilege: dare all’utente/servizio il minimo livello di accesso necessario per la sua funzione, e niente di più. Questo limita i danni in caso di credenziali compromesse o errori umani.
Oltre all’identità, Azure consente di controllare l’accesso ai servizi anche via networking. Servizi come Azure Storage, SQL, Synapse offrono firewall e Virtual Network integration: possiamo decidere che un certo storage account è accessibile solo da indirizzi IP specifici (whitelist IP) o solo da dentro una certa VNet (Virtual Network) aziendale. Inoltre, con Private Endpoint possiamo far sì che un servizio Azure (ad esempio un account di storage) abbia un indirizzo IP privato all’interno della rete aziendale, eliminando l’esposizione sul pubblico internet. Così facendo, anche se l’autenticazione fallisse, un attaccante esterno non potrebbe nemmeno raggiungere l’endpoint del servizio se non è all’interno della rete autorizzata. Nel contesto dei dati, è comune isolare ad esempio il Data Lake dentro una VNet e permettere l’accesso solo ai servizi dati (Synapse, adf) che sono anch’essi integrati nella VNet tramite Managed VNet o ablità analoghe.
Defender for Cloud e compliance: Microsoft offre un servizio chiamato Defender for Cloud (un tempo Azure Security Center) che aiuta a monitorare e rafforzare la sicurezza delle risorse Azure. Per il mondo dati, Defender for Cloud può fare una valutazione continua dei nostri setup rispetto a scaffolding di best practice e standard di sicurezza. Ad esempio, c’è un set di controlli di sicurezza raccomandati nel Microsoft Cloud Security Benchmark (MCSB) che include regole come “Storage account should have private endpoints or service endpoints” oppure “Key Vault should have soft-delete enabled”, etc. Defender confronta la nostra configurazione con queste regole e segnala quelle in cui non siamo conformi, suggerendo rimedi (per esempio: “abilita il firewall su questo servizio”, “forza MFA su questo account”, ecc.). Inoltre, c’è un modulo di Regulatory Compliance dove possiamo selezionare vari standard come ISO/IEC 27001, GDPR, NIST e vedere una mappatura di quanto la nostra infrastruttura aderisce a quei controlli. Per esempio, per GDPR potrebbe esserci un controllo che richiede la crittografia dei dati personali: Defender mostrerà se tutti i database con dati personali sono effettivamente crittografati o se ce n’è qualcuno non conforme.
Un concetto importante di compliance in Azure sono le Azure Policy: regole che possono essere impostate a livello di subscription o resource group per impedire o segnalare configurazioni non volute (ad esempio, impedire la creazione di risorse in region non approvate, o richiedere che tutti i container di storage abbiano il logging attivo). Spesso, pacchetti di policy vengono raggruppati in Initiative per coprire un intero standard (il pacchetto di policy per il CIS benchmark, per PCI DSS, ecc.). Attivando queste iniziative su una subscription, si attiva di fatto un controllo continuo: qualsiasi risorsa che viola una policy appare come non compliant e può anche far parte di un report di conformità.
Esempi pratici di misure di sicurezza applicate: immaginiamo di voler mettere in sicurezza un progetto di data analytics con un data lake e Synapse. Un possibile approccio: creare un’Azure Virtual Network dedicata ai servizi dati, inserire il workspace Synapse e l’istanza di Azure Data Factory in modalità Managed VNet, e configurare Private Endpoints per lo Storage account e per il SQL dedicato di Synapse. Così tutti i componenti comunicano su rete privata. Abilitare l’Azure Defender su queste risorse farà sì che se qualcuno, ad esempio, disabilita il firewall o lascia un datastore aperto, arrivi un warning. Inoltre, possiamo utilizzare Managed Identities per i servizi: Azure Data Factory e Synapse hanno identità gestite che possiamo autorizzare al Data Lake (invece di usare chiavi di account), migliorando la sicurezza delle credenziali. Le credenziali specifiche (come stringhe di connessione a database esterni) le mettiamo in Azure Key Vault e di nuovo diamo solo al Data Factory accesso a quelle chiavi.
Un aspetto spesso trascurato è l’audit trail: assicurarsi che i log di accesso e utilizzo siano conservati. Azure permette, ad esempio, di abilitare diagnostica e log per quasi tutti i servizi (es: log delle letture/scritture sul data lake, log delle query eseguite su Synapse, log di chi pubblica pipeline, etc.) e inviarli a un Log Analytics Workspace o ad un Event Hub per analisi successive. In questo modo, se c’è un incidente di sicurezza, si può risalire a chi ha fatto cosa.
Principali best practice riassunte:
· Implementare least privilege sistematicamente: revisione periodica degli accessi, rimuovere utenti non più necessari, usare gruppi per assegnare ruoli (anziché dare permessi a singoli individui, così se qualcuno cambia ruolo, basta toglierlo dal gruppo).
· Proteggere i dati in movimento e a riposo: mantenere abilitata la crittografia predefinita di Azure (di solito non c’è da fare nulla, è by default) e se richiesto da policy interne, usare Customer Managed Keys (ad esempio portando una chiave in Key Vault per crittografare i dati invece di quella gestita da MS, per poter fare key rotation).
· Isolare la rete dove possibile: preferire Private Link e VNet Service Endpoints per le connessioni tra servizi (così i nostri dati, ad esempio da ADF a Storage, non passano mai per IP pubblici). Se si usano macchine virtuali o container per elaborazioni custom, metterli nella stessa VNet per poter raggiungere i servizi privati.
· Attivare Defender for Cloud e le sue policy: correggere attivamente le raccomandazioni. Ad esempio, se ci dice che un certo storage non ha il logging attivo o un certo SQL non forza la cifratura TLS, intervenire subito.
· Automatizzare la remediation dove possibile: Azure Policy consente in alcuni casi di non solo rilevare ma anche correggere (es: se qualcuno crea uno storage senza crittografia, la policy può automaticamente attivarla). Questo toglie spazio all’errore umano.
· Mantenere un occhio sull’Azure Monitor e costituire dashboard di sicurezza e compliance: ad esempio centralizzare la percentuale di compliance agli standard nel tempo e cercare di raggiungere il 100%.
In sintesi, la sicurezza dei dati in Azure è ottenuta tramite una stratificazione di difese: dall’identità (chi sei) alla rete (da dove ti connetti) ai dati stessi (cifratura, controllo accessi alle colonne, etc.), fino al monitoraggio continuo (Detect & Respond). Uno studente dovrebbe cogliere che in parallelo agli aspetti funzionali (come trasporto e analisi dei dati) ci dev’essere sempre un’attenzione a questi aspetti di protezione e conformità, perché sono parte integrante di qualsiasi progetto in produzione.
10. Monitoraggio e Gestione dei Costi in Azure
L’ultimo tassello di cui parliamo riguarda la osservabilità delle soluzioni e la gestione dei costi nel cloud. Azure fornisce strumenti integrati per controllare sia lo stato di salute delle applicazioni (monitoraggio di performance, errori, utilizzo) sia l’andamento della spesa per evitare sorprese in bolletta. In contesti di analisi dati dove si possono avere molti servizi diversi (pipeline, database, cluster, storage, ecc.), è essenziale avere sotto controllo questi due aspetti per mantenere le soluzioni affidabili e sostenibili economicamente.
Azure Monitor è il servizio ombrello che copre il monitoraggio end-to-end in Azure. Comprende la raccolta di metriche (valori numerici campionati nel tempo, come utilizzo CPU, memoria, I/O, latenze, conteggi di richieste, etc.) e di log (eventi e tracce dettagliate, come messaggi di errore, esecuzione di specifici step, output di debug). Attraverso Azure Monitor, si possono impostare Allerte su metriche o log per ricevere notifiche o eseguire azioni automatiche al verificarsi di certe condizioni (esempio: se l’utilizzo CPU di un cluster Spark rimane sopra l’80% per più di 10 minuti, invia un’email o scala il cluster; oppure se una pipeline di ADF fallisce, manda un SMS al reperibile).
Una componente fondamentale di Azure Monitor per analizzare i log è Log Analytics: un workspace in cui è possibile inviare e conservare log provenienti da varie fonti (servizi Azure, ma anche agenti su macchine on-premises, applicazioni custom, etc.) e interrogarli con un linguaggio potente chiamato KQL (Kusto Query Language). Ad esempio, i log delle esecuzioni di pipeline ADF o Synapse, i log delle query di Synapse SQL, e metriche personalizzate possono finire in Log Analytics e l’utente può scrivere query per aggregarli, visualizzarli, identificare trend o anomalie.
Per quanto riguarda la gestione dei costi, Azure offre Cost Management + Billing: un portale e set di API/alert per monitorare la spesa cloud. In contesti aziendali grandi, le risorse Azure sono spesso suddivise per scope di costi: ad esempio per subscription, per resource group, o tag. È possibile definire budget mensili/trimestrali per uno scope (ad esempio: “spesa massima per la subscription DataProject = 5000€ al mese”) e poi ricevere avvisi man mano che ci si avvicina al limite. Azure Cost Management offre report e breakdown: possiamo vedere quanto stiamo spendendo in totale e per servizio (es: 30% su VM, 20% su Database, 10% su Data Factory, ecc.), e individuare le risorse più costose.
È importante capire il modello di costo dei servizi di cui abbiamo parlato. Ad esempio, Azure Data Factory costa in base alle pipeline eseguite e ai Data Flow cluster attivati (quindi, pay-per-use), Synapse dedicato costa per ora di istanza attiva (che sia usata o no), Synapse serverless costa per TB di dati letti dalle query, Spark pool costa per durata e dimensione del cluster; ADLS costa in base ai GB memorizzati e operazioni effettuate; Power BI ha un licensing diverso (pro user o per capacità), etc. Conoscere questi modelli aiuta a usare le risorse in modo efficiente.
Esempi di monitoraggio e ottimizzazione costi: immagina di avere un pipeline ETL nightly che deve finire entro le 6 del mattino. Puoi impostare su Azure Monitor un alert che si attiva se la pipeline non è completata entro un certo orario (usando i log di ADF) per avvisare il team. Oppure puoi monitorare la latenza media delle query del tuo endpoint Synapse: se vedi un trend in crescita, potresti scoprire col monitoraggio che negli ultimi giorni un particolare job Spark sta caricando molto il cluster e decidere di aumentare i nodi o ottimizzarne il codice.
Dal lato costi, un esempio pratico: supponiamo che il team abbia dimenticato un cluster Spark di Synapse acceso durante il weekend. Cost Management mostrerà un aumento anomalo per il servizio Synapse. Inoltre, grazie ai budget alert, se definito un budget, potresti ricevere un avviso “Hai raggiunto il 80% del tuo budget per questo periodo” che fa scattare un’indagine, portando a trovare il cluster non spento. Un altro esempio è l’ottimizzazione dell’ingestione di log: Azure Monitor addebita un costo per ogni GB di log ingerito e per la loro retention. Se stiamo raccogliendo troppi log dettagliati (magari debug molto verbosi da applicazioni) potremmo vedere la voce “Log Data Ingestion” molto alta nei costi. Con un’analisi, possiamo decidere di abbassare il livello di logging o impostare delle regole di campionamento (col filtraggio, Azure Monitor può ingoiare solo X% di certi log per ridurre il volume) o ridurre il tempo di mantenimento dei log (se non ci servono log di 3 anni fa, potremmo tenere solo 30 giorni di storia, abbassando i costi).
Strumenti di ottimizzazione: Azure Advisor e specificamente la sezione Cost Recommendations forniscono suggerimenti come “Hai questi 10 database sottoutilizzati, potresti ridimensionarli per risparmiare X al mese” oppure “Se converti questo pagamento in una Reserved Instance per 1 anno risparmi Y%”. Le Reserved Instances e i Savings Plan sono meccanismi di Azure per ottimizzare i costi impegnandosi a un uso constante: ad esempio, se sai che terrai un Synapse dedicato attivo per molti mesi, puoi riservarlo per 1 o 3 anni a un prezzo scontato rispetto al pay-as-you-go. Anche acquistare capacità riservata per Data Factory o altri servizi può dare sconti se hai utilizzi certi di un certo ammontare.
Best practice finale sulla gestione operativa: taggare tutte le risorse con etichette come progetto, ambiente, owner è estremamente utile sia per capire chi/quale reparto consuma, sia per filtrare i cost report (posso sommare costi di tutte le risorse taggate come env:production). Creare dashboard di monitoraggio che includono sia indicatori tecnici (performance, throughput) sia indicatori di costo dà una vista unificata del “benessere” del sistema. Ad esempio, un dashboard potrebbe mostrare: numero di esecuzioni pipeline successo/fallite, utilizzo medio CPU dei cluster, quantità di dati processati giornaliera, spesa cumulativa mese corrente vs budget, ecc. Questo aiuta i team a essere proattivi.
In conclusione, dopo aver costruito una soluzione dati, il lavoro non è finito: occorre osservarla e controllarla nel tempo. Azure fornisce gli strumenti per farlo, ma vanno configurati e usati con costanza. Per un nuovo studente, può sembrare secondario rispetto a “far funzionare la pipeline di analisi”, ma nella realtà professionale, monitoraggio e cost management sono ciò che distingue un progetto di successo nel lungo periodo da uno che crea incidenti o sforamenti di budget. Imparare a usare Azure Monitor e Cost Management è quindi parte integrante delle competenze di un buon data engineer o cloud solution architect.
Conclusioni
Azure Data Factory rappresenta quindi la chiusura perfetta di un percorso che ci ha mostrato quanto sia strategico disporre di uno strumento capace di orchestrare flussi di dati complessi in modo semplice, sicuro e scalabile. La possibilità di creare pipeline automatizzate che gestiscono ingestione, trasformazione e pubblicazione dei dati senza intervento manuale consente alle organizzazioni di ridurre errori, accelerare i processi e garantire coerenza operativa. L’approccio serverless elimina il peso dell’infrastruttura, mentre la flessibilità offerta da trigger, parametri e attività di controllo permette di adattare le soluzioni a scenari diversi e di riutilizzarle con facilità. L’integrazione con servizi come Azure Key Vault e l’uso di identità gestite rafforzano la sicurezza, mentre il monitoraggio avanzato consente di ottimizzare le performance e individuare colli di bottiglia. In un contesto in cui i dati sono il cuore delle decisioni, ADF diventa il punto di partenza per architetture evolute che includono data lake, lakehouse e strumenti di analisi come Synapse e Power BI, creando un ecosistema coerente e orientato alla governance. Le best practice discusse, dalla modularità alla gestione sicura delle connessioni, rappresentano la base per implementazioni solide e conformi agli standard enterprise. In definitiva, padroneggiare Azure Data Factory significa acquisire una competenza chiave per progettare soluzioni di integrazione dati moderne, capaci di supportare analisi avanzate, machine learning e processi decisionali data-driven, trasformando la complessità in efficienza e aprendo la strada a un’infrastruttura intelligente e pronta per il futuro.
Riepilogo capitolo
Il documento descrive diverse tecnologie e pratiche per l'elaborazione, modellazione, sicurezza, monitoraggio e gestione dei costi nell'ecosistema dati di Azure, con particolare attenzione a strumenti come Azure Data Factory, Synapse Analytics, Power BI e Azure Stream Analytics.
· Potenza dei Mapping Data Flow: I Mapping Data Flow combinano semplicità visiva e scalabilità di Spark, eseguendo trasformazioni distribuite su cluster Spark gestiti automaticamente da Azure Integration Runtime, con modalità di debug per anteprime dati durante lo sviluppo.
· Modellazione dati in Power BI: Power BI permette di trasformare dati grezzi in modelli semantici strutturati, utilizzando DAX per calcoli avanzati e relazioni tra tabelle, facilitando analisi coerenti e self-service.
· Importazione dati in Power BI: I dati possono essere importati in-memory per migliori prestazioni, con il modello che funziona come un database in memoria e supporta relazioni a stella tra tabelle di fatto e dimensione.
· Sicurezza e networking in Azure: Azure offre controlli di accesso basati su identità e networking, come firewall, integrazione con Virtual Network e Private Endpoint per limitare l'accesso ai servizi solo a reti autorizzate, migliorando la protezione dei dati.
· Monitoraggio e gestione costi in Azure: Azure Monitor e Log Analytics consentono di raccogliere metriche e log per monitorare performance e errori, mentre Cost Management + Billing permette di impostare budget, alert e analizzare spese per mantenere soluzioni affidabili ed economicamente sostenibili.
· Azure Stream Analytics: ASA facilita la costruzione di pipeline di analisi in tempo reale con un linguaggio SQL-like, offrendo metriche di performance, modalità cluster dedicata e integrazione di rete per sicurezza e scalabilità.
· Azure Synapse Analytics: Combina un data warehouse SQL e un ambiente big data Spark, permettendo l'accesso nativo ai dati in Azure Data Lake Storage Gen2 senza duplicazioni, con gestione semplificata di cluster Spark autoscalanti e supporto per vari linguaggi.
· Modelli semantici e misure in Power BI: Il modello semantico funge da punto unico per calcoli riutilizzabili, con misure DAX che si aggiornano dinamicamente in base ai filtri, favorendo coerenza e self-service negli utenti finali.
· Audit e protezione dati: Azure consente di abilitare diagnostica e log per tracciare accessi e operazioni, oltre a mantenere la crittografia dei dati a riposo e in transito, con possibilità di gestire chiavi personalizzate per policy di sicurezza avanzate.
CAPITOLO 12 – Il servizio governance
Introduzione
La governance in Azure è l’insieme di strumenti, controlli e processi che consentono di gestire in modo centralizzato le risorse cloud di un’organizzazione, controllando l’accesso a tali risorse e assicurandone la conformità a norme e linee guida interne. Gli elementi principali della governance di Azure includono i Management Groups (Gruppi di gestione), le Sottoscrizioni (Subscriptions), le Azure Policy, gli Azure Blueprints, il controllo degli accessi con RBAC (Role-Based Access Control) e la gestione dei costi tramite Cost Management. L’obiettivo è garantire che ogni applicazione o carico di lavoro nel cloud rispetti gli standard aziendali di sicurezza, qualità, conformità e budget, riducendo i rischi e semplificando le operazioni quotidiane.
In Azure, la governance opera grazie a un modello gerarchico e a regole centralizzate che coinvolgono vari componenti: i Management Groups creano una struttura gerarchica sopra le sottoscrizioni, permettendo di applicare policy e iniziative di sicurezza su livelli elevati e di ereditarle automaticamente verso gli elementi sottostanti. Le Azure Policy definiscono regole di configurazione che vengono valutate e applicate continuamente; se una risorsa non rispetta una policy assegnata, Azure può bloccarne la distribuzione oppure segnalarla come non conforme. Il controllo degli accessi è gestito mediante ruoli e permessi assegnati con il sistema RBAC, applicabili a diversi ambiti (singola risorsa, gruppo di risorse, sottoscrizione, ecc.), garantendo che ogni utente disponga solo dei privilegi minimi necessari (principio del minimo privilegio). Per assicurare la conformità a standard di sicurezza, Azure fornisce inoltre strumenti come Microsoft Defender for Cloud, che valuta continuamente lo stato di sicurezza dell’ambiente rispetto a benchmark e normative (ad esempio CIS, PCI-DSS, ISO 27001) e fornisce punteggi e raccomandazioni su come migliorare la postura di sicurezza. Sul fronte dei costi, la funzionalità di Cost Management permette di definire budget di spesa e di impostare avvisi al raggiungimento di soglie predeterminate, oltre ad offrire analisi dettagliate per individuare tendenze di costo e possibili ottimizzazioni. Tutti questi componenti sono integrati nel portale di Azure, in particolare nella sezione Governance, che offre un quadro unificato da cui gli amministratori possono applicare policy, gestire permessi, monitorare la conformità e controllare i costi.
Esempio pratico: immaginiamo un’azienda che vuole impostare una solida governance per il proprio ambiente Azure. Per prima cosa, crea un gruppo di gestione radice (Tenant Root Group) e, sotto di esso, due Management Group: uno dedicato all’ambiente di Produzione e uno all’ambiente di Sviluppo. Sul Management Group di Produzione, l’azienda assegna un’iniziativa di Azure Policy contenente varie regole fondamentali. Ad esempio, richiede l’uso di Private Endpoint per tutti i servizi di archiviazione e i database, in modo che questi siano accessibili solo tramite la rete privata aziendale (garantendo una maggiore sicurezza e isolamento). Inoltre, impone che ogni risorsa abbia alcuni tag obbligatori (come Environment e Department) per facilitare la classificazione e la ripartizione dei costi tra diversi progetti o reparti. Infine, definisce un budget mensile per le spese della sottoscrizione di Produzione, con invio di avvisi automatici al raggiungimento dell’80% e poi del 100% del budget, così da evitare spese eccessive non controllate. In parallelo, per gestire i permessi, utilizza il sistema RBAC: assegna ai team di sviluppo applicativo il ruolo di Contributor sulle risorse delle proprie sottoscrizioni (permettendo loro di creare e gestire risorse, ma non di alterare i permessi di altri utenti), mentre riserva al team di piattaforma centralizzato il ruolo di Owner sulle sottoscrizioni stesse (in modo che solo il team centrale abbia pieno controllo e possa gestire a sua volta i permessi). In questo scenario combinato, la governance garantisce che i vari team possano lavorare in autonomia sulle proprie risorse cloud, ma sempre nel rispetto di paletti e controlli decisi a livello aziendale: nessuna risorsa critica potrà sfuggire alle regole di sicurezza (grazie alle policy), i costi saranno monitorati e suddivisi correttamente (grazie a budget e tag), e gli accessi rimarranno limitati secondo il ruolo di ciascuno (grazie a RBAC).
È utile introdurre qui alcuni termini chiave della governance di Azure che verranno ripresi nelle sezioni successive. In particolare: un’Iniziativa (Initiative) è un insieme di policy raggruppate in un unico pacchetto (spesso per perseguire un obiettivo comune, ad es. varie regole relative alla sicurezza); un’Assegnazione (Assignment) indica l’applicazione di una singola policy o di un’iniziativa a uno specifico ambito (che può essere un Management Group, una Sottoscrizione o un Resource Group); infine, la Compliance (conformità) rappresenta il grado di aderenza delle risorse alle policy assegnate ed è valutata automaticamente dal sistema, che evidenzia eventuali risorse non conformi per poter intervenire.
Inquadramento argomenti del capitolo con slides illustrate
La governance in Azure è l’insieme di strumenti, controlli e processi che permettono di gestire centralmente risorse, accessi e conformità. I principali elementi includono Management Groups, Subscriptions, Policy, Blueprints, RBAC e Cost Management. L’obiettivo è garantire che ogni workload rispetti gli standard di sicurezza, qualità, conformità e costo, riducendo rischi e semplificando l’operatività. I Management Groups creano una gerarchia sopra le subscription, con policy e iniziative ereditate dai figli. Azure Policy applica regole di configurazione, mentre RBAC gestisce l’accesso granularmente. Defender for Cloud valuta la conformità e Cost Management fornisce strumenti di analisi e controllo della spesa. Un esempio pratico: un’azienda crea management group per Produzione e Sviluppo, impone Private Endpoints e tag obbligatori, abilita budget con alert e assegna ruoli tramite RBAC. Terminologia chiave: iniziativa, assegnazione e compliance. Visivamente, la gerarchia va dal tenant root group fino alle risorse, con policy ereditate e punti di applicazione RBAC.
Azure Policy consente di creare e assegnare regole per governare la configurazione delle risorse, mantenendo la conformità automatica. Le policy impongono standard come regioni consentite, SKU approvati o tag obbligatori e possono negare, modificare o verificare risorse durante creazione e aggiornamento. Gli effetti includono Deny, Modify, Audit e Append. Le policy sono in JSON e si raggruppano in Initiatives per applicazioni di conformità. Esempi tipici: limitare le regioni disponibili, consentire solo SKU approvati, richiedere tag specifici o imporre Private Endpoint. Il motore valuta costantemente e può eseguire remediation dove previsto. Buone pratiche: assegnare policy al livello più alto, versionare le iniziative, formalizzare le exemption e monitorare periodicamente la compliance. Suggerimento visivo: tabella delle policy comuni con effetto e casi d’uso.
Azure Blueprints semplifica la distribuzione di ambienti conformi e ripetibili, combinando Policy, Role assignments, Resource Groups e template ARM o Bicep in una definizione versionabile. Permette di riutilizzare configurazioni, applicare aggiornamenti controllati e garantire coerenza tra ambienti di sviluppo e produzione. I vantaggi includono governance as code, versionamento, lock delle risorse e visibilità sugli assignment. Un esempio: un blueprint di produzione che crea resource group di rete e carico, applica policy di deny public IP, distribuisce VNet con Private Endpoints e assegna ruoli mirati. Modificando il blueprint, si possono aggiornare gli assignment. Buone pratiche: blueprint piccoli e specifici, naming coerente, documentazione dei parametri e allineamento agli standard Microsoft. Visualmente, un diagramma mostra i componenti blueprint e il flusso Define, Publish, Assign, Update.
Il Role-Based Access Control, o RBAC, gestisce autorizzazioni granulari assegnando ruoli a utenti, gruppi e identità su diversi livelli: risorsa, gruppo di risorse, subscription o management group. Questo garantisce segregazione dei compiti e applica il principio del minimo privilegio. I ruoli comuni sono Owner, Contributor e Reader, oltre a ruoli specifici come Storage Blob Data Reader. Managed Identities facilitano accessi sicuri senza gestione di segreti, che vanno archiviati in Key Vault. Esempi: assegnare Reader al team audit, Contributor su resource group specifici o User Access Administrator al team piattaforma; creare ruoli personalizzati e monitorare i cambiamenti tramite activity log e alert. Buone pratiche: evitare assegnazioni larghe, preferire gruppi rispetto a singoli utenti, usare PIM e Just-In-Time per ruoli privilegiati. Suggerimento visivo: tabella ruoli-permessi e flowchart richiesta JIT.
I Management Groups organizzano le subscription in modo gerarchico, permettendo di applicare policy e RBAC con ereditarietà. Facilitano la gestione su larga scala e la separazione per domini, come Produzione e Sviluppo. Una struttura tipica: tenant root group, gruppo aziendale, subscription e sottogruppi. Applicando una initiative a livello alto, tutte le subscription e resource group figli ereditano le regole. Esempi: applicare iniziative ISO 27001 o Microsoft Cloud Security Benchmark, imporre tag obbligatori, negare IP pubblici o abilitare Defender for Cloud su tutte le subscription di un dominio. Buone pratiche: progettare la gerarchia in base a funzioni o compliance, usare naming coerente, limitare eccezioni e monitorare l’impatto delle iniziative. Visual: albero gerarchico con ereditarietà di policy e ruoli.
Microsoft Cost Management offre strumenti FinOps per analizzare, monitorare e ottimizzare i costi cloud. È possibile definire budget, ricevere alert al superamento delle soglie, individuare anomalie, allocare costi tramite regole e esportare i dati su Power BI. Gli alert includono budget alerts, credit alerts e department quota alerts, attivati automaticamente al raggiungimento delle soglie. Esempi: budget mensile con soglie e destinatari designati, regole di cost allocation tramite tag, dashboard su Power BI per analisi dei consumi. Buone pratiche: applicare tag coerenti, configurare reserved instances o savings plan, impostare retention dei log per ottimizzare i costi. Visual: grafico spesa vs budget, tabella tag chiave per allocazione.
I tag classificano e rendono ricercabili le risorse, ad esempio Environment=Prod, Department=Finance, Project=Migration o Owner=Alessandro. Sono fondamentali per governance, sicurezza, costo e automazione, consentendo policy e regole di allocazione costi basate su tag. Le policy possono richiedere tag obbligatori e aggiungerli automaticamente con effetto Modify; i tag abilitano filtri e query nei log. Esempi: ricerca delle risorse in produzione per audit, limitazioni operative su risorse con tag specifici, allocazione costi per dipartimento e deprovisioning automatico di asset chiusi. Buone pratiche: catalogo tag aziendale, validazione sintassi, evitare varianti, dashboard di copertura, e abbinamento di tag a RBAC e Policy. Visual: tabella tag canonici, flusso di ereditarietà e remediation automatica.
Azure supporta numerosi standard di conformità tramite Microsoft Defender for Cloud, che rappresenta framework e benchmark di sicurezza e genera report nel Regulatory compliance dashboard. Sono inclusi benchmark generici come MCSB e standard come CIS, ISO 27001, PCI DSS, SOC. Ogni standard contiene controlli valutati automaticamente; le non conformità generano raccomandazioni e remediation. È possibile assegnare standard come iniziative di Azure Policy e generare report di conformità. Esempi: abilitare CIS e ISO 27001, utilizzare la dashboard per identificare e correggere risorse non conformi e tracciare i trend con Azure Workbooks. Buone pratiche: integrare Purview Compliance Manager, allineare policy agli standard, automatizzare remediation e assegnare ownership per i controlli falliti. Visual: tabella standard con valutazioni, icone di stato e mappa dei controlli prioritari.
L’Activity log traccia tutte le operazioni sulle risorse, utile per audit e investigazioni. Gli alert aiutano a reagire rapidamente a eventi come errori, metriche anomale o policy non conformi. Per audit continuo, si raccolgono log e metriche in Azure Monitor, impostando query e dashboard, e si usano alert di Cost Management e dashboard di Defender per la sicurezza. Esempi: alert per errori deploy, esportazione activity log per 90 giorni, alert su budget superato o policy violate. Buone pratiche: soglie significative, evitare alert rumorosi, usare Action Groups per notifiche e proteggere i log con retention e accesso controllato. Visual: dashboard con activity log, lista alert e tempi di risoluzione.
L’automazione semplifica la gestione delle policy e delle attività ripetitive. Con Azure Automation, Policy remediation ed Event Grid puoi pianificare azioni automatiche, come deploy, correzioni, tagging o avvio e spegnimento di VM. Esempi: runbook che imposta tag mancanti, gestisce accensione e spegnimento VM, o applica remediation su storage senza Private Endpoint. È possibile pianificare deploy delle policy e tracciare le esecuzioni. Le buone pratiche includono versionamento degli script, uso di Managed Identity, registrazione output nei log e test in ambienti di sviluppo. Le automazioni vanno coordinate con Policy e Blueprint per coerenza. Visualmente: tabella delle attività pianificate con stato e schema evento-azione, come alert budget che avvia runbook di spegnimento risorse di test.
1. Gruppi di gestione (Management Groups)
I Management Groups di Azure sono il mezzo con cui si possono organizzare gerarchicamente più sottoscrizioni, così da applicare configurazioni e controlli comuni in modo centralizzato. In contesti aziendali con numerose sottoscrizioni Azure (ad esempio per diversi dipartimenti, team o progetti), i Management Group aiutano a mantenere un ordine e una coerenza globale. Si immagini la struttura come un albero: in cima c’è il Tenant Root Group (il gruppo radice fornito di default per ogni tenant Azure AD), sotto il quale l’azienda può creare una gerarchia di Management Group rispecchiando la propria organizzazione. Ad esempio, si potrebbe avere un Management Group per l’azienda Contoso che racchiude tutti gli altri, al cui interno due Management Group denominati Produzione e Sviluppo, ciascuno contenente le relative sottoscrizioni Azure. Questa organizzazione gerarchica consente di applicare policy o assegnare ruoli RBAC su un nodo alto della gerarchia sapendo che tutti gli elementi sottostanti (sottoscrizioni, gruppi di risorse e risorse singole) erediteranno automaticamente tali impostazioni. Ciò rende possibile, ad esempio, applicare un set di regole di sicurezza comune a tutta l’azienda con un solo intervento sul Management Group principale, invece di dover replicare le stesse configurazioni su ogni sottoscrizione manualmente. I Management Group facilitano quindi la gestione su larga scala e permettono anche di separare logicamente diversi domini amministrativi; ad esempio, una multinazionale potrebbe tenere separate le risorse Azure di diverse filiali o linee di business creando Management Group distinti pur sotto lo stesso tenant.
Utilizzando i Management Group in combinazione con le Azure Policy, si può ottenere che tutte le sottoscrizioni figlie rispettino standard unificati. Ad esempio, applicando un’iniziativa di policy relativa alla sicurezza (come un insieme di regole per il rispetto dello standard ISO/IEC 27001 o del Microsoft Cloud Security Benchmark) direttamente sul Management Group aziendale, si fa in modo che ogni sottoscrizione sotto quell’ombrello venga automaticamente valutata e tenuta conforme a quei controlli di sicurezza. Allo stesso modo, a livello di un Management Group si potrebbero imporre dei tag obbligatori per tutte le risorse (ad esempio richiedere il tag Project e Owner su ogni risorsa creata, per motivi organizzativi e di addebito costi), oppure applicare una regola che nega gli IP pubblici su tutte le macchine virtuali nei progetti interni, o ancora abilitare in blocco servizi come Defender for Cloud su tutte le sottoscrizioni. Tutte queste regolamentazioni propagate dall’alto assicurano coerenza e riducono il rischio di configurazioni disallineate o fuori standard (il cosiddetto drift configurativo) tra le varie sottoscrizioni.
Buone pratiche: nella progettazione dei Management Group è importante riflettere la struttura aziendale o le esigenze di governance. Si può scegliere una gerarchia basata sulle funzioni organizzative (es. un Management Group per Finanza, uno per IT, uno per Ricerca, ecc.) oppure sugli ambienti (es. Produzione vs Test/Sviluppo), a seconda di dove ha più senso applicare regole comuni e dove invece mantenere separazione. È consigliabile adottare una convenzione di nomi chiara per i gruppi, così che dal nome sia intuibile la posizione nella gerarchia e lo scopo (ad esempio Contoso-Prod come gruppo per tutte le sottoscrizioni di produzione di Contoso). Inoltre, conviene minimizzare le eccezioni localizzate: se si applica una policy a livello di Management Group, è preferibile non escludere troppe sottostrutture o risorse specifiche, altrimenti la governance diventa frammentata e difficile da gestire. Infine, prima di assegnare iniziative molto restrittive a livelli elevati, è bene valutarne l’impatto: ad esempio testarle su un sottoinsieme di risorse o in una sottoscrizione non produttiva, monitorando che non blocchino involontariamente attività legittime, per poi estenderle gradualmente con fiducia all’intera gerarchia.
Azure Policy
Le Azure Policy rappresentano il cuore del meccanismo di governance tecnica di Azure, poiché consentono di stabilire regole dettagliate sulle configurazioni delle risorse e fare in modo che tali regole vengano fatte rispettare automaticamente dal sistema. In altre parole, mentre i Management Group definiscono dove si applicano certe impostazioni (lo scope organizzativo), le Azure Policy definiscono cosa viene controllato e come.
Scopo e funzionamento: una Azure Policy è fondamentalmente una regola espressa in formato JSON che specifica una condizione da verificare sulle risorse (o sulle azioni di creazione/modifica delle risorse) e un effetto da applicare se la condizione non è soddisfatta. Lo scopo è mantenere la conformità automatica alle best practice e ai requisiti aziendali. Ad esempio, si può creare una policy che impone l’uso di regioni Azure specifiche (proibendo il deploy di risorse in altre aree geografiche non approvate), oppure una policy che richiede la crittografia di tutti i dischi, o ancora che vieta l’utilizzo di SKU di macchine virtuali troppo costose o non standardizzate. Una volta assegnata a un determinato ambito (un Management Group, una sottoscrizione, o anche un singolo Resource Group), la policy viene valutata in continuazione da Azure: ogni volta che qualcuno prova a creare o modificare una risorsa in quello scope, il sistema controlla se l’operazione infrange la policy. Inoltre, periodicamente Azure ricontrolla anche tutte le risorse esistenti per segnalare eventuali elementi non conformi.
Tipi di effetto delle policy: quando una condizione di policy viene violata, l’azione intrapresa dipende dall’“effetto” definito in quella policy. I tipi di effetto più comuni sono:
· Deny: l’azione non conforme viene bloccata. Ad esempio, se esiste una policy che nega la creazione di macchine virtuali in una certa regione, un tentativo di creare una VM in quella regione fallirà immediatamente con un messaggio di errore, impedendo di fatto di uscire dallo standard.
· Audit: l’azione è consentita, ma viene registrata una segnalazione di non conformità. Questo è utile per controlli di tipo soft: ad esempio una policy potrebbe solo segnalare se un tag obbligatorio manca, lasciando comunque creare la risorsa. L’idea è raccogliere dati di conformità senza impedire il lavoro, riservandosi di intervenire successivamente sulle deviazioni.
· Modify: la policy interviene attivamente per correggere o integrare la configurazione. Un caso tipico è la policy che aggiunge automaticamente un tag mancante se l’utente non lo ha specificato durante la creazione della risorsa. Oppure potrebbe impostare in automatico la crittografia su un servizio se chi lo crea l’aveva lasciata disabilitata. In pratica “salva” l’utente da una violazione applicando un default conforme.
· Append: simile a Modify, questo effetto aggiunge determinati valori o impostazioni alla risorsa in fase di creazione. Ad esempio, potrebbe aggiungere una determinata impostazione di sicurezza a tutti i database creati, senza sovrascrivere altri parametri.
Le policy vengono gestite e monitorate tramite il portale Azure (sezione Azure Policy). Qui, oltre a definire regole e assegnarle, è possibile controllare la Compliance complessiva: Azure mostra quanti elementi sono conformi o no per ciascuna policy assegnata, con percentuali e liste dettagliate. Questo aiuta i team a capire dove esistono eventuali falle nella governance e a porvi rimedio.
Spesso più policy collegate fra loro per scopo vengono raccolte in un’Iniziativa (Initiative), che è un contenitore logico di policy. Ad esempio, Microsoft fornisce out-of-the-box l’iniziativa [Azure Security Benchmark] che raggruppa decine di policy relative alla sicurezza delle risorse Azure. In questo modo si può assegnare l’intera iniziativa invece che le singole policy una per una, ottenendo una copertura ampia con un solo gesto.
Esempi pratici: le Azure Policy trovano applicazione in moltissimi scenari. Eccone alcuni:
· Restrizione delle regioni: un’azienda può voler limitare le regioni Azure utilizzabili alle sole aree in cui ha sede o dove vigono certe normative (ad esempio, evitare che dati sensibili vengano collocati in data center extra-UE). Una policy di tipo Deny può impedire la creazione di risorse al di fuori di, poniamo, “North Europe” e “West Europe”.
· Controllo delle SKU supportate: per standardizzare le infrastrutture, si può fare in modo che vengano usate solo determinate dimensioni di VM o tipi di servizi. Ad esempio, se un certo servizio interno supporta solo macchine virtuali fino a una certa potenza, una policy può negare l’uso di SKU più grandi (o magari più vecchie/non più consigliate).
· Imposizione di tag obbligatori: come accennato, i tag sono essenziali per tracciare costi e responsabilità. Una policy può richiedere che ogni risorsa abbia i tag Environment e Department. Se qualcuno cerca di creare una risorsa senza questi tag, l’effetto Modify potrebbe aggiungerli automaticamente con valori di default, oppure l’effetto Deny potrebbe bloccare l’operazione finché non vengono specificati. In ogni caso, si ottiene che nessuna risorsa rimanga priva di tag importanti.
· Forzare configurazioni di sicurezza: ad esempio, si può creare una policy che nega la creazione di un archivio dati (storage account) che non sia configurato con un Private Endpoint. Così, anche se un utente disattento provasse a crearne uno accessibile pubblicamente da Internet, Azure lo impedirebbe, garantendo che lo standard di collegamento privato sia sempre rispettato.
Quando viene assegnata una policy o un’iniziativa, Azure esegue immediatamente una valutazione su tutte le risorse esistenti in quello scope. Questo significa che non solo le nuove risorse saranno sottoposte al controllo, ma anche quelle già create in passato vengono verificate: se la policy trova risorse non conformi, le segnalerà. In alcuni casi, Azure Policy consente di definire azioni di remediation automatica per le risorse esistenti. Ad esempio, se si introduce una nuova policy che richiede un determinato tag, si può avviare una remediation task che percorre tutte le risorse attuali e aggiunge quel tag dove manca. Oppure, se la policy impone la crittografia di dischi e trova dischi non crittografati, può attivare automaticamente la crittografia su quelli (ove supportato) o inviare un report agli amministratori per intervento manuale. L’idea è chiudere il gap anche sulle risorse legacy, non solo su quelle future.
Buone pratiche nella gestione delle policy: per beneficare appieno di Azure Policy, è consigliato innanzitutto assegnare le policy al livello più alto appropriato. Ad esempio, se una regola vale per tutta l’organizzazione, meglio applicarla sul Management Group principale, così si propaga a cascata ovunque. Applicare la stessa policy singolarmente a tante sottoscrizioni è meno efficiente e aumenta le probabilità di dimenticanze o incoerenze. Allo stesso modo, è utile creare iniziative per raggruppare policy correlate, versionandole nel tempo. Mantenere versioni (v1, v2, ecc.) documentate delle iniziative aiuta a capire, se cambiano, cosa è stato modificato e perché, e a riprodurre facilmente la stessa configurazione in ambienti differenti (ad esempio test vs produzione). Bisogna gestire con prudenza le eccezioni (exemptions): Azure permette di esentare specifiche risorse da una policy (nel caso in cui ci siano motivi validi per non applicare una certa regola a quella risorsa). Ogni esenzione però indebolisce un po’ la governance, quindi andrebbe concessa solo in casi speciali, con un processo di approvazione formale e magari temporanea (rimuovendo l’esenzione non appena possibile). Un’altra buona pratica è monitorare periodicamente lo stato di conformità: far sì che il team di governance o sicurezza controlli i report di Azure Policy per vedere se il grado di compliance sta migliorando o peggiorando. Se persistono molte risorse non conformi, potrebbe essere necessario intervenire (magari rivedere la policy se era troppo stringente o formare meglio i team all’uso corretto del cloud). Infine, dove possibile, conviene automatizzare la risposta alle non conformità: come vedremo anche più avanti, Azure offre integrazioni per far scattare azioni automatiche (script, runbook) quando ci sono violazioni di policy, così da correggerle subito o notificare chi di dovere senza aspettare controlli manuali.
2. Azure Blueprints
Se Azure Policy aiuta a controllare che le configurazioni rispettino certe regole, gli Azure Blueprints servono a distribuire interi ambienti Azure in modo standardizzato e conforme fin dal primo momento. Un blueprint è essenzialmente un modello (versionabile e riutilizzabile) che combina vari artefatti di Azure – come policy, ruoli, template di risorse e strutture di Resource Group – con lo scopo di creare ambienti completi che seguano automaticamente le linee guida di governance stabilite.
Scopo e utilizzo: Azure Blueprints è particolarmente utile quando bisogna fornire a team diversi ambienti simili tra loro, come ad esempio più subscription di sviluppo e produzione che devono rispettare certe configurazioni comuni. Invece di costruire ogni ambiente manualmente e ricordarsi di applicare tutte le policy, ruoli e impostazioni richieste, si definisce un blueprint una volta sola e poi lo si può assegnare a ogni sottoscrizione necessaria. Un blueprint può includere:
· Policy e Iniziative Azure da applicare (così ogni risorsa nell’ambiente sarà automaticamente soggetta a quelle regole di governance);
· Ruoli RBAC da assegnare (per esempio, il blueprint può prevedere che nella sottoscrizione vengano assegnati subito i ruoli di Reader al team di sicurezza e di Contributor a un certo team di sviluppo, senza intervento manuale post-creazione);
· Struttura di base dei Resource Group (ad es. creare automaticamente un Resource Group chiamato “Networking” e uno “CoreServices” in ogni subscription configurata, per poi inserirvi le risorse pertinenti);
· Template ARM o Bicep per distribuire risorse predefinite (ad esempio una rete virtuale con le sue subnet, un insieme di log analytics per la raccolta dei log, o altri componenti infrastrutturali che devono sempre essere presenti).
In pratica, applicare un blueprint su una sottoscrizione significa costruire un ambiente chiavi in mano: l’infrastruttura fondamentale viene creata e le regole di governance (policy, accessi) sono impostate senza ulteriori interventi manuali. Questo garantisce coerenza tra ambienti diversi. Si pensi al tipico scenario Dev-Test-Prod: con i blueprint si può fare in modo che tutti e tre gli ambienti abbiano la stessa base (stessa rete, stessi controlli) differenziando magari la potenza o quantità di risorse a seconda del caso, ma sapendo che nulla è stato tralasciato in Prod rispetto a Test in termini di controlli.
Vantaggi: uno dei maggiori benefici di Azure Blueprints è di incarnare il concetto di infrastructure as code anche per la governance – a volte si parla infatti di governance “as code”. Il blueprint è definito come codice, può essere salvato in un repository, revisionato, versionato e aggiornato in modo controllato. Ogni blueprint infatti supporta un controllo di versione: se inizialmente si crea la versione 1.0 di un blueprint e la si assegna a dieci sottoscrizioni, in seguito è possibile apportare miglioramenti (per esempio aggiungere una nuova policy, o modificare un parametro di una risorsa) e salvare il blueprint come versione 1.1. A questo punto Azure permette di scegliere se le sottoscrizioni che avevano la versione 1.0 debbano essere aggiornate alla 1.1: c’è quindi un vero e proprio ciclo di vita, simile a quello del software, per mantenere gli ambienti sincronizzati con l’ultima definizione approvata. Un altro vantaggio offerto dai blueprint è il concetto di lock sulle risorse gestite: le risorse distribuite tramite blueprint possono essere contrassegnate in modo tale da impedirne modifiche o cancellazioni accidentali al di fuori del blueprint. Ad esempio, se il blueprint crea un Resource Group e il suo scopo è che rimanga lì con certe policy, un utente non potrebbe eliminare quel Resource Group a mano libera se è protetto da lock (a meno di togliere deliberatamente il lock con elevati permessi, naturalmente). Questo aiuta a prevenire deviazioni dalla configurazione prevista. Inoltre, i blueprint forniscono visibilità centralizzata: un amministratore può vedere dall’interfaccia di Blueprints quali blueprint sono pubblicati, quali versioni e soprattutto dove sono assegnati (quali sottoscrizioni hanno quali blueprint attivi). Ciò facilita il tracciamento della governance applicata. In sintesi, Blueprints è ideale per scenari di enviroment provisioning ripetibili, tipici di organizzazioni che vogliono offrire ai propri team un “starter kit” Azure già in linea con gli standard aziendali.
Esempi pratici: un caso pratico può essere un blueprint per l’ambiente di Produzione. Potremmo definire che quando una nuova sottoscrizione di produzione viene creata per un progetto:
· il blueprint provvede subito a creare due Resource Group fondamentali, uno per la rete (dove posizionare magari le VNet, i gateway, etc.) e uno per il workload applicativo (dove andranno VM, database, storage dell’applicazione);
· applica sul scope della sottoscrizione o dei singoli RG delle policy di sicurezza chiave, ad esempio una policy Deny che vieta di assegnare IP pubblici alle VM o ai database (così da forzare l’uso della rete privata), e una policy Require Tag che impone i tag Owner e Criticality su ogni risorsa;
· distribuisce tramite template una Virtual Network standard con alcune subnet predefinite e magari già un collegamento (peering) verso la rete on-premises o un servizio di monitoraggio;
· assegna automaticamente il ruolo Reader al gruppo del reparto Sicurezza su quella sottoscrizione (in modo che abbiano visibilità completa) e il ruolo Contributor al team di progetto che utilizzerà l’ambiente, mantenendo eventuali privilegi più elevati (Owner) al solo amministratore centrale.
Tutto ciò avviene in pochi minuti quando si assegna il blueprint alla nuova sottoscrizione di Produzione. Se poi nel tempo le regole cambiano – ad esempio si decide che da oggi serve anche un terzo Resource Group per un nuovo componente, o che va aggiunta una policy aggiuntiva – basterà aggiornare il blueprint e ripubblicarlo in nuova versione. Gli ambienti esistenti segnalati come assegnati a quel blueprint potranno essere aggiornati alla nuova versione con un processo di deployment incrementale (ad esempio verrà creato il nuovo RG mancante, applicata la nuova policy, ecc., senza dover riconfigurare tutto da zero manualmente).
Buone pratiche per i blueprint: per massimizzare efficacia e manutenibilità, conviene progettare blueprint modulari e specifici. Ad esempio, invece di un unico blueprint gigantesco “Tutto-Prod”, si potrebbe averne uno per le configurazioni di rete di base, uno per le policy di sicurezza di base, uno per la configurazione dei logging/monitoring, e così via. In questo modo, se un progetto ha bisogno solo di una parte, si assegnano solo i blueprint necessari. Blueprint più piccoli significano anche minori probabilità di conflitti e più facilità nel testare nuove versioni. Importante poi avere una nomenclatura coerente: nominare i blueprint in modo descrittivo (es. “Blueprint-BaseNetwork-v1.0”) aiuta a capirne subito il contenuto e lo scopo. Ogni blueprint può definire dei parametri (ad esempio un nome univoco da dare a una risorsa, o scegliere se includere un certo modulo): è bene documentare questi parametri e fornire valori di default sensati. Un’altra buona pratica è allineare i blueprint agli standard di sicurezza riconosciuti: molte organizzazioni mappano i contenuti dei blueprint con i controlli del Security Benchmark di Azure o altre best practice, così da essere sicuri che ogni ambiente creato tramite blueprint soddisfi requisiti di conformità fin dalla creazione. In ultimo, assicurarsi di aggiornare i blueprint quando necessario: man mano che Azure introduce nuove funzionalità utili alla governance (nuovi policy alias, nuovi servizi) può aver senso rivedere periodicamente i blueprint per incorporarli e mantenere gli ambienti sempre al passo con le migliori prassi.
3. Controllo degli accessi (RBAC)
La sicurezza di un ambiente cloud non dipende solo dalle configurazioni delle risorse, ma anche da chi può fare cosa su di esse. Il meccanismo di Role-Based Access Control (RBAC) in Azure risponde proprio a questa esigenza, consentendo di assegnare permessi in maniera granulare agli utenti e ai sistemi in base ai ruoli loro attribuiti. È uno strumento essenziale di governance perché permette di applicare il principio del least privilege (minimo privilegio) e mantenere una separazione dei compiti tra i vari team.
Ruoli e ambiti: Azure fornisce decine di ruoli predefiniti per coprire i casi d’uso più comuni. I ruoli sono essentially insiemi di permessi (azioni consentite o negate) su determinati tipi di risorse. I tre ruoli di base da cui tutto parte sono:
· Owner (Proprietario): può fare tutto su quell’ambito, includendo creare, modificare e cancellare risorse, e in più gestire le autorizzazioni stesse (cioè assegnare ruoli ad altri). In genere è il ruolo più potente e va assegnato con parsimonia.
· Contributor (Collaboratore): può creare, gestire e eliminare risorse, ma non può gestire i permessi degli altri (non può assegnare ruoli). È il ruolo tipico dato ai team che devono poter operare sulle risorse ma senza poter alterare la struttura di sicurezza.
· Reader (Lettore): può solo visualizzare risorse ed effettuare query/letture, ma non può modificare nulla. Utile per chi deve monitorare o fare audit senza intervenire.
Oltre a questi, Azure ha molti ruoli specifici per servizio: ad esempio Virtual Machine Contributor (simile a Contributor ma limitato alle macchine virtuali e risorse correlate), Storage Account Contributor, SQL DB Contributor, nonché ruoli ancora più specifici come Storage Blob Data Reader (che consente solo di leggere i contenuti dei blob storage, senza accesso ad altre proprietà). In più è possibile definire ruoli personalizzati se i ruoli built-in non soddisfano particolari necessità: si possono scegliere esattamente le azioni consentite costruendo un ruolo su misura.
Questi ruoli vengono assegnati a principali (principals), che possono essere utenti individuali, gruppi di Azure AD (che rappresentano insiemi di utenti, spesso utilizzati per facilitare la gestione collettiva dei permessi) oppure applicazioni/identità di servizio. L’assegnazione avviene sempre su uno scope preciso: può essere l’intera sottoscrizione, oppure un singolo Resource Group, o addirittura una singola risorsa (come un singolo database). Grazie all’ereditarietà degli scope, se assegno un ruolo a livello di sottoscrizione, automaticamente chi lo riceve ha quei permessi anche su tutti i resource group e risorse contenuti nella sottoscrizione; viceversa un ruolo assegnato su un resource group non vale al di fuori di esso.
Gestione delle identità applicative: oltre agli esseri umani, spesso sono le applicazioni o i servizi a dover accedere a risorse Azure (si pensi a un’applicazione web che deve leggere dati da un database, o uno script che deve avviare/arrestare macchine virtuali). In questi casi, Azure consiglia di usare le Managed Identities. Una Managed Identity è essenzialmente un utente “virtuale” gestito automaticamente da Azure (non ha password che l’utente debba gestire, Azure la ruota e la protegge internamente) che può essere collegato a un servizio come una VM, un’App Service o un Function. Una volta che un servizio ha una Managed Identity, le si possono assegnare ruoli RBAC come se fosse un qualunque account: ad esempio dare a una funzione Azure il ruolo di Lettore su un account di archiviazione, cosicché possa leggerne i dati direttamente, evitando la necessità di conservare chiavi di accesso nel codice. Per segreti più generali (come stringhe di connessione, certificati, chiavi API per servizi esterni) la best practice è usare Azure Key Vault: piuttosto che mettere questi segreti nel codice o in configurazioni in chiaro, l’applicazione li legge in modo sicuro dal Key Vault, e l’accesso al Key Vault stesso può essere regolato via RBAC (ad esempio, solo la Managed Identity dell’applicazione X ha il ruolo di Secret Reader sul Key Vault, e quindi può prelevare le credenziali necessarie).
Esempi di assegnazioni RBAC:
· Un classico scenario è dare al team di audit interno visibilità sull’ambiente cloud senza rischi di modifica. Per farlo, si crea un gruppo di Azure AD contenente gli account degli auditor, e si assegna a quel gruppo il ruolo Reader su tutte le sottoscrizioni (magari mediante assegnazione sul Management Group root, ereditato a cascata). Così ogni auditor potrà vedere configurazioni, log, policy, ecc., ma non potrà per errore creare, modificare o cancellare nulla.
· I team di sviluppo applicativo tipicamente hanno bisogno di lavorare sulle proprie risorse ma non su quelle altrui. Quindi il team che segue il Progetto A riceverà il ruolo Contributor sul Resource Group (o sulla sottoscrizione) che contiene le risorse di Progetto A, permettendo loro di gestirle (VM, database, ecc.), mentre non avrà alcun permesso sui Resource Group di altri progetti. Se un altro team (Progetto B) prova ad accedere alle risorse di A, non avrà diritti sufficienti. Questo isolamento riduce rischi di interferenza e mantiene i confini tra i vari workload.
· Il team IT centrale o di piattaforma cloud in genere mantiene i permessi più elevati: alcuni utenti chiave potrebbero avere il ruolo di Owner sulle sottoscrizioni critiche, il che permette loro di fare qualsiasi operazione, inclusa la gestione dei permessi (ad esempio per assegnare Contributor ai vari team come visto sopra). In aggiunta, Azure offre il ruolo User Access Administrator, che solo gestisce i permessi ma non dà altre autorizzazioni: questo potrebbe essere assegnato a un team dedicato alla gestione account, permettendo loro di aggiungere/rimuovere utenti dai ruoli senza poter però creare o modificare le risorse cloud (separando nettamente chi gestisce l’accesso da chi gestisce le risorse). Spesso nelle organizzazioni si definisce un certo processo per cui i nuovi progetti o team vengono aggiunti al cloud proprio attraverso la concessione di ruoli da parte di questi amministratori centrali. In casi particolari potrebbero crearsi ruoli personalizzati: ad esempio, un ruolo che permette solo di riavviare o arrestare macchine virtuali e nient’altro, utile da assegnare a un team di help desk che deve poter intervenire sui server senza però modificarne la configurazione.
È importante notare che ogni modifica nelle assegnazioni di ruoli viene tracciata: nell’Activity Log di Azure troviamo eventi specifici per l’aggiunta o rimozione di un ruolo su un certo scope. Questo consente di fare auditing sulle operazioni di sicurezza. Ad esempio, se improvvisamente un utente ottiene il ruolo Owner su una sottoscrizione senza che ciò fosse pianificato, un responsabile può scoprirlo e intervenire (magari rimuovendo l’assegnazione e verificando con il team di sicurezza l’accaduto). Si possono anche impostare alert per tali eventi critici (lo vedremo nella parte su monitoraggio), così da essere notificati immediatamente.
Buone pratiche per RBAC: gestire i permessi può diventare complesso se non lo si fa con metodo. Un principio guida è di assegnare ruoli preferibilmente a gruppi di Azure AD invece che a singoli utenti. Questo perché i gruppi permettono di concentrarsi sui ruoli funzionali (es. “sviluppatori del progetto X”) e non sulle singole persone: quando arriva una nuova persona nel team, basta aggiungerla al gruppo e automaticamente eredita tutti i permessi del gruppo; se qualcuno lascia il team, rimuovendolo dal gruppo si rimuovono anche tutti i suoi accessi in giro per Azure, senza doverli cercare uno ad uno. Questo facilita enormemente la gestione del ciclo di vita degli accessi.
Un’altra best practice è seguire il principio di minimo privilegio e di separazione dei compiti: evitare di assegnare a un solo individuo o gruppo troppi poteri se non necessario. Ad esempio, se un ruolo Contributor a livello di sottoscrizione non è strettamente necessario (magari il team deve operare solo su uno specifico Resource Group), è meglio limitarlo, così in caso di errore umano o compromissione di un account, i potenziali danni sono limitati solo a una porzione dell’ambiente e non a tutto.
Per i ruoli altamente privilegiati (come Owner o simili) Azure offre funzionalità avanzate, in particolare PIM (Privileged Identity Management). PIM consente di rendere just-in-time l’assegnazione di ruoli critici: un utente che deve svolgere un’azione da Owner può “attivare” temporaneamente quel ruolo per poche ore previa approvazione, dopodiché il ruolo gli viene revocato automaticamente. Questo significa, ad esempio, che anche se Tizio è in teoria un Global Admin, per la maggior parte del tempo non ha i poteri attivi finché non li richiede esplicitamente per una necessità. Ciò riduce drasticamente la finestra in cui un malintenzionato potrebbe sfruttare account privilegiati.
Infine, è opportuno riesaminare periodicamente le assegnazioni RBAC: Azure non lo fa in automatico, ma come prassi interna il reparto IT dovrebbe controllare (magari con cadenza trimestrale) gli accessi esistenti, verificare che chi ha certi ruoli ne abbia ancora bisogno, e rimuovere eventuali eccessi. Col tempo i progetti cambiano, le persone ruotano, e senza una pulizia periodica si rischia di accumulare permessi obsoleti che rappresentano vulnerabilità potenziali.
4. Gestione dei costi e budget
Un aspetto cruciale della governance cloud è assicurarsi che i costi siano gestiti e ottimizzati in linea con il budget e le aspettative aziendali. Azure fornisce uno strumento integrato chiamato Cost Management (sviluppato in origine dalla piattaforma Cloudyn, ora parte del portale Azure) che aiuta a monitorare la spesa, definire budget, analizzare le voci di costo e individuare opportunità di risparmio.
Analisi e monitoraggio dei costi: attraverso il portale, Cost Management offre dashboard e viste personalizzabili per esaminare i costi aggregati secondo vari criteri: per servizio (quanto si spende in VM, in database, in storage, ecc.), per risorsa o gruppo di risorse, per tag (ad esempio sommare i costi di tutte le risorse con tag Department: Marketing), per periodo temporale. Si possono identificare trend di spesa e prevedere, con estrapolazioni, se un certo budget verrà sforato prima di fine periodo. Uno strumento molto utile è la creazione di budget di spesa: si definisce un importo massimo per una determinata entità (ad esempio un budget mensile di 5.000 euro per la sottoscrizione di sviluppo, o annuo di 100.000 euro per un progetto), e si collegano a quel budget delle soglie di allarme. Tipicamente si impostano avvisi al 50%, 80%, 100% del budget, ma i valori sono personalizzabili. Azure quindi calcola di giorno in giorno la spesa cumulativa e, non appena supera una soglia, genera un’allerta. Queste allerte possono tradursi in email inviate ai proprietari del budget o a figure finanziarie, così nessuno viene colto di sorpresa a fine mese. Nel caso di clienti enterprise con contratti a crediti o con suddivisione in dipartimenti, esistono credit alerts (per avvisare se si sta per esaurire il credito acquistato) e department quota alerts (se un dipartimento supera la quota prevista). Azure consente anche di impostare alert di anomalia: ad esempio, se in genere la spesa giornaliera su una sottoscrizione è di circa 100 euro e improvvisamente in un giorno sale a 500 euro, il sistema può considerarlo anomalo e mandare un avviso anche se il budget mensile non è ancora superato, perché potrebbe segnalare un uso imprevisto (forse qualcuno ha attivato accidentalmente risorse costose, o c’è un attacco in corso che genera costi).
Ottimizzazione e allocazione dei costi: una volta raccolti i dati, il passo successivo è ottimizzare. Cost Management fornisce alcune raccomandazioni (ad esempio suggerisce l’acquisto di istanze riservate se nota che certe VM sono accese costantemente, perché l’istanza riservata farebbe risparmiare rispetto alla tariffa pay-as-you-go). Inoltre, un elemento chiave è capire come ripartire i costi internamente in azienda: grazie ai tag, come già sottolineato, è possibile classificare le risorse per progetto, per reparto, per cliente, ecc. Cost Management consente di utilizzare questi tag per creare viste su misura: ad esempio, generare un report mensile per ogni Department che sommi tutti i costi delle risorse taggate con Department: X. Se ci sono costi condivisi (come infrastrutture di rete comuni o servizi condivisi), l’azienda può definire regole di allocazione per suddividere quei costi tra più centri di costo. Ad esempio, se un cluster Kubernetes è usato da 3 diverse business unit, e non è facilmente separabile, si può decidere di allocare il 30% del costo alla BU1, 50% alla BU2 e 20% alla BU3, e fare in modo che i report riflettano questa ripartizione (queste regole però vanno gestite spesso fuori da Azure, esportando i dati e imputandoli con logiche proprie, oppure usando le funzioni avanzate di Cost Management per l’EA).
Un altro strumento importante è l’integrazione con sistemi esterni. Cost Management permette di esportare i dati grezzi di costo su base regolare, ad esempio verso un file CSV in un account di archiviazione, oppure direttamente dentro Power BI per costruire dashboard personalizzate e incrociare i dati di costo con altri dati aziendali. Questo è utile quando si vuole realizzare una reportistica più sofisticata o consolidare i costi Azure con quelli di altri servizi cloud o on-premises.
Esempi pratici:
· Un team IT imposta un budget mensile di 10.000 € per la sottoscrizione di Produzione. Nel portale, sceglie come soglie l’80% (8.000 €) e il 100% (10.000 €). Come destinatari degli alert inserisce l’indirizzo del responsabile IT e del controller finanziario. Durante il mese, man mano che Azure registra i consumi, calcola che il budget sta per essere raggiunto il giorno 20 del mese: automaticamente viene inviata un’email di avviso dell’80%. Questo permette al team di investigare la causa (magari un aumento di traffico ha richiesto più potenza di calcolo) e decidere se intervenire (ad esempio ottimizzando qualche risorsa) oppure se il budget era sottostimato. Se si arriva al 100%, scatta un secondo avviso di budget esaurito, segnalando chiaramente l’anomalia rispetto ai piani iniziali.
· Un’azienda che suddivide i costi tra reparti utilizza rigorosamente i tag. Ogni risorsa in Azure porta il tag Department col valore del reparto di appartenenza, e Project con il nome del progetto interno. A fine mese, tramite Cost Management, il cloud economist estrae un report che raggruppa la spesa totale per Department. Vede così che, per esempio, il reparto Marketing nel mese di settembre ha speso 3.200 €, il reparto R&D 5.400 €, e così via, potendo addebitare queste cifre sui rispettivi centri di costo aziendali. Non solo: nota anche che un certo progetto trasversale, presente in più reparti ma taggato uniformemente come Project: Apollo, ha un costo complessivo di 7.000 € (somma delle risorse taggate con quel progetto attraverso vari reparti). Queste informazioni aiutano a capire dove si concentrano gli investimenti cloud e se corrispondono alle priorità strategiche. Inoltre, esaminando la composizione dei costi, l’azienda può scoprire cose come “il 40% della spesa di quel progetto sono database non usati di notte”: informazione che può portare a introdurre meccanismi di spegnimento automatico o ridimensionamento per risparmiare.
Buone pratiche per il controllo dei costi: la chiave per una buona gestione finanziaria del cloud è la visibilità e la responsabilizzazione. Per ottenere visibilità, come detto, l’uso coerente dei tag è fondamentale: se poche risorse sono taggate, i report saranno monchi e servirà molto lavoro manuale per capire chi sta spendendo cosa. Quindi, definire un set di tag finanziari (ad es. Department, Project, Environment, Owner) e assicurarsi tramite policy che vengano applicati sistematicamente è un primo passo. Un’altra pratica raccomandata è sfruttare i saving plans o le istanze riservate per le risorse a utilizzo costante: ad esempio, se so che avrò app e database accesi 24/7 per i prossimi mesi o anni, acquistare capacità riservata può ridurre i costi del 20-50%. Azure Cost Management spesso suggerisce queste ottimizzazioni: conviene prenderle in considerazione e valutarle insieme al procurement. Importante anche impostare politiche di spegnimento e ridimensionamento: il cloud permette flessibilità, quindi se un’applicazione non è usata di notte o nel weekend, script o servizi di autoscaling dovrebbero ridurre al minimo le risorse impiegate in quei periodi (ad esempio spegnere macchine virtuali di test alle 19:00 e riaccenderle alle 8:00 del mattino seguente).
Dal punto di vista tecnico, si può risparmiare anche ottimizzando la gestione dei log e metriche. Azure Monitor accumula dati che anch’essi costano: mantenere illimitatamente log dettagliati di ogni servizio potrebbe generare spese considerevoli. Quindi definire una retention policy (es. mantenere 30 giorni di log dettagliati online, poi archiviare quelli più vecchi in uno storage meno costoso, oppure cancellarli se non servono) aiuta a controllare i costi di monitoraggio.
Infine, instaurare in azienda una cultura FinOps: ovvero fare in modo che i team IT e i team di business collaborino sulla gestione dei costi, con review periodiche, analisi congiunte dei report e condivisione delle responsabilità sui budget. Il cloud rende molto facile consumare risorse, ma la governance finanziaria assicura che ciò avvenga in modo sostenibile e consapevole.
5. Tag e organizzazione
Nel caos che potrebbe derivare da centinaia di risorse cloud, i tag sono uno strumento semplice ma potentissimo per portare ordine. Un tag in Azure è una coppia chiave:valore che si può assegnare a quasi qualsiasi risorsa (ci sono poche eccezioni). Pensiamo ai tag come a delle etichette colorate che applichiamo su cartelle e documenti in un archivio: con poche parole chiave possiamo categorizzare gli oggetti in modi trasversali rispetto alla loro collocazione fisica. Allo stesso modo, i tag permettono di raggruppare risorse che magari risiedono in resource group diversi o sottoscrizioni diverse, ma che condividono un attributo logico importante.
Utilità dei tag per la governance: i tag rendono più facile trovare e filtrare le risorse. Nel portale Azure o via script/API, posso chiedere “trova tutte le risorse con tag Project = XYZ” e avrò l’elenco completo di tutto ciò che appartiene a quel progetto, anche se è sparso su vari servizi. Ma l’aspetto ancora più rilevante è che Azure consente di usare i tag come base per varie politiche e regole:
· Azure Policy e tag obbligatori: come discusso, possiamo implementare policy che richiedono la presenza di specifici tag su certe risorse. Questo garantisce che, ad esempio, nessuno crei risorse senza indicare a quale ambiente o progetto appartengono. L’effetto Modify consente persino di aggiungere un tag mancante automaticamente.
· Ereditarietà dei tag: Azure offre meccanismi (come l’uso del parametro ApplyToChildren in alcune policy) per propagare tag da un livello superiore a quelli inferiori. Ad esempio, si può fare in modo che se un certo tag è impostato su un Resource Group, tutte le risorse al suo interno ereditino quel tag senza doverlo assegnare manualmente ogni volta.
· Cost management e tag: come appena visto, i tag sono fondamentali per attribuire costi: senza tag, si saprà solo la spesa per sottoscrizione o per servizio, ma non si riuscirà a distinguere chi ha usato cosa. Con i tag, invece, si ottengono viste per progetto, team, ambiente, ecc.
· Query di log e automazione: si possono scrivere query nel Log Analytics (Azure Monitor) filtrando per tag. Ad esempio “mostrami tutti gli alert di monitoraggio relativi a risorse taggate come Prod”, e così focalizzarsi solo sugli eventi critici di produzione. Oppure script di pulizia che eliminano risorse orfane con un certo tag (es. ToBeDeleted: True).
In sostanza, i tag aggiungono metadati personalizzati alle risorse, permettendo di colmare il gap tra l’organizzazione tecnica (per risorsa e gruppo) e l’organizzazione logica per business (per progetto, per proprietario, per importanza, ecc.).
Esempi di uso dei tag:
· Organizzazione ambienti: se tutte le risorse di produzione hanno Environment=Prod e quelle di test Environment=Test, si può facilmente filtrare qualsiasi vista (nel portale, nei report costi, nelle query) per ambiente. Questo è utile, ad esempio, per avere un quadro dei soli sistemi di produzione durante un audit di sicurezza, oppure per lanciare un comando in PowerShell che effettui una certa azione (come riavviare macchine) solo su quelle di test.
· Controllo azioni per tag: Azure consente persino di condizionare certe autorizzazioni all’esistenza di un tag specifico. Ad esempio, potrei creare un ruolo personalizzato o una condizione RBAC avanzata che dice: “consenti all’utente X di eliminare macchine virtuali solo se tali VM hanno il tag Environment=Test”. In questo modo, anche se quell’utente vede le VM di produzione, non potrà eliminarle perché il tag non corrisponde. Questo livello fine di controllo è poco usato, ma dimostra come i tag possano partecipare anche alla sicurezza operativa.
· Allocazione spese e chargeback: come già illustrato, un pratico utilizzo è assicurarsi che ogni risorsa sia taggata con Department e Project. Così a fine trimestre l’IT può calcolare esattamente quanto dev’essere addebitato al budget di Marketing, quanto a quello di Ricerca, ecc., in base ai tag delle risorse effettivamente consumate. Senza tag, dovrebbe fare stime manuali molto meno precise.
· Lifecycle management: supponiamo di condurre un hackathon o un progetto temporaneo chiamato MigrationX, per cui si creano molte risorse cloud. Se tutte queste vengono taggate con Project=MigrationX, una volta concluso il progetto diventa semplicissimo individuarle e decidere cosa farne. Si potrebbe ad esempio realizzare un runbook che ogni mese controlla se esistono risorse con Project=MigrationX e, se il project status nel CMDB risulta chiuso, le spegne o le elimina dopo aver avvisato i proprietari. I tag forniscono il contesto necessario per prendere decisioni automatiche o semi-automatiche sulla vita delle risorse.
Buone pratiche nella gestione dei tag: per sfruttare appieno i vantaggi dei tag, occorre un po’ di disciplina. Primo, definire un catalogo di tag aziendale: una lista di tag ammessi (e significato di ciascuno) e possibilmente dei valori permessi. Ad esempio, stabilire che si userà il tag Environment con valori standardizzati Dev, Test, Prod, UAT (anziché lasciare libertà totale, che porta a varianti come “Production” scritto per esteso, “PROD” tutto maiuscolo, ecc.). Oppure decidere che il tag CostCenter deve contenere un codice numerico di 3 cifre corrispondente ai centri di costo interni. Queste convenzioni dovrebbero essere comunicate a tutti i team che operano su Azure.
In parallelo, è utile implementare controlli di conformità sui tag stessi: ad esempio, si possono usare Azure Policy che verificano la correttezza dei tag (c’è una funzionalità per controllare che un tag assuma solo certi valori ammessi, oppure per aggiungere automaticamente un tag Owner con il nome di chi crea la risorsa, se non è specificato). Ciò previene errori di battitura o usi inconsistenzi dei tag.
Un altro punto è prevenire la proliferazione incontrollata di tag: Azure attualmente permette un massimo di 50 tag differenti su ogni risorsa, ma di fatto usarne troppi genera confusione. Meglio averne pochi ma ben pensati, e scoraggiare la creazione di tag superflui o ridondanti. Se un team vuole introdurre un nuovo tag, magari valutarne l’utilità a livello generale – forse un tag esistente può già coprire l’esigenza oppure conviene estendere il catalogo ufficiale.
Monitorare la copertura dei tag è altrettanto importante: ad esempio, creare un dashboard che mostri quanti server hanno il tag Owner compilato e quanti no, o quali sottoscrizioni hanno il 100% delle risorse taggate e quali invece ne hanno molte senza tag. Questo tipo di metriche aiuta a identificare dove la pratica del tagging non è ancora adottata correttamente, così da intervenire con formazione o con policy più stringenti.
Infine, integrare i tag nei processi: se si fanno attivare procedure automatiche o alert basati su tag (come nell’esempio di prima dove un alert scatta se c’è un tag specifico su una VM), si incoraggia l’uso consistente di quei tag perché se mancano certe automazioni non funzionerebbero. Ad esempio, se i team sanno che solo le VM con tag AutoShutdown=True verranno spente di notte, saranno motivati ad aggiungere quel tag alle VM di test per risparmiare costi; e se sanno che se non mettono Owner non arriveranno notifiche di problemi al giusto responsabile, ci faranno attenzione. Insomma, i tag funzionano meglio se diventano parte integrante dell’ecosistema di governance, anziché un semplice campo descrittivo facoltativo.
6. Conformità e standard
Molte organizzazioni che usano Azure hanno necessità di aderire a standard di conformità esterni (normative, certificazioni) o interni (policy aziendali, architetture di riferimento). La governance cloud deve includere anche questi aspetti, assicurando che l’ambiente Azure supporti e dimostri tale conformità. Azure offre numerosi strumenti in tal senso, integrati soprattutto nel servizio Microsoft Defender for Cloud.
Standard supportati da Azure: all’interno di Defender for Cloud c’è una sezione chiamata Regulatory Compliance dove è possibile selezionare e attivare diversi standard e framework di sicurezza. Microsoft mette a disposizione sia standard internazionali comuni, sia benchmark specifici per il cloud. Ad esempio, alcuni degli standard disponibili sono:
· ISO/IEC 27001 – lo standard internazionale per i sistemi di gestione della sicurezza informatica;
· PCI DSS – requisiti per la sicurezza dei dati delle carte di pagamento, obbligatorio ad esempio se si gestiscono transazioni con carte di credito;
· SOC 2 – criteri di sicurezza, disponibilità, integrità, riservatezza e privacy per servizi cloud, tipicamente richiesti in ambito audit finanziario;
· CIS Azure Foundations Benchmark – un insieme di raccomandazioni specifiche per Azure definito dal Center for Internet Security;
· NIST SP 800-53 – linee guida di sicurezza del governo USA, e così via.
Oltre a questi, di default Azure applica il Microsoft Cloud Security Benchmark (MCSB), che è un compendio delle best practice di sicurezza cloud suggerite da Microsoft stessa, e che funge anche da base per molti degli altri standard.
Valutazione automatica dei controlli: una volta selezionati gli standard rilevanti e associati alle proprie sottoscrizioni in Defender for Cloud, Azure effettua continuamente scansioni dell’ambiente per verificare i vari controlli previsti. Ogni standard infatti è composto da decine (a volte centinaia) di requisiti di sicurezza o configurazione. Per ciascuno, Azure controlla lo stato delle risorse: se il controllo è rispettato da tutte le risorse applicabili, viene segnato come passato; se ci sono violazioni, viene segnato come fallito (failed). Ad esempio, un controllo ISO 27001 potrebbe richiedere che tutti i dati sensibili siano criptati a riposo: Azure allora verifica se su tutti i database e storage account la crittografia è attivata; se anche uno solo non lo è, quel controllo risulta non conforme. Questi risultati sono visibili nella dashboard di Regulatory Compliance, con un punteggio complessivo per standard (ad esempio “Conformità ISO 27001: 75%” indica che il 75% di tutti i controlli di quello standard passano, il resto ha delle eccezioni da sanare). Per ogni controllo fallito, Defender for Cloud fornisce una raccomandazione dettagliata su cosa fare: cliccando sulla voce, si ottengono istruzioni e spesso script automatici (Fix It) per risolvere il problema. Ad esempio, per “VM senza endpoint firewall attivo”, Azure potrebbe offrire direttamente un pulsante per abilitare il firewall su quelle VM, oppure un link alla documentazione su come configurarlo.
Azure Policy e standard: un altro elemento importante è che molti di questi standard vengono forniti anche come Iniziative di Azure Policy predefinite. Ciò significa che l’azienda può decidere di assegnare tali iniziative al proprio ambiente, rendendo attivi i controlli: non solo saprà se è conforme o no, ma le policy agiranno per impedire o correggere le deviazioni. Ad esempio, l’iniziativa PCI DSS contiene policy che negano configurazioni non consentite dallo standard (come macchine virtuali senza antivirus, o storage account senza logging). Assegnando quell’iniziativa, l’azienda si assicura che da lì in avanti nessuno possa creare qualcosa di non conforme a PCI, perché Azure glielo impedirà immediatamente tramite la policy. Ovviamente, questo richiede attenzione: a differenza di Defender for Cloud che si limita a rilevare e segnalare, le policy possono impattare l’operatività bloccando operazioni. Quindi è opportuno testare queste iniziative in ambienti di staging prima di applicarle in produzione, oppure iniziare con l’effetto Audit (solo segnalazione) e poi passare a Deny quando si è certi.
Esempi di gestione della conformità:
· Un’azienda nel settore sanitario deve rispettare standard severi di sicurezza e privacy. Decide quindi di adottare CIS Benchmark e HIPAA/HITRUST (standard specifici per dati sanitari). Attiva questi due nel pannello di compliance. Dopo la prima scansione, vede che il suo punteggio CIS è solo del 60%: molti controlli non sono soddisfatti. Ad esempio, individua che “Tutte le VM devono avere la crittografia dei dischi abilitata” è marcato come failed perché alcune VM di test sono state create senza cifratura. Grazie alla raccomandazione associata, procede ad abilitare la crittografia su quelle VM. Un altro controllo CIS fallito segnala che su alcune subnet manca un Network Security Group (firewall): anche qui, il team segue le istruzioni e implementa gli NSG mancanti. Pian piano, risolve i vari gap e vede il punteggio di conformità salire. Inoltre, per prevenire regressioni, decide di assegnare l’iniziativa Azure Policy di CIS Benchmark su tutte le sottoscrizioni: così, se qualcuno tenta in futuro di creare una risorsa non allineata ai requisiti CIS, verrà bloccato o avvisato immediatamente.
· Un’altra organizzazione deve annualmente certificarsi ISO 27001. Sa che dovrà presentare auditor esterni un report di conformità. Azure semplifica questo compito: dopo aver lavorato per rimediare alle raccomandazioni di Defender for Cloud, il responsabile può generare direttamente dal portale un report CSV/PDF che elenca tutti i controlli ISO 27001 e lo stato di ciascuno (compliant / non compliant), includendo evidenza delle risorse fuori standard. Questo documento può essere usato come parte del materiale giustificativo per la certificazione. Inoltre, l’azienda crea con Azure Workbooks un pannello che mostra mese per mese l’evoluzione della conformità per vari standard, così da evidenziare trend (ad esempio se la conformità sta migliorando grazie agli interventi fatti o se nuovi problemi stanno emergendo).
Buone pratiche per conformità e governance normativa: il primo passo è mappare gli standard aziendali con quelli supportati da Azure. Microsoft ne offre molti, ma se ne servisse uno non presente, si possono sempre creare policy custom per coprirne i requisiti. È utile anche integrare il vantage point tecnologico di Azure con strumenti più ampi: Microsoft Purview Compliance Manager, ad esempio, permette di tracciare non solo la conformità tecnica (di cui Azure Defender si occupa) ma anche quella procedurale e documentale. In Compliance Manager si possono gestire controlli come “esiste un processo di backup documentato” o “il personale ha ricevuto formazione annuale sulla sicurezza”: cose che Azure da solo non conosce, ma che completano il quadro della conformità. Centralizzare i risultati di Azure e di altre fonti in un unico sistema di record aiuta ad avere un quadro complessivo per gli auditor e per gli stakeholder interni.
Un’altra best practice è fare in modo che le policy interne riflettano gli standard esterni: ad esempio, se la regolamentazione impone l’uso di crittografia, assicurarsi di avere sempre una Azure Policy attiva che richiede la crittografia sulle risorse pertinenti; se uno standard raccomanda pen test periodici, definire in Azure Policy eventuali parametri che segnalino risorse non scansionate di recente, e così via. In pratica, usare gli strumenti di governance per codificare quanto più possibile i requisiti normativi.
L’automazione è importante: quando i controlli segnalano problemi, conviene avere già predisposto chi se ne occupa e come. Ad esempio, se un controllo di compliance critica fallisce (es: un gateway storage è aperto all’Internet pubblico quando non dovrebbe), si potrebbe attivare subito un runbook che chiude quell’endpoint, o almeno innescare un alert critico al Security Operations Center. Non aspettare il prossimo audit per correggere, ma reagire in tempo quasi reale.Infine, la conformità va gestita come un progetto continuo: nominare owner responsabili per area di conformità (es: uno per le reti, uno per i dati, uno per le identità) in modo che sia chiaro chi deve seguire le raccomandazioni in quei domini e chi deve prendere decisioni su eventuali risk acceptance (accettazione del rischio se si decide consapevolmente di non implementare un controllo per qualche ragione). La governance efficace è collaborazione tra i team tecnici, legali e di compliance, e Azure fornisce gli strumenti per rendere oggettivo e monitorabile lo stato di conformità tecnica in ogni momento.
7. Monitoraggio, audit e alert
Abbiamo visto come impostare regole e controlli; un altro pilastro della governance è sorvegliare l’ambiente e poter reagire rapidamente agli eventi critici. Azure fornisce meccanismi di monitoraggio continuo, logging e notifiche (alert) che permettono ai team di mantenere il polso della situazione e di intervenire prima che piccoli problemi diventino grandi impatti.
Activity Log e audit trail: ogni azione amministrativa o operazione sulle risorse Azure lascia una traccia nell’Activity Log della sottoscrizione. Questo log registra eventi come la creazione o cancellazione di una VM, la modifica di una configurazione di rete, l’assegnazione di un ruolo RBAC, l’applicazione di una policy, e così via. Per ciascun evento, vengono registrati timestamp, chi (utente o identità) lo ha compiuto, l’esito (successo/fallimento) e alcuni dettagli. L’Activity Log relativo agli ultimi 90 giorni è consultabile nel portale o via API, e rappresenta la base per qualsiasi audit: in caso di incidente di sicurezza o malfunzionamento, analizzare questi log aiuta a capire la sequenza di azioni che hanno portato alla situazione attuale. Per conservare gli audit log oltre 90 giorni (magari per obblighi di compliance o per analisi storica), si può configurare l’inoltro a un Log Analytics Workspace di Azure Monitor, dove potranno essere mantenuti per periodi più lunghi (anche anni) o esportati per archiviazione. Attraverso Azure Monitor, questi log possono essere analizzati usando il linguaggio KQL (Kusto Query Language), potente per filtrare e aggregare informazioni. Ad esempio, si può interrogare: “mostrami tutti i delete negli ultimi 6 mesi sulla sottoscrizione X” oppure “quante volte l’utente Y ha pubblicato un Azure Resource Manager template questo mese”. Ciò fornisce una comprensione profonda delle attività sull’ambiente.
Monitoraggio delle risorse e metriche: oltre alle operazioni amministrative, Azure raccoglie metriche e log di runtime per i servizi (CPU delle VM, utilizzo memoria, richieste su un’app, letture/scritture su un database, ecc.). Questi dati fanno parte di Azure Monitor e possono essere visualizzati in tempo reale e storicizzati. Per la governance, monitorare alcune di queste metriche può essere importante: ad esempio, tenere d’occhio il tasso di errore nelle distribuzioni (se molte VM falliscono il provisioning, c’è un problema di piattaforma o configurazione da investigare), oppure tracciare la crescita di utilizzo di storage (per pianificare espansioni e costi), o monitorare il numero di risorse per tipo (per capire se l’ambiente sta scalando oltre le previsioni).
Alert: il sistema di allerta di Azure permette di definire delle regole – basate su log o metriche – tali per cui, quando certe condizioni sono vere, venga generato un avviso attivo. Gli alert sono estremamente configurabili: possono coprire dagli aspetti infrastrutturali (es. CPU di una VM, coda di servizio che cresce troppo, ecc.), a quelli di sicurezza (es. rilevamento di una minaccia da Defender for Cloud), fino a quelli di governance (es. superamento di budget, o rilevamento di risorsa non taggata). Ogni regola di alert può essere associata a uno o più Action Group, ovvero insiemi di azioni da intraprendere quando l’alert scatta: tipicamente invio di email, ma anche SMS, chiamate webhoook o integrazione con sistemi di gestione incident aziendali (ServiceNow, PagerDuty, ecc.).
Ecco alcuni esempi di alert utili in ottica governance:
· Errori di distribuzione: impostare un alert che si attiva quando un deployment di Azure Resource Manager fallisce (magari perché una policy ha bloccato la creazione, o per un errore di template). Questo notifica immediatamente i team se il rilascio di nuove risorse non va a buon fine, così possono correggere il problema.
· Violazione di policy critiche: ad esempio, se esiste una policy che blocca la creazione di risorse senza tag Environment, potremmo creare un alert che ogni volta che quella policy registra un evento Deny ne avvisa gli amministratori. Così si può contattare l’utente e istruirlo su come procedere correttamente (o verificare se stava tentando qualcosa che evidenzia una nuova necessità).
· Raggiungimento soglie di spesa: come già trattato, definire alert di budget è fondamentale per non avere sorprese finanziarie. Questi alert informano i referenti che la spesa sta eccedendo il previsto, permettendo di intervenire (es. bloccare ambienti di test, ottimizzare risorse, etc.).
· Eventi di sicurezza: Azure Defender genera i suoi alert in caso rilevi comportamenti anomali (es: una VM che inizia a fare scanning di porte in rete, segno di compromissione). È buona norma che tali alert siano indirizzati verso il SOC (Security Operations Center) o chi segue la sicurezza. Allo stesso modo, un alert manuale può essere definito, ad esempio, per notificare se qualcuno disabilita il firewall di una base dati o apre una porta molto sensibile in un NSG, operazioni che al di là del rispetto delle policy potrebbero indicare un rischio.
Audit continuo e integrazione con la governance: per un efficace controllo, l’ideale è costruire dashboard di monitoraggio che diano una vista d’insieme dello stato di governance. Ad esempio, un cruscotto che mostri: numero di risorse totali e quante non taggate, percentuale di compliance alle policy, numero di alert critici aperti, costo mensile vs budget, e simili indicatori. Azure Monitor e Azure Dashboards permettono di aggregare widget da varie fonti (incluso Defender for Cloud) per creare queste viste riepilogative. In aggiunta, Azure Workbooks offre modelli interessanti per la Cloud Governance: ad esempio, c’è un workbook che presenta statistiche sul tagging, sulle policy, ed evidenzia i top 10 errori/alert. Questi strumenti aiutano a trasformare i dati grezzi di log e metriche in insight azionabili dai responsabili.
Buone pratiche per il monitoraggio e gli alert: definire troppi alert può diventare controproducente se non calibrati bene. È preferibile iniziare impostando alert su situazioni veramente importanti (signal-to-noise ratio alto) e poi eventualmente raffinarli. Ad esempio:
· Scegliere soglie sensate per metriche: un alert CPU > 80% su una VM potrebbe andare bene, ma su un’altra VM 80% potrebbe essere normale; quindi adeguare soglia e durata della condizione per evitare falsi positivi.
· Utilizzare le regole di soppressione o di gestione avanzata: Azure consente, ad esempio, di evitare di ricevere 100 alert identici se un evento si ripete molte volte in poco tempo, consolidandoli. Bisogna configurarlo opportunamente per non essere sommersi da email ripetitive.
· Fare regolarmente triage degli alert: controllare quali alert scattano più spesso e valutare: sono tutti necessari? Hanno qualcuno che li prende in carico? Se un certo tipo di alert viene sempre ignorato, o va migliorata la sua definizione o non è davvero utile.
· Organizzare gli Action Group con cura: ad esempio, per gli alert di sicurezza è utile che inviino email magari a una lista di distribuzione del team sicurezza e contemporaneamente aprano un ticket su un sistema di incident management. Per alert operativi (es. CPU alta), magari basta un’email al team DevOps di riferimento del servizio colpito. Distinguere i canali evita che persone ricevano alert irrilevanti o che, all’opposto, alert importanti passino inosservati perché arrivano a troppi destinatari generici.
Anche i log (Activity Log, Log Analytics) vanno protetti: è consigliato attivare la retention adeguata (molti standard richiedono di mantenere i log di audit per almeno 6-12 mesi), e limitare chi può cancellare o modificare log. Azure permette per esempio di archiviare in modo immutabile certi dati (log immutabili) per evitare manomissioni. Inoltre, assicurarsi che i log critici (come quelli di sicurezza) siano centralizzati: magari inviati anche a un SIEM esterno se l’azienda ne ha uno, così da incrociare eventi di Azure con quelli on-premises.
In conclusione, un monitoraggio e alerting ben impostato funge da sistema nervoso della governance: rileva immediatamente eventuali anomalie (sia tecniche che di policy) e attiva i riflessi dell’organizzazione per rispondere. È ciò che consente di passare da una governance statica (“abbiamo scritto delle regole”) a una governance dinamica e proattiva (“vediamo in tempo reale se le regole vengono seguite e agiamo se qualcosa devia”).
8. Automazione della governance
Un ambiente ben governato idealmente dovrebbe autogovernarsi il più possibile, reagendo automaticamente a determinati eventi o correggendo situazioni fuori standard senza richiedere sempre l’intervento umano. In Azure, vari servizi permettono di implementare l’automazione di compiti amministrativi e di enforcement della governance.
Strumenti di automazione in Azure:
· Azure Automation Account: fornisce un ambiente in cui creare Runbook, ovvero script (in PowerShell, Python, o grafiche con logica dichiarativa) che possono svolgere praticamente qualsiasi operazione sulle risorse Azure (e anche su sistemi esterni, volendo). I runbook possono essere eseguiti manualmente, schedulati a intervalli regolari oppure attivati da webhook/API. Questo servizio è spesso usato per compiti ricorrenti di manutenzione, backup, cleanup o integrazione tra sistemi.
· Event Grid e Automazione eventi: Azure Event Grid consente di intercettare eventi provenienti da vari servizi Azure (ad esempio “una macchina virtuale è stata creata” o “un nuovo log di alert è disponibile”) e innescare azioni di conseguenza. Combinando Event Grid con Azure Functions o Logic Apps, si possono costruire workflow serverless che reagiscono agli eventi del cloud.
· Automation nativa di Azure Policy (Remediation): come accennato in precedenza, Azure Policy stessa può lanciare deployment di correzione quando trova risorse non conformi, se tale opzione è configurata. Ad esempio, se una policy segnala che mancano degli agent di monitoraggio su alcune VM, si può associare un’azione correttiva che installa automaticamente l’agente sulle VM in questione. Questo è un tipo di automazione molto mirata e integrata nel sistema di policy.
· Altri servizi: anche servizi come Azure Logic Apps (automazione tramite workflow low-code) possono essere utili per scenari di governance, ad esempio per creare flussi di approvazione (richiesta di elevare permessi, approvazione manuale, etc.), oppure per integrazioni con database o applicazioni esterne (invia notifica su Teams, scrivi su una lista SharePoint degli accessi concessi, ecc.).
Esempi di automazione della governance:
· Auto-tagging: se per qualche ragione non si vuole fare tutto con Azure Policy, si può scrivere un runbook che periodicamente analizza tutte le nuove risorse create nell’ultimo giorno e assegna loro i tag mancanti basandosi su certe regole (ad esempio tagga automaticamente con Environment=Prod se stanno in una sottoscrizione di produzione, ecc.). Questo script poi può essere eseguito ogni notte per garantire che il tagging sia sempre applicato.
· Gestione orari delle VM: molto gettonata è l’automazione di accensione/spegnimento di macchine virtuali. Attraverso runbook schedulati, si può risparmiare sui costi spegnendo fuori orario di ufficio i server di test o di sviluppo, e riaccendendoli al mattino. Microsoft fornisce anche soluzioni preconfezionate (come i Start/Stop VM solutions nel Automation Account) per configurare facilmente questi orari.
· Remediation di sicurezza: consideriamo il punto di prima, manca un Private Endpoint su uno storage account considerato sensibile. Potrei avere un runbook che, quando chiamato con il nome di quello storage account, crea automaticamente un Private Endpoint associato alla rete aziendale. Potrei allora collegare questo runbook a un alert: se viene generato un alert “Storage senza private endpoint”, il runbook parte e risolve il problema in autonomia entro pochi minuti, riportando la risorsa in compliance. All’amministratore arriverebbe magari solo la notifica che c’era un problema ma è stato risolto automaticamente.
· Deployment continuo di baseline: un altro scenario è mantenere consistentemente applicate certe configurazioni. Immaginiamo di avere un set di policy che per qualche motivo tendono ad essere rimosse o disabilitate per errore umano: potrei creare un workflow automatico che ogni settimana re-applica quell’iniziativa di policy su tutti gli scope dove deve stare, assicurandomi che eventuali rimozioni vengano sanate (questo più che altro come safety net contro modifiche errate).
· Reazione ad alert di budget: come suggerito prima, supponiamo un alert segnali che la spesa sta sforando. Oltre a notificare le persone, potremmo avere un’automazione che riduce la capacità di cluster di test, o mette in pausa servizi non essenziali se il budget è in pericolo. Chiaramente queste azioni vanno ponderate per non causare disservizi, ma in ambienti non critici possono essere soluzioni utili per tenere i costi in riga.
Buone pratiche per l’automazione: trattandosi di scrivere codice o configurazioni, l’automazione va affrontata con lo stesso rigore che si avrebbe per il software in produzione. Quindi:
· Versionamento e test: mantenere gli script in un repository (GitHub, Azure DevOps) per avere controllo delle versioni, fare code review se il team è multiplo e tracciare le modifiche. Testare i runbook in ambienti di prova prima di attivarli in produzione: un runbook mal scritto potrebbe cancellare risorse sbagliate o creare disservizi, quindi vanno provati con attenzione. Azure Automation consente di avere vari runbook (bozza vs pubblicato) per facilitare questo iter.
· Credenziali sicure: i runbook spesso hanno bisogno di autenticarsi sulle risorse Azure (se girano all’interno di Azure Automation nel cloud, possono usare l’identità del Automation Account stesso). Meglio evitare di inserire credenziali statiche in chiaro nello script; al posto, come già detto, usare una Managed Identity per il Automation Account e assegnarle i ruoli minimi necessari (es: se un runbook deve solo spegnere/accendere VM, dargli Contributor sulle VM ma non su altro). Oppure, se serve proprio usare account con password, memorizzarle in un Credential Asset cifrato nell’Automation Account o in Key Vault e leggerle da lì, così non compaiono mai in testo semplice.
· Logging delle esecuzioni: assicurarsi che ogni esecuzione di runbook lasci traccia. Azure Automation di base registra se un job è stato eseguito con successo o errori, ma è utile che lo script produca output dettagliato in log (magari scrivendo su un Log Analytics Workspace le operazioni fatte, o inviando un resoconto via email a un indirizzo dedicato). Questo aiuta in fase di debugging se qualcosa va storto e in generale per mantenere la tracciabilità: in futuro, capire se un certo cambiamento su una risorsa è avvenuto per mano di un umano o per via di un’automazione, ecco che i log dello script lo possono chiarire.
· Coordinazione con policy e blueprint: l’automazione non deve contraddire o sovrapporsi in modo incoerente ad altri meccanismi di governance. Ad esempio, se ho una policy che nega macchine in una regione, non avrebbe senso avere un runbook che sposta macchine in quella regione. Oppure, se un blueprint definisce certe risorse, non creare un runbook che modifica manualmente quelle stesse risorse in modo divergente. Invece, l’automazione dovrebbe completare la governance: fare ciò che non è staticamente definibile a priori. Un buon approccio è usare l’automazione per rimorchiare gli eventi: lasciare che blueprint e policy impostino il quadro, e intervenire con script quando c’è una deviazione o una necessità operativa (es. pulizia periodica, azioni su evento di alert, etc.).
In definitiva, l’automazione nella governance Azure consente di scalare le operazioni di controllo senza dover aumentare linearmente il personale: più l’ambiente cresce, più regole e check automatici lavorano in background per mantenerlo sano. Ciò libera il team IT da tanti interventi manuali ripetitivi, permettendo loro di concentrarsi su attività a maggior valore aggiunto (come migliorare ulteriormente le regole, analizzare trend, ottimizzare costi e performance). Implementare l’automazione richiede investimento iniziale, ma ripaga in consistenza e affidabilità operativa nel lungo periodo.
ConclusioniIn questo capitolo abbiamo esplorato i principali concetti e strumenti legati alla governance in Azure: dall’organizzazione gerarchica delle risorse con i Management Group, alla definizione e imposizione di regole con Azure Policy e Blueprints; dalla gestione degli accessi con RBAC, al controllo dei costi con budget e tag; dalla conformità a standard di sicurezza, al monitoraggio attivo con log e alert, fino all’automazione delle attività ripetitive. Ciò che emerge è che la governance efficace non è un singolo prodotto, ma un insieme integrato di pratiche e tecnologie che lavorano all’unisono.
Azure fornisce la piattaforma e gli strumenti per implementare questi controlli in profondità, ma la strategia di governance deve essere progettata tenendo conto degli obiettivi e delle esigenze specifiche dell’organizzazione. Per gli studenti e i professionisti che si avvicinano a questi temi, è importante capire che ogni elemento ha il suo ruolo: i Management Group e la suddivisione delle sottoscrizioni danno struttura, le Policy definiscono i confini tecnici, i ruoli RBAC regolano chi può operare, i tag legano le risorse ai contesti aziendali, la conformità e il monitoraggio assicurano uno sguardo vigile sullo stato del sistema, e l’automazione mantiene tutto funzionante senza sforzo manuale costante.
Applicare una buona governance in Azure significa poter innovare e utilizzare i servizi cloud in modo rapido e fluido, senza però mai perdere il controllo sugli aspetti cruciali di sicurezza, qualità e costo. In altri termini, la governance è ciò che consente al cloud di essere una risorsa e non un rischio per l’azienda. Con le conoscenze di base fornite da questo ebook, si è pronti per approfondire ogni argomento specifico e passare dalla teoria alla pratica, configurando ambienti Azure che siano non solo funzionali, ma anche ben governati sin dal primo giorno.
Riepilogo capitolo
Il documento fornisce una panoramica dettagliata degli strumenti e delle pratiche per la governance efficace di ambienti Azure, coprendo l'organizzazione, la sicurezza, la conformità, il controllo dei costi, il monitoraggio e l'automazione.
· Management Group per organizzazione gerarchica: I Management Group consentono di strutturare più sottoscrizioni Azure in una gerarchia che riflette l'organizzazione aziendale, facilitando l'applicazione centralizzata di policy e ruoli RBAC che si propagano automaticamente alle risorse sottostanti, migliorando coerenza e controllo.
· Azure Policy per conformità automatica: Le Azure Policy definiscono regole di configurazione e compliance da applicare a risorse o azioni, con effetti come Deny, Audit, Modify e Append, permettendo di mantenere standard aziendali e di sicurezza in modo automatico e continuo.
· Azure Blueprints per ambienti standardizzati: I Blueprints combinano policy, ruoli, template e strutture di Resource Group in modelli riutilizzabili e versionabili per distribuire ambienti Azure coerenti e conformi, facilitando provisioning rapido e gestione del ciclo di vita degli ambienti.
· RBAC per controllo degli accessi: Il Role-Based Access Control permette di assegnare permessi granulari a utenti, gruppi e identità di servizio su specifici scope, applicando il principio del minimo privilegio e facilitando la separazione dei compiti, con supporto a ruoli predefiniti e personalizzati.
· Gestione dei costi e budget: Azure Cost Management offre strumenti per monitorare la spesa, definire budget con soglie di allarme, analizzare i costi per tag o risorse, e suggerire ottimizzazioni come istanze riservate o spegnimento automatico, supportando la responsabilizzazione finanziaria.
· Tag per organizzazione e tracciabilità: I tag sono etichette chiave-valore applicate alle risorse che facilitano la categorizzazione trasversale, il controllo delle policy, l'allocazione dei costi e l'automazione operativa, con best practice che includono cataloghi standardizzati e controlli di conformità.
· Conformità e standard normativi: Azure Defender for Cloud e Azure Policy supportano la valutazione continua della conformità a standard come ISO 27001, PCI DSS e CIS Benchmark, con reportistica, raccomandazioni e possibilità di enforcement automatico tramite policy, integrando anche strumenti di compliance più ampi.
· Monitoraggio, audit e alert: Azure fornisce logging dettagliato delle attività, metriche di performance, e sistemi di alert configurabili per rilevare anomalie, violazioni di policy o superamenti di budget, con integrazione a sistemi di incident management e best practice per evitare sovraccarico di notifiche.
· Automazione della governance: Servizi come Azure Automation, Event Grid, e le funzionalità di remediation di Azure Policy permettono di automatizzare attività di tagging, gestione risorse, correzione di non conformità e risposte ad alert, migliorando efficienza e consistenza della governance con controlli di versione e sicurezza.
PROGETTO FINALE – Realizzazione di un e-commerce
Checklist
1. Crea scatole (Management Groups e Resource Groups).
2. Dai nomi e tag.
3. Metti regole di sicurezza (Entra ID, MFA).
4. Crea Key Vault per le chiavi.
5. Attiva Defender for Cloud.
6. Crea le reti (hub e spoke) e collega tutto.
7. Crea Storage per immagini.
8. Crea Database SQL.
9. Crea App Service per il sito.
10. Crea VM se serve.
11. Attiva Monitor e alert.
12. Controlla i costi.
1. Prepariamo della scatola dove mettere le cose (Governance)
Questa parte serve per organizzare tutto prima di creare le risorse. Così non ci perdiamo e tutto sarà ordinato e sicuro.
1.1 Vai sul portale Azure
· Apri il browser.
· Scrivi: https://portal.azure.com.
· Fai login con il tuo account aziendale.
1.2 Crea i “Management Groups” (gruppi di gestione)
· Nel menu a sinistra, cerca Management Groups.
· Clicca Crea.
· Scrivi il nome:
o mg-root (radice, il gruppo principale).
· Poi crea altri due gruppi:
o mg-prod (per produzione).
o mg-nonprod (per test e sviluppo).
· Conferma cliccando Crea ogni volta.
1.3 Sposta le Subscription nei gruppi
· Vai su Management Groups.
· Seleziona mg-prod.
· Clicca Aggiungi Subscription.
· Scegli la Subscription che userai per il sito e-commerce.
· Fai lo stesso per mg-nonprod (se hai ambienti di test).
1.4 Applica le regole (Policy)
· Cerca Azure Policy nel portale.
· Clicca Definizioni → Assegna Policy.
· Scegli regole semplici:
o Regione consentita (es. West Europe).
o Tag obbligatori (es. env, service, owner).
o Blocca risorse senza Private Endpoint.
· Applica queste regole al gruppo mg-prod.
1.5 Decidi i nomi e i tag
· Regola dei nomi (semplice e chiara):
o Resource Group front-end: rg-ecom-fe.
o Resource Group dati: rg-ecom-data.
o Resource Group rete: rg-ecom-net.
o Resource Group sicurezza: rg-ecom-sec.
· Tag da mettere SEMPRE:
o env=prod
o service=ecommerce
o owner=IT
o costCenter=1234.
1.6 Controlla chi può fare cosa (RBAC)
· Vai su Microsoft Entra ID.
· Crea gruppi:
o AppOps (gestisce il sito).
o NetOps (gestisce la rete).
o SecOps (gestisce la sicurezza).
· Vai su ogni Resource Group e assegna i permessi:
o AppOps → Contributor su rg-ecom-fe.
o NetOps → Network Contributor su rg-ecom-net.
o SecOps → Security Reader su rg-ecom-sec.
· Attiva MFA (codice sul telefono) per tutti.
1.7 Metti il salvadanaio per le chiavi (Key Vault)
· Vai su Key Vault → Crea.
· Nome: kv-ecom.
· Metti dentro le password e le chiavi (es. connessione SQL).
· Blocca accesso pubblico → usa Private Endpoint.
2. Attribuiamo le etichette agli oggetti per riconoscerli (Naming e Tag)
Le etichette servono per riconoscere subito le cose e per non fare confusione. Se dai nomi chiari e metti i tag giusti, sarà tutto ordinato e facile da trovare.
2.1 Vai sul portale Azure
· Apri il browser.
· Scrivi: https://portal.azure.com.
· Fai login con il tuo account.
2.2 Decidi i nomi prima di creare le risorse
· Regola semplice:
o RG = Resource Group
o FE = Front-End (il sito)
o DATA = Dati (database e storage)
o NET = Rete
o SEC = Sicurezza
Esempi di nomi:
· rg-ecom-fe → per il sito web.
· rg-ecom-data → per database e immagini.
· rg-ecom-net → per la rete.
· rg-ecom-sec → per sicurezza e chiavi.
2.3 Metti i tag (etichette digitali)
I tag sono come post-it che dicono cosa è quella risorsa.
Tag da mettere SEMPRE:
· env=prod → ambiente di produzione.
· service=ecommerce → servizio e-commerce.
· owner=IT → chi lo gestisce.
· costCenter=1234 → codice per i costi.
2.4 Come si fa sul portale
· Quando crei una risorsa (es. App Service, Storage, SQL), nella schermata di creazione c’è la sezione Tag.
· Clicca Aggiungi tag.
· Scrivi:
o Nome: env → Valore: prod.
o Nome: service → Valore: ecommerce.
o Nome: owner → Valore: IT.
o Nome: costCenter → Valore: 1234.
· Fai Salva.
2.5 Imposta una regola per obbligare i tag
· Vai su Azure Policy.
· Cerca Require tag.
· Clicca Assegna.
· Scegli il gruppo mg-prod.
· Così, se qualcuno dimentica i tag, Azure non fa creare la risorsa.
3. Chi può entrare? (Sicurezza e Utenti)
Questa parte serve per decidere chi può toccare cosa. Così nessuno fa pasticci e tutto è sicuro.
3.1 Vai sul portale Azure
· Apri il browser.
· Scrivi: https://portal.azure.com.
· Fai login con il tuo account.
3.2 Apri Microsoft Entra ID
· Nel menu a sinistra, cerca Microsoft Entra ID (prima si chiamava Azure AD).
· Clicca per entrare.
3.3 Crea i gruppi di persone
· Vai su Gruppi → Nuovo gruppo.
· Tipo: Sicurezza.
· Nome gruppo:
o AppOps → chi gestisce il sito.
o NetOps → chi gestisce la rete.
o SecOps → chi controlla la sicurezza.
· Clicca Crea per ogni gruppo.
3.4 Metti le persone nei gruppi
· Apri il gruppo AppOps.
· Clicca Membri → Aggiungi membri.
· Scegli le persone giuste.
· Fai lo stesso per NetOps e SecOps.
3.5 Dai i permessi giusti (RBAC)
· Vai su Resource Groups.
· Apri rg-ecom-fe (front-end).
· Clicca Controllo di accesso (IAM).
· Clicca Aggiungi ruolo.
· Scegli Contributor.
· Seleziona il gruppo AppOps.
· Fai Salva.
· Ripeti:
o rg-ecom-net → ruolo Network Contributor per NetOps.
o rg-ecom-sec → ruolo Security Reader per SecOps.
3.6 Attiva la protezione extra (MFA)
· Torna in Microsoft Entra ID.
· Vai su Sicurezza → Autenticazione multifattore.
· Attiva MFA per tutti (così serve il codice sul telefono oltre alla password).
3.7 Metti regole di accesso (Conditional Access)
· Vai su Sicurezza → Accesso condizionale.
· Crea una regola:
o Nome: Accesso sicuro Azure.
o App: Azure Management.
o Condizione: solo da IP aziendali o dispositivi conformi.
· Clicca Crea.
4. Costruiamo una cassaforte per custodire le chiavi (Key Vault)
Il Key Vault è come una cassaforte digitale dove mettiamo le password, le chiavi e i segreti. Così nessuno li vede e sono al sicuro.
4.1 Vai sul portale Azure
· Apri il browser.
· Scrivi: https://portal.azure.com.
· Fai login con il tuo account.
4.2 Cerca Key Vault
· Nel menu in alto, scrivi Key Vault.
· Clicca Crea.
4.3 Scegli dove metterlo
· Subscription: scegli quella di produzione.
· Resource Group: seleziona rg-ecom-sec (quello della sicurezza).
· Nome: scrivi kv-ecom.
· Regione: scegli la stessa del resto (es. West Europe).
4.4 Imposta la sicurezza
· Attiva Soft Delete e Purge Protection (così non si cancella per sbaglio).
· Blocca accesso pubblico:
o Vai su Networking.
o Metti Deny public network access.
· Aggiungi Private Endpoint:
o Clicca Aggiungi Private Endpoint.
o Scegli la subnet di sicurezza (es. sec-subnet).
o Conferma.
4.5 Metti dentro i segreti
· Dopo che il Key Vault è creato, aprilo.
· Vai su Secrets → Generate/Import.
· Nome: SQL-Connection.
· Valore: incolla la stringa di connessione del database.
· Fai Crea.
· Ripeti per altre chiavi (es. Storage, API Key).
4.6 Dai permessi giusti
· Vai su Access policies (o RBAC se hai scelto quello).
· Aggiungi il gruppo AppOps con permesso Get (per leggere i segreti).
· Fai Salva.
5. Costruiamo un sistema di difesa (Defender for Cloud)
Questa parte serve per proteggere tutto: il sito, il database, le macchine e i dati. Defender for Cloud è come un poliziotto che controlla se tutto è sicuro.
5.1 Vai sul portale Azure
· Apri il browser.
· Scrivi: https://portal.azure.com.
· Fai login con il tuo account.
5.2 Cerca Defender for Cloud
· Nel menu in alto, scrivi Defender for Cloud.
· Clicca per entrare.
5.3 Attiva la protezione
· Clicca Impostazioni → Piani.
· Attiva:
o Defender for Servers (per le VM).
o Defender for Databases (per SQL).
o Defender for Storage (per Blob e Files).
o Defender for App Service (per il sito).
· Conferma.
5.4 Controlla il punteggio di sicurezza
· Vai su Secure Score.
· Guarda il numero (più alto è, meglio è).
· Se è basso, clicca sulle raccomandazioni.
5.5 Segui i consigli
· Esempi di consigli:
o Attiva MFA per tutti.
o Blocca accesso pubblico ai database.
o Aggiorna le VM.
· Clicca Correggi dove serve.
5.6 Metti gli avvisi
· Vai su Impostazioni di avviso.
· Crea regole per:
o Accessi strani.
o File sospetti.
o VM senza patch.
· Scegli dove mandare gli avvisi (email o Teams).
5.7 Collega al SIEM (opzionale)
· Se vuoi controllare tutto in un posto, collega a Microsoft Sentinel.
· Vai su Impostazioni → SIEM → Connetti.
6. Costruiamo le strade che collegano le risorse (Rete)
La rete è come le strade che collegano le case (le risorse). Se le strade sono sicure e ben fatte, tutto funziona senza problemi.
6.1 Vai sul portale Azure
· Apri il browser.
· Scrivi: https://portal.azure.com.
· Fai login con il tuo account.
6.2 Crea la rete principale (Hub)
· Cerca Virtual Network.
· Clicca Crea.
· Nome: vnet-hub.
· Indirizzo: 10.0.0.0/16 (è come il quartiere).
· Aggiungi subnet:
o AzureFirewallSubnet → per il firewall.
o GatewaySubnet → per la VPN.
o BastionSubnet → per entrare nelle VM senza IP pubblico.
· Fai Crea.
6.3 Crea le reti secondarie (Spoke)
· Ripeti la stessa cosa per:
o vnet-spoke-fe (per il sito) → indirizzo 10.1.0.0/16.
§ Subnet: fe-app (per App Service), fe-pe (per Private Endpoints).
o vnet-spoke-data (per i dati) → indirizzo 10.2.0.0/16.
§ Subnet: data-pe (per Private Endpoints), vm-data (per VM dati).
· Fai Crea.
6.4 Collega le reti (Peering)
· Vai su vnet-hub.
· Clicca Peering → Aggiungi.
· Collega vnet-spoke-fe e vnet-spoke-data al vnet-hub.
· Spunta Usa gateway remoto sugli spoke (così passano dal firewall).
6.5 Metti le regole (NSG)
· Vai su Network Security Groups → Crea.
· Nome: nsg-fe-app.
· Regole:
o Blocca tutto in ingresso.
o Permetti solo uscita verso Internet e Azure.
· Fai lo stesso per nsg-data-pe e nsg-vm-data:
o Permetti solo traffico interno e Bastion.
· Associa ogni NSG alla sua subnet.
6.6 Aggiungi Private Endpoints
· Vai su SQL Database → Networking → Private Endpoint.
· Crea un endpoint nella subnet data-pe.
· Fai lo stesso per Storage e Key Vault.
· Così nessuno accede da Internet.
6.7 Metti la VPN (opzionale)
· Vai su VPN Gateway → Crea.
· Collega la rete hub alla sede aziendale.
· Se vuoi più velocità, usa ExpressRoute.
7. Costruiamo il magazzino per i nostri oggetti (Storage)
Il magazzino è dove mettiamo le immagini, i file, le code e le tabelle. Così il sito e-commerce ha tutto quello che gli serve.
7.1 Vai sul portale Azure
· Apri il browser.
· Scrivi: https://portal.azure.com.
· Fai login con il tuo account.
7.2 Crea l’account di archiviazione
· Cerca Storage Account.
· Clicca Crea.
· Scegli:
o Subscription: quella di produzione.
o Resource Group: rg-ecom-data.
o Nome: stgimg-ecom.
o Regione: la stessa delle altre risorse (es. West Europe).
· Tipo: GPv2 (Generazione 2).
· Ridondanza: GZRS (alta sicurezza) o LRS (più economico).
· Fai Crea.
7.3 Blocca accesso pubblico
· Dopo che è creato, apri l’account.
· Vai su Networking.
· Metti Deny public network access.
· Aggiungi Private Endpoint:
o Clicca Aggiungi Private Endpoint.
o Scegli la subnet data-pe.
o Conferma.
7.4 Crea il contenitore per le immagini
· Vai su Container.
· Clicca + Container.
· Nome: product-images.
· Accesso: Privato (così nessuno entra senza permesso).
· Fai Crea.
7.5 Metti regole per i file vecchi (Lifecycle)
· Vai su Lifecycle Management.
· Clicca + Regola.
· Nome: sposta-file.
· Regola:
o Dopo 30 giorni → sposta da Hot a Cool.
o Dopo 180 giorni → sposta a Archive.
· Fai Salva.
7.6 Aggiungi altre cose (opzionale)
· Azure Files:
o Vai su File Shares.
o Clicca + File Share.
o Nome: fe-content.
o Serve per condividere file tra VM e app.
· Queue Storage:
o Vai su Queues.
o Clicca + Queue.
o Nome: img-jobs (per lavori come ridimensionare immagini).
· Table Storage:
o Vai su Tables.
o Clicca + Table.
o Nome: metadata (per info semplici).
8. Costruiamo il database per prodotti, ordini e clienti (SQL)
Il database è come un quaderno gigante dove scriviamo tutti i dati del sito e-commerce: prodotti, ordini, clienti. Deve essere sicuro e veloce.
8.1 Vai sul portale Azure
· Apri il browser.
· Scrivi: https://portal.azure.com.
· Fai login con il tuo account.
8.2 Cerca Azure SQL Database
· Nel menu in alto, scrivi SQL Database.
· Clicca Crea.
8.3 Scegli dove metterlo
· Subscription: quella di produzione.
· Resource Group: rg-ecom-data.
· Nome database: sql-ecom.
· Regione: la stessa delle altre risorse (es. West Europe).
8.4 Crea il server SQL
· Nella schermata di creazione, clicca Crea nuovo server.
· Nome: sqlsrv-ecom.
· Scegli un nome utente (es. adminsql).
· Metti una password sicura (scrivila in Key Vault!).
· Conferma.
8.5 Imposta il livello
· Scegli Basic se vuoi spendere poco (va bene per iniziare).
· Se il sito cresce, puoi passare a Standard o Premium.
8.6 Blocca accesso pubblico
· Vai su Networking.
· Metti Deny public network access.
· Aggiungi Private Endpoint:
o Clicca Aggiungi Private Endpoint.
o Scegli la subnet data-pe.
o Conferma.
8.7 Attiva la sicurezza
· Vai su Impostazioni di sicurezza.
· Controlla che TDE (cifratura) sia attiva (di solito è già attiva).
· Attiva Auditing (per registrare chi fa cosa).
· Attiva Advanced Threat Protection (ti avvisa se succede qualcosa di strano).
8.8 Salva la stringa di connessione
· Dopo che il database è pronto, vai su Connessioni.
· Copia la connection string.
· Vai su Key Vault.
· Metti la stringa come Secret (così l’App Service la prende in modo sicuro).
9. Costruiamo il sito: l’interfaccia utente dell’e-commerce (App Service)
L’App Service è la “casetta” dove vive il tuo sito. Gli diamo un nome, gli carichiamo il codice e lo colleghiamo in modo sicuro a database e storage.
9.1 Entra nel portale
· Apri il browser.
· Vai su https://portal.azure.com.
· Fai login.
9.2 Crea l’App Service (la casetta del sito)
1. In alto, cerca App Service.
2. Clicca Crea.
3. Compila:
o Subscription: quella di produzione.
o Resource Group: rg-ecom-fe.
o Nome app: app-ecom-web.
o Sistema operativo: Linux (va bene e costa meno).
o Regione: la stessa delle altre risorse (es. West Europe).
o Piano: inizia con B1 (Basic). Se il sito cresce, potrai aumentare.
4. Clicca Rivedi e crea → Crea.
9.3 Metti il sito in modalità “pacchetto” (più semplice da pubblicare)
· Apri la tua app app-ecom-web.
· Vai su Configurazione → Impostazioni applicazione.
· Clicca + Nuova impostazione.
· Nome: WEBSITE_RUN_FROM_PACKAGE
Valore: 1· Salva.
Così puoi caricare il sito come file ZIP o farlo prendere da GitHub senza confusione.
9.4 Carica il codice del sito
Opzione A – ZIP (semplicissima)
1. Vai su Deployment Center → Local Git/GitHub/ZIP.
2. Scegli ZIP → Carica → seleziona lo zip del tuo sito.
3. Clicca Salva.
Opzione B – GitHub (CI/CD automatico)
1. Vai su Deployment Center.
2. Scegli GitHub.
3. Seleziona Repository e branch.
4. Conferma: Azure pubblicherà ogni volta che fai “push”.
9.5 Accendi la sicurezza del sito
1. Vai su TLS/SSL settings → attiva Solo HTTPS.
2. Se hai un dominio personalizzato (es. shop.tuaazienda.it):
o Vai su Custom domains → Aggiungi → segui i passi (DNS CNAME/A).
o Carica il certificato (o usa App Service Managed Certificate se compatibile).
9.6 Collega il sito alla rete (per parlare in privato con SQL/Storage)
1. Vai su Networking → VNet Integration.
2. Clicca Aggiungi.
3. Scegli la subnet fe-app dentro vnet-spoke-fe.
4. Conferma.
Così il sito può raggiungere SQL, Storage e Key Vault solo tramite rete privata.
9.7 Blocca gli accessi non desiderati (Access Restrictions)
1. Vai su Networking → Access restrictions.
2. Aggiungi una regola Consenti solo da:
o Front Door / CDN (se lo usi),
o IP aziendali (se serve).
3. Metti una regola Nega come “tutto il resto”.
4. Salva.
9.8 Prendi le password in modo sicuro (Key Vault references)
1. Vai su Configurazione → Impostazioni applicazione.
2. Crea una nuova impostazione per la stringa del DB:
o Nome: SQLCONNSTR_ECOM
o Valore: metti il riferimento a Key Vault (il portale ti aiuta: “Aggiungi riferimento Key Vault”).
3. Fai lo stesso per eventuali chiavi di Storage o API.
4. Salva.
In questo modo, l’app non contiene password scritte in chiaro.
9.9 Controlla che il sito parli in privato con SQL e Storage
· Vai su SQL Database → Networking: accesso pubblico negato e Private Endpoint attivo (già fatto nel Punto 8).
· Vai su Storage Account → Networking: accesso pubblico negato e Private Endpoint attivo (già fatto nel Punto 7).
· Prova il sito: dovrebbe funzionare senza accesso pubblico ai dati.
9.10 Migliora velocità e protezione (opzionale)
· Front Door / CDN:
o Crea Azure Front Door per cache globale e WAF.
o Punta il tuo dominio al Front Door.
o Aggiungi la regola di Access restriction per accettare solo traffico da Front Door.
· Scalabilità automatica:
o Cambia il piano a Premium v3 se ti servono più istanze e autoscale.
9.11 Metti le “spie” per vedere se tutto va bene (log)
1. Vai su Diagnostica / App Service logs.
2. Attiva Application Logging e Access Logging.
3. Invia a Log Analytics (il workspace creato nel Punto 7/Monitor).
4. Torna in Azure Monitor e crea alert per:
o Errori 5xx,
o Tempo di risposta alto,
o Arresti anomali.
9.12 Prova il sito
· Clicca su Browse nella tua app.
· Apri la pagina: controlla immagini, login, carrello, pagamenti (se già configurati).
· Se qualcosa non va, guarda i log e gli alert.
10. Aggiungiamo un computer virtuale per le nostre operazioni (VM)
La VM è come un computer finto nel cloud. La usiamo per fare lavori speciali (per esempio, elaborare immagini o usare programmi “vecchi” che servono ancora).
10.1 Entra nel portale
· Apri il browser.
· Vai su https://portal.azure.com.
· Fai login.
10.2 Crea la macchina virtuale
1. Cerca Virtual Machines.
2. Clicca Crea → Macchina virtuale di Azure.
3. Compila:
o Subscription: produzione.
o Resource Group: rg-ecom-data (o rg-ecom-fe se ti serve vicino al sito).
o Nome: vm-imgproc-01.
o Regione: la stessa delle altre (es. West Europe).
o Immagine: Windows Server (se ti serve Windows) oppure Ubuntu (se preferisci Linux).
o Dimensione: scegli una misura piccola per iniziare (es. D2s_v5). Se ti serve grafica/CAD sceglierai una con GPU in futuro.
4. Credenziali:
o Crea un utente e una password (mettile anche in Key Vault).
5. Clicca Avanti.
10.3 Metti la VM dentro la rete giusta
1. Rete:
o VNet: vnet-spoke-data.
o Subnet: vm-data.
2. IP pubblico: Niente (metti “Nessuno”).
3. Porte aperte: Nessuna (non aprire RDP/SSH da Internet).
4. Clicca Avanti.
Così la VM è privata e protetta nella tua rete.
10.4 Dischi veloci e diagnostica
1. Disco OS: seleziona Premium SSD (più veloce).
2. Diagnostica di avvio: Attiva (così vedi i messaggi in caso di problemi).
3. Account di archiviazione per diagnostica: usa lo Storage che hai creato (Punto 7).
4. Clicca Avanti.
10.5 Sicurezza extra (Defender & aggiornamenti)
1. Defender for Cloud: lascialo attivo (ti protegge la VM).
2. Patch automatiche: attiva Update Management (così si aggiorna da sola).
3. Clicca Avanti.
10.6 Controllo accessi (NSG)
1. Se vedi Network Security Group (NSG):
o Scegli Usa NSG esistente e seleziona nsg-vm-data oppure
o Crea regole che bloccano tutto in ingresso.
2. Conferma.
10.7 Crea la VM
· Clicca Rivedi e crea → Crea.
· Attendi la fine del deployment.
10.8 Entra nella VM in modo sicuro (Bastion)
1. Vai sulla tua VM → Connetti → Bastion.
2. Se non ce l’hai, crea Azure Bastion nella rete hub (BastionSubnet).
3. Clicca Connetti:
o Per Windows: si apre RDP nel browser.
o Per Linux: si apre SSH nel browser.
4. Inserisci utente e password.
5. Ora sei dentro al “computer finto” senza usare Internet.
10.9 Installa quello che ti serve
· Dentro la VM:
o Installa il tuo programma (es. elaboratore di immagini).
o Collega le cartelle di Azure Files (dal Punto 7) se ti servono file condivisi.
o Configura l’app per leggere/scrivere su Blob Storage (con chiavi prese dal Key Vault).
10.10 Metti gli avvisi (se succede qualcosa)
1. Torna al portale → Azure Monitor.
2. Crea alert per la VM:
o CPU > 80%.
o Spazio disco basso.
o Errori di sistema.
3. Invia gli alert via email o Teams.
10.11 Risparmio sui costi (molto utile)
· Se la VM lavora sempre, valuta:
o Reserved Instances o Savings Plans (costano meno nel tempo).
· Se fa lavori ogni tanto, puoi:
o Spegnerla di notte (con Automation o Runbook).
o Usare Spot VM per lavori non critici (costano poco, ma possono fermarsi).
10.12 Alta disponibilità (se vuoi più affidabilità)
· Se il lavoro è importante:
o Metti la VM in Availability Zones (più resiliente).
o Oppure usa Scale Set (più VM uguali che si accendono da sole quando serve).
11. Teniamo tutto sotto controllo (Monitor)
Questa parte serve per tenere d’occhio il sito, il database, le VM e la rete. Se qualcosa va storto, Azure ti avvisa subito.
11.1 Vai sul portale Azure
· Apri il browser.
· Vai su https://portal.azure.com.
· Fai login.
11.2 Cerca Azure Monitor
· Nel menu in alto, scrivi Monitor.
· Clicca per entrare.
11.3 Crea il quaderno dei log (Log Analytics Workspace)
· Vai su Log Analytics Workspace → Crea.
· Nome: law-ecom.
· Resource Group: rg-ecom-sec.
· Regione: la stessa delle altre (es. West Europe).
· Clicca Crea.
11.4 Collega le risorse al quaderno
· Vai su ogni risorsa (App Service, VM, Storage, SQL).
· Cerca Diagnostica o Diagnostic settings.
· Clicca Aggiungi impostazione.
· Scegli Invia a Log Analytics.
· Seleziona il workspace law-ecom.
· Salva.
Così tutti i dati finiscono nello stesso posto.
11.5 Metti le spie (Alert)
· Vai su Monitor → Avvisi → Crea regola di avviso.
· Scegli la risorsa (es. App Service).
· Condizione:
o CPU > 80%.
o Errori 5xx.
o Tempo di risposta > 2 secondi.
· Azione:
o Email al team.
o Messaggio su Teams (se configurato).
· Fai Crea.
· Ripeti per VM (CPU, disco), SQL (latenza, errori), Storage (spazio).
11.6 Crea il cruscotto (Workbook)
· Vai su Monitor → Workbook → Nuovo.
· Aggiungi grafici:
o CPU App Service.
o Errori HTTP.
o Query SQL lente.
o Spazio Storage.
· Salva il workbook come Ecommerce-Dashboard.
11.7 Metti regole automatiche (opzionale)
· Vai su Automation o Logic Apps.
· Crea un flusso:
o Se CPU > 90% → manda messaggio su Teams.
o Se VM inattiva → spegnila per risparmiare.
12. Teniamo sotto controllo i costi (Cost Management)
Questa parte serve per controllare quanto spendi su Azure. Così non ti trovi sorprese e puoi risparmiare.
12.1 Vai sul portale Azure
· Apri il browser.
· Vai su https://portal.azure.com.
· Fai login.
12.2 Cerca Cost Management + Billing
· Nel menu in alto, scrivi Cost Management + Billing.
· Clicca per entrare.
12.3 Crea un budget
1. Vai su Cost Management → Budget.
2. Clicca + Crea budget.
3. Nome: Budget-Ecommerce.
4. Importo: scrivi quanto vuoi spendere al mese (es. 500 €).
5. Periodo: Mensile.
6. Clicca Avanti.
12.4 Metti gli avvisi
· Scegli quando ricevere avvisi:
o 80% → ti avvisa che stai quasi finendo.
o 100% → ti avvisa che hai finito il budget.
· Scegli dove mandare l’avviso:
o Email al tuo team.
o Teams (se configurato).
· Clicca Crea.
12.5 Guarda i grafici
· Vai su Analisi costi.
· Vedi:
o Quanto spendi per App Service.
o Quanto per SQL Database.
o Quanto per Storage.
o Quanto per VM.
· Puoi filtrare per Resource Group o Tag (es. env=prod).
12.6 Trova i consigli per risparmiare
· Vai su Advisor (lo trovi nel portale).
· Leggi i suggerimenti:
o Spegni le VM quando non servono.
o Usa Reserved Instances per VM che restano accese sempre.
o Usa Savings Plans per risparmiare su App Service e SQL.
o Usa Spot VM per lavori non importanti (costano pochissimo).
12.7 Controlla ogni mese
· Vai su Report.
· Scarica il PDF o collega a Power BI per vedere i dati.
· Controlla se il budget è rispettato.
CONCLUSIONI
1. Cosa si impara e quali posizioni si possono ricoprire a lavoro
Ha compreso i fondamenti della governance in Azure
Ha acquisito una visione chiara di cosa significhi governare un ambiente cloud, comprendendo l'importanza di strumenti, processi e controlli per garantire sicurezza, conformità e gestione efficiente delle risorse.
Sa strutturare un ambiente Azure con Management Groups
È in grado di progettare e implementare una gerarchia di Management Groups per organizzare le sottoscrizioni in modo coerente con la struttura aziendale, facilitando l’applicazione centralizzata di policy e ruoli.
Conosce l’uso delle Azure Policy per il controllo delle configurazioni
Ha imparato a creare, assegnare e monitorare policy per garantire che le risorse rispettino standard aziendali, con effetti come deny, audit, modify e append.
È capace di creare ambienti standardizzati con Azure Blueprints
Sa come combinare policy, ruoli, gruppi di risorse e template per distribuire ambienti coerenti e conformi, utili per DevOps e ambienti ripetibili.
Gestisce i permessi con il modello RBAC
Comprende come assegnare ruoli predefiniti o personalizzati a utenti, gruppi o identità di servizio, applicando il principio del minimo privilegio e garantendo la sicurezza degli accessi.
Monitora e ottimizza i costi con Cost Management
È in grado di definire budget, configurare alert di spesa, analizzare i costi per tag, servizio o progetto, e proporre strategie FinOps per l’ottimizzazione delle risorse.
Utilizza i tag per organizzare e tracciare le risorse
Ha imparato a progettare un catalogo di tag aziendali, applicarli sistematicamente e usarli per governance, cost allocation, automazione e reporting.
Gestisce la conformità agli standard di sicurezza
Sa come attivare benchmark come ISO 27001, CIS o PCI DSS, monitorare la conformità con Defender for Cloud e implementare remediation automatizzate.
Implementa monitoraggio e alert per una governance proattiva
È in grado di configurare log, metriche, alert e dashboard per rilevare anomalie, violazioni di policy o eventi critici, migliorando la reattività e la trasparenza operativa.
Automatizza attività di governance con runbook e policy
Ha acquisito competenze nell’uso di Azure Automation, Event Grid e remediation policy per automatizzare attività ripetitive, migliorare la coerenza e ridurre l’errore umano.
Come proporsi nel mondo del lavoro:
Con queste competenze, una persona può candidarsi per ruoli come Cloud Administrator, Cloud Governance Specialist, Azure Consultant o DevOps Engineer. Può valorizzare il proprio profilo evidenziando la capacità di progettare ambienti Azure sicuri, conformi e ottimizzati, di implementare policy e blueprint, di gestire accessi e costi, e di automatizzare processi di governance. Inoltre, può proporsi come figura chiave per supportare le aziende nella transizione verso il cloud in modo controllato e sostenibile.
2. Profilo LinkedIn – Specialista in Governance Cloud su Microsoft Azure
Sono un professionista appassionato di tecnologie cloud, con una solida formazione nella governance di ambienti Microsoft Azure. Dopo un percorso di studio approfondito, ho acquisito competenze pratiche e teoriche che mi permettono di progettare, implementare e gestire ambienti cloud sicuri, conformi e ottimizzati.
🔹 Competenze principali:
· Progettazione di strutture gerarchiche in Azure tramite Management Groups e Sottoscrizioni
· Creazione e assegnazione di Azure Policy per il controllo delle configurazioni
· Distribuzione di ambienti standardizzati con Azure Blueprints
· Gestione degli accessi con Role-Based Access Control (RBAC) e Managed Identities
· Monitoraggio e ottimizzazione dei costi con Microsoft Cost Management e strategie FinOps
· Utilizzo avanzato dei tag per organizzazione, automazione e allocazione dei costi
· Implementazione di standard di conformità (ISO 27001, CIS, PCI DSS) con Defender for Cloud
· Configurazione di alert e dashboard per il monitoraggio continuo e la risposta agli eventi
· Automazione delle attività di governance con Azure Automation, Runbook e Policy Remediation
· Approccio proattivo alla sicurezza, alla compliance e all’efficienza operativa
Obiettivo professionale:
Contribuire alla trasformazione digitale delle aziende supportandole nella gestione del cloud in modo sicuro, scalabile e conforme. Sono alla ricerca di opportunità come Cloud Administrator, Azure Consultant o Governance Specialist, dove poter mettere in pratica le mie competenze e continuare a crescere in un ambiente dinamico e innovativo.
Contattami per collaborazioni, opportunità professionali o progetti legati alla governance in Azure.
3. Curriculum vitae basato su queste competenze
Mario Rossi
Firenze, Italia
mario.rossi@email.com
+39 333 1234567
linkedin.com/in/nomecognomePROFILO PROFESSIONALE
Professionista IT con una solida formazione nella governance di ambienti Microsoft Azure. Specializzato nella progettazione e gestione di infrastrutture cloud sicure, conformi e ottimizzate. Competenze trasversali in policy, controllo accessi, gestione dei costi, automazione e conformità agli standard. Motivato a contribuire alla trasformazione digitale delle aziende attraverso soluzioni cloud scalabili e ben governate.COMPETENZE TECNICHE
- Governance in Microsoft Azure: Management Groups, Subscriptions, Azure Policy, Blueprints
- Sicurezza e Accessi: Role-Based Access Control (RBAC), Managed Identities, PIM
- FinOps e Cost Management: Budget, alert, analisi costi, ottimizzazione risorse
- Tagging e Organizzazione: Cataloghi di tag, policy di tagging, cost allocation
- Conformità: Microsoft Defender for Cloud, ISO 27001, CIS Benchmark, PCI DSS
- Monitoraggio e Audit: Azure Monitor, Activity Log, Log Analytics, alert e dashboard
- Automazione: Azure Automation, Runbook, Event Grid, Policy Remediation
- Infrastructure as Code: ARM/Bicep Templates, distribuzione ambienti standardizzati
- Strumenti: Azure Portal, PowerShell, Azure CLI, Power BI, GitHub
FORMAZIONE
Corso Avanzato – “Governance in Microsoft Azure”
Studio approfondito su:
- Strutturazione gerarchica con Management Groups
- Creazione e assegnazione di Azure Policy
- Implementazione di Blueprints per ambienti Dev/Prod
- Gestione dei permessi con RBAC
- Monitoraggio e automazione della governance
Altri studi
[Inserire eventuali titoli di studio, corsi universitari o certificazioni IT]ESPERIENZE PROFESSIONALI
[Se non hai ancora esperienze lavorative nel settore, puoi inserire progetti personali, stage o attività formative. Esempio:]Progetto personale – Simulazione di ambiente Azure governato
- Progettazione di una gerarchia di Management Groups per un’azienda fittizia
- Implementazione di policy per sicurezza, tagging e controllo costi
- Creazione di blueprint per ambienti Dev e Prod
- Configurazione di alert per budget e conformità
- Automazione di attività ricorrenti con runbook e remediation
Entrare OBIETTIVO PROFESSIONALE in un team IT o cloud per contribuire alla progettazione e gestione di ambienti Azure ben governati. Interesse particolare per ruoli come:
- Cloud Administrator
- Azure Governance Specialist
- DevOps Engineer
- IT Compliance Analyst
LINGUE
- Italiano: madrelingua
- Inglese: buono (B2)
ALTRE INFORMAZIONI
- Disponibilità a trasferte e lavoro da remoto
- Interesse per la formazione continua e le certificazioni Microsoft (es. AZ-900, AZ-104, AZ-500)
4. Lettera di presentazione
Firenze, [Data]
Oggetto: Candidatura per posizione in ambito Cloud / Governance Azure
Gentile [Nome del Responsabile HR o dell’Azienda],
mi chiamo Mario Rossi e desidero sottoporre alla Vostra attenzione la mia candidatura per una posizione in ambito IT, con particolare interesse per ruoli legati alla gestione e governance di ambienti cloud su Microsoft Azure.
Nel mio recente percorso formativo ho approfondito in modo strutturato e pratico i principali strumenti e concetti della governance in Azure. Ho acquisito competenze nella progettazione di ambienti cloud scalabili e sicuri, utilizzando Management Groups, Azure Policy, Blueprints e RBAC per garantire il rispetto degli standard aziendali in termini di sicurezza, conformità e ottimizzazione dei costi. Ho inoltre sviluppato familiarità con strumenti come Cost Management, Defender for Cloud, Azure Monitor e Azure Automation, che mi permettono di contribuire attivamente alla gestione efficiente e proattiva di ambienti cloud complessi.
Sono una persona precisa, curiosa e orientata al miglioramento continuo. Credo fortemente nell’importanza della governance come leva strategica per garantire innovazione sostenibile nel cloud, e sono motivato a mettere in pratica le mie competenze in un contesto dinamico e stimolante.
Sarei lieto di poter approfondire la mia candidatura in un colloquio conoscitivo, durante il quale potrò illustrare nel dettaglio il mio percorso e il valore che potrei portare al Vostro team.
RingraziandoLa per l’attenzione, porgo cordiali saluti.
Mario Rossi
mario.rossi@email.com
+39 333 1234567
linkedin.com/in/nomecognome